1. Introduction
For decades, the evolution of image retrieval approaches was mainly supported by the development of novel features for representing the visual content. Other relevant stages of the retrieval pipeline were often neglected [
1]. Even in the era of deep learning-based features, retrieval systems often perform comparisons by computing measures which consider only pairs of images and ignore the relevant information encoded in the relationships among images. Traditionally, such measures are defined based on pairwise dissimilarities between features represented in a high dimensional Euclidean space [
2].
To go beyond pairwise analysis, post-processing methods have been proposed with the aim of increasing the effectiveness retrieval tasks without the need for user intervention [
3,
4,
5,
6]. Such unsupervised methods aim at replacing similarities between pairs of images by globally defined measures, capable of analyzing collections in terms of the underlying data manifold, i.e., in the context of other objects [
2,
4].
Diversified context-sensitive methods have been exploited by post-processing approaches for retrieval tasks. Among them, two categories can be highlighted as very representative of existing methods:
diffusion processes [
3,
7,
8] and
rank-based approaches [
6,
9,
10]. The most common diffusion processes are inspired by random walks [
5], and therefore supported by a strong mathematical background. Very significant improvements to retrieval performance have been achieved by such methods [
3,
7,
8]. However, they often require high computational efforts, mainly due to the asymptotic complexity associated with matrices multiplication or inversion procedures.
More recently, rank-based methods also have attracted a lot of attention, mainly due to relevant similarity information encoded in the ranked lists [
11,
12]. While the rank-based strategies also achieve very significant effectiveness gains, such methods lack a theoretical basis and convergence aspects are mainly based on empirical analysis [
13]. On the other hand, a positive aspect is related to the low computational costs required. Most of relevant similarity information is located at top rank positions, reducing the amount of data which needs to be processed and enabling the development of efficient algorithms [
14]. In fact, efficiency aspects assumed a relevant role last years for both diffusion and rank-based methods, especially regarding its application to query images outside of the dataset [
15,
16].
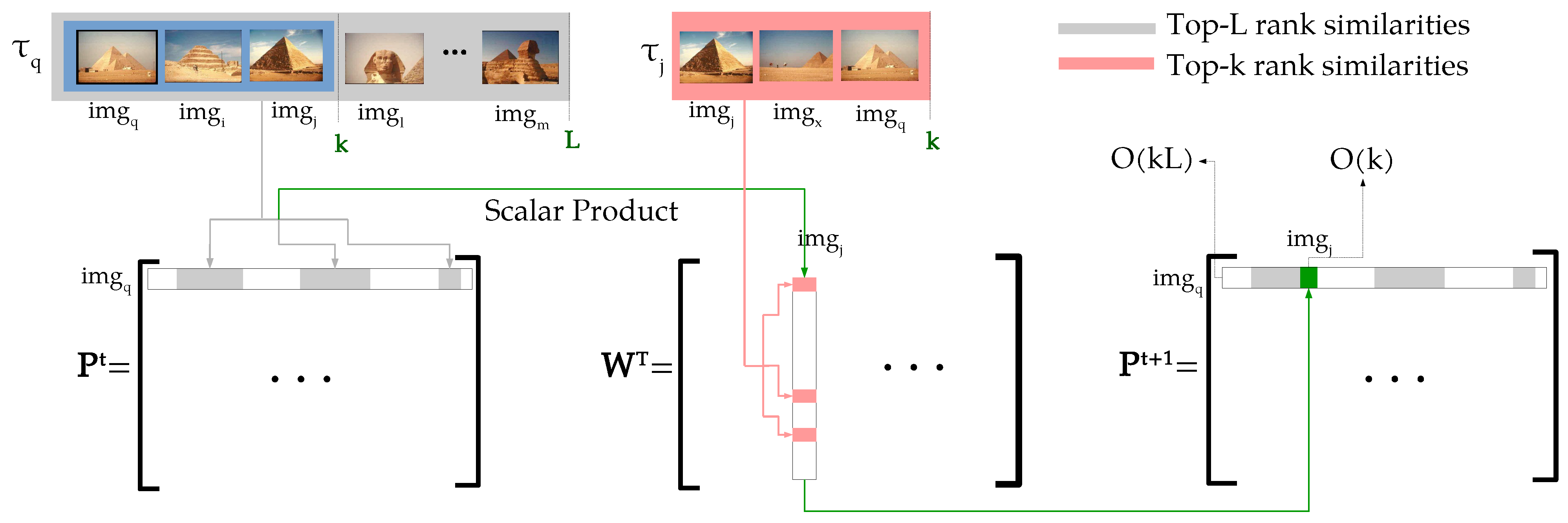
In this paper, we propose a diffusion process completely defined in terms of ranking information. The method is capable of approximating a diffusion process based only on the top positions of ranked lists, while assures its convergence. Therefore, since it combines diffusion and rank-based approaches, both efficiency and theoretical requirements are met. The main contributions of this work are three-fold and can be summarized as follows:
Efficiency and Complexity Aspects: traditionally, diffusion processes compute the elements of affinity matrices through successive multiplications, considering all the collection images. To reduce the computational costs, sparse affinity matrices [
8] are employed for the first iteration. However, there is no guarantees that the multiplied matrices are also sparse and classic diffusion methods do not know in advance where the non-zero values appear in the matrices computed over the iterations. Therefore, a full multiplication of
time complexity is required for each iteration. In opposite, the proposed method keeps the sparsity of matrices by computing only a small subset of affinities, which are indexed through rank information. First, the proposed method derives a novel similarity measure based only on top-
k ranking information. Then, only the matrix positions indexed by the top-
L rank positions (
) are computed. Inspired by [
9,
17], the overlap between ranked lists and, equivalently, between elements of rows/columns being multiplied is considered.
Figure 1 illustrates this process for computing a matrix row, with sparsity depicted in white. The operation is constrained to top-
L rank positions with time complexity of
, and therefore
for each row (with
L constant), and hence
for all rows, i.e., the whole dataset. Therefore, the method computes only a small subset of operations required by diffusion processes, reducing the conventional time complexity for the whole dataset from
to
.
Theoretical Aspects: while convergence is an aspect well-defined and widely studied for diffusion processes [
5,
18], the same cannot be said about rank-based approaches. In fact, the use of classic proofs for rank-based approaches is not straight-forward and the convergence is still an open topic when considering rank information [
19], only analyzed through empirical studies [
13]. Once the connection between diffusion and rank-based methods is formally established, we discuss the extension of convergence properties from diffusion to the proposed rank-based approach. To the best of our knowledge, this is the first work which presents a formal proof of convergence of rank-based methods.
Unseen Query Images: most of both diffusion and ranked-based methods, consider the query image to be contained in the dataset. Alternatively, a query image can be included in the dataset at query time. However, even an efficient algorithm of
is unfeasible to be executed on-line for larger datasets. A more recent research trend consists on post-processing approaches for efficiently dealing with unseen queries at query time [
15,
16]. The proposed method also allows its use for unseen queries through a simple regional diffusion constrained to top-
L rank positions of the query, which can be computed in
.
An extensive experimental evaluation was conducted considering different retrieval scenarios. The evaluation for general image retrieval tasks was conducted on 6 public datasets and several features, including global (shape, color, and texture), local, and convolution-neural-network-based features. The performance on Person reidentification (re-ID) tasks was also evaluated on two recent datasets using diverse features. The proposed method achieves very significant gains, reaching up to +40% of relative gain on image retrieval and +50% on person re-ID tasks. Comparisons with various recent methods on different datasets were also conducted and the proposed algorithm yields comparable or superior performance to state-of-the-art approaches.
The remainder of this paper is organized as follows.
Section 2 discusses the relationship between diffusion, rank-based and the proposed approach.
Section 3 formally defines the proposed method, while
Section 4 discusses complexity aspects and presents an efficient algorithmic solution.
Section 5 describes the conducted experimental evaluation and, finally,
Section 6 discusses the conclusions.
2. Diffusion, Rank-Based, and the Proposed Method
Diffusion is one of the most widely spread processes in science [
17,
20]. In the retrieval domain, diffusion approaches rely on the definition of a global measure, which describes the relationship between pairs of points in terms of their connectivity [
2,
3,
4]. In general, diffusion methods start from an affinity matrix, which establishes a similarity relationship among different dataset elements [
5].
Let
=
be an image collection of size
n =
. Let
denotes a
d-dimensional representation of an image
given by a feature extraction function, such that
. The dataset can be represented by a set
=
and the affinity matrix
among the elements is often computed by a Gaussian kernel as
where
is a parameter to be defined and the function
is commonly defined by the Euclidean distance
.
Most of the diffusion processes [
5] are mainly defined in terms of successive multiplications of affinity matrices, such that their high computational cost is mainly caused by the matrix multiplication operations. This is due to the fact that similarities to all images need to be computed, even those with very low similarity values, whose impact on retrieval results is very small. Additionally, even when sparse affinity matrices are considered, such sparsity is not guaranteed to be kept through the iterative matrices multiplications.
While the diffusion methods use the similarity measure computed based on visual features, the rank-based approaches exploit the similarity encoded in ranking information. The rank information is initially represented in terms of ranked lists, which are computed based on the distance function . One key advantage of rank-based models is due to the fact that top positions of ranked lists are expected to contain the most similar images to the query. Therefore, instead of full ranked lists which can be very time-consuming to compute according to the size of the dataset, only a subset (of a fixed size L) needs to be considered.
Formally, let be a ranked list computed in response to a query image . Let be a subset of the collection , such that and . The ranked list can be defined as a bijection from the set onto the set . The notation denotes the position (or rank) of image in the ranked list according to the distance . Hence, if the image is ranked before in the ranked list , i.e., , then (, ) ≤(, ).
In general, to compute a more global similarity measure between two images
and
, the rank-based methods exploit the similarity between their respective ranked lists
and
. Several distinct approaches have been proposed in order to model the rank similarity information. The asymmetry of the
k-neighborhood sets were exploited in various works [
10,
21,
22]. Rank correlation measures and similarity between neighborhood sets have also been successfully employed [
6,
23]. More recently, graph [
12,
24,
25] and hypergraph [
26] formulations have been used.
In terms of objectives and outputs, both approaches, diffusion and rank-based, are comparable in that both aim at obtaining more global similarity measures that are expected to produce more effective retrieval results. However, each category presents distinct advantages. While rank-based approaches focus on the similarity encoded in the top positions of ranked lists, reducing the computational cost, the diffusion approaches benefit from a strong mathematical background.
In this scenario, the Rank Diffusion Process with Assured Convergence (RDPAC) is proposed in this paper based on an efficient formulation capable of avoiding the computation of small and irrelevant similarity values. The main idea consists of exploiting the rank information to identify and index the high similarity values in the transition and affinity matrices. In this way, the method admits an efficient algorithmic solution capable of computing an effective approximation of diffusion processes. Mostly related to [
17], the proposed approach presents relevant novelties: a theoretical convergence analysis, a novel rank similarity measure, a post-diffusion reciprocal step and its capacity of dealing with unseen queries in on-line time. The proof of convergence of the method presented in this work is a topic which has not been addressed for other rank-based approaches. The proposed similarity considers only ranking information. This makes it robust to feature variations, and therefore, suitable for fusion tasks.
3. Rank Diffusion Process with Assured Convergence
The presentation of our method is organized in four main steps: (
i) a similarity measure is defined based on ranking information; (
ii) a normalization is conducted for improving the symmetry of ranking references; (
iii) the rank diffusion process is performed, requiring a small number of iterations; (
iv) a post-diffusion step is conducted for exploiting the reciprocal rank information. Each step is discussed and formally defined in the next sections in terms of matrix operations. The efficient algorithmic solutions are discussed in
Section 4.
3.1. Rank Similarity Measure
In this work, a novel approach is proposed for defining the affinity matrix
by using a rank-based strategy. Although we mentioned a common retrieval pipeline based on the Euclidean distance, the method requires only the ranked lists, such that any distance measure can be used. Based only on rank information, our approach defines a very sparse matrix and, at same time, allows predicting information about its sparsity. By exploiting the information about sparsity, it is possible to derive efficient algorithmic solutions (discussed in
Section 4).
Taking every image in the collection as a query, a set of ranked lists
=
can be obtained. Based on similarity information encoded on the set
, a rank similarity measure is defined. The confidence of similarity information reaches its maximum at top positions and decreases at increasing depths of ranked lists. Hence, a rank similarity measure is proposed by assigning weights to positions inspired by the Rank-Biased Overlap (RBO) [
27]. The RBO measure is based on a probabilistic model which considers the probability of a hypothetical user of keeping examining subsequent levels of the ranked list.
The affinity matrix can be computed according to the different sizes of ranked lists. Let
s denotes the size of ranked lists, the subscript notation
is used to refer to affinity matrix computed by considering the size
s. Each position of the matrix
is defined as follows:
where
p denotes a probability parameter.
In our method, the ranked list size s assumes two different values according to the step being executed. During the rank diffusion, the size is defined as , where k denotes the number of nearest neighbors (including the point itself). For the normalization, the size is defined as , defining a more comprehensive collection subset, although much smaller than n, i.e., .
In this way, both matrices
and
are very sparse, which allows an efficient algorithmic approximation of the diffusion process. Beyond a novel formulation for the similarity measure, the rank information is exploited to identify high similarities positions in sparse matrices. By computing only such positions, a low complexity can be kept for the algorithm, which is one of key characteristics of the proposed approach, discussed in
Section 4.
3.2. Pre-Diffusion Rank Normalization
In contrast to most distance/similarity pairwise measures, the rank measures are not symmetric. Even if an image
is at top positions of a ranked list
, there is no guarantee that
is well ranked in
. As a result, different values are assigned to symmetric matrix elements, such that
, which can negatively affect the retrieval results. In fact, the benefits of improving the symmetry of the
k-neighborhood relationship are remarkable in image retrieval applications [
28].
Therefore, a pre-processing step based on reciprocal ranking information is conducted before the rank diffusion process. The reciprocal rank references have been exploited by other works, usually considering the information of rank position. In our approach the rank similarity measure described in the previous section is used.
The affinity matrix is computed by considering an intermediary size of ranked lists
. By slightly abusing the notation, from now on
denotes a symmetric version of
, i.e., we have
The number of non-zero entries per row in the so normalized matrix
is defined in the interval
, depending of the size of intersection among references and reciprocal rank references. Based on the normalized matrix
, the ranking information is updated through a re-sorting procedure. The ranked lists are re-sorted in descending order of affinity score, according to a stable sorting algorithm. The resultant normalized set of ranked lists
is used for the diffusion process, i.e., Equation (
2), and consequently,
used in next section is computed based on
.
We further column-wise normalize matrix
to a matrix
where
is a small constant to ensure that the sum of each column <1.
3.3. Rank Diffusion with Assured Convergence
To make the graph diffusion process independent from the number of iterations, accumulation of similarity values over iterations is widely used [
29]. For each iteration, the similarity information is diffused through a transition matrix
and added to the similarity information diffused in previous steps. We initialize the transition matrix
as
and define the iterative diffusion as
where
is a parameter in the interval (0,1) and
is the identity matrix. The accumulation of similarity values is achieved through the addition of the identity matrix as we will see in the next section. The addition of the identity matrix also contributes to convergence of the iterative process in (
5).
Given the asymmetry of the affinity matrix
, due to column-wise normalization in (
4), its transposition is used for considering the multiplication among corresponding rank similarity scores. A non-transposed matrix defines reciprocal rank relationships, which is performed as a post-diffusion step, as discussed in
Section 3.5.
3.4. Proof of Convergence
To prove the convergence of the iterative diffusion process in Equation (
5), we first consider its simpler variant defined as
where
.
As we show now, so defined
is guaranteed to converge. We can transform (
6) to
Due to the column-wise normalization of the matrix
, the sum of each row of
. This implies
, and consequently,
This proves the convergence of (
6) after a sufficient number of iterations. The convergence proof also applies to the diffusion process in Equation (
5). We do not use the closed form solution (
12) in our experiments, since the matrix inversion is computationally expensive. Both iterative processes accumulate diffused similarity values, and can be viewed as special instances of
where
is a graph affinity matrix. Under the assumption that the sum of each row of
, which implies that the spectral radius of
is smaller than one, (
13) converges to a fixed and nontrivial solution given by
, which makes independent of the number of iterations.
In contrast, the rank-based diffusion in [
17] represents the simplest realization of a diffusion process on a graph as it only computes powers of the graph matrix, i.e., the edge weights at time (or iteration)
t are given by
. Hence, this process is sensitive to the number of iterations [
29]. For example, if the sum of each row of
is smaller than one, then it converges to the zero matrix, in which case determining a right stopping time
t is critical. To avoid the convergence to zero matrix, a small value of
t is used as
.
3.5. Post-Diffusion Reciprocal Analysis
Despite of the relevant similarity information encoded in the reciprocal rank references, such information is not considered during the rank diffusion process. More specifically, for two images and , the diffusion step considers the information encoded in the rank similarity of and to another images contained in a shared k-neighborhood. The information about the rank similarity of these images to and is not exploited.
Let
be the final number of iterations used in (
5). To aggregate the reciprocal analysis over the gains already obtained by the diffusion process, a post-diffusion step is proposed. The result of the rank diffusion process given by matrix
is subsequently column normalized according to Equation (
4). The post-diffusion step is then computed as
The matrix
is squared for analyzing similarity between rows (ranked lists) versus columns (reciprocal references). Due to the asymmetry of rank-based matrices, the multiplication by the tranposition considers similarity between ranked lists, while the reciprocal ranking references are considered without the transposition. In contrast to Equation (
5), the multiplication for reciprocal analysis does not consider transposed matrices. The obtained
denotes the final result matrix which is used to define the similarity scores and the re-ranked retrieval results denoted by the set of ranked lists
.
3.6. Rank Fusion
Several different visual features have been proposed over recent decades aiming to mimic the inherent complexity associated with the visual human perception. However, given the myriad of available features, how to combine them so that their complementarity is well exploited becomes a key question. Our answer is to derive a rank fusion approach embedded in the diffusion process.
Let
be a set of visual features. Let
be the set of ranked lists computed for a given feature
. The rank diffusion is computed for each feature, in order to obtain a re-ranked set
. Based on such set of ranked lists, Equation (
2) is used to derive a rank similarity matrix, given by
, where
L denotes the size of ranked lists and
i stands for feature
. A fused similarity matrix
is defined as:
Finally, the fused similarity matrix is used to derive a novel set of ranked lists, which is submitted to the proposed rank diffusion process.
4. Efficiency and Complexity Aspects
In this section, we discuss and present algorithms for efficiently computing the main steps of the proposed method. Inspired by [
17], the algorithm identifies high similarities values indexed through ranking information according to top-
L positions, while discards the remaining information which results in the sparsity of the transition matrix
.
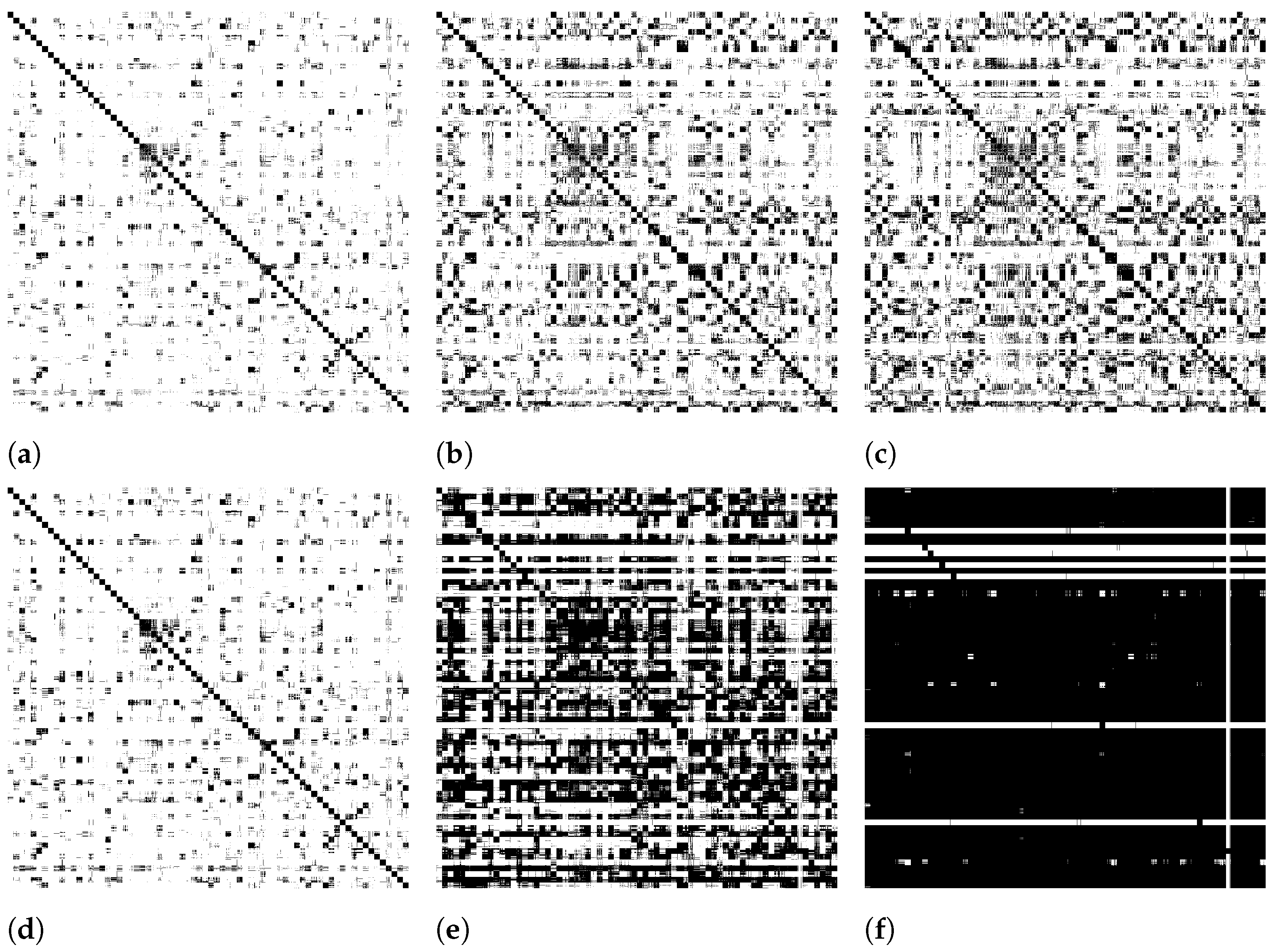
Figure 2 illustrates the impact of our approach on the sparsity along iterations. First line depicts the matrix
with a constrained top-
L diffusion, while the second line considers the whole dataset. In this way, the value of
L can be seen as a trade-off parameter between effectiveness and efficiency. As experimentally evaluated in
Section 5, the impact of lost information after top-
L is not significant, even for relatively small values of
L.
4.1. Efficient Algorithmic Solutions
For deriving the algorithms, we exploit a neighborhood set
, which contains the
s most similar images to a given image
. The first main step of the method consists in the computation of the affinity matrix
and its rank normalization. Algorithm 1 addresses the efficient computation of
constrained to top-
L rank positions according to Equation (
2).
| Algorithm 1 Rank Sim. Measure |
- Require:
Set of ranked lists , Parameter size L - Ensure:
Sparse matrix - 1:
for all do - 2:
for all do - 3:
- 4:
end for - 5:
end for
|
The efficient rank normalization is presented in Algorithm 2, which is equivalent to Equation (
3). Line 2 process aims at considering most of non-zero entries for each row, which can reach
. In general, presented algorithms follow the same principle of bounding the processing to the top ranking positions, which are used to discard sparse positions of matrix
and
.
| Algorithm 2 Rank Normalization |
- Require:
Set of ranked lists , matrix , Parameter L - Ensure:
Reciprocal normalized set of ranked lists - 1:
for all do - 2:
for all do - 3:
- 4:
end for - 5:
end for - 6:
|
The normalization procedures given by Equation (
4) are addressed in Algorithm 3. The same algorithm can be used for computing the normalization of matrix
before the reciprocal analysis, by using the constant
L instead of
k.
| Algorithm 3 Matrix Normalization |
- Require:
Matrix - Ensure:
Normalized Matrix - 1:
for all do - 2:
- 3:
end for - 4:
for all do - 5:
for all do - 6:
- 7:
end for - 8:
end for - 9:
for all do - 10:
for all do - 11:
- 12:
end for - 13:
end for
|
Algorithm 4 presents the proposed approach for computing the rank diffusion, defined by Equation (
5). It is the central element of the proposed method, and it is iterated
times. An analogous solution can be used to compute the post-diffusion reciprocal analysis, defined in Equation (
14).
| Algorithm 4 Rank Diffusion |
- Require:
Matrices and - Ensure:
Matrix - 1:
for all do - 2:
- 3:
for all do - 4:
ifthen - 5:
- 6:
end if - 7:
for all do - 8:
- 9:
end for - 10:
- 11:
end for - 12:
end for
|
4.2. Complexity Analysis
As discussed before, the diffusion processes typically exhibits an asymptotic complexity of , mainly due to successive matrices multiplications required. It occurs because both relevant and non-relevant similarity information are processed. In contrast, our approach exploits rank information, which allows the algorithms presented in the previous section to compute only relevant similarity scores.
The inputs are ranked lists, which can be computed by employing an efficient k-NN graph construction method with the NN-Descent algorithm [
30] or other recent approaches [
31,
32]. Based on the ranked lists, the sparse affinity matrix can be computed in
according to Algorithm 1. Since
L is a constant, only the loop in lines 1–5 depend on the number of elements in the dataset.
Algorithms 2 and 3 are also for analogous reasons. All the internal loops are constrained to constants L or k. The sorting step in Algorithm 2 is also performed until a constant L, being for each ranked list and for the whole dataset.
The most computationally expensive step is given by Algorithm 4. However, notice that loops in lines 3–11 and 7–9 are constrained to constants L and k, respectively, keeping the asymptotic complexity of . This algorithm is iterated times, where is also constant. Therefore, we can conclude that all the algorithms can be computed in .
4.3. Regional Diffusion for Unseen Queries
Let be an unseen query image, defined outside of the collection, such that . In fact, such situation represents a classical and common real-world image retrieval scenario. The objective is to efficiently obtain retrieval results re-ranked by the proposed diffusion process. The main idea of our solution is computing a regional diffusion, constrained only to the top-L images of the unseen query ranking.
Firstly, an initial neighborhood set
and a corresponding ranked list
can be obtained through an efficient k-NN search approach [
30,
31,
32]. The neighborhood set
is used to define a sub-collection
, such that
. Next, the set of pre-computed ranked lists for images in
are updated in order to contain only images of the sub-collection, removing the other images. Formally, let
be two images of the sub-collection. The updated ranked list
is defined as a bijection from the set
onto the set
. The position of image
in the ranked list
is defined as:
Once the ranked lists are updated, the Rank Diffusion Process is executed for the sub-collection in order to obtain the re-ranked retrieval results for the unseen query. As all the procedures are constrained to L, the time complexity is . As discussed in experimental section, the results can be obtained in on-line time without significant effectiveness losses in comparison to the global diffusion, defined for the whole collection.
6. Conclusions
In this work, we introduce a rank diffusion process for post-processing tasks in image retrieval scenarios. The proposed method embraces key advantages from both diffusion and ranked-based approaches, while avoiding most of their disadvantages. Formally defined as a diffusion process, the method is proved to converge, different from most of rank-based approaches. In addition, the method can be computed by low-complexity algorithms, in contrast to most diffusion methods. An extensive experimental evaluation demonstrates that significant effectiveness gains can be achieved on different retrieval tasks, considering various datasets and several visual features, evidencing the capacity of improving the retrieval results.
Concerning limitations, a relevant requirement of the proposed method consists of the need for computing the set of ranked lists for the images. Brute force strategies for computing the ranked lists can be unfeasible, especially for large-scale datasets. In this scenario, the use of the proposed method is limited to efficient approaches for obtaining the initial ranking results. Indexing and hashing approaches have been exploited for this objective. In our experimental evaluation, indexing approaches were used for larger datasets.
As future work, we intend to investigate if other diffusion methods for image retrieval can be efficiently computed by exploiting the proposed approach. In addition, we also intend to investigate the application of the proposed approach in other scenarios, which require efficient computation of successive multiplication matrix procedures, similar to diffusion processes.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}