
Benchmark Analysis of YOLO Performance on Edge Intelligence Devices



Abstract
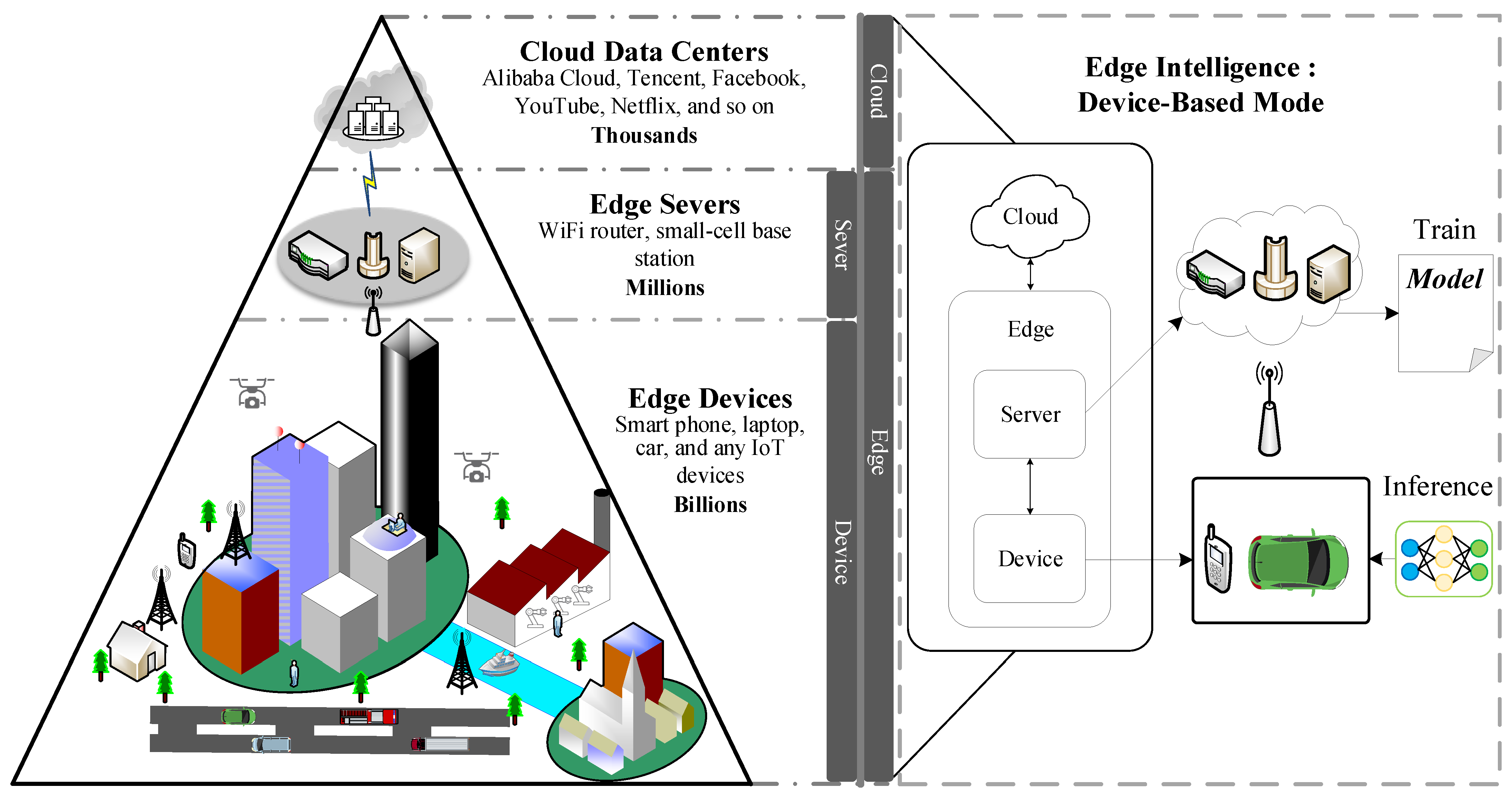
:1. Introduction
2. Related Work
3. Backgrounds and Methodology
3.1. YOLO Networks
3.2. Hardware Platforms
3.2.1. Jetson Nano and Jetson Xavier NX
3.2.2. Intel Neural Compute Stick2
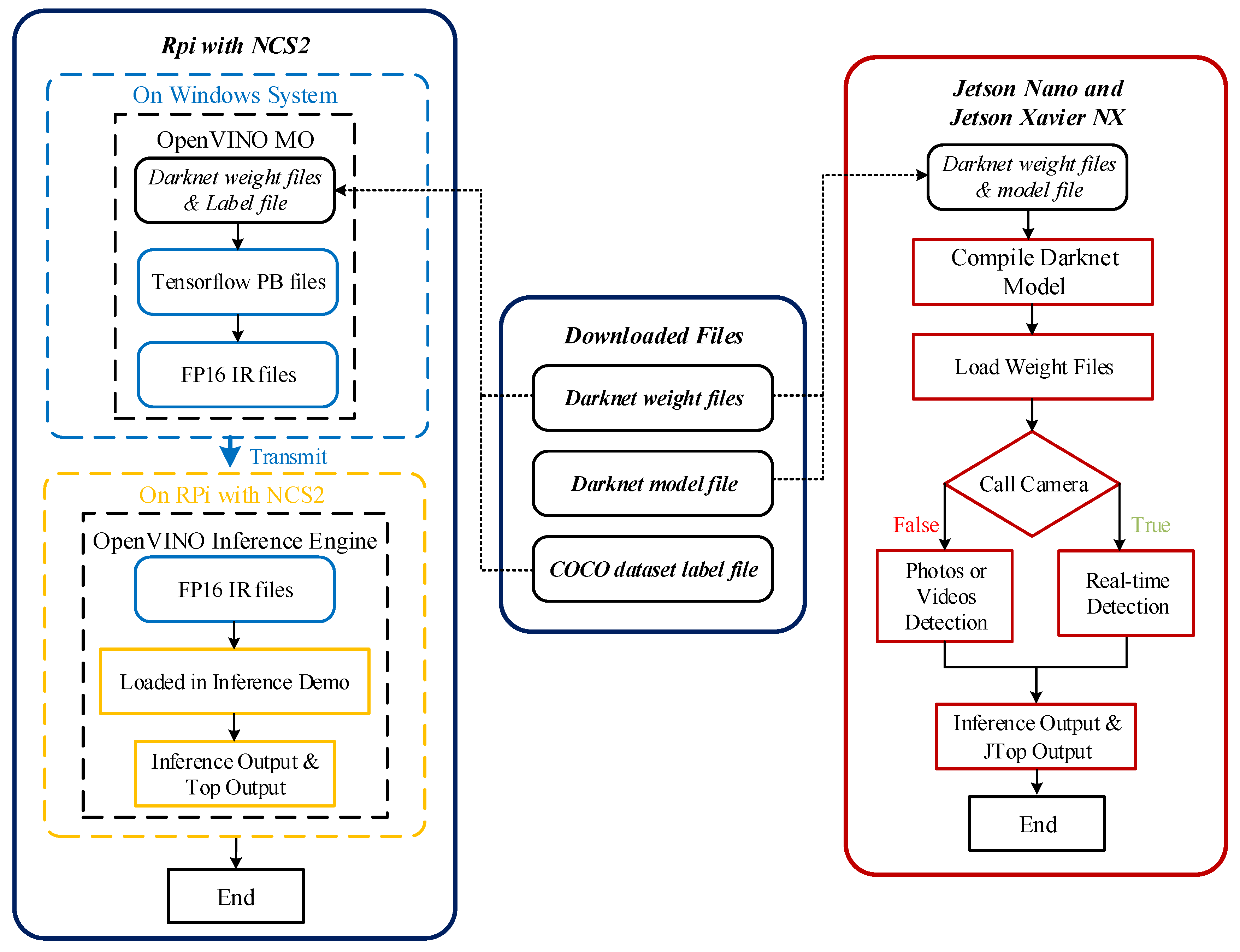
3.3. Compilation Workflow
3.3.1. Jetson Nano and Jetson Xavier NX
3.3.2. RPi and Intel Neural Compute Stick2
4. Benchmark Results and Analysis
4.1. Benchmarking Jetson Nano, Jetson Xavier NX and RPi with Intel Neural Compute Stick2
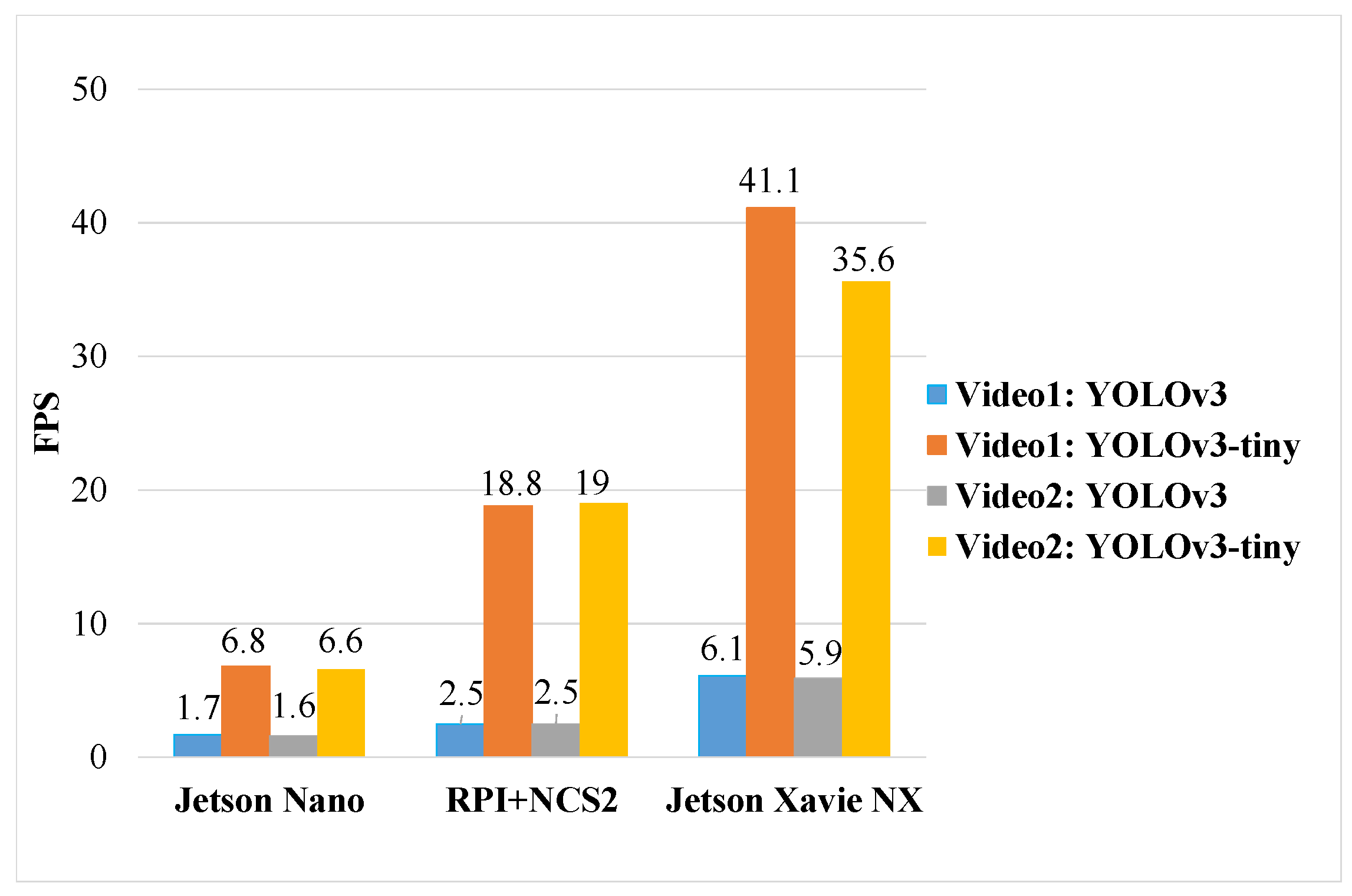
4.1.1. Inference Performance
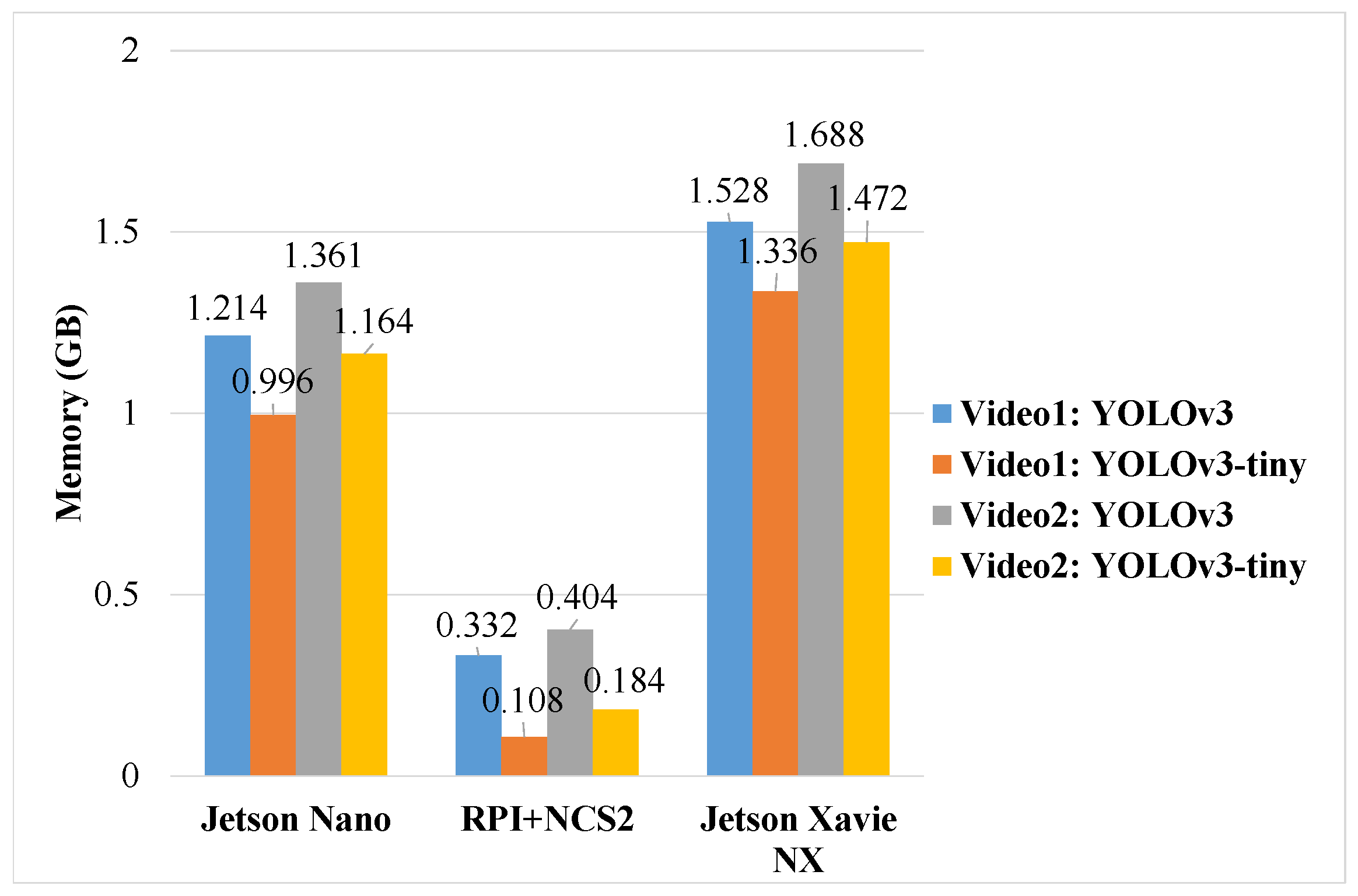
4.1.2. Memory Usage
4.1.3. Energy Consumption
4.2. Performance Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| SBCs | Single-board computers |
| AI | artificial intelligence |
| IoT | Internet of things |
| 5G | 5th Generation mobile networks |
| eMBB | enhanced mobile broadband |
| uRLLC | ultra reliable low latency communications |
| mMTC | Massive Machine Type Communication |
| EI | Edge Intelligence |
| ASIC | Application Specific Integrated Circuit |
| FPGA | Field Programmable Gate Array |
| NCS2 | Neural Compute Stick2 |
| UAV | Unmanned Aerial Vehicle |
| RPi | Raspberry Pi |
| YOLO | You Only Look Once |
| SoC | System on Chip |
| IR | Intermediate Representation |
| FP16 | Half-Precision |
| FP32 | Sigle-Precision |
| PB | Protocol Buffer |
| MO | Model Optimizer |
| API | Application Programming Interface |
| FPS | Frames-Per-Second |
References
- Redana, S.; Bulakci, O.; Mannweiler, C.; Gallo, L.; Kousaridas, A.; Navratil, D.; Tzanakaki, A.; Gutiwrrez, J.; Karl, H.; Hasselmeyer, P.; et al. 5G PPP Architecture Working Group—View on 5G Architecture, Version 3.0. 2019. Available online: https://zenodo.org/record/3265031#.Yj1fbDURXIU (accessed on 9 August 2021).
- Pokhrel, S.R.; Ding, J.; Park, J.; Park, O.S.; Choi, J. Towards Enabling Critical mMTC: A Review of URLLC within mMTC. IEEE Access 2020, 8, 131796–131813. [Google Scholar] [CrossRef]
- Ericsson. IoT Connections Outlook: In 2026, NB-IoT and Cat-M Technologies Are Expected to Make Up 45 percent of All Cellular IoT Connections. Available online: https://www.ericsson.com/en/mobility-report/dataforecasts/iot-connections-outlook (accessed on 9 August 2021).
- Khan, L.U.; Yaqoob, I.; Tran, N.H.; Kazmi, S.M.A.; Dang, T.N.; Hong, C.S. Edge-Computing-Enabled Smart Cities: A Comprehensive Survey. IEEE Internet Things J. 2020, 7, 10200–10232. [Google Scholar] [CrossRef] [Green Version]
- Artunedo Guillen, D.; Sayadi, B.; Bisson, P.; Wary, J.P.; Lonsethagen, H.; Anton, C.; de la Oliva, A.; Kaloxylos, A.; Frascolla, V. Edge Computing for 5G Networks—White Paper. 2020. Available online: https://zenodo.org/record/3698117#.Yj1fpDURXIU (accessed on 9 August 2021).
- Naouri, A.; Wu, H.; Nouri, N.A.; Dhelim, S.; Ning, H. A Novel Framework for Mobile-Edge Computing by Optimizing Task Offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, M.; Wang, X.; Ma, X.; Liu, J. Deep Learning for Edge Computing Applications: A State-of-the-Art Survey. IEEE Access 2020, 8, 58322–58336. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge Intelligence: Paving the Last Mile of Artificial Intelligence With Edge Computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of Edge Computing and Deep Learning: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef] [Green Version]
- Mittal, S. A Survey on optimized implementation of deep learning models on the NVIDIA Jetson platform. J. Syst. Archit. 2019, 97, 428–442. [Google Scholar] [CrossRef]
- Kang, P.; Lim, S. A Taste of Scientific Computing on the GPU-Accelerated Edge Device. IEEE Access 2020, 8, 208337–208347. [Google Scholar] [CrossRef]
- Mittal, S.; Vaishay, S. A survey of techniques for optimizing deep learning on GPUs. J. Syst. Archit. 2019, 99, 101635. [Google Scholar] [CrossRef]
- Park, J.; Samarakoon, S.; Bennis, M.; Debbah, M. Wireless Network Intelligence at the Edge. Proc. IEEE 2019, 107, 2204–2239. [Google Scholar] [CrossRef] [Green Version]
- Nair, D.; Pakdaman, A.; Plöger, P. Performance Evaluation of Low-Cost Machine Vision Cameras for Image-Based Grasp Verification. arXiv 2020, arXiv:2003.10167. [Google Scholar]
- Intel. Intel® Movidius™ Myriad™ X VPUs. Available online: https://www.intel.com/content/www/us/en/artificialintelligence/movidius-myriad-vpus.html (accessed on 9 August 2021).
- LLC, G. Coral Dev Board Datasheet Version 1.3. Available online: https://coral.ai/static/files/Coral-DevBoard-datasheet.pdf (accessed on 9 August 2021).
- Torres-Sánchez, E.; Alastruey-Benedé, J.; Torres-Moreno, E. Developing an AI IoT application with open software on a RISC-V SoC. In Proceedings of the 2020 XXXV Conference on Design of Circuits and Integrated Systems (DCIS), Segovia, Spain, 18–20 November 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Attaran, N.; Puranik, A.; Brooks, J.; Mohsenin, T. Embedded Low-Power Processor for Personalized Stress Detection. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 2032–2036. [Google Scholar] [CrossRef]
- Basulto-Lantsova, A.; Padilla-Medina, J.A.; Perez-Pinal, F.J.; Barranco-Gutierrez, A.I. Performance comparative of OpenCV Template Matching method on Jetson TX2 and Jetson Nano developer kits. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 0812–0816. [Google Scholar] [CrossRef]
- Jo, J.; Jeong, S.; Kang, P. Benchmarking GPU-Accelerated Edge Devices. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Korea, 19–22 February 2020; pp. 117–120. [Google Scholar] [CrossRef]
- Suzen, A.A.; Duman, B.; Sen, B. Benchmark Analysis of Jetson TX2, Jetson Nano and Raspberry PI using Deep-CNN. In Proceedings of the 2020 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 26–27 June 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Aleksandrova, O.; Bashkov, Y. Face recognition systems based on Neural Compute Stick 2, CPU, GPU comparison. In Proceedings of the 2020 IEEE 2nd International Conference on Advanced Trends in Information Theory (ATIT), Kyiv, Ukraine, 25–27 November 2020; pp. 104–107. [Google Scholar] [CrossRef]
- Antonini, M.; Vu, T.H.; Min, C.; Montanari, A.; Mathur, A.; Kawsar, F. Resource Characterisation of Personal-Scale Sensing Models on Edge Accelerators. In Proceedings of the First International Workshop on Challenges in Artificial Intelligence and Machine Learning for Internet of Things (AIChallengeIoT’19), Harbin, China, 25–26 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 49–55. [Google Scholar] [CrossRef]
- Sahu, P.; Yu, D.; Qin, H. Apply lightweight deep learning on internet of things for low-cost and easy-to-access skin cancer detection. In Medical Imaging 2018: Imaging Informatics for Healthcare, Research, and Applications; Zhang, J., Chen, P.H., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, DC, USA, 2018; Volume 10579, pp. 254–262. [Google Scholar] [CrossRef]
- Srinivasan, V.; Meudt, S.; Schwenker, F. Deep Learning Algorithms for Emotion Recognition on Low Power Single Board Computers. In Multimodal Pattern Recognition of Social Signals in Human-Computer-Interaction; Schwenker, F., Scherer, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 59–70. [Google Scholar]
- Jung, T.H.; Cates, B.; Choi, I.K.; Lee, S.H.; Choi, J.M. Multi-Camera-Based Person Recognition System for Autonomous Tractors. Designs 2020, 4, 54. [Google Scholar] [CrossRef]
- Zheng, Y.Y.; Kong, J.L.; Jin, X.B.; Wang, X.Y.; Su, T.L.; Zuo, M. CropDeep: The Crop Vision Dataset for Deep-Learning-Based Classification and Detection in Precision Agriculture. Sensors 2019, 19, 1058. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Horng, G.J.; Liu, M.X.; Chen, C.C. The Smart Image Recognition Mechanism for Crop Harvesting System in Intelligent Agriculture. IEEE Sens. J. 2020, 20, 2766–2781. [Google Scholar] [CrossRef]
- Ferdowsi, A.; Challita, U.; Saad, W. Deep Learning for Reliable Mobile Edge Analytics in Intelligent Transportation Systems: An Overview. IEEE Veh. Technol. Mag. 2019, 14, 62–70. [Google Scholar] [CrossRef]
- Arabi, S.; Haghighat, A.; Sharma, A. A deep-learning-based computer vision solution for construction vehicle detection. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 753–767. [Google Scholar] [CrossRef]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The ApolloScape Open Dataset for Autonomous Driving and Its Application. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2702–2719. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge Intelligence: The Confluence of Edge Computing and Artificial Intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar] [CrossRef] [Green Version]
- Li, E.; Zhou, Z.; Chen, X. Edge Intelligence: On-Demand Deep Learning Model Co-Inference with Device-Edge Synergy. In Proceedings of the 2018 Workshop on Mobile Edge Communications (MECOMM’18), Budapest, Hungary, 20 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 31–36. [Google Scholar] [CrossRef]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar] [CrossRef]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar] [CrossRef] [Green Version]
- NVIDIA Jetson Nano. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-nano (accessed on 9 August 2021).
- NVIDIA Jetson Xavier NX. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-xavier-nx/ (accessed on 9 August 2021).
- Neural Compute Stick 2 Documentation. Available online: https://software.intel.com/content/www/us/en/develop/articles/get-started-with-neural-compute-stick.html (accessed on 9 August 2021).
- AlexeyAB. Darknet. Available online: https://github.com/AlexeyAB/darknet#pre-trained-models (accessed on 9 August 2021).
- COCO. Common Objects in Context. Available online: https://cocodataset.org (accessed on 9 August 2021).
- Intel. Intel Distribution of OpenVINO Toolkit. Available online: https://docs.openvinotoolkit.org (accessed on 9 August 2021).
- Lun, W. Sample Videos. Available online: https://gitee.com/ve2102388688/sample-videos/tree/master (accessed on 9 August 2021).
- Jing, Y.; Wu, T.; Li, J.; Zhang, Z.; Gao, C. GPU acceleration design method for driver’s seatbelt detection. In Proceedings of the 2019 14th IEEE International Conference on Electronic Measurement Instruments (ICEMI), Changsha, China, 1–3 November 2019; pp. 949–953. [Google Scholar] [CrossRef]
- Han, B.G.; Lee, J.G.; Lim, K.T.; Choi, D.H. Design of a Scalable and Fast YOLO for Edge-Computing Devices. Sensors 2020, 20, 6779. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
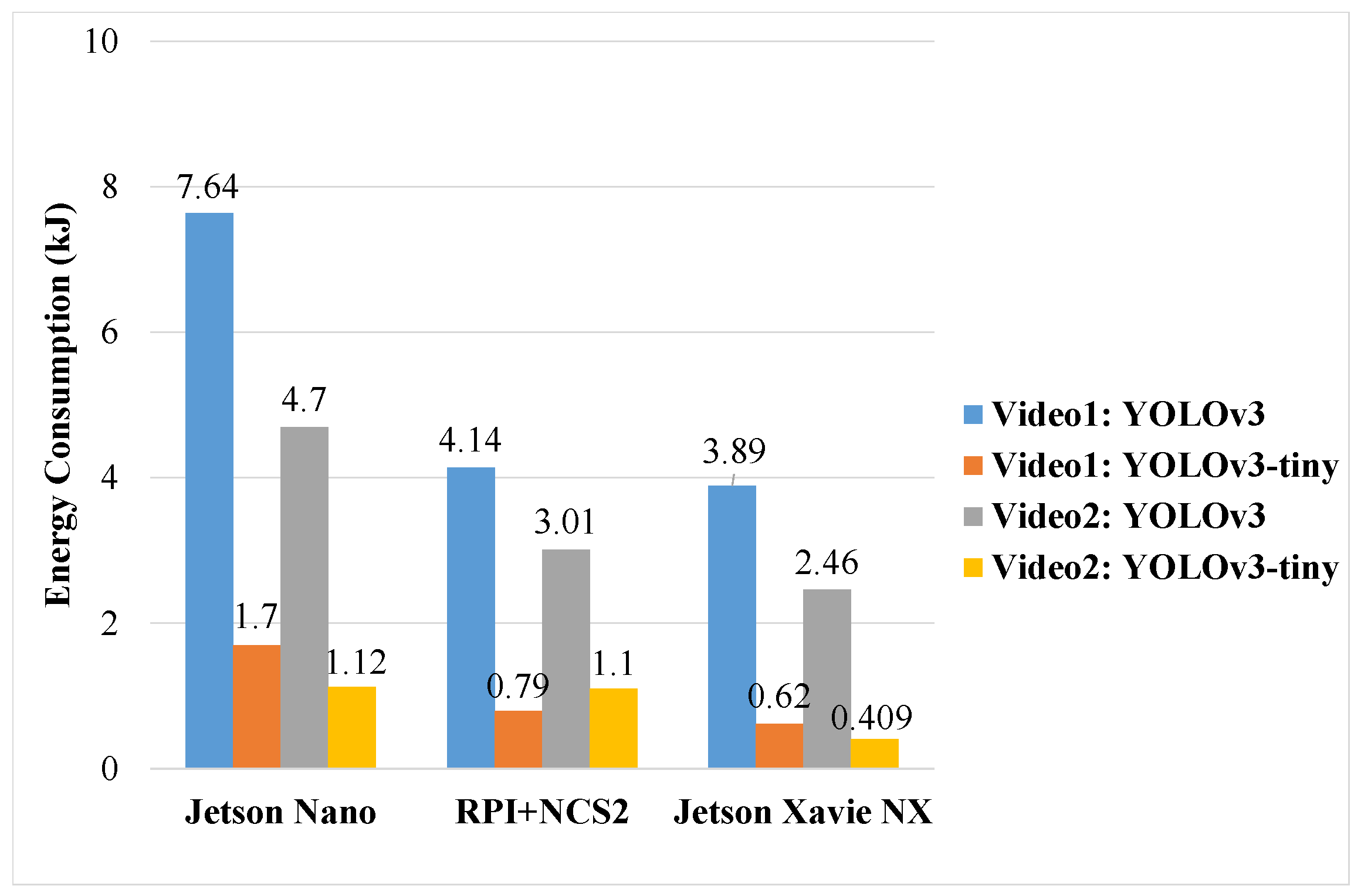{kind=link}
{kind=link}
| YOLO | Total Layers of Backbone |
|---|---|
| YOLOv3 | 106 |
| YOLOv3-tiny | 24 |
| YOLOv4 | 161 |
| YOLOv4-tiny | 38 |
| NVIDIA Jetson Nano | NVIDIA Jetson Xavier NX | Raspberry 4B + Intel NCS2 | |
|---|---|---|---|
| Edge Accelerator | 128-core NVIDIA Maxwell GPU | 384-core NVIDIA Volta GPU with 48 Tensor Cores | Intel Movidius Myriad X VPU |
| AI Performance | 0.5 TFLOPs | 1.3 TFLOPs | 1 TFLOPs |
| CPU | Quad-core ARM Cortex-A57 MPCore processor | 6-core NVIDIA Carmel ARM v8.2 64-bit CPU 6 MB L2 + 4 MB L3 | Quad-core ARM Cortex-A72 |
| Memory | 4 GB 64-bit LPDDR4 25.6 GB/s | 8 GB 128-bit LPDDR4x 51.2 GB/s | 4 GB LPDDR4 |
| Edge Accelerator Interface | PCIe | PCIe | USB 3.0 |
| Dimensions | 69.6 mm × 45 mm | 69.6 mm × 45 mm | 85 mm × 56 mm +72.5 mm × 27 mm |
| Nominal Power Envelope | 5 W–10 W | 10 W–15 W | 3 W–6.25 W +1 W |
| Price | USD 89 | USD 399 | USD 55 + USD 69 |
| Models | Accelerator -Based SBCs | Mean Confidence (%) | FPS | CPU Usage (%) | Memory Usage (GB) | Power (W) | Time (s) | |
|---|---|---|---|---|---|---|---|---|
| Video1 | YOLOv3 | RPi + NCS2 | 99.3 | 2.5 | 4.3 | 0.33 | 6.0 | 690 |
| Nano | 99.7 | 1.7 | 26.5 | 1.21 | 7.9 | 967 | ||
| NX | 99.7 | 6.1 | 22.5 | 1.51 | 15.2 | 256 | ||
| YOLOv3-tiny | RPi + NCS2 | 0 | 18.8 | 15.5 | 0.11 | 6.5 | 121 | |
| Nano | 59.7 | 6.8 | 28.8 | 1.00 | 7.2 | 236 | ||
| NX | 59.7 | 41.1 | 30.5 | 1.33 | 13.5 | 46 | ||
| Video2 | YOLOv3 | RPi + NCS2 | 85.8 | 2.5 | 9.8 | 0.41 | 6.2 | 496 |
| Nano | 71.5 | 1.6 | 28.8 | 1.36 | 8.0 | 587 | ||
| NX | 71.5 | 5.9 | 26.8 | 1.69 | 15.2 | 162 | ||
| YOLOv3-tiny | RPi + NCS2 | 61.5 | 19.0 | 24.8 | 0.18 | 6.8 | 162 | |
| Nano | 54.1 | 6.6 | 37.3 | 1.16 | 7.4 | 152 | ||
| NX | 54.1 | 35.6 | 55.5 | 1.47 | 13.2 | 31 |
| Accelerator-Based SBC | Idle Total | Idle CPU | Idle GPU/NCS2 |
|---|---|---|---|
| RPi + NCS2 | 3.16 | - | 0.64 |
| Jetson Nano | 2.60 | 0.4 | 0.04 |
| Jetson Xavier | 3.15 | 0.7 | 0.08 |
| Models | S Value | FPS | CPU Usage (%) | Memory Usage (GB) | GPU Power (W) | Energy Consumption (kJ) | |
|---|---|---|---|---|---|---|---|
| Video1 | YOLOv3 | 320 | 2.4 | 26.8 | 0.86 | 3.7 | 5.43 |
| 608 | 0.9 | 25.5 | 1.19 | 3.9 | 16.01 | ||
| YOLOv3-tiny | 320 | 10.3 | 30.5 | 1.00 | 3.7 | 1.18 | |
| 608 | 3.3 | 27.0 | 1.01 | 3.9 | 3.00 | ||
| Video2 | YOLOv3 | 320 | 2.5 | 30.8 | 1.31 | 3.3 | 3.26 |
| 608 | 0.8 | 26.8 | 1.31 | 3.4 | 9.72 | ||
| YOLOv3-tiny | 320 | 9.9 | 41.3 | 1.13 | 3.3 | 0.77 | |
| 608 | 3.3 | 31.8 | 1.13 | 3.4 | 2.18 |
| Models | Mean Confidence (%) | FPS | CPU Usage (%) | Memory Usage (GB) | GPU Power (W) | Energy Consumption (kJ) | |
|---|---|---|---|---|---|---|---|
| Video1 | YOLOv4 | 94.2 | 1.6 | 26.8 | 1.22 | 4.0 | 7.92 |
| YOLOv4-tiny | 67.1 | 15.0 | 34.3 | 0.98 | 3.9 | 0.86 | |
| Video2 | YOLOv4 | 75.6 | 1.6 | 29.5 | 1.36 | 3.5 | 3.78 |
| YOLOv4-tiny | 61.9 | 14.2 | 54.5 | 1.10 | 3.4 | 0.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, H.; Mu, G.; Zhong, S.; Zhang, P.; Yuan, T. Benchmark Analysis of YOLO Performance on Edge Intelligence Devices. Cryptography 2022, 6, 16. https://doi.org/10.3390/cryptography6020016
Feng H, Mu G, Zhong S, Zhang P, Yuan T. Benchmark Analysis of YOLO Performance on Edge Intelligence Devices. Cryptography. 2022; 6(2):16. https://doi.org/10.3390/cryptography6020016
Chicago/Turabian StyleFeng, Haogang, Gaoze Mu, Shida Zhong, Peichang Zhang, and Tao Yuan. 2022. "Benchmark Analysis of YOLO Performance on Edge Intelligence Devices" Cryptography 6, no. 2: 16. https://doi.org/10.3390/cryptography6020016