
A Robust Machine Learning Model for Diabetic Retinopathy Classification



Abstract
:1. Introduction
2. Related Work
- The images with the same structure were removed after checking their similarity with the structural similarity index (SSIM). The redundant information has been eliminated in order to obtain clean and non-repetitive data.
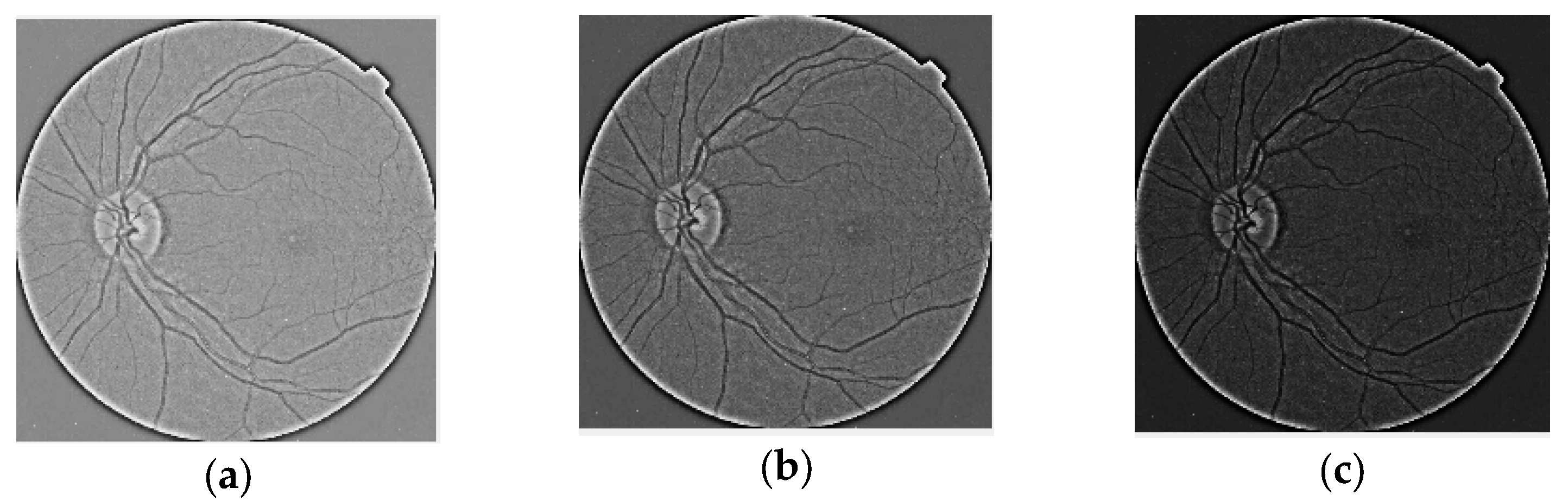
- We designed adjustment parameters by contrast as gamma correction and creating new image sets for each DR level.
- We computed Shannon and fuzzy entropies from all images.
- We implemented a fully automatic ensemble learning ML framework applicable to DR diagnosis and binary classification between NoDR/Mild, NoDR/Moderate, NoDR/Proliferate, and NoDR/Severe classes and extracting base classifiers.
- We developed the fastest, most accurate, and most reliable EL model for the DR level.
- The bootstrap statistical technique is used to validate the relevant model.
3. Materials and Methods
3.1. Dealing with Duplicate Images
3.2. Image Preprocessing and Feature Extractions
3.2.1. Image Preprocessing
3.2.2. Feature Extraction
- (1)
- Shannon entropy (SE) [28]:

3.2.3. AutoML with PyCaret
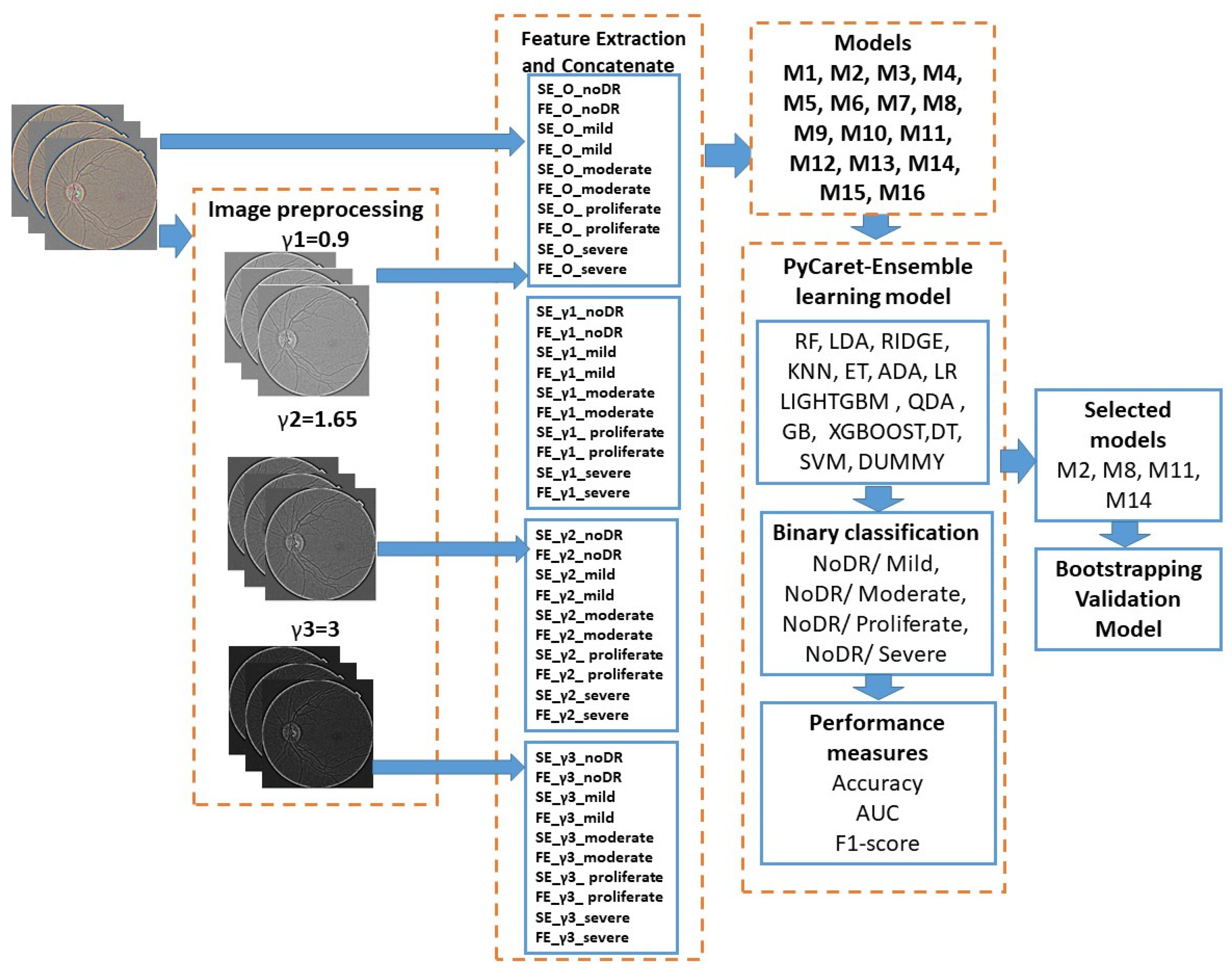
3.3. Proposed Methodology
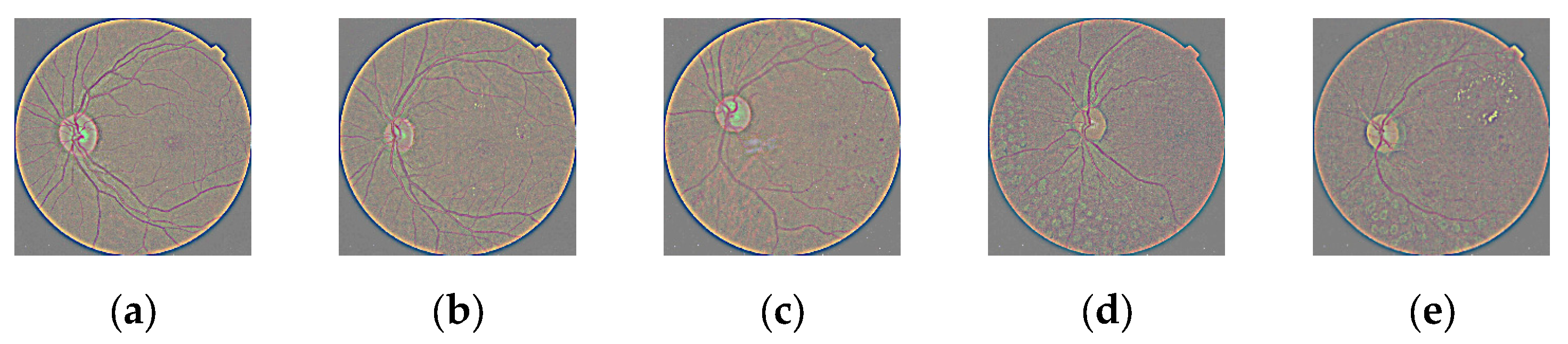
- Images were processed before manipulating contrast.
- Ten features were obtained for each image set after extracting the features. Four subblocks were created by computing these for each level of contrast, type of entropy, and level of DR. Table 2 stores the 16 models and features that were contained; these were extracted from the four subblocks, and in each model, we selected the features extracted from noDR and each level of DR disease.
- Fifteen MLs were fed with the features proposed in Table 2 for the ensemble learning process, which was performed with the PyCaret tool. After, extraction of the features, four groups of models occurred, as in Table 3. In terms of accuracy, the AUC and F1 score metrics were evaluated for binary classification (see Table 4).
- The last block consisted of an evaluation of each selected model (see Table 5) in the previous step with the bootstrapping statistical technique. In this sense, 100 subsets were generated, and these became new training datasets. Each new training dataset picked a sample of observations with a replacement from the original dataset; in this way, each selected classifier shown in bold in Table 5 was retrained 100 times for each subset, and the average of the generated accuracy across 100 bootstrap samples of the held-out test set was stored in order to validate the model. The best classifier was chosen based on the accuracy, area under the curve, and F1 score, and their connections are presented in Table 6.

{kind=link}
{kind=link}
{kind=link}
| Model Index | Features |
|---|---|
| M1 | SE_O_noDR. SE_O_mild, FE_O_noDR, FE_O_mild |
| M2 | SE_γ1_noDR, SE_γ1_mild, FE_γ1_noDR, FE_γ1_mild |
| M3 | SE_γ2_noDR, SE_γ2_mild, FE_γ2_noDR, FE_γ2_mild |
| M4 | SE_γ3_noDR, FE_γ3_noDR, SE_γ3_mild, FE_γ3_mild |
| M5 | SE_O_noDR, SE_O_proliferate, FE_O_noDR, FE_O_proliferate |
| M6 | SE_γ1_noDR, SE_γ1_proliferate, FE_γ1_noDR, FE_γ1_proliferate |
| M7 | SE_γ2_noDR, SE_γ2_proliferate, FE_γ2_noDR, FE_γ2_proliferate |
| M8 | SE_γ3_noDR, SE_γ3_proliferate, FE_γ3_noDR, FE_γ3_proliferate |
| M9 | SE_O_noDR, SE_O_severe, FE_O_noDR, FE_O_severe |
| M10 | SE_γ1_noDR, SE_γ1_severe, FE_γ1_noDR, FE_γ1_severe |
| M11 | SE_γ2_noDR, SE_γ2_severe, FE_γ2_noDR, FE_γ2_severe |
| M12 | SE_γ3_noDR, SE_γ3_severe, FE_γ3_noDR, FE_γ3_severe |
| M13 | SE_O_noDR, FE_O_noDR, SE_O_moderate, FE_O_moderate |
| M14 | SE_γ1_noDR, SE_γ1_moderate, FE_γ1_noDR, FE_γ1_moderate |
| M15 | SE_γ2_noDR, SE_γ2_moderate, FE_γ2_noDR, FE_γ2_moderate |
| M16 | SE_γ3_noDR, SE_γ3_moderate, FE_γ3_noDR, FE_γ3_moderate |
| Model Groups | Grouping Explanation |
|---|---|
| M1, M5, M9, M13 | Models are tested with features extracted from original images |
| M2, M6, M10, M14 | Models are tested with features extracted from images preprocessed with γ1 |
| M3, M7, M11, M15 | Models are tested with features extracted from images preprocessed with γ2 |
| M4, M7, M12, M16 | Models are tested with features extracted from images preprocessed with γ3 |
| Metrics | Explanations | Equations (True Positives (TP), the False Positives (FP), the True Negatives (TN) and the False Negatives (FN)) |
|---|---|---|
| Accuracy (ACC) | It shows how well the model correctly classified the different classes [32]. | |
| Area Under the Curve (AUC) | AUC is a measure of the performance of an estimator in binary classification problems [32]. | |
| F1 score | F1 score is computed with precision and recall, and it evaluates proposed method [32]. |
| Model Index | Classifier | Hyperparameters |
|---|---|---|
| M1 | LGBM | boosting_type = ‘gbdt’, learning_rate = 0.1, num_leaves = 31 |
| M2 | XGB | booster = ‘gbtree’, n_estimators = 100, |
| M3 | RF | criterion = ‘gini’, n_estimators = 100 |
| M4 | GBC | criterion = ‘friedman_mse’, n_estimators = 100, random_state = 123, |
| M5 | XGB | booster = ‘gbtree’, n_estimators = 100, |
| M6 | XGB | booster = ‘gbtree’, n_estimators = 100, |
| M7 | XGB | booster = ‘gbtree’ n_estimators = 100 |
| M8 | RF | criterion = ‘gini’, n_estimators = 100 |
| M9 | XGB | booster = ‘gbtree’ n_estimators = 100 |
| M10 | LIGHTGBM | boosting_type = ‘gbdt’, n_estimators = 100, num_leaves = 31, |
| M11 | GBC | criterion = ‘friedman_mse’, n_estimators = 100, random_state = 123, |
| M12 | KNN | algorithm = ‘ auto’, leaf_size = 30, metric = ‘minkowski’, n_neighbors = 5 |
| M13 | XGB | Booster = ‘gbtree’ n_estimators = 100 |
| M14 | LIGHTGBM | boosting_type = ‘gbdt’, n_estimators = 100, num_leaves = 31, |
| M15 | RF | criterion = ‘gini, n_estimators = 100, |
| M16 | KNN | algorithm = ‘auto’, leaf_size = 30, metric = ‘minkowski’, n_neighbors = 5 |
| Classes | Model | Accuracy | AUC | F1_Score |
|---|---|---|---|---|
| No_DR/moderate | M1 | 0.870 | 0.938 | 0.899 |
| M2 | 0.882 | 0.946 | 0.909 | |
| M3 | 0.880 | 0.942 | 0.906 | |
| M4 | 0.880 | 0.942 | 0.907 | |
| No_DR/proliferate | M5 | 0.917 | 0.927 | 0.683 |
| M6 | 0.917 | 0.937 | 0.686 | |
| M7 | 0.918 | 0.927 | 0.680 | |
| M8 | 0.922 | 0.953 | 0.702 | |
| No_DR/severe | M9 | 0.916 | 0.924 | 0.510 |
| M10 | 0.920 | 0.929 | 0.537 | |
| M11 | 0.929 | 0.941 | 0.902 | |
| M12 | 0.919 | 0.910 | 0.490 | |
| No_DR/mild | M13 | 0.916 | 0.949 | 0.746 |
| M14 | 0.925 | 0.942 | 0.779 | |
| M15 | 0.928 | 0.934 | 0.780 | |
| M16 | 0.918 | 0.947 | 0.757 |
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qummar, S.; Khan, F.G.; Shah, S.; Khan, A.; Shamshirband, S.; Rehman, Z.U.; Khan, I.A.; Jadoon, W. A deep learning ensemble approach for diabetic retinopathy detection. IEEE Access 2019, 7, 150530–150539. [Google Scholar] [CrossRef]
- Thomas, R.L.; Halim, S.; Gurudas, S.; Sivaprasad, S.; Owens, D.R. IDF Diabetes Atlas: A review of studies utilising retinal photography on the global prevalence of diabetes related retinopathy between 2015 and 2018. Diabetes Res. Clin. Pract. 2019, 157, 107840. [Google Scholar] [CrossRef] [PubMed]
- Steinmetz, J.D.; A Bourne, R.R.; Briant, P.S.; Flaxman, S.R.; Taylor, H.R.B.; Jonas, J.B.; Abdoli, A.A.; Abrha, W.A.; Abualhasan, A.; Abu-Gharbieh, E.G.; et al. Causes of blindness and vision impairment in 2020 and trends over 30 years, and prevalence of avoidable blindness in relation to VISION 2020: The Right to Sight: An analysis for the Global Burden of Disease Study. Lancet Glob. Health 2021, 9, e144–e160. [Google Scholar] [CrossRef] [PubMed]
- Jan, S.; Ahmad, I.; Karim, S.; Hussain, S.; Rehman, M.; Shah, M.A. Status of diabetic retinopathy and its presentation patterns in diabetics at ophthalomogy clinics. J. Postgrad. Med. Inst. 2018, 32, 2143. [Google Scholar]
- Dogra, M.R.; Katoch, D. Clinical features and characteristics of retinopathy of prematurity in developing countries. Ann. Eye Sci. 2018, 3, 1–7. [Google Scholar] [CrossRef]
- Dammann, O.; Hartnett, M.E.; Stahl, A. Retinopathy of Prematurity. Dev. Med. Child Neurol. 2023, 65, 625–631. [Google Scholar] [CrossRef]
- Mokbul, M.I. Optical coherence tomography: Basic concepts and applications in neuroscience research. J. Med. Eng. 2017, 2017, 3409327. [Google Scholar]
- Rehman, S.U.; Tu, S.; Shah, Z.; Ahmad, J.; Waqas, M.; Rehman, O.U.; Kouba, A.; Abbasi, Q.H. Deep Learning Models for Intelligent Healthcare: Implementation and Challenges. In Proceedings of the Artificial Intelligence and Security: 7th International Conference (ICAIS 2021), Dublin, Ireland, 19–23 July 2021; pp. 214–225. [Google Scholar]
- Latif, J.; Tu, S.; Xiao, C.; Rehman, S.U.; Sadiq, M.; Farhan, M. Digital forensics use case for glaucoma detection using transfer learning based on deep convolutional neural networks. Secur. Commun. Netw. 2021, 2021, 4494447. [Google Scholar] [CrossRef]
- Chatterjee, S.; Byun, Y.C. EEG-Based Emotion Classification Using Stacking Ensemble Approach. Sensors 2022, 22, 8550. [Google Scholar] [CrossRef]
- Wong, C.Y.; Liu, S.; Liu, S.C.; Rahman, M.A.; Lin, S.C.F.; Jiang, G.; Kwok, N.; Shi, H. Image contrast enhancement using histogram equalization with maximum intensity coverage. J. Mod. Opt. 2016, 63, 1618–1629. [Google Scholar] [CrossRef]
- Kong, T.L.; Isa, N.A.M. Enhancer-based contrast enhancement technique for non-uniform illumination and low-contrast images. Multimed. Tools Appl. 2017, 76, 14305–14326. [Google Scholar] [CrossRef]
- Rahman, S.; Rahman, M.M.; Abdullah-Al-Wadud, M.; Al-Quaderi, G.D.; Shoyaib, M. An adaptive gamma correction for image enhancement. Eurasip JIVP 2016, 10, 35. [Google Scholar] [CrossRef]
- Assegie, T.A.; Suresh, T.; Purushothaman, R.; Ganesan, R.; Kumar, N.K. Early Prediction of Gestational Diabetes with Parameter-Tuned K-Nearest Neighbor Classifier. J. Robot. Control 2023, 4, 452–458. [Google Scholar]
- Solkar, S.; Das, L. A New Approach for Detection and Classification of Diabetic Retinopathy Using PNN and SVM Classifiers. IOSR J. Comput. Eng. 2017, 19, 62–68. [Google Scholar]
- Pratt, H.; Coenen, F.; Broadbent, D.M.; Harding, S.P.; Zheng, Y. Convolutional neural networks for diabetic retinopathy. Procedia Comput. Sci. 2016, 90, 200–205. [Google Scholar] [CrossRef]
- Hemanth, D.J.; Deperlioglu, O.; Kose, U. An enhanced diabetic retinopathy detection and classification approach using deep convolutional neural network. Neural Comput. Appl. 2020, 32, 707–721. [Google Scholar] [CrossRef]
- Ai, Z.; Huang, X.; Fan, Y.; Feng, J.; Zeng, F.; Lu, Y. DR-IIXRN: Detection algorithm of diabetic retinopathy based on deep ensemble learning and attention mechanism. Front. Neuroinform. 2021, 15, 778552. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, S.; Chatterjee, A. Transfer-Ensemble Learning based Deep Convolutional Neural Networks for Diabetic Retinopathy Classification. arXiv 2023, arXiv:2308.00525. [Google Scholar]
- Nilashi, M.; Samad, S.; Yadegaridehkordi, E.; Alizadeh, A.; Akbari, E.; Ibrahim, O. Early detection of diabetic retinopathy using ensemble learning approach. J. Soft Comput. Decis. Support Syst. 2019, 6, 12–17. [Google Scholar]
- Sikder, N.; Masud, M.; Bairagi, A.K.; Arif, A.S.M.; Nahid, A.A.; Alhumyani, H.A. Severity Classification of Diabetic Retinopathy Using an Ensemble Learning Algorithm through Analyzing Retinal Images. Symmetry 2021, 13, 670. [Google Scholar] [CrossRef]
- Antal, B.; Hajdu, A. An ensemble-based system for automatic screening of diabetic retinopathy. Knowl.-Based Syst. 2014, 60, 20. [Google Scholar] [CrossRef]
- Alshayeji, M.H.; Abed, S.; Sindhu, S.C.B. Two-stage framework for diabetic retinopathy diagnosis and disease stage screening with ensemble learning. Expert Syst. Appl. 2023, 225, 120206. [Google Scholar] [CrossRef]
- Uppamma, P.; Bhattacharya, S. A multidomain bio-inspired feature extraction and selection model for diabetic retinopathy severity classification: An ensemble learning approach. Sci. Rep. 2023, 13, 18572. [Google Scholar] [CrossRef] [PubMed]
- Ramasamy, L.K.; Padinjappurathu, S.G.; Kadry, S.; Damaševičius, R. Detection of diabetic retinopathy using a fusion of textural and ridgelet features of retinal images and sequential minimal optimization classifier. PeerJ Comput. Sci. 2021, 7, e456. [Google Scholar] [CrossRef] [PubMed]
- Bakurov, I.; Buzzelli, M.; Schettini, R.; Castelli, M.; Vanneschi, L. Structural Similarity Index (SSIM) Revisited: A Data-Driven Approach. Expert Syst. Appl. 2022, 189, 116087. [Google Scholar] [CrossRef]
- Avci, E.; Avci, D. An expert system based on fuzzy entropy for automatic threshold selection in image processing. Expert Syst. Appl. 2009, 36, 3077–3085. [Google Scholar] [CrossRef]
- Aljanabi, M.A.; Hussain, Z.M.; Lu, S.F. An entropy-histogram approach for image similarity and face recognition. Math. Probl. Eng. 2018, 06, 9801308. [Google Scholar] [CrossRef]
- Tsai, Y.; Lee, Y.; Matsuyama, E. Information entropy measure for evaluation of image quality. J. Digit. Imaging 2008, 21, 338–347. [Google Scholar] [CrossRef]
- Versaci, M.; Morabito, F.C. Image edge detection: A new approach based on fuzzy entropy and fuzzy divergence. Int. J. Fuzzy Syst. 2021, 23, 918–936. [Google Scholar] [CrossRef]
- Porwal, P.; Pachade, S.; Kamble, R.; Kokare, M.; Deshmukh, G.; Sahasrabuddhe, V.; Meriaudeau, F. Indian Diabetic Retinopathy Image Dataset (IDRiD): A Database for Diabetic Retinopathy Screening Research. Data 2018, 3, 25. [Google Scholar] [CrossRef]
- Saleh, E.; Błaszczyński, J.; Moreno, A.; Valls, A.; Romero-Aroca, P.; de la Riva-Fernández, S.; Slowinschi, R. Learning ensemble classifiers for diabetic retinopathy assessment. Artif. Intell. Med. 2018, 85, 50–63. [Google Scholar] [CrossRef] [PubMed]
- Sabbir, M.M.H.; Sayeed, A.; Jamee, M.A.U.Z. Diabetic retinopathy detection using texture features and ensemble learning. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; Volume 7, pp. 178–181. [Google Scholar]
- Odeh, I.; Alkasassbeh, M.; Alauthman, M. Diabetic retinopathy detection using ensemble machine learning. IEEE Access 2021, 21, 12545. [Google Scholar]
- Du, J.; Zou, B.; Ouyang, P.; Zhao, R. Retinal microaneurysm detection based on transformation splicing and multi-context ensemble learning. Biomed. Signal Process. Control 2022, 74, 103536. [Google Scholar] [CrossRef]
- Luo, X.; Wang, W.; Xu, Y.; Lai, Z.; Jin, X.; Zhang, B.; Zhang, D. A deep convolutional neural network for diabetic retinopathy detection via mining local and long-range dependence. CAAI Trans. Intell. Technol. 2023. [Google Scholar] [CrossRef]


| References | Method | Strengths | Weakness |
|---|---|---|---|
| [1] | EL | Detecting duplicate images and removing them. | Has moderate accuracy and F-measure performance |
| [12] | KNN | Hyperparameters optimization is employed to tune | The performance is not effective. |
| [13] | Neural Network SVM | Segmentation of blood vessels in RD is performed. | The hyperparameters are not tuned The performance is not good enough for the accuracy. |
| [17] | CNN | Pre-trained convolutional neural networks is applied | CNNs are very time-consuming |
| [19] | EL | Selecting the important features and EL | The performance is not good enough for the accuracy. |
| [20] | EL | Emphasizes features extracted from anatomical components | The rest and training dataset do not contain the same preprocessing methods |
| [21] | EL | Proposed method is fully automatic using a bagging ensemble learning technique | Computationally expensive |
| [22] | NB, KNN, SVM, MP, RF, LR | These data were fed into a novel Modified Moth Flame Optimization-based feature selection | The hyperparameters are not tuned. |
| Reference and Year | Method | Dataset | Metrics |
|---|---|---|---|
| Porwal et al., 2018 [31]. | EL | SJRUH | 74.49 accuracy |
| Sabbir et al., 2020 [33]. | EL | MESSIDOR | 92.0% accuracy |
| Odeh et al., 2021 [34]. | EL | Messidor (InfoGainEval.) | 70.7% accuracy |
| Du et al., 2022 [35]. | EL | DiaretDB1 | 79.3% AUC |
| Luo et al., 2023 [36]. | CNNs | EyePACS datasets | 92.1% accuracy 96.7% AUC |
| Alshayeji et al., 2023 [23]. | EL (Boosted trees) | Kaggle EyePACS datasets | 91.7% accuracy |
| Ours (M11 model) | EL | IDRiD | 92.9% accuracy, 94.1% AUC 90.2% F1 score |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tăbăcaru, G.; Moldovanu, S.; Răducan, E.; Barbu, M. A Robust Machine Learning Model for Diabetic Retinopathy Classification. J. Imaging 2024, 10, 8. https://doi.org/10.3390/jimaging10010008
Tăbăcaru G, Moldovanu S, Răducan E, Barbu M. A Robust Machine Learning Model for Diabetic Retinopathy Classification. Journal of Imaging. 2024; 10(1):8. https://doi.org/10.3390/jimaging10010008
Chicago/Turabian StyleTăbăcaru, Gigi, Simona Moldovanu, Elena Răducan, and Marian Barbu. 2024. "A Robust Machine Learning Model for Diabetic Retinopathy Classification" Journal of Imaging 10, no. 1: 8. https://doi.org/10.3390/jimaging10010008