
The Face Deepfake Detection Challenge

 , , ,
, , ,  , , , , ,
, , , , ,  , ,
, ,  , , , , , , , , and
, , , , , , , , and
Abstract
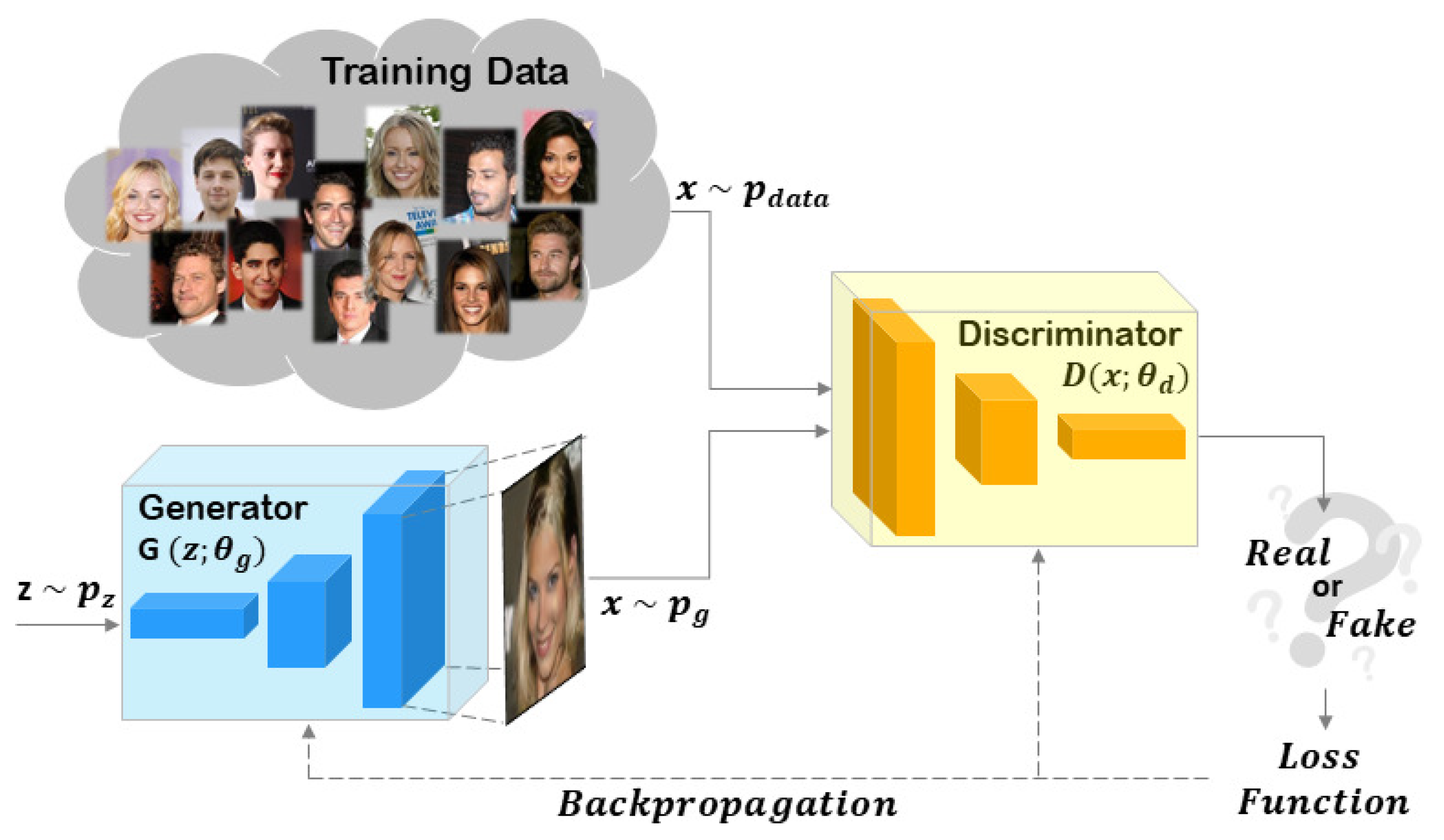
:1. Introduction
- A detailed description of the Deepfake Detection and Reconstruction Challenge, organized at the 21st International Conference on Image Analysis and Processing (ICIAP);
- The best challenge solutions created by participating teams were included in the paper;
- A new dataset for the deepfake detection task, which turns out to be different from common datasets available in the literature due to its diversity in terms of image size, types of attacks applied, and much more, was proposed;
- Finally, the first dataset covering a task never addressed by researchers in the domain (creating an algorithm able to reconstruct the original image from deepfake) was proposed.
2. Deepfake Literature Overview
2.1. Deepfake Creation Methods
2.2. Deepfake Detection Methods
3. Deepfake Images Detection and Reconstruction Challenge Description
3.1. Deepfake Detection Task
- CelebA: a large-scale face attributes dataset containing 40 labels related to facial attributes such as hair color, gender and age. The dataset is composed by 178 × 218 JPEG images;
- FFHQ: a high-quality image dataset of human faces. The images were crawled from Flickr and automatically aligned and cropped using dlib (http://dlib.net/, accessed on 3 November 2021). The dataset is composed of high-quality 1024 × 1024 PNG images;
- StarGAN: CelebA images were manipulated by means of a pre-trained template (available in the official repository) obtaining images with a resolution of 256 × 256;
- GDWCT: CelebA images were manipulated by means of a pre-trained template (available in the official repository) obtaining images with a resolution of 216 × 216;
- AttGAN: CelebA images were manipulated by means of a pre-trained template (available in the official repository) obtaining images with a resolution of 256 × 256;
- StyleGAN: images were generated considering FFHQ as the input dataset, obtaining images with 1024 × 1024 resolution;
- StyleGAN2: Images were generated considering FFHQ as the input dataset, obtaining images with 1024 × 1024 resolution.
- Rotation: a random integer number determined the degree of rotation between 45, 90, 135, 180, 225, 270, 315;
- Scaling: a random integer number determined whether to reduce the image by 50% or magnify it by 100%;
- Gaussian Noise: an integer random number determined the size of the kernel to be applied between [3 × 3, 9 × 9, 15 × 15];
- Mirror: a random integer number determined whether to mirror horizontally, vertically or both;
- JPEG Compression: a random integer number generated in the range [50, 99] determined the quality factor parameter.
3.2. Source Image Reconstruction Task
4. Researcher Solutions
4.1. DC-GAN (Amped Team)
- Image compression: images were compressed with the JPEG algorithm, at a quality factor picked uniformly in the range [50, 99];
- Noise addition: images were corrupted with additive Gaussian noise, with variable limit in range [10.0, 50.0];
- Blurring: Gaussian blurring was applied to the images, with blur a limit of 3, and sigma limit of 0;
- Flipping: both horizontal and vertical flipped versions of each image were generated;
- Resizing: images were scaled by the following size [180, 256, 300, 384, 512];
- Random blackout: a region around the mouth, nose or eyes was randomly replaced with a black rectangle.
4.2. Convolutional Cross Vision Transformer—AIMH Lab Team
- To build a leaner architecture than previous approaches in order to apply it more easily on a large scale;
- Simplifying Vision Transformer training by exploiting the inductive biases inherent in Convolutional Neural Networks;
- Construct an architecture capable of analyze an image with a local-global vision;
4.3. Deepfake Detection Using the Discrete Cosine Transform on Multi-Scaled and Multi-Compressed Images—PRA Lab—Div. Biometria Team
- u is the horizontal spatial frequency;
- v is the vertical spatial frequency;
- C is a normalising scale factor (orthonormality).
- Gaussian filters: , , with = 3;
- Rotation: 45, 90, 135, 180, 225, 270, 315 degrees;
- Flip: vertical flip, horizontal flip or both;
- Resize: 50% downscaling, 50% upscaling;
- JPEG compression: JPEG compression version at quality 95%.
5. Ranking and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Guarnera, L.; Giudice, O.; Battiato, S. Deepfake Style Transfer Mixture: A First Forensic Ballistics Study on Synthetic Images. In Proceedings of the International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 151–163. [Google Scholar]
- Giudice, O.; Paratore, A.; Moltisanti, M.; Battiato, S. A Classification Engine for Image Ballistics of Social Data. In Proceedings of the International Conference on Image Analysis and Processing, Catania, Italy, 11–15 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 625–636. [Google Scholar]
- Wang, X.; Guo, H.; Hu, S.; Chang, M.C.; Lyu, S. GAN-generated Faces Detection: A Survey and New Perspectives. arXiv 2022, arXiv:2202.07145. [Google Scholar]
- Verdoliva, L. Media Forensics and Deepfakes: An Overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and Beyond: A Survey of Face Manipulation and Fake Detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. AttGAN: Facial Attribute Editing by Only Changing What You Want. IEEE Trans. Image Process. 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [PubMed]
- Cho, W.; Choi, S.; Park, D.K.; Shin, I.; Choo, J. Image-to-image Translation via Group-wise Deep Whitening-and-coloring Transformation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10639–10647. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. StarGAN v2: Diverse Image Synthesis for Multiple Domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8188–8197. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Do, N.T.; Na, I.S.; Kim, S.H. Forensics Face Detection from GANs Using Convolutional Neural Network. ISITC 2018, 2018, 376–379. [Google Scholar]
- Mo, H.; Chen, B.; Luo, W. Fake Faces Identification via Convolutional Neural Network. In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, 20–22 June 2018; pp. 43–47. [Google Scholar]
- Li, H.; Li, B.; Tan, S.; Huang, J. Identification of Deep Network Generated Images Using Disparities in Color Components. Signal Process. 2020, 174, 107616. [Google Scholar] [CrossRef]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated Images are Surprisingly Easy to Spot…for Now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- Gragnaniello, D.; Cozzolino, D.; Marra, F.; Poggi, G.; Verdoliva, L. Are GAN Generated Images Easy to Detect? A Critical Analysis of the State-of-the-art. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Guarnera, L.; Giudice, O.; Nastasi, C.; Battiato, S. Preliminary forensics analysis of deepfake images. In Proceedings of the 2020 AEIT International Annual Conference (AEIT), Catania, Italy, 23–25 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Korshunov, P.; Marcel, S. Deepfakes: A New Threat to Face Recognition? Assessment and Detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing Deep Fakes Using Inconsistent Head Poses. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. Faceforensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Dufour, N.; Gully, A. Contributing data to deep-fake detection research. Google AI Blog 2019, 1, 3. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for Deepfake Forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The Deepfake Detection Challenge (DFDC) Dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. Deeperforensics-1.0: A Large-scale Dataset for Real-world Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2889–2898. [Google Scholar]
- Le, T.; Nguyen, H.H.; Yamagishi, J.; Echizen, I. OpenForensics: Large-Scale Challenging Dataset For Multi-Face Forgery Detection And Segmentation In-The-Wild. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; IEEE Computer Society: Los Alamitos, CA, USA, 2021; pp. 10097–10107. [Google Scholar] [CrossRef]
- Coccomini, D.A.; Messina, N.; Gennaro, C.; Falchi, F. Combining EfficientNet and Vision Transformers for Video Deepfake Detection. In Proceedings of the International Conference on Image Analysis and Processing, Paris, France, 27–28 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 219–229. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.G. WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 16 October 2020; pp. 2382–2390. [Google Scholar] [CrossRef]
- He, Y.; Gan, B.; Chen, S.; Zhou, Y.; Yin, G.; Song, L.; Sheng, L.; Shao, J.; Liu, Z. ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4358–4367. [Google Scholar]
- Seferbekov, S. DFDC 1st Place Solution. Available online: https://www.kaggle.com/c/deepfake-detection-challenge (accessed on 1 March 2022).
- Montserrat, D.M.; Hao, H.; Yarlagadda, S.K.; Baireddy, S.; Shao, R.; Horváth, J.; Bartusiak, E.; Yang, J.; Guera, D.; Zhu, F.; et al. Deepfakes Detection with Automatic Face Weighting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 668–669. [Google Scholar]
- Wodajo, D.; Atnafu, S. Deepfake Video Detection Using Convolutional Vision Transformer. arXiv 2021, arXiv:2102.11126. [Google Scholar]
- Heo, Y.J.; Choi, Y.J.; Lee, Y.W.; Kim, B.G. Deepfake Detection Scheme Based on Vision Transformer and Distillation. arXiv 2021, arXiv:2104.01353. [Google Scholar]
- Lago, F.; Pasquini, C.; Böhme, R.; Dumont, H.; Goffaux, V.; Boato, G. More Real Than Real: A Study on Human Visual Perception of Synthetic Faces [Applications Corner]. IEEE Signal Process. Mag. 2022, 39, 109–116. [Google Scholar] [CrossRef]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do GANs Leave Artificial Fingerprints? In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 506–511. [Google Scholar]
- Yu, N.; Davis, L.; Fritz, M. Attributing Fake Images to GANs: Learning and Analyzing GAN Fingerprints. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7555–7565. [Google Scholar]
- Dzanic, T.; Shah, K.; Witherden, F. Fourier Spectrum Discrepancies in Deep Network Generated Images. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 3022–3032. [Google Scholar]
- Durall, R.; Keuper, M.; Keuper, J. Watch Your Up-Convolution: CNN Based Generative Deep Neural Networks Are Failing to Reproduce Spectral Distributions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7887–7896. [Google Scholar] [CrossRef]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging Frequency Analysis for Deep Fake Image Recognition. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Online, 13–18 July 2020; Volume 119, pp. 3247–3258. [Google Scholar]
- Giudice, O.; Guarnera, L.; Battiato, S. Fighting Deepfakes by Detecting GAN DCT Anomalies. J. Imaging 2021, 7, 128. [Google Scholar] [CrossRef] [PubMed]
- Guarnera, L.; Giudice, O.; Battiato, S. DeepFake Detection by Analyzing Convolutional Traces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 666–667. [Google Scholar]
- Guarnera, L.; Giudice, O.; Battiato, S. Fighting Deepfake by Exposing the Convolutional Traces on Images. IEEE Access 2020, 8, 165085–165098. [Google Scholar] [CrossRef]
- Moon, T.K. The Expectation-Maximization Algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Guarnera, L.; Giudice, O.; Nießner, M.; Battiato, S. On the Exploitation of Deepfake Model Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 61–70. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, E.Y.; Guo, Z.; Zhang, X.; Jojic, V.; Wang, W. Metric Learning from Relative Comparisons by Minimizing Squared Residual. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 978–983. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 17–23 July 2019; pp. 6105–6114. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Abeba, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Chen, C.F.R.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:abs/1905.11946. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:abs/2104.00298. [Google Scholar]
- Concas, S.; Perelli, G.; Marcialis, G.L.; Puglisi, G. Tensor-Based Deepfake Detection In Scaled And Compressed Images. In Proceedings of the 29th IEEE International Conference on Image Processing (IEEE ICIP), Bordeaux, France, 16–19 October 2022. in press. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K. Discrete Cosine Transform. IEEE Trans. Comput. 1974, C-23, 90–93. [Google Scholar] [CrossRef]
- Lam, E.; Goodman, J. A Mathematical Analysis of the DCT Coefficient Distributions for Images. IEEE Trans. Image Process. 2000, 9, 1661–1666. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model and Crop Size | AUC Value |
|---|---|
| Enet B0 with cropped-image size 64 × 64 | 0.8115 |
| Enet B0 with cropped-image size 128 × 128 | 0.8524 |
| Enet B4 with cropped-image size 128 × 128 | 0.8758 |
| Enet B5 with cropped-image size 128 × 128 | 0.9674 |
| Ranking | Team Name | Accuracy (%) |
|---|---|---|
| #1 | VisionLabs | 93.61% |
| #2 | DC-GAN (Amped Team) | 90.05% |
| #3 | Team Nirma | 75.38% |
| #4 | AIMH Lab | 72.62% |
| #5 | PRA Lab—Div. Biometria | 63.97% |
| #6 | Team Wolfpack | 40.61% |
| #7 | SolveKaro | 36.85% |
| (a) VisionLabs | |||
| Precision | Recall | F1-score | |
| Real | 0.89 | 0.88 | 0.89 |
| Deepfake | 0.95 | 0.96 | 0.96 |
| accuracy | 0.94 | ||
| macro avg | 0.92 | 0.92 | 0.92 |
| weighted avg | 0.94 | 0.94 | 0.94 |
| (b) DC-GAN (Amped Team) | |||
| Precision | Recall | F1-score | |
| Real | 0.86 | 0.78 | 0.82 |
| Deepfake | 0.92 | 0.95 | 0.93 |
| accuracy | 0.90 | ||
| macro avg | 0.89 | 0.87 | 0.88 |
| weighted avg | 0.90 | 0.90 | 0.90 |
| (c) Team Nirma | |||
| Precision | Recall | F1-score | |
| Real | 0.55 | 0.80 | 0.65 |
| Deepfake | 0.90 | 0.74 | 0.81 |
| accuracy | 0.75 | ||
| macro avg | 0.72 | 0.77 | 0.73 |
| weighted avg | 0.80 | 0.75 | 0.76 |
| (d) AIMH Lab | |||
| Precision | Recall | F1-score | |
| Real | 0.52 | 0.49 | 0.51 |
| Deepfake | 0.80 | 0.82 | 0.81 |
| accuracy | 0.73 | ||
| macro avg | 0.66 | 0.66 | 0.66 |
| weighted avg | 0.72 | 0.73 | 0.72 |
| (e) PRA Lab—Div. Biometria | |||
| Precision | Recall | F1-score | |
| Real | 0.43 | 0.76 | 0.55 |
| Deepfake | 0.86 | 0.59 | 0.70 |
| accuracy | 0.64 | ||
| macro avg | 0.64 | 0.68 | 0.62 |
| weighted avg | 0.74 | 0.64 | 0.66 |
| (f) Team Wolfpack | |||
| Precision | Recall | F1-score | |
| Real | 0.05 | 0.06 | 0.05 |
| Deepfake | 0.59 | 0.55 | 0.57 |
| accuracy | 0.41 | ||
| macro avg | 0.32 | 0.30 | 0.31 |
| weighted avg | 0.44 | 0.41 | 0.42 |
| (g) SolveKaro | |||
| Precision | Recall | F1-score | |
| Real | 0.17 | 0.31 | 0.22 |
| Deepfake | 0.59 | 0.39 | 0.47 |
| accuracy | 0.37 | ||
| macro avg | 0.38 | 0.35 | 0.34 |
| weighted avg | 0.47 | 0.37 | 0.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guarnera, L.; Giudice, O.; Guarnera, F.; Ortis, A.; Puglisi, G.; Paratore, A.; Bui, L.M.Q.; Fontani, M.; Coccomini, D.A.; Caldelli, R.; et al. The Face Deepfake Detection Challenge. J. Imaging 2022, 8, 263. https://doi.org/10.3390/jimaging8100263
Guarnera L, Giudice O, Guarnera F, Ortis A, Puglisi G, Paratore A, Bui LMQ, Fontani M, Coccomini DA, Caldelli R, et al. The Face Deepfake Detection Challenge. Journal of Imaging. 2022; 8(10):263. https://doi.org/10.3390/jimaging8100263
Chicago/Turabian StyleGuarnera, Luca, Oliver Giudice, Francesco Guarnera, Alessandro Ortis, Giovanni Puglisi, Antonino Paratore, Linh M. Q. Bui, Marco Fontani, Davide Alessandro Coccomini, Roberto Caldelli, and et al. 2022. "The Face Deepfake Detection Challenge" Journal of Imaging 8, no. 10: 263. https://doi.org/10.3390/jimaging8100263