
A Deep-Learning Approach to Driver Drowsiness Detection

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Related Work
3. Data Acquisition and Preprocessing
3.1. Dataset Description
3.2. Dataset Pre-Processing
4. Proposed Model Development and Training
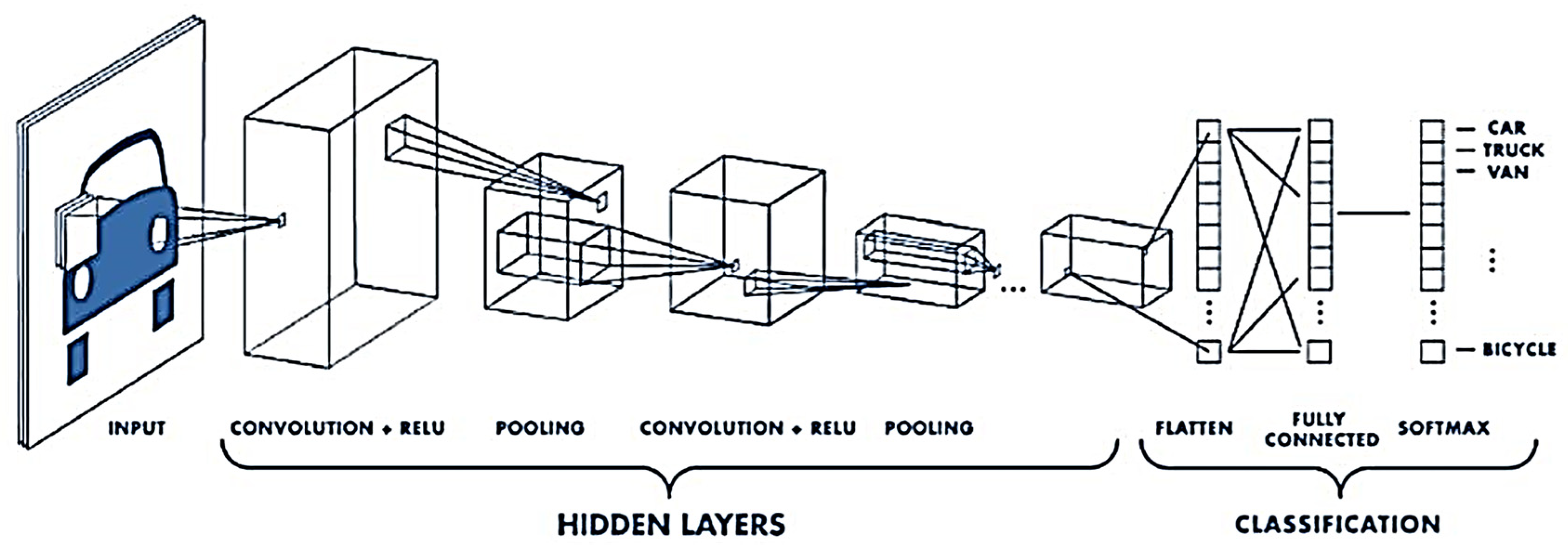
4.1. Model Description
4.1.1. Conv2D Layer
4.1.2. MaxPooling2D Layer
4.1.3. Flatten Layer
4.1.4. Dropout Layer
4.1.5. Dense Layer
4.2. Model Development
4.2.1. Haar Cascade Classifier
4.2.2. CNN Model
4.2.3. VGG16 Model
4.3. Model Training
4.3.1. Optimization Techniques
4.3.2. Regularization Techniques
5. Proposed Model Evaluation
5.1. Evaluation Metrics
- Accuracy: The result of dividing the number of true classified outcomes by the whole of classified instances. The accuracy is computed using the equation:
- Recall: The percentage of positive tweets that are properly determined using the model in the dataset. The recall is calculated using
- Precision: The proportion of true positive tweets among all forecasted positive tweets. The equation of precision measure is calculated using the following:
- F1-score: A harmonic mean of precision and recall. The F-score measure equation is
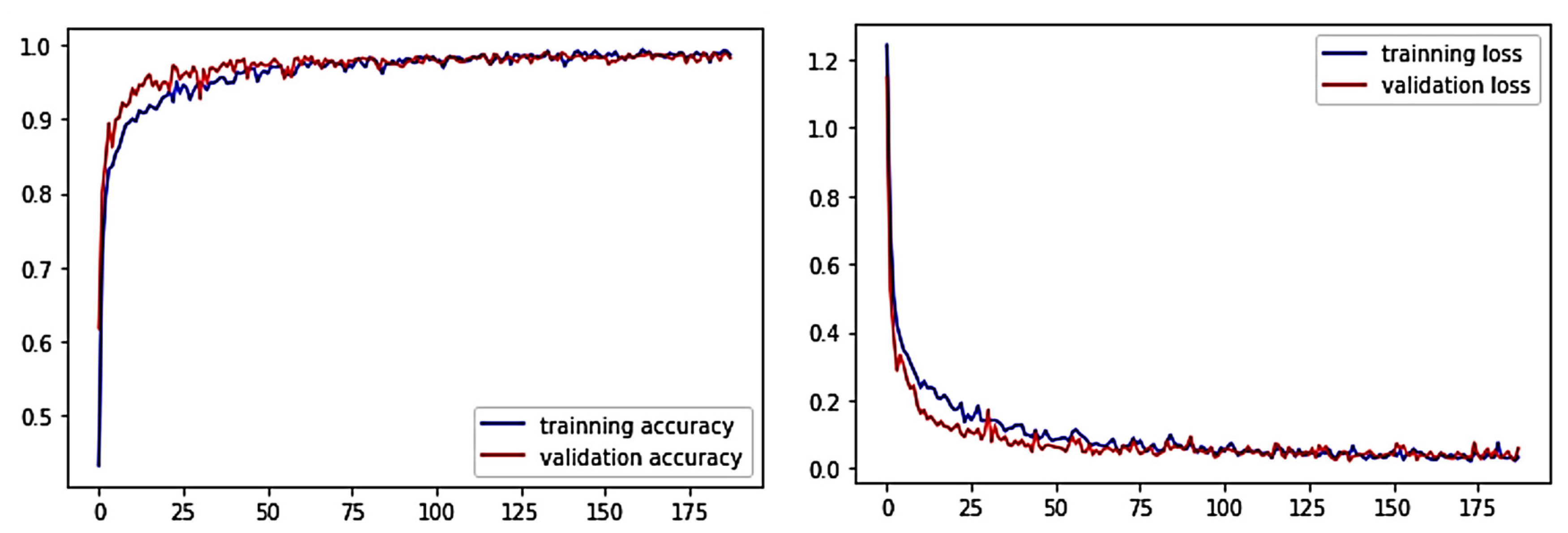
5.1.1. CNN Model Evaluation
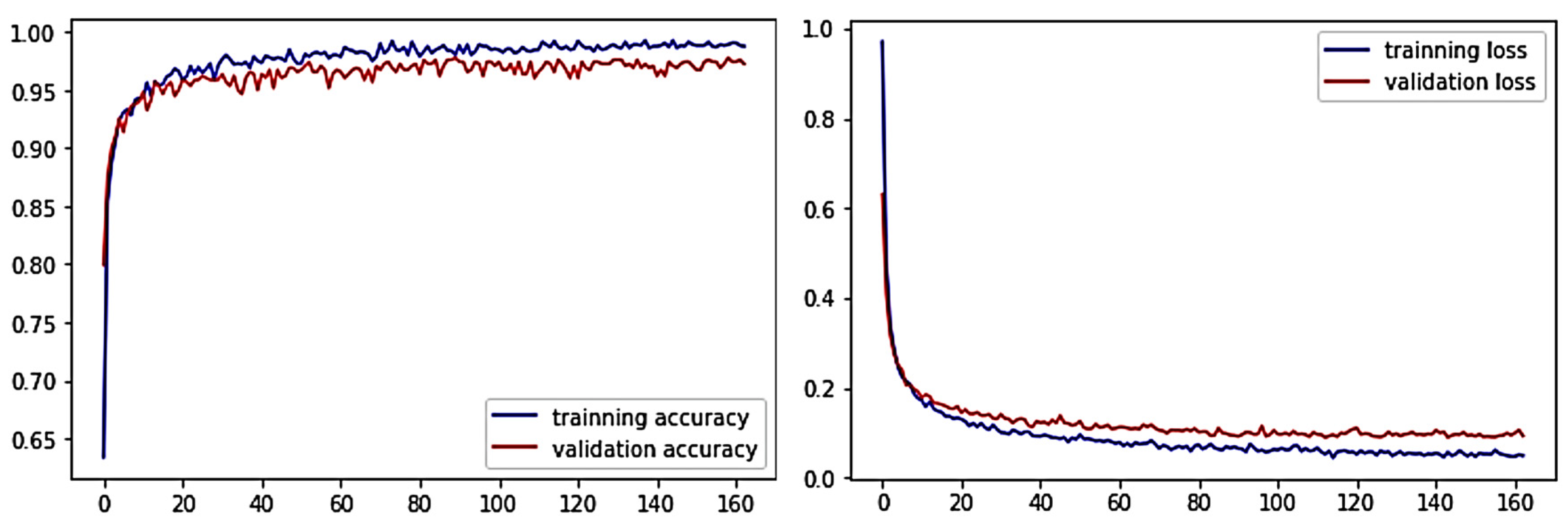
5.1.2. VGG16 Model Evaluation
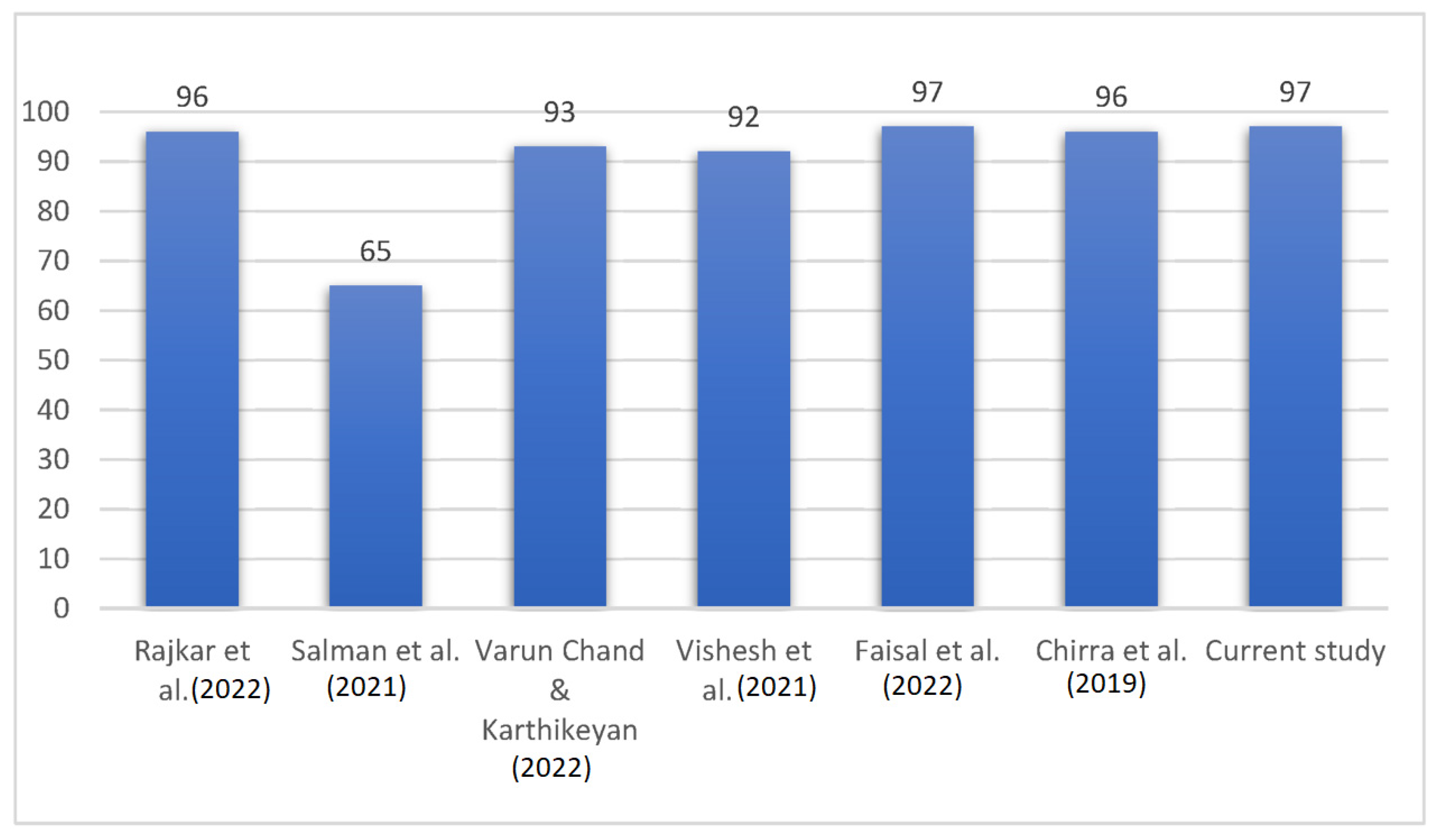
5.1.3. Comparative Analysis
5.1.4. Statistical Analysis
5.1.5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, M.A.A.; Alsawwaf, M.; Arab, B.; Alhashim, M.; Almashharawi, F.; Hakami, O.; Olatunji, S.O.; Farooqui, M.; Rahman, A. Road Damages Detection and Classification Using Deep Learning and UAVs. In Proceedings of the Asian Conference on Innovation in Technology (ASIANCON), Ravet, India, 26–28 August 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Jamal, A.; Rahman, M.T.; Al-Ahmadi, H.M.; Mansoor, U. The Dilemma of Road Safety in the Eastern Province of Saudi Arabia: Consequences and Prevention Strategies. Int. J. Environ. Res. Public Health 2020, 17, 157. [Google Scholar] [CrossRef] [PubMed]
- Tavakoli Kashani, A.; Rakhshani Moghadam, M.; Amirifar, S. Factors affecting driver injury severity in fatigue and drowsiness accidents: A data mining framework. J. Inj. Violence Res. 2022, 14, 75–88. [Google Scholar] [CrossRef] [PubMed]
- Tefft, B.C. Prevalence of Motor Vehicle Crashes Involving Drowsy Drivers, United States 2009–2013. AAA Foundation for Traffic Safety. Available online: https://aaafoundation.org/prevalence-motor-vehicle-crashes-involving-drowsy-drivers-united-states-2009-2013 (accessed on 14 June 2018).
- Azam, K.; Shakoor, A.; Shah, R.A.; Khan, A.; Shah, S.A.; Khalil, M.S. Comparison of fatigue related road traffic crashes on the national highways and motorways in Pakistan. J. Eng. Appl. Sci. 2014, 33, 47–54. [Google Scholar]
- Chirra, V.R.R.; Uyyala, S.R.; Kolli, V.K.K. Deep CNN: A Machine Learning Approach for Driver Drowsiness Detection Based on Eye State. Rev. D’Intell. Artif. 2019, 33, 461–466. [Google Scholar] [CrossRef]
- Rajkar, A.; Kulkarni, N.; Raut, A. Driver drowsiness detection using deep learning. In Applied Information Processing Systems, Proceedings of ICCET 2021, Lonere, India, 30–31 January 2021; Springer: Singapore, 2022; pp. 73–82. [Google Scholar]
- Salman, R.M.; Rashid, M.; Roy, R.; Ahsan, M.M.; Siddique, Z. Driver drowsiness detection using ensemble convolutional neural networks on YawDD. arXiv 2021, arXiv:2112.10298. [Google Scholar]
- Magán, E.; Sesmero, M.P.; Alonso-Weber, J.M.; Sanchis, A. Driver drowsiness detection by applying deep learning techniques to sequences of images. Appl. Sci. 2022, 12, 1145. [Google Scholar] [CrossRef]
- Florez, R.; Palomino-Quispe, F.; Coaquira-Castillo, R.J.; Herrera-Levano, J.C.; Paixão, T.; Alvarez, A.B. A CNN-Based Approach for Driver Drowsiness Detection by Real-Time Eye State Identification. Appl. Sci. 2023, 13, 7849. [Google Scholar] [CrossRef]
- Utaminingrum, F.; Praetya, R.P.; Sari, Y.A. Image Processing for Rapidly Eye Detection based on Robust Haar Sliding Window. Int. J. Electr. Comput. Eng. 2017, 7, 823–830. [Google Scholar] [CrossRef]
- Budiyanto, A.; Manan, A.; Wahyuni, E.S. Eye Detection System Based on Image Processing for Vehicle Safety. Techné J. Ilm. Elektroteknika 2020, 19, 11–22. [Google Scholar] [CrossRef]
- Li, K.; Gong, Y.; Ren, Z. A Fatigue Driving Detection Algorithm Based on Facial Multi-Feature Fusion. IEEE Access 2020, 8, 101244–101259. [Google Scholar] [CrossRef]
- Wider Face: A Face Detection Benchmark. Available online: http://shuoyang1213.me/WIDERFACE/ (accessed on 10 April 2023).
- Rodzi, A.H.; Zin, Z.M.; Ibrahim, N. Vision based Eye Closeness Classification for Driver’s Distraction and Drowsiness Using PERCLOS and Support Vector Machines: Comparative Study between RGB and Grayscale Images. J. Phys. Conf. Ser. 2019, 1235, 012036. [Google Scholar] [CrossRef]
- Jose, J.; Vimali, J.S.; Ajitha, P.; Gowri, S.; Sivasangari, A.; Jinila, B. Drowsiness Detection System for Drivers Using Image Processing Technique. In Proceedings of the 2021 5th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 3–5 June 2021; pp. 1527–1530. [Google Scholar] [CrossRef]
- Dogiwal, S.R.; Sharma, V. Driver Fatigue Detection Analysis Based on Image Segmentation & Feature Extraction Using SVM. SKIT Res. J. 2020, 10, 1–5. [Google Scholar]
- Kholerdi, H.A.; TaheriNejad, N.; Ghaderi, R.; Baleghi, Y. Driver’s drowsiness detection using an enhanced image processing technique inspired by the human visual system. Connect. Sci. 2016, 28, 27–46. [Google Scholar] [CrossRef]
- Naseem, M.T.; Qureshi, I.M.; Rahman, A.; Muzaffar, M.Z. Robust and Fragile Watermarking for Medical Images using Redundant Residue Number System and Chaos. Neural Netw. World 2020, 30, 177–192. [Google Scholar] [CrossRef]
- Singh, G. Real Time Drivers Drowsiness Detection and alert System by Measuring EAR. Int. J. Comput. Appl. 2018, 181, 38–45. [Google Scholar] [CrossRef]
- Bakheet, S.; Al-Hamadi, A. A framework for instantaneous driver drowsiness detection based on improved HOG features and naïve Bayesian classification. Brain Sci. 2021, 11, 240. [Google Scholar] [CrossRef] [PubMed]
- Jain, M.; Bhagerathi, B.; Sowmyarani, C.N. Real-Time Driver Drowsiness Detection using Computer Vision. Int. J. Eng. Adv. Technol. 2021, 11, 109–113. [Google Scholar] [CrossRef]
- Kongcharoen, W.; Nuchitprasitchai, S.; Nilsiam, Y.; Pearce, J.M. Real-Time Eye State Detection System for Driver Drowsiness Using Convolutional Neural Network. In Proceedings of the 2020 17th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 24–27 June 2020; pp. 551–554. [Google Scholar] [CrossRef]
- Pachouly, S.P.; Bhondve, N.B.; Dalvi, A.D.; Dhande, V.D.; Bhamare, N.B. Driver Drowsiness Detection using Machine Learning with Visual Behaviour. Int. J. Creat. Res. Thoughts 2020, 8, 2974–2979. [Google Scholar]
- Albadawi, Y.; Takruri, M.; Awad, M. A Review of Recent Developments in Driver Drowsiness Detection Systems. Sensors 2022, 22, 2069. [Google Scholar] [CrossRef]
- Wang, X.; Chen, L.; Zhang, Y.; Shi, H.; Wang, G.; Wang, Q.; Han, J.; Zhong, F. A real-time driver fatigue identification method based on Ga-GRNN. Front. Public Health 2022, 10, 991350. [Google Scholar] [CrossRef]
- Varun Chand, H.; Karthikeyan, J. CNN based driver drowsiness detection system using emotion analysis. Intell. Autom. Soft Comput. 2022, 31, 717–728. [Google Scholar] [CrossRef]
- Phan, A.-C.; Nguyen, N.-H.-Q.; Trieu, T.-N.; Phan, T.-C. An efficient approach for detecting driver drowsiness based on Deep Learning. Appl. Sci. 2021, 11, 8441. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, Z.; Wang Liu, Q. Driver drowsiness detection using facial dynamic fusion information and a DBN. IET Intell. Transp. Syst. 2018, 12, 127–133. [Google Scholar] [CrossRef]
- Silahtaroğlu, M.; Dereli, S. An image processing-based system proposal for real-time detection of drowsiness from a vehicle driver’s eye movements. Acad. Perspect. Procedia 2021, 4, 74–80. [Google Scholar] [CrossRef]
- Guede-Fernández, F.; Fernández-Chimeno, M.; Ramos-Castro, J.; García-González, M.A. Driver Drowsiness Detection Based on Respiratory Signal Analysis. IEEE Access 2019, 7, 81826–81838. [Google Scholar] [CrossRef]
- Vishesh, P.; Raghavendra, S.; Jankatti, S.; Rekha, V. Eyeblink detection using CNN to detect drowsiness level in drivers for road safety. Indones. J. Electr. Eng. Comput. Sci. 2021, 22, 22222. [Google Scholar] [CrossRef]
- Sukrit, M.; Sharad, D.; Sahil, G.; Arpita, J.B. Real-Time Driver Drowsiness Detection System Using Eye Aspect Ratio and Eye Closure Ratio. In Proceedings of the International Conference on Sustainable Computing in Science, Technology and Management (SUSCOM), Jaipur, India, 26–28 February 2019. [Google Scholar]
- Siddiqui, H.U.R.; Saleem, A.A.; Brown, R.; Bademci, B.; Lee, E.; Rustam, F.; Dudley, S. Non-Invasive Driver Drowsiness Detection System. Sensors 2021, 21, 4833. [Google Scholar] [CrossRef]
- Faisal, T.; Negassi, I.; Goitom, G.; Yassin, M.; Bashir, A.; Awawdeh, M. Systematic development of real-time driver drowsiness detection system using Deep Learning. IAES Int. J. Artif. Intell. 2022, 11, 148–160. [Google Scholar] [CrossRef]
- Kavitha, M.N.; Saranya, S.S.; Adithyan, K.D.; Soundharapandi, R.; Vignesh, A.S. Novel approach for driver drowsiness detection using Deep Learning. AIP Publ. 2021, 2387, 140027. [Google Scholar] [CrossRef]
- Rahman, S.; Dash, S.; Luhach, A.K.; Chilamkurti, N.; Baek, S.; Nam, Y. A Neuro-fuzzy approach for user behaviour classification and prediction. J. Cloud Comp. 2019, 8, 17. [Google Scholar] [CrossRef]
- Perumandla, D. Drowsiness_Dataset, Kaggle. 2020. Available online: https://www.kaggle.com/datasets/dheerajperumandla/drowsiness-dataset (accessed on 10 February 2023).
- Google Collab: Welcome to Colaboratory—Colaboratory. Available online: https://colab.research.google.com/?utm_source=scs-index (accessed on 20 April 2023).
- Introduction to Convolution Neural Network—GeeksforGeeks, Geeks for Geeks. 2022. Available online: https://www.geeksforgeeks.org/introduction-convolution-neuralnetwork/ (accessed on 16 April 2022).
- PyTorch Conv2D Explained with Examples—MLK—Machine Learning Knowledge, MLK—Machine Learning Knowledge. 2022. Available online: https://machinelearningknowledge.ai/pytorch-conv2d-explained-with-examples (accessed on 16 April 2022).
- CNN. Introduction to Pooling Layer—GeeksforGeeks, GeeksforGeeks. 2022. Available online: https://www.geeksforgeeks.org/cnn-introduction-to-pooling-layer/ (accessed on 16 April 2022).
- Tensorflow.js tf.layers.flatten() Function—GeeksforGeeks, GeeksforGeeks. 2022. Available online: https://www.geeksforgeeks.org/tensorflow-js-tf-layers-flatten-function/ (accessed on 16 April 2022).
- Pelt, D.M.; Sethian, J.A. A mixed-scale dense convolutional neural network for image analysis. Proc. Natl. Acad. Sci. USA 2018, 115, 254–259. [Google Scholar] [CrossRef]
- ImageNet. Available online: image-net.org (accessed on 1 May 2023).
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. In Advances in Information Retrieval; Losada, D.E., Fernández-Luna, J.M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3408. [Google Scholar] [CrossRef]
- Basheer Ahmed, M.I.; Zaghdoud, R.; Ahmed, M.S.; Sendi, R.; Alsharif, S.; Alabdulkarim, J.; Albin Saad, B.A.; Alsabt, R.; Rahman, A.; Krishnasamy, G. A Real-Time Computer Vision Based Approach to Detection and Classification of Traffic Incidents. Big Data Cogn. Comput. 2023, 7, 22. [Google Scholar] [CrossRef]
- Olatunji, S.O.; Alsheikh, N.; Alnajrani, L.; Alanazy, A.; Almusairii, M.; Alshammasi, S.; Alansari, A.; Zaghdoud, R.; Alahmadi, A.; Basheer Ahmed, M.I.; et al. Comprehensible Machine-Learning-Based Models for the Pre-Emptive Diagnosis of Multiple Sclerosis Using Clinical Data: A Retrospective Study in the Eastern Province of Saudi Arabia. Int. J. Environ. Res. Public Health 2023, 20, 4261. [Google Scholar] [CrossRef] [PubMed]
- Talha, M.; Sarfraz, M.; Rahman, A.; Ghauri, S.A.; Mohammad, R.M.; Krishnasamy, G.; Alkharraa, M. Voting-Based Deep Convolutional Neural Networks (VB-DCNNs) for M-QAM and M-PSK Signals Classification. Electronics 2023, 12, 1913. [Google Scholar] [CrossRef]
- Ibrahim, N.M.; Gabr, D.G.; Rahman, A.; Musleh, D.; AlKhulaifi, D.; AlKharraa, M. Transfer Learning Approach to Seed Taxonomy: A Wild Plant Case Study. Big Data Cogn. Comput. 2023, 7, 128. [Google Scholar] [CrossRef]
- Olatunji, S.O.; Alansari, A.; Alkhorasani, H.; Alsubaii, M.; Sakloua, R.; Alzahrani, R.; Alsaleem, Y.; Alassaf, R.; Farooqui, M.; Basheer Ahmed, M.I.; et al. Preemptive Diagnosis of Alzheimer’s Disease in the Eastern Province of Saudi Arabia Using Computational Intelligence Techniques. Comput. Intell. Neurosci. 2022, 2022, 5476714. [Google Scholar] [CrossRef] [PubMed]
- Olatunji, S.O.; Alansari, A.; Alkhorasani, H.; Alsubaii, M.; Sakloua, R.; Alzahrani, R.; Alsaleem, Y.; Almutairi, M.; Alhamad, N.; Alyami, A.; et al. A Novel Ensemble-Based Technique for the Preemptive Diagnosis of Rheumatoid Arthritis Disease in the Eastern Province of Saudi Arabia Using Clinical Data. Comput. Math. Methods Med. 2022, 2022, 2339546. [Google Scholar] [CrossRef]
- Rahman, A.; Ahmed, M.; Zaman, G.; Iqbal, T.; Khan, M.A.A.; Farooqui, M.; Ahmed, M.I.B.; Ahmed, M.S.; Nabeel, M.; Omar, A. Geo-Spatial Disease Clustering for Public Health Decision Making. Informatica 2022, 46, 21–32. [Google Scholar] [CrossRef]
- Gollapalli, M.; Rahman, A.; Musleh, D.; Ibrahim, N.; Khan, M.A.; Sagheer, A.; Ayesha, A.; Aftab, K.M.; Mehwash, F.; Tahir, I.; et al. A neuro-fuzzy approach to road traffic congestion prediction. Comput. Mater. Contin. 2022, 73, 295–310. [Google Scholar] [CrossRef]
- Rahman, A.; Ahmed, M.I.B. Virtual Clinic: A CDSS Assisted Telemedicine Framework. In Telemedicine Technologies; Elsevier: Amsterdam, The Netherlands, 2019; pp. 227–238. [Google Scholar]
- Khan, T.A.; Fatima, A.; Shahzad, T.; Rahman, A.; Alissa, K.; Ghazal, T.M.; Al-Sakhnini, M.M.; Abbas, S.; Khan, M.A.; Ahmed, A. Secure IoMT for Disease Prediction Empowered with Transfer Learning in Healthcare 5.0, the Concept and Case Study. IEEE Access 2023, 11, 39418–39430. [Google Scholar] [CrossRef]
- Mohammed, I.; Alsuhaibani, S.A. Alsuhaibani, S.A. A neuro-fuzzy inference model for diabetic retinopathy classification. In Intelligent Data Analysis for Biomedical Applications; Academic Press: Cambridge, MA, USA, 2019; pp. 147–172. [Google Scholar]
- Ahmed, M.I.B.; Rahman, A.U.; Farooqui, M.; Alamoudi, F.; Baageel, R.; Alqarni, A. Early identification of COVID-19 using dynamic fuzzy rule based system. Math. Model. Eng. Probl. 2021, 8, 805–812. [Google Scholar] [CrossRef]
- Alotaibi, S.M.; Rahman, A.; Basheer, M.I.; Khan, M.A. Ensemble machine learning based identification of pediatric epilepsy. Comput. Mater. Contin. 2021, 68, 149–165. [Google Scholar]
- Ahmed, M.S.; Rahman, A.; AlGhamdi, F.; AlDakheel, S.; Hakami, H.; AlJumah, A.; AlIbrahim, Z.; Youldash, M.; Alam Khan, M.A.; Basheer Ahmed, M.I. Joint Diagnosis of Pneumonia, COVID-19, and Tuberculosis from Chest X-ray Images: A Deep Learning Approach. Diagnostics 2023, 13, 2562. [Google Scholar] [CrossRef] [PubMed]
- Statology. Weltch t-Test. 2020. Available online: https://www.statology.org/welchs-t-test-calculator/ (accessed on 3 August 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | % of Accidents | % of Fatalities and Injuries |
|---|---|---|
| Kingdom of Saudi Arabia | 11.6% | 6.2% |
| United Kingdom | 2–4% | 10–20% |
| United States | 1–3% | 41% |
| Pakistan | 19% | 35.5% |
| Ref. | Dataset | Methods | Best Result |
|---|---|---|---|
| [6] | A private dataset consists of 2850 images. | Deep-stacked CNN | Accuracy of 96%. |
| [7] | Two datasets: the Closed Eye in the Wild dataset (CEW) and the Yawing Detection Dataset (YawDD). | Forward deep-learning CNN | Accuracy of 96%. |
| [8] | YawDD dataset which consists of 107 images. | Ensemble CNN (ECNN). | F1 score of 93%. |
| [9] | UTA Real-Life Drowsiness Dataset (UTA-RLDD), which includes 60 videos. | Recurrent and convolutional neural networks, as well as a fuzzy logic-based approach. | Accuracy of 93% in fuzzy logic-based approach. |
| [10] | NITYMED videos dataset. | InceptionV3, VGG16 and ResNet50V2 | Accuracy of 99.71% for eyeball detection. |
| [11] | Private dataset. | Haar sliding window. | Accuracy of 92%. |
| [12] | Private dataset. | Viola–Jones Method. | Accuracy of 84%. |
| [13] | WIDER_ FACE dataset. | Improved YOLOv3-tiny network. | Accuracy of 95%. |
| [14] | Private dataset. | Computer Vision PERCLOS approach and the Support Vector Machines algorithm. | Accuracy of 91%. |
| [15] | Private dataset. | Viola–Jones algorithm. | Accuracy of 95%. |
| [17] | Private dataset. | Support Vector Machine algorithm. | Accuracy of 93%. |
| [18] | Private dataset. | Viola–Jones algorithm. | Accuracy of 90%. |
| [19] | Private dataset consists of 17,000 images. | CNN | Accuracy of 99%. |
| [20] | The NTHU-DDD dataset, consisting of 376 videos. | Histogram of Oriented Gradient (HOG) technique and Naïve Bayes (NB) algorithm. | Accuracy of 85%. |
| [21] | The UTA Real-Life Drowsiness Dataset (UTA-RLDD). | Recurrent and convolutional neural network. | Accuracy of 65%. |
| [22] | The ibug-300w Dataset contains 300 images. | Opencv’s built-in HAAR cascades. | The accuracy is 100%. |
| [23] | Media Research Lab’s dataset of eyes is used. | Convolutional neural network. | The accuracy is 94%. |
| [24] | No mention of the source. | Opencv with the EAR function. | Not mentioned. |
| [26] | 16,600 images with 11 features. | Random forest, k-nearest neighbor, general regression neural network, and generic algorithm (GA)-RNN. | GA-RNN with an accuracy of 93%. |
| [27] | Image dataset of size 17,243. | SVM, KNN, and the CNN. | Conventional neural network (CNN) with an accuracy of 93%. |
| [28] | Mixed dataset of size 16,577 of images and videos. | Mobilenet-V2 and resnet-50V2. | Resnet-50V2 with an accuracy of 97%. |
| [29] | A private dataset. | Deep belief network (DBN). | Achieved an accuracy of 96% |
| [30] | A private dataset. | Eye Aspect Ratio (EAR) and blinking analysis, and Dlib library. | An accuracy of 92%. |
| [31] | A private dataset. | A novel algorithm for monitoring driver’s state called TEDD. | An accuracy of 96%. |
| [32] | Eye Blink dataset, consisting of eye images from 22 participants. | CNN and opencv, along with a new method called Horizontal and Vertical Gradient Features (hvgfs). | Achieve an accuracy of 97%. |
| [33] | Used a dataset of 10 subjects to generate the facial images. | Random forest. | An accuracy of 84% |
| [34] | A dataset consisting of age, label (drowsy/non-drowsy), and respiration per minute. | Support Vector Machine, Decision Tree, Logistic Regression, Gradient Boosting Machine, Extra Tree Classifier and Multilayer Perceptron. | Support Vector Machine achieved the best accuracy of 87%. |
| [35] | The dataset used was developed and generated by the authors. | CNN | 97% accuracy. |
| [36] | Online dataset from Kaggle | Artificial Neural Network. | 97% accuracy. |
| Class | Precision | Recall | F1-Score |
|---|---|---|---|
| 0 | 0.95 | 0.92 | 0.94 |
| 1 | 0.93 | 0.96 | 0.95 |
| 2 | 0.99 | 0.98 | 0.98 |
| 3 | 0.98 | 0.99 | 0.98 |
| Class | Precision | Recall | F1-Score |
|---|---|---|---|
| 0 | 0.40 | 0.94 | 0.56 |
| 1 | 0.55 | 0.15 | 0.23 |
| 2 | 0.98 | 0.64 | 0.77 |
| 3 | 0.82 | 0.98 | 0.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, M.I.B.; Alabdulkarem, H.; Alomair, F.; Aldossary, D.; Alahmari, M.; Alhumaidan, M.; Alrassan, S.; Rahman, A.; Youldash, M.; Zaman, G. A Deep-Learning Approach to Driver Drowsiness Detection. Safety 2023, 9, 65. https://doi.org/10.3390/safety9030065
Ahmed MIB, Alabdulkarem H, Alomair F, Aldossary D, Alahmari M, Alhumaidan M, Alrassan S, Rahman A, Youldash M, Zaman G. A Deep-Learning Approach to Driver Drowsiness Detection. Safety. 2023; 9(3):65. https://doi.org/10.3390/safety9030065
Chicago/Turabian StyleAhmed, Mohammed Imran Basheer, Halah Alabdulkarem, Fatimah Alomair, Dana Aldossary, Manar Alahmari, Munira Alhumaidan, Shoog Alrassan, Atta Rahman, Mustafa Youldash, and Gohar Zaman. 2023. "A Deep-Learning Approach to Driver Drowsiness Detection" Safety 9, no. 3: 65. https://doi.org/10.3390/safety9030065