
Trust Development and Explainability: A Longitudinal Study with a Personalized Assistive System
 , , , , and
, , , , and
Abstract
:1. Introduction
2. Related Work and Experimental Hypotheses
2.1. Initial Trust
2.2. Trust Development over Time
2.3. Trust Violation and Restoration
3. Method
3.1. Experimental Design
3.1.1. Use Case: PLANT as a Personalized Assistive System
- Kinesthetic: Full text with highlights.
- Auditory: Reading and listening to the summary.
- Reading/Writing: Bullet points.
- Visual: Graphical representation.




3.1.2. Participants
3.1.3. Experimental Conditions
- Correct with explanation (CwE): PLANT provides correct recommendations throughout the entire study. From the beginning and throughout the study, the system allows participants to access a short explanatory description of how recommendations are generated by means of NLP algorithms (i.e., a ‘global explanation’).
- hlCorrect without explanation (CwoE): PLANT provides correct recommendations throughout the entire study but does not offer any explanation concerning its inner workings.
- Faulty with explanation (FwE): From the beginning and throughout the study, PLANT allows participants to access a short explanatory description of how recommendations are generated. The system initially provides three correct recommendations to let participants familiarize themselves with the system and to support trust formation. At the fourth interaction, the system provides a faulty recommendation (i.e., trust violation) and offers an explanation focused on the inaccuracy of one of the algorithms used by the system. The final three recommendations are again correct.
- Faulty without explanation (FwoE): PLANT initially provides three correct recommendations to let participants familiarize themselves with the system and to support trust formation. At the fourth interaction, the system provides a faulty recommendation (i.e., trust violation) and offers no explanation for the malfunction. The final three recommendations are again correct.
Malfunction Explanation
3.1.4. Procedure
3.2. Measurements
3.2.1. Questionnaires
3.2.2. Interviews and Focus Groups
4. Results
4.1. Quantitative Analysis
4.1.1. Initial Trust Perception
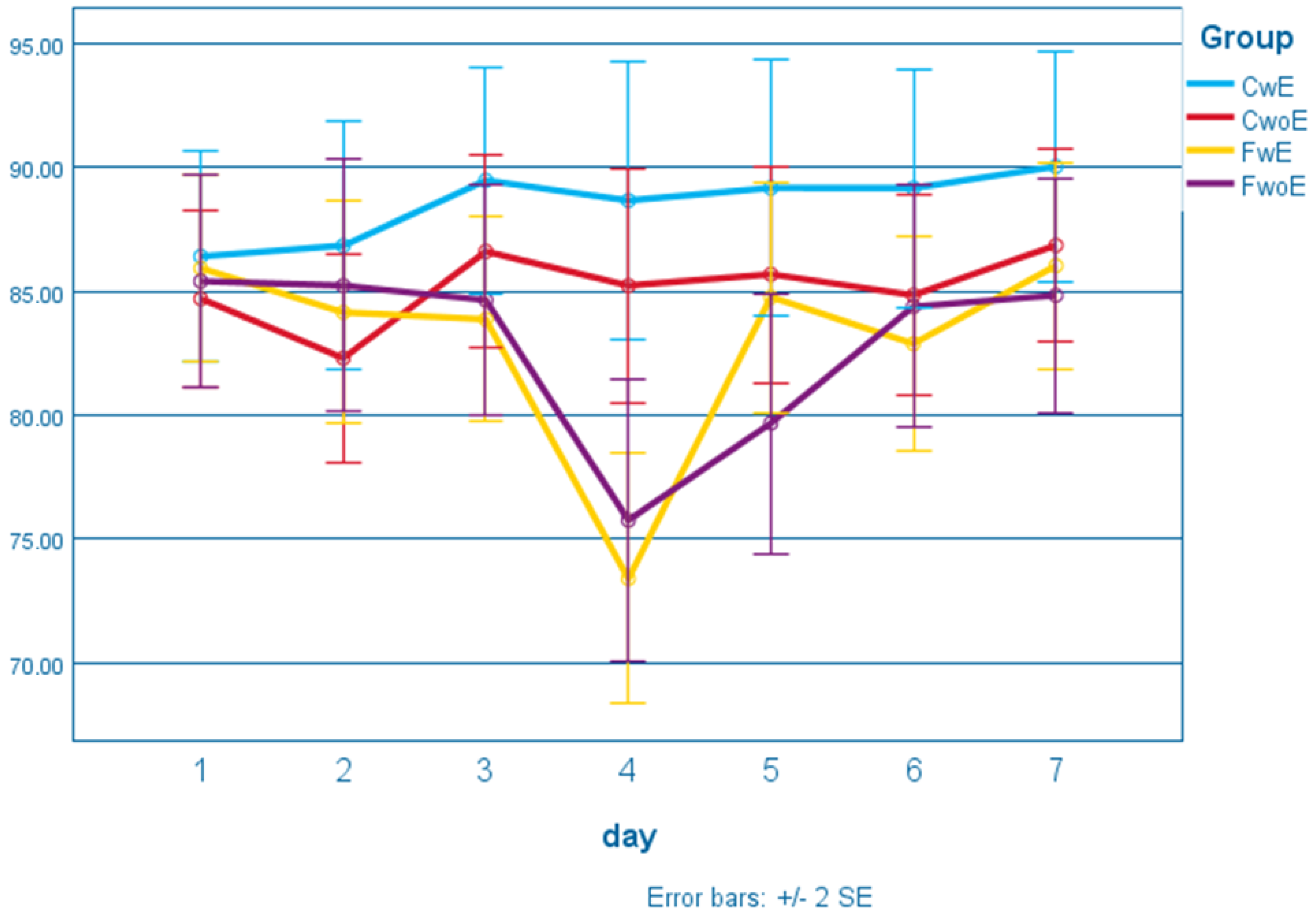
4.1.2. Trust Development over Time in Groups without Malfunction
4.1.3. Trust Violation and Restoration
4.2. Qualitative Analysis
4.2.1. PLANT’s Accuracy and Reliability
4.2.2. Perception of Malfunctions
4.2.3. Transparency through Explanations
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gill, H.; Boies, K.; Finegan, J.E.; McNally, J. Antecedents of trust: Establishing a boundary condition for the relation between propensity to trust and intention to trust. J. Bus. Psychol. 2005, 19, 287–302. [Google Scholar] [CrossRef]
- McAllister, D.J. Affect-and cognition-based trust as foundations for interpersonal cooperation in organizations. Acad. Manag. J. 1995, 38, 24–59. [Google Scholar] [CrossRef]
- Zucker, L.G. Institutional theories of organization. Annu. Rev. Sociol. 1987, 13, 443–464. [Google Scholar] [CrossRef]
- Schoorman, F.D.; Mayer, R.C.; Davis, J.H. An integrative model of organizational trust: Past, present, and future. Acad. Manag. Rev. 2007, 32, 344–354. [Google Scholar] [CrossRef]
- Lewicki, R.J.; Wiethoff, C. Trust, trust development, and trust repair. In The Handbook of Conflict Resolution: Theory and Practice; John Wiley & Sons, Inc.: New York, NY, USA, 2006; Volume 2, pp. 92–119. [Google Scholar]
- Rotter, J.B. Generalized expectancies for interpersonal trust. Am. Psychol. 1971, 26, 443. [Google Scholar] [CrossRef]
- Simpson, J.A. Foundations of interpersonal trust. Soc. Psychol. Handb. Basic Princ. 2007, 2, 587–607. [Google Scholar]
- Lee, J.D.; See, K.A. Trust in automation: Designing for appropriate reliance. Hum. Factors 2004, 46, 50–80. [Google Scholar] [CrossRef]
- Schaefer, K.E.; Chen, J.Y.; Szalma, J.L.; Hancock, P.A. A meta-analysis of factors influencing the development of trust in automation: Implications for understanding autonomy in future systems. Hum. Factors 2016, 58, 377–400. [Google Scholar] [CrossRef] [PubMed]
- Holliday, D.; Wilson, S.; Stumpf, S. User trust in intelligent systems: A journey over time. In Proceedings of the 21st International Conference on Intelligent User Interfaces (IUI), Sonoma, Ca, USA, 7–10 March 2016; ACM: New York, NY, USA, 2016; pp. 164–168. [Google Scholar]
- Basu, C.; Singhal, M. Trust dynamics in human autonomous vehicle interaction: A review of trust models. In Proceedings of the 2016 AAAI Spring Symposium Series, Palo Alto, CA, USA, 21–23 March 2016. [Google Scholar]
- Schmidt, P.; Biessmann, F.; Teubner, T. Transparency and trust in artificial intelligence systems. J. Decis. Syst. 2020, 29, 260–278. [Google Scholar] [CrossRef]
- Kim, J.; Rohrbach, A.; Darrell, T.; Canny, J.; Akata, Z. Textual explanations for self-driving vehicles. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 563–578. [Google Scholar]
- Jacovi, A.; Marasović, A.; Miller, T.; Goldberg, Y. Formalizing trust in artificial intelligence: Prerequisites, causes and goals of human trust in AI. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT), Virtual Event, Canada, 3–10 March 2021; pp. 624–635. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Ajenaghughrure, I.B.; da Costa Sousa, S.C.; Lamas, D. Risk and Trust in artificial intelligence technologies: A case study of Autonomous Vehicles. In Proceedings of the 13th International Conference on Human System Interaction (HSI), Tokyo, Japan, 6–8 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 118–123. [Google Scholar]
- Zang, J.; Jeon, M. The effects of transparency and reliability of in-vehicle intelligent agents on driver perception, takeover performance, workload and situation awareness in conditionally automated vehicles. Multimodal Technol. Interact. 2022, 6, 82. [Google Scholar] [CrossRef]
- De Graaf, M.M.; Malle, B.F. How people explain action (and autonomous intelligent systems should too). In Proceedings of the 2017 AAAI Fall Symposium Series, Arlington, VA, USA, 9–11 November 2017. [Google Scholar]
- Hagras, H. Toward human-understandable, explainable AI. Computer 2018, 51, 28–36. [Google Scholar] [CrossRef]
- Papagni, G.; Koeszegi, S. Understandable and trustworthy explainable robots: A sensemaking perspective. Paladyn J. Behav. Robot. 2020, 12, 13–30. [Google Scholar] [CrossRef]
- Pu, P.; Chen, L. Trust-inspiring explanation interfaces for recommender systems. Knowl.-Based Syst. 2007, 20, 542–556. [Google Scholar] [CrossRef]
- Lomas, M.; Chevalier, R.; Cross, E.V.; Garrett, R.C.; Hoare, J.; Kopack, M. Explaining robot actions. In Proceedings of the 7th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Boston, MA, USA, 5–8 March 2012; pp. 187–188. [Google Scholar]
- Glikson, E.; Woolley, A.W. Human trust in artificial intelligence: Review of empirical research. Acad. Manag. Ann. 2020, 14, 627–660. [Google Scholar] [CrossRef]
- Gambetta, D. Can we trust trust? In Trust: Making and Breaking Cooperative Relations; Department of Sociology, University of Oxford: Oxford, UK, 2000; Chapter 13; pp. 213–237. [Google Scholar]
- Siau, K.; Wang, W. Building trust in artificial intelligence, machine learning, and robotics. Cut. Bus. Technol. J. 2018, 31, 47–53. [Google Scholar]
- van Maris, A.; Lehmann, H.; Natale, L.; Grzyb, B. The influence of a robot’s embodiment on trust: A longitudinal study. In Proceedings of the Companion of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; pp. 313–314. [Google Scholar]
- Rossi, A.; Dautenhahn, K.; Koay, K.L.; Walters, M.L.; Holthaus, P. Evaluating People’s Perceptions of Trust in a Robot in a Repeated Interactions Study. In Proceedings of the International Conference on Social Robotics, Golden, CO, USA, 14–18 November 2020; Springer: Cham, Switzerland, 2020; pp. 453–465. [Google Scholar]
- McKnight, D.H.; Cummings, L.L.; Chervany, N.L. Initial trust formation in new organizational relationships. Acad. Manag. Rev. 1998, 23, 473–490. [Google Scholar] [CrossRef]
- Lyon, F.; Möllering, G.; Saunders, M.N. Introduction. Researching trust: The ongoing challenge of matching objectives and methods. In Handbook of Research Methods on Trust: Second Edition; Edward Elgar Publishing Ltd.: Cheltenham, Gloucestershire, UK, 2015; pp. 1–22. [Google Scholar]
- De Visser, E.J.; Peeters, M.M.; Jung, M.F.; Kohn, S.; Shaw, T.H.; Pak, R.; Neerincx, M.A. Towards a theory of longitudinal trust calibration in human–robot teams. Int. J. Soc. Robot. 2020, 12, 459–478. [Google Scholar] [CrossRef]
- Papagni, G.; de Pagter, J.; Zafari, S.; Filzmoser, M.; Koeszegi, S.T. Artificial agents’ explainability to support trust: Considerations on timing and context. AI Soc. 2022, 38, 947–960. [Google Scholar] [CrossRef]
- Lockey, S.; Gillespie, N.; Holm, D.; Someh, I.A. A Review of Trust in Artificial Intelligence: Challenges, Vulnerabilities and Future Directions. In Proceedings of the 54th Hawaii International Conference on System Sciences (HICSS), Kauai, HI, USA, 5–8 January 2021; Hawaii International Conference on System Sciences. pp. 5463–5472. [Google Scholar]
- Li, X.; Hess, T.J.; Valacich, J.S. Why do we trust new technology? A study of initial trust formation with organizational information systems. J. Strateg. Inf. Syst. 2008, 17, 39–71. [Google Scholar] [CrossRef]
- Andras, P.; Esterle, L.; Guckert, M.; Han, T.A.; Lewis, P.R.; Milanovic, K.; Payne, T.; Perret, C.; Pitt, J.; Powers, S.T.; et al. Trusting intelligent machines: Deepening trust within socio-technical systems. IEEE Technol. Soc. Mag. 2018, 37, 76–83. [Google Scholar] [CrossRef]
- Neri, H.; Cozman, F. The role of experts in the public perception of risk of artificial intelligence. AI Soc. 2020, 35, 663–673. [Google Scholar] [CrossRef]
- Lankton, N.K.; McKnight, D.H.; Tripp, J. Technology, humanness, and trust: Rethinking trust in technology. J. Assoc. Inf. Syst. 2015, 16, 880–918. [Google Scholar] [CrossRef]
- Sood, K. The ultimate black box: The thorny issue of programming moral standards in machines [Industry View]. IEEE Technol. Soc. Mag. 2018, 37, 27–29. [Google Scholar] [CrossRef]
- Kaplan, A.D.; Kessler, T.T.; Brill, J.C.; Hancock, P. Trust in artificial intelligence: Meta-analytic findings. Hum. Factors 2021. [Google Scholar] [CrossRef] [PubMed]
- Dzindolet, M.T.; Peterson, S.A.; Pomranky, R.A.; Pierce, L.G.; Beck, H.P. The role of trust in automation reliance. Int. J. Hum.-Comput. Stud. 2003, 58, 697–718. [Google Scholar] [CrossRef]
- Kerschner, C.; Ehlers, M.H. A framework of attitudes towards technology in theory and practice. Ecol. Econ. 2016, 126, 139–151. [Google Scholar] [CrossRef]
- Haspiel, J.; Du, N.; Meyerson, J.; Robert, L.P., Jr.; Tilbury, D.; Yang, X.J.; Pradhan, A.K. Explanations and expectations: Trust building in automated vehicles. In Proceedings of the Companion of the 2018 ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA, 5–8 March 2018; pp. 119–120. [Google Scholar]
- Du, N.; Haspiel, J.; Zhang, Q.; Tilbury, D.; Pradhan, A.K.; Yang, X.J.; Robert Jr, L.P. Look who’s talking now: Implications of AV’s explanations on driver’s trust, AV preference, anxiety and mental workload. Transp. Res. Part Emerg. Technol. 2019, 104, 428–442. [Google Scholar] [CrossRef]
- Haresamudram, K.; Larsson, S.; Heintz, F. Three levels of AI transparency. Computer 2023, 56, 93–100. [Google Scholar] [CrossRef]
- Zhang, T.; Tao, D.; Qu, X.; Zhang, X.; Lin, R.; Zhang, W. The roles of initial trust and perceived risk in public’s acceptance of automated vehicles. Transp. Res. Part C Emerg. Technol. 2019, 98, 207–220. [Google Scholar] [CrossRef]
- Hancock, P.A.; Billings, D.R.; Schaefer, K.E.; Chen, J.Y.; De Visser, E.J.; Parasuraman, R. A meta-analysis of factors affecting trust in human-robot interaction. Hum. Factors 2011, 53, 517–527. [Google Scholar] [CrossRef] [PubMed]
- Hoff, K.A.; Bashir, M. Trust in automation: Integrating empirical evidence on factors that influence trust. Hum. Factors 2015, 57, 407–434. [Google Scholar] [CrossRef] [PubMed]
- O’neill, O. Autonomy and Trust in Bioethics; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Fossa, F. “I don’t trust you, you faker!” On Trust, Reliance, and Artificial Agency. Teoria 2019, 39, 63–80. [Google Scholar]
- Schwarz, C.; Gaspar, J.; Brown, T. The effect of reliability on drivers’ trust and behavior in conditional automation. Cogn. Technol. Work 2019, 21, 41–54. [Google Scholar] [CrossRef]
- Luhmann, N. Familiarity, confidence, trust: Problems and alternatives. Trust. Mak. Break. Coop. Relat. 2000, 6, 94–107. [Google Scholar]
- Komiak, S.Y.; Benbasat, I. The effects of personalizaion and familiarity on trust and adoption of recommendation agents. MIS Q. 2006, 30, 941–960. [Google Scholar] [CrossRef]
- Yang, J.X.; Unhelkar, V.V.; Li, K.; Shah, J.A. Evaluating effects of user experience and system transparency on trust in automation. In Proceedings of the 12th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Vienna, Austria, 6–9 March 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 408–416. [Google Scholar]
- Cramer, H.; Evers, V.; Ramlal, S.; Van Someren, M.; Rutledge, L.; Stash, N.; Aroyo, L.; Wielinga, B. The effects of transparency on trust in and acceptance of a content-based art recommender. User Model. User-Adapt. Interact. 2008, 18, 455–496. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Baker, A.L.; Phillips, E.K.; Ullman, D.; Keebler, J.R. Toward an understanding of trust repair in human-robot interaction: Current research and future directions. ACM Trans. Interact. Intell. Syst. (TiiS) 2018, 8, 1–30. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD), San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Robinette, P.; Howard, A.M.; Wagner, A.R. Effect of robot performance on human–robot trust in time-critical situations. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 425–436. [Google Scholar] [CrossRef]
- Tolmeijer, S.; Weiss, A.; Hanheide, M.; Lindner, F.; Powers, T.M.; Dixon, C.; Tielman, M.L. Taxonomy of trust-relevant failures and mitigation strategies. In Proceedings of the 15th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Cambridge, UK, 23–26 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3–12. [Google Scholar]
- Desai, M.; Kaniarasu, P.; Medvedev, M.; Steinfeld, A.; Yanco, H. Impact of robot failures and feedback on real-time trust. In Proceedings of the 8th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Tokyo, Japan, 3–6 March 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 251–258. [Google Scholar]
- Freedy, A.; DeVisser, E.; Weltman, G.; Coeyman, N. Measurement of trust in human-robot collaboration. In Proceedings of the 2007 International Symposium on Collaborative Technologies and Systems, Orlando, FL, USA, 25 May 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 106–114. [Google Scholar]
- Elangovan, A.; Auer-Rizzi, W.; Szabo, E. Why don’t I trust you now? An attributional approach to erosion of trust. J. Manag. Psychol. 2007, 22, 4–24. [Google Scholar] [CrossRef]
- Salem, M.; Lakatos, G.; Amirabdollahian, F.; Dautenhahn, K. Would you trust a (faulty) robot? Effects of error, task type and personality on human-robot cooperation and trust. In Proceedings of the 10th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Portland, OR, USA, 2–5 March 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–8. [Google Scholar]
- Perkins, L.; Miller, J.E.; Hashemi, A.; Burns, G. Designing for human-centered systems: Situational risk as a factor of trust in automation. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting (HFES Annual), San Francisco, CA, USA, 27 September–1 October 2010; SAGE Publications Sage CA: Los Angeles, CA, USA, 2010; Volume 54, pp. 2130–2134. [Google Scholar]
- Furner, C.P.; Drake, J.R.; Zinko, R.; Kisling, E. Online review antecedents of trust, purchase, and recommendation intention: A simulation-based experiment for hotels and AirBnBs. J. Internet Commer. 2022, 21, 79–103. [Google Scholar] [CrossRef]
- Walton, D. Dialogical Models of Explanation. ExaCt 2007, 2007, 1–9. [Google Scholar]
- Madumal, P.; Miller, T.; Vetere, F.; Sonenberg, L. Towards a grounded dialog model for explainable artificial intelligence. arXiv 2018, arXiv:1806.08055. [Google Scholar]
- Wang, N.; Pynadath, D.V.; Hill, S.G. Trust calibration within a human-robot team: Comparing automatically generated explanations. In Proceedings of the 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Christchurch, New Zealand, 7–10 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 109–116. [Google Scholar]
- Kraus, J.; Scholz, D.; Stiegemeier, D.; Baumann, M. The more you know: Trust dynamics and calibration in highly automated driving and the effects of take-overs, system malfunction, and system transparency. Hum. Factors 2020, 62, 718–736. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Jiang, S.; Chen, Y.; Campbell, K.D. To explain or not to explain: A study on the necessity of explanations for autonomous vehicles. arXiv 2020, arXiv:2006.11684. [Google Scholar]
- Xu, Z.; Jiang, Z.; Wang, G.; Wang, R.; Li, T.; Liu, J.; Zhang, Y.; Liu, P. When the automated driving system fails: Dynamics of public responses to automated vehicles. Transp. Res. Part C Emerg. Technol. 2021, 129, 103271. [Google Scholar] [CrossRef]
- Riek, L.D. Wizard of oz studies in hri: A systematic review and new reporting guidelines. J. Hum.-Robot. Interact. 2012, 1, 119–136. [Google Scholar] [CrossRef]
- Schaefer, K.E. Measuring trust in human robot interactions: Development of the “trust perception scale-HRI”. In Robust Intelligence and Trust in Autonomous Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 191–218. [Google Scholar]
- Malle, B.F.; Ullman, D. A multidimensional conception and measure of human-robot trust. In Trust in Human-Robot Interaction; Elsevier: Amsterdam, The Netherlands, 2021; pp. 3–25. [Google Scholar]
- Ekman, F.; Johansson, M.; Sochor, J. Creating appropriate trust in automated vehicle systems: A framework for HMI design. IEEE Trans. Hum.-Mach. Syst. 2017, 48, 95–101. [Google Scholar] [CrossRef]
- Leichtmann, B.; Humer, C.; Hinterreiter, A.; Streit, M.; Mara, M. Effects of Explainable Artificial Intelligence on trust and human behavior in a high-risk decision task. Comput. Hum. Behav. 2022, 139, 107539. [Google Scholar] [CrossRef]
- Gurney, J.K. Sue my car not me: Products liability and accidents involving autonomous vehicles. Univ. Ill. J. Law Technol. Policy 2013, 247–277. [Google Scholar]
- O’Leary, D.E. GOOGLE’S Duplex: Pretending to be human. Intell. Syst. Accounting, Financ. Manag. 2019, 26, 46–53. [Google Scholar] [CrossRef]
- Soh, J. The executive’s guide to getting AI wrong. Asian Manag. Insights (Singap. Manag. Univ.) 2022, 9, 74–80. [Google Scholar]
- Frison, A.K.; Wintersberger, P.; Riener, A.; Schartmüller, C.; Boyle, L.N.; Miller, E.; Weigl, K. In UX we trust: Investigation of aesthetics and usability of driver-vehicle interfaces and their impact on the perception of automated driving. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Schraagen, J.M.; Elsasser, P.; Fricke, H.; Hof, M.; Ragalmuto, F. Trusting the X in XAI: Effects of different types of explanations by a self-driving car on trust, explanation satisfaction and mental models. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Virtual, 5–9 October 2020; SAGE Publications Sage CA: Los Angeles, CA, USA, 2020; Volume 64, pp. 339–343. [Google Scholar]
- Kim, G.; Yeo, D.; Jo, T.; Rus, D.; Kim, S. What and When to Explain? On-road Evaluation of Explanations in Highly Automated Vehicles. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2023, 7, 1–26. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order | Participants |
|---|---|
| ‘A’,‘B’,‘C’,‘X’,‘D’,‘E’,‘F’,‘G’ | even user ID |
| ‘A’,‘D’,‘E’,‘X’,‘F’,‘B’,‘C’,‘G’ | odd user ID |
| ‘A’,‘D’,‘F’,‘B’,‘C’,‘Y’,‘E’,‘G’ | even user ID |
| ‘A’,‘B’,‘D’,‘F’,‘E’,‘Y’,‘C’,‘G’ | odd user ID |
| Group | Frequency | Gender | Learning Style | |||||
|---|---|---|---|---|---|---|---|---|
| Male | Female | Other | K | V | A | R | ||
| CwE | 37 (22%) | 14 | 23 | 0 | 18 | 8 | 8 | 3 |
| CwoE | 52 (30%) | 14 | 38 | 0 | 21 | 12 | 5 | 14 |
| FwE | 46 (27%) | 8 | 37 | 1 | 21 | 8 | 5 | 12 |
| FwoE | 36 (21%) | 12 | 24 | 0 | 18 | 10 | 6 | 2 |
| Total | 171 (100%) | 48 | 122 | 1 | 78 | 38 | 24 | 31 |
| Day | Group | Mean | SE | LB | UB |
|---|---|---|---|---|---|
| 3 | CwE | 89.48 | 2.29 | 84.95 | 94.01 |
| CWoE | 86.61 | 1.94 | 82.79 | 90.43 | |
| FWE | 83.87 | 2.06 | 79.81 | 87.93 | |
| FWoE | 84.65 | 2.33 | 80.05 | 89.24 | |
| 4 | CwE | 88.67 | 2.81 | 83.12 | 94.22 |
| CwoE | 85.23 | 2.37 | 80.55 | 89.92 | |
| FwE | 73.40 | 2.52 | 68.42 | 78.38 | |
| FwoE | 75.76 | 2.85 | 70.13 | 81.39 | |
| 5 | CwE | 89.18 | 2.59 | 84.06 | 94.30 |
| CwoE | 85.69 | 2.18 | 81.37 | 90.01 | |
| FwE | 84.77 | 2.33 | 80.18 | 89.36 | |
| FwoE | 79.68 | 2.63 | 74.49 | 84.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zafari, S.; de Pagter, J.; Papagni, G.; Rosenstein, A.; Filzmoser, M.; Koeszegi, S.T. Trust Development and Explainability: A Longitudinal Study with a Personalized Assistive System. Multimodal Technol. Interact. 2024, 8, 20. https://doi.org/10.3390/mti8030020
Zafari S, de Pagter J, Papagni G, Rosenstein A, Filzmoser M, Koeszegi ST. Trust Development and Explainability: A Longitudinal Study with a Personalized Assistive System. Multimodal Technologies and Interaction. 2024; 8(3):20. https://doi.org/10.3390/mti8030020
Chicago/Turabian StyleZafari, Setareh, Jesse de Pagter, Guglielmo Papagni, Alischa Rosenstein, Michael Filzmoser, and Sabine T. Koeszegi. 2024. "Trust Development and Explainability: A Longitudinal Study with a Personalized Assistive System" Multimodal Technologies and Interaction 8, no. 3: 20. https://doi.org/10.3390/mti8030020