1. Introduction
Elliptic curve cryptography (ECC) was presented by N. Koblitz and V. Miller [
1,
2] in 1986. The ECC is an encryption technique based on the discrete logarithm problem. The public key cryptographic primitives can be implemented by using the elliptic curves over finite fields to generate finite abelian groups. The ECC provides similar security to existing public key cryptography but via application of a smaller key. The ECC with a 160-bit key has the equivalent security level of Rivest–Shamir–Adleman (RSA) and digital signature algorithms (DSA) that require a 1024-bit key. The ECC is defined over prime finite fields GF(
p) or binary finite fields GF(2
m). The ECC design over prime fields generally provides more robust resistance to side-channel attacks as compared with those over binary fields. However, the ECC design over binary fields has the carry-free feature and makes arithmetic operations more suitable for hardware implementation.
The authors of [
3] presented a method for constructing dynamic lookup tables in order to realize multiplication over a finite field. The Euclidian algorithm can be used for the inverse operation at the expense of computation time. Algorithms for the point multiplication over the ECC have been investigated in many studies. The method of non-adjacent forms (NAF) was presented by Morain et al. [
4] to record the scalar in a point multiplication with an aim of reducing nonzero bits and thus the number of point additions. The authors of [
5] used the representation of integers in binary form for simplification. Nowadays, most ECC techniques are performed over Koblitz curves [
1,
6]. Solinas [
7] presented the Frobenius map method for data encryption. The projective and affine coordinates were combined in [
8] to implement high-efficiency point addition and point doubling operations. There are no inverse operations involved in the exploitation of the coordinate transform techniques. Guo et al. developed [
9] a scalar multiplication algorithm based on the step multi-base representation via point halving and the septuple formula to significantly reduce computational cost. The triple-based chain method was proposed in [
10] to optimize the time usage in the elliptic curve cryptosystem. The authors of [
11] presented a configurable ECC crypto-processor. The ECC operates over the prime field and is defined by the Weierstrass equation. This crypto-processor was verified on a Xilinx FPGA board.
The existing work on modular multipliers over binary finite fields GF(2
m) can be found in [
12,
13,
14]. In [
15], a speed-oriented architecture over the finite fields GF(2
163) and GF(2
571) were implemented by using a balanced quadratic multiplier with high operating frequency. Li et al. [
16] exploited the Karatsuba–Ofman multiplier to a scalar multiplication over the finite fields over GF(2
571) and GF(2
283). To minimize the number of point additions without increasing the number of point doubling, the Radix-2
w arithmetic for scalar multiplication was proposed in [
17]. The authors of [
18] developed a new Montgomery point multiplication algorithm for large field-size ECC over GF(2
571) and GF(2
409) to optimize resource utilization efficiency. Recently, Zhang et al. [
19] introduced a high-performance scalar multiplication architecture over binary fields. A low-latency window (LLW) algorithm was presented for hardware implementation to enhance security, as was an enhanced comb method for point addition and point doubling. The above methods in [
15,
16,
17,
18,
19] transformed the process of scalar multiplication from an affine coordinate system to a projective coordinate system. These designs were implemented and verified on the FPGA boards.
Different from operations over the projective coordinate system, this paper focuses on the scalar multiplication over the affine system. The hardware architecture and circuit are synthesized for future ASIC implementation. In the affine coordinate system, point addition and point doubling require one modular inversion operation each time. Because the inversion over the finite field is the most time-consuming operation among all of the basic operations. Reducing the number of inverse operations is an important objective of our design. The main idea of this paper can be described as follows: The Fermat’s little theorem [
20] is flexibly used for the inverse operation, which controls the critical path easily, as hardware implementation is required. The Horner’s rule is also innovatively exploited to improve the method in [
5]. By the binary representation and grouping techniques for constructing lookup tables, the operations of point addition and point doubling are improved. A high-speed scalar multiplication is therefore achieved. The presented approach is applicable to the digital signature [
21] for real-time mutual authentication. Finally, the proposed lookup table-based algorithms can be utilized for software and hardware implementations as the developed arithmetic operations are simple and consistent in their execution. From the perspective of the hardware design, the computational time of the scalar multiplication by the proposed method is reduced by 67% over the conventional algorithm. This is because the presented two-time point doubling is superior to the conventional method.
The rest of the paper is organized as follows: The finite field arithmetic is introduced in
Section 2.
Section 3 briefs the concepts of point addition and point doubling in ECC. The proposed algorithms for the finite field arithmetic is described in
Section 4.
Section 5 presents the new algorithm for scalar multiplication, which combines the methodology in
Section 4.
Section 6 concludes this paper.
2. Finite Field Arithmetic
The finite field is a set of finite elements of the field, also known as the Galois field (GF). Multiplication, addition, subtraction and division are defined and certain basic rules are satisfied.
The finite field GF(2) has two elements, with values of 0 and 1. The finite field GF(2) can be extended to GF(2
m) by a primitive polynomial. The finite field GF(2
m) has 2
melements with the values from 0 to 2
m − 1. The primitive polynomial is an irreducible polynomial denoted as
. The national institute of standards and technology (NIST) recommended the primitive polynomials that are applicable to different GF(2
m) finite fields in the public document FIPS 186-4 [
22] issued in 2013, as shown in
Table 1.
2.1. Addition and Subtraction
The addition operation over the finite field is , where . The element has m-bit representation in a vector form. The addition is based on the bitwise exclusive OR (XOR) operation. Consider an example of GF(23). Let and . The result of is . The subtraction operation is the same as the addition operation.
2.2. Finite Field Multiplication
Multiplication over the finite field is defined as
, where
. The element
can be represented by the polynomial
, where
. The element
is expressed by the polynomial
, where
. The element
is represented by
, where
. The multiplication result
is the polynomial multiplication of
and
modulo
, where
is the primitive polynomial. That is,
Take the field GF(23) as an example. Let the elements and be and , respectively. The primitive polynomial is . The multiplication result of and is obtained as .
2.3. Finite Field Division
The division operation is
. It can be viewed as
, where
is the inverse element of
. The inverse element of an element can be obtained quickly by Fermat’s little theorem. Let
represent the element of a finite field, briefly denoted as
. Using the fact that
, we have
. Furthermore,
The inverse element can be calculated efficiently.
4. Proposed Lookup Table-Based Techniques for Arithmetic on
This paper focuses on the finite field .
4.1. Improved Multiplication Algorithm
Let
. By Horner’s rule,
is expressed as
Furthermore, the multiplication of the polynomials
and
is re-written as
Define as the number of input items of .
As
,
. In the case of
,
. According to (16), one needs only
executions to create an H table. The table of
for
is shown in
Table 2.
4.2. Lookup Table-Based Modulo Operation
Consider the multiplication of
. We have
where
. In (17), there are
q terms (
) to perform a modulo
operation, because of the degree. As a result, we can establish a table with which to manage these
terms. The table is used to store the results of
. Such a table is required when
. The inputs of the table with
q terms are
. The output is
, where
. For
, the M table is constructed as
Table 3.
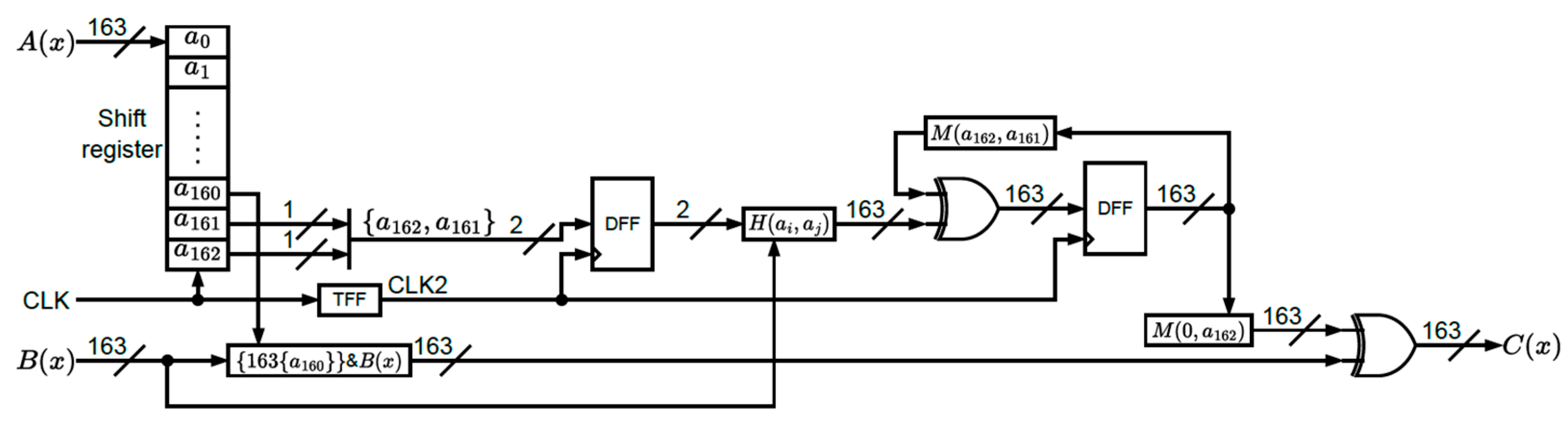
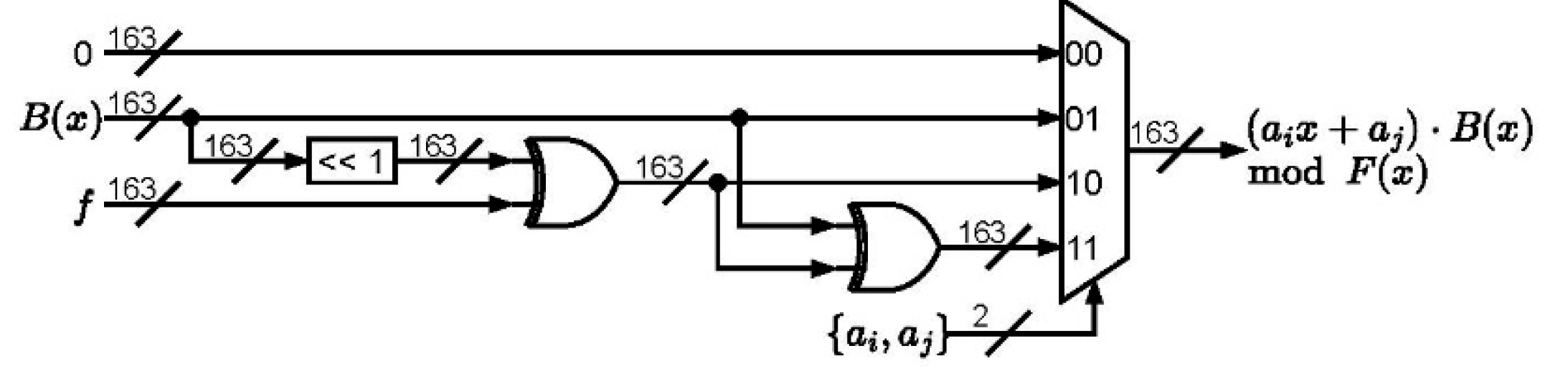
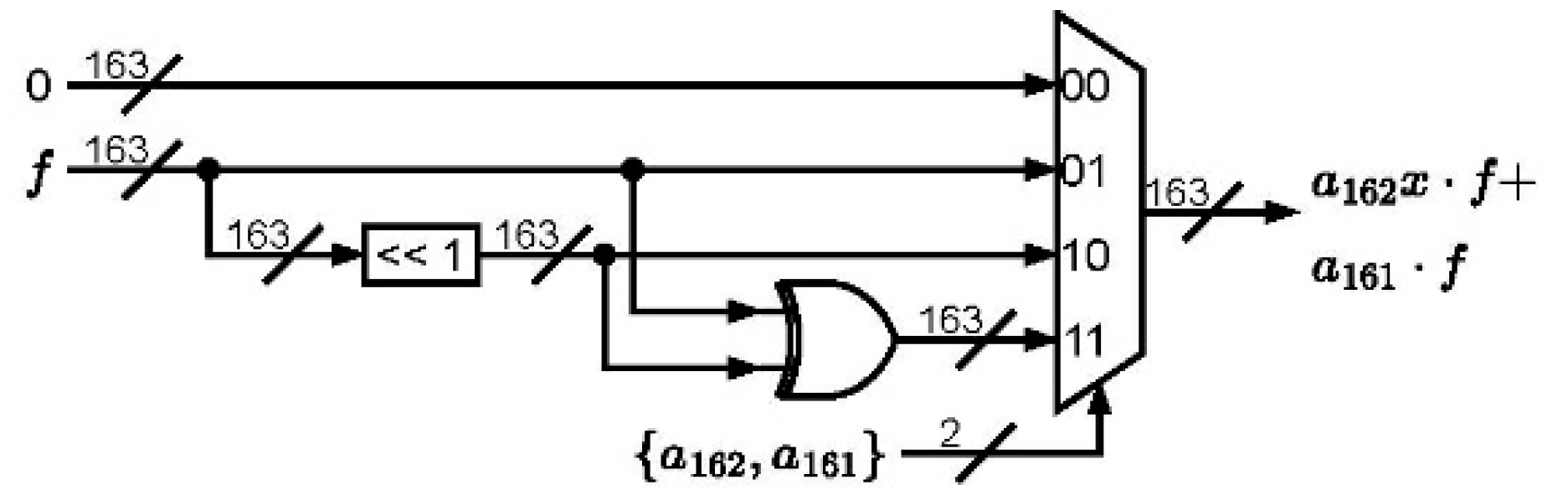
The circuit of the finite field multiplication is depicted in
Figure 1, where the H and M tables are included. It can also be observed that the H table dominates the critical path of the whole architecture. Note that two XOR elements and one multiplexer are required for constructing the H table as depicted in
Figure 2. The M table includes one XOR logic and one multiplexer in
Figure 3.
For the software implementation, there is more time to establish these tables and store the corresponding values. However, the building and searching time for the tables will increase as the tables become large. Additionally, in terms of hardware implementation, more logic elements are required.
4.3. Improved Squaring Operation
The squaring operation of
is
Consider modulo operations of each term as follows:
Let
, where
. In light of (19), we have
where
.
4.4. Improved Inverse Operation
As shown in (12), we have
(21) can be re-written as
where
and
are sign function defined as follows:
Simplification of and in (22) is required.
As
is even, it is derived that
According to (24) and (25), (22) is represented as
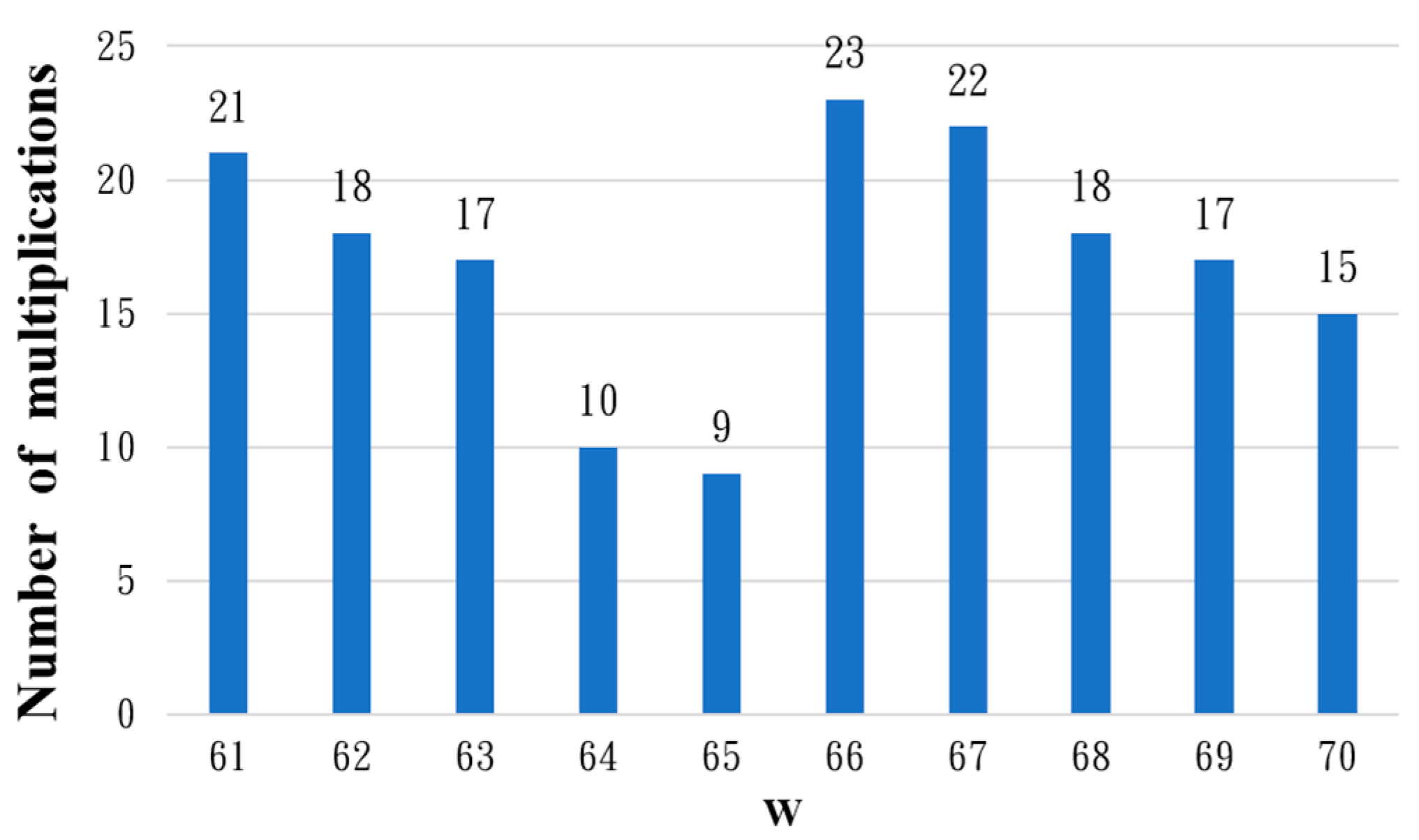
The original Fermat’s little theorem for the inverse element operation needs to go through 162 cycles of power operation and 161 cycles of multiplication operation. The main purpose of the above simplification process is to reduce the number of multiplication operations, but there is also a need to increase the number of different
power operations. We investigate the number of multiplications for the inverse operation on the field GF(2
163) for various
. The results are depicted in
Figure 4 for
to
.
It can be seen in
Figure 1 that grouping by
requires the lowest number of multiplications. In the following, the inverse operation of
and grouping by
are simplified, where
, as shown in (27).
Simplify
and
in (27) and let
. We have
Using the idea, it is derived as follows:
where
.
where
.
where
.
where
.
where
.
Among these, is the same as the residue , so there is no need to simplify the residue further, though it does need to store the value of after the operation. In this case, where , the inverse operation over the field GF(2163) requires 9 multiplication operations, 1 squaring operation and power operations.
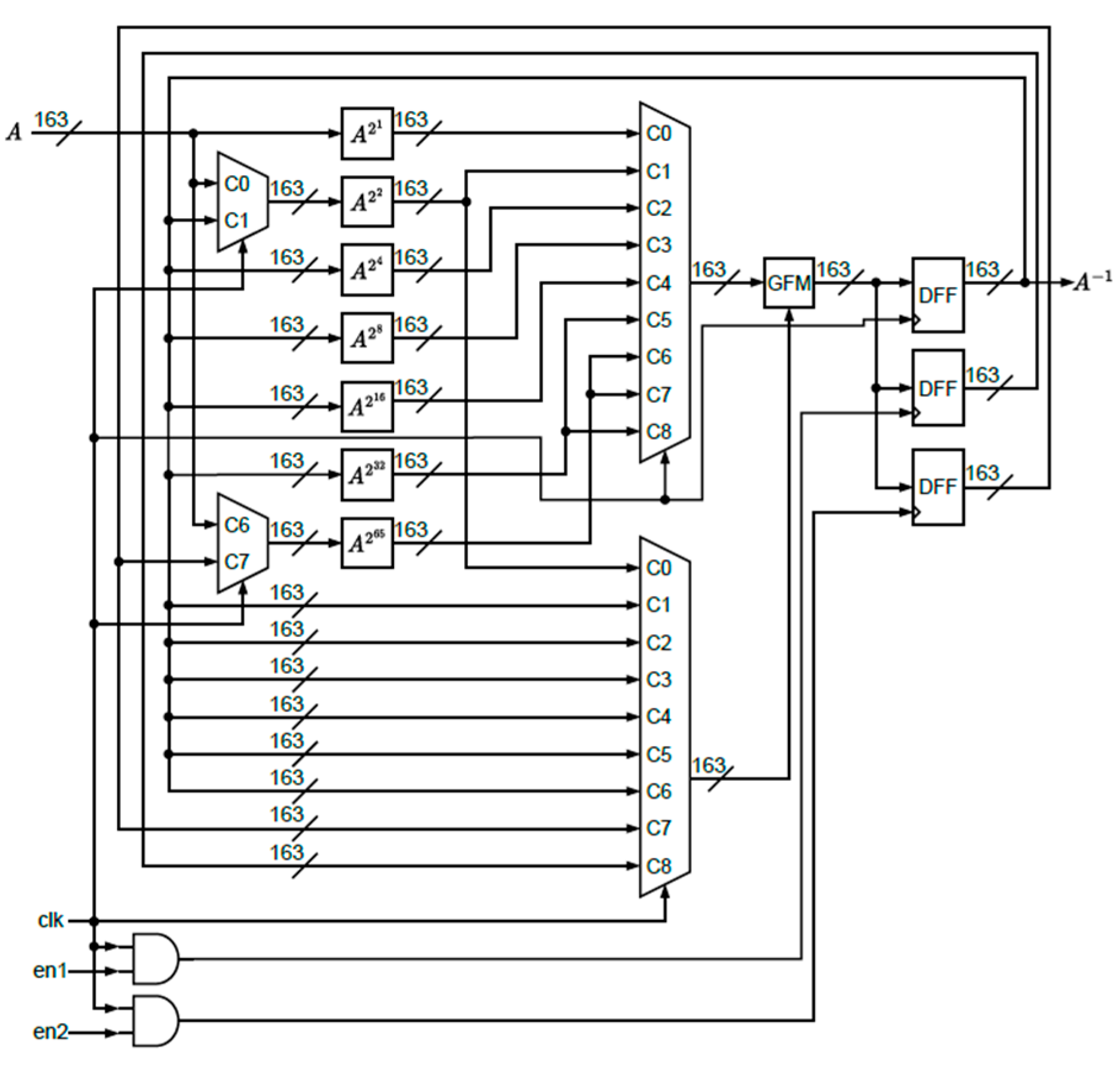
The circuit for inverse operation over GF(2
163) is shown in
Figure 5. The GFM is the Galois field multiplication unit and the input C
i in the multiplexer means the
ith cycle.
5. Proposed Elliptic Curve Scalar Multiplication Operation
By building a table of elliptic curve points and using a table lookup method and an inverse operation that reduces the number of iterations of point doubling by two, the speed of scalar multiplication of elliptic curves is increased.
5.1. Conventional Multiple Time Point Doubling Algorithm
Consider Algorithm 1, called Point_Doubling_Repeating
, where
is the point of the elliptic curve and
is a positive integer. If
, the point of
will be subjected to a point doubling operation twice. The coordinate of
is
and the result of point doubling is
.
| Algorithm 1 Point Doubling Repeating |
1: Function Point_Doubling_Repeating
2: for from to do
3:
4:
5:
6:
7:
8:
9: end for
10: end function |
The computational complexity of Algorithm 1 is listed in
Table 4 with
and
. It is observed that point doubling two times (
) requires the inverse operation two times. In fact,
inverse operations are needed as
.
5.2. Proposed Two-Time Point Doubling Algorithm
Algorithm 2, Point_Doubling_Modify
, is presented, where the input of
point is
. As
, the point doubling is performed once and the output is
. When
, the improved algorithm for point doubling twice is executed and the output is
.
| Algorithm 2 Point Doubling Modify |
1: Function Point_Doubling_Modify
2: if then
3:
4:
5:
6:
7: else if then
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
20:
21:
22:
23:
24:
25:
26:
27:
28:
29:
30: end if
31: return
32: end function |
The number of finite field operations required for improved two-time point doubling is shown in
Table 5. It can be found that, after simplification, only one inverse operation is required.
Comparison with the conventional two-time point doubling is revealed in
Table 6. Although the proposed two-time point doubling algorithm reduces the number of inverse operations by 1, it increases the number of multiplication operations by 5 and the number of squaring operations by 2.
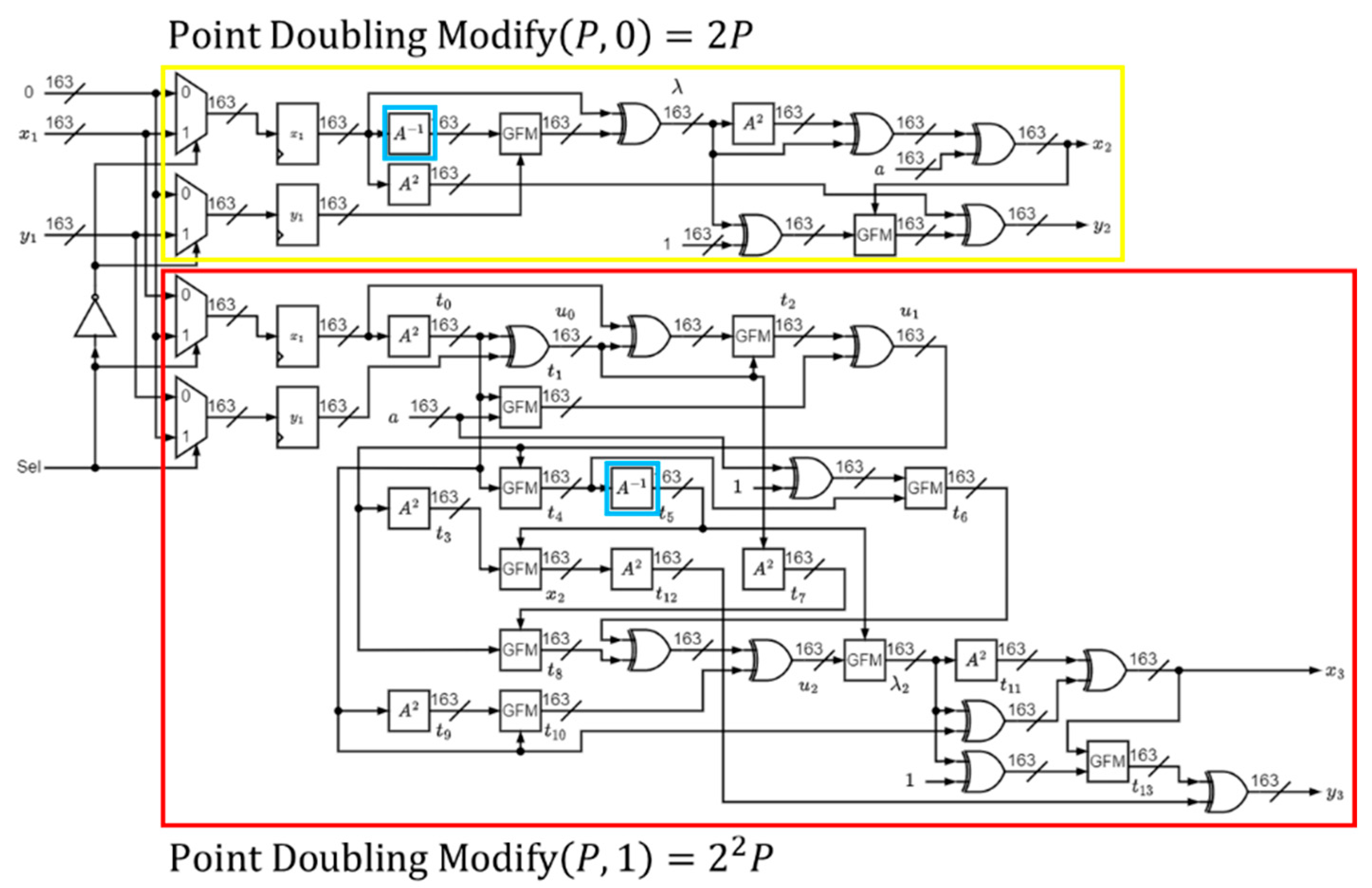
The proposed architecture of two-time point doubling is presented in
Figure 6. The yellow block is used to perform one-time point doubling and the red block is for computing two-time point doubling.
The inverse operation utilizes the framework in
Figure 5.
5.3. Proposed Elliptic Curve Scalar Multiplication Algorithm
The elliptic curve scalar multiplication operation is defined in (14). The positive integer K is expressed as follows in the binary form.
where
.
If
is odd,
K is re-written as
by Horner’s rule. Moreover,
It is observed in (36) that the last term is
and that the common term is expressed as
. As a result, the L table is motivated and constructed. The L table is listed as
Table 7, where the input is
. As when one builds the L table, the operations for point addition and doubling once need to be performed first. There are an additional four 163-bit registers required for the table.
The term of
can be viewed as a point of the elliptic curve. This term requires point doubling once, as
. Furthermore,
is the operation of two-time point doubling. According to (36), a new scalar multiplication technique is proposed in Algorithm 3.
| Algorithm 3 New Scalar Multiplication 1 |
1: Function New_ScalarM
2:
3: To make a lookup table as shown in Table 7
4: for from to do
5: Point_Doubling_Repeating
6: Point_Addition
7: end for
8: Point_Doubling_Repeating
9: Point_Addition
10: return
11: end function |
We replace Point_Doubling_Repeating
with Point_Doubling_Modify
in Algorithm 3. Algorithm 4 is therefore obtained.
| Algorithm 4 New Scalar Multiplication 2 |
1: Function New_ScalarM
2:
3: To make a lookup table as shown in Table 7
4: for from to 0 do
5: Point_Doubling_Modify
6: Point_Addition
7: end for
8: Point_Doubling_Modify
9: Point_Addition
10: return
11: end function |
The numbers of arithmetic operations required in Algorithms 3 and 4 are demonstrated in
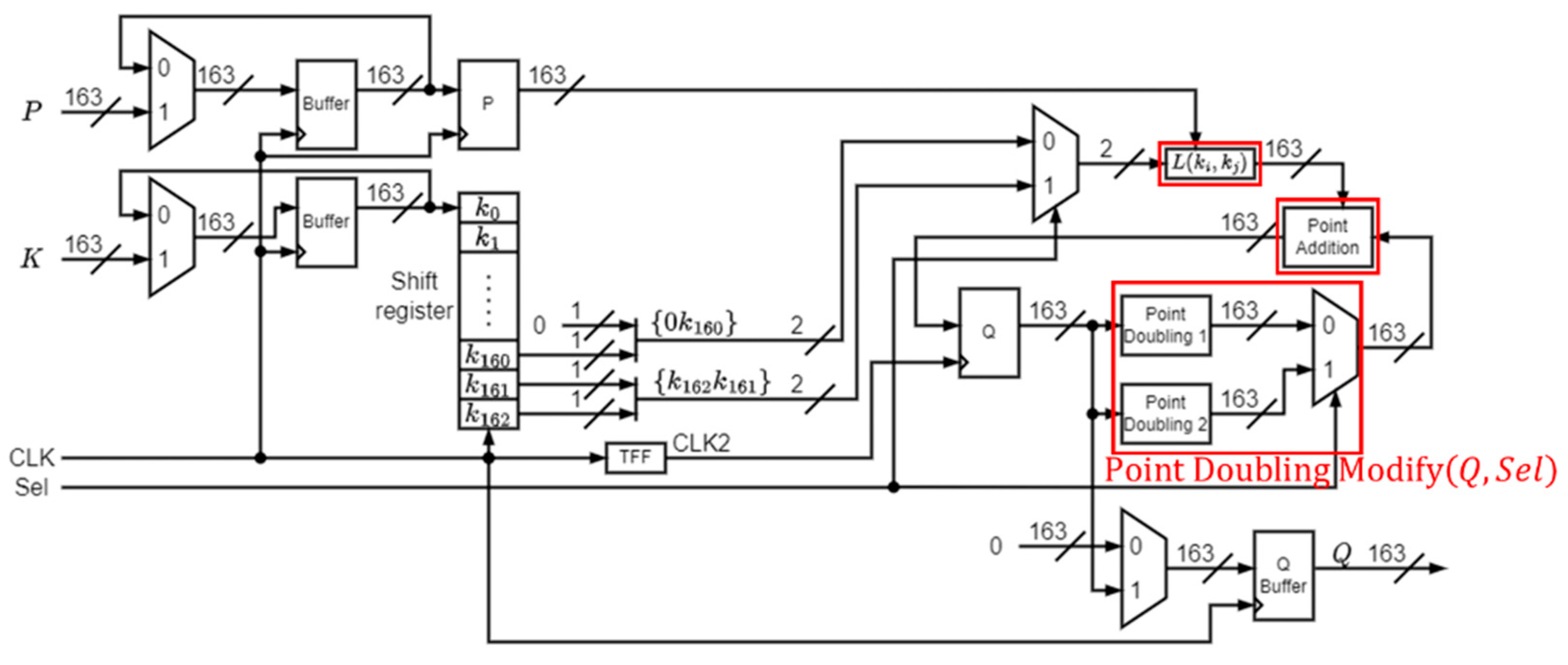
Table 8. The proposed framework of the scalar multiplication by Algorithm 4 is depicted in
Figure 7, where Algorithm 2 is applied for point doubling. Note that using the improved two-time point doubling reduces the number of inverse operations by 81. However, the numbers of multiplication and squaring operations will increase by 405 and 162, respectively.
5.4. Performance Evaluation
The results of multiplication over the finite field GF(2163) are obtained after computing 163 coefficients. Utilization of the H table by Horner’s rule only needs computation of coefficients. The M table is exploited in order to speed up the modulo operation by the XOR operation. The inverse operation using Fermat’s little theorem is obtained by the simplifications of and . The results of and are stored in advance. Thus, this leads to improvements in performance of the inverse operation.
The most time-consuming operation over the finite field is the inverse operation. Exploiting Horner’s rule to compute the inverse requires nine multiplication and one squaring operation. The conventional two-time point doubling needs two inverse operations. However, the proposed method requires only one inverse operation at the expense of five multiplication and two squaring operations. Finally, the proposed algorithm reduces four multiplications and increase two squaring operations. Elliptic curve point multiplication KP is improved by using the idea that the integer K is expressed in the binary form with Horner’s rule-based grouping technique. The L table is established to further enhance the efficiency of the scalar multiplication.
The efficiency evaluations for the proposed hardware design are listed in
Table 9,
Table 10,
Table 11 and
Table 12. All circuits are synthesized with Taiwan Semiconductor Manufacturing Company (TSMC) 40 nm standard cell library by Synopsys Design Compiler
Table 9 indicates the synthesized results of the proposed multiplication method, with various d values. It is observed that the shortest critical path happens as
d = 2. For the proposed squaring circuits,
Table 10 shows that the critical path becomes short with the increase of n. However, the improvements are not significant from the cases of 2
16 to 2
65.
Table 11 reveals that the proposed two-time point doubling has a 48% shorter computing time when compared with the conventional one, and with low area–time complexity. Take the architectures of scalar multiplication into consideration in
Table 12. The delay of Algorithm 4 is improved by 67% over Algorithm 3, with an area increase of only 12%.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}