
Lily Database: A Comprehensive Genomic Resource for the Liliaceae Family

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sources and Data Processing
2.2. Marker Development
2.3. TF Gene Analysis
2.4. Expression Analysis
2.5. Database Architecture and Web Interface Design
3. Result and Discussion
3.1. Content of the Lily-Db
3.1.1. Germplasm Information
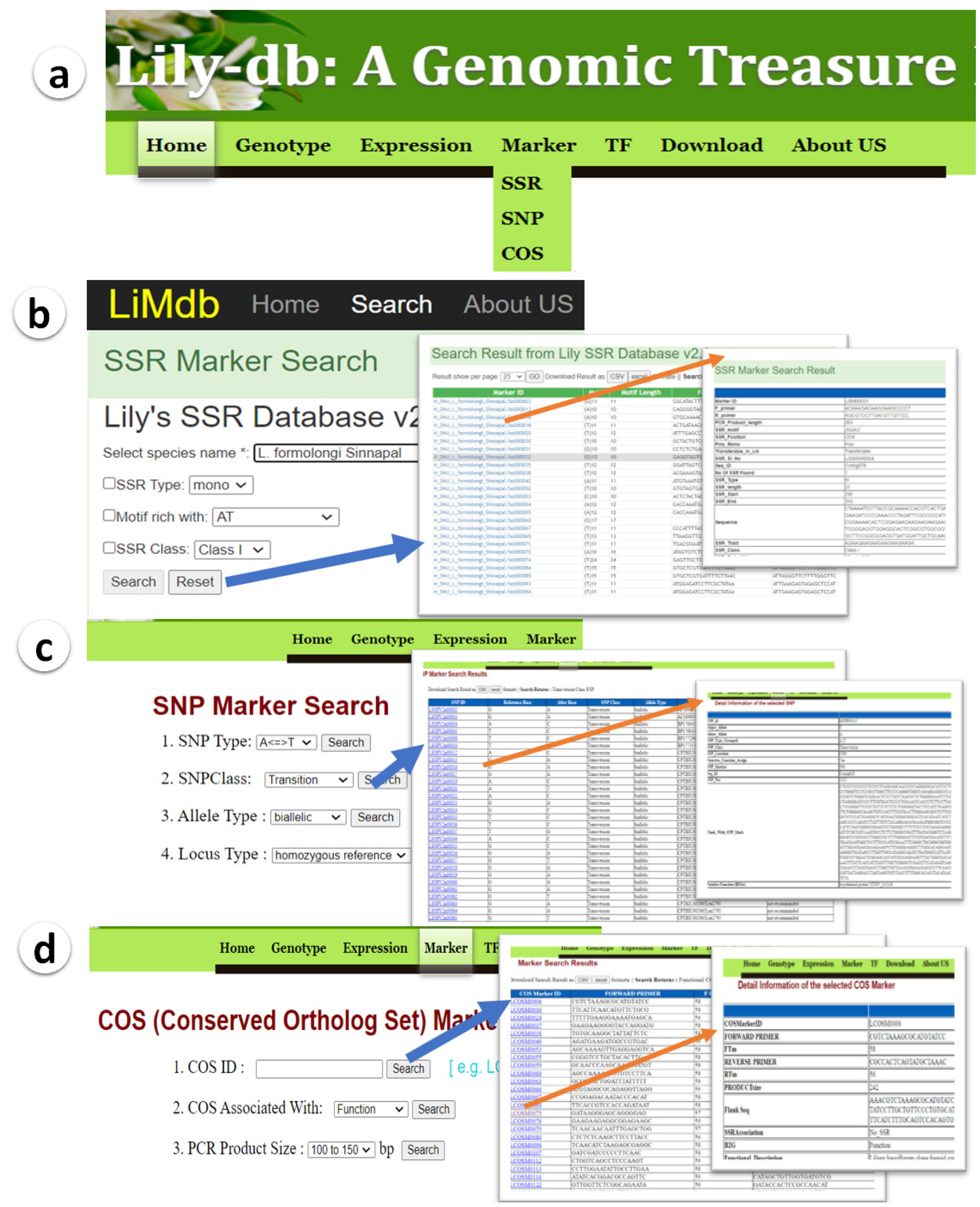
3.1.2. Molecular Markers Developments and Database Features
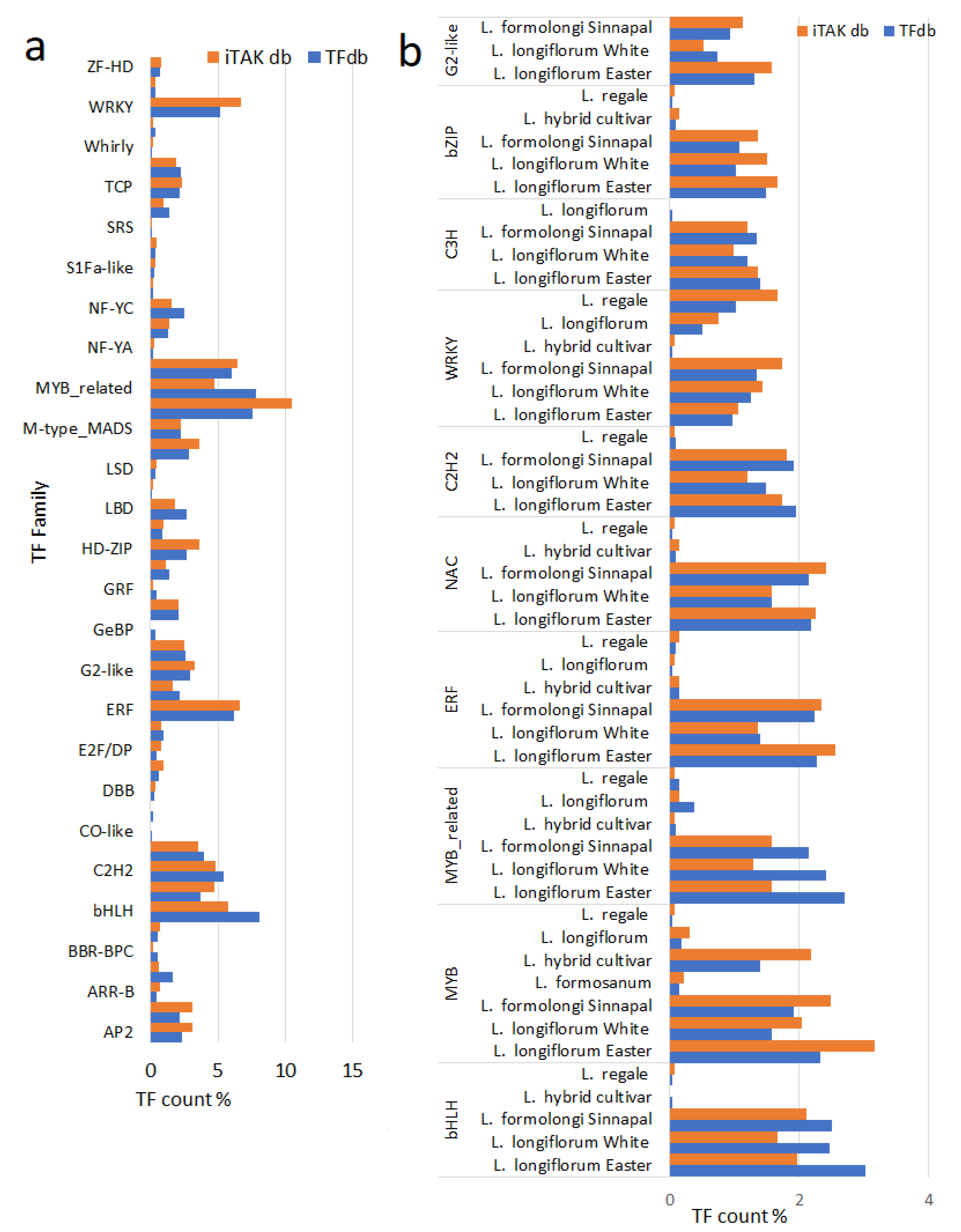
3.1.3. Transcription Factor Genes
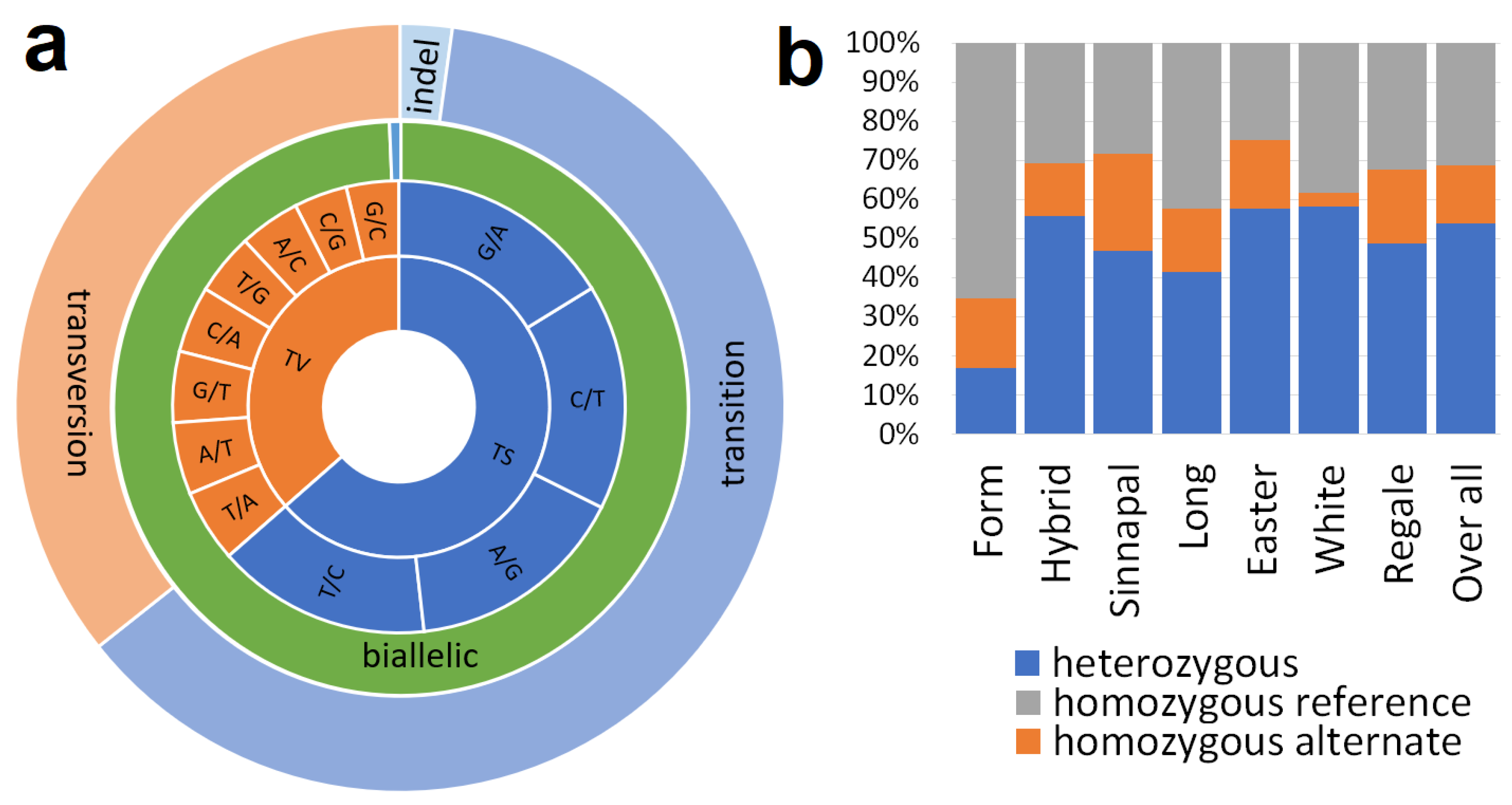
3.1.4. Gene Expression Data
3.2. Applications, Limitations and Future Directions
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Biswas, M.K.; Bagchi, M.; Nath, U.K.; Biswas, D.; Natarajan, S.; Jesse, D.M.I.; Park, J.; Nou, I. Transcriptome wide SSR discovery cross-taxa transferability and development of marker database for studying genetic diversity population structure of Lilium species. Sci. Rep. 2020, 10, 18621. [Google Scholar] [CrossRef] [PubMed]
- Angiosperm Phylogeny Group; Chase, M.W.; Christenhusz, M.J.; Fay, M.F.; Byng, J.W.; Judd, W.S.; Soltis, D.E.; Mabberley, D.J.; Sennikov, A.N.; Soltis, P.S. An update of the Angiosperm Phylogeny Group classification for the orders and families of flowering plants: APG IV. Bot. J. Linn. Soc. 2016, 181, 1–20. [Google Scholar] [CrossRef]
- Biswas, M.K.; Nath, U.K.; Howlader, J.; Bagchi, M.; Natarajan, S.; Kayum, M.A.; Kim, H.; Park, J.; Kang, J.; Nou, I. Exploration and exploitation of novel SSR markers for candidate transcription factor genes in Lilium species. Genes 2018, 9, 97. [Google Scholar] [CrossRef] [PubMed]
- Buschman, J. Globalisation-flower-flower bulbs-bulb flowers. In IX International Symposium on Flower Bulbs 673; ISHS: Leuven, Belgium, 2004; pp. 27–33. [Google Scholar]
- Wilford, R.; Gardens, K.R.B. The Kew Gardener s Guide to Growing Bulbs: The Art and Science to Grow Your Own Bulbs; White Lion Publishing: London, UK, 2019. [Google Scholar]
- Li, Y.; Zhang, L.; Wang, T.; Zhang, C.; Wang, R.; Zhang, D.; Xie, Y.; Zhou, N.; Wang, W.; Zhang, H. The complete chloroplast genome sequences of three lilies: Genome structure, comparative genomic and phylogenetic analyses. J. Plant Res. 2022, 135, 723–737. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Bi, Y.; Yang, F.; Zhang, M.; Chen, X.; Xue, J.; Zhang, X. Complete chloroplast genome sequences of Lilium: Insights into evolutionary dynamics and phylogenetic analyses. Sci. Rep. 2017, 7, 5751. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Yu, Y.; Deng, Y.; Li, J.; Huang, Z.; Zhou, S. The chloroplast genome of Lilium henrici: Genome structure and comparative analysis. Molecules 2018, 23, 1276. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Lee, S.I.; Kim, B.R.; Choi, I.Y.; Ryser, P.; Kim, N.S. Chloroplast genomes of Lilium lancifolium, L. amabile, L. callosum, and L. philadelphicum: Molecular characterization and their use in phylogenetic analysis in the genus Lilium and other allied genera in the order Liliales. PLoS ONE 2017, 12, e0186788. [Google Scholar]
- Howlader, J.; Robin, A.H.K.; Natarajan, S.; Biswas, M.K.; Sumi, K.R.; Song, C.Y.; Park, J.; Nou, I. Transcriptome analysis by rna–seq reveals genes related to plant height in two sets of parent-hybrid combinations in easter lily (Lilium longiflorum). Sci. Rep. 2020, 10, 9082. [Google Scholar] [CrossRef]
- Du, F.; Wu, Y.; Zhang, L.; Li, X.; Zhao, X.; Wang, W.; Gao, Z.; Xia, Y. De novo assembled transcriptome analysis and SSR marker development of a mixture of six tissues from Lilium Oriental hybrid ‘Sorbonne’. Plant Mol. Biol. Rep. 2015, 33, 281–293. [Google Scholar] [CrossRef]
- Sun, M.; Zhao, Y.; Shao, X.; Ge, J.; Tang, X.; Zhu, P.; Wang, J.; Zhao, T. EST–SSR Marker Development and Full-Length Transcriptome Sequence Analysis of Tiger Lily (Lilium lancifolium Thunb). Appl. Bionics Biomech. 2022, 2022, 7641048. [Google Scholar] [CrossRef]
- Droc, G.; Lariviere, D.; Guignon, V.; Yahiaoui, N.; This, D.; Garsmeur, O.; Dereeper, A.; Hamelin, C.; Argout, X.; Dufayard, J. The banana genome hub. Database 2013, 2013, bat035. [Google Scholar] [CrossRef]
- Fernandez-Pozo, N.; Menda, N.; Edwards, J.D.; Saha, S.; Tecle, I.Y.; Strickler, S.R.; Bombarely, A.; Fisher-York, T.; Pujar, A.; Foerster, H. The Sol Genomics Network (SGN)—From genotype to phenotype to breeding. Nucleic Acids Res. 2015, 43, D1036–D1041. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Wang, T.; He, X.; Cai, X.; Lin, R.; Liang, J.; Wu, J.; King, G.; Wang, X. BRAD V3. 0: An upgraded Brassicaceae database. Nucleic Acids Res. 2022, 50, D1432–D1441. [Google Scholar] [CrossRef] [PubMed]
- Jung, S.; Lee, T.; Cheng, C.; Zheng, P.; Bubble, K.; Crabb, J.; Gasic, K.; Yu, J.; Humann, J.; Hough, H. Resources for peach genomics, genetics and breeding research in GDR, the Genome Database for Rosaceae. In X International Peach Symposium 1352; ISHS: Leuven, Belgium, 2022; pp. 149–156. [Google Scholar]
- Liu, H.; Wang, X.; Liu, S.; Huang, Y.; Guo, Y.; Xie, W.; Liu, H.; ul Qamar, M.T.; Xu, Q.; Chen, L. Citrus Pan-Genome to Breeding Database (CPBD): A comprehensive genome database for citrus breeding. Mol. Plant 2022, 15, 1503–1505. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Nguyen, X.T.; Kim, J.; Kim, N. Genetic diversity and structure analyses on the natural populations of diploids and triploids of tiger lily, Lilium lancifolium Thunb., from Korea, China, and Japan. Genes Genom. 2016, 38, 467–477. [Google Scholar] [CrossRef]
- Wen, C.S.; Hsiao, J.Y. Altitudinal genetic differentiation and diversity of Taiwan lily (Lilium longiflorum var. formosanum; Liliaceae) using RAPD markers and morphological characters. Int. J. Plant Sci. 2001, 162, 287–295. [Google Scholar] [CrossRef]
- Shahin, A.; Smulders, M.J.; van Tuyl, J.M.; Arens, P.; Bakker, F.T. Using multi-locus allelic sequence data to estimate genetic divergence among four Lilium (Liliaceae) cultivars. Front. Plant Sci. 2014, 5, 567. [Google Scholar] [CrossRef]
- Yuan, S.; Ge, L.; Liu, C.; Ming, J. The development of EST-SSR markers in Lilium regale and their cross-amplification in related species. Euphytica 2013, 189, 393–419. [Google Scholar] [CrossRef]
- Varshney, A.; Sharma, M.P.; Adholeya, A.; Dhawan, V.; Srivastava, P.S. Enhanced growth of micropropagated bulblets of Lilium sp. inoculated with arbuscular mycorrhizal fungi at different P fertility levels in an alfisol. J. Hortic. Sci. Biotechnol. 2002, 77, 258–263. [Google Scholar] [CrossRef]
- Xi, M.; Sun, L.; Qiu, S.; Liu, J.; Xu, J.; Shi, J. In vitro mutagenesis and identification of mutants via ISSR in lily (Lilium longiflorum). Plant Cell Rep. 2012, 31, 1043–1051. [Google Scholar] [CrossRef]
- Yin, Z.; Zhao, B.; Bi, W.; Chen, L.; Wang, Q. Direct shoot regeneration from basal leaf segments of Lilium and assessment of genetic stability in regenerants by ISSR and AFLP markers. Vitr. Cell. Dev. Biol.-Plant 2013, 49, 333–342. [Google Scholar] [CrossRef]
- Brown, J.; Pirrung, M.; McCue, L.A. FQC Dashboard: Integrates FastQC results into a web-based, interactive, and extensible FASTQ quality control tool. Bioinformatics 2017, 33, 3137–3139. [Google Scholar] [CrossRef] [PubMed]
- Hancock, B. Trinity v3, a DDoS tool, hits the streets. Comput. Secur. 2000, 19, 574. [Google Scholar] [CrossRef]
- Li, B.; Dewey, C.N. RSEM: Accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinform. 2011, 12, 323. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Wang, L.; Tak, B.C.; Wang, L.; Tang, C. Cap3: A cloud auto-provisioning framework for parallel processing using on-demand and spot instances. In Proceedings of the 2013 IEEE Sixth International Conference on Cloud Computing, Santa Clara, CA, USA, 28 June–3 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 228–235. [Google Scholar]
- Biswas, M.K.; Natarajan, S.; Biswas, D.; Nath, U.K.; Park, J.; Nou, I. LSAT: Liliaceae Simple Sequences Analysis Tool, a web server. Bioinformation 2018, 14, 181. [Google Scholar] [CrossRef]
- Zheng, Y.; Jiao, C.; Sun, H.; Rosli, H.G.; Pombo, M.A.; Zhang, P.; Banf, M.; Dai, X.; Martin, G.B.; Giovannoni, J.J. iTAK: A program for genome-wide prediction and classification of plant transcription factors, transcriptional regulators, and protein kinases. Mol. Plant 2016, 9, 1667–1670. [Google Scholar] [CrossRef]
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for Illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef]
- Jin, J.; Tian, F.; Yang, D.; Meng, Y.; Kong, L.; Luo, J.; Gao, G. PlantTFDB 4.0: Toward a central hub for transcription factors and regulatory interactions in plants. Nucleic Acids Res. 2017, 45, D1040–D1045. [Google Scholar] [CrossRef]
- Love, M.; Anders, S.; Huber, W. Differential analysis of count data–the DESeq2 package. Genome Biol. 2014, 15, 550. [Google Scholar]
- Biswas, M.K.; Xu, Q.; Mayer, C.; Deng, X. Genome wide characterization of short tandem repeat markers in sweet orange (Citrus sinensis). PLoS ONE 2014, 9, e104182. [Google Scholar] [CrossRef]
- Biswas, M.K.; Chai, L.; Mayer, C.; Xu, Q.; Guo, W.; Deng, X. Exploiting BAC-end sequences for the mining, characterization and utility of new short sequences repeat (SSR) markers in Citrus. Mol. Biol. Rep. 2012, 39, 5373–5386. [Google Scholar] [CrossRef] [PubMed]
- Arora, V.; Kapoor, N.; Fatma, S.; Jaiswal, S.; Iquebal, M.A.; Rai, A.; Kumar, D. BanSatDB, a whole-genome-based database of putative and experimentally validated microsatellite markers of three Musa species. Crop J. 2018, 6, 642–650. [Google Scholar] [CrossRef]
- Xu, H.; Yu, Q.; Shi, Y.; Hua, X.; Tang, H.; Yang, L.; Ming, R.; Zhang, J. PGD: Pineapple genomics database. Hortic. Res. 2018, 5, 66. [Google Scholar] [CrossRef]
- Moyle, R.L.; Crowe, M.L.; Ripi-Koia, J.; Fairbairn, D.J.; Botella, J.R. PineappleDB: An Online Pineapple Bioinformatics Resource. BMC Plant Biol. 2005, 5, 21. [Google Scholar] [CrossRef] [PubMed]
- Mokhtar, M.M.; Atia, M.A.M. SSRome: An integrated database and pipelines for exploring microsatellites in all organisms. Nucleic Acids Res. 2019, 47, D244–D252. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Dossa, K.; Wang, L.; Zhang, Y.; Wei, X.; Liao, B.; Zhang, X. PMDBase: A database for studying microsatellite DNA and marker development in plants. Nucleic Acids Res. 2017, 45, D1046–D1053. [Google Scholar] [CrossRef] [PubMed]
- Pham, G.M.; Newton, L.; Wiegert-Rininger, K.; Vaillancourt, B.; Douches, D.S.; Buell, C.R. Extensive genome heterogeneity leads to preferential allele expression and copy number-dependent expression in cultivated potato. Plant J. 2017, 92, 624–637. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, H.; Long, Y.; Shu, Y.; Zhai, J. Plant public RNA-seq database: A comprehensive online database for expression analysis of ~45 000 plant public RNA-seq libraries. Plant Biotechnol. J. 2022, 20, 806. [Google Scholar] [CrossRef]
- Ma, X.; Yan, H.; Yang, J.; Liu, Y.; Li, Z.; Sheng, M.; Cao, Y.; Yu, X.; Yi, X.; Xu, W. PlantGSAD: A comprehensive gene set annotation database for plant species. Nucleic Acids Res. 2022, 50, D1456–D1467. [Google Scholar] [CrossRef]
- Zhou, Z.; Tan, C.; Chau, M.H.K.; Jiang, X.; Ke, Z.; Chen, X.; Cao, Y.; Kwok, Y.K.; Bellgard, M.; Leung, T.Y. TEDD: A database of temporal gene expression patterns during multiple developmental periods in human and model organisms. Nucleic Acids Res. 2023, 51, D1168–D1178. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Species | No of Sequences | Total No of Bases | GC Count | GC Content % | Data Source | Lily Group |
|---|---|---|---|---|---|---|
| L. formosanum | 1339 | 397,156 | 181,219 | 45.63% | NCBI | Asiatic |
| L. longiflorum | 1336 | 920,102 | 430,617 | 46.80% | NCBI | Longiflorum |
| L. longiflorum Easter | 179,988 | 113,297,779 | 49,127,334 | 43.36% | SNU | Longiflorum |
| L. longiflorum White | 85,647 | 58,051,294 | 26,248,028 | 45.22% | SNU | Longiflorum |
| L. regale | 1171 | 581,552 | 271,740 | 46.73% | NCBI | Oriental |
| Lily Hybrid | 953 | 681,293 | 327,827 | 48.12% | NCBI | Hybrid |
| L. formolongi Sinnapal | 90,115 | 60,473,109 | 27,533,192 | 45.53% | SNU | Hybrid |
| L. candidum | 458,622 | 345,516,278 | 109,031,745 | 31.56% | NCBI | Oriental |
| Species (Dataset) | L. formosanum | L. longiflorum | L. longiflorum Easter | L. longiflorum White | L. regale | Lily Hybrid | L. formolongi Sinnapal | Over All for RNA Data | L. candidum (Genomic Data) |
|---|---|---|---|---|---|---|---|---|---|
| No of SSR containing sequences | 438 | 434 | 22,723 | 9792 | 444 | 242 | 11,066 | 45,139 | 106,749 |
| % of SSR sequences | 32.71 | 32.49 | 12.62 | 11.43 | 37.92 | 25.39 | 12.28 | 12.52 | 23.28 |
| No of Sequences have more than one SSR | 62 | 67 | 3778 | 1638 | 77 | 44 | 1872 | 7538 | 17,249 |
| Total No of SSR identify | 515 | 512 | 27,332 | 11,760 | 533 | 295 | 13,374 | 54,321 | 106,749 |
| SSR density (per bp) | 771.18 | 1797.07 | 4138.66 | 4929.05 | 1091.09 | 2309.47 | 4514.95 | 2793.07 | 3236.71 |
| No compound SSR | 1 | 2 | 235 | 158 | 1 | 2 | 169 | 568 | 2821 |
| Class II SSR | 137 | 393 | 25,131 | 10,514 | 168 | 235 | 11,967 | 48,545 | 83,250 |
| Class I SSR | 377 | 117 | 1966 | 1088 | 364 | 58 | 1238 | 5208 | 20,678 |
| AT-rich | 475 | 365 | 15,177 | 4761 | 451 | 147 | 5573 | 26,949 | 83,369 |
| GC rich | 34 | 124 | 6458 | 4148 | 55 | 104 | 4605 | 15,528 | 3282 |
| Balance | 5 | 21 | 5462 | 2693 | 26 | 42 | 3027 | 11,276 | 17,277 |
| Mono | 477 | 307 | 10,541 | 2688 | 432 | 114 | 3363 | 17,922 | 14,260 |
| Di | 5 | 30 | 7651 | 3474 | 31 | 47 | 3899 | 15,137 | 66,903 |
| Tri | 33 | 173 | 8471 | 5289 | 63 | 131 | 5792 | 19,952 | 21,821 |
| Tetra | 0 | 2 | 357 | 117 | 2 | 2 | 127 | 607 | 2783 |
| Penta | 0 | 0 | 133 | 46 | 2 | 1 | 46 | 228 | 608 |
| Hexa | 0 | 0 | 179 | 146 | 3 | 0 | 147 | 475 | 374 |
| No of SSR primer modeling | 456 | 506 | 26,943 | 11,511 | 521 | 290 | 7636 | 47,863 | 103,929 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biswas, M.K.; Natarajan, S.; Biswas, D.; Howlader, J.; Park, J.-I.; Nou, I.-S. Lily Database: A Comprehensive Genomic Resource for the Liliaceae Family. Horticulturae 2024, 10, 23. https://doi.org/10.3390/horticulturae10010023
Biswas MK, Natarajan S, Biswas D, Howlader J, Park J-I, Nou I-S. Lily Database: A Comprehensive Genomic Resource for the Liliaceae Family. Horticulturae. 2024; 10(1):23. https://doi.org/10.3390/horticulturae10010023
Chicago/Turabian StyleBiswas, Manosh Kumar, Sathishkumar Natarajan, Dhiman Biswas, Jewel Howlader, Jong-In Park, and Ill-Sup Nou. 2024. "Lily Database: A Comprehensive Genomic Resource for the Liliaceae Family" Horticulturae 10, no. 1: 23. https://doi.org/10.3390/horticulturae10010023