1. Introduction
In the United States, more than 40 percent of all bridges are built of steel (U.S. National Bridge Inventory (NBI)), and corrosion is a major factor in the deterioration of these structures. Each year, the federal government and state Departments of Transportation (DOTs) spend billions of dollars on bridge rehabilitation and maintenance due to corrosion [
1]. Corrosion reduces the effective cross-sections of critical structural components and subsequently decreases the axial, bending, and fatigue strength, which can lead to the failure of individual elements and entire structures. In order to detect and mitigate corrosion damage, regular inspection is essential. Steel structural elements must be evaluated in terms of the initiation of corrosion, section loss, or any other possible adverse effect on the strength or serviceability of structural elements. Since maintenance decisions mainly depend on the information collected during inspection, accurate bridge inspection and data analysis is important in optimizing bridge maintenance strategies and avoiding unnecessary repair costs.
The manual inspection of the bridge is always time-consuming and the result is inconsistent, subjective, and largely dependent on the experience and judgment of the inspector [
2,
3]. In addition, traditional bridge inspection is costly and associated with safety risks for the inspection crew and public. Unmanned aerial vehicles (UAVs) have proven to be a viable and safer solution to perform such inspections in many adverse conditions by flying up close to the structures and taking large numbers of high-resolution images from multiple angles [
4,
5]. Integrating UAVs with artificial intelligence (AI) in infrastructure inspections, particularly in tasks like defect detection, classification, and segmentation, offers significant benefits in terms of reduced time and costs and the enhanced accuracy of the results [
6,
7]. This study has focused on automated corrosion classification and condition rating to address the inefficiencies of traditional inspection.
Corrosion exhibits two main visual characteristics: a rough surface texture and a red color spectrum. These properties have been used for corrosion detection by applying feature-based classification techniques [
8]. Machine learning-based corrosion detection, such as support vector machines (SVM) and random forest, requires experts to manually define relevant features. The algorithm then learns to detect corrosion based on these features. For instance, in a study by Khayatazad et al. (2020), the authors quantified and combined roughness and color for corrosion detection. The uniformity metric calculated from the gray-level co-occurrence matrix and the histogram of corrosion-representative colors were used to analyze roughness and color, respectively [
9]. These techniques require manual feature engineering, which may not capture all variations in the data, and the quality of the manually selected features might affect performance of the algorithm. Image processing techniques such as histogram equalization and edge detection mitigate the need for the manual adjustment of threshold parameters, but they still require predefined rules to extract features directly from the images. The designed features may lack robustness when faced with diverse variations, leading to a significant decrease in recognition accuracy if the algorithm fails to effectively capture the advanced features present in the images [
10]. Deep learning-based (DL) approaches automatically learn hierarchical features from raw data and adapt the learned features, effectively reducing the need for human intervention. DL-based techniques can handle complex, unstructured data and often achieve state-of-the-art performance. Convolutional neural networks (CNNs) are a class of deep neural networks, most commonly applied to analyze images [
11]. CNNs have been used for object detection, classification, and segmentation and consistently exhibit remarkable performance compared to traditional classification algorithms. Petricca et al. (2016) presented a comparison between computer vision techniques and CNNs for automatic metal corrosion detection. The authors classified the image pixels based on the specific color components. The findings indicated that the deep learning approach achieved more uniform results and significantly higher accuracy compared to computer vision techniques [
12]. Some studies have evaluated the performance of CNNs with different architectures in corrosion detection. Atha and Jahanshahi (2018) evaluated VGG and ZF Net, two different architectures of CNN, for corrosion detection. The authors also proposed two CNN architectures specifically designed for corrosion detection, namely Corrosion7 and Corrosion5. It was shown that the deeper architecture, VGG16, performed better in terms of accuracy than a smaller network such as ZF Net. The authors achieved 96.68% mean precision using 926 images. However, only clearly visible surface images were considered in this study [
13]. Jin Lim et al. (2021) applied Faster RCNN with RGB and thermographic images for steel bridge corrosion inspection. They achieved an average precision (AP) value of 88% for surface and subsurface corrosion detection [
14].
While corrosion detection is concerned with identifying the presence and location of corrosion in an image using bounding boxes, segmentation is focused on the pixel-level classification and delineation of object boundaries. Long et al. (2015) introduced fully convolutional networks (FCNs) as the first deep learning-based technique to perform the segmentation task, and since then, many image segmentation techniques, such as U-Net [
15], DeepLab [
16], PSPNet [
17], SegNet [
18], and Mask RCNN [
19], have been developed. Each of these techniques has unique architectural features, which make them suitable for different image segmentation tasks. Recently, Ta et al. (2022) utilized the Mask RCNN algorithm, an instance segmentation approach, for the detection of corroded bolts. The model was able to accurately detect corrosion in the tested structure. The accuracy of the model declined along with the image capturing distance [
20]. Nash et al. (2018) proposed a modified VGG-16 architecture to perform the pixel-level segmentation of corrosion. Neither of the models trained on small and large datasets achieved human-level accuracy for corrosion detection [
21]. In their study, Rahman et al. (2021) proposed a semantic CNN model for corrosion detection and segmentation. The authors proposed a corrosion evaluation method based on the grayscale value for the classification of each pixel of a corrosion segment into heavy, medium, and light corrosion categories [
8].
For the problem of bridge inspection, inspectors are responsible for assigning corrosion condition states to the corroded structural elements according to the BIRM [
22] and American Association of State Highway and Transportation Officials (AASHTO) regulations [
23].
Table 1 demonstrates these condition states. The number of studies that use DL-based methods to evaluate and assign standardized condition states to the corroded areas in the image is very limited. In a recent study, Munawar et al. (2022) divided the images into four corrosion levels, no corrosion (negative class), low-level corrosion (images having less than 5% of corroded pixels), medium-level corrosion (images having less than 15% of corroded pixels), and high-level corrosion (images having more than 15% of corroded pixels) [
24], based on the number of corroded pixels. Notably, this classification method differs from the approach suggested by the Bridge Inspection Reference Manual (1), which recommends assessing the corrosion condition based on the severity of the corrosion.
To address the need for a practical corrosion condition rating approach, in the current study, we trained two DL-based corrosion segmentation algorithms to automatically rate the corroded areas and assign corrosion severity levels to them. The required corrosion images for the training of the algorithms were collected and annotated according to the AASHTO and BIRM regulations. The acquired corrosion images and corresponding annotations have been made openly accessible online and provide a resource for the training of future corrosion and condition rating models [
25].
3. Model Training and Validation
In this study, YOLOv8m-seg, which is a medium-sized segmentation model with over 27 million parameters, was used. The annotated files, which were in .json format originally, needed to be converted to .txt format for the training of the YOLOv8 model. For this conversion, the “json2yolo” github repository was utilized [
30]. The training and validation images were randomly selected in each dataset following a ratio of 80% for training and 20% for validation and testing. A total of 412 images were considered for training, 90 images for validation, and 12 images were randomly selected to test the model’s performance. The same training, validation, and testing images were used to train both the YOLOv8 and Mask RCNN models for comparison purposes.
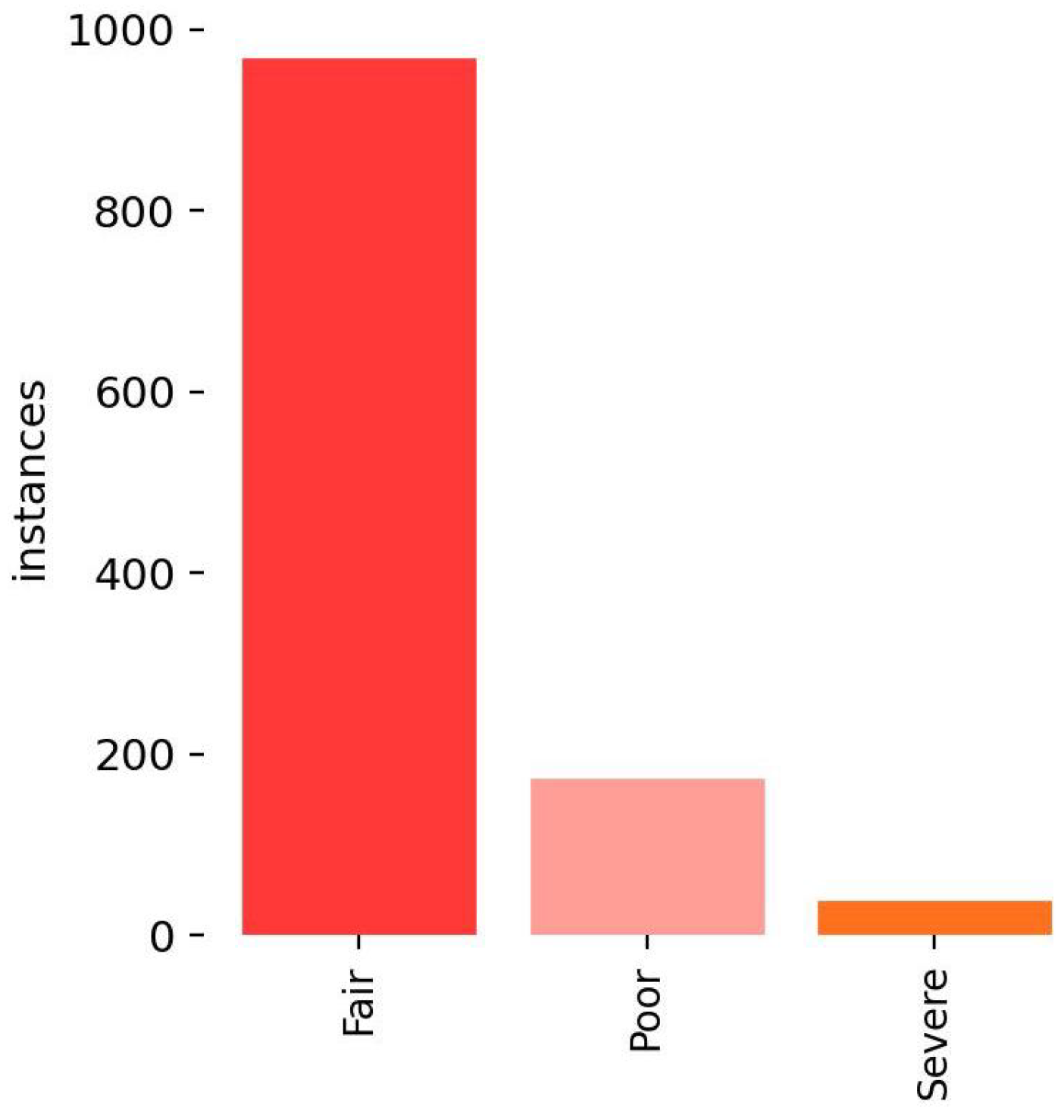
The distribution of instances for each class is depicted in
Figure 4. As can be seen in the figure, the number of “Fair” instances is significantly higher than that of “Poor” and “Severe” cases. This observation can be attributed to the relative ease of identifying “Fair” corrosion in the structural elements of the bridge. While most of the collected images contain mild corrosion, it is more challenging to find deeper and more severe corrosion in real bridges.
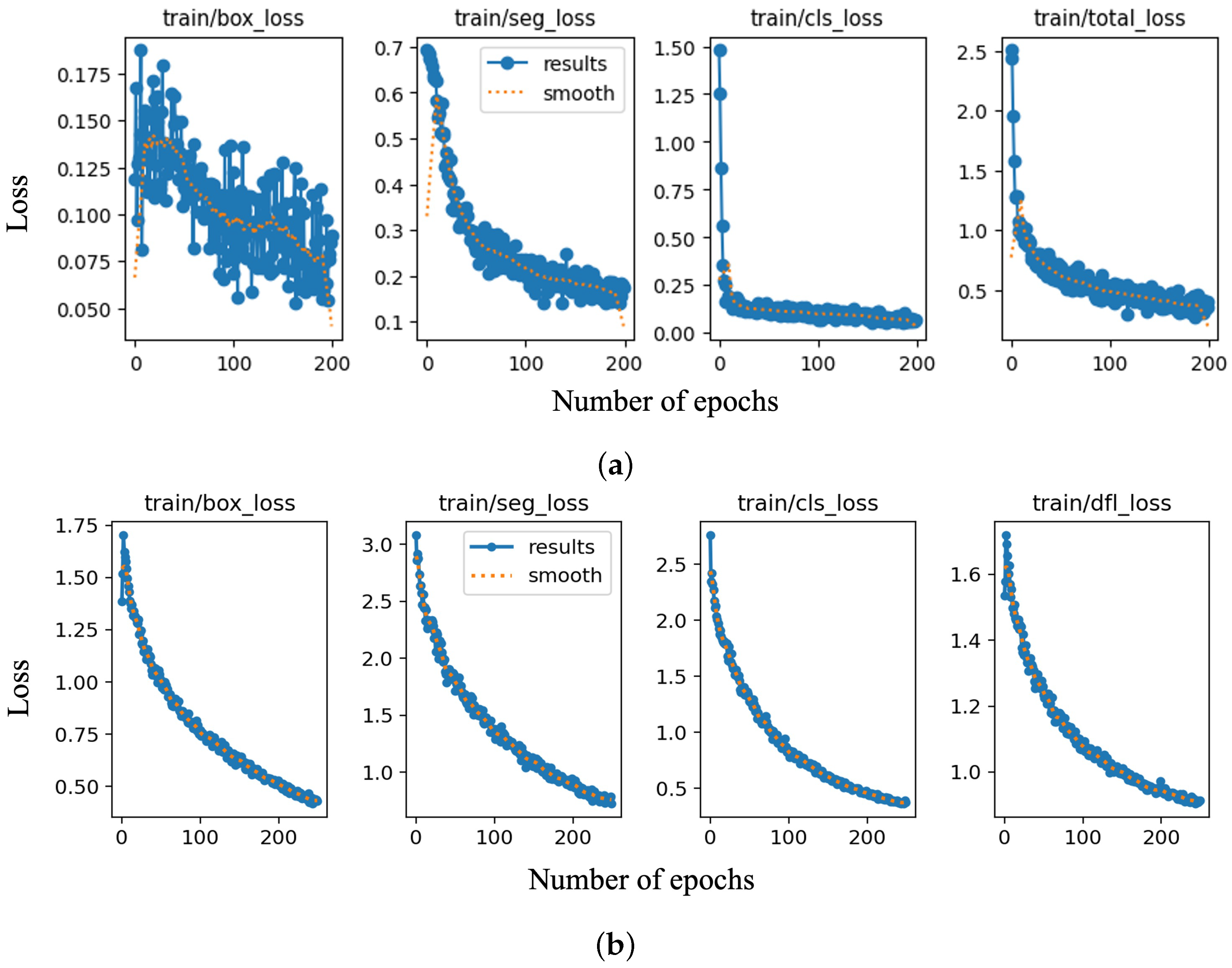
In order to perform the training task, Google Colab Pro was employed, taking advantage of a T4 GPU, the Python programming language, and the large RAM resources. Hyperparameters such as the learning rate, batch size, and number of epochs were optimized based on the performance of the models during training and validation. For the YOLOv8 model, a learning rate of 0.0001 was obtained, along with a batch size of 8 and 250 epochs. The image size was set to 640 by 640 pixels. These values were determined through trial and error to find the optimal balance between model accuracy and training efficiency. Similarly, for the Mask RCNN model, a learning rate of 0.00025 was chosen, along with a batch size of 8 and 200 epochs. The image size was also set to 640 by 640. These values also were selected based on experimentation and previous knowledge of the model’s performance. After training was completed, a file containing the custom-trained weights was saved in the training path. These weights were adjusted during the optimization process to minimize the difference between the predicted outputs and the actual outputs (labels) in the training data. The final weight values were utilized to perform predictions on the selected set of images (test images). This process involved using the trained model to classify and rate the condition of corrosion within the given images. The training loss values versus the number of epochs for the Mask RCNN and YOLOv8 models are shown in
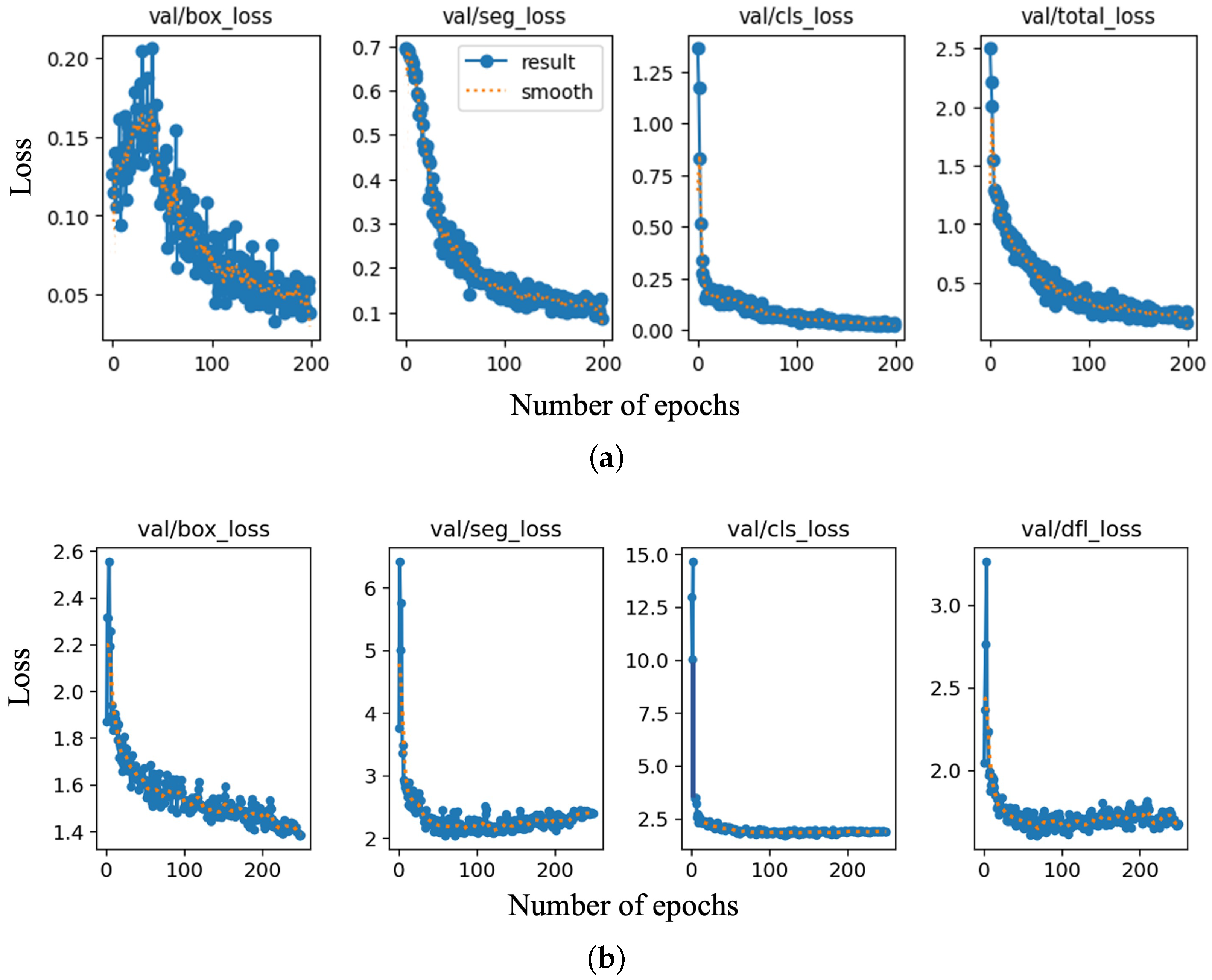
Figure 5a and b, respectively. The overall trend of the loss plot shows a consistent decrease, which indicates that the training model is learning and improving its performance over time. The validation loss values versus the number of epochs are also shown in
Figure 6.
As can be seen in
Figure 5, all types of loss converge to a low and stable value, indicating that both models have learned the patterns in the data. In the case of Mask RCNN, the segmentation loss has a higher value compared to the bounding and classification loss, which suggests that the model struggles with the segmentation tasks. The YOLOv8 trained model has higher segmentation and DFL loss, which shows the inherent difficulty in accurately predicting object masks. The higher DFL loss may indicate that the model is struggling with the class imbalance.
Validation loss measures the model’s performance on a validation dataset, and it provides an indication of how well the model generalizes to unseen data. It was used to tune the hyperparameters, such as the learning rate, number of epochs, batch size, etc. Overfitting (when the training loss continues to decrease, but the validation loss starts to increase) and underfitting (when both the training and validation loss are high) can be avoided by comparing the validation and training loss. The validation loss of the Mask RCNN trained model is as low as its training losses (
Figure 6). YOLOv8 shows higher validation loss values compared to the training losses. This could be an indication of overfitting or a lack of diversity in the training dataset.
4. Evaluation
Precision and recall values are two important metrics used to assess the performance of classification models. The precision value quantifies the accuracy of the corrosion detection algorithm, indicating the proportion of correctly identified corrosion instances. The recall value represents the fraction of all target corrosion instances that are successfully detected. The precision and recall values are obtained as follows:
True positive (TP) represents the number of cases that are positive and detected as positive (correctly detected corrosion). False positive (FP) represents the number of cases that are negative but detected as positive (falsely detected non-corrosion). False negative (FN) represents the number of cases that are positive but detected as negative (missed corrosion). Finally, true negative (TN) is the number of negative instances correctly predicted as negative (correctly detected non-corrosion).
The
F1 Score combines the precision and recall of a classifier into a single metric by taking their harmonic mean as follows:
Mean average precision (mAP) measures the accuracy of object localization and segmentation by considering the precision and recall values at different levels of intersection over union (IoU) thresholds. It evaluates how well the predicted bounding boxes or segmentation masks align with the ground truth annotations:
where
N is the number of classes or categories and
is the average precision (AP) for class
i. In terms of evaluation metrics for bounding box regression, intersection over union (IoU) is the most popular metric. The IoU for the bounding box and mask can be obtained as follows:
In Equation (
9), (
B) and (
M) distinguish the metrics of segmentation.
and
represent the prediction and ground truth, while (
B) and (
M) evaluate the detection (Box) and segmentation (Mask), respectively. mAP50 represents the average precision when the IoU threshold is set to 0.5. This threshold considers a detection as a true positive if the IoU between the predicted and the ground truth mask is greater than or equal to 0.5. This metric provides a more comprehensive evaluation of the models’ performance on the validation and testing datasets. These values for both the YOLOv8 and Mask RCNN trained models were calculated and are listed in
Table 2.
The F1 score values in
Table 2 show that YOLOv8 achieved an F1 score of 0.730, while Mask RCNN achieved a slightly higher F1 score of 0.745. This indicates that both models exhibit reasonable overall performance, with Mask RCNN having a slight advantage in terms of F1 score and striking a better balance between precision and recall. YOLOv8 achieved higher precision (0.853) compared to Mask RCNN (0.625). This indicates that YOLOv8 tends to make fewer false positive predictions. The Mask RCNN trained model had a higher recall rate (0.922) compared to YOLOv8 (0.647), which indicates its better ability to detect and include relevant objects in its predictions. The mAP50 values of the Mask RCNN trained model were 0.483 on the validation dataset and 0.674 on the test dataset. The YOLOv8 model achieved mAP50 values of 0.484 on the validation dataset and 0.726 on the test dataset. The Mask RCNN model had slightly lower mAP50 values compared to YOLOv8, indicating that YOLOv8 performs better in terms of mean average precision at the 50% IoU threshold. The YOLOv8 model outperformed the Mask RCNN model in terms of speed, with an inference time of 0.03 s per image, compared to 0.12 s per image for Mask RCNN. Based on the available metrics in the chart, the Mask RCNN model generally outperforms the YOLOv8 model in terms of F1 score and recall but YOLOv8 achieves higher precision and mAP50. This implies that YOLOv8 tends to provide more accurate predictions concerning the relevant objects that it detects, albeit with potentially fewer true positives. It is important to note that the comparison is limited to the provided metrics, and further analysis, including additional metrics and experimental conditions, is needed to discuss the performance of these models accurately.
5. Test Results and Discussion
To evaluate the performance of the trained Mask RCNN and YOLOv8 models for corrosion segmentation and condition rating, prediction was performed on the test images that were not used for training and validation. Only objects identified with confidence of 0.5 and 0.35 or higher for Mask RCNN and YOLOv8, respectively, were considered in the test. The representative results are shown in
Figure 7,
Figure 8 and
Figure 9. Each figure contains four images in a row. The first row shows the original test images, the second row represents the corresponding annotations, the third row shows the prediction of the YOLOv8 trained model, and the last row depicts the prediction of Mask RCNN. A brief discussion of the results for each sample image is provided below.
Figure 7a shows mild corrosion in the bottom flange of a beam. The corroded portion of the flange is annotated as “Fair” and its mask is shown in the second row of
Figure 7a with a green color. As can be seen in the third and fourth rows of
Figure 7a, both the Mask RCNN and YOLOv8 models classified and segmented the corroded portions of the beam correctly. YOLOv8’s mask area and shape is closer to the annotation and has higher confidence compared to Mask RCNN. A small corroded area in the middle of the upper side of the image is correctly detected as “Fair” and segmented by both models, but it is not considered in the annotation due to its small area.
Similar to
Figure 7a,
Figure 7b contains some “Fair” corrosion. There is a perfect match between the annotation and output of the YOLOv8 model. YOLOv8 also labeled a small area as “Fair”, which is not labeled in the annotation. Mask RCNN labeled two additional instances in the image as “Fair” that are not included in the annotation.
The third picture from the left (
Figure 7c) shows a corroded support with relatively severe corrosion, which was annotated as “Poor”. Both of the trained models correctly labeled the corroded area as “Poor”, while Mask RCNN labeled it with lower confidence compared to YOLOv8 (83% vs. 93%). There is some mismatch between the mask depicted by the Mask RCNN trained model and the annotation. It incorrectly detected a small portion of the concrete below the support as poor corrosion.
In
Figure 7d, Mask RCNN correctly labels the entire corroded area with higher confidence compared to YOLOv8. Two corrosion instances are missing in the prediction of the YOLOv8 model, while the Mask RCNN trained model correctly classified and labeled all of them with a high confidence score (93% and 97%).
Figure 8a shows a girder flange. The lower part of the beam flange, which was annotated as “Poor”, is correctly labeled and segmented by the YOLOv8 trained model. Some parts of the deck concrete are labeled as “Poor” by YOLOv8, which is not correct. In the lower right corner of the image, a corroded portion of an adjacent girder can be seen, which is not included in the annotation, but both models labeled it as “Fair”. Mask RCNN labeled some parts of the flange as “Poor” and the rest as “Fair”, which is not correct.
As illustrated in
Figure 8b, the corroded portion of the lower flange is correctly detected and labeled by both of the models. YOLOv8 has slightly higher confidence compared to Mask RCNN. A small part in the middle of the flange, which seems less corroded compared to the rest of the flange, is excluded from the mask provided by YOLOv8.
YOLOv8 segmented and labeled the web and the upper part of the support, the flange, and the brace as “Poor”, while, in the annotation, only the girder web is considered “Poor” (
Figure 8c). The middle part of the web that is less corroded is annotated as “Fair”, while Mask RCNN labeled the entire web and flange as “Poor”. The support and some parts of the brace are excluded from the mask depicted by the Mask RCNN trained model.
As shown in
Figure 8d, the corroded support, beam flange, web, and braces are precisely detected by the YOLOv8 trained model. The dark background between the brace and the web stiffener is not included in the YOLOv8-predicted mask, while Mask RCNN detected it as “Poor” corrosion. Moreover, some small parts of the background concrete are included in the mask depicted by the Mask RCNN trained model. A small corroded area in the girder web is labeled as “Fair” by both models, which appears as less severe corrosion compared to the other parts.
Figure 9a shows the bottom flange of a girder, which is delaminated due to corrosion. This corroded area is annotated as “Poor”, but YOLOv8 and Mask RCNN labeled it as “Fair” with confidence of 89% and 62%, respectively. Both models provided a very precise mask of the corroded area since it is easily distinguishable from the background in this image.
As shown in
Figure 9b, YOLOv8 was able to detect all instances that were annotated as “Fair”, with a small mismatch in the detected mask. Both the YOLOv8 and Mask RCNN models correctly labeled the corroded parts of the girder flange. The corrosion mask provided by Mask RCNN is closer to the annotation, and it has higher confidence compared to YOLOv8.
Figure 9c illustrates a severely corroded beam with section loss, which was annotated as “Severe”. The YOLOv8 trained model provided a precise mask of the severely corroded beam and labeled it correctly with high confidence (93%). A small part of the background concrete is also included in the mask. Mask RCNN mislabeled the severely corroded brace as “Poor” with confidence of 84%. A small portion of the beam is missing from the mask provided by Mask RCNN.
Figure 9d shows a severely corroded beam with section loss. The dark background of the image was not included in the annotation. The YOLOv8 trained model labeled the severely corroded area of the beam correctly with high confidence (90%). The model labeled a small portion of the dark background as “Severe”, even though this area was not included in the annotation due to its invisible degree of corrosion. Similar to the previous image, the trained Mask RCNN model mislabeled the severely corroded area of the beam as “Poor” with confidence of 73%.
Analyzing the evaluation metric values on the validation and test data, as well as the predictions of the two trained algorithms on the test data, suggests that the YOLOv8 trained model excels in the precision and mAP50 values, providing accurate predictions in some cases. On the other hand, Mask RCNN demonstrates higher recall, capturing more relevant objects. If precision and the minimization of false positives are prioritized, YOLOv8 may be preferred. If the primary focus is comprehensive detection and recall, Mask RCNN might be the better choice.
6. Conclusions
In this study, 514 corrosion images with various degrees of severity were gathered from bridge structural elements, and pixel-wise annotation was performed on each image. The corroded areas were annotated into three classes: “Fair”, “Poor”, and “Severe”. Our annotation process adhered to the guidelines outlined in the Bridge Inspectors Reference Manual (BIRM) and American Association of State Highway and Transportation Officials (AASHTO) regulations for corrosion condition rating (defect #1000). This annotation at the pixel level ensures that the trained algorithms can be directly applied to the corrosion condition rating process, offering practical application for engineers. The collected corrosion images and corresponding annotations can be found online and offer valuable support in advancing the segmentation models by providing high-quality images and corresponding annotations [
25]. Two state-of-the-art segmentation algorithms, YOLOv8 and Mask RCNN, were chosen and trained on the labeled dataset to perform pixel-level corrosion segmentation and condition rating. The training process involved optimizing the hyperparameters to obtain the best weights of convolutional layers for accurate and reliable corrosion severity assessments. The trained Mask RCNN and YOLOv8 models achieved mAP50 values of 0.674 and 0.726 on the test images, which is an indication of the models’ ability to perform semantic segmentation with a reasonable level of overlap with the ground truth annotations (IoU = 50%). These results indicate the efficacy of trained Mask RCNN and YOLOv8 models in segmenting and rating corrosion. The main highlights of this study can be summarized as follows.
The applicability of these algorithms is broad and extends to various conditions. However, it is important to note that the performance of these methods may be influenced by the quality of images and factors such as the lighting conditions and the complexity of the corrosion patterns. It is advisable to ensure the quality of the images during data acquisition to optimize the performance of these segmentation algorithms.
In terms of performance, we found that both the Mask RCNN and YOLOv8 models achieved satisfactory results in segmenting and rating corrosion. The YOLOv8 model had slightly higher mAP50 values on the validation (0.484) and test (0.726) datasets compared to Mask RCNN (0.483 and 0.674), indicating more accurate predictions while maintaining a good balance between avoiding false positives and capturing as many true positives as possible.
Mask RCNN model achieved higher F1 score and recall values, which indicate that the model is adept at identifying most of the relevant instances in the dataset. Mask RCNN excels in providing precise instance segmentation with detailed masks, making it suitable for objects with crucial boundaries.
Mask RCNN has a two-stage architecture, which can be computationally intensive, impacting the real-time performance. Its training may require more computational resources compared to some single-stage approaches. YOLOv8 is designed for real-time object detection, making it efficient in scenarios where low latency is critical.
In YOLOv8, the default task is object detection, which involves detecting and localizing objects in an image or video. Semantic segmentation, on the other hand, aims to label every pixel in an image with the corresponding class value. While YOLOv8 can be used for object detection, it is not designed specifically for semantic segmentation. It may face challenges in achieving pixel-level instance segmentation accuracy comparable to algorithms specifically designed for semantic segmentation, such as Mask RCNN. Its performance may be influenced by the sensitivity of certain hyperparameters, requiring careful tuning for optimal results.
In the future, to improve the accuracy of the corrosion condition rating model, we aim to obtain more diverse images with varying corrosion severity levels, lighting, and background conditions. Including a greater number of images depicting severe and poor corrosion instances will help to address the class imbalance problem and enhance the segmentation models’ performance considerably.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}