Do Not Freak Me Out! The Impact of Lip Movement and Appearance on Knowledge Gain and Confidence


Abstract
:1. Introduction
2. Literature Review
2.1. VA Design Features
2.2. Confidence and Knowledge
3. Methodology
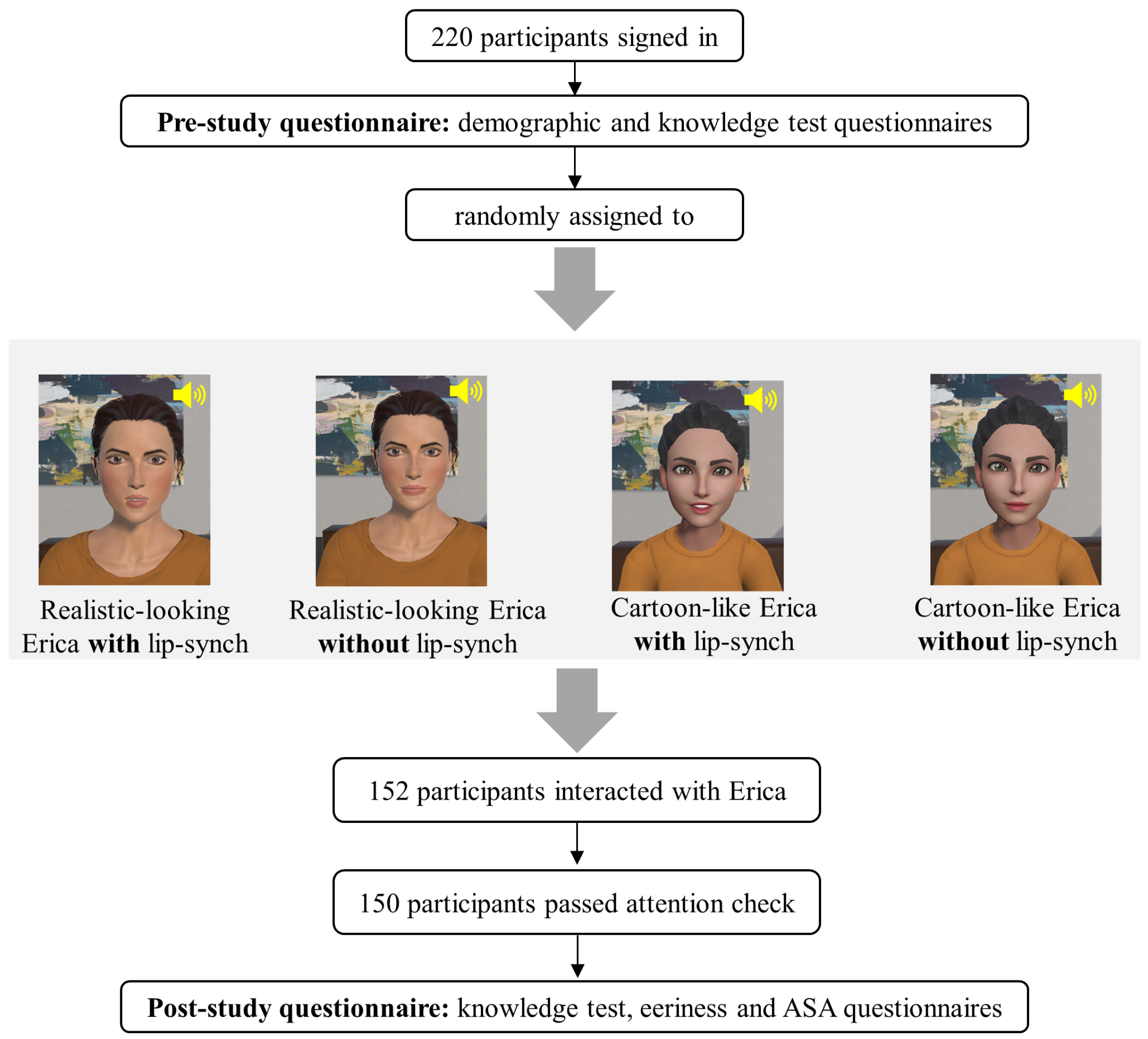
3.1. Study Design
3.2. Recruitment
3.3. Procedure
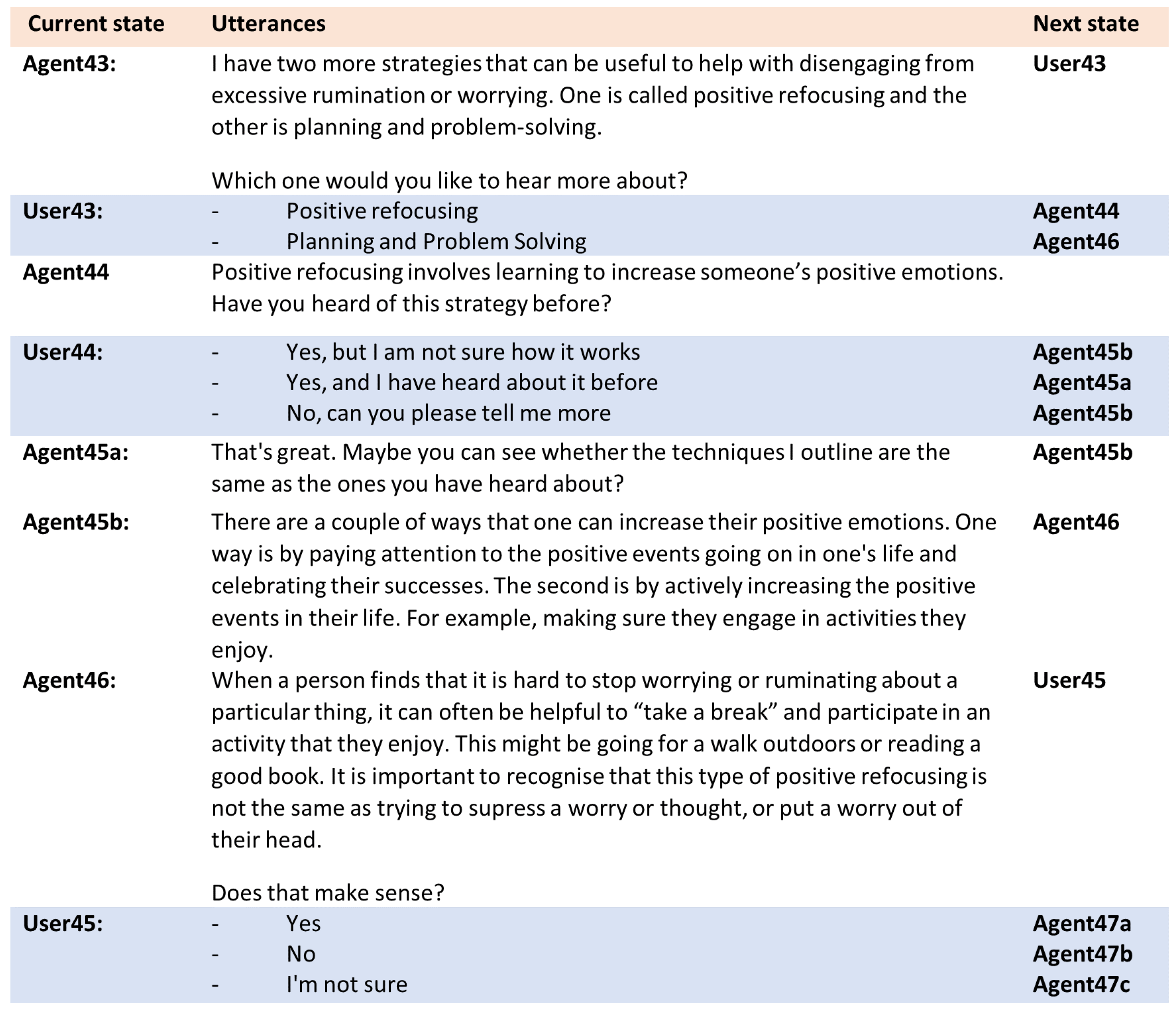
3.4. Dialogue
3.5. Measures
3.5.1. Basic Demographic Data
3.5.2. Knowledge Test
3.5.3. Eeriness Questionnaire
3.5.4. ASA—Short Questionnaire
3.5.5. Logfile Data
3.6. Data Analysis
4. Results
4.1. Participants
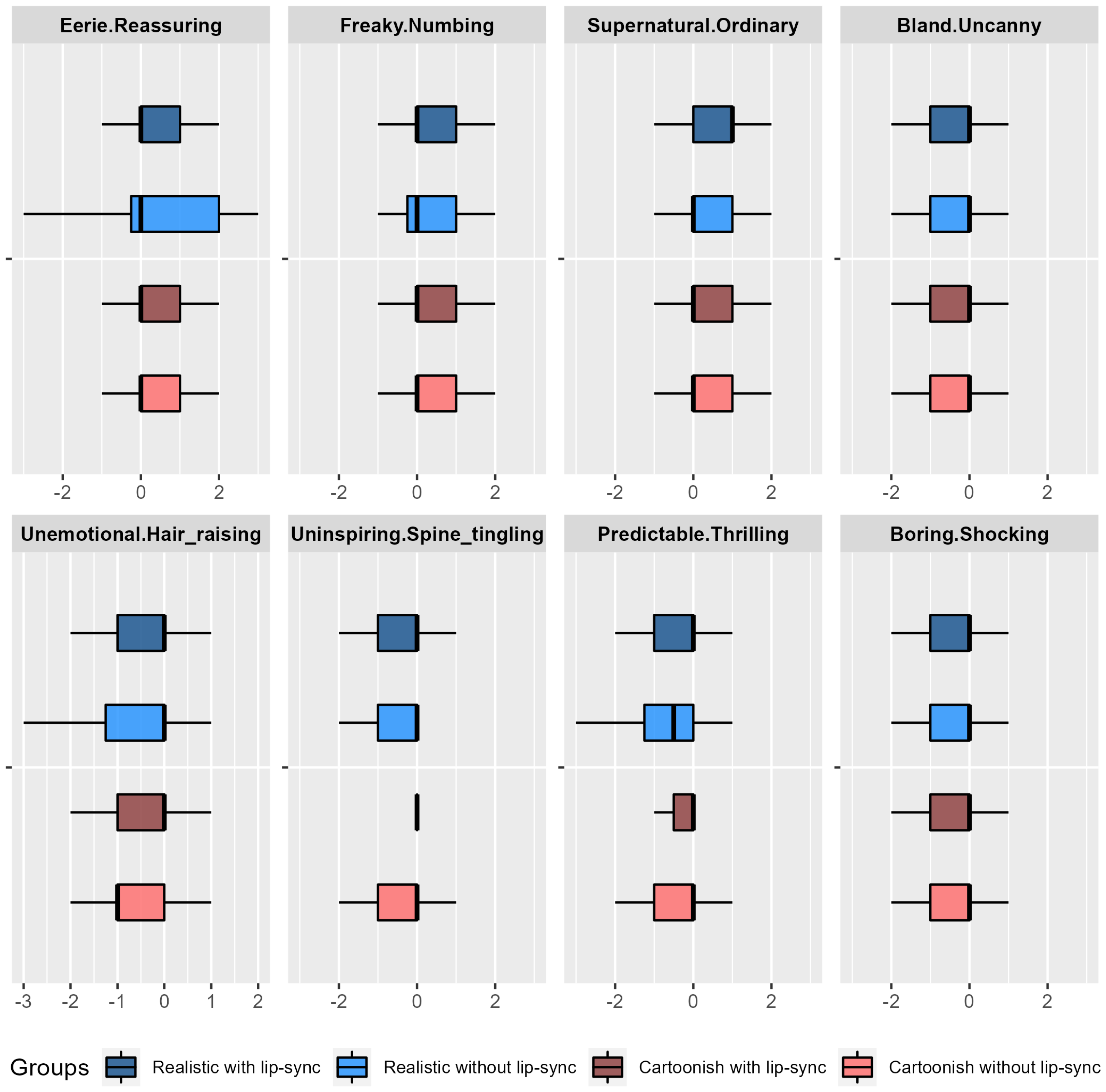
4.2. Eeriness
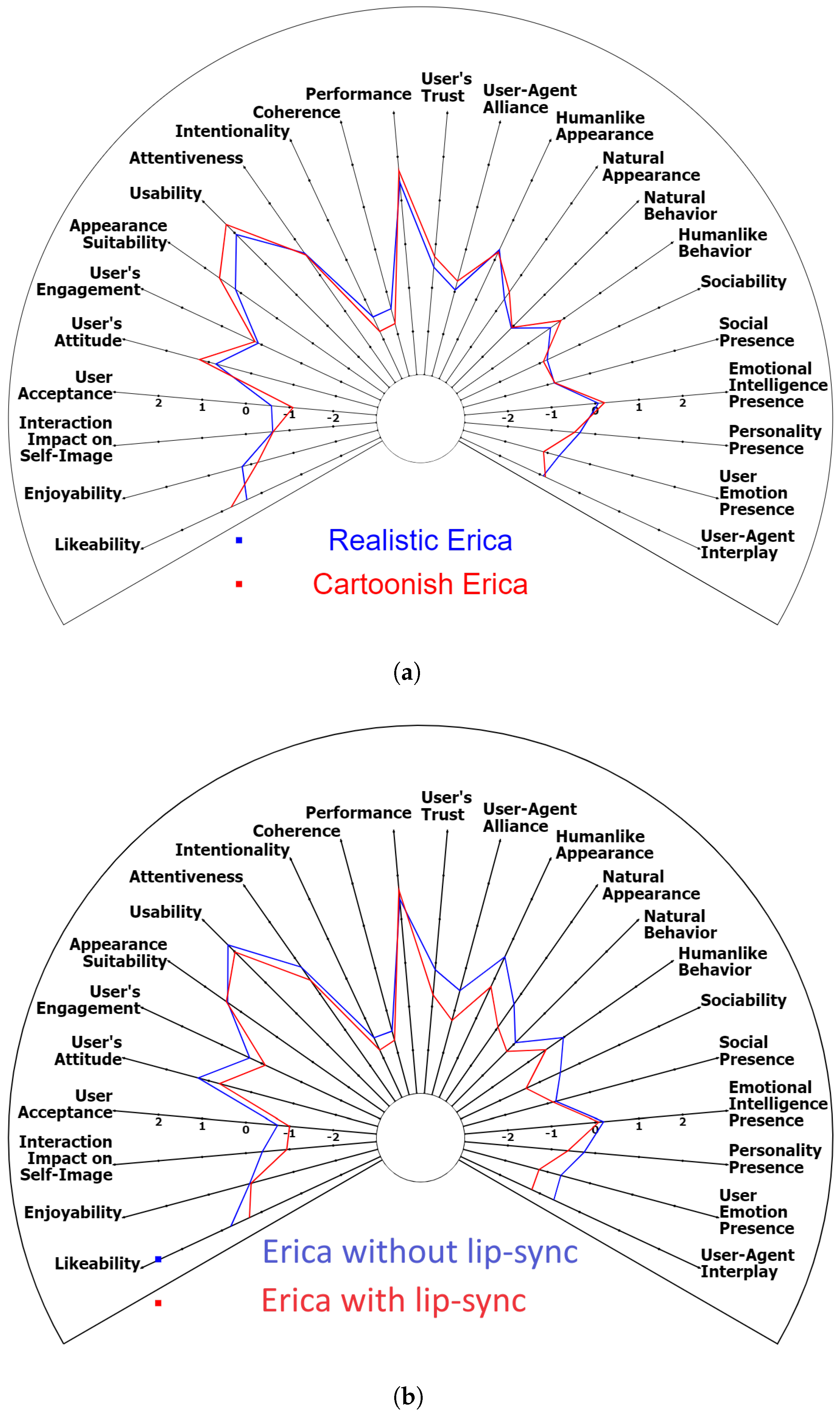
4.3. User–Agent Interaction Experience
4.4. Knowledge Test
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yuan, X.; Chee, Y.S. Design and evaluation of Elva: An embodied tour guide in an interactive virtual art gallery. Comput. Animat. Virtual Worlds 2005, 16, 109–119. [Google Scholar] [CrossRef]
- Aljameel, S.S.; O’Shea, J.D.; Crockett, K.A.; Latham, A.; Kaleem, M. Development of an Arabic conversational intelligent tutoring system for education of children with ASD. In Proceedings of the 2017 IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Annecy, France, 26–28 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 24–29. [Google Scholar]
- Provoost, S.; Lau, H.M.; Ruwaard, J.; Riper, H. Embodied Conversational Agents in Clinical Psychology: A Scoping Review. J. Med. Internet Res. 2017, 19, e151. [Google Scholar] [CrossRef]
- Ter Stal, S.; Kramer, L.L.; Tabak, M.; op den Akker, H.; Hermens, H. Design features of embodied conversational agents in ehealth: A literature review. Int. J. Hum.-Comput. Stud. 2020, 138, 102409. [Google Scholar] [CrossRef]
- Loveys, K.; Sebaratnam, G.; Sagar, M.; Broadbent, E. The effect of design features on relationship quality with embodied conversational agents: A systematic review. Int. J. Soc. Robot. 2020, 12, 1293–1312. [Google Scholar] [CrossRef]
- Ruhland, K.; Peters, C.E.; Andrist, S.; Badler, J.B.; Badler, N.I.; Gleicher, M.; Mutlu, B.; McDonnell, R. A Review of Eye Gaze in Virtual Agents, Social Robotics and HCI: Behaviour Generation, User Interaction and Perception. Comput. Graph. Forum 2015, 34, 299–326. [Google Scholar] [CrossRef]
- Gan, Q.; Liu, Z.; Liu, T.; Zhao, Y.; Chai, Y. Design and user experience analysis of AR intelligent virtual agents on smartphones. Cogn. Syst. Res. 2023, 78, 33–47. [Google Scholar] [CrossRef]
- Thaler, M.; Schlögl, S.; Groth, A. Agent vs. avatar: Comparing embodied conversational agents concerning characteristics of the uncanny valley. In Proceedings of the 2020 IEEE International Conference on Human-Machine Systems (ICHMS), Rome, Italy, 7–9 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Mori, M. the uncanny valley. Energy 1970, 7, 33–35. [Google Scholar] [CrossRef]
- Abdulrahman, A.; Richards, D.; Bilgin, A.A. A Comparison of Human and Machine-Generated Voice. In Proceedings of the 25th ACM Symposium on Virtual Reality Software and Technology, New York, NY, USA, 12–15 November 2019. [Google Scholar] [CrossRef]
- Isbister, K.; Nass, C. Consistency of Personality in Interactive Characters: Verbal Cues, Non-Verbal Cues, and User Characteristics. Int. J. Hum.-Comput. Stud. 2000, 53, 251–267. [Google Scholar] [CrossRef]
- Mitchell, W.J.; Szerszen Sr, K.A.; Lu, A.S.; Schermerhorn, P.W.; Scheutz, M.; MacDorman, K.F.J.i.P. A mismatch in the human realism of face and voice produces an uncanny valley. i-Perception 2011, 2, 10–12. [Google Scholar] [CrossRef]
- Zanbaka, C.; Goolkasian, P.; Hodges, L. Can a virtual cat persuade you?: The role of gender and realism in speaker persuasiveness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 22 April 2006. [Google Scholar] [CrossRef]
- Lee, E.J. The more humanlike, the better? How speech type and users’ cognitive style affect social responses to computers. Comput. Hum. Behav. 2010, 26, 665–672. [Google Scholar] [CrossRef]
- Dickerson, R.; Johnsen, K.; Raij, A.; Lok, B.; Stevens, A.; Bernard, T.; Lind, D.S. Virtual patients: Assessment of synthesized versus recorded speech. Stud. Health Technol. Inform. 2006, 119, 114–119. [Google Scholar]
- Torre, I.; Latupeirissa, A.B.; McGinn, C. How context shapes the appropriateness of a robot’s voice. In Proceedings of the 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 215–222. [Google Scholar] [CrossRef]
- Bahrick, L.E.; Hollich, G. Intermodal Perception. In Reference Module in Neuroscience and Biobehavioral Psychology; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar] [CrossRef]
- Torre, I.; Carrigan, E.; Domijan, K.; McDonnell, R.; Harte, N. The Effect of Audio-Visual Smiles on Social Influence in a Cooperative Human–Agent Interaction Task. ACM Trans. Comput. Hum. Interact. 2021, 28, 1–38. [Google Scholar] [CrossRef]
- Tinwell, A.; Grimshaw-Aagaard, M.; Williams, A. Uncanny behaviour in survival horror games. J. Gaming Virtual Worlds 2010, 2, 3–25. [Google Scholar] [CrossRef]
- Milcent, A.S.; Kadri, A.; Richir, S. Using facial expressiveness of a virtual agent to induce empathy in users. Int. J. Hum. Comput. Interact. 2022, 38, 240–252. [Google Scholar] [CrossRef]
- Peixoto, B.; Melo, M.; Cabral, L.; Bessa, M. Evaluation of animation and lip-sync of avatars, and user interaction in immersive virtual reality learning environments. In Proceedings of the 2021 International Conference on Graphics and Interaction (ICGI), Porto, Portugal, 4–5 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–7. [Google Scholar]
- McDonnell, R.; Breidt, M.; Bülthoff, H.H. Render me real? investigating the effect of render style on the perception of animated virtual humans. ACM Trans. Graph. 2012, 31, 1–11. [Google Scholar] [CrossRef]
- Basori, A.H.; Ali, I.R. Emotion expression of avatar through eye behaviors, lip synchronization and MPEG4 in virtual reality based on Xface toolkit: Present and future. Procedia-Soc. Behav. Sci. 2013, 97, 700–706. [Google Scholar] [CrossRef]
- Pesonen, H.; Leinonen, J.; Haaranen, L.; Hellas, A. Exploring the Interplay of Achievement Goals, Self-Efficacy, Prior Experience and Course Achievement. In Proceedings of the 2023 Conference on United Kingdom & Ireland Computing Education Research, Swansea, Wales, UK, 7–8 September 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Elshan, E.; Zierau, N.; Engel, C.; Janson, A.; Leimeister, J.M. Understanding the design elements affecting user acceptance of intelligent agents: Past, present and future. Inf. Syst. Front. 2022, 24, 699–730. [Google Scholar] [CrossRef]
- Im, H.; Sung, B.; Lee, G.; Kok, K.Q.X. Let voice assistants sound like a machine: Voice and task type effects on perceived fluency, competence, and consumer attitude. Comput. Hum. Behav. 2023, 145, 107791. [Google Scholar] [CrossRef]
- Zhou, M.X.; Mark, G.; Li, J.; Yang, H. Trusting virtual agents: The effect of personality. ACM Trans. Interact. Intell. Syst. (TiiS) 2019, 9, 1–36. [Google Scholar] [CrossRef]
- Baylor, A.L.; Kim, Y. Pedagogical agent design: The impact of agent realism, gender, ethnicity, and instructional role. In Proceedings of the International Conference on Intelligent Tutoring Systems; Springer: Berlin/Heidelberg, Germany, 2004; pp. 592–603. [Google Scholar]
- Salehi, V.; Nia, F.T. Effect of levels of realism in mobile-based pedagogical agents on health e-learning. Future Med. Educ. J. 2019, 9, 40–45. [Google Scholar]
- Tinwell, A.; Grimshaw, M.; Williams, A. Uncanny speech. In Game Sound Technology and Player Interaction: Concepts and Developments; IGI Global: Hershey, PA, USA, 2011; pp. 213–234. [Google Scholar]
- Richards, D.; Miranda Maciel, P.S.; Janssen, H. The Co-Design of an Embodied Conversational Agent to Help Stroke Survivors Manage Their Recovery. Robotics 2023, 12, 120. [Google Scholar] [CrossRef]
- Phan, N.T.T.; Chen, C.H. Taiwanese Engineering Students’ Self-Efficacy and Academic Performance. Arab. World Engl. J. 2022. [Google Scholar]
- Lucero, K.S.; Chen, P. What do reinforcement and confidence have to do with it? A systematic pathway analysis of knowledge, competence, confidence, and intention to change. J. Eur. CME 2020, 9, 1834759. [Google Scholar] [CrossRef] [PubMed]
- Owens, K.M.; Keller, S. Exploring workforce confidence and patient experiences: A quantitative analysis. Patient Exp. J. 2018, 5, 97–105. [Google Scholar] [CrossRef]
- Bandura, A. Self-efficacy: Toward a unifying theory of behavioral change. Psychol. Rev. 1977, 84, 191. [Google Scholar] [CrossRef]
- Bakker, D.; Kazantzis, N.; Rickwood, D.; Rickard, N. A randomized controlled trial of three smartphone apps for enhancing public mental health. Behav. Res. Ther. 2018, 109, 75–83. [Google Scholar] [CrossRef] [PubMed]
- Farley, H. Promoting self-efficacy in patients with chronic disease beyond traditional education: A literature review. Nurs. Open 2020, 7, 30–41. [Google Scholar] [CrossRef]
- Chang, C.Y.; Hwang, G.J.; Gau, M.L. Promoting students’ learning achievement and self-efficacy: A mobile chatbot approach for nursing training. Br. J. Educ. Technol. 2022, 53, 171–188. [Google Scholar] [CrossRef]
- Brinsley, J.; Singh, B.; Maher, C.A. A digital lifestyle program for psychological distress, wellbeing and return-to-work: A proof-of-concept study. Arch. Phys. Med. Rehabil. 2023, 104, 1903–1912. [Google Scholar] [CrossRef]
- Meaghan, C. Guiney, Abigail Harris, A.Z.; Cancelli, A. School Psychologists’ Sense of Self-Efficacy for Consultation. J. Educ. Psychol. Consult. 2014, 24, 28–54. [Google Scholar] [CrossRef]
- Hopman, K.; Richards, D.; Norberg, M.M. A Digital Coach to Promote Emotion Regulation Skills. Multimodal Technol. Interact. 2023, 7, 57. [Google Scholar] [CrossRef]
- Ho, C.C.; MacDorman, K.F. Revisiting the uncanny valley theory: Developing and validating an alternative to the Godspeed indices. Comput. Hum. Behav. 2010, 26, 1508–1518. [Google Scholar] [CrossRef]
- Fitrianie, S.; Bruijnes, M.; Li, F.; Abdulrahman, A.; Brinkman, W.P. The Artificial-Social-Agent Questionnaire: Establishing the Long and Short Questionnaire Versions. In Proceedings of the 22nd ACM International Conference on Intelligent Virtual Agents, IVA ’22, New York, NY, USA, 6–9 September 2022. [Google Scholar] [CrossRef]
- Sidebotham, D.; Barlow, C.J.; Martin, J.; Jones, P.M. Interpreting frequentist hypothesis tests: Insights from Bayesian inference. Can. J. Anesth./J. Can. d’anesthésie 2023, 70, 1560–1575. [Google Scholar] [CrossRef]
- Wagenmakers, E.J.; Marsman, M.; Jamil, T.; Ly, A.; Verhagen, J.; Love, J.; Selker, R.; Gronau, Q.F.; Šmíra, M.; Epskamp, S.; et al. Bayesian inference for psychology. Part I: Theoretical advantages and practical ramifications. Psychon. Bull. Rev. 2018, 25, 35–57. [Google Scholar] [CrossRef]
- Benavoli, A.; Corani, G.; Demšar, J.; Zaffalon, M. Time for a Change: A Tutorial for Comparing Multiple Classifiers through Bayesian Analysis. J. Mach. Learn. Res. 2017, 18, 2653–2688. [Google Scholar]
- Bååth, R. Bayesian first aid: A package that implements Bayesian alternatives to the classical *.test functions in R. Proc. useR 2014, 2014, 2. [Google Scholar]
- Mathur, M.B.; Reichling, D.B. Navigating a social world with robot partners: A quantitative cartography of the Uncanny Valley. Cognition 2016, 146, 22–32. [Google Scholar] [CrossRef]
- Sharma, M.; Vemuri, K. Accepting human-like avatars in social and professional roles. ACM Trans. Hum.-Robot Interact. (THRI) 2022, 11, 1–19. [Google Scholar] [CrossRef]
- Schroeder, N.L.; Adesope, O.O. A Systematic Review of Pedagogical Agents’ Persona, Motivation, and Cognitive Load Implications for Learners. J. Res. Technol. Educ. 2014, 46, 229–251. [Google Scholar] [CrossRef]
- Gurung, N.; Grant, J.B.; Hearth, D. The Uncanny Effect of Speech: The Impact of Appearance and Speaking on Impression Formation in Human–Robot Interactions. Int. J. Soc. Robot. 2023, 1–16. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Setting | N | Female (Male, Non-Binary) |
|---|---|---|---|
| RL+LS | Realistic-looking with lip-sync | 37 | 78% (22%, 0%) |
| RL-LS | Realistic-looking without lip-sync | 35 | 77% (17%, 1%) |
| CL+LS | cartoon-like look with lip-sync | 28 | 89% (11%, 0%) |
| CL-LS | cartoon-like look without lip-sync | 50 | 66% (32%, 2%) |
| Setting | Before Interaction | After Interaction | ||||
|---|---|---|---|---|---|---|
| RL+LS | knowledge | 0.84 | 0.23 | 0.83 | 0.23 | −0.01 [−0.10, 0.07] |
| confidence | 4.98 | 1.00 | 5.93 | 1.00 | 0.95 [0.66, 1.20] | |
| recommending | 4.26 | 0.99 | 5.11 | 0.98 | 0.85 [0.56, 1.20] | |
| RL-LS | knowledge | 0.76 | 0.26 | 0.77 | 0.25 | 0.01 [−0.08, 0.10] |
| confidence | 5.09 | 1.03 | 5.70 | 0.95 | 0.58 [0.35, 0.79] | |
| recommending | 4.46 | 0.96 | 5.22 | 1.27 | 0.75 [0.47, 1.00] | |
| CL+LS | knowledge | 0.82 | 0.24 | 0.83 | 0.25 | , |
| confidence | 4.81 | 1.03 | 5.75 | 1.11 | 0.93 [0.57, 1.30] | |
| recommending | 4.39 | 0.87 | 5.37 | 1.20 | 0.94 [0.55, 1.30] | |
| CL-LS | knowledge | 0.83 | 0.22 | 0.87 | 0.18 | 0.04 [−0.030, 0.11] |
| confidence | 4.89 | 0.79 | 5.81 | 0.86 | 0.93 [0.71, 1.10] | |
| recommending | 4.32 | 0.67 | 5.33 | 1.06 | 0.99 [0.74, 1.20] | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulrahman, A.; Hopman, K.; Richards, D. Do Not Freak Me Out! The Impact of Lip Movement and Appearance on Knowledge Gain and Confidence. Multimodal Technol. Interact. 2024, 8, 22. https://doi.org/10.3390/mti8030022
Abdulrahman A, Hopman K, Richards D. Do Not Freak Me Out! The Impact of Lip Movement and Appearance on Knowledge Gain and Confidence. Multimodal Technologies and Interaction. 2024; 8(3):22. https://doi.org/10.3390/mti8030022
Chicago/Turabian StyleAbdulrahman, Amal, Katherine Hopman, and Deborah Richards. 2024. "Do Not Freak Me Out! The Impact of Lip Movement and Appearance on Knowledge Gain and Confidence" Multimodal Technologies and Interaction 8, no. 3: 22. https://doi.org/10.3390/mti8030022