

Privacy-Preserving k-Nearest Neighbor Classification over Malicious Participants in Outsourced Cloud Environments
Abstract
:1. Introduction
- In this study, we propose a solution based on somewhat homomorphic encryption (SHE) [11,12] to address security and privacy concerns when a user outsources sensitive data to a cloud. This solution, that the outsourced data are encrypted and stored on the cloud, can eliminate potential security and privacy risks. This outsourcing stage’s primary goal is to ensure the confidentiality and integrity of sensitive information in cloud environments.
- Inspired by [13], a secure computation protocol based on garbled circuits is proposed to address the security and privacy issues in data interaction between two clouds. In this protocol, each cloud can only obtain its garbled data and cannot access the raw data from the other cloud, thereby ensuring data confidentiality.
- The subordinate phrase of maintaining the anonymity of the QU’s identity, daring the authentication process, does not appear to modify the subject of a proposed solution. A proposed solution introduces a Fujisaki–Okamoto commitment (FO)-based [14,15] lightweight anonymous two-way authentication protocol between a cloud and a querying user. The authentication process in our novel protocol ensures the anonymity of a query user by using the commitment.
- Finally, the security model, security definitions, and security requirements in a malicious dyadic cloud environment are given. And we prove that our solution can satisfy our security and privacy protection goals. In addition, our experimental results based on simulated data show feasibility and reliability.
2. Related Work
3. Preliminary
3.1. Somewhat Homomorphic Encryption
- Homomorphic addition: Given two ciphertexts and , there exists an operation ⊕ such that . Given a ciphertext and an open constant , .
- Homomorphic multiplication: Given two ciphertexts and , there exists an operation ⊗ such that . Given a ciphertext and an open constant , .
3.2. Elliptic Curves
3.3. Fujisaki–Okamoto Commitment Agreement
3.4. Non-Contact Commitment
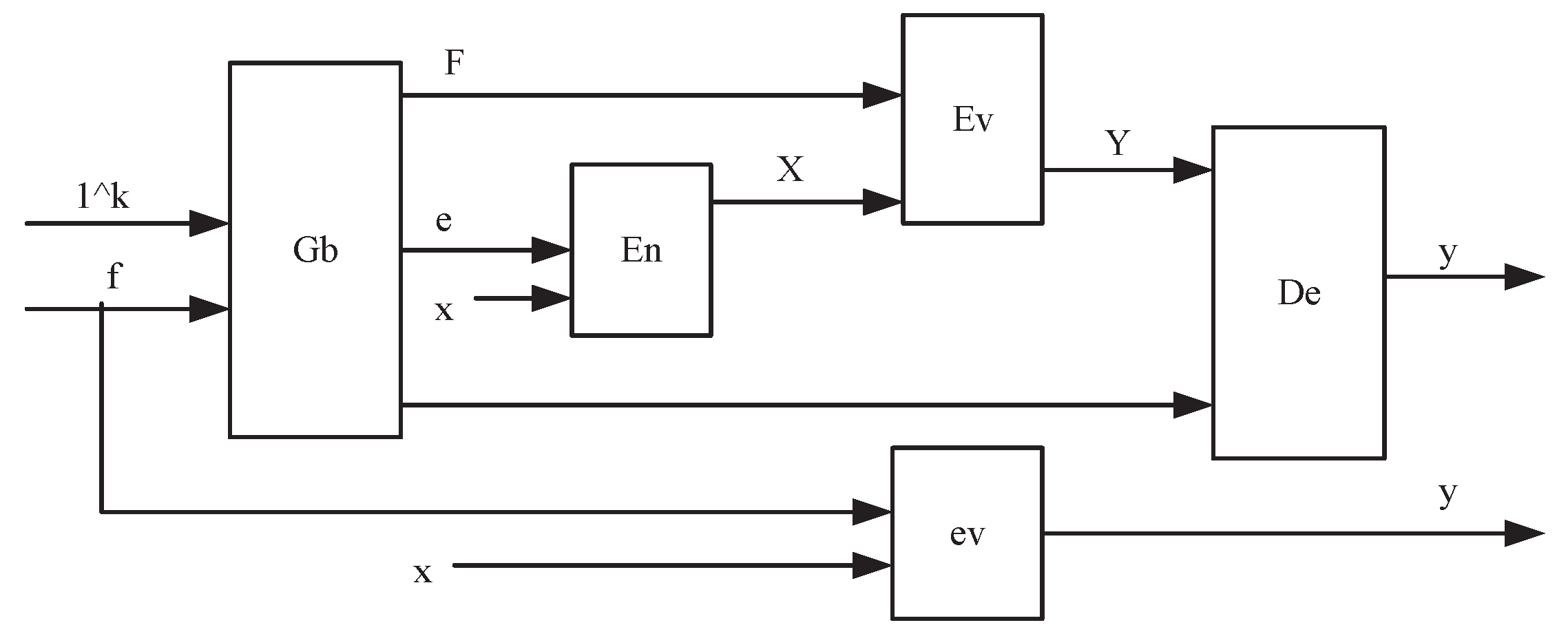
3.5. Garbled Circuits
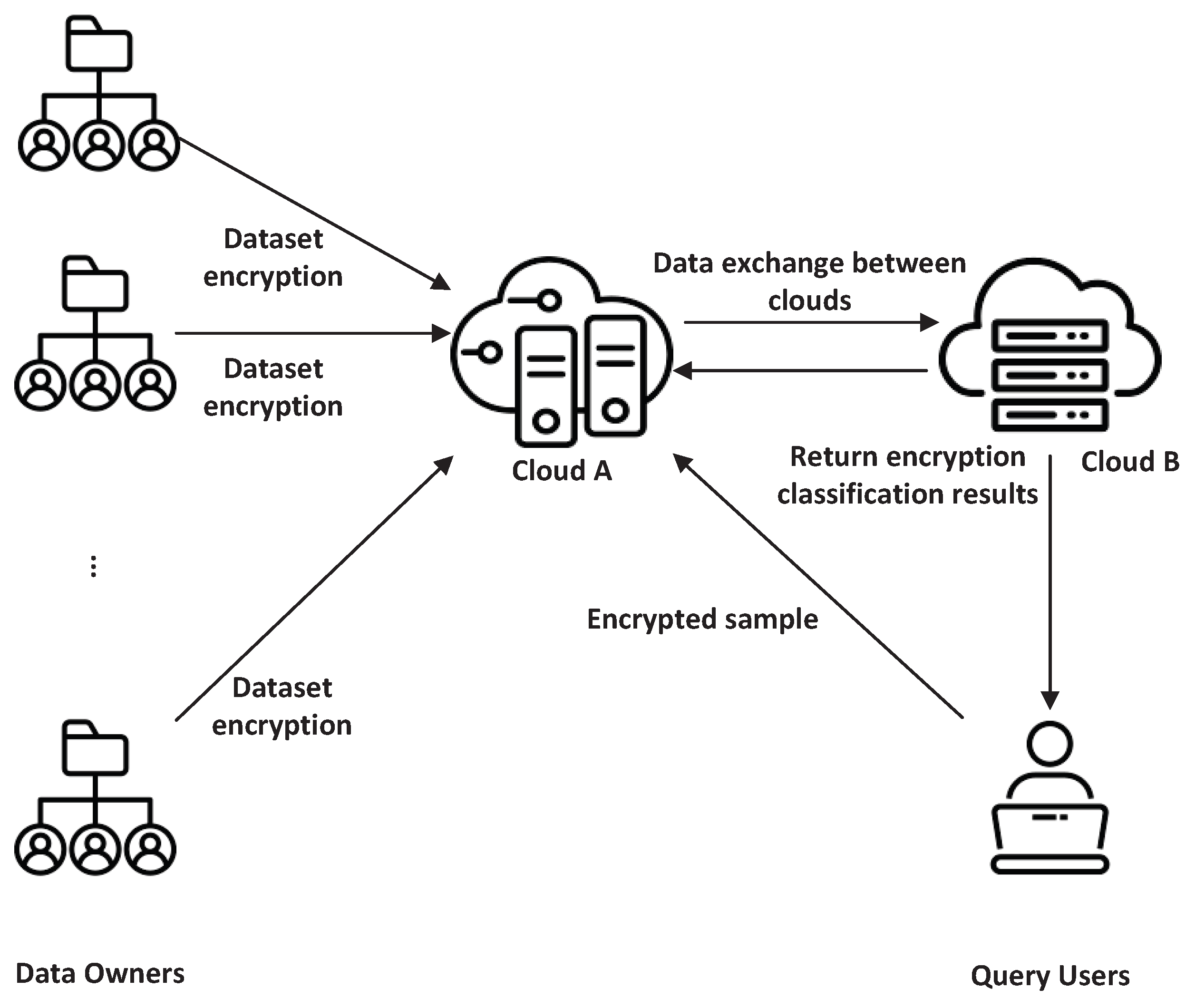
4. System Model, Threat Model, and Design Goals
4.1. Notations
4.2. System Model
- Dyadic cloud: In our system, two independent clouds are denoted as and , respectively. They both maintain the data provided by the data owners. Through a series of secure protocols, they can answer multiple queries in a way that preserves privacy.
- Data owner (DO): Our solution requires that the DO generates and encrypts its data with SHE and then uploads the encrypted data to a cloud.
- Query user (QU): An anonymous two-way authentication protocol based on Fujisaki–Okamoto commitment is adopted between a cloud and the QU. Next, our solution requires that a QU submits its encrypted sample to a cloud when it needs to query some information. A cloud will respond to the QU’s query when it receives a QU’s request—the QU recovery query results.
4.3. Threat Model
- The malicious may illegally collect and infer the true identity of a QU, and the can reconstruct sensitive information based on storage location information. In an outsourcing system, the can arbitrarily deviate from the specified computation task. It not only tries to capture users’ private information but also may return a deliberately forged result to fool the QU.
- The semi-honest QU that an attacker compromised may access the system by impersonating a legitimate QU, and it also performs a replay attack or observes messages between a cloud and a legitimate QU to capture another QU’s privacy.
4.4. Design Goals
- Privacy of data outsource: A DO’s plaintext data and private key are uniquely known only to itself and will not be disclosed to other participating parties.
- Privacy of query data: The data access pattern in the ciphertext KNN classification process ensures that the data points in the ciphertext data set corresponding to the KNN classification labels are not disclosed to the cloud. Additionally, the authentication process between a QU and the cloud ensures the confidentiality of the real identity. While adversaries can obtain the pseudonym of the QU, they cannot deduce any relevant information about the real identity of the QU, thereby preventing potential privacy leakage risks.
- Privacy of interaction between clouds: In the protocol of secure mean calculation, data privacy is ensured as each cloud can only access its own obfuscated data, thereby preventing access to the original data of another cloud.
5. Our Scheme
5.1. Plaintext Encoding
5.2. Security of Data Outsourcing
- Step 1: Select an element from a discrete Gaussian distribution .
- Step 2: Select an element from .
- Step 3: Set the public key to , where , and the private key is .
- Step 4: A DO utilizes the expansion factor to expand and round each of the sample data and transforms each sample’s class label into a 0-1 vector . If the condition is satisfied, the t-th position in is set to 1, while the other bits are set to 0.
- Step 5: The DO divides data value D into s blocks, each containing l samples. We assume the total number of samples n is a multiple of l. For each data block i, the DO bundles l data records with the same attribute j and encrypts them with public key to obtain .
- Step 6: The DO encrypts the class labels corresponding to each sample in data block i to obtain .
- Step 7: The DO receives and transmits the encrypted data to .
5.3. Query Privacy
- Step 1: The QU randomly selects , by performing the following computation.
- Step 2: The QU calculates . Then, the QU computesand sends , respectively, to and .
- Step 3: The and the check if c is satisfied.
- Step 1: The and the , respectively, randomly generate and send them to the QU that is requested for signature for anonymous authentication.
- Step 2: After receiving the , the QU randomly selects to serve as a session key. Then, we generate a proof P for the user’s identity in the following manner:where is calculated via the following equation.
- Step 3: According to the equation’s results, P is obtained for the QU.
- Step 4: The QU encrypts with the public key and obtainsThen, the QU sends to the and the .
- Step 5: The and the first decrypt the result of with the private key to evidence the QU and the . Unauthorized cloud entities should not access the secret y stored by I. When the P provided by the QU is accurate, the following equation holds according to the FOC protocol. , whereThen, the and the can verify the QU according to the following equation.
- Step 6: If the above verification is correct, then the QU is legal. The and the use the to encode the message and transmit it to the QU for encryption.
- Step 7: If the QU can decrypt the messages sent by the and the with the , then the and the are secure, and authentication is concluded.
- Step 1: The QU initially generates a random number that is positive in value and converts q into a -dimensional vector .
- Step 2: The QU encrypts each element of vector with the obtaining the ciphertext query data points and sends them to the for ciphertext KNN classification.
5.4. Security of Data Exchange among Clouds
- Step 1: The randomly selects for the promise and, respectively, sends to the and the . The generates random number and shares the secret as , sends to the , and sends to the .
- Step 2: The selects seed for pseudo-random function and then sends to the .
- Step 3: The and the generate the corresponding circuit based on function and randomly select , for all and to generate the following commitments:Finally, the and the send to the the following message:
- Step 4: If the information sent by the and the is different, then the will stop.
- Step 5: The and the send uncommitted messages , , , and , , , , respectively, to the .
- Step 6: For , the for any correct are used to calculate:If there is a call, then return ⊥, and then stop. Similarly, the knows the data and , and the protocol stops if the or the cannot unlock and corresponding to the promise , , , . Then, executes , and sends Y and to the and the .
- Step 7: The and the calculate whether holds.
- Step 1: The calculates the ciphertext inner product of the ciphertext query sample and the ciphertext data point in the ciphertext data, and it obtains the following set of ciphertext inner products.
- Step 2: The arranges the elements in the set of ciphertext inner product and the set of ciphertext classification labels V by using the random permutation function , and it obtains the following two sets of random permutations.The sends collection and V to .
- Step 1: The uses the received ciphertext inner product set for KNN search.
- Step 2: The bases on the structure obtained by using the ciphertext inner product for KNN search, and the ciphertext KNN classification label set is obtained from the ciphertext classification label set V and sent to the QU.
5.5. Query Result Recovery
6. Security Analysis
6.1. Data Outsourcing Security
6.2. Query Privacy Security
6.3. Data Interaction between Clouds Security
7. Experiment
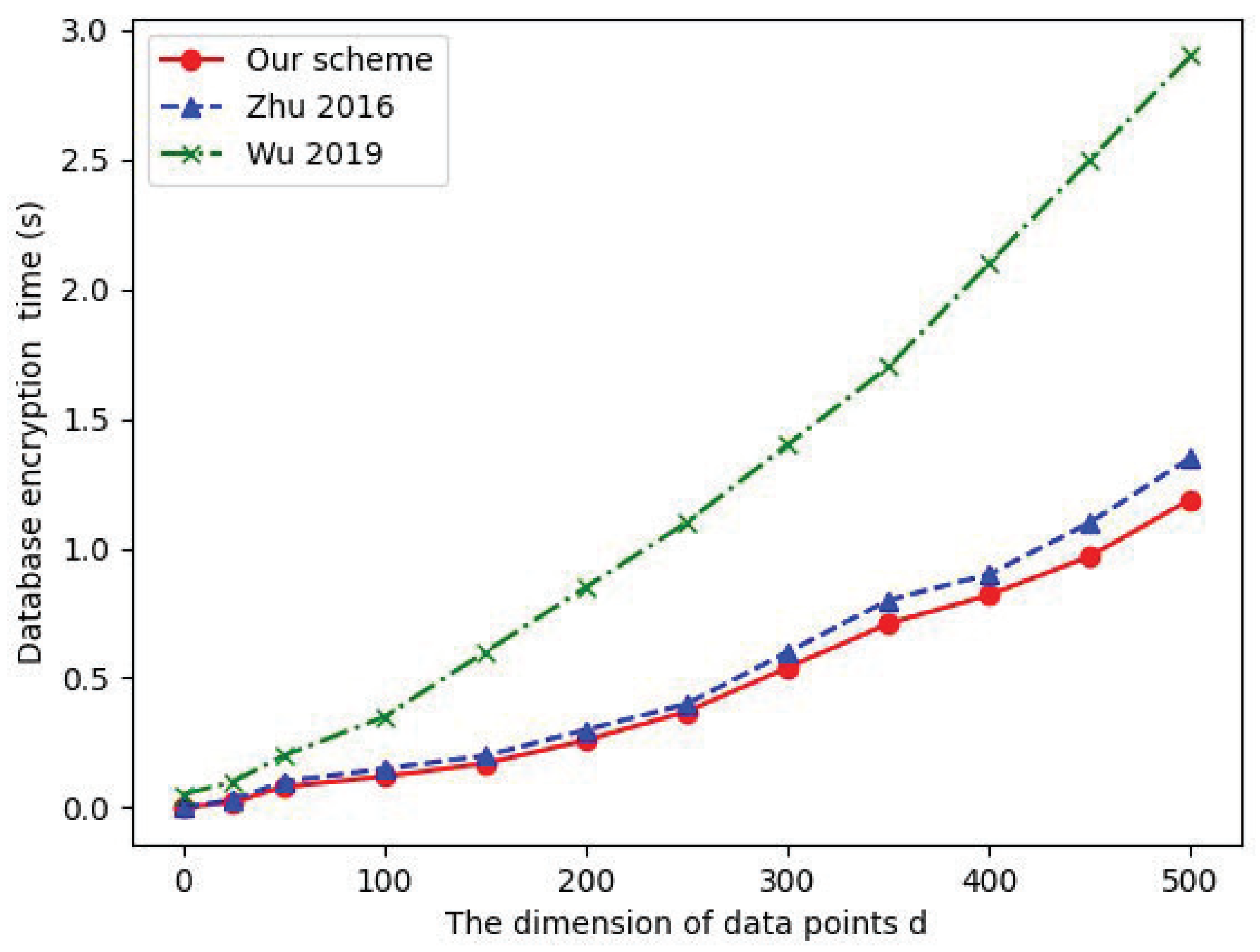
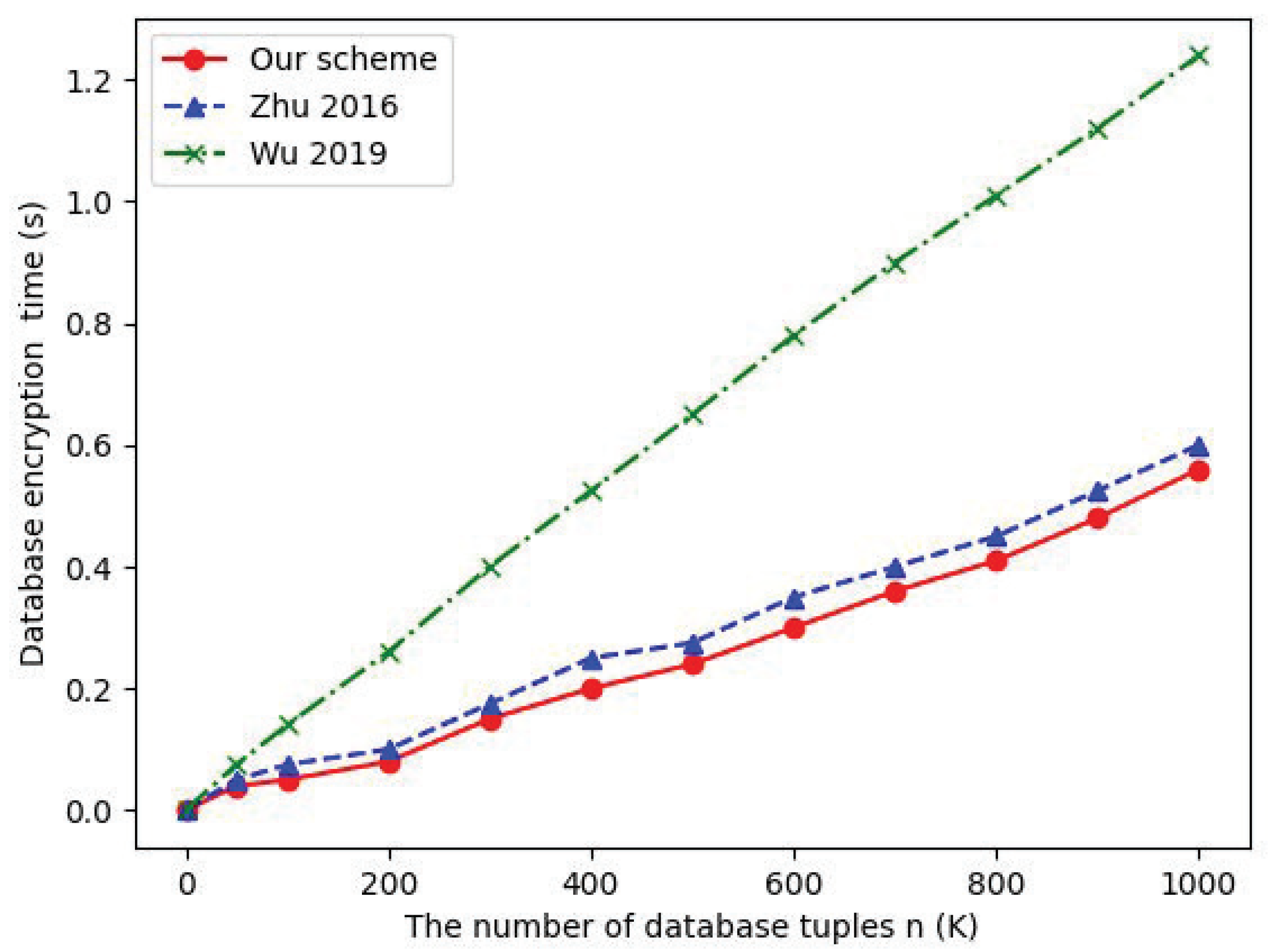
7.1. Data Outsourcing
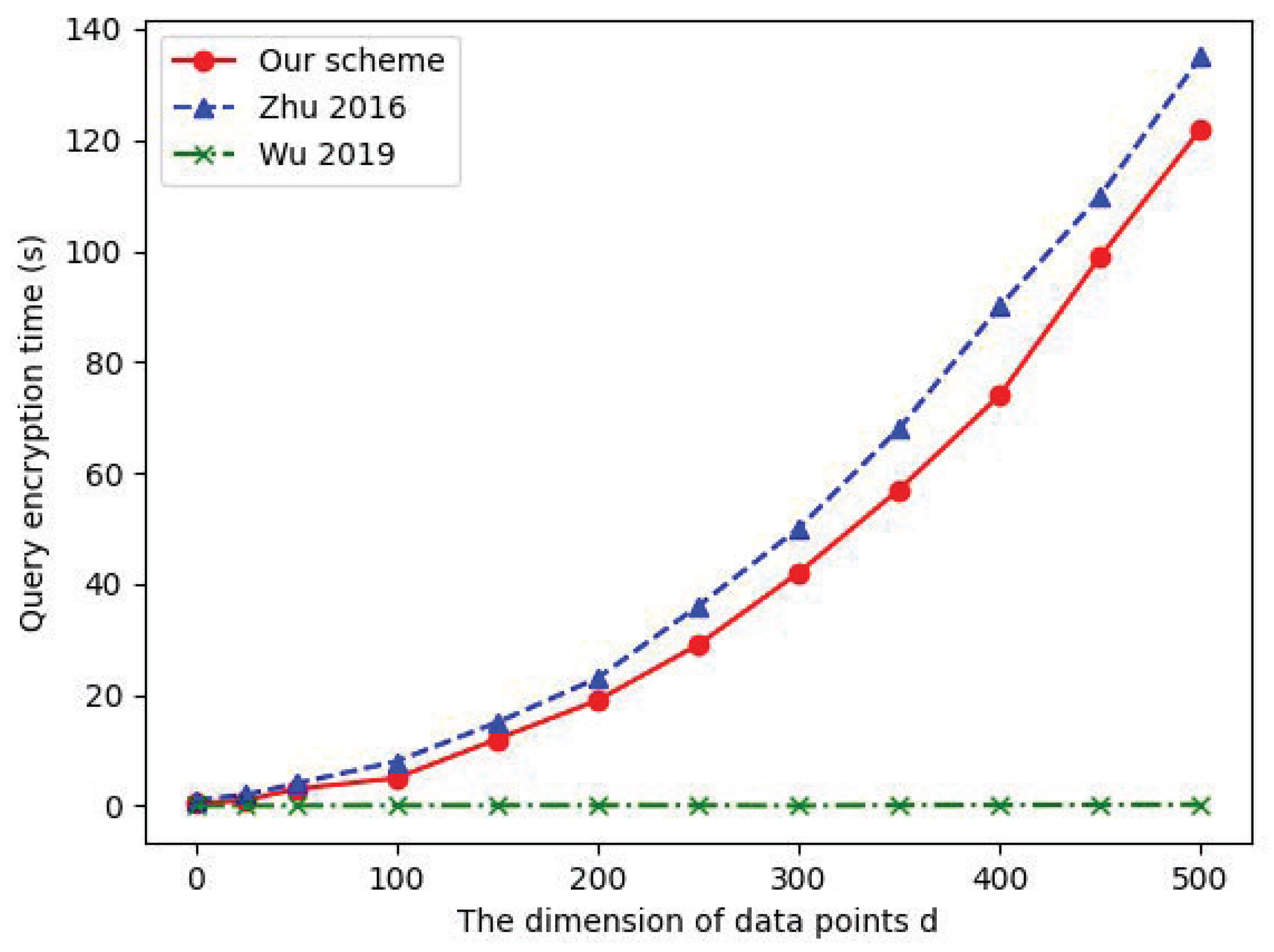
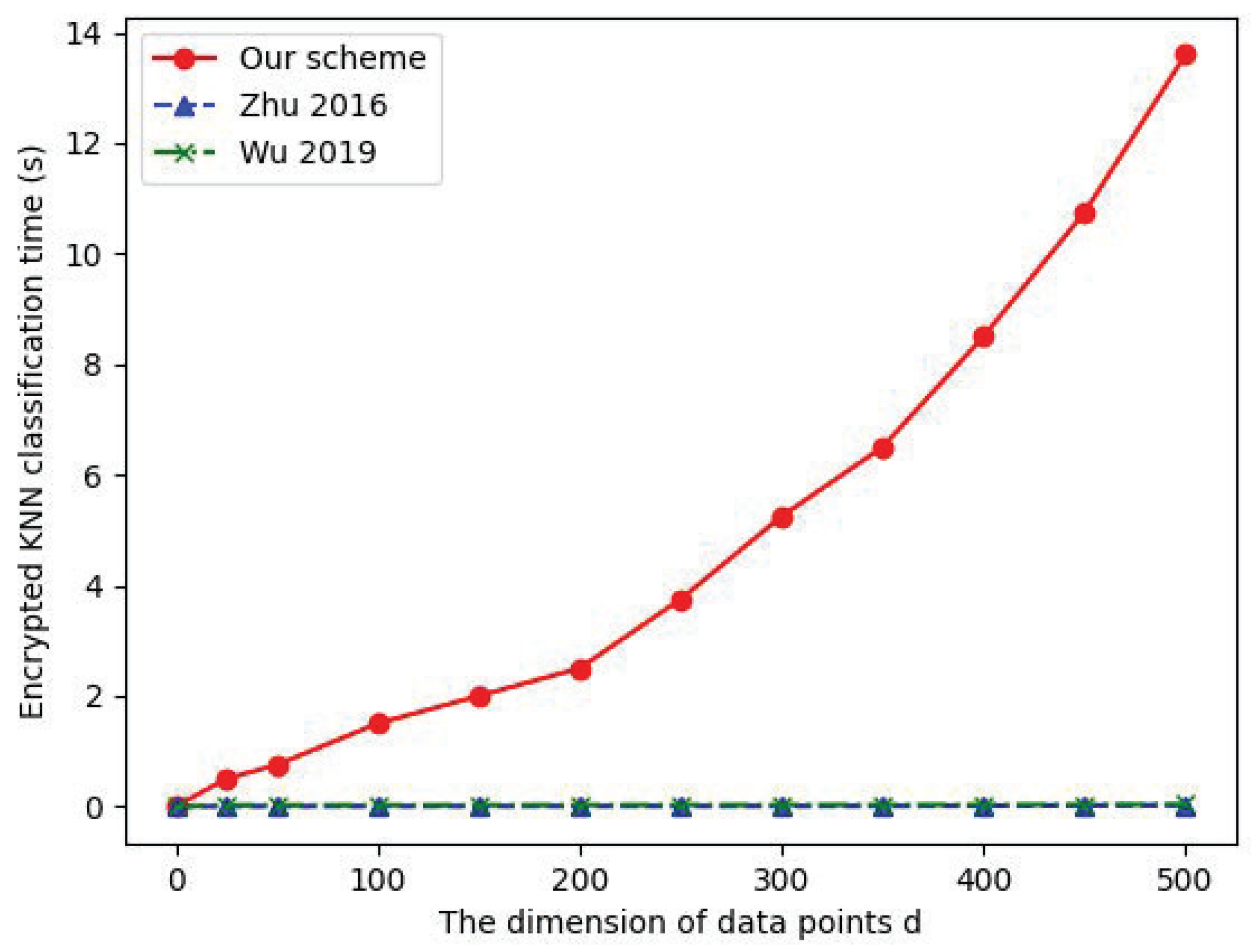
7.2. Data Query
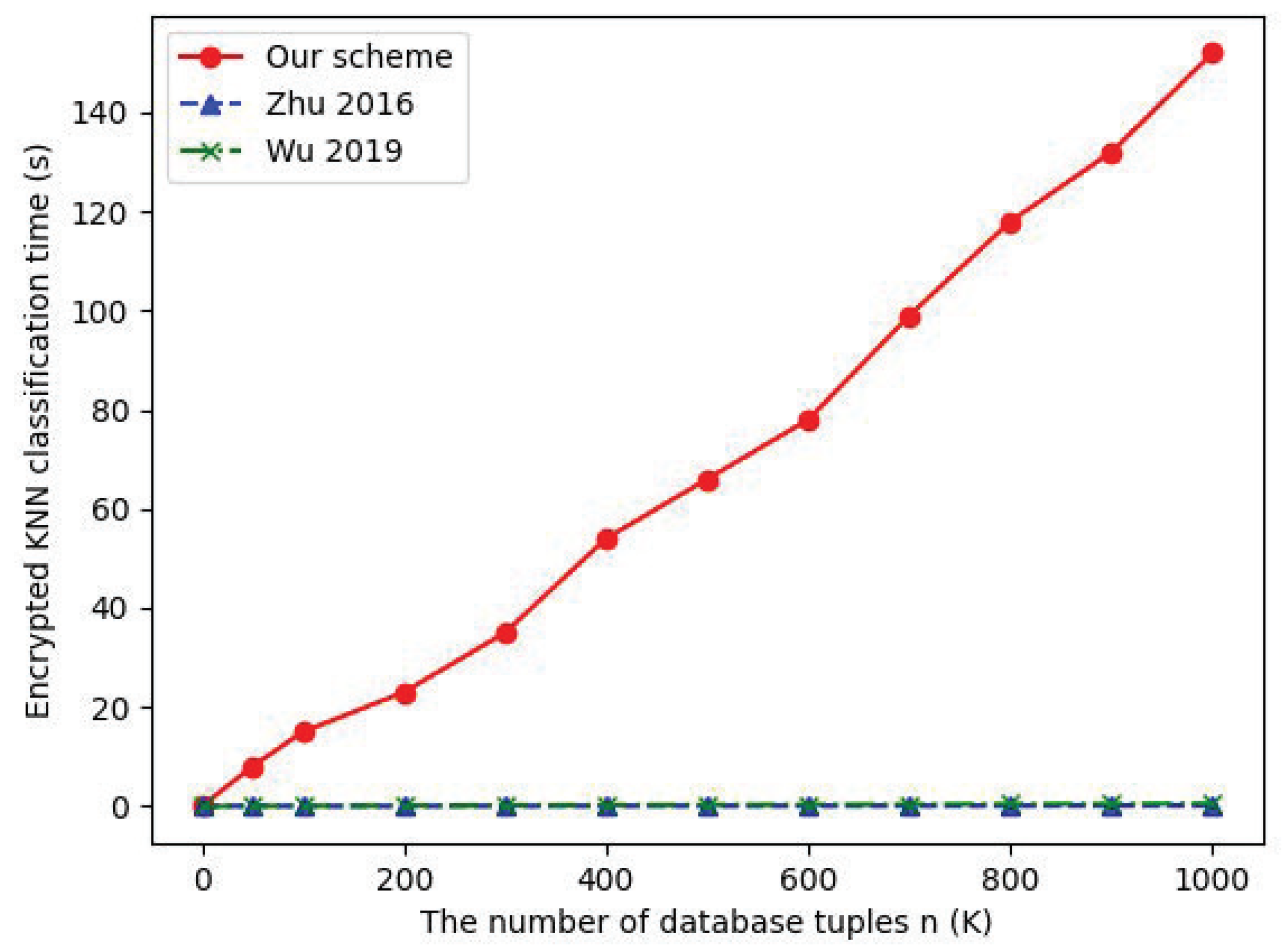
7.3. Data Interaction between Clouds
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| KNN | k-nearest neighbor |
| SHE | somewhat homomorphic encryption |
| SIMD | single-instruction multiple data |
| FOC | Fujisaki–Okamoto commitment |
| GEN | the generation algorithm |
| ENC | the encryption algorithm |
| DEC | the decryption algorithm |
| ECC | elliptic curve |
| DO | data owner |
| QU | query user |
References
- Shan, Z.; Ren, K.; Blanton, M.; Wang, C. Practical Secure Computation Outsourcing: A Survey. Acm Comput. Surv. (CSUR) 2018, 51, 1–40. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, Y.; Shen, G. PPDDS: A privacy-preserving disease diagnosis scheme based on the secure Mahalanobis distance evaluation model. IEEE Syst. J. 2021, 16, 4552–4562. [Google Scholar] [CrossRef]
- Zissis, D.; Lekkas, D. Addressing cloud computing security issues. Future Gener. Comput. Syst. 2012, 28, 583–592. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, Y.; Jiang, Y.; Shen, J. Obfuscating EVES algorithm and its application in fair electronic transactions in public clouds. IEEE Syst. J. 2019, 13, 1478–1486. [Google Scholar] [CrossRef]
- Barona, R.; Anita, E.A.M. A survey on data breach challenges in cloud computing security: Issues and threats. In Proceedings of the International Conference on Circuit, Power and Computing Technologies (ICCPCT), Bhubaneswar, India, 20–21 April 2017. [Google Scholar]
- Zhang, M.; Chen, Y.; Lin, J. A privacy-preserving optimization of neighborhood-based recommendation for medical-aided diagnosis and treatment. IEEE Internet Things J. 2021, 8, 10830–10842. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, Y.; Lin, J. Privacy-preserving cloud computing on sensitive data: A survey of methods, products and challenges. Comput. Commun. 2019, 140, 38–60. [Google Scholar]
- Zhang, M.; Chen, Y.; Lin, J. A Secure and Dynamic Multi-Keyword Ranked Search Scheme over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 340–352. [Google Scholar]
- Wang, B.; Liao, Q.; Zhang, C. Weight Based KNN Recommender System. In Proceedings of the 2013 5th International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2013. [Google Scholar]
- Barona, R.; Anita, E.A.M. Privacy-Preserving Distributed k-Means Clustering over Arbitrarily Partitioned Data; ACM SIGKDD: Chicago, IL, USA, 2005. [Google Scholar]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. 2012. Available online: https://eprint.iacr.org/2012/144 (accessed on 8 November 2023).
- Smart, N.P.; Vercauteren, F. Fully Homomorphic SIMD Operations. Des. Codes Cryptogr. 2014, 71, 57–81. [Google Scholar] [CrossRef]
- Yiu, M.L.; Assent, I.; Jensen, C.S.; Kalnis, P. Outsourced Similarity Search on Metric Data Assets. IEEE Trans. Knowl. Data Eng. 2010, 24, 338–352. [Google Scholar] [CrossRef]
- Boudot, F. Efficient proofs that a committed number lies in an interval. In Proceedings of the Advances in Cryptology—EUROCRYPT 2000, International Conference on the Theory and Application of Cryptographic Techniques, Bruges, France, 14–18 May 2000; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Barona, R.; Anita, E.A.M. An Authentication Scheme in VANETs Based on Group Signature. In Proceedings of the Intelligent Computing Theories and Application: 15th International Conference, Nanchang, China, 3–6 August 2019. [Google Scholar]
- Wong, W.K.; Cheung, D.W.; Kao, B.; Mamoulis, N. Secure kNN Computation on Encrypted Databases. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009. [Google Scholar]
- Zhou, L.; Zhu, Y.; Castiglione, A. Efficient k-NN query over encrypted data in cloud with limited key-disclosure and offline data owner. Comput. Secur. 2017, 69, 84–96. [Google Scholar] [CrossRef]
- Wu, W.; Parampalli, U.; Liu, J.; Xian, M. Privacy preserving k-nearest neighbor classification over encrypted database in outsourced cloud environments. World Wide Web 2019, 22, 101–123. [Google Scholar] [CrossRef]
- Zhu, Y.; Huang, Z.; Takagi, T. Secure and controllable k-NN query over encrypted cloud data with key confidentiality. J. Parallel Distrib. Comput. 2016, 89, 1–12. [Google Scholar] [CrossRef]
- Elmehdwi, Y.; Samanthula, B.K.; Jiang, W. Secure k-nearest neighbor query over encrypted data in outsourced environments. In Proceedings of the International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014. [Google Scholar]
- Guan, Y.; Lu, R.; Zheng, Y.; Shao, J.; Wei, G. Toward Oblivious Location-Based k-Nearest Neighbor Query in Smart Cities. IEEE Internet Things J. 2021, 8, 14219–14231. [Google Scholar] [CrossRef]
- Samanthula, B.K.; Elmehdwi, Y.; Jiang, W. Privacy-Preserving k-Nearest Neighbor Computation in Multiple Cloud Environments. IEEE Access 2016, 4, 9589–9603. [Google Scholar]
- Samanthula, B.K.; Elmehdwi, Y.; Jiang, W. k-Nearest Neighbor Classification over Semantically Secure Encrypted Relational Data. IEEE Trans. Knowl. Data Eng. 2014, 27, 1261–1273. [Google Scholar] [CrossRef]
- Cui, N.; Yang, X.; Wang, B.; Li, J.; Wang, G. SVkNN: Efficient Secure and Verifiable k-Nearest Neighbor Query on the Cloud Platform. In Proceedings of the International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020. [Google Scholar]
- Liu, Q.; Hao, Z.; Peng, Y.; Jiang, H.; Wu, J.; Peng, T.; Wang, G.; Zhang, S. SecVKQ: Secure and verifiable kNN queries in sensor–cloud systems. IEEE Trans. Knowl. Data Eng. 2021, 120, 102300. [Google Scholar] [CrossRef]
- Yang, S.; Tang, S.; Zhang, X. Privacy-preserving k nearest neighbor query with authentication on road networks. J. Parallel Distrib. Comput. 2019, 134, 25–36. [Google Scholar] [CrossRef]
- Wu, W.; Liu, J.; Rong, H.; Wang, H.; Xian, M. Efficient k-Nearest Neighbor Classification Over Semantically Secure Hybrid Encrypted Cloud Database. IEEE Access 2018, 6, 41771–41784. [Google Scholar] [CrossRef]
- Lian, H.; Qiu, W.; Yan, D.; Huang, Z.; Tang, P. Efficient and secure k-nearest neighbor query on outsourced data. Peer Netw. Appl. 2020, 13, 2324–2333. [Google Scholar] [CrossRef]
- Du, J.; Bian, F. A Privacy-Preserving and Efficient k-Nearest Neighbor Query and Classification Scheme Based on k-Dimensional Tree for Outsourced Data. IEEE Access 2020, 8, 69333–69345. [Google Scholar] [CrossRef]
- Jiang, X.; Li, L. Efficient secure and verifiable KNN set similarity search over outsourced clouds. High-Confid. Comput. 2023, 3, 100100. [Google Scholar] [CrossRef]
- Pei, X.; Li, L.; Jiang, X. Efficient privacy-preserving k-nearest neighbors in cloud computing. In Proceedings of the International Conference on Cloud Computing, Internet of Things, and Computer Applications (CICA 2022), Dubai, United Arab Emirates, 22 March 2022. [Google Scholar]
- Hsu, Y.C.; Hsueh, C.H.; Wu, J.L. A Privacy Preserving Cloud-Based K-NN Search Scheme with Lightweight User Loads. Computers 2020, 9, 1. [Google Scholar] [CrossRef]
- Zheng, Y.; Lu, R.; Guan, Y.; Shao, J.; Zhu, H. Achieving Efficient and Privacy-Preserving Exact Set Similarity Search over Encrypted Data. IEEE Trans. Dependable Secur. Comput. 2020, 19, 1090–1103. [Google Scholar] [CrossRef]
- Zuber, M.; Sirdey, R. Efficient homomorphic evaluation of k-NN classifiers. Enhancing Technol. 2021, 2021, 111–129. [Google Scholar] [CrossRef]
- Li, Z.; Tian, G.; Tan, S. Secure and Efficient k-Nearest Neighbor Query with Privacy-Preserving Authentication. In Proceedings of the International Symposium on Security and Privacy in Social Networks and Big Data, Hangzhou, China, 22 July 2022. [Google Scholar]
- Ameur, Y.; Aziz, R.; Audigier, V.; Bouzefrane, S. Secure and Non-interactive k-NN Classifier Using Symmetric Fully Homomorphic Encryption. In Proceedings of the International Conference on Privacy in Statistical Databases, Paris, France, 21 September 2022. [Google Scholar]
- Cheng, K.; Wang, L.; Shen, Y.; Wang, H.; Wang, Y.; Jiang, X.; Zhong, H. Secure k-NN Query on Encrypted Cloud Data with Multiple Keys. IEEE Trans. Big Data 2017, 7, 689–702. [Google Scholar] [CrossRef]
- Cui, N.; Qian, K.; Cai, T.; Li, J.; Yang, X.; Cui, J.; Zhong, H. Towards Multi-User, Secure, and Verifiable k-NN Query in Cloud Database. IEEE Trans. Knowl. Data Eng. 2023, 35, 9333–9349. [Google Scholar] [CrossRef]
- Naor, M. Bit Commitment Using Pseudorandomness. Des. Codes Cryptogr. 1991, 4, 151–158. [Google Scholar] [CrossRef]
- Blum, M.; Feldman, P.; Micali, S. Non-Interactive Zero-Knowledge and Its Applications. In Proceedings of the Twentieth Annual ACM Symposium on Theory of Computing, Chicago, IL, USA, 2–4 May 2019. [Google Scholar]
- Kim, J.; Koo, D.; Kim, Y.; Yoon, H.; Shin, J.; Kim, S. Efficient Privacy-Preserving Matrix Factorization for Recommendation via Fully Homomorphic Encryption. Des. Codes Cryptogr. 2014, 71, 57–81. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| ⊕ | homomorphic addition |
| ⊗ | homomorphic multiplication |
| D | data set of n labeled samples |
| d | each sample dimension in the data |
| the secret parameters | |
| random numbers selected in the cyclic group | |
| q | a private plain query point for the query user |
| user’s secret parameters | |
| random parameters | |
| a random number | |
| the user’s commitment computed | |
| the QU’s public key | |
| the QU’s private key | |
| q of the encrypted query points | |
| encrypted KNN classification label set | |
| KNN categorical tag set | |
| polynomial ring | |
| session key |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, X.; Li, Y.; Jiang, Y.; Wang, J.; Fang, J. Privacy-Preserving k-Nearest Neighbor Classification over Malicious Participants in Outsourced Cloud Environments. Cryptography 2023, 7, 59. https://doi.org/10.3390/cryptography7040059
Guo X, Li Y, Jiang Y, Wang J, Fang J. Privacy-Preserving k-Nearest Neighbor Classification over Malicious Participants in Outsourced Cloud Environments. Cryptography. 2023; 7(4):59. https://doi.org/10.3390/cryptography7040059
Chicago/Turabian StyleGuo, Xian, Ye Li, Yongbo Jiang, Jing Wang, and Junli Fang. 2023. "Privacy-Preserving k-Nearest Neighbor Classification over Malicious Participants in Outsourced Cloud Environments" Cryptography 7, no. 4: 59. https://doi.org/10.3390/cryptography7040059