

Vision Transformer Customized for Environment Detection and Collision Prediction to Assist the Visually Impaired

 , , ,
, , ,
Abstract
:1. Introduction
- The creation and utilization of a dataset that includes object classes that are particularly important for VIIs (e.g., crosswalk, elevator), while accounting for different weather conditions and times of the day (with varying brightness and contrast levels).
- The successful implementation and demonstration of a state-of-the-art self-supervised learning algorithm that uses vision transformers for object detection, semantic segmentation, and custom algorithms for collision prediction.
- Multimodal sensory feedback modules to convey environmental information and potential collisions to the user, to provide real-time navigation assistance in both indoor and outdoor environments.
2. Related Work
2.1. Assistive Systems
2.2. Self-Supervised Learning
3. Dataset
Data Allocation
4. Methodology
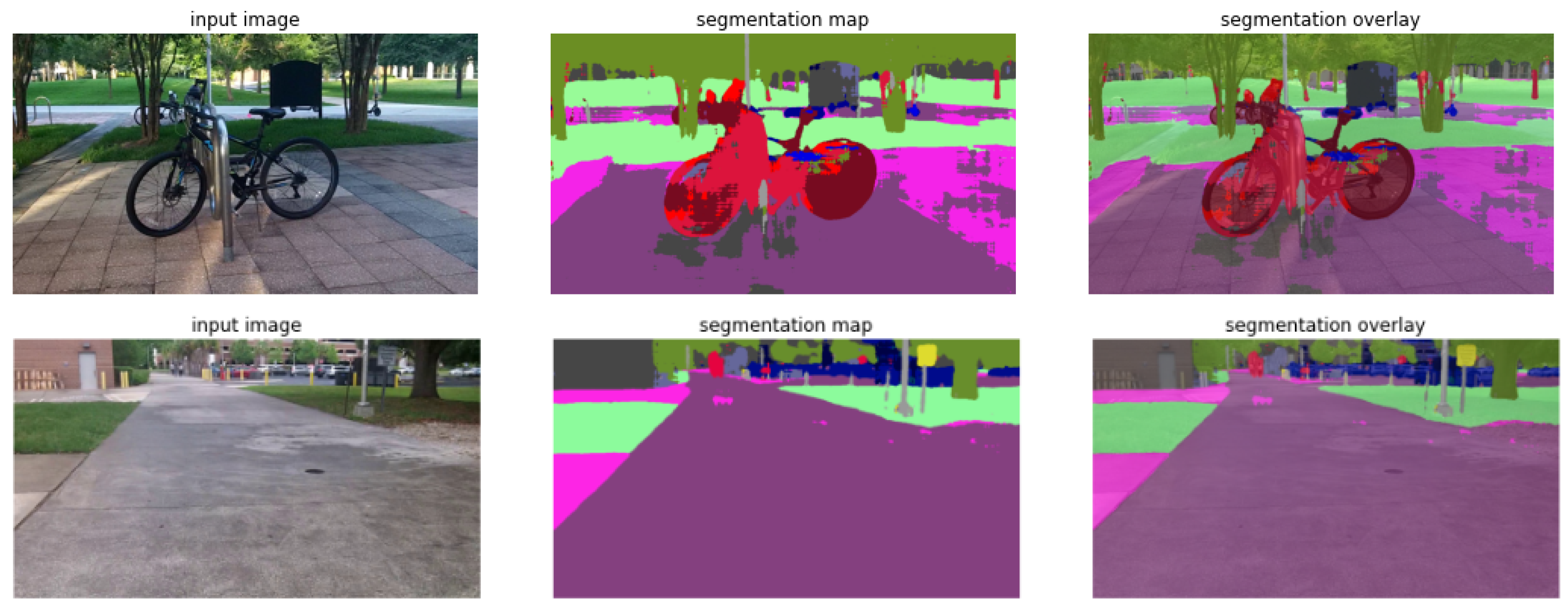
4.1. Framework for Object Detection and Semantic Segmentation
4.2. Collision Prediction Algorithm
- (a)
- Calculation of the center of the objects with respect to the image coordinate frame.
- (b)
- Relative positions of the objects with respect to the user.
- Case 1: Object I at is on the left side of the user.
- Case 2: Object I at is in front of the user.
- Case 3: Object I at is on the right side of the user.
- (c)
- Identify objects moving closer/further with respect to the user.
- Case 1: . The Object is moving closer to the user.
- Case 2: . The object is moving further from the user.
- Case 3: . The object is stationary if the user is stationary, or it is moving in the same direction and speed as the user.

- (d)
- Generate object trajectory vectors.
| Algorithm 1: Collision avoidance and feedback |
|
4.3. Auditory and Vibrotactile Feedback
5. Evaluation Setting
5.1. Networks Architecture
5.2. Implementation Specifics
6. Results and Discussion
6.1. Object Detection and Semantic Segmentation
6.2. Collision Prediction
6.3. Limitations and Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Centers for Disease Control and Prevention. Fast Facts of Common Eye Disorders. 2021. Available online: https://www.cdc.gov/visionhealth/basics/ced/fastfacts.htm (accessed on 8 January 2021).
- World Health Organization. Vision Impairment and Blindness. 2021. Available online: https://www.who.int/news-room/fact-sheets/detail/blindness-and-visual-impairment (accessed on 8 January 2021).
- Straub, M.; Riener, A.; Ferscha, A. Route guidance with a vibro-tactile waist belt. In Proceedings of the 4th European Conference on Smart Sensing and Context, Guildford, UK, 16–18 September 2009. [Google Scholar]
- Degeler, A. FeelSpace Uses Vibrating Motors to Help the Blind Feel the Right Direction. 2015. Available online: https://thenextweb.com/eu/2015/12/17/feelspace-helps-blind-feel-right-direction-vibrating-motors/ (accessed on 8 January 2021).
- Yelamarthi, K.; Haas, D.; Nielsen, D.; Mothersell, S. RFID and GPS integrated navigation system for the visually impaired. In Proceedings of the 2010 53rd IEEE International Midwest Symposium on Circuits and Systems, Seattle, WA, USA, 1–4 August 2010; pp. 1149–1152. [Google Scholar]
- Bai, Y.; Jia, W.; Zhang, H.; Mao, Z.H.; Sun, M. Landmark-based indoor positioning for visually impaired individuals. In Proceedings of the 2014 12th International Conference on Signal Processing (ICSP), Hangzhou, China, 19–23 October 2014; pp. 668–671. [Google Scholar]
- Ganz, A.; Gandhi, S.R.; Schafer, J.; Singh, T.; Puleo, E.; Mullett, G.; Wilson, C. PERCEPT: Indoor navigation for the blind and visually impaired. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 856–859. [Google Scholar]
- Boudreault, A.; Bouchard, B.; Gaboury, S.; Bouchard, J. Blind Sight Navigator: A New Orthosis for People with Visual Impairments. In Proceedings of the 9th ACM International Conference on Pervasive Technologies Related to Assistive Environments, New York, NY, USA, 29 June–1 July 2016; pp. 1–4. [Google Scholar]
- Venkateswar, S.; Mehendale, N. Intelligent belt for the blind. Int. J. Sci. Eng. Res. 2012, 3, 1–3. [Google Scholar]
- Green, J. Aid for the blind and visually impaired people. M2 Presswire. 14 February 2017. [Google Scholar]
- Vera Yánez, D.; Marcillo, D.; Fernandes, H.; Barroso, J.; Pereira, A. Blind Guide: Anytime, anywhere. In Proceedings of the 7th International Conference on Software Development and Technologies for Enhancing Accessibility and Fighting Info-Exclusion (DSAI 2016), Association for Computing Machinery, New York, NY, USA, 3–6 August 2016; pp. 346–352. [Google Scholar] [CrossRef]
- Yi, C.; Flores, R.W.; Chincha, R.; Tian, Y. Finding objects for assisting blind people. Netw. Model. Anal. Health Inform. Bioinform. 2013, 2, 71–79. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bigham, J.P.; Jayant, C.; Miller, A.; White, B.; Yeh, T. VizWiz: LocateIt-enabling blind people to locate objects in their environment. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 65–72. [Google Scholar]
- Chincha, R.; Tian, Y. Finding objects for blind people based on SURF features. In Proceedings of the 2011 IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW), Atlanta, GA, USA, 12–15 November 2011; pp. 526–527. [Google Scholar]
- Schauerte, B.; Martinez, M.; Constantinescu, A.; Stiefelhagen, R. An assistive vision system for the blind that helps find lost things. Part II. In Proceedings of the Computers Helping People with Special Needs: 13th International Conference, ICCHP, Linz, Austria, 11–13 July 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 13, pp. 566–572. [Google Scholar]
- Khan, I.; Khusro, S.; Ullah, I. Technology-assisted white cane: Evaluation and future directions. PeerJ 2018, 6, e6058. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Profita, H.; Cromer, P.; Leduc-Mills, B.; Bharadwaj, S. ioCane: A Smart-Phone and Sensor-Augmented Mobility Aid for the Blind; University of Colorado: Boulder, CO, USA, 2013; pp. 377–409. [Google Scholar]
- Villanueva, J.; Farcy, R. Optical device indicating a safe free path to blind people. IEEE Trans. Instrum. Meas. 2011, 61, 170–177. [Google Scholar] [CrossRef]
- Real, S.; Araujo, A. Navigation systems for the blind and visually impaired: Past work, challenges, and open problems. Sensors 2019, 19, 3404. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhou, J.; Wei, C.; Wang, H.; Shen, W.; Xie, C.; Yuille, A.; Kong, T. ibot: Image bert pre-training with online tokenizer. arXiv 2021, arXiv:2111.07832. [Google Scholar]
- Budrionis, A.; Plikynas, D.; Daniušis, P.; Indrulionis, A. Smartphone-based computer vision travelling aids for blind and visually impaired individuals: A systematic review. Assist. Technol. 2022, 34, 178–194. [Google Scholar] [CrossRef]
- Tahoun, N.; Awad, A.; Bonny, T. Smart assistant for blind and visually impaired people. In Proceedings of the 2019 3rd International Conference on Advances in Artificial Intelligence, New York, NY, USA, 26–28 October 2019; pp. 227–231. [Google Scholar]
- Qian, K.; Zhao, W.; Ma, Z.; Ma, J.; Ma, X.; Yu, H. Wearable-assisted localization and inspection guidance system using egocentric stereo cameras. IEEE Sens. J. 2017, 18, 809–821. [Google Scholar] [CrossRef]
- Lin, S.; Wang, K.; Yang, K.; Cheng, R. KrNet: A kinetic real-time convolutional neural network for navigational assistance. In Proceedings of the International Conference on Computers Helping People with Special Needs, Lecco, Italy, 9–11 September 2018; Springer: Linz, Austria, 2018; pp. 55–62. [Google Scholar]
- Yang, K.; Wang, K.; Chen, H.; Bai, J. Reducing the minimum range of a RGB-depth sensor to aid navigation in visually impaired individuals. Appl. Opt. 2018, 57, 2809–2819. [Google Scholar] [CrossRef]
- Afif, M.; Ayachi, R.; Said, Y.; Pissaloux, E.; Atri, M. An evaluation of retinanet on indoor object detection for blind and visually impaired persons assistance navigation. Neural Process. Lett. 2020, 51, 2265–2279. [Google Scholar] [CrossRef]
- Islam, M.M.; Sadi, M.S.; Zamli, K.Z.; Ahmed, M.M. Developing walking assistants for visually impaired people: A review. IEEE Sens. J. 2019, 19, 2814–2828. [Google Scholar] [CrossRef]
- Bai, J.; Liu, Z.; Lin, Y.; Li, Y.; Lian, S.; Liu, D. Wearable travel aid for environment perception and navigation of visually impaired people. Electronics 2019, 8, 697. [Google Scholar] [CrossRef] [Green Version]
- Martinez, M.; Yang, K.; Constantinescu, A.; Stiefelhagen, R. Helping the blind to get through COVID-19: Social distancing assistant using real-time semantic segmentation on RGB-D video. Sensors 2020, 20, 5202. [Google Scholar] [CrossRef]
- Liu, L.; Wang, Y.; Zhao, H. An Image Segmentation Method for the blind sidewalks recognition by using the convolutional neural network U-net. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–4. [Google Scholar]
- Gandhi, S.; Gandhi, N. A CMUcam5 computer vision based arduino wearable navigation system for the visually impaired. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 1768–1774. [Google Scholar]
- Zhang, J.; Yang, K.; Constantinescu, A.; Peng, K.; Muller, K.; Stiefelhagen, R. Trans4Trans: Efficient transformer for transparent object segmentation to help visually impaired people navigate in the real world. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1760–1770. [Google Scholar]
- Croce, D.; Giarre, L.; Pascucci, F.; Tinnirello, I.; Galioto, G.E.; Garlisi, D.; Valvo, A.L. An indoor and outdoor navigation system for visually impaired people. IEEE Access 2019, 7, 170406–170418. [Google Scholar] [CrossRef]
- Mahendran, J.K.; Barry, D.T.; Nivedha, A.K.; Bhandarkar, S.M. Computer vision-based assistance system for the visually impaired using mobile edge artificial intelligence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2418–2427. [Google Scholar]
- Lin, Y.; Wang, K.; Yi, W.; Lian, S. Deep learning based wearable assistive system for visually impaired people. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Montreal, QC, Canada, 10–17 October 2019; pp. 143–147. [Google Scholar]
- Dimas, G.; Cholopoulou, E.; Iakovidis, D.K. Self-Supervised Soft Obstacle Detection for Safe Navigation of Visually Impaired People. In Proceedings of the 2021 IEEE International Conference on Imaging Systems and Techniques (IST), New York, NY, USA, 21–23 July 2021; pp. 1–6. [Google Scholar]
- Kumar, B. ViT Cane: Visual Assistant for the Visually Impaired. arXiv 2021, arXiv:2109.13857. [Google Scholar]
- Yadav, S.; Joshi, R.C.; Dutta, M.K.; Kiac, M.; Sikora, P. Fusion of object recognition and obstacle detection approach for assisting visually challenged person. In Proceedings of the 2020 43rd International Conference on Telecommunications and Signal Processing (TSP), Milan, Italy, 7–9 July 2020; pp. 537–540. [Google Scholar]
- Saunshi, N.; Ash, J.; Goel, S.; Misra, D.; Zhang, C.; Arora, S.; Kakade, S.; Krishnamurthy, A. Understanding contrastive learning requires incorporating inductive biases. arXiv 2022, arXiv:2202.14037. [Google Scholar]
- Grill, J.B.; Strub, F.; Altche, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent—A new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Yalin Bastanlar and Semih Orhan. Self-supervised contrastive representation learning in computer vision. In Artificial Intelligence Annual Volume 2022; IntechOpen: London, UK, 2022. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jegou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 9650–9660. [Google Scholar]
- Singh, G.; Akrigg, S.; Di Maio, M.; Fontana, V.; Alitappeh, R.J.; Khan, S.; Saha, S.; Jeddisaravi, K.; Yousefi, F.; Culley, J.; et al. Road: The road event awareness dataset for autonomous driving. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1036–1054. [Google Scholar] [CrossRef]
- Pototzky, D.; Sultan, A.; Kirschner, M.; Schmidt-Thieme, L. Self-supervised Learning for Object Detection in Autonomous Driving. In Proceedings of the DAGM German Conference on Pattern Recognition, Konstanz, Germany, 28 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 484–497. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Kim, J.H.; Kwon, S.; Fu, J.; Park, J.H. Hair Follicle Classification and Hair Loss Severity Estimation Using Mask R-CNN. J. Imaging 2022, 8, 283. [Google Scholar] [CrossRef]
- Pandey, V. Self-Supervised Semantic Segmentation Based on Self-Attention. Master’s Thesis, University of Twente, Twente, The Netherlands, 2021. [Google Scholar]
- Muhtar, D.; Zhang, X.; Xiao, P. Index Your Position: A Novel Self-Supervised Learning Method for Remote Sensing Images Semantic Segmentation. IEEE Trans. Geosci. Remote. Sens. 2022, 5, 10971. [Google Scholar] [CrossRef]
- Wang, H.; Sun, Y.; Liu, M. Self-supervised drivable area and road anomaly segmentation using rgb-d data for robotic wheelchairs. IEEE Robot. Autom. Lett. 2019, 4, 4386–4393. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Festvox. Festival. GitHub Repository. 2023. Available online: https://github.com/festvox/festival (accessed on 1 June 2023).
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–21 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. Part V. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; Volume 13, pp. 740–755. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Time of the Day | Weather |
|---|---|---|
| 11 May 2022 | 5 pm | sunny |
| 13 May 2022 | 4 pm | sunny |
| 16 May 2022 | 11 am | sunny |
| 20 May 2022 | 6 pm | cloudy |
| 23 May 2022 | 8 pm | cloudy |
| 24 May 2022 | 10 am | sunny |
| 24 May 2022 | 7 pm | sunny |
| 25 May 2022 | 3 pm | sunny |
| 26 May 2022 | 11 am | sunny |
| 28 May 2022 | 6 pm | sunny |
| 29 May 2022 | 3 pm | sunny |
| Class Number | Class Name | Total Number of Images | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| 0 | Asphalt | 1076 | 0.97 | 0.97 | 0.97 |
| 1 | Bike | 62 | 0.90 | 0.90 | 0.90 |
| 2 | Car | 280 | 0.92 | 1.00 | 0.96 |
| 3 | Chair | 507 | 0.98 | 0.97 | 0.97 |
| 4 | Crosswalk | 3524 | 0.94 | 0.91 | 0.93 |
| 5 | Door | 1829 | 0.94 | 0.94 | 0.94 |
| 6 | Elevator | 347 | 0.96 | 0.96 | 0.96 |
| 7 | Grass | 569 | 0.98 | 0.97 | 0.98 |
| 8 | Gravel | 1296 | 0.93 | 0.95 | 0.94 |
| 9 | Indoorfloor | 758 | 0.96 | 0.96 | 0.96 |
| 10 | Fire hydrant | 430 | 0.96 | 0.93 | 0.94 |
| 11 | Garden wall | 95 | 0.93 | 0.93 | 0.93 |
| 12 | Parking | 965 | 0.98 | 0.95 | 0.96 |
| 13 | Pavement | 1111 | 0.93 | 0.93 | 0.93 |
| 14 | Vegetation | 732 | 0.93 | 0.96 | 0.94 |
| 15 | Red pavement | 629 | 0.97 | 0.95 | 0.96 |
| 16 | Sidewalk | 2732 | 0.91 | 0.96 | 0.93 |
| 17 | Stair | 4128 | 0.96 | 0.96 | 0.96 |
| 18 | Traffic cone | 70 | 0.97 | 0.85 | 0.90 |
| 19 | Trail | 3651 | 0.94 | 0.96 | 0.95 |
| 20 | Trash bin | 101 | 0.67 | 1.00 | 0.80 |
| 21 | Tree | 1690 | 0.92 | 0.94 | 0.93 |
| 22 | Wooden bridge | 1399 | 0.96 | 0.96 | 0.96 |
| 23 | Wood flooring | 420 | 0.97 | 0.91 | 0.94 |
| Accuracy | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bayat, N.; Kim, J.-H.; Choudhury, R.; Kadhim, I.F.; Al-Mashhadani, Z.; Aldritz Dela Virgen, M.; Latorre, R.; De La Paz, R.; Park, J.-H. Vision Transformer Customized for Environment Detection and Collision Prediction to Assist the Visually Impaired. J. Imaging 2023, 9, 161. https://doi.org/10.3390/jimaging9080161
Bayat N, Kim J-H, Choudhury R, Kadhim IF, Al-Mashhadani Z, Aldritz Dela Virgen M, Latorre R, De La Paz R, Park J-H. Vision Transformer Customized for Environment Detection and Collision Prediction to Assist the Visually Impaired. Journal of Imaging. 2023; 9(8):161. https://doi.org/10.3390/jimaging9080161
Chicago/Turabian StyleBayat, Nasrin, Jong-Hwan Kim, Renoa Choudhury, Ibrahim F. Kadhim, Zubaidah Al-Mashhadani, Mark Aldritz Dela Virgen, Reuben Latorre, Ricardo De La Paz, and Joon-Hyuk Park. 2023. "Vision Transformer Customized for Environment Detection and Collision Prediction to Assist the Visually Impaired" Journal of Imaging 9, no. 8: 161. https://doi.org/10.3390/jimaging9080161