
Binary and Multiclass Text Classification by Means of Separable Convolutional Neural Network


Abstract
:1. Introduction
- Putting content in categories to enhance browsing or distinguish related content during internet search or web browsing. Many platforms such as Google and Facebook use automated technologies to classify and trace content and products, which reduces manual work thus highly time-efficient [1]. It helps them drag websites quickly, which eventually assists all other processes like search or answering questions. Furthermore, automating the content tags on internet sites and mobile applications can make the user practice better and helps to standardize them. In other fields which consider emergency response systems, text classification makes these responses more accurate and faster.
- Text classification also plays a significant role in other fields, for instance, economy [2]; wherein marketing text classification is becoming more targeted and automatic. Marketers can observe and match users based on how they speak about a product or trademark online, where classifiers would be trained to recognize promoters or detractors. Doctors, academic researchers, lawyers even governments can all benefit from text classification technology.
- With the expansion of information fed by the mass of text data, it is no longer possible for a human observer to understand or even categorize all of the data coming in. Automatic classification of data, especially textual data, is becoming increasingly important as the amount of information available grows in tandem with the amount of computing power available. It also allows many other different processes to be developed like text prediction, question answering, sentence completion, information extraction, machine translation, text generation, and language understanding [3].
- The Naïve Bayes method comprises the Naïve Bayes techniques as a group of supervised learning algorithms, which are sets of uncomplicated and sufficient machine learning approaches for binary classifications [7,8]. It produces classifications based on Bayes’ theorem and the “naïve” presumption of conditional freedom between any two features as long as the class variable has a definition. This method can also be illustrated using a straightforward Bayesian network [9]. The goal of the naive base classifier is to select the probability of the features appearing in each class and select the higher probability from the classes. It takes the probability of a word feature as the number of a word appears in a document over the word’s appearance in all of the documents.
- The linear support vector machine algorithm is a supervised and linear machine learning algorithm that is often used to divide data into two groups [10]. This classification algorithm is capable of representing a vector in multidimensional space. It focuses on the observations on each class’s edges and uses the midpoint between them as the threshold. The margin is described as the least distance between the class’s edge and the threshold. If the threshold is placed in the middle of the distance between the class’s edges, the margin will be as significant as it can be. It aims to find the maximum-margin hyperplane that separates the group of word features into two classes [11].
- Stochastic gradient descent (SGD) is a straightforward and efficient method for classifications. It can use logistic regression, linear support vector machine, and different cost functions. Despite that, SGD, an old machine learning technique, has acquired a significant amount of attention just lately in the context of large-scale learning. SGD is successfully applied to sparse machine learning situations and is often engaged in text classification and natural language processing [12].
2. Materials and Methods
2.1. Embedding and Pooling Layers in Convolutional Neural Network
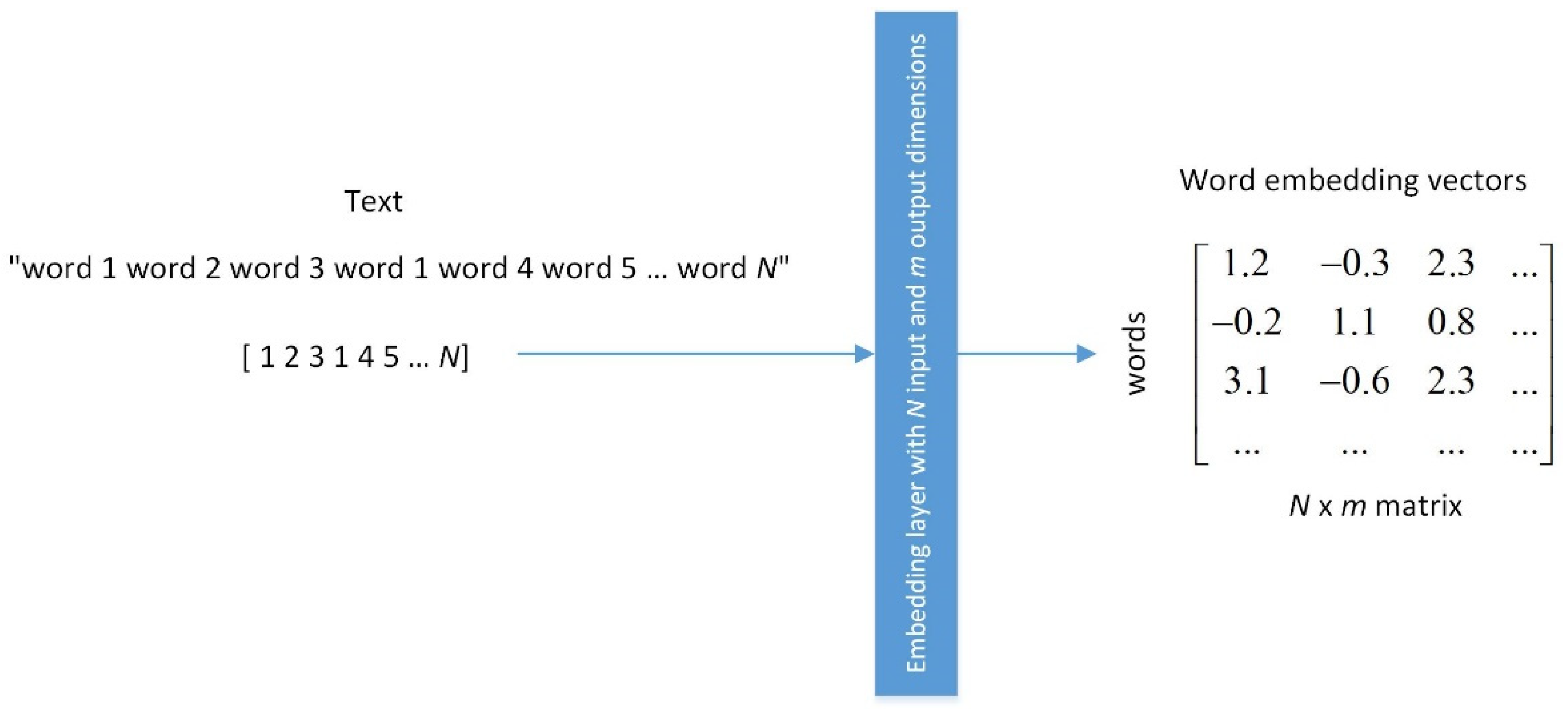
2.1.1. Word Embedding Layer
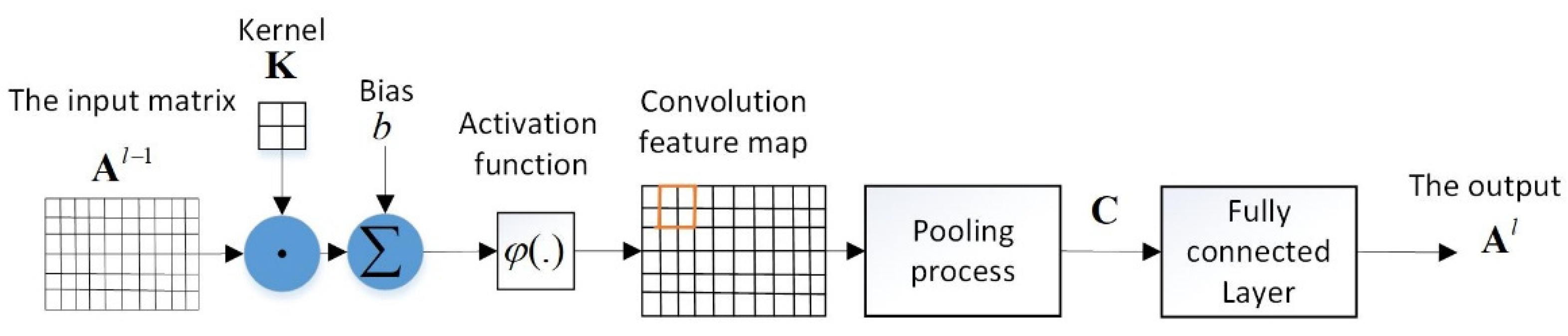
2.1.2. Convolutional, Pooling and Fully Connected Layers
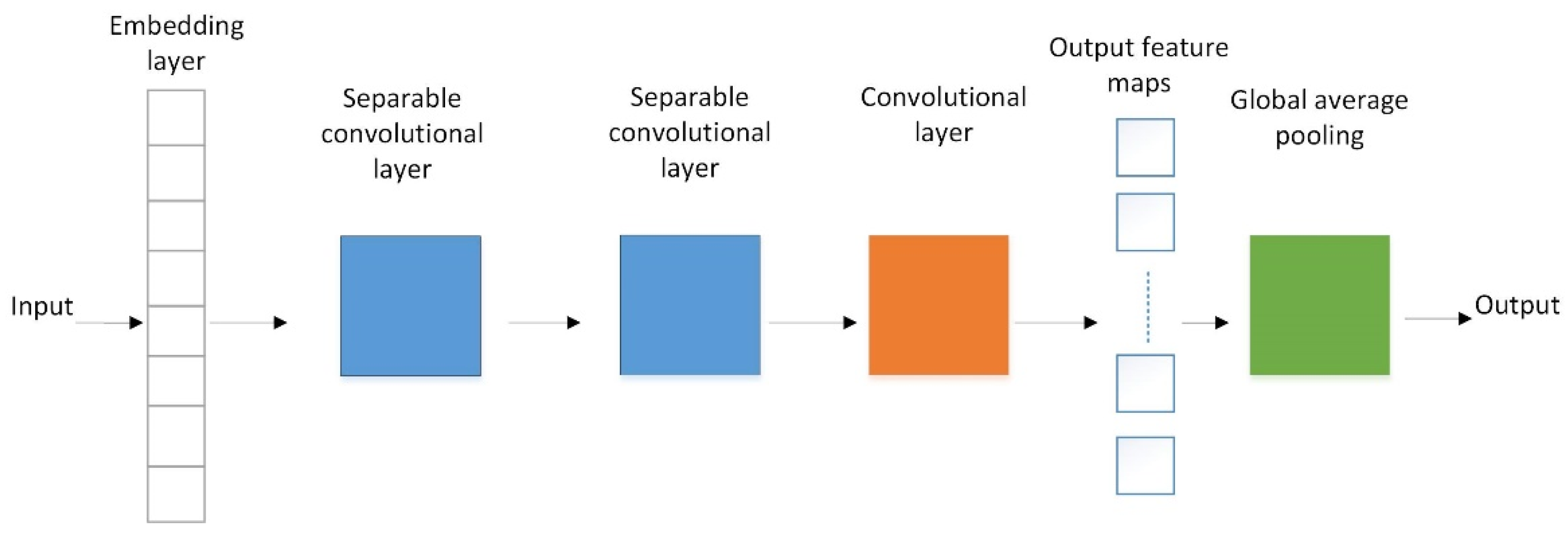
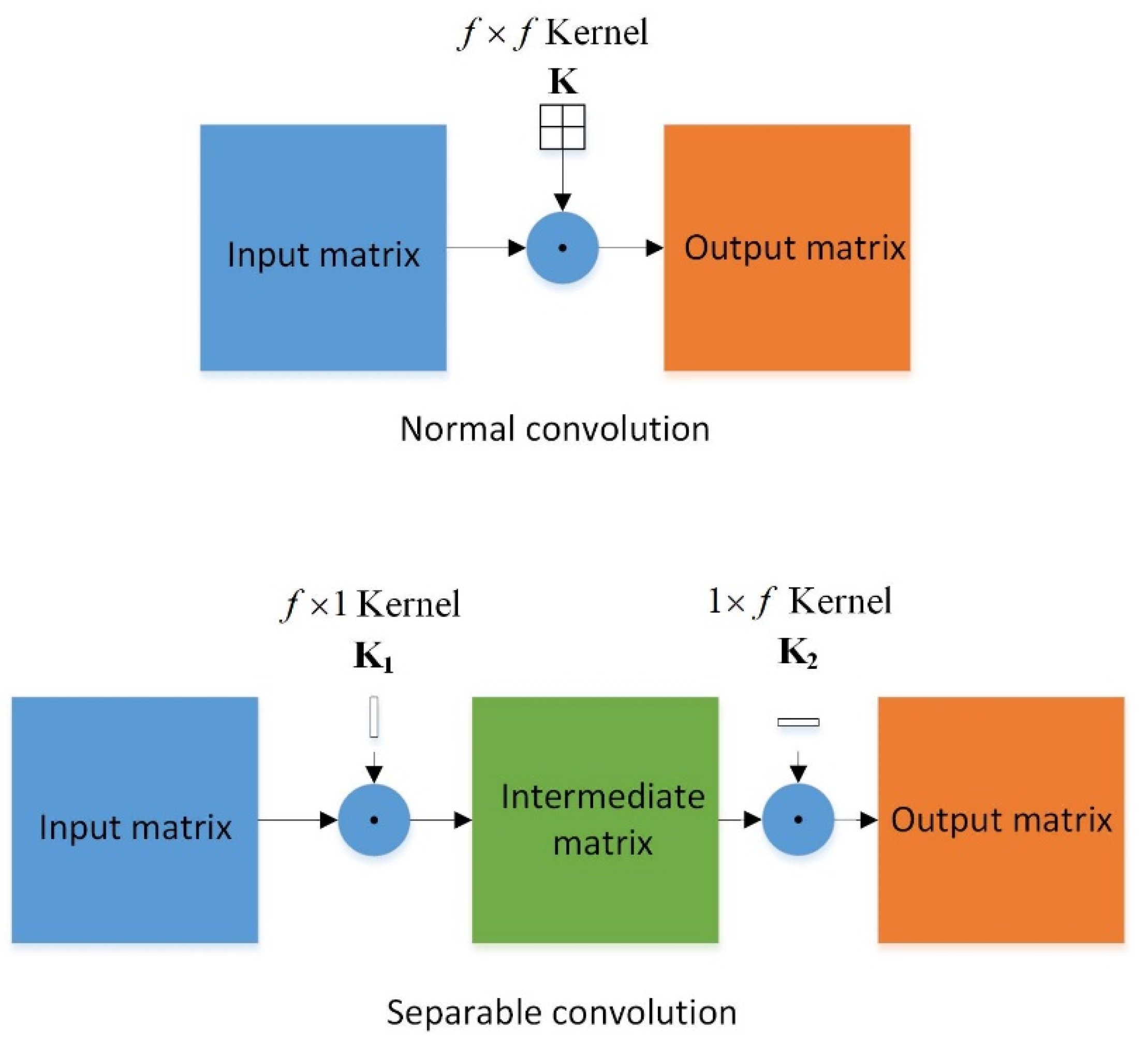
2.2. Separable Convolutional Neural Network with Embedding Layer and Global Average Pooling
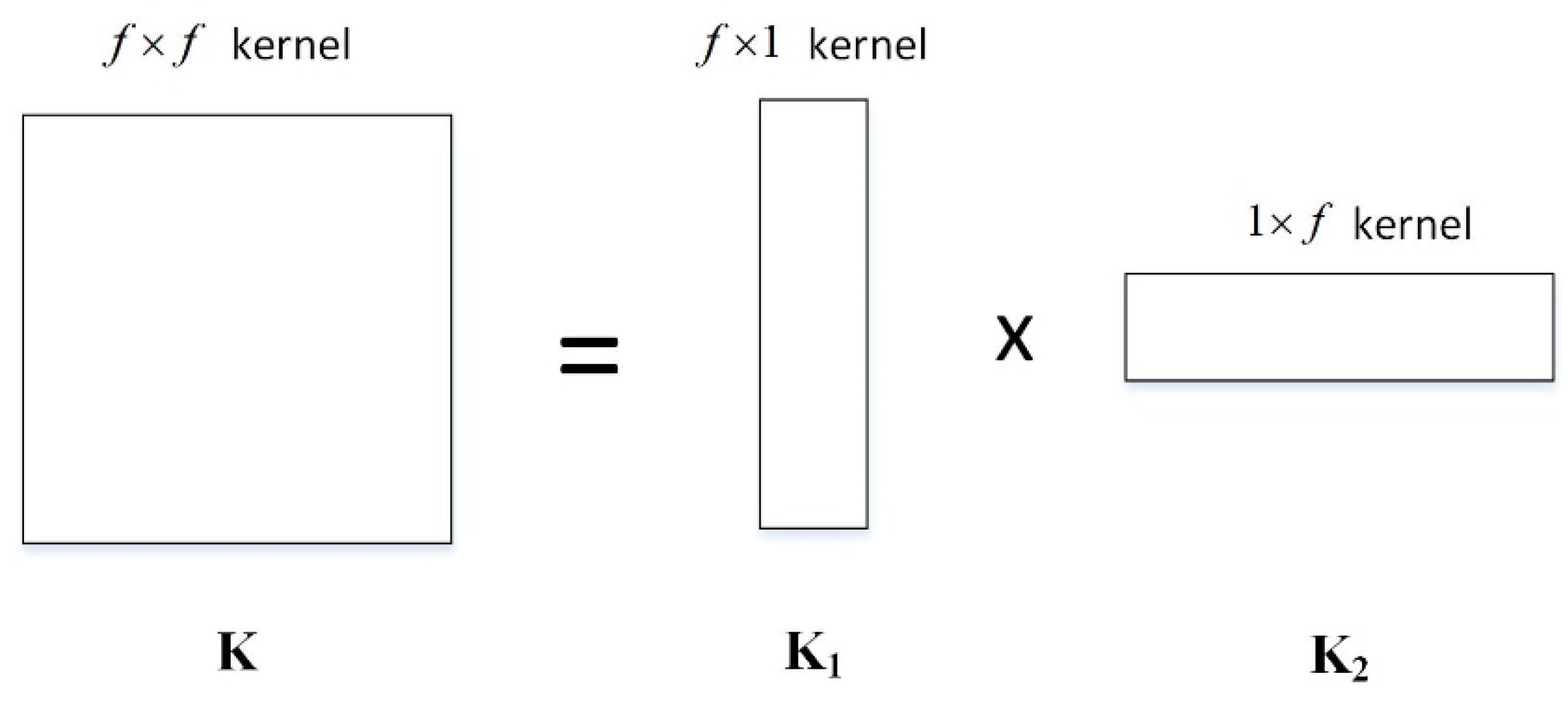
2.2.1. Separable Convolutional Layer
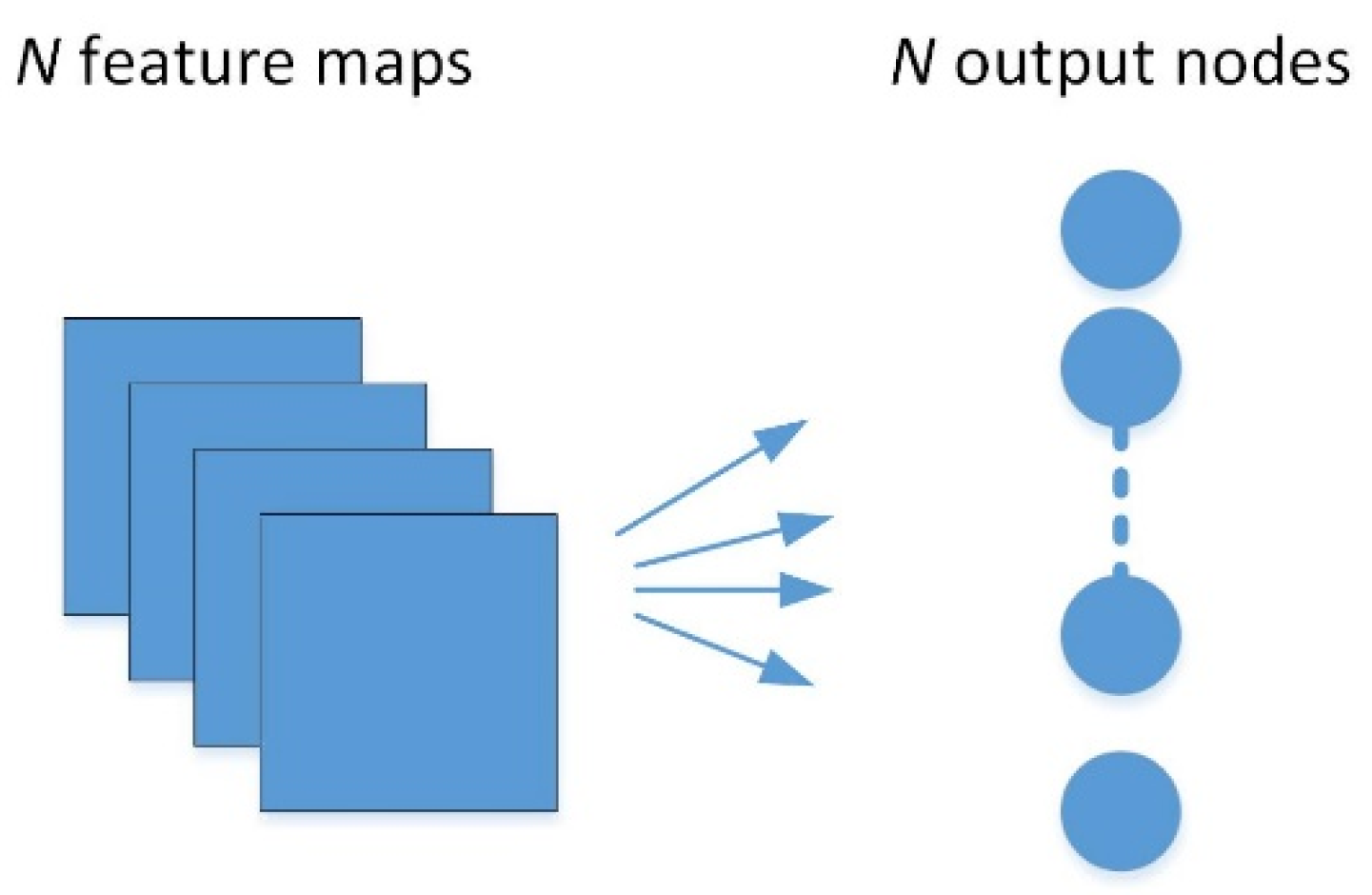
2.2.2. Global Average Pooling
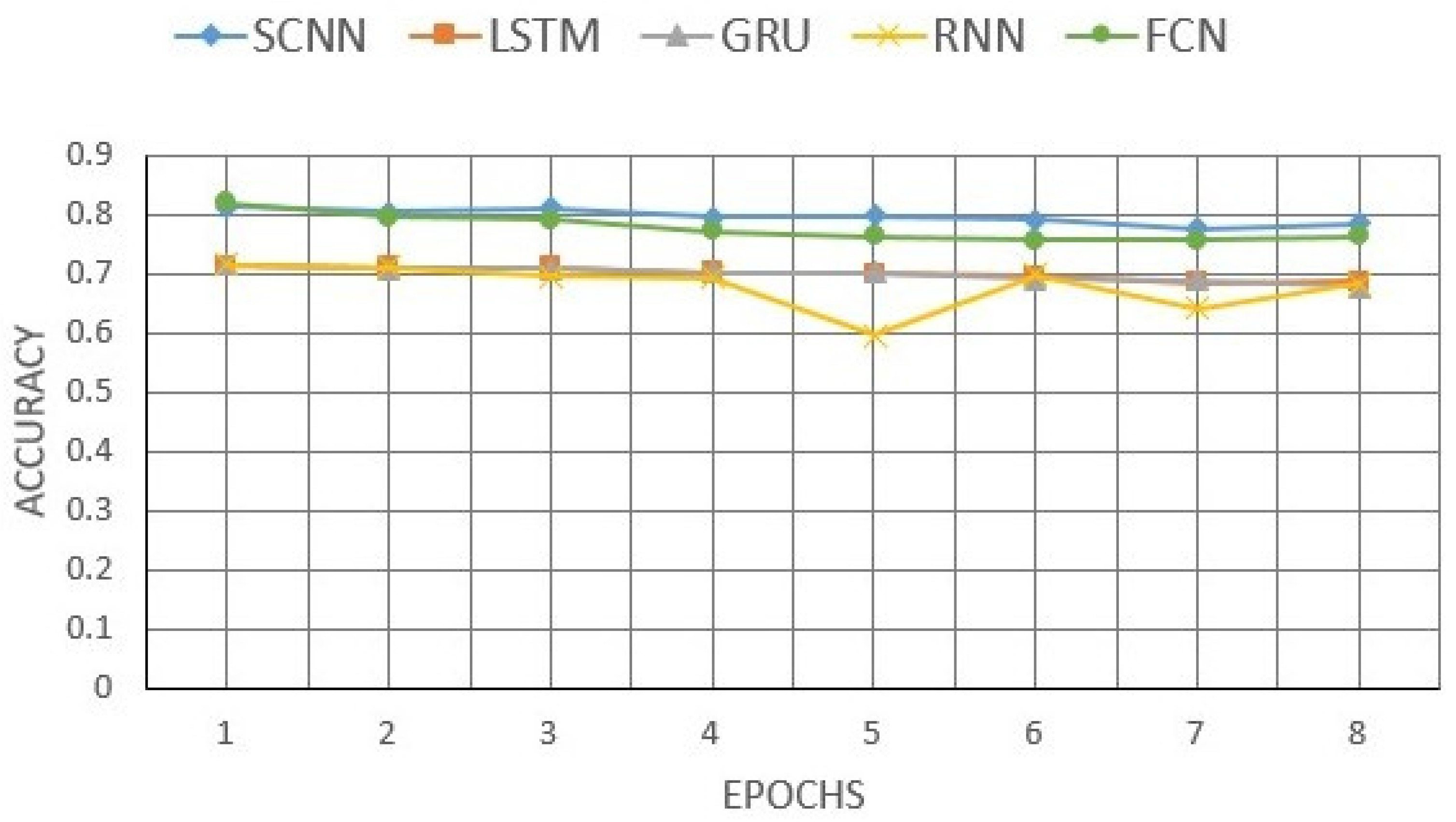
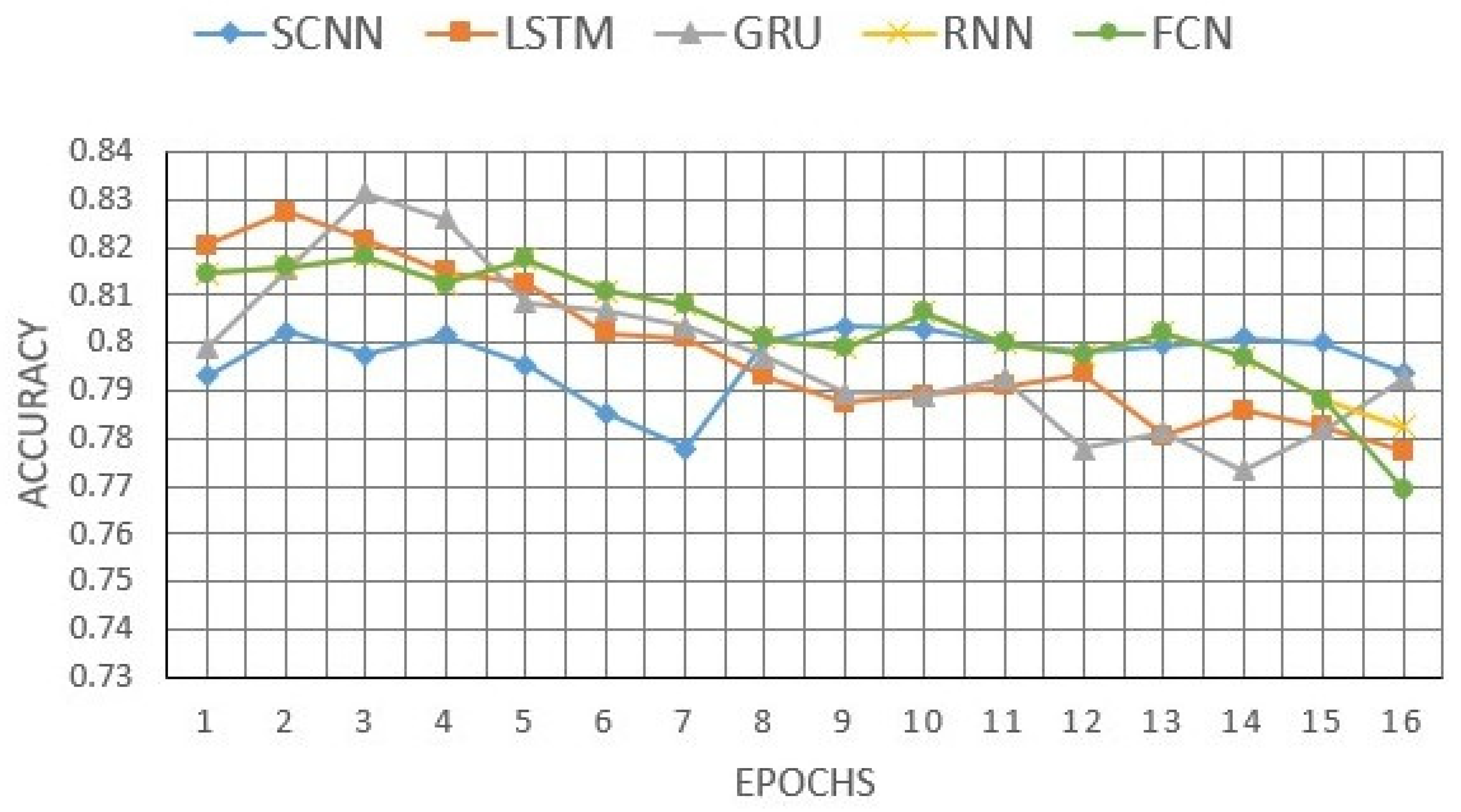
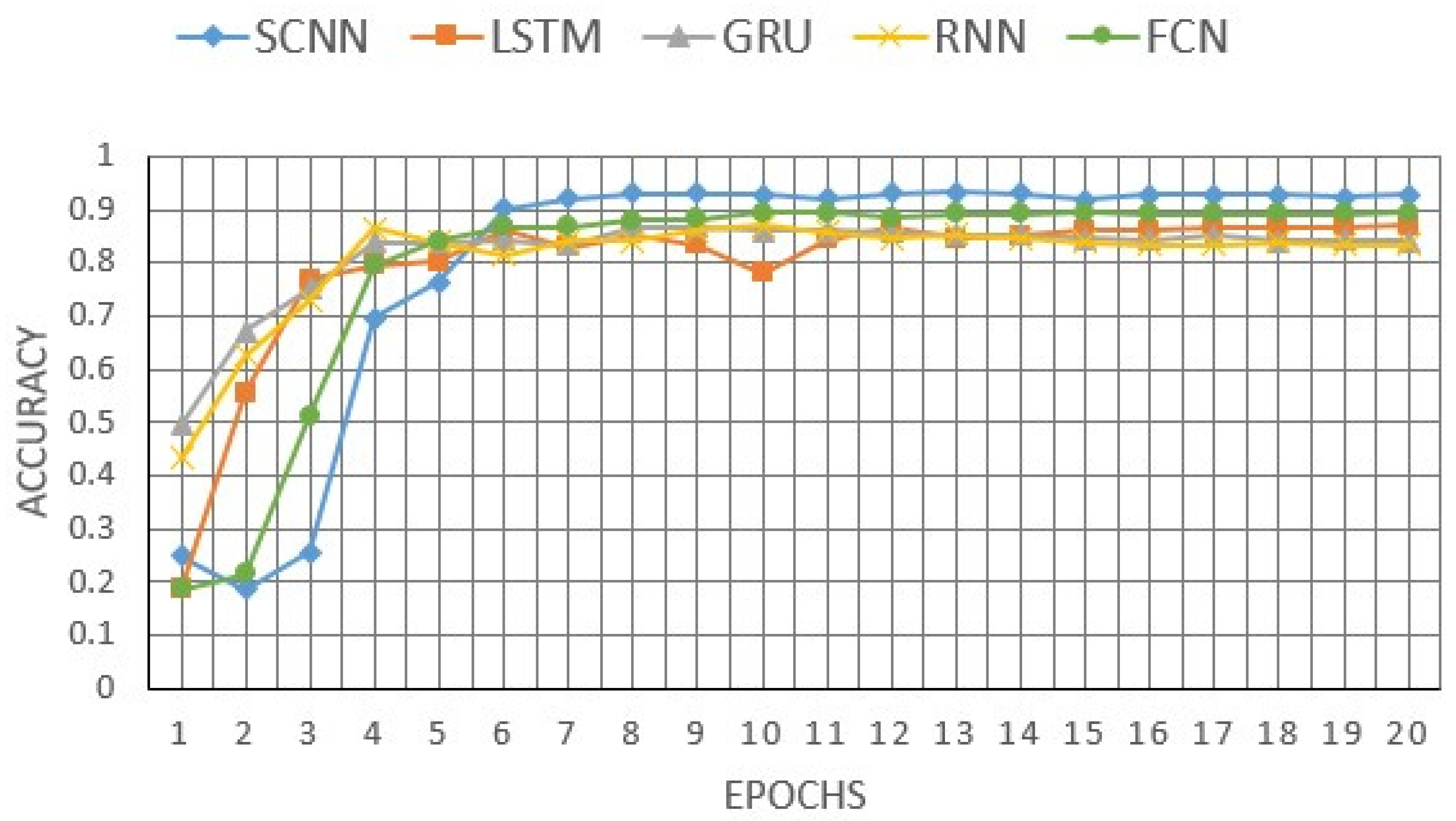
3. Results of Binary and Multiclass Text Classifications
4. Conclusions
- Higher accuracy reached 79.4% in the case of the Softmax activation function in the last layer of the network (this accuracy exceeds 78.6% in the case of the sigmoid activation function), and 92.81% for the multiclass classification.
- Lower computation complexity. Using the separable convolutional layer reduced the learning parameters of the network with keeping its ability of feature extraction enabling the data to be expressed as spatial with the locally and equally possible to occur extracted features at any input.
- Fast calculation time. The lower computation complexity reduced the training and testing time of the SCNN without affecting its quality and accuracy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ghavami, P. Big Data Analytic Methods, 2nd ed.; Walter de Gruyter Inc.: Berlin, Germany, 2020; pp. 65–88. [Google Scholar] [CrossRef]
- Hong, T.; Choi, J.A.; Lim, K.; Kim, P. Enhancing Personalized Ads Using Interest Category Classification of SNS Users Based on Deep Neural Networks. Sensors 2020, 21, 199. [Google Scholar] [CrossRef]
- Collins, E.; Rozanov, N.; Zhang, B. Evolutionary Data Measures: Understanding the Difficulty of Text Classification Tasks. In Proceedings of the 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 31 October–1 November 2018; pp. 380–391. [Google Scholar] [CrossRef]
- Han, S. Predictive Analytics: Semi-Supervised Learning Classification Based on Generalized Additive Logistic Regression for Corporate Credit Anomaly Detection. IEEE Access 2020, 8, 199060–199069. [Google Scholar] [CrossRef]
- Lee, W.M. Python® Machine Learning, 1st ed.; John Wiley & Sons Inc.: Indianapolis, IN, USA, 2019; pp. 151–175. [Google Scholar] [CrossRef]
- Tamhane, A.C. Predictive Analytics: Parametric Models for Regression and Classification Using R, 1st ed.; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2021; pp. 181–224. [Google Scholar] [CrossRef]
- Tan, Y.; Shenoy, P.P. A bias-variance based heuristic for constructing a hybrid logistic regression-naïve Bayes model for classification. Int. J. Approx. Reason. 2020, 117, 15–28. [Google Scholar] [CrossRef]
- Kim, H.; Kim, J.; Kim, J.; Lim, P. Towards perfect text classification with Wikipedia-based semantic Naïve Bayes learning. Neurocomputing 2018, 315, 128–134. [Google Scholar] [CrossRef]
- Islamiyah; Dengen, N.; Maria, E. Naïve Bayes Classifiers for Tweet Sentiment Analysis Using GPU. Int. J. Eng. Adv. Technol. 2019, 8, 1470–1472. [Google Scholar] [CrossRef]
- Xi, X.; Zhang, F.; Li, X. Dual Random Projection for Linear Support Vector Machine. DEStech Trans. Comput. Sci. Eng. 2017, 173–180. [Google Scholar] [CrossRef] [Green Version]
- Singh, C.; Walia, E.; Kaur, K.P. Enhancing color image retrieval performance with feature fusion and non-linear support vector machine classifier. Optik 2018, 158, 127–141. [Google Scholar] [CrossRef]
- Sirignano, J.; Spiliopoulos, K. Stochastic Gradient Descent in Continuous Time: A Central Limit Theorem. Stoch. Syst. 2020, 10, 124–151. [Google Scholar] [CrossRef]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meimandi, K.J.; Gerber, M.S.; Barnes, L.E. Hdltex: Hierarchical deep learning for text classification. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 364–371. [Google Scholar] [CrossRef] [Green Version]
- Prusa, J.D.; Khoshgoftaar, T.M. Designing a Better Data Representation for Deep Neural Networks and Text Classification. In Proceedings of the 2016 IEEE 17th International Conference on Information Reuse and Integration (IRI), Pittsburgh, PA, USA, 28–30 July 2016; pp. 411–416. [Google Scholar] [CrossRef]
- Amato, F.; Mazzocca, N.; Moscato, F.; Vivenzio, E. Multilayer Perceptron: An Intelligent Model for Classification and Intrusion Detection. In Proceedings of the 31st International Conference on Advanced Information Networking and Applications Workshops (WAINA), Taipei, Taiwan, 27–29 March 2017; pp. 686–691. [Google Scholar] [CrossRef]
- Prastowo, E.Y.; Endroyono; Yuniarno, E. Combining SentiStrength and Multilayer Perceptron in Twitter Sentiment Classification. In Proceedings of the 2019 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 28–29 August 2019; pp. 381–386. [Google Scholar] [CrossRef]
- Solovyeva, E.B.; Degtyarev, S.A. Synthesis of Neural Pulse Interference Filters for Image Restoration. Radioelectron. Commun. Syst. 2008, 51, 661–668. [Google Scholar] [CrossRef]
- Solovyeva, E.B.; Inshakov, Y.M.; Ezerov, K.S. Using the NI ELVIS II Complex for Improvement of Laboratory Course in Electrical Engineering. In Proceedings of the 2018 IEEE International Conference “Quality Management, Transport and Information Security, Information Technologies” (IT&MQ&IS), St. Petersburg, Russia, 24−28 September 2018; pp. 725–730. [Google Scholar] [CrossRef]
- Solovyeva, E. A Split Signal Polynomial as a Model of an Impulse Noise Filter for Speech Signal Recovery. J. Phys. Conf. Ser. (JPCS) 2017, 803, 012156. [Google Scholar] [CrossRef]
- Zhao, Y.; Shen, Y.; Yao, J. Recurrent Neural Network for Text Classification with Hierarchical Multiscale Dense Connections. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 5450–5456. [Google Scholar] [CrossRef] [Green Version]
- Buber, E.; Diri, B. Web Page Classification Using RNN. Procedia Comput. Sci. 2019, 154, 62–72. [Google Scholar] [CrossRef]
- Son, G.; Kwon, S.; Park, N. Gender Classification Based on The Non-Lexical Cues of Emergency Calls with Recurrent Neural Networks (RNN). Symmetry 2019, 11, 525. [Google Scholar] [CrossRef] [Green Version]
- Solovyeva, E. Types of Recurrent Neural Networks for Non-linear Dynamic System Modelling. In Proceedings of the 2017 IEEE International Conference on Soft Computing and Measurements (SCM2017), St. Petersburg, Russia, 24−26 May 2017; pp. 252–255. [Google Scholar] [CrossRef]
- Song, P.; Geng, C.; Li, Z. Research on Text Classification Based on Convolutional Neural Network. In Proceedings of the International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 27–29 September 2019; pp. 229–232. [Google Scholar] [CrossRef]
- Abdulnabi, N.Z.T.; Altun, O. Batch size for training convolutional neural networks for sentence classification. J. Adv. Technol. Eng. Res. 2016, 2, 156–163. [Google Scholar] [CrossRef]
- Truşcǎ, M.; Spanakis, G. Hybrid Tiled Convolutional Neural Networks (HTCNN) Text Sentiment Classification. In Proceedings of the 12th International Conference on Agents and Artificial Intelligence, Valletta, Malta, 22–24 February 2020; pp. 506–513. [Google Scholar] [CrossRef]
- Tiryaki, O.; Okan Sakar, C. Nonlinear Feature Extraction using Multilayer Perceptron based Alternating Regression for Classification and Multiple-output Regression Problems. In Proceedings of the 7th International Conference on Data Science, Technology and Applications, Porto, Portugal, 26–28 July 2018; pp. 107–117. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Y.; Tian, J.; Li, T. LSTM-CNN Hybrid Model for Text Classification. In Proceedings of the IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018; pp. 1675–1680. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, L.; Gomez, A.N.; Chollet, F. Depthwise Separable Convolutions for Neural Machine Translation. In Proceedings of the ICLR 2018 Conference, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–10. [Google Scholar]
- Timo, I. Denk. Text Classification with Separable Convolutional Neural Networks, Technical Report for Internship; Baden-Wurttemberg Cooperative State University Karlsruhe: Karlsruhe, Germany, 17 September 2018. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, B.; Ding, Y. DSXplore: Optimizing Convolutional Neural Networks via Sliding-Channel Convolutions. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Portland, ON, USA, 17–21 May 2021; pp. 619–628. [Google Scholar] [CrossRef]
- Yadav, R. Light-Weighted CNN for Text Classification; Project Report; Technical University of Kaiserslautern: Kaiserslautern, Germany, 16 April 2020. [Google Scholar]
- Khanal, J.; Tayara, H.; Chong, K.T. Identifying Enhancers and Their Strength by the Integration of Word Embedding and Convolution Neural Network. IEEE Access 2020, 8, 58369–58376. [Google Scholar] [CrossRef]
- Abdulmumin, I.; Galadanci, B.S. hauWE: Hausa Words Embedding for Natural Language Processing. In Proceedings of the 2019 2nd International Conference of the IEEE Nigeria Computer Chapter (Nigeria ComputConf), Zaria, Nigeria, 14–17 October 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Pierina, G.A. Bag of Embedding Words for Sentiment Analysis of Tweets. J. Comput. 2019, 14, 223–231. [Google Scholar] [CrossRef]
- Xiao, L.; Wang, G.; Zuo, Y. Research on Patent Text Classification Based on Word2Vec and LSTM. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 71–74. [Google Scholar] [CrossRef]
- Ihm, S.Y.; Lee, J.H.; Park, Y.H. Skip-Gram-KR: Korean Word Embedding for Semantic Clustering. IEEE Access 2019, 7, 39948–39961. [Google Scholar] [CrossRef]
- Gao, X.; Ichise, R. Adjusting Word Embeddings by Deep Neural Networks. In Proceedings of the 9th International Conference on Agents and Artificial Intelligence, Porto, Portugal, 24–26 February 2017; pp. 398–406. [Google Scholar] [CrossRef]
- Yan, F.; Fan, Q.; Lu, M. Improving semantic similarity retrieval with word embeddings. Concurr. Comput. Pract. Exp. 2018, 30, e4489. [Google Scholar] [CrossRef]
- Sellam, D.V.; Das, A.R.; Kumar, A.; Rahut, Y. Text Analysis Via Composite Feature Extraction. J. Adv. Res. Dyn. Control Syst. 2020, 24, 310–320. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhu, Z.; Xin, B. One-step Local Feature Extraction using CNN. In Proceedings of the 2020 IEEE International Conference on Networking, Sensing and Control (ICNSC), Nanjing, China, 30 October–2 November 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mehrkanoon, S. Deep neural-kernel blocks. Neural Netw. 2019, 116, 46–55. [Google Scholar] [CrossRef]
- Wang, M.; Shang, Z. Deep Separable Convolution Neural Network for Illumination Estimation. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence, Prague, Czech Republic, 91–21 February 2019; pp. 879–886. [Google Scholar] [CrossRef]
- Mao, Y.; He, Z.; Ma, Z.; Tang, X.; Wang, Z. Efficient Convolution Neural Networks for Object Tracking Using Separable Convolution and Filter Pruning. IEEE Access 2019, 7, 106466–106474. [Google Scholar] [CrossRef]
- Junejo, I.N.; Ahmed, N. A multi-branch separable convolution neural network for pedestrian attribute recognition. Heliyon 2020, 6, e03563. [Google Scholar] [CrossRef]
- Hssayni, E.H. Regularization of Deep Neural Networks with Average Pooling Dropout. J. Adv. Res. Dyn. Control Syst. 2020, 12, 1720–1726. [Google Scholar] [CrossRef]
- Li, Y.; Wang, K. Modified convolutional neural network with global average pooling for intelligent fault diagnosis of industrial gearbox. Eksploat. I Niezawodn.—Maint. Reliab. 2019, 22, 63–72. [Google Scholar] [CrossRef]
- Hsiao, T.Y.; Chang, Y.C.; Chiu, C.T. Filter-based Deep-Compression with Global Average Pooling for Convolutional Networks. In Proceedings of the 2018 IEEE International Workshop on Signal Processing Systems (SiPS), Cape Town, South Africa, 21–24 October 2018; pp. 247–251. [Google Scholar] [CrossRef]
- Hsiao, T.Y.; Chang, Y.C.; Chou, H.H.; Chiu, C.T. Filter-based deep-compression with global average pooling for convolutional networks. J. Syst. Archit. 2019, 95, 9–18. [Google Scholar] [CrossRef]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance Evaluation of Deep Neural Networks Applied to Speech Recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Network | Number of Parameters | Total Time (s) | D (%) |
|---|---|---|---|
| LSTM | 131,681 | 599.9 | 68.89 |
| GRU | 124,065 | 567.18 | 67.88 |
| RNN | 107,969 | 239.2 | 68.35 |
| FCN | 198,209 | 25.6 | 76.40 |
| SCNN | 103,466 | 149.8 | 78.60 |
| Type of Network | Number of Parameters | Total Time (s) | D (%) |
|---|---|---|---|
| LSTM | 131,746 | 2242.8 | 77.75 |
| GRU | 124,130 | 2286.45 | 79.25 |
| RNN | 108,034 | 1877.36 | 78.25 |
| FCN | 102,914 | 42.73 | 76.95 |
| SCNN | 103,466 | 311.92 | 79.40 |
| Type of Network | Number of Parameters | Total Time (s) | D (%) |
|---|---|---|---|
| LSTM | 111,494 | 125.5 | 87.13 |
| GRU | 104,006 | 117.14 | 84.13 |
| RNN | 88,166 | 64.55 | 83.53 |
| FCN | 83,046 | 4.14 | 89.52 |
| SCNN | 84,102 | 12.84 | 92.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Solovyeva, E.; Abdullah, A. Binary and Multiclass Text Classification by Means of Separable Convolutional Neural Network. Inventions 2021, 6, 70. https://doi.org/10.3390/inventions6040070
Solovyeva E, Abdullah A. Binary and Multiclass Text Classification by Means of Separable Convolutional Neural Network. Inventions. 2021; 6(4):70. https://doi.org/10.3390/inventions6040070
Chicago/Turabian StyleSolovyeva, Elena, and Ali Abdullah. 2021. "Binary and Multiclass Text Classification by Means of Separable Convolutional Neural Network" Inventions 6, no. 4: 70. https://doi.org/10.3390/inventions6040070