
HOSVD-Based Algorithm for Weighted Tensor Completion


Abstract
:1. Introduction
1.1. Contributions
1.2. Organization
2. Related Work, Background, and Problem Statement
2.1. Matrix Completion
2.2. Tensor Completion Problem
- (1)
- (2)
- (3)
- Under what conditions can one expect to achieve a unique and exact completion (see e.g., [34])?
2.2.1. Preliminaries and Notations
- Outer product: Let . The outer product among these n vectors is a tensor defined as:The tensor is of rank one if it can be written as the outer product of n vectors.
- Kronecker product of matrices: The Kronecker product of and is denoted by . The result is a matrix of size defined by
- Khatri-Rao product: Given matrices and , their Khatri-Rao product is denoted by . The result is a matrix of size defined bywhere and stand for the i-th column of A and B respectively.
- Hadamard product: Given , their Hadamard product is defined by element-wise multiplication, i.e.,
- Mode-k product: Let and , the multiplication between on its mode-k with U is denoted as with
2.2.2. CP-Based Method for Tensor Completion
2.2.3. HOSVD-Based Method for Tensor Completion
- Unfold along mode k to obtain matrix ;
- Find the economic SVD decomposition of ;
- Set to be the first columns of ;
- .
2.2.4. Tensor Completion Problem under Study
| Problem: Weighted Universal Tensor Completion Parameters:
Goal: Design an efficient algorithm with the following guarantees:
|
3. Main Results
3.1. General Upper Bound
3.2. Results for Weighted HOSVD Algorithm
3.2.1. General Upper Bound for Weighted HOSVD
3.2.2. Case Study: When
- Upper bound: Then the following holds with high probability.For our weighted HOSVD algorithm , for any Tucker tensor with , returns so that with high probability over the choice of ,where and .
- Lower bound: If additionally, is flat (the entries of are close), then for our weighted HOSVD algorithm , there exists some so that with probability at least over the choice of ,where , , and is some constant to measure the “flatness" of .
4. Experiments
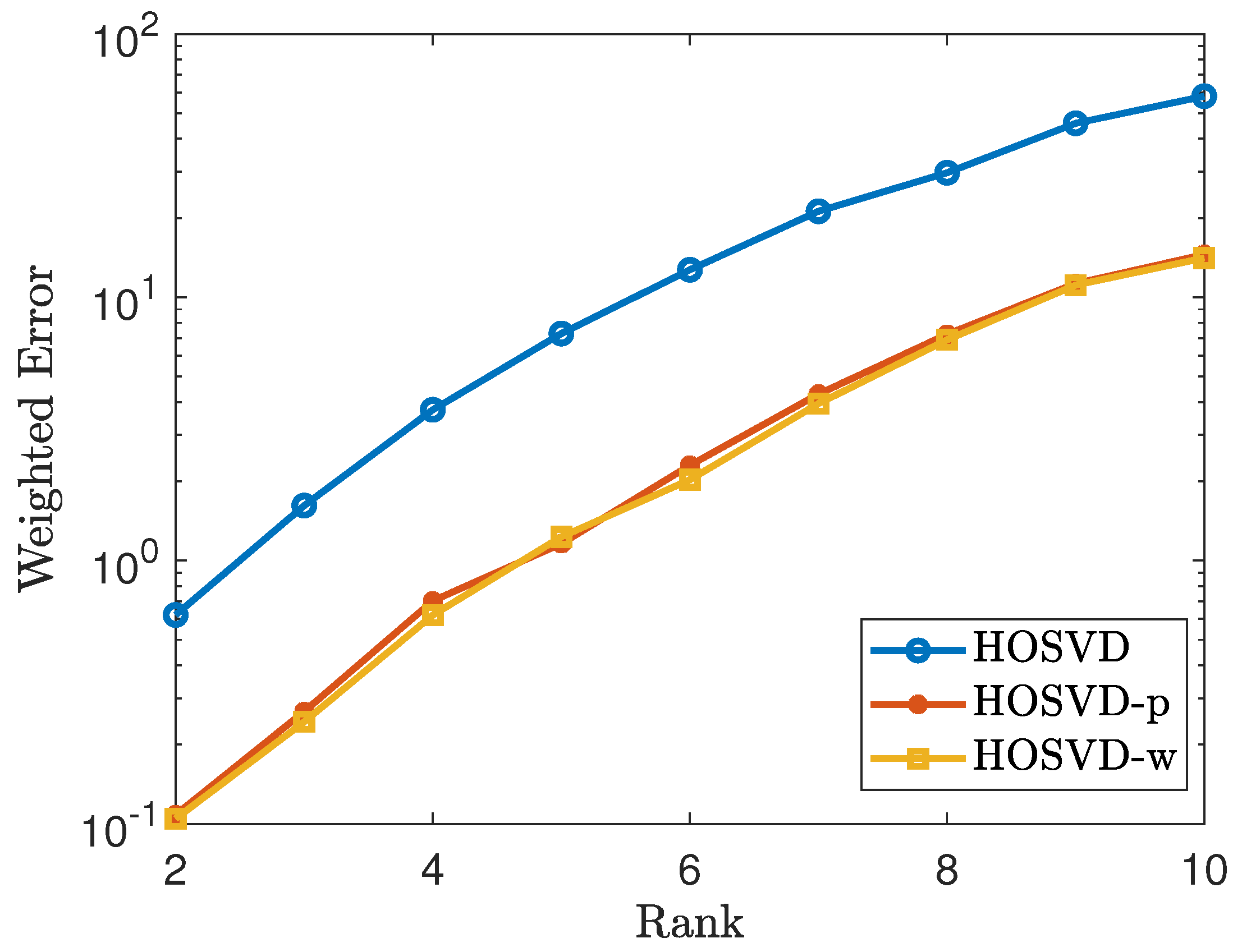
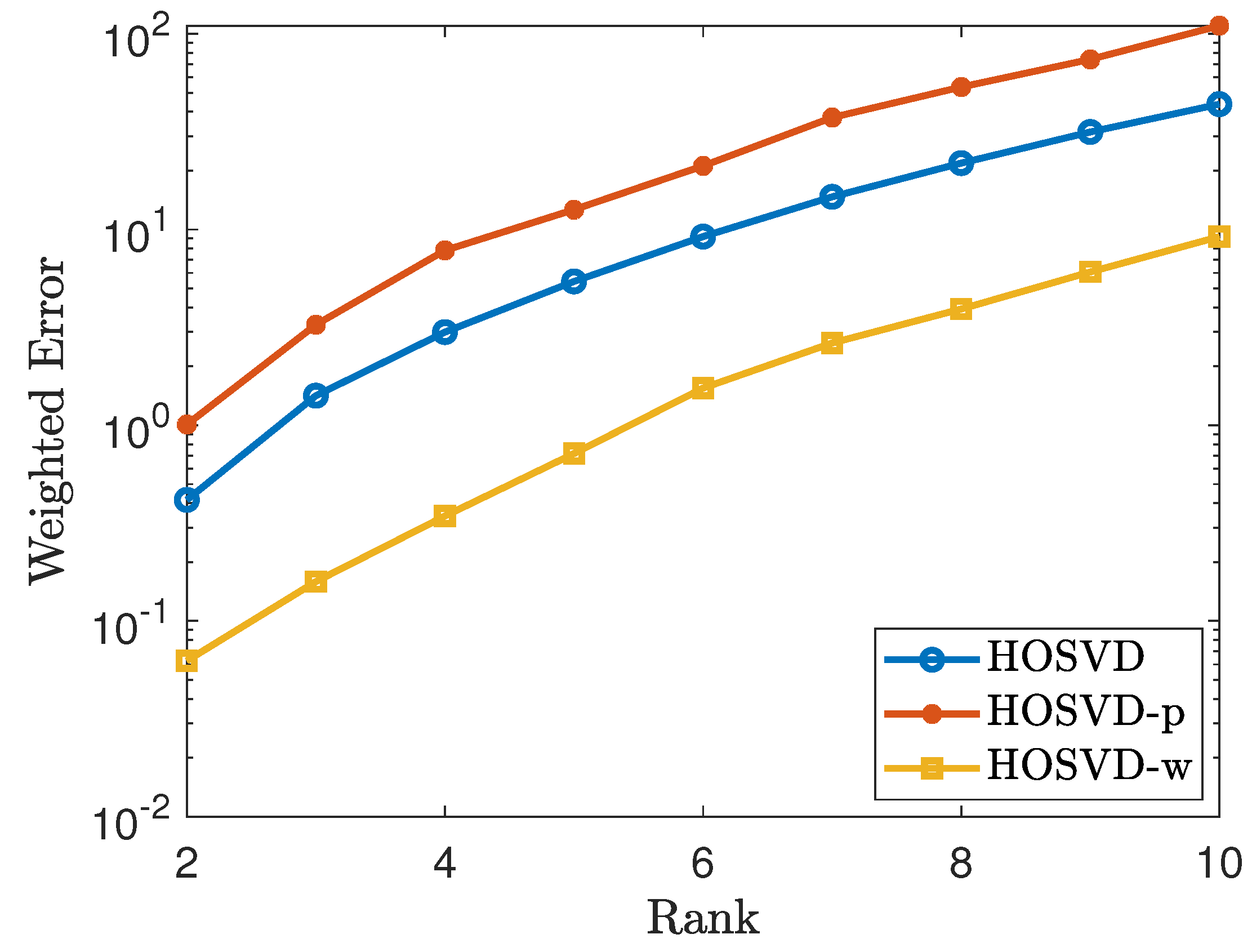
4.1. Simulations for Uniform Sampling Pattern
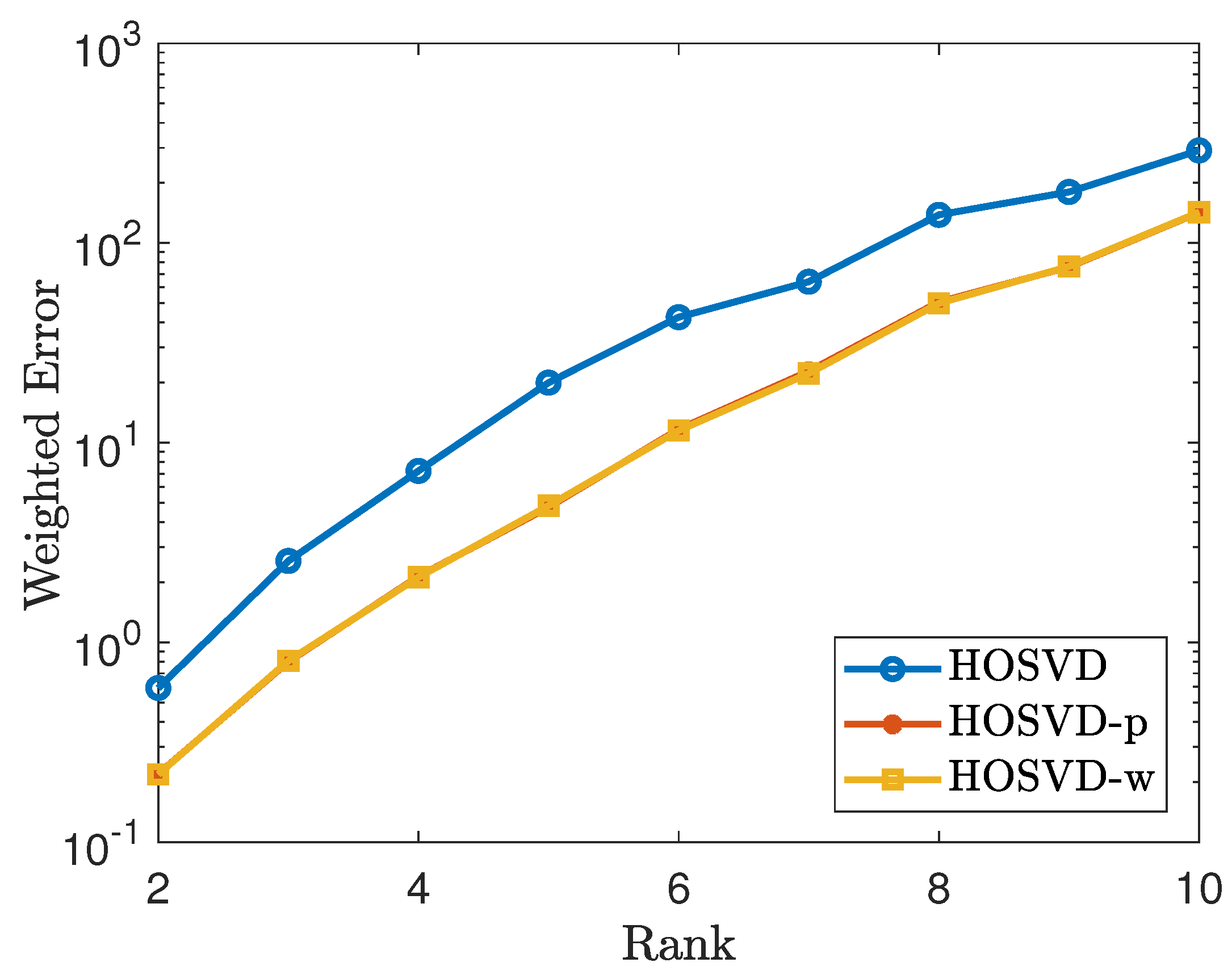
4.2. Simulation for Non-Uniform Sampling Pattern
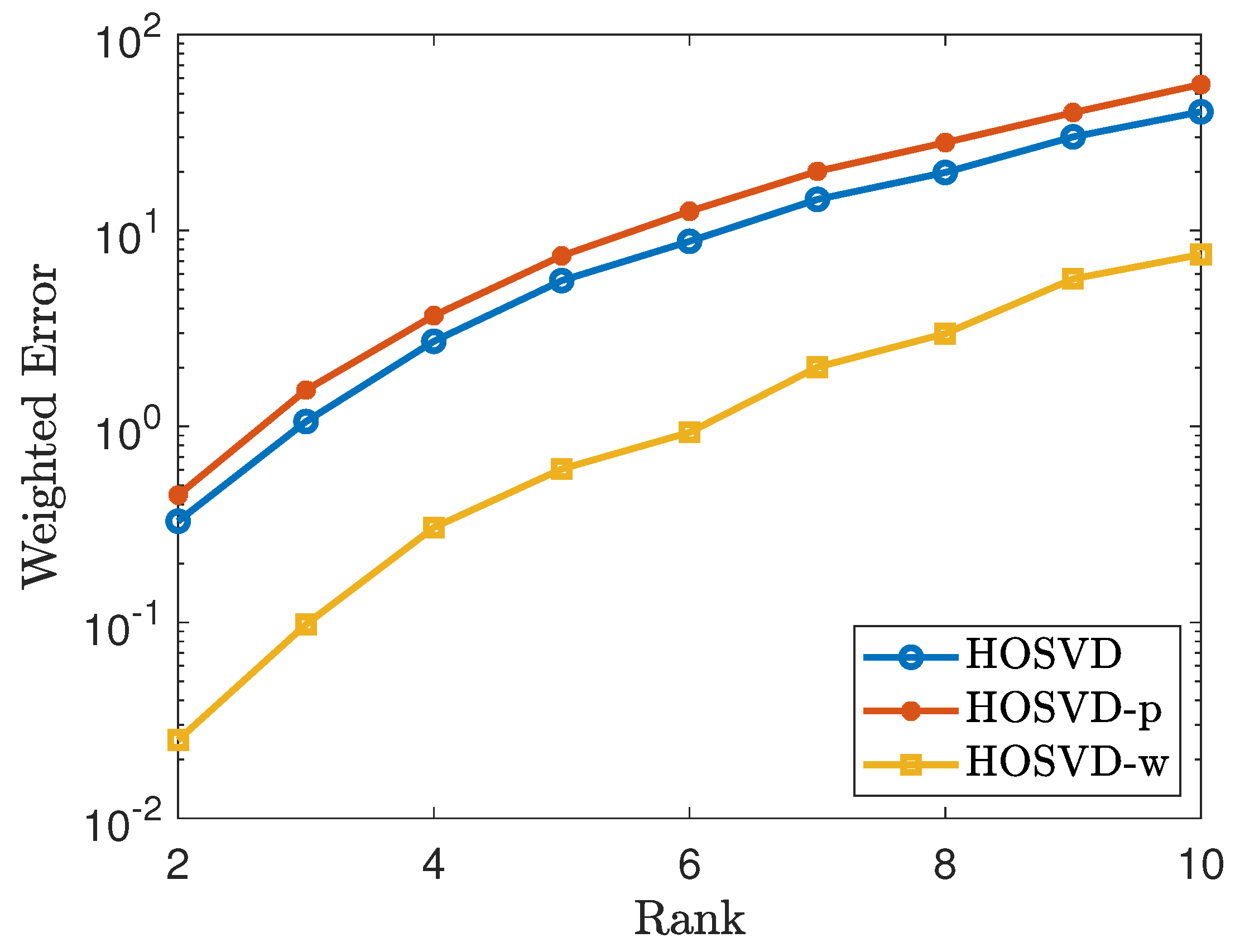
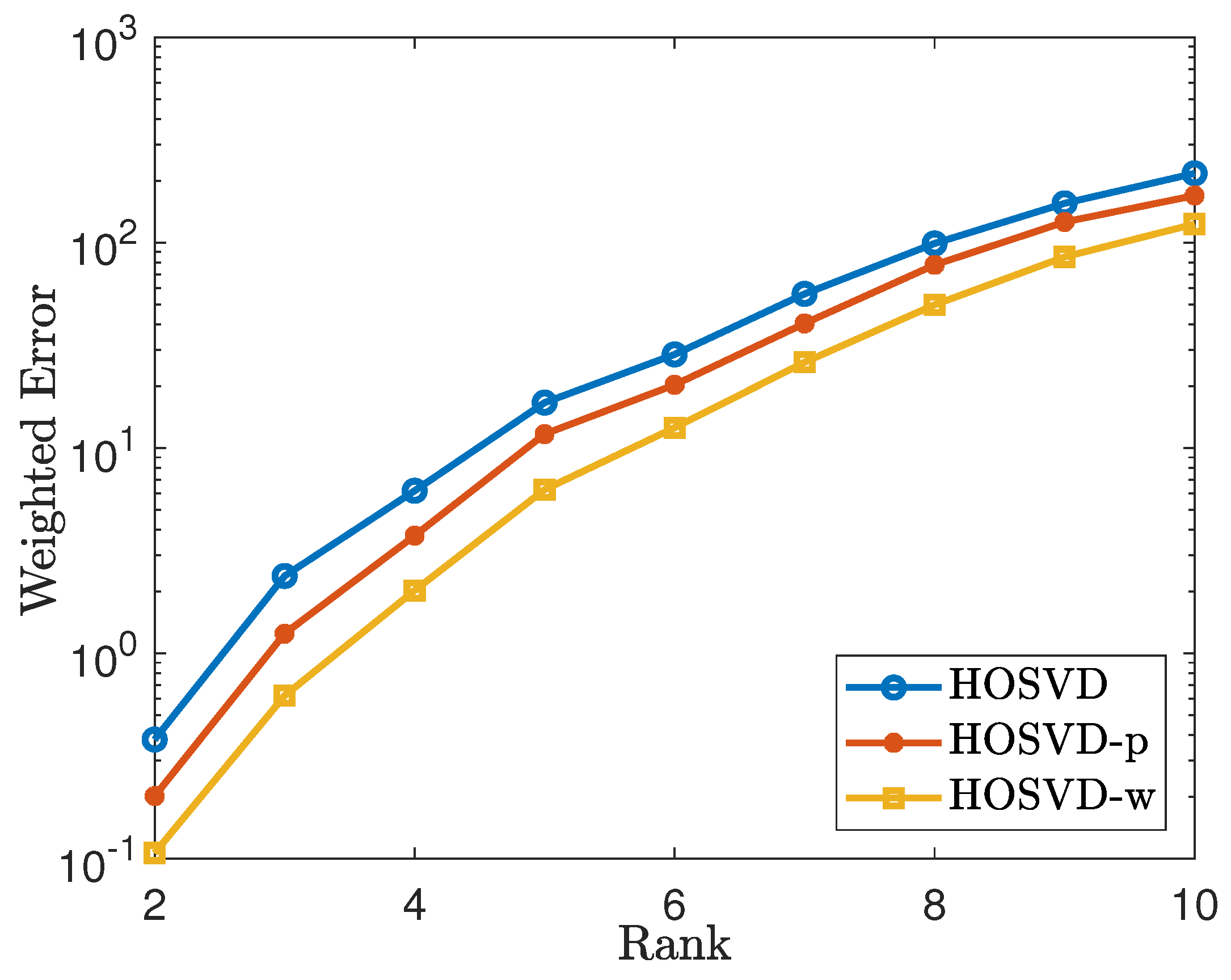
4.3. Test for Real Data
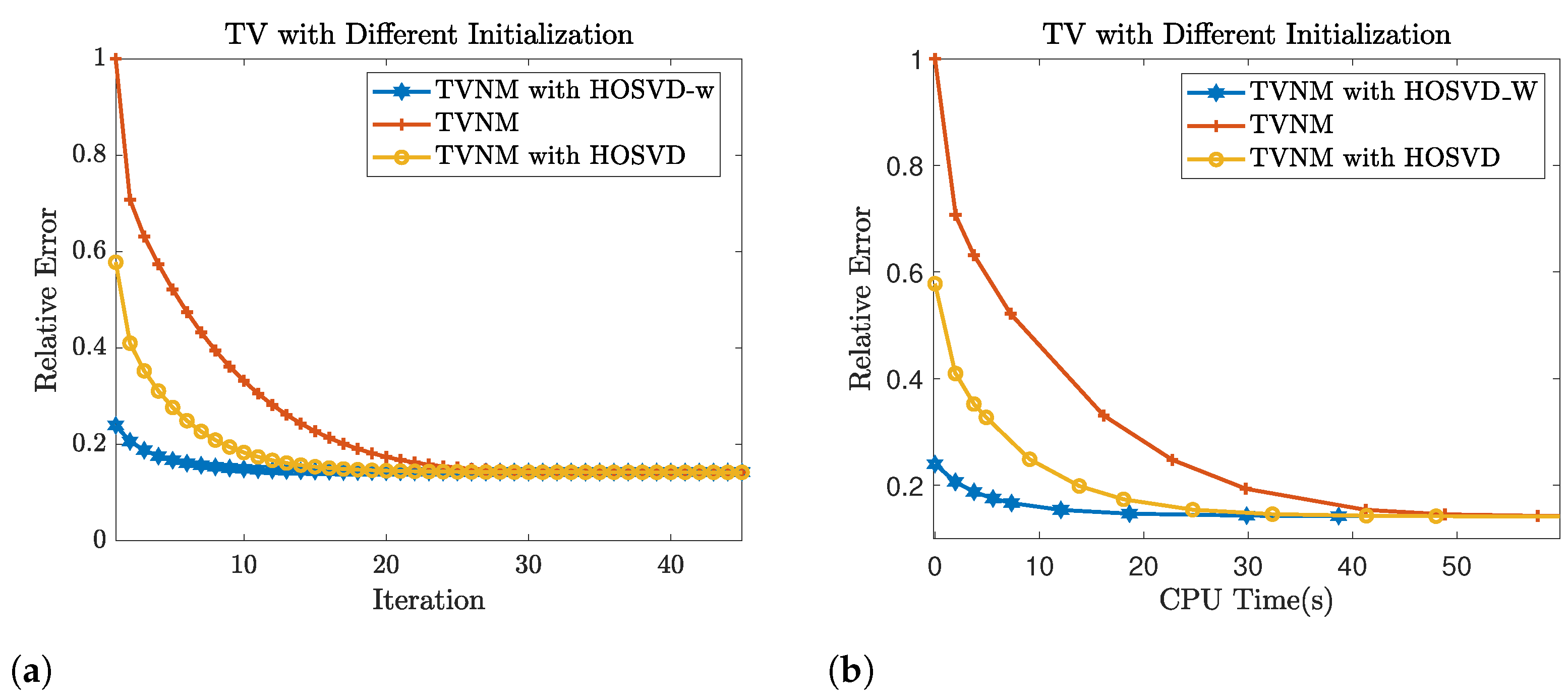
4.4. The Application of Weighted HOSVD on Total Variation Minimization
| Algorithm 1: TV Minimization for Tensor. |
 |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof for Theorem 1
Appendix B. Proof of Theorems 2 and 3
Appendix B.1. General Upper Bound for Weighted HOSVD Algorithm
Appendix B.2. Case Study: Ω∼W
Appendix B.2.1. Upper Bound
Appendix B.2.2. Lower Bound
- The set has size , for
- for all .
- for all .
- (a)
- (b)
References
- Hitchcock, F.L. The expression of a tensor or a polyadic as a sum of products. J. Math. Phys. 1927, 6, 164–189. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Zare, A.; Ozdemir, A.; Iwen, M.A.; Aviyente, S. Extension of PCA to higher order data structures: An introduction to tensors, tensor decompositions, and tensor PCA. Proc. IEEE 2018, 106, 1341–1358. [Google Scholar] [CrossRef] [Green Version]
- Ge, H.; Caverlee, J.; Zhang, N.; Squicciarini, A. Uncovering the spatio-temporal dynamics of memes in the presence of incomplete information. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 1493–1502. [Google Scholar]
- Liu, J.; Musialski, P.; Wonka, P.; Ye, J. Tensor completion for estimating missing values in visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 208–220. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Shang, F.; Cheng, H.; Cheng, J.; Tong, H. Factor matrix trace norm minimization for low-rank tensor completion. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014; pp. 866–874. [Google Scholar]
- Song, Q.; Ge, H.; Caverlee, J.; Hu, X. Tensor Completion Algorithms in Big Data Analytics. ACM Trans. Knowl. Discov. Data 2019, 13, 1–48. [Google Scholar] [CrossRef]
- Kressner, D.; Steinlechner, M.; Vandereycken, B. Low-rank tensor completion by Riemannian optimization. BIT Numer. Math. 2014, 54, 447–468. [Google Scholar] [CrossRef] [Green Version]
- Ermiş, B.; Acar, E.; Cemgil, A.T. Link prediction in heterogeneous data via generalized coupled tensor factorization. Data Min. Knowl. Discov. 2015, 29, 203–236. [Google Scholar] [CrossRef]
- Symeonidis, P.; Nanopoulos, A.; Manolopoulos, Y. Tag recommendations based on tensor dimensionality reduction. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 43–50. [Google Scholar]
- Cai, J.F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Cai, T.T.; Zhou, W.X. Matrix completion via max-norm constrained optimization. Electron. J. Stat. 2016, 10, 1493–1525. [Google Scholar] [CrossRef]
- Candes, E.J.; Plan, Y. Matrix completion with noise. Proc. IEEE 2010, 98, 925–936. [Google Scholar] [CrossRef] [Green Version]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717. [Google Scholar] [CrossRef] [Green Version]
- Amit, Y.; Fink, M.; Srebro, N.; Ullman, S. Uncovering shared structures in multiclass classification. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 17–24. [Google Scholar]
- Cai, H.; Cai, J.F.; Wang, T.; Yin, G. Accelerated Structured Alternating Projections for Robust Spectrally Sparse Signal Recovery. IEEE Trans. Signal Process. 2021, 69, 809–821. [Google Scholar] [CrossRef]
- Gleich, D.F.; Lim, L.H. Rank aggregation via nuclear norm minimization. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 60–68. [Google Scholar]
- Liu, Z.; Vandenberghe, L. Interior-point method for nuclear norm approximation with application to system identification. SIAM J. Matrix Anal. Appl. 2009, 31, 1235–1256. [Google Scholar] [CrossRef]
- Foucart, S.; Needell, D.; Pathak, R.; Plan, Y.; Wootters, M. Weighted matrix completion from non-random, non-uniform sampling patterns. IEEE Trans. Inf. Theory 2020, 67, 1264–1290. [Google Scholar] [CrossRef]
- Bhojanapalli, S.; Jain, P. Universal matrix completion. arXiv 2014, arXiv:1402.2324. [Google Scholar]
- Heiman, E.; Schechtman, G.; Shraibman, A. Deterministic algorithms for matrix completion. Random Struct. Algorithms 2014, 45, 306–317. [Google Scholar] [CrossRef]
- Li, Y.; Liang, Y.; Risteski, A. Recovery guarantee of weighted low-rank approximation via alternating minimization. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2358–2367. [Google Scholar]
- Pimentel-Alarcón, D.L.; Boston, N.; Nowak, R.D. A characterization of deterministic sampling patterns for low-rank matrix completion. IEEE J. Sel. Top. Signal Process. 2016, 10, 623–636. [Google Scholar] [CrossRef] [Green Version]
- Shapiro, A.; Xie, Y.; Zhang, R. Matrix completion with deterministic pattern: A geometric perspective. IEEE Trans. Signal Process. 2018, 67, 1088–1103. [Google Scholar] [CrossRef] [Green Version]
- Ashraphijuo, M.; Aggarwal, V.; Wang, X. On deterministic sampling patterns for robust low-rank matrix completion. IEEE Signal Process. Lett. 2017, 25, 343–347. [Google Scholar] [CrossRef] [Green Version]
- Ashraphijuo, M.; Wang, X.; Aggarwal, V. Rank determination for low-rank data completion. J. Mach. Learn. Res. 2017, 18, 3422–3450. [Google Scholar]
- Pimentel-Alarcón, D.L.; Nowak, R.D. A converse to low-rank matrix completion. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 96–100. [Google Scholar]
- Chatterjee, S. A deterministic theory of low rank matrix completion. arXiv 2019, arXiv:1910.01079. [Google Scholar]
- Király, F.J.; Theran, L.; Tomioka, R. The algebraic combinatorial approach for low-rank matrix completion. arXiv 2012, arXiv:1211.4116. [Google Scholar]
- Eftekhari, A.; Yang, D.; Wakin, M.B. Weighted matrix completion and recovery with prior subspace information. IEEE Trans. Inf. Theory 2018, 64, 4044–4071. [Google Scholar] [CrossRef] [Green Version]
- Negahban, S.; Wainwright, M.J. Restricted strong convexity and weighted matrix completion: Optimal bounds with noise. J. Mach. Learn. Res. 2012, 13, 1665–1697. [Google Scholar]
- Lee, T.; Shraibman, A. Matrix completion from any given set of observations. In Proceedings of the Advances in Neural Information Processing Systems, Red Hook, NY, USA, 5–10 December 2013; pp. 1781–1787. [Google Scholar]
- Gandy, S.; Recht, B.; Yamada, I. Tensor completion and low-n-rank tensor recovery via convex optimization. Inverse Probl. 2011, 27, 025010. [Google Scholar] [CrossRef] [Green Version]
- Ashraphijuo, M.; Wang, X. Fundamental conditions for low-CP-rank tensor completion. J. Mach. Learn. Res. 2017, 18, 2116–2145. [Google Scholar]
- Barak, B.; Moitra, A. Noisy tensor completion via the sum-of-squares hierarchy. In Proceedings of the Conference on Learning Theory, New York, NY, USA, 23–26 June 2016; pp. 417–445. [Google Scholar]
- Jain, P.; Oh, S. Provable tensor factorization with missing data. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1431–1439. [Google Scholar]
- Goldfarb, D.; Qin, Z. Robust low-rank tensor recovery: Models and algorithms. SIAM J. Matrix Anal. Appl. 2014, 35, 225–253. [Google Scholar] [CrossRef] [Green Version]
- Mu, C.; Huang, B.; Wright, J.; Goldfarb, D. Square deal: Lower bounds and improved relaxations for tensor recovery. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 73–81. [Google Scholar]
- Hitchcock, F.L. Multiple invariants and generalized rank of a p-way matrix or tensor. J. Math. Phys. 1928, 7, 39–79. [Google Scholar] [CrossRef]
- Kruskal, J.B. Rank, decomposition, and uniqueness for 3-way and N-way arrays. In Multiway Data Analysis; North-Holland Publishing Co.: Amsterdam, The Netherlands, 1989; pp. 7–18. [Google Scholar]
- Acar, E.; Yener, B. Unsupervised multiway data analysis: A literature survey. IEEE Trans. Knowl. Data Eng. 2008, 21, 6–20. [Google Scholar] [CrossRef]
- Sidiropoulos, N.D.; De Lathauwer, L.; Fu, X.; Huang, K.; Papalexakis, E.E.; Faloutsos, C. Tensor decomposition for signal processing and machine learning. IEEE Trans. Signal Process. 2017, 65, 3551–3582. [Google Scholar] [CrossRef]
- Carroll, J.D.; Chang, J.J. Analysis of individual differences in multidimensional scaling via an N-way generalization of “Eckart-Young” decomposition. Psychometrika 1970, 35, 283–319. [Google Scholar] [CrossRef]
- Bro, R. PARAFAC. Tutorial and applications. Chemom. Intell. Lab. Syst. 1997, 38, 149–172. [Google Scholar] [CrossRef]
- Kiers, H.A.; Ten Berge, J.M.; Bro, R. PARAFAC2—Part I. A direct fitting algorithm for the PARAFAC2 model. J. Chemometr. 1999, 13, 275–294. [Google Scholar] [CrossRef]
- Tomasi, G.; Bro, R. PARAFAC and missing values. Chemom. Intell. Lab. Syst. 2005, 75, 163–180. [Google Scholar] [CrossRef]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef] [Green Version]
- Kroonenberg, P.M.; De Leeuw, J. Principal component analysis of three-mode data by means of alternating least squares algorithms. Psychometrika 1980, 45, 69–97. [Google Scholar] [CrossRef]
- Fang, Z.; Yang, X.; Han, L.; Liu, X. A sequentially truncated higher order singular value decomposition-based algorithm for tensor completion. IEEE Trans. Cybern. 2018, 49, 1956–1967. [Google Scholar] [CrossRef] [PubMed]
- Niebles, J.C.; Chen, C.W.; Li, F.F. Modeling temporal structure of decomposable motion segments for activity classification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 392–405. [Google Scholar]
- Ravichandran, A.; Chaudhry, R.; Vidal, R. Dynamic Texture Toolbox. 2011. Available online: http://www.vision.jhu.edu (accessed on 10 May 2021).
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, Q.; Jin, J.; Shen, Y. Structure tensor total variation-regularized weighted nuclear norm minimization for hyperspectral image mixed denoising. Signal Process. 2017, 131, 202–219. [Google Scholar] [CrossRef]
- Madathil, B.; George, S.N. Twist tensor total variation regularized-reweighted nuclear norm based tensor completion for video missing area recovery. Inf. Sci. 2018, 423, 376–397. [Google Scholar] [CrossRef]
- Yao, J.; Xu, Z.; Huang, X.; Huang, J. Accelerated dynamic MRI reconstruction with total variation and nuclear norm regularization. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 635–642. [Google Scholar]
- Wang, Y.; Peng, J.; Zhao, Q.; Leung, Y.; Zhao, X.L.; Meng, D. Hyperspectral image restoration via total variation regularized low-rank tensor decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1227–1243. [Google Scholar] [CrossRef] [Green Version]
- Ji, T.Y.; Huang, T.Z.; Zhao, X.L.; Ma, T.H.; Liu, G. Tensor completion using total variation and low-rank matrix factorization. Inf. Sci. 2016, 326, 243–257. [Google Scholar] [CrossRef]
- Li, X.; Ye, Y.; Xu, X. Low-rank tensor completion with total variation for visual data inpainting. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Chao, Z.; Huang, L.; Needell, D. Tensor Completion through Total Variation with Initialization from Weighted HOSVD. In Proceedings of the Information Theory and Applications, San Diego, CA, USA, 2–7 February 2020. [Google Scholar]
- Tropp, J.A. User-friendly tail bounds for sums of random matrices. Found. Comput. Math. 2012, 12, 389–434. [Google Scholar] [CrossRef] [Green Version]
- Lancaster, P.; Farahat, H. Norms on direct sums and tensor products. Math. Comp. 1972, 26, 401–414. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video | SR | Input Rank | HOSVD-w+TV | HOSVD | HOSVD-w/HOSVD-p | TVM |
|---|---|---|---|---|---|---|
 | 10% | 13.29 (16.3 s) | 1.27 (3.74 s) | 10.15 (11.4 s) | 13.04 (41.3 s) | |
| 30% | 16.96 (14.0 s) | 4.26 (4.01 s) | 12.05 (7.23 s) | 17.05 (29.7 s) | ||
| 50% | 19.60 (12.2 s) | 8.21 (2.99 s) | 14.59 (7.03 s) | 19.68 (23.8 s) | ||
| 80% | 24.90 (11.5 s) | 17.29 (6.55 s) | 19.75 (8.08 s) | 25.01 (18.1 s) | ||
 | 10% | 10.98 (13.1 s) | 1.19 (4.20 s) | 7.88 (8.76 s) | 10.89 (42.2 s) | |
| 30% | 14.44 (16.1 s) | 4.11 (3.80 s) | 10.40 (7.51 s) | 14.50 (31.4 s) | ||
| 50% | 16.95 (15.3 s) | 7.85 (5.86 s) | 12.84 (7.64 s) | 16.96 (26.6 s) | ||
| 80% | 22.21 (15.1 s) | 16.51 (7.24 s) | 18.64 (8.45 s) | 22.19 (18.4 s) | ||
 | 10% | 12.34 (16.1 s) | 1.22 (2.73 s) | 8.46 (9.88 s) | 12.23 (45.7 s) | |
| 30% | 17.10 (15.3 s) | 4.24 (3.17 s) | 11.62 (7.62 s) | 17.19 (35.3 s) | ||
| 50% | 20.44 (12.3 s) | 8.20 (3.92 s) | 14.54 (5.85 s) | 20.49 (28.9 s) | ||
| 80% | 26.80 (12.4 s) | 18.03 (8.40 s) | 21.38 (8.93s) | 26.71 (20.9 s) |
| Video | SR | Input Rank | HOSVD | HOSVD-w | HOSVD-p |
|---|---|---|---|---|---|
 | 10% | 1.09 | 10.07 | 5.56 | |
| 30% | 3.74 | 11.81 | 7.53 | ||
| 50% | 7.05 | 13.22 | 10.73 | ||
| 80% | 15.76 | 19.60 | 17.39 | ||
 | 10% | 1.13 | 8.04 | 4.33 | |
| 30% | 3.79 | 10.13 | 6.80 | ||
| 50% | 7.15 | 12.57 | 10.14 | ||
| 80% | 14.81 | 18.55 | 16.31 | ||
 | 10% | 1.09 | 8.31 | 4.73 | |
| 30% | 3.76 | 11.05 | 6.87 | ||
| 50% | 7.18 | 13.78 | 9.99 | ||
| 80% | 15.88 | 20.82 | 16.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chao, Z.; Huang, L.; Needell, D. HOSVD-Based Algorithm for Weighted Tensor Completion. J. Imaging 2021, 7, 110. https://doi.org/10.3390/jimaging7070110
Chao Z, Huang L, Needell D. HOSVD-Based Algorithm for Weighted Tensor Completion. Journal of Imaging. 2021; 7(7):110. https://doi.org/10.3390/jimaging7070110
Chicago/Turabian StyleChao, Zehan, Longxiu Huang, and Deanna Needell. 2021. "HOSVD-Based Algorithm for Weighted Tensor Completion" Journal of Imaging 7, no. 7: 110. https://doi.org/10.3390/jimaging7070110