1. Introduction
Small vessels in the brain, such as the Lenticulostriate Arteries (LSA), which supply blood to the basal ganglia [
1,
2], are the terminal branches of the arterial vascular tree. Pathology of these small vessels is associated with ageing, dementia and Alzheimer’s disease [
3,
4,
5]. Segmentation and quantification of these small vessels is a critical step in the study of Cerebral Small Vessel Disease or CSVD [
6,
7]. The 7 Tesla (7T) Time-of-Flight MRA is capable of depicting such small vessels non-invasively [
8,
9]. This paper refers to vessels as small when they have an apparent diameter of only one to two voxels, as seen in 7T MRA with a resolution of 300 µm.
Manual segmentation of small vessels in 7T MRA is reliable but also time-consuming and laborious. Non-Deep Learning (non-DL) approaches [
10,
11], which are capable of extracting vessels based on structural properties, can detect medium to large vessels but detecting small vessels can be challenging [
12]. Manual and semi-automated techniques involve manual efforts in parameter tuning or annotating vessels, making it a time-consuming task requiring experience to achieve the required sensitivity to achieve robust detection of small vessels. Some of the semi-automated techniques use machine learning algorithms to extract features based on the annotations of observers and classify the non-annotated pixels of the image. Another common problem of semi-automatic vessel segmentation [
13] is generating spurious points in the segmentation result [
14]. The aim of this research is to develop an approach that is capable of effectively segmenting small vessels using fully automated deep learning techniques based on convolutional neural networks, rendering time-consuming parameter tuning or manual intervention obsolete.
In recent years, deep learning-based architectures have been widely used for segmentation tasks [
15,
16]. The U-Net [
17,
18] and Attention U-Net [
19] have proven to be promising techniques in biomedical image segmentation [
20,
21]. These methods can be trained using small-size datasets and have outperformed the traditional methods [
17]. Therefore, these architectures are used as baselines for the proposed small vessel segmentation approach. This paper proposes a network combining multi-scale deep supervision [
22] in U-Net with elastic deformation consistency learning [
23]. The deep supervision considers the loss at various levels of the U-Net, thereby it should improve the segmentation performance. The consistency learning with elastic deformation makes the model equivariant to these transformations and increases the generalisability. The authors hypothesised that the performance achieved by training this network, which is a combination of these approaches, is better than the existing methods discussed above. Moreover, such a method might also be applicable for segmentation tasks other than blood vessels—while segmenting regions of interest with vastly different sizes and dealing with the problem of the imperfect dataset.
Contribution
This paper proposes a semi-supervised learning approach, deformation-aware learning DS6, which can learn to perform volumetric segmentation from a small training set. Furthermore, a modified version of U-Net Multi-scale Supervision (U-Net MSS) has been proposed here as the network backbone. The proposed DS6 approach combines elastic deformation with the network backbone using a Siamese architecture. The proposed method has been evaluated for the task of vessel segmentation from 7T ToF-MRA volumes. The proposed method has been compared against previously proposed deep learning and non-deep learning methods for its overall segmentation quality. Moreover, the effect of training set size on the performance of the method and also the performance of the method while segmenting 1.5T and 3T ToF-MRA have been evaluated.
3. Proposed Methodology
The backbone network is a modified version of U-Net MSS [
37]. The original U-Net MSS [
37] performs five times downsampling using strided convolution and transposed convolution for upsampling, whereas this modified version performs four times downsampling using Max-Pool and performs upsampling using interpolation. Moreover, the original U-Net MSS uses Instance Normalisation and LeakyReLU in its convolution blocks; but this modified U-Net MSS uses Batch Normalisation and ReLU. In addition to the final segmentation output, the outputs of two of the following layers (different scales) are also considered for loss calculation. These additional outputs were interpolated using the nearest neighbour to the size of the segmentation mask before loss calculation.
Figure 1 portrays the modified version of the U-Net MSS used in this research. Equation (
1) represents the loss function of the proposed U-Net MSS. The
m refers to the total up-sampling scales in the U-Net,
is the loss at each up-sampling scale,
is the weight assigned to loss at a specific up-sampling level and network parameter
.
To enable the model to learn consistency under elastic deformations [
39], the work by [
23] was re-implemented and extended by using the modified U-Net MSS in place of U-Net, as shown in
Figure 2. Let
be the set of input volumes while
is the set of corresponding labels and
be the set of elastic transformations. The proposed network uses a Siamese architecture to learn from the original data and deformed data using its two identical branches. The first branch is fed with the tuple (
x,
y), where
x,
y, while the second branch is fed with the elastically transformed volume and label (
t(x),
t(y)), where
t. These tuples are passed through the U-Net MSS to derive segmentation outputs
and
, respectively. These outputs are compared with the corresponding labels to derive the supervised loss depicted in Equation (
2). Furthermore, the
is elastically transformed by
t to
. Now, the
is compared with
for computing the consistency loss in self-supervised manner as shown in Equation (
3). The network was trained to find the optimal value of
that minimises the overall loss defined by the sum of the supervised and the consistency loss.
The authors hypothesise that this proposed network can learn consistency under elastic transformations and will be able to learn from the available small dataset with noisy labels. The supervised loss
trains the network to segment the images using the ground-truth labels, and the consistency loss
ensures that the network is equivariant to the elastic transformation. This transformation can also be used as data augmentation for the models, but this was not applied in this research work as it was already shown by [
23] that the deformation consistency performs better than using it as data augmentation.
Elastic deformation of a given volume can be obtained by applying a displacement field to the volume, as shown in Equation (
4), where
,
and
are the displacements in
x,
y and
z direction, respectively; g denotes the grey values of each voxel of the original image, whereas
denotes the grey values of the deformed image [
42]. The displacement fields were randomly generated by initialising a grid with random values within a specified limit, followed by interpolating the displacement at each voxel from the grid using a cubic B-spline [
43].
4. Datasets and Labels
To be able to validate the proposed approach, a high-resolution TOF-MRA dataset was needed. Images obtained with high spatial resolution on a 7T MR scanner contain more small vessels in comparison to a 3T MR scanner [
26]. Hence, the dataset by [
44] was chosen, which comprises 3D TOF-MRA of 11 subjects imaged at 7T. The data had an isotropic resolution of 300 µm and were acquired with prospective motion correction to prevent image blurring, hence preventing the loss of small vessels [
44,
45].
For this dataset, no ground-truth segmentation was available. The labels for these MRA images were created semi-automatically using Ilastik [
46] by a computer scientist (see Acknowledgement), who was initially trained, and later, the segmentation quality was checked visually by a domain expert (H.M.). Ilastik is a widely used tool for pixel classification, which provides the capability to create custom pixel classification workflows. The annotator can visualise the volume and then annotate the small vessels using points or scribbles by adjusting the pointer diameter. Ilastik uses these annotations and pixel features of the image to segment small vessels in the rest of the volume using the Random Forest algorithm. Further, the user can go through the rest of the slices and manually modify the segmentation. Alternatively, Ilastik can also be used for fully manual segmentation. For the label creation task on the dataset, Ilastik’s semi-automatic option with manual interaction was used.
The quality of the labelled images can be visually assessed by comparing the maximum intensity projection (MIP) of the original volume with the label, which is shown in
Figure 3. The label generated is not entirely perfect, as it is noisy, contains gaps in certain regions, and does not capture all small vessels, which can be attributed to the limitations of the tool. For a more accurate analysis of the method, the fully manual segmentation option of Ilastik was used to manually segment a small region of interest (ROI) of dimension 64
, as can be seen in Figure 7.
For training and evaluation of the network, the dataset was randomly divided into training, validation, and test sets in the ratio of 6:2:3. The performance of the methods was evaluated using 3-fold cross-validation. For further evaluation of the generalisation capabilities of the proposed network, publicly available MRA images from the IXI dataset (IXI dataset:
https://brain-development.org/ixi-dataset/, accessed on 15 September 2022) were used. The data were collected on two different field strengths, 1.5T and 3T. The labels for these images were created using Ilastik using a semi-automated manner, as mentioned earlier.
5. Experimental Setup
The Siamese network used in this research consists of a U-Net MSS [
22] as the backbone architecture, as explained in the previous section. Every MRA image volume was converted to 3D patches with dimensions 64
, and with a stride of 32, 32, 16 across sagittal (width), coronal (height), and axial (depth), respectively, to get overlapped samples—to allow the network to learn inter-patch continuity. Having six image volumes for training and two volumes for validation, this configuration created 20,412 patches for training and 6804 for validation. For additional trainings to judge the effect of the training set size on the models, three additional training sets with one, two, and four volumes were also created. For the training of the deep learning models, 8000 patches were selected at random in each epoch and fixed 6000 patches for validation—to reduce the number of iterations per epoch, reducing the required training time. For evaluation, the three test volumes were converted to non-overlapping patches of size 64
using strides of 64 across all dimensions, this resulted in 1012 patches. For the calculation of the supervised loss and the consistency loss, the focal Tversky loss or FTL [
47] as in Equation (
5) was used and was optimised during training using the Adam optimiser [
48] with a learning rate of 0.01. The range of
is between 1 and 3. The Tversky Index (TI) was calculated using Equation (
6), where
and
are the parameters to decide the weight given to the false negatives and to the false positives. The
represents the probability of voxel
i being vessel, and
represents the probability of pixel
i being non-vessel. Similarly, the
and
represent the label of the pixel with value either 0 or 1. In this research,
was chosen to be 0.7 and
to be 0.75 after experimentation.
The implementation of the deep learning models was done using PyTorch [
49]. A differentiable version of the elastic transformation was implemented by extending the random elastic transformation of TorchIO [
50] by replacing its SimpleITK-based [
51] implementation of the transformation with a modified version of the kernel transformation (using the 3D B-spline kernel) of AirLab [
52]. The number of control points along each dimension of the grid (see
Section 3) was chosen randomly to be five, six or seven, to introduce different levels of deformation. The maximum displacement was set to 0.02, and two borders were locked. Elastic transformations, along with the selection of its number of control points, were performed randomly for each patch for each training iteration. In this manner, the network encountered differently deformed patches with different levels of deformations during the training process. The code of this implementation can be obtained from GitHub (
https://github.com/soumickmj/DS6, accessed on 15 September 2022).
As all the models (proposed method and the baselines) converged between 20 and 30 epochs, the trainings were performed for 50 epochs with mixed precision [
53] using Nvidia Apex (
https://github.com/NVIDIA/apex, accessed on 8 March 2020, commit 5633f6d) on Nvidia Tesla V100-SXM2-32GB GPU. Using Mixed precision, it was possible to train with a batch size of 20, in comparison to a batch size of eight with Full precision (more details in
Appendix B). The lowest validation loss was noted, and the corresponding epoch’s model weights were saved. These trained models were then made deformation-aware by further training for 50 more epochs with the proposed Siamese architecture.
6. Evaluation
In this section, the performance of the proposed method is compared against that of other methods. Two different non-deep learning (Non-DL)-based methods were used for comparison—Frangi filter [
10], which is one of the most widely used methods for vessel segmentation and the MSFDF pipeline [
11], which is one of the state-of-the-art methods for vessel segmentation for SWI and TOF image volumes. For both of these methods, the volumes were pre-processed with N4 bias field correction [
54] to remove intensity inhomogeneities, which is a common effect in high-field MR images resulting in spatial intensity variations [
55]. Multiple experiments were performed with manual tunings of the parameters of the Frangi filter to obtain a suitable parameter set. Finally, a three-scale (1, 2, 3) Frangi filter with a
of 0.1 (Frangi correction constant) and a final threshold of 0.01 was chosen for this dataset and was applied on pre-normalised images (between 0–1). For the MSFDF pipeline, the official implementation (
https://github.com/braincharter/vasculature_notebook, accessed on 10 December 2020, commit 0bb7244) was used with all the default parameters as provided, except for the Otsu offset, which was set to 0.0 (default 0.2) to reduce noise contamination in the final segmentation. Besides the bias-field corrected image volumes, the method required a brain mask. To that end, the brain extraction tool or BET [
56,
57] of the FSL [
58] was used (fractional threshold set to 0.1).
The performance of the proposed model was compared against two established deep learning-based baseline models—U-Net [
18], for being one of the most popular methods for segmentation and Attention U-Net [
19], which was proposed as an upgrade of U-Net. The performance of the proposed method was compared with and without the deformation consistency; the Siamese network U-Net MSS + Deformation (proposed method) and the modified U-Net MSS (proposed backbone), respectively. The proposed method was also compared against a re-implemented version U-Net + Deformation [
23]. This re-implemented version had exactly the same setup as the proposed method, except for the network model. No pre-processing, such as bias field correction or brain extraction, was performed on the images before supplying them to the deep learning models, except for normalising the intensities (between 0–1).
Quantitative evaluation of the 3D segmentations was performed using the Dice coefficient and the Intersection over Union (IoU), also known as the Jaccard Index. For qualitative analysis, maximum intensity projections (MIP) were computed to provide an overview of the 3D data as a 2D representation. MIPs were computed for whole brain assessment as well as ROI-specific. ROI-specific MIPs enable visual comparison of the small vessel segmentation quality of the different approaches used.
The first set of evaluations was performed by comparing the results against the 7T MRA dataset labels, which were created semi-automatically with Ilastik (see
Section 4). Then, the effect of the training set size on the results was evaluated. Moreover, given that the dataset labels are noisy, evaluations of the models were performed by comparing the results against a manually segmented ground-truth. Lastly, to evaluate the generalisation capabilities of the models, they were employed to segment 1.5T and 3T MRA volumes.
6.1. On 7T MRA Test Set
The first set of evaluations was performed for three out of eleven volumes of the 7T MRA dataset with 300 µm isotropic resolution (test set separated from the dataset before training/validation).
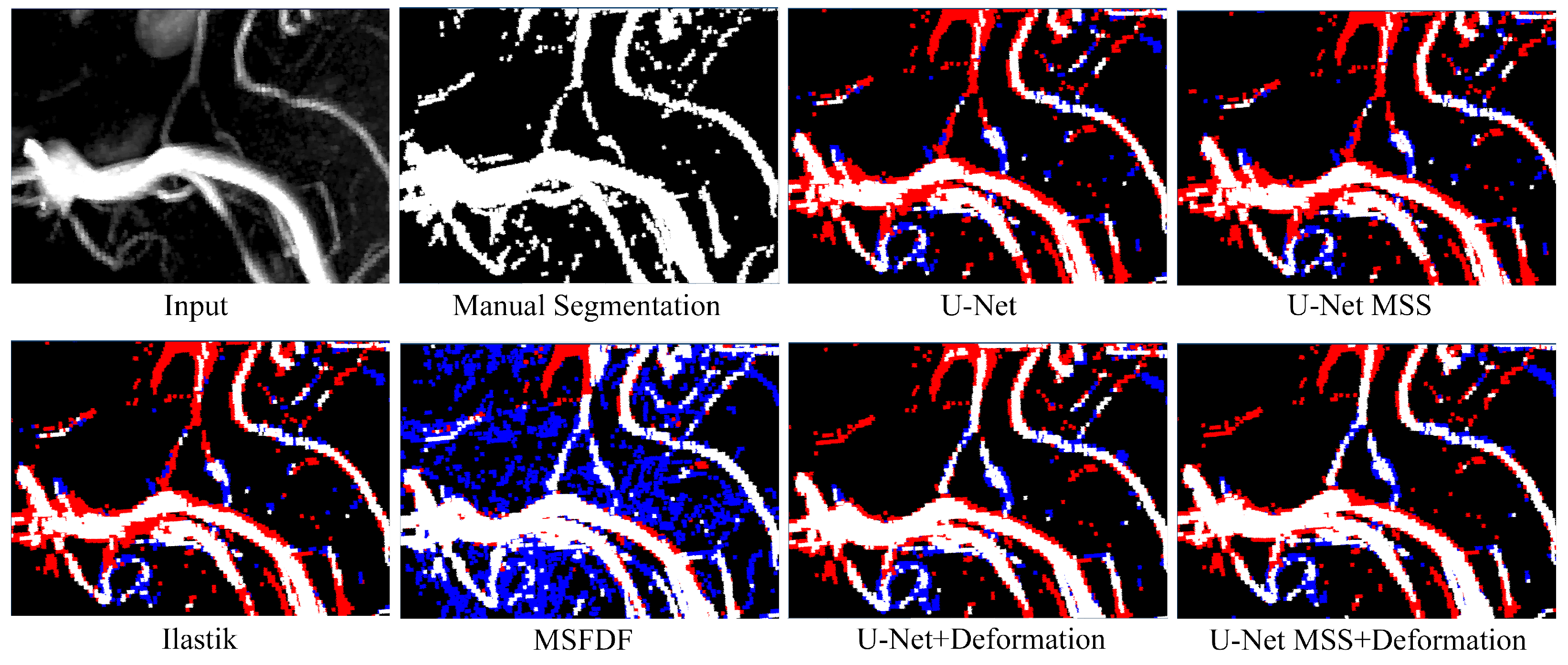
As shown in
Table 1, the Frangi filter and the method proposed in [
11] did not perform competitively with Deep Learning methods quantitatively. Further, qualitatively, it is evident from
Figure 4 that both Non-Deep Learning methods failed to detect small vessels in most of the cases. The Frangi filter failed to detect small vessels in columns three and four. In the method proposed in [
11], non-vessel regions were segmented as vessels, which is evident from the dominant blue in columns one and two. All deep neural networks outperformed traditional techniques by a large margin (51.81 ± 3.09 for Frangi: the best non-DL baseline, 76.19 ± 0.17 for baseline U-Net: the worst DL baseline) even with imperfectly labelled data. Careful visual inspection of the MIPs showed that U-Net MSS segmented the vessels better than the rest of the models. Further, on applying deformation-aware learning, a considerable improvement (4.27%) was observed with U-Net and also with U-Net MSS (1.37%). This can also be further noticed in the evaluation with different training set sizes conducted on the same models, where deformation-aware learning improved the performance of the models.
Statistical Hypothesis Testing
The statistical significance of the improvements observed was analysed by means of an independent two-sample t-test. As the test set of this research contains only three volumes and the population size might be too small to perform a reliable hypothesis testing, an additional set of Dice scores was calculated by dividing the volumes on the x-axis into nine equal non-overlapping (independent) slabs—resulting in slabs with dimensions 80 × 630 × 195. It was observed that deformation-aware learning resulted in significant improvement for both U-Net and U-Net MSS (p-values 0.004 and 0.013, respectively). Furthermore, the incorporation of multi-scale supervision with U-Net resulted in a significant improvement (p-value 0.003). However, U-Net MSS with deformation did not show any significant improvement over U-Net with deformation (p-value 0.086).
6.2. On the Effect of the Training Set Size
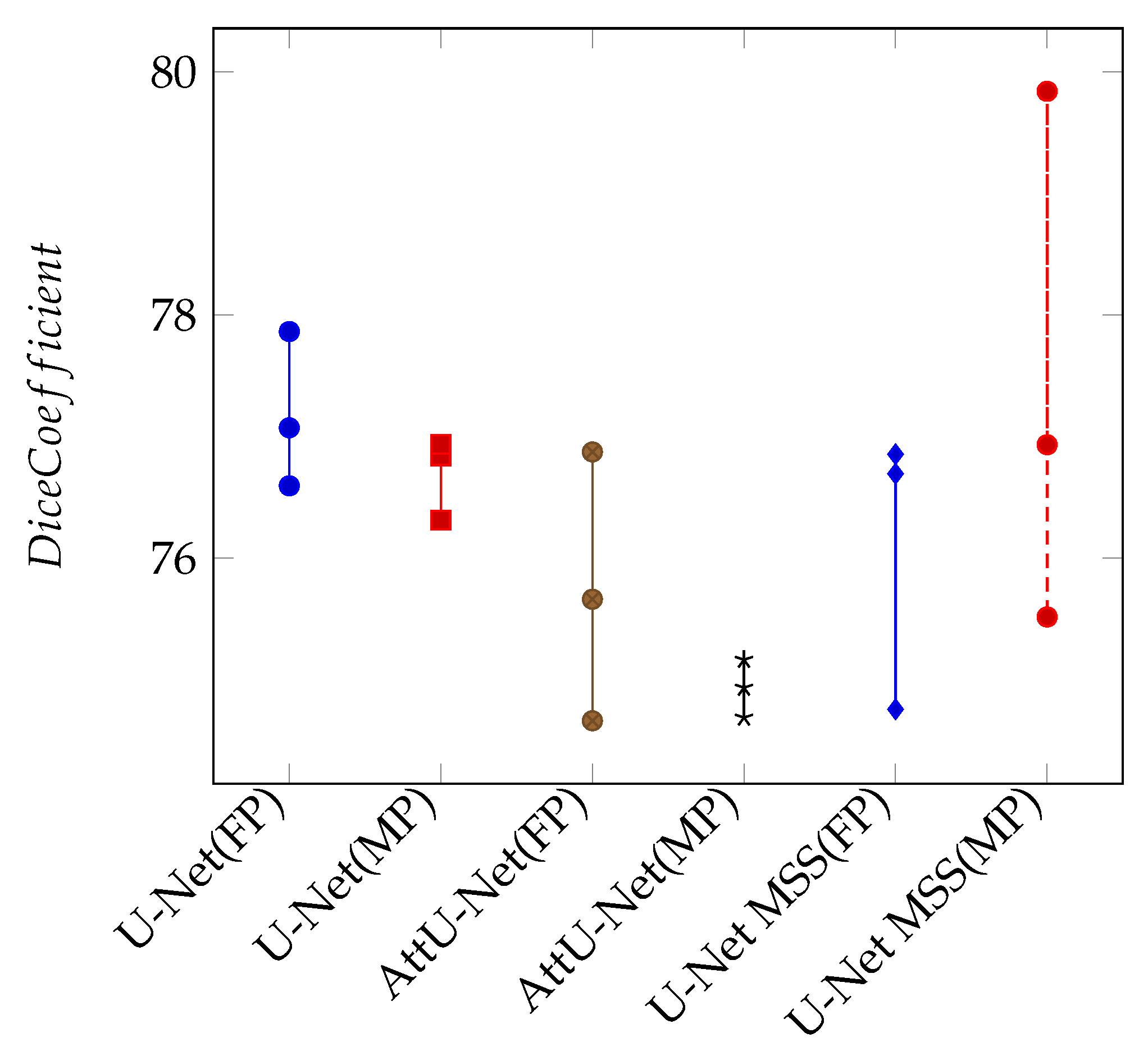
Further experiments were performed with varying training set sizes to understand its influence on the performance of the models and to understand how a lower number of volumes can be used for training the models to archive adequate performance. Four different training set sizes were experimented with: Six, Four, Two, and One. The sizes of the validation and test set were kept fixed (two and three, respectively). A 3-fold cross-validation was used for each training set size.
Table 2 shows the results obtained by training the networks with different training set sizes, and
Figure 5 portrays the resultant Dice scores using violin plots to observe the data distribution. From the violin plots, it can be observed that the median values (the middle-dotted lines inside the violins) are higher in every case for deformation-aware models. Moreover, it can be observed that the models trained with six volumes performed better than the models trained with smaller training sets and the models trained with one volume performed the worst. The result of the models trained with four and two volumes are very similar, but the results of trainings with two volumes are better than four. Given that the dataset labels are imperfect, it could have contributed to these counter-intuitive results, but this requires further investigation.
Models trained on a single volume still show good segmentation of vessels (74.81 ± 1.32 Dice for U-Net MSS + Deformation), which are comparable with the ones trained with six volumes even though typical deep learning models expect to have a large dataset. It can be further observed in
Figure 6 that U-Net MSS trained with deformation-aware learning could maintain certain vessel continuity better than its counterpart, which was trained without deformation.
6.3. On a Manually Segmented ROI of 7T MRA
The labels created semi-automatically using Ilastik were imperfect (as discussed in
Section 4). Hence, a single 64
ROI was segmented manually from an input image of the 7T MRA test set, and the performance of the methods was compared against this manually segmented ROI (considered perfect label, hence, ground truth).
Figure 7 shows a qualitative analysis comparing the manual segmentation against the prediction from all methods. The comparison shows that the semi-automated segmentation with Ilastik and all the baselines failed to detect the entire Y-shaped small vessels at the centre of the ROI. On the contrary, the models trained with deformation were able to detect these Y-shaped small vessels and maintain vessel continuity. Further, for quantitative analysis, the Dice scores of the predictions against the manually segmented ROI were calculated (see
Table 3). It can be observed that the training labels created with Ilastik achieved only a 50.21 Dice while being compared against the manually segmented ROI. Furthermore, U-Net MSS resulted in 9.95% better Dice than U-Net, and deformation-aware U-Net MSS resulted in 18.98% better Dice than the U-Net MSS without deformation.
6.4. On Publicly Available Dataset
with Lower Resolution than the Training Set: IXI MRA
To evaluate the generalisation capabilities of the model, it was applied to the publicly available IXI MRA dataset. The data were acquired at 1.5T and 3T with a lower image resolution of 450 µm. Due to this reduced resolution, the IXI dataset is less sensitive to small vessels (based on the true vessel lumen and not the apparent vessel diameter in voxel). The resolution of this dataset (450 µm) is 1.5 times lower in each direction in comparison to the training dataset (300 µm) acquired using a 7T scanner. This difference in resolution motivated the authors to perform experiments with two additional patch sizes (32 and 96) during inference apart from 64, which has been used during training. It can be observed that the patch size 96 gave the best performance, which is 1.5 times higher than the training patch size.
Table 4 summarises the quantitative performance of the models on 1.5T and 3T images. It shows that, in general, the U-Net MSS model with deformation consistency outperforms the model without deformation consistency on both image sets (10.84% and 3.42% improvement with deformation for 1.5T and 3T, respectively, for patch size 96
).
A qualitative analysis was performed on these image sets to gain further understanding of the segmentation performance (see
Figure 8).
Figure 8a,b shows the MIP and segmentation mask by U-Net MSS and U-Net MSS + deform with patch sizes 64 and 96 on 1.5T and 3T volumes, respectively. The image shows that the predicted segmentation mask is in line with the MIP and shows various areas where the prediction is better than the provided imperfect dataset labels. With the increase in the patch size, there is an improvement in the predictions, but the level of noise increases as well.
7. Discussion
This work presented a self-supervised approach using deformation-aware learning and has shown its application to the small vessel segmentation task while being trained with a small, imperfectly labelled dataset.
In the above sections, it can be observed that the quantitative, as well as the qualitative performance of U-Net MSS, is higher in comparison to U-Net, as seen in
Table 1 and
Figure 4. This is in line with the literature (see also the summary of
Section 2 and
Section 3) in the sense that the U-Net MSS learns discriminative features as the loss is calculated at multiple levels, and this facilitates efficient gradient flow in comparison to U-Net. Further, it can be observed that the deformation-based models outperform the models trained without deformation (see
Table 1). This could be attributed to the deformation-aware training, where the model is made to learn the shape consistency of the vessels when they are deformed. The findings are in line with the findings of the previously published works [
23,
59], where it was also shown that making the network transformation equivariant improved the performance. The proposed U-Net MSS model with deformation outperforms all the other models in quantitative as well as qualitative aspects. The authors hypothesise the reason for this to be the efficient gradient flow of U-Net MSS on top of the consistency learning that assists the model in learning discriminative features.
Given the imperfect training annotation, the authors further strengthen their claim by performing the evaluation against manual segmentation. As seen in
Table 3 and
Figure 7, the models trained with deformation-aware learning outperform the baselines. It can be hypothesised that deformation-aware learning helps train the network to be consistent, even when there are inconsistencies present in the annotations. Although the manual segmentation is imperfect due to the challenging nature of small vessel segmentation even by a human rater, quantitative estimates and qualitative perception matched well for these ROI-specific comparisons, indicating the improved small vessel segmentation performance of the methods introduced in this study.
While comparing against the noisy dataset labels (created semi-automatically with Ilastik), the modified U-Net MSS performed 4.15% better than the baseline U-Net. After enabling deformation-awareness for the models, U-Net achieved 4.27% higher, and U-Net MSS achieved 1.37% higher Dice than their corresponding models without deformation. As these labels are noisy, the improvements can be observed more clearly when the outputs were compared against manually segmented ground-truth label for an ROI. It is worth stating that the dataset labels created with Ilastik received only 50.21 Dice when they were compared against this manually created ROI ground-truth label. While comparing against this manually created label, U-Net MSS achieved 9.95% better Dice than U-Net. Deformation-aware U-Net got 26.05% better than U-Net without deformation, and deformation-aware U-Net MSS got 18.98% better Dice than the U-Net MSS without deformation. Another important aspect to observe is that when the results were compared to the manual annotation, all the DL methods resulted in less Dice than when they were compared against the semi-automatic Ilastik labels (
Table 1 and
Table 3, respectively)—this can be attributed to the noise in the Ilastik label. However, the non-DL baselines yielded better Dice scores while comparing against manual annotations than while comparing against the Ilastik labels. Moreover, in these comparisons against the manual labels, the non-DL baselines yielded better Dice than the DL models without deformation. This can be attributed to the fact that the models which were trained using imperfect labels and without deformation-awareness failed to learn properly.
The performance of the model trained with and without deformation was analysed on lower resolution image volumes (450 µm isotropic resolution) of 1.5T and 3T, where the model results improved with increasing patch size and was able to capture vessels that were not captured in the annotation but the level of noise in the results increased as well. The network was trained using image volumes with 300 µm isotropic resolution with a patch size of 64, and it performed best for patch size 96 for the 450 µm image volumes. So, it can be said that the performance of the model was dependent on the patch size, and a clear relationship can be observed between the image resolution and patch size, as when the image resolution decreased by a factor of 1.5, the patch size had to be increased by a factor of 1.5 to get better results. This is counter-intuitive and demands further in-depth investigations. It is to be noted that the models were trained on 7T MRA without bias field correction, and due to that fact, the 7T volumes had field inhomogeneity. The 1.5T and 3T volumes did not have such observable inhomogeneity, and testing models trained on 7T data might have had a negative impact due to this fact.
The experiments performed with the different training set sizes have shown that the trainings with six volumes performed better than the trainings performed with smaller datasets. However, trainings performed with two and four volumes were inconclusive. They resulted in similar Dice scores for the proposed method (77.84 ± 2.35 and 77.79 ± 2.05 Dice, respectively, for U-Net MSS + Deformation), but a training set size of two performed better than four for the rest of the models, which is completely counter-intuitive and further investigations are needed to determine the cause. Trainings performed with one volume yielded poorer, but still acceptable results (74.81 ± 1.32 Dice for the proposed U-Net MSS + Deformation). One possible future experiment can be performed by creating one perfect ground-truth for one volume and training the models with just that volume, and comparing the performance against this paper where up to six volumes (imperfectly labelled) were used for training.
The limitation of the proposed approach is the missing continuity of the small vessels in some of the regions, as seen in the last column of
Figure 4. This can be attributed to the fact that the model was trained using patches and lacks the context of continuity within the whole volume, which leads the model to predict stray points with a higher intensity as small vessels, which could be avoided if continuity is taken into consideration. Prior knowledge of vessels being cylindrical in nature is disrupted with deformation to a certain extent. In addition, since the Dice coefficient is calculated concerning an imperfect labelled image, some of the inherently detected vessels in the proposed model are considered over-segmented.
The main challenge for the quantitative evaluation is the missing ground truth due to the non-trivial nature of (small) vessel segmentation itself as well as the study design, i.e., learning from imperfect annotations. Therefore, the quantitative metrics reported here (i.e., Dice and IoU) have to be interpreted with care. Hence, a qualitative comparison of whole-brain and ROI-specific MIPs were used to strengthen any claims made from the quantitative assessment. ROI-specific MIPs were further used to judge small vessel segmentation qualitatively. Further, for a single ROI, manual segmentation was done to further strengthen claims on small vessel segmentation quantitatively and qualitatively (see
Figure 7). Imperfection in the annotations as well as manual segmentation of a single ROI prevented a detailed quantitative comparison of small vs. medium to large-scale segmentation performance by, i.e., stratifying the vessels by their diameter. This is mainly due to false positives, i.e., noise in the segmentation and vessel discontinuities which would be a considerable bias in any diameter-specific comparison of segmentation methods.
Furthermore, the models were evaluated for robustness against different MR image artefacts by performing artefact testing—shown in
Appendix A. It was revealed that the models are not robust to random spikes but are robust against random noise and random bias fields.
8. Conclusions
The proposed network uses a modified version of U-Net Multi-Scale Supervision (MSS) architecture with deformations, which makes it equivariant to elastic deformations. The evaluation of this proposed approach was performed for the task of small vessel segmentation from MR angiograms. The training and testing of the model were performed using a 7T MRA dataset with a resolution of 300 µm. Segmentation of 7T MRA is highly relevant as it can help in the detection of cerebral small vessel disease. The proposed method was compared against non-machine learning methods, such as the Frangi filter and the MSFDF pipeline, as well as against Deep learning methods, such as U-Net and Attention U-Net. The proposed method outperformed all these baseline methods while being trained using a small, imperfectly labelled (noisy) dataset. It could be observed that the models with deformation consistency significantly outperformed the ones without. When the models were trained with only one volume, deformation-aware models could maintain vessel continuity better than their counterparts without deformation-aware learning. As the dataset labels were imperfect, the improvements achieved by the proposed model (U-Net MSS + Deformation) can be observed clearer when the results were compared against manually segmented ROI, where U-Net MSS achieved 52.17 and 62.07 Dice scores, with and without deformation, respectively. This research has shown that the proposed modified U-Net MSS with deformation-aware learning outperformed the baseline methods, and deformation-aware learning outperformed models without deformation-awareness. Furthermore, it can be said that the current trained network of the proposed method can be employed to perform vessel segmentation on 7T MRA. The network can be fine-tuned and also used for 1.5T and 3T MRA images. The possibility of training the proposed DS6 approach on a small dataset for the task of vessel segmentation has been demonstrated here. This might also be applicable for other tasks to combat the small training dataset problem. The code of this research is publicly available on GitHub
https://github.com/soumickmj/DS6, accessed on 15 September 2022).
In future work, the authors aim to explore further generalisability of the model by performing mixed training with different resolutions (150 µm, 300 µm and 450 µm) and with different field strengths (1.5T, 3T and 7T). Moreover, trainings will be performed using MIP as an additional loss term to try to improve the continuity of vessels. Experiments can also be performed by training the network from scratch by using the network’s predicted output as labels, as they are better than the original imperfect annotations. Furthermore, introspection on how deformation-aware learning is helping the models learn different shapes of vessels is also another interesting future direction of work. Finally, the superiority of the proposed method while training on a small dataset and its applicability in segmentation tasks with different sizes of regions of interest, as observed in this research, makes it interesting to apply to other image segmentation tasks where requirements are similar.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











