
Replacing Histogram with Smooth Empirical Probability Density Function Estimated by K-Moments


School of Civil Engineering, National Technical University of Athens, Heroon Polytechneiou 5, GR 157 80 Zographou, Greece
Sci 2022, 4(4), 50; https://doi.org/10.3390/sci4040050
Submission received: 12 November 2022
/
Revised: 2 December 2022
/
Accepted: 8 December 2022
/
Published: 12 December 2022
Abstract
:Whilst several methods exist to provide sample estimates of the probability distribution function at several points, for the probability density of continuous stochastic variables, only a gross representation through the histogram is typically used. It is shown that the newly introduced concept of knowable moments (K-moments) can provide smooth empirical representations of the distribution function, which in turn can yield point and interval estimates of the density function at a large number of points or even at any arbitrary point within the range of the available observations. The proposed framework is simple to apply and is illustrated with several applications for a variety of distribution functions.
1. Introduction
The concepts of distribution function () and probability density () of a stochastic (or random) variable ( with realizations ; notice the notational convention to underline stochastic variables—the Dutch convention) are central in Kolmogorov’s foundation of probability in 1933 [1,2] and its applications. (Here, we adhere to the original Kolmogorov’s terms, noting that in the English literature is also known as the cumulative distribution function.) Their estimation, based on a sample of , is crucial in most applications.
The standard estimate of was again introduced by Kolmogorov [3], who termed it the empirical distribution, and is still in common use [4], sometimes under the name sample distribution function. Denoting the ith order statistic in a sample of size , i.e., the ith smallest of the variables arranged in increasing order (), the standard estimate is:
where is the number of the values in the observed sample that do not exceed (an integer). The function has a staircase form with discontinuities at each of the observations (see Appendix A for an illustration and more details). If is a continuous variable, almost certainly the values are distinct and the jump of at equals . Apparently then, the representation of the continuous by the discontinuous is not ideal. This representation has two additional problems, i.e., (a) for the resulting is 0, and (b) for the resulting is 1. Both these are problematic results if the variable is unbounded.
Both the latter problems are usually tackled with the notion of so-called plotting positions (e.g., [5])—a rather unsatisfactory name. There is a variety of plotting position formulae, each of which is a modification of Equation (1) by adding one or two constants in the numerator and/or the denominator. A review of these formulae and their justification is provided by Koutsoyiannis (2022) [6], along with a set of new proposed ones, derived using the theoretical properties of order statistics.
One could also think to tackle the discontinuity problem by replacing the staircase function by some type of interpolation (e.g., linear or logarithmic). However, the thus resulting function would again be too rough for practical applications. In particular, a rough function, where the roughness is a statistical sampling effect rather than an intrinsic property of the distribution function, cannot support reliable estimation of derivatives. Since the density is the first derivative of the distribution , the above framework cannot be used to estimate the former. An illustration of the roughness of and , if the former is estimated from Equation (1) and the latter by the numerical derivative of the former, is provided in Appendix A (in particular, in Figure A1).
Methods for a detailed estimation of the probability density at different points are lacking. Instead, a gross estimation based on the histogram constitutes the standard representation of the density. Yet, the estimation of the density is necessary for several tasks, e.g., those involving hazard (where the hazard function is defined as ; see [7]) or entropy (where entropy is the expectation of properly standardized; see Section 3.3).
The histogram representation is constructed by choosing (a) an interval that contains all observations (often called the range) and (b) a number of equally spaced bins, so that the width of the bins is
The number is usually small, typically chosen by the old Sturges’ rule [8]:
For example, for a sample size , this results in . The underlying rationale for the rule and comparisons with additional rules are provided by Scott [9]. Once are chosen, the density estimate is
The entire framework for the construction of histogram entails subjectivity, and lacks detail and accuracy.
As an alternative to constructing a smooth empirical density function, Rosenblatt [10] and Parzen [7] proposed the use of kernel smoothing. They have been followed by several researchers who developed the method further [11,12,13,14]. This is regarded as a non-parametric method, but it uses a specified kernel function which contains parameters, where both the function expression and its parameters are arbitrarily chosen by the user. Typical kernel functions include uniform, triangular, quadratic (Epanechnikov), biweight, triweight, normal, and even atomic kernels [15,16]. While the methods of this type may provide a smooth function, their reliability is questionable, and the results are affected by a great deal of subjectivity owing to user choices. These characteristics are illustrated in Appendix A (in particular, in Figure A2).
Here, we propose a new method of estimation of the probability density based on the concept of knowable moments, abbreviated as K-moments. As shown in [6] (pp. 147–249) and summarized in the next section, the noncentral K-moment of order , , can: (a) yield a reliable and unbiased estimate from a sample, up to order equal to the sample size , and (b) be assigned a value of return period, or equivalently distribution function estimate, . In addition, the sequence of estimates form a smooth function which can be used in estimating the probability density at a large number of points (as opposed to the roughness implied by Equation (1)—or other versions thereof based on plotting positions and eventually on order statistics—and as illustrated in Figure A1 of Appendix A). The estimate is based on the notion of order statistics but, contrary to their standard use, where only one sample value is used at a time, the K-moment framework combines many order statistics simultaneously, thus converting a rough arrangement to smooth, without involving any subjectively chosen kernel function.
2. K-Moments and Their Relevance
2.1. Definition and Interpretation
We recall that the noncentral (or raw) moment of order p of a stochastic variable is defined as the expectation:
with representing the mean. Let be independent copies of , forming a sample. Then, the standard estimator of from the sample is
It is well known that the estimator of the noncentral moment is unbiased, i.e.,
While unbiasedness is theoretically guaranteed, the convergence of to is extraordinarily slow if is not very low [17]. In practice, for large or moderate (greater than 2 or 3, depending on the sample size), what we actually calculate by applying the standard estimator, is an estimate of some extreme quantity, rather than an estimate of the moment . To see this, we recall that for positive and for large (or even modest) p the approximation holds, so that
Thus, unless p is very small, we cannot infer the value of from data, i.e., it is unknowable (Koutsoyiannis, 2019 [18]; see also [6], pp. 125–126). This is the case even if the sample size n is extraordinarily large [6,18]. This reduces the power of the concept of moments for statistical inference, which is the formal probabilistic induction (the modern version of the Aristotelian epagoge/ἐπαγωγή) and is based on expectations, estimated from samples by virtue of stationarity and ergodicity.
To obtain a knowable moment of order p, Koutsoyiannis [18] raised to a low power, and for the remaining multiplicative terms, replaced with , hence defining the noncentral knowable moment (or noncentral K-moment) of orders (p, q) as:
with the most interesting special case obtained for :
Koutsoyiannis [6,18] also introduced other types of K-moments, among which here we will use, in addition to , the tail-based (noncentral) moments:
where is the tail function.
For an interpretation of K-moments we consider the maximum of stochastic variables , which is the largest (pth) order statistic:
It is readily obtained that if is the distribution function of and its probability density function, then those of are:
where the former is the product of p instances of (justified by the fact that the variables are independent copies of , by definition of the sample concept), while the latter is the derivative of with respect to . The expected maximum of order p of , i.e., the expected value of , is therefore:
and this is precisely the noncentral K-moment . Likewise, the minimum of the p variables
has expectation:
which is the tail K-moment .
It is thus easy to see that the sequence of is non-decreasing and that of is non-increasing as p increases.
2.2. Estimation of K-Moments
Several estimators of the K-moments have been developed in [6], among which here we use the unbiased ones [6] (pp. 193–196 and 229–231):
where
and is the gamma function. This allows estimation of the K-moments for any order p from 1 to . Thus, from a sample of size we can estimate a number of noncentral and tail moments equal to (notice that ), with high reliability and low uncertainty (see [6], p. 195). It can be easily verified that for any order p,
which is a necessary condition for unbiasedness. Special cases of K-moment estimator coefficients are shown in Table 1.
The fact that for suggests that, as the moment order increases, progressively fewer data values determine the moment estimate, until it remains only one (the maximum for the noncentral moment and the minimum for the tail moment), when , with . Furthermore, if then for all , and therefore estimation becomes impossible.
2.3. Estimation of the Distribution Function at K-Moment Values
Order statistics have an important advantage over other statistics, as to each of them we can assign a value of the distribution function, or equivalently, the return period. We recall that for a specific event the return period, , is defined to be the mean time between consecutive occurrences of the event . Assuming that the event is the exceedance of a certain level , i.e., , the return period is related to the distribution function by
where is a time window width (time scale or time step) used to define the metric (e.g., year if is the annual rainfall total). This is known as the return period of maxima.
Likewise, for the non-exceedance of the value , i.e., , the return period (of minima) is
As seen above, the K-moments are closely related to order statistics and therefore it becomes possible to assign return periods to K-moment values. Intuitively, we can expect that the pth noncentral K-moment (the value ) will correspond to a return period of about 2pD. Τhis is precise for a symmetric distribution and for p = 1, as is the mean value which has return period 2D. (For instance, the mean of annual rainfall is exceeded, or non-exceeded, on the average, every two years). As we will see below, the return period cannot be much lower than 2pD for any p and for any distribution.
Generally, we can expect that the return period is an increasing function of the moment order p, with a relationship of approximate proportionality:
As justified above, a coefficient of proportionality equal to 2 can be used as a first rough approximation (rule of thumb that helps intuition). However, more precisely, the coefficient of proportionality, call it , depends on the distribution function and the order p, but its variation is not wide. The precise definition of is:
For given p and distribution function , , , and are analytically or numerically determined from their definitions, but this might be complicated. However, the small variation of with p makes possible a very good approximation if we first accurately determine (a) the value for , and (b) the asymptotic value . The value is very easy to determine, as it refers to the return period of the mean:
and can also be reliably estimated from a sample by Equation (1).
Furthermore, in a number of customary distributions, specifically those belonging to the domain of attraction of the Extreme Value Type I distribution (see [6] (pp. 76–79 and 235–236), has a constant value, independent of the distribution:
where γ is the Euler constant. For heavy tailed distributions depends on the higher tail index only. Details are given in [6] (pp. 208–215), while for the distributions examined in this study, which are listed along with their main characteristics in Table 2, they are shown in Table 3.
Given and , the coefficient for any order can be satisfactorily (see [6], (pp. 216–218)) approximated with the following simple relationship:
while more accurate approximations are given in [6] (pp. 208–215) and also discussed in Section 4 below. Equation (26) yields a linear relationship between the return period T and p:
from which we find
Likewise, for the tail moments we have:
with
while the limiting value depends only on the lower tail index and is for the normal and other symmetric distributions, and for distributions with lower-tail index equal to one such as the exponential and Pareto distributions (see Table 3).
Again we can use the approximation:
and find
3. Results
3.1. Estimation of Probability Density
Based on the above framework, we can estimate values of K-moments and , namely the ordered values . To each one of them we can assign an empirical estimate of the distribution function and . This is similar to the distribution function values assigned via the order statistics (the plotting positions) except that (a) the number of values in the K-moments framework is twice that of the case of order statistics, and (b) the arrangement of point estimates in the former case is smooth, while in the latter is rough. The smooth arrangement allows a direct estimate of the probability density for . As at points and , the values of the distribution function have been estimated from Equations (28) and (32), i.e., and , it is then straightforward to approximate the derivative by its discrete version:
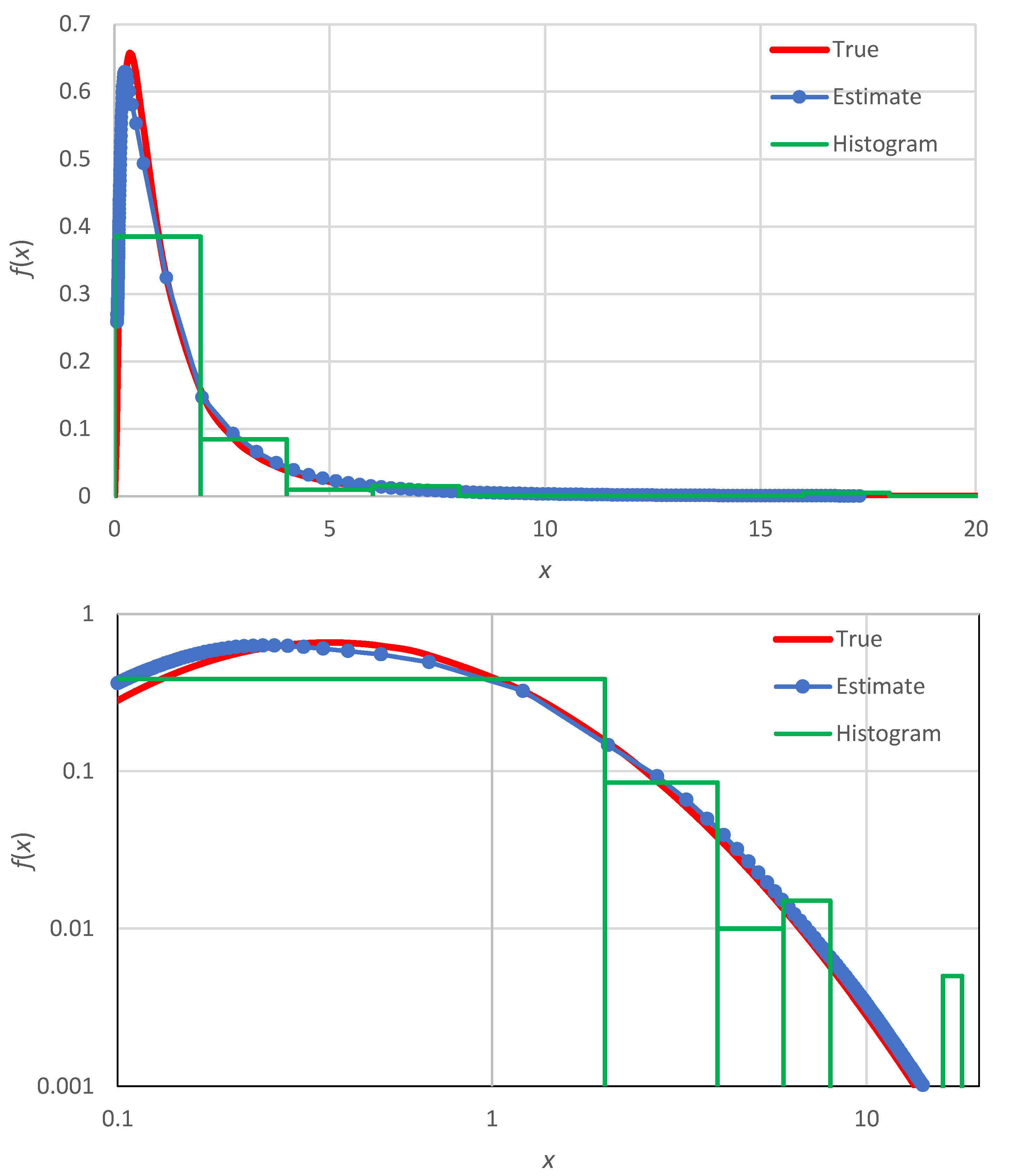
This procedure will result in different values of the density . In Section 4 we will see that it is possible to expand the number of estimation points by using non-integer orders p, but in general the number is more than enough. This is illustrated in Figure 1 for a synthetic sample of size 100, generated from a lognormal distribution, also in comparison with a histogram of bins (slightly more than the number resulting from Sturges’ rule, ).
Clearly the histogram representation of the true density (also shown in in Figure 1) is poor: five of its ten bins are empty, its shape is rough and the increasing limb of the density (for small ) is not captured at all. In contrast, the proposed method results in a very faithful representation of the true density.
3.2. Uncertainty Assessment
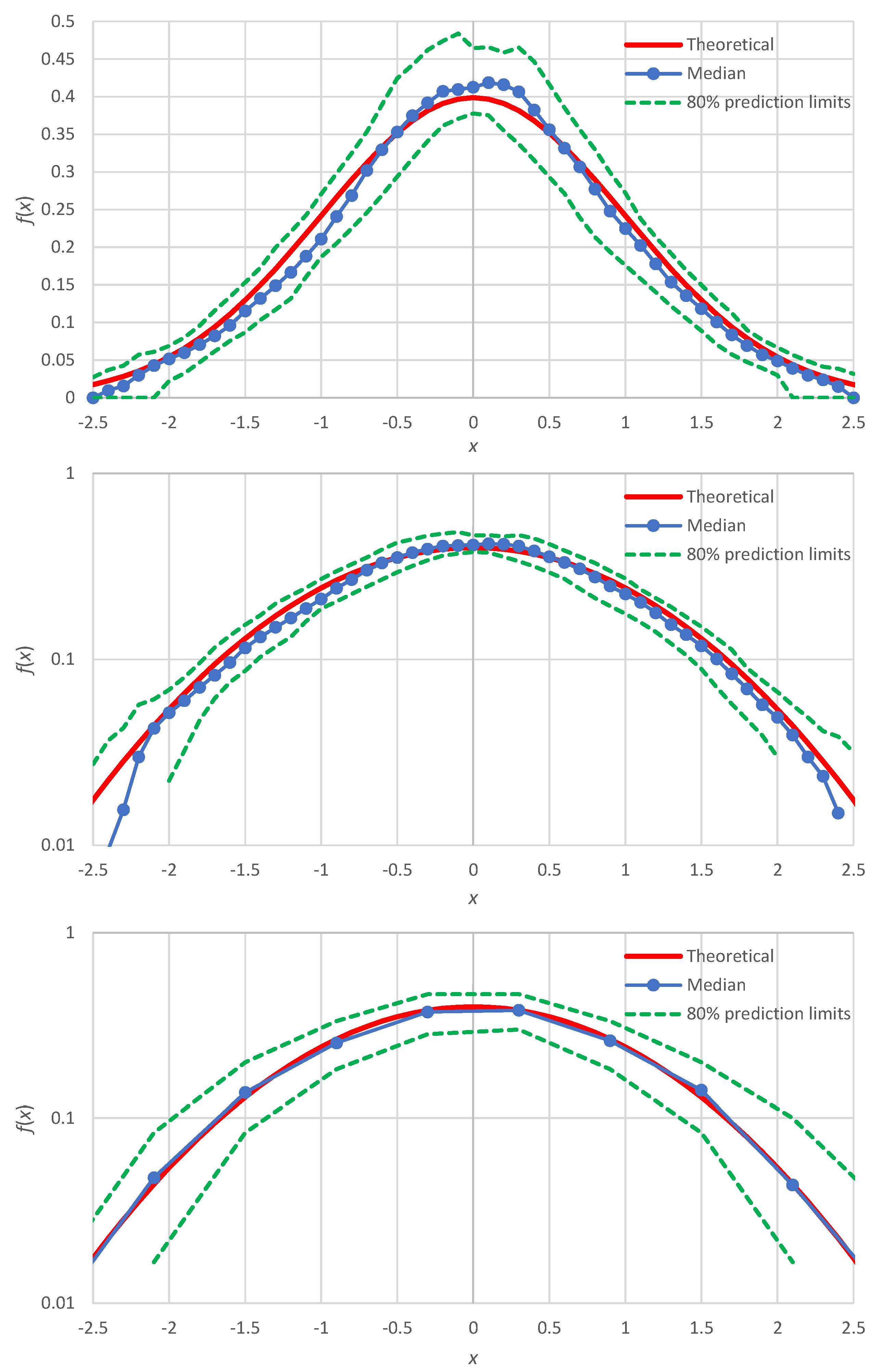
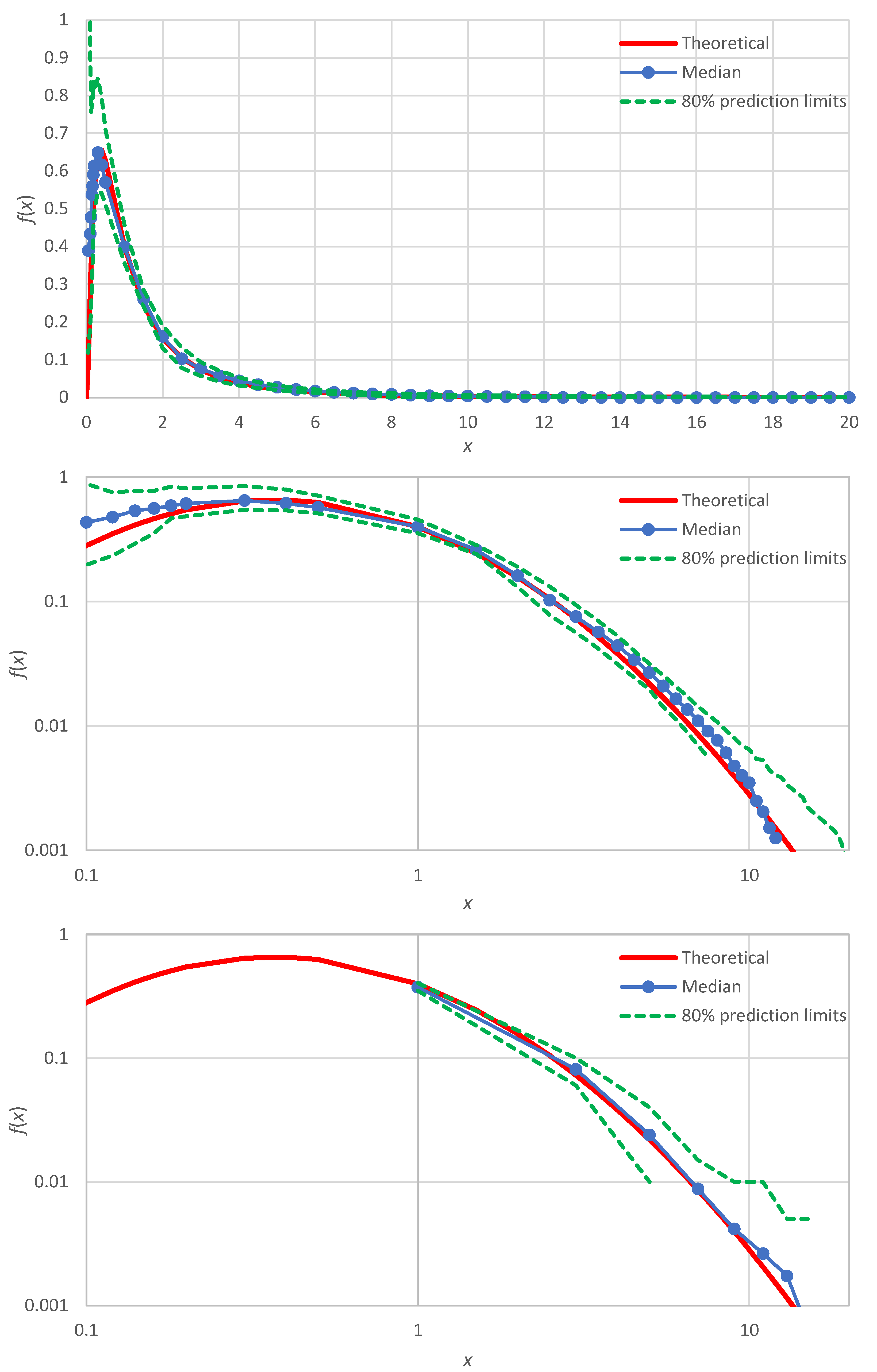
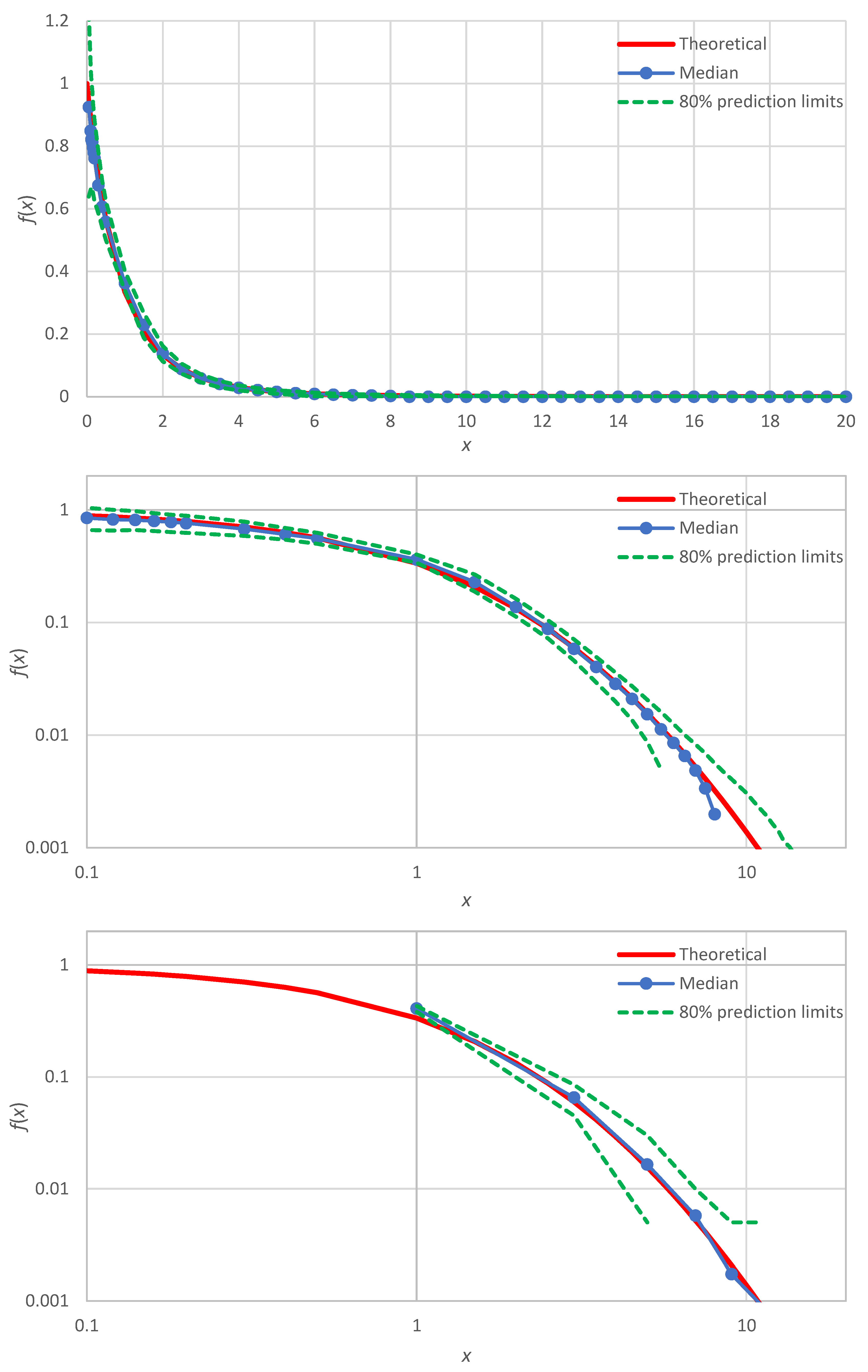
A more systematic illustration is made by means of Monte Carlo distribution with 100 realizations of samples of 100 items each, for all four distributions listed in Table 2. The Monte Carlo simulations allow assessing the estimation uncertainty in terms of prediction limits. The results of this investigation are shown in Figure 2 for the exponential distribution, Figure 3 for the normal distribution, Figure 4 for the lognormal distribution and Figure 5 for the Pareto distribution.
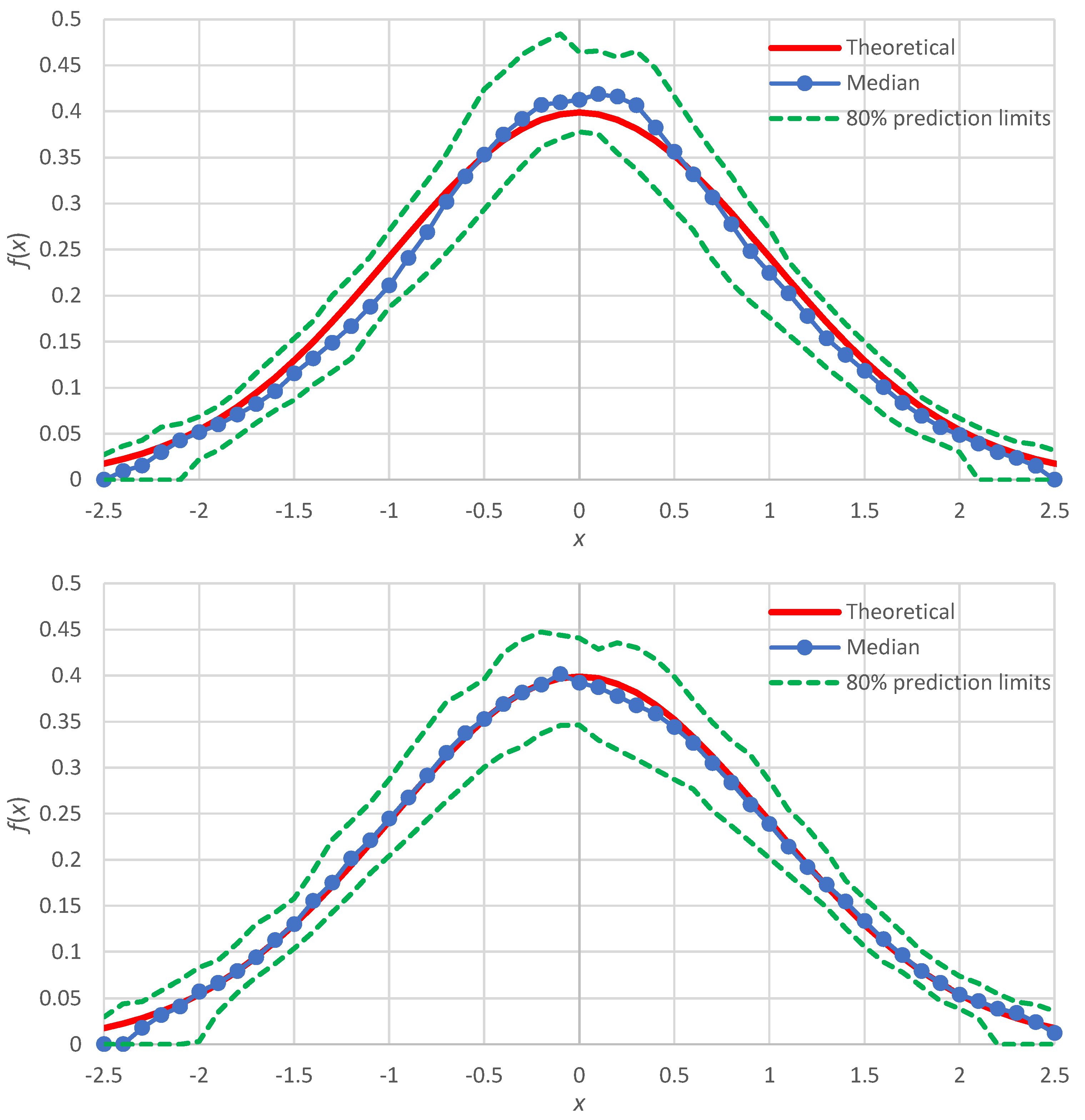
In all cases, the estimated probability density, expressed in terms of the median of the simulations (or the average thereof, which is very close to the median and was not plotted in the figures), harmonizes with the true shape of the probability density. This applies to the body of the distribution, as well as to the right and left tails, which are better discerned in the double logarithmic plots of the figures (middle panels). Slight discrepancies appear in the normal distribution (Figure 3), which will be discussed in Section 4. For comparison, in each of the figures, double logarithmic plots are also provided for the classical histograms (lower panels). In these, the simulated medians harmonize well with the true densities, yet the points are too few and the left tails of the distributions are not captured. As per the uncertainty, the proposed method clearly outperforms the histogram framework as the zones defined by prediction limits are quite narrower in the former case than in the latter.
3.3. Entropy Estimation
Most of the statistical estimators (e.g., of moments) do not involve the probability density and thus they do not require the estimation thereof. Entropy is an exception, because its very definition relies on the logarithm of the density function. Namely, the entropy of the stochastic variable is defined as:
where is a background measure, which can be any probability density, proper (with integral equal to 1) or improper (meaning that its integral diverges). Typically, it is an (improper) Lebesgue density, i.e., a constant with dimensions , so that the argument of the logarithm function be dimensionless. Here, we assume .
The common practice is to estimate through a histogram. However, this technique is not perfect because of the rough shape of the estimate and the subjective choices about the bins. These may result in a distorted estimate. To illustrate this, we consider the following example, based on the exponential distribution. For a sample of size from this distribution, the expected values of the highest of the values is , where is the nth harmonic number, and that of the lowest is (see Koutsoyiannis [6], pp. 182–183). Therefore, the expected value of the range is . In the limiting case of only one bin (), the entropy will be estimated as . At the opposite end, if we choose too many bins, , so that each one contains either one or zero elements, then the probability density estimate will be either 0 (for the bins containing no element) or where . The former case does not contribute to entropy, so that the summation to estimate entropy (by converting the integral in (34)) is made on the bins containing elements. The entropy in this case will be This depends on k and by choosing a large k it can become arbitrarily small (even negative) as . The true entropy is (Table 2). Now, assuming, for instance, the true entropy is , while the estimates are and . These values indicate the subjectivity of the estimates. A good choice of will result in good estimate, yet we cannot be certain about its reliability as we cannot control the factors producing the estimation errors.
The more detailed representation of the probability density allows for a better estimation of entropy. However, we must have in mind that in unbounded stochastic variables there is uncertainty beyond the maximum (or the minimum) observed value in the sample, which we denote as . For a variable bounded by zero from below and unbounded from above, we can proceed with the correction proposed by Koutsoyiannis and Sargentis [19] to take into account the contribution of probability density for .
Specifically, the expectation of any function can be calculated as
The quantity can directly be estimated from the available data, by approximating the integral with a sum. Assuming that the data are given in terms of density estimates at points , with and , we have:
To estimate the quantity we assume that beyond an exponential approximation is sufficient for the purpose:
where and are parameters to be estimated. For the moment of order of the distribution we have:
where is the incomplete gamma function. In particular for we have
with
Furthermore, for the entropy we have
We assume that is known from the data, estimated as . In the case that, in addition, can reliably be estimated as , the sought parameter is estimated as . However, in the outmost available point of the tail, is not adequately reliable. An alternative option is to estimate from the data the quantity
where is determined by the standard sample estimator. In this case, solving the rightmost of Equation (39) for we find
This allows estimation of for the expectation of any function . We note that the correction is applied only if the quantity within the square root turns out to be positive (which is usually the case).
If the distribution is unbounded from both below and above (e.g., in the normal distribution), then we apply the procedure twice for the lower and upper tail. In this case, we have and where the subscripts L and R refer to left (below) and right (above), respectively. In this case, Equation (42) automatically includes both corrections and in Equation (43) we should replace with the sum .
Application of this technique for the Monte Carlo simulations described above are given in Table 4, in which we see that the method works well.
4. Discussion
The method is described above in its minimal configuration. Improvements are possible in several ways, e.g., to take into account possible dependence of the consecutive variables (i.e., when we do not have an observed sample but a time series), or to use more accurate representations of the relationship between K-moments and their corresponding values of distribution functions. These issues are studied in Koutsoyiannis [6] (pp. 147–249)—but not for the density estimation.
Here, we discuss the case of improvement of the distribution function estimation for the normal distribution, for which the simulation results (Figure 3) showed slight discrepancies. As shown in [6] (pp. 209–213), the more accurate representation of the Λ-coefficients for the normal distribution are
where for the normal distribution . In this case, we find:
In addition, noticing that the points plotted around are at greater distances to each other than the other points, we can use non-integer values of between 1 and 2. Repeating the Monte Carlo simulation with these two modifications, we get the results shown in Figure 6 (lower panel), which are in better agreement with the true density than those of the minimal version, also reproduced in Figure 6 (upper panel).
Even if we use the minimal version, it is possible and sometimes useful to calculate for non-integer order . In this case, we can even find (see derivation in Appendix B) an analytical expression for the probability density estimate, which for the noncentral K-moments is
where
and is given by Equation (18). It is reminded that denotes the nth harmonic number. Similar equations can be developed for the tail K-moments.
Notice in Equations (48) and (49) that the lower limit of the sum is not the non-integer p but its floor . This means that the functions and will not be fully continuous, but only left continuous. However, the discontinuities are practically negligible for .
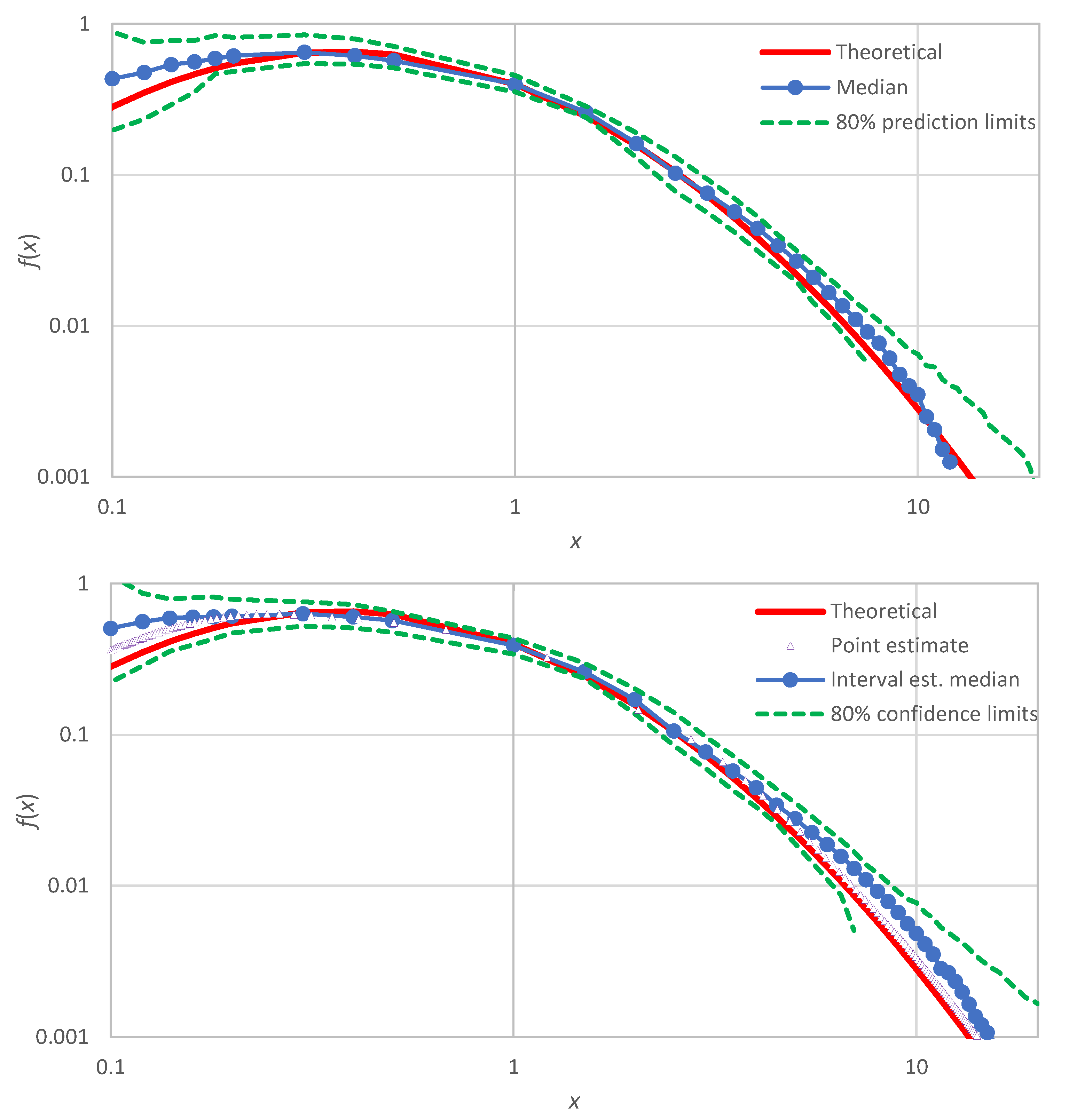
A final note is that the proposed method, in addition to providing point estimates , can also produce interval estimates of by means of confidence limits determined by Monte Carlo simulation. These differ from the prediction limits of Section 3.2, which were constructed for a known true distribution function that was used to generate several (in our case 100) realizations of samples. For the confidence limits, the true distribution is assumed unknown and the simulation is made from the estimate , which is determined at the points and The generation from this distribution is easy: the values are generated as , where is a random number from the uniform distribution in [0, 1]. The inverse function is determined by interpolation (and occasionally extrapolation) from the sequence of points , with the sequence of being . The interpolation is better made in terms of the quantity instead of .
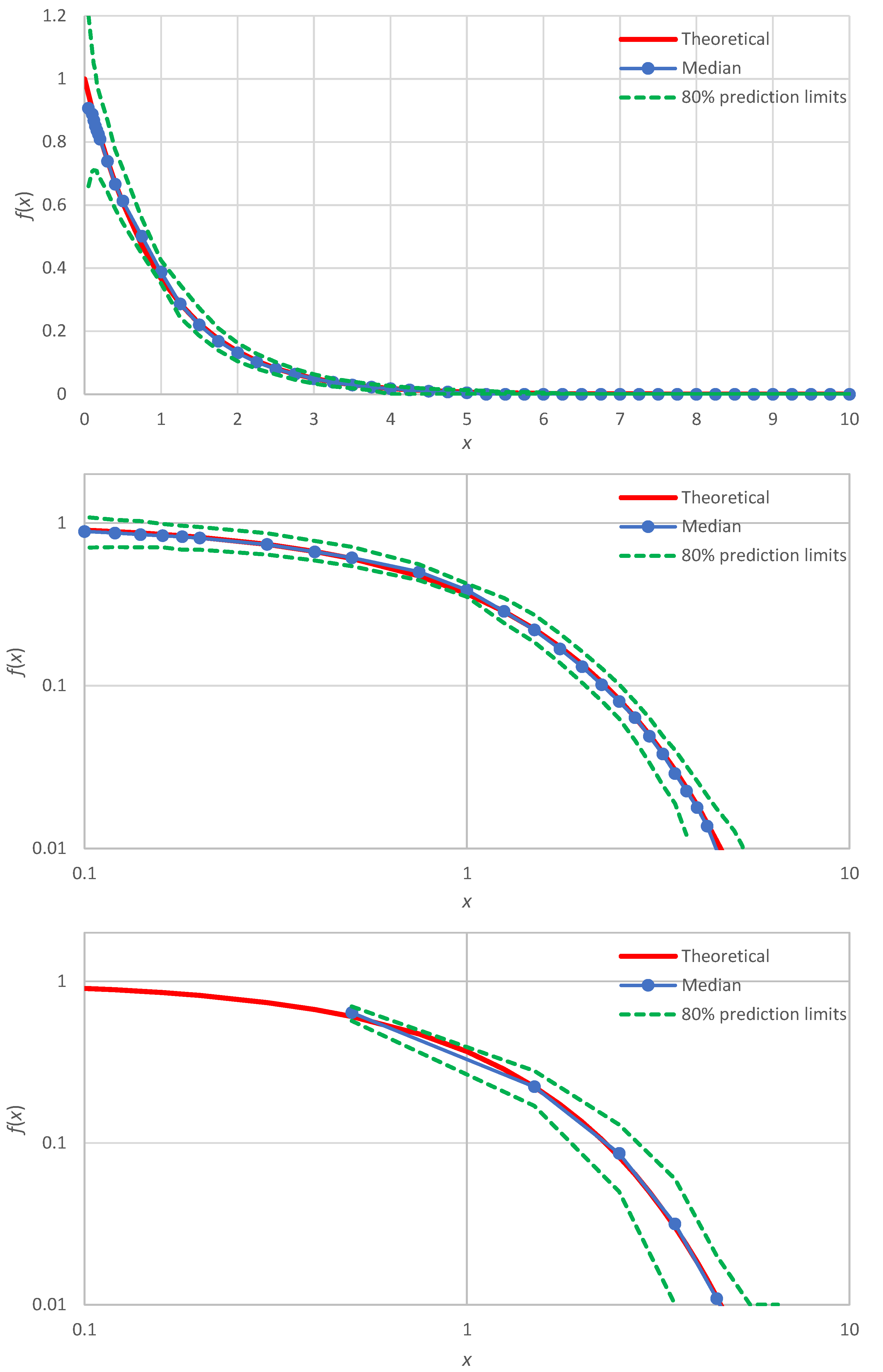
An illustration for the example of Figure 1 (lognormal distribution) is shown in Figure 7 (lower panel), where the produced confidence band is also compared with uncertainty band defined by the prediction limits of the lognormal distribution (upper panel of Figure 7). We observe that: (a) the confidence band (lower panel) has about the same width as the uncertainty band (upper panel), and (b) the true distribution, which was not used in the Monte Carlo simulation of the lower panel, is contained within the produced confidence band—as it should.
5. Conclusions
For continuous stochastic variables, the proposed framework is an improved, detailed and smooth alternative to the widely used concept of the histogram, which provides only a gross representation of the probability density. The proposed framework is based on the concept of knowable moments (K-moments) and its characteristics that make possible the estimate of the probability density are:
- The ability to reliably estimate from a sample, moments of high order, up to the sample size.
- The ability to assign values of the distribution function to each estimated value of K-moment.
- The smoothness of the estimated values, which are linear combinations of a number of observations, rather than based on a single observation as in other approaches.
The latter characteristic is crucial in estimating the probability density, which is the first derivative of the distribution function.
Prominent characteristics of the proposed method of density estimation, confirmed by several applications of the method for a variety of distribution functions, are:
- The faithful representation of the true density, both in the body and the tails of the distribution.
- The dense and smooth shape, owing to the ability to estimate values of the density at very many points (even for any arbitrary point) within the range of the available observations.
- The low uncertainty of estimates.
- The ability to provide both point and interval estimates (confidence limits), with the latter becoming possible by Monte Carlo simulation.
- The simplicity of the calculations, which can be made in a typical spreadsheet environment.
Specifically, the calculations include the following steps, which summarize the numerical part of the proposed method.
- We sort the observed sample in ascending order.
- We calculate the estimates from Equations (17) and (18).
- We estimate the coefficient from Equation (24) and calculate from Equation (30).
- We calculate the estimates and from Equations (28) and (32) for all derived in step 2. (By plotting the tails and in double logarithmic graphs, we check whether the empirically estimated tail indices agree with those assumed in Step 4 and, if not, we repeat steps 4 and 5 with new estimates).
- We calculate the estimates of from Equation (33).
These calculations are illustrated in the Supporting Information, which contains a spreadsheet accompanying this paper. This gives a full-scale application of the method, related to the construction of Figure 1.
A problem of the method is that it requires one to have an idea of the type of the true distribution, in terms of its upper- and lower-tail indices, in order to estimate the asymptotic Λ-coefficients (). If the sample size is large, the K-moments can support the estimation of these tail indices (cf. points steps 4 and 5 above). However, for small samples () their estimation becomes problematic and higher uncertainty is induced. This issue requires further investigation.
Supplementary Materials
As a supporting information, an Excel spreadsheet with application of the method (including the construction of Figure 1) can be downloaded at: https://www.mdpi.com/article/10.3390/sci4040050/s1 or from http://www.itia.ntua.gr/2256/.
Funding
This research received no external funding but was conducted for scientific curiosity.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
I thank three reviewers for their constructive comments which helped improve the paper.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Illustration of Alternative Techniques
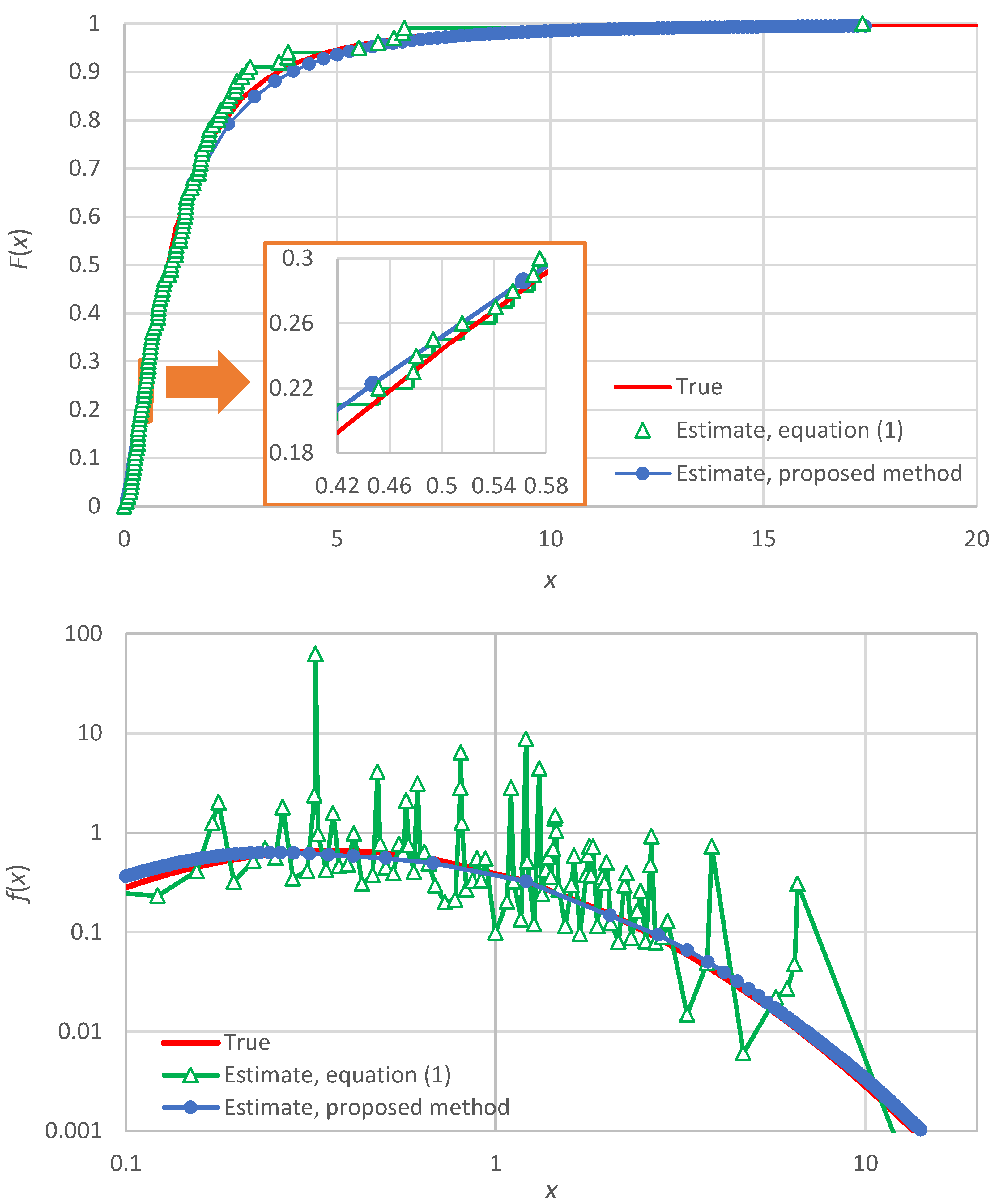
As stated in the Introduction, if we use the empirical estimate of the distribution function by Equation (1), we get a staircase-like function, which is illustrated in the upper panel of Figure A1 using the same data as in Figure 1. This is not a continuous function and thus it does not allow calculation of the derivative, which is the probability density . One may think of keeping only the left-hand point in each stair step (the triangles in Figure A1) and replace the staircase form with a broken line (drawing straight-line segments between two consecutive points depicted as triangles). However, even in this case there will be roughness, which is hugely magnified if we take the derivative (slope of each linear segment). This is depicted in the lower panel of Figure A1, where the thus estimated values of vary by several orders of magnitude and the different point estimates are far distant from the true . The huge roughness and variability that appear exclude the possibility of regarding the numerical results by this method as estimates of the probability density.
As an alternative that can derive a smooth density estimate, the use of kernel functions has been proposed, as described in the Introduction. The kernel estimate of probability density is derived as
where is the kernel function, which has the property , and is a parameter, termed the bandwidth. Two of the most common kernel functions are the uniform:
and the normal (Gaussian):
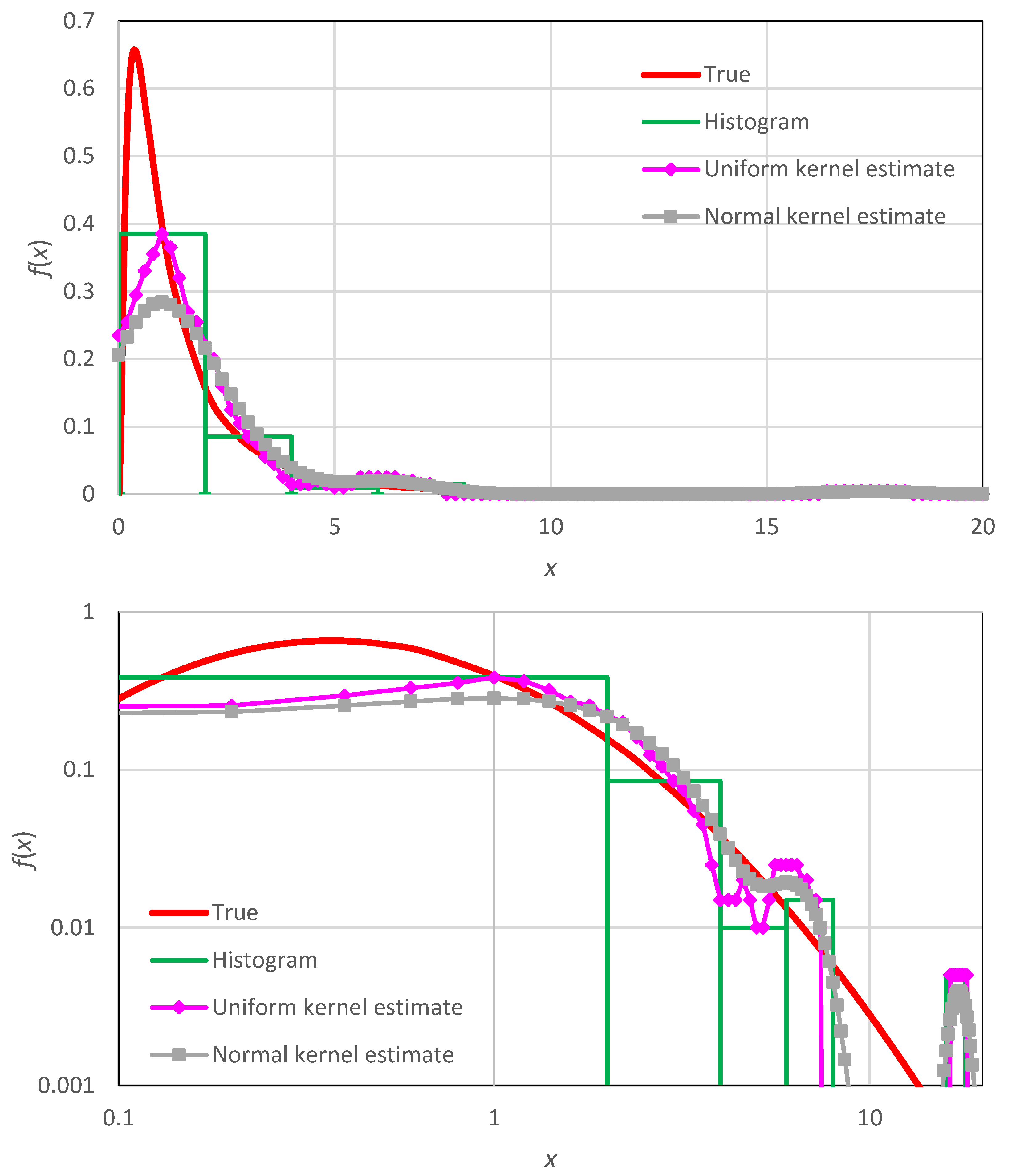
These are illustrated in Figure A2, where we may observe that, despite producing a smooth curve, the entire shape remains erratic and follows the empirical histogram, rather than approaching the true density. In addition, the curves are much more subjective than the histogram per se, as they depend on the user choices of the kernel and its bandwidth.
Figure A1.
Illustration of the estimate of the distribution function using Equation (1) (upper, with inset to better depict the staircase form) and that of the probability density (lower) as the numerical derivative of with the staircase form replaced by a broken line form. The data series of Figure 1 was used ( values, generated from a lognormal distribution with parameters ; see Table 2). The abscissae of the points of estimates are the midpoints of the intervals . As the estimates of vary by orders of magnitude, logarithmic axes are used. In both panels the estimates by the proposed method (from Figure 1) are also shown for comparison.
Figure A1.
Illustration of the estimate of the distribution function using Equation (1) (upper, with inset to better depict the staircase form) and that of the probability density (lower) as the numerical derivative of with the staircase form replaced by a broken line form. The data series of Figure 1 was used ( values, generated from a lognormal distribution with parameters ; see Table 2). The abscissae of the points of estimates are the midpoints of the intervals . As the estimates of vary by orders of magnitude, logarithmic axes are used. In both panels the estimates by the proposed method (from Figure 1) are also shown for comparison.

Figure A2.
Illustration of the probability density estimate using (a) the histogram (Equation (4) with 10 bins for the range [0, 20]), (b) the uniform kernel (Equation (A2) with ) and (c) the normal kernel (Equation (A3) with ), plotted in Cartesian (upper) and logarithmic (lower) axes. The data series of Figure 1 was used ( values, generated from a lognormal distribution with parameters ; see Table 2).
Figure A2.
Illustration of the probability density estimate using (a) the histogram (Equation (4) with 10 bins for the range [0, 20]), (b) the uniform kernel (Equation (A2) with ) and (c) the normal kernel (Equation (A3) with ), plotted in Cartesian (upper) and logarithmic (lower) axes. The data series of Figure 1 was used ( values, generated from a lognormal distribution with parameters ; see Table 2).

Appendix B. Proof of Equation (48)
We start from the obvious relationship
where the first term in the right-hand side is the density . The left-hand side can be approximated using Equation (28), from which we find
The second term in the right-hand side of Equation (A4) can be approximated by using the estimate of . Combining Equations (17) and (18) and replacing with the floor in the lower limit of the sum, we find:
By taking the derivative with respect to , after the algebraic manipulations we get:
or
where we have used the definitions of and in Equations (18) and (49), respectively. By combining all above we find:
which can also be written in the form of Equation (48).
References
- Kolmogorov, A.N. Grundbegriffe der Wahrscheinlichkeitsrechnung; Ergebnisse der Math: Berlin, Germany, 1933. [Google Scholar]
- Kolmogorov, A.N. Foundations of the Theory of Probability, 2nd ed.; Chelsea Publishing Company: New York, NY, USA, 1956; p. 84. [Google Scholar]
- Kolmogorov, A.N. Sulla determinazione empirica di una legge di distribuzione. Inst. Ital. Attuari Giorn 1933, 4, 83–91. [Google Scholar]
- Papoulis, A. Probability and Statistics; Prentice-Hall: Hoboken, NJ, USA, USA, 1990. [Google Scholar]
- Weisstein, E.W. Plotting Position. From MathWorld—A Wolfram Web Resource. Available online: https://mathworld.wolfram.com/PlottingPosition.html (accessed on 6 November 2022).
- Koutsoyiannis, D. Stochastics of Hydroclimatic Extremes—A Cool Look at Risk, 2nd ed.; Kallipos Open Academic Editions: Athens, Greece, 2022; p. 346. ISBN 978-618-85370-0-2. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Sturges, H.A. The choice of a class interval. J. Am. Stat. Assoc. 1926, 21, 65–66. [Google Scholar] [CrossRef]
- Scott, D.W. Sturges’ rule. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 303–306. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on some nonparametric estimates of a density function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Scott, D.W. On optimal and data-based histograms. Biometrika 1979, 66, 605–610. [Google Scholar] [CrossRef]
- Terrell, G.R.; Scott, D.W. Variable kernel Density estimation. Ann. Stat. 1992, 20, 1236–1265. [Google Scholar] [CrossRef]
- Chen, Y.C. A tutorial on kernel density estimation and recent advances. Biostat. Epidemiol. 2017, 1, 161–187. [Google Scholar] [CrossRef]
- Węglarczyk, S. Kernel density estimation and its application. In ITM Web of Conferences; EDP Sciences: Les Ulis, France, 2018; Volume 23, p. 00037. [Google Scholar] [CrossRef]
- Scott, D.W. Kernel density estimation. Wiley StatsRef Stat. Ref. Online 2018, 1–7. [Google Scholar] [CrossRef]
- Eremenko, S.Y. Atomic Machine Learning. J. Neurocomput. 2018, 3, 13–28. [Google Scholar]
- Lombardo, F.; Volpi, E.; Koutsoyiannis, D.; Papalexiou, S.M. Just two moments! A cautionary note against use of high-order moments in multifractal models in hydrology. Hydrol. Earth Syst. Sci. 2014, 18, 243–255. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D. Knowable moments for high-order stochastic characterization and modelling of hydrological processes. Hydrol. Sci. J. 2019, 64, 19–33. [Google Scholar] [CrossRef] [Green Version]
- Koutsoyiannis, D.; Sargentis, G.-F. Entropy and Wealth. Entropy 2021, 23, 1356. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Illustration of the probability density estimate using the proposed method, plotted in Cartesian (upper) and logarithmic (lower) axes. A data series of values was used, generated from a lognormal distribution (see Table 2) with parameters . The density of the generating distribution is marked as “true”. The points marked as “estimate” are calculated by the proposed method (Equation (33)) and their abscissae are the midpoints of the intervals and . For comparison, the histogram of 10 bins, calculated as in Equation (4) for the range [0, 20] (width ) is also shown.
Figure 1.
Illustration of the probability density estimate using the proposed method, plotted in Cartesian (upper) and logarithmic (lower) axes. A data series of values was used, generated from a lognormal distribution (see Table 2) with parameters . The density of the generating distribution is marked as “true”. The points marked as “estimate” are calculated by the proposed method (Equation (33)) and their abscissae are the midpoints of the intervals and . For comparison, the histogram of 10 bins, calculated as in Equation (4) for the range [0, 20] (width ) is also shown.

Figure 2.
Illustration of the median estimate and uncertainty (in terms of prediction limits) of the probability density using the proposed method, plotted in Cartesian (upper) and logarithmic (middle) axes. The original results from the proposed method are interpolated at the points that are plotted in the graphs. For comparison, results for the classical histogram with 10 bins are also shown (lower), plotted with abscissae equal to the midpoints of the bins. The true distribution is exponential with parameters as in Table 4, from which 100 data series of values each were generated and processed to produce the uncertainty band.
Figure 2.
Illustration of the median estimate and uncertainty (in terms of prediction limits) of the probability density using the proposed method, plotted in Cartesian (upper) and logarithmic (middle) axes. The original results from the proposed method are interpolated at the points that are plotted in the graphs. For comparison, results for the classical histogram with 10 bins are also shown (lower), plotted with abscissae equal to the midpoints of the bins. The true distribution is exponential with parameters as in Table 4, from which 100 data series of values each were generated and processed to produce the uncertainty band.

Figure 3.
Illustration of the median estimate and uncertainty (in terms of prediction limits) of the probability density as in Figure 2 but for the normal distribution with parameters as in Table 4.

Figure 4.
Illustration of the median estimate and uncertainty (in terms of prediction limits) of the probability density as in Figure 2 but for the lognormal distribution with parameters as in Table 4.

Figure 5.
Illustration of the median estimate and uncertainty (in terms of prediction limits) of the probability density as in Figure 2 but for the Pareto distribution with parameters as in Table 4.

Figure 6.
Comparison of the Monte Carlo simulation results for the normal distribution (with parameters as in Table 4) with the minimal version of the method (upper; copy of the upper panel of Figure 3) and the enhanced version (lower; using Equations (46) and (47)).

Figure 7.
Comparison of the Monte Carlo simulation results for prediction limits of the lognormal distribution (with parameters as in Table 4) with the minimal version of the method (upper; copy of the middle panel of Figure 4) and for the confidence limits of the empirical probability density of Figure 1 (lower). The plotted “point estimates” are precisely those shown in Figure 1.
Figure 7.
Comparison of the Monte Carlo simulation results for prediction limits of the lognormal distribution (with parameters as in Table 4) with the minimal version of the method (upper; copy of the middle panel of Figure 4) and for the confidence limits of the empirical probability density of Figure 1 (lower). The plotted “point estimates” are precisely those shown in Figure 1.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Special cases of K-moment estimator coefficients (adapted from [6], p. 194).
Table 1.
Special cases of K-moment estimator coefficients (adapted from [6], p. 194).
| Case | Case | ||
|---|---|---|---|
| * symmetry: (minimum at ) |
* ) is the beta function.
Table 2.
Main characteristics of the distribution functions used in the illustrations.
| Name, Parameters *, Domain | ||||
|---|---|---|---|---|
| Exponential | ||||
| Normal | ||||
| Lognormal | ||||
| Pareto |
* Parameter notation: mean; standard deviation; scale parameter, upper tail index; shape parameter other than tail index.
Table 3.
Characteristic values for the distributions of Table 2.
Table 3.
Characteristic values for the distributions of Table 2.
| Distribution | ||||
|---|---|---|---|---|
| Exponential | * | 1 | ||
| Normal | 2 | |||
| Lognormal | 1 † | |||
| Pareto | 1 |
* is the Euler’s constant. † The theoretically consistent value is , but the convergence to the limit is very slow and thus the value 1 (like in the exponential and Pareto distribution) provides more accurate numerical results for typical sample sizes.
Table 4.
Estimated means, standard deviations and entropies: averages from the 100 Monte Carlo simulations performed in the study with sample size 100.
Table 4.
Estimated means, standard deviations and entropies: averages from the 100 Monte Carlo simulations performed in the study with sample size 100.
| Distribution, Parameters | Mean | Standard Deviation | Entropy | |||||
|---|---|---|---|---|---|---|---|---|
| True | Est. 1 * | Est. 2 * | True | Est. 1 | Est. 2 | True | Est. 2 | |
| Exponential, | 1 | 0.99 | 1.00 | 1 | 0.98 | 0.98 | 1 | 0.96 |
| Normal, | 0 | 0.01 | 0.01 | 1 | 0.99 | 0.99 | 1.42 | 1.37 |
| Lognormal, | 1.65 | 1.69 | 1.80 | 2.16 | 2.26 | 2.31 | 1.42 | 1.42 |
| Pareto, | 1.25 | 1.26 | 1.27 | 1.61 | 1.56 | 1.57 | 1.20 | 1.18 |
* Est. 1: Estimate from the typical sample statistics (without involving the probability density function); Est 2: Estimate from the empirical density function.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Koutsoyiannis, D. Replacing Histogram with Smooth Empirical Probability Density Function Estimated by K-Moments. Sci 2022, 4, 50. https://doi.org/10.3390/sci4040050
AMA Style
Koutsoyiannis D. Replacing Histogram with Smooth Empirical Probability Density Function Estimated by K-Moments. Sci. 2022; 4(4):50. https://doi.org/10.3390/sci4040050
Chicago/Turabian StyleKoutsoyiannis, Demetris. 2022. "Replacing Histogram with Smooth Empirical Probability Density Function Estimated by K-Moments" Sci 4, no. 4: 50. https://doi.org/10.3390/sci4040050