
Longitudinal Study on Sustained Attention to Response Task (SART): Clustering Approach for Mobility and Cognitive Decline


 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
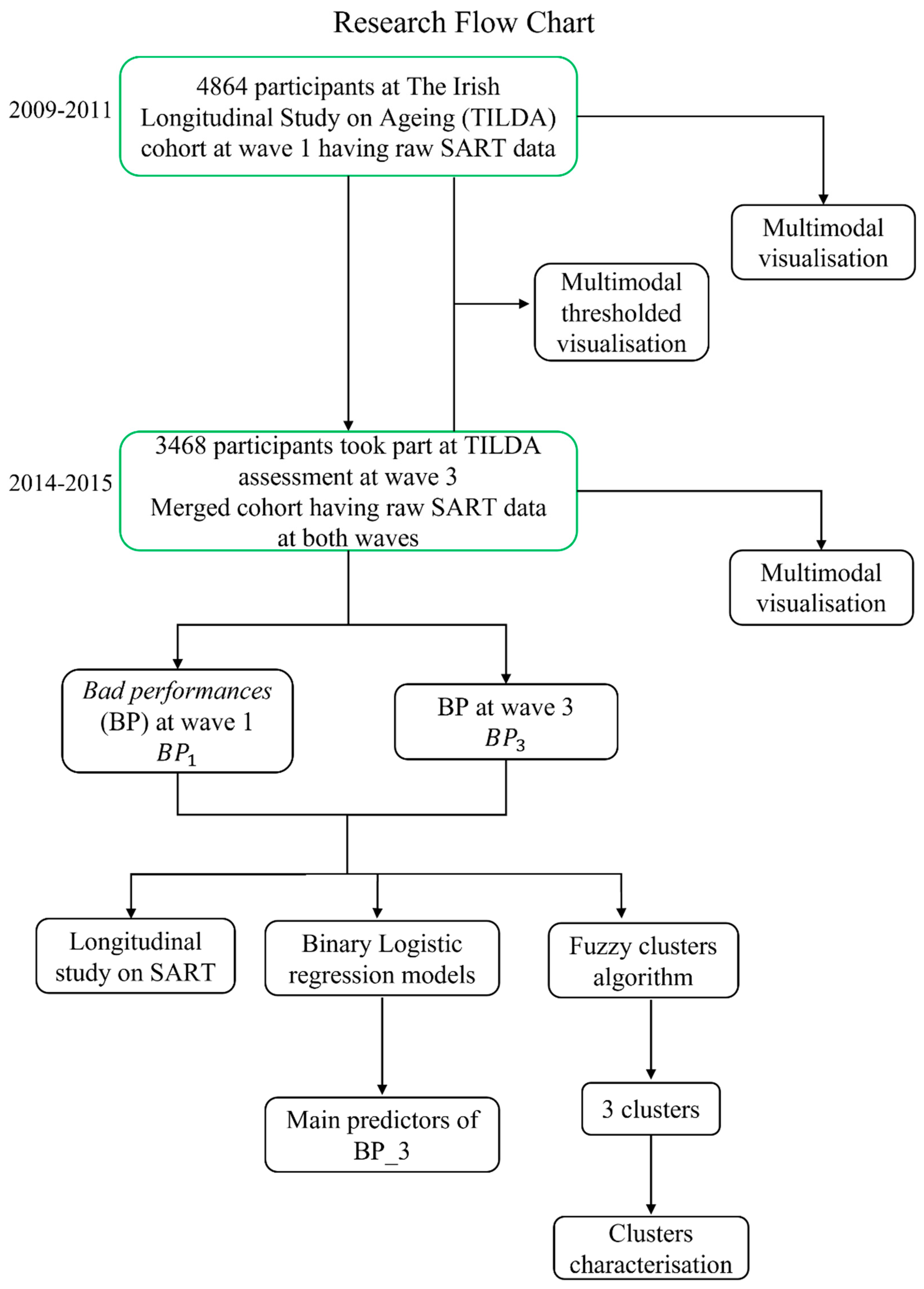
2. Materials and Methods
2.1. Dataset
2.1.1. Design and Setting
2.1.2. SART Protocol
2.1.3. Mobility Variables
- -
- TUG: TUG measures the time (seconds) taken for a participant to stand up, walk 3 m at normal pace along a line on the floor, turn around, walk back to the chair, and sit down [31]. The test is not just a measure of physical ability, but requires an individual to process instructions, plan and execute movements, focus on the task and avoid distractions. This cognitive component makes the test more complex than straight-line walking. Generally, a cut-off of 12 [29,47] or 14 [48,49] seconds (s) is clinically used to discriminate participants with significant mobility impairment and falls risk. The TUG in wave 1 () and wave 3 () were utilised in this study. Given our aim to capture risk of early mobility decline in this relatively healthy community-based sample, we chose the more restrictive cut-off of 12 s to define clinically significant mobility impairment in both waves. Specifically, we defined mobility decline (TUG decline) for a given participant when was less than 12 s () and was greater than or equal to 12 s ().
- -
- Gait speed: gait speed was assessed using a computerised walkway (4.88 m GAITRite (CIR Systems Inc., Franklin, NJ, USA) pressure sensing mat) [24,33]. Participants performed two walks at usual pace and two walks under dual-task conditions (i.e., reciting alternate letters of the alphabet), starting and finishing 2.5 m before and 2.0 m after the walkway. The measured usual gait speed (UGS) and dual-task gait speed (DTGS) were calculated as an average between the two walks under each condition and did not include the acceleration and deceleration phases. Variable cut-offs have been used in the literature to individuate mobility disability (range 30–100 cm/s) [30] and slow usual pace in older adults (range 80–120 cm/s) [50,51,52]. We considered the UGS at wave 1 () and at wave 3 (), and defined ‘UGS decline’ for a given participant when was greater or equal than 100 cm/s () and slower than 100 cm/s (). Similarly, we defined DTGS decline for a given participant when DTGS at wave 1 () was greater or equal than 100 cm/s () and DTGS at wave 3 () slower than 100 cm/s ().
- -
- Falls: as part of the CAPI, participants were asked whether they had fallen in the year prior to the interview. We recorded the number of recalled falls in wave 1 () and wave 3 (), and defined as ‘new fallers’ participants who had at least 1 fall in the year prior to the examination at wave 3 () and no falls in the year prior to the examination at wave 1 ().
2.1.4. Cognitive Variables
- -
- MMSE: Global cognitive function was assessed using the MMSE test, giving participants a score from 0 (minimum) to 30 (maximum) [35]. We considered the MMSE score in wave 1 () and wave 3 ( and, in line with previous recommendations [53], defined as clinically meaningful cognitive decline a decrease of at least 2 points between wave 1 and 3 ().
- -
2.1.5. Covariates
2.2. Multimodal Visualisation
2.2.1. Entire Sample
2.2.2. Thresholded Multimodal Visualisation
2.2.3. Longitudinal Multimodal Visualisation
2.3. Fuzzy Clusters
- elements of the same group are similar to each other (they are ‘close’ to each other),
- elements in different groups are dissimilar (they are far apart from each other).
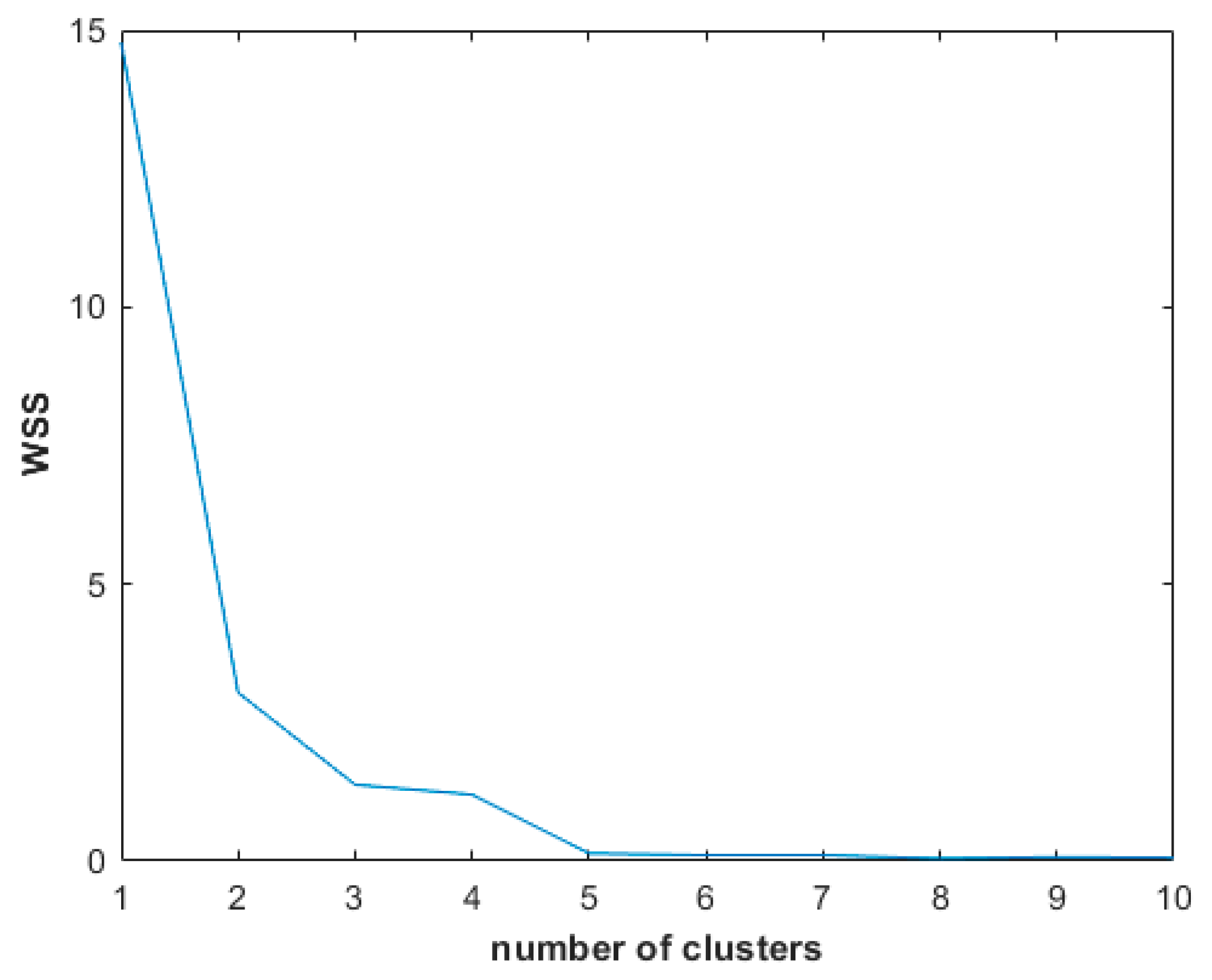
Elbow Method
2.4. Statistical Analysis
2.4.1. Longitudinal Study on SART
2.4.2. Clusters Characterisation
3. Results
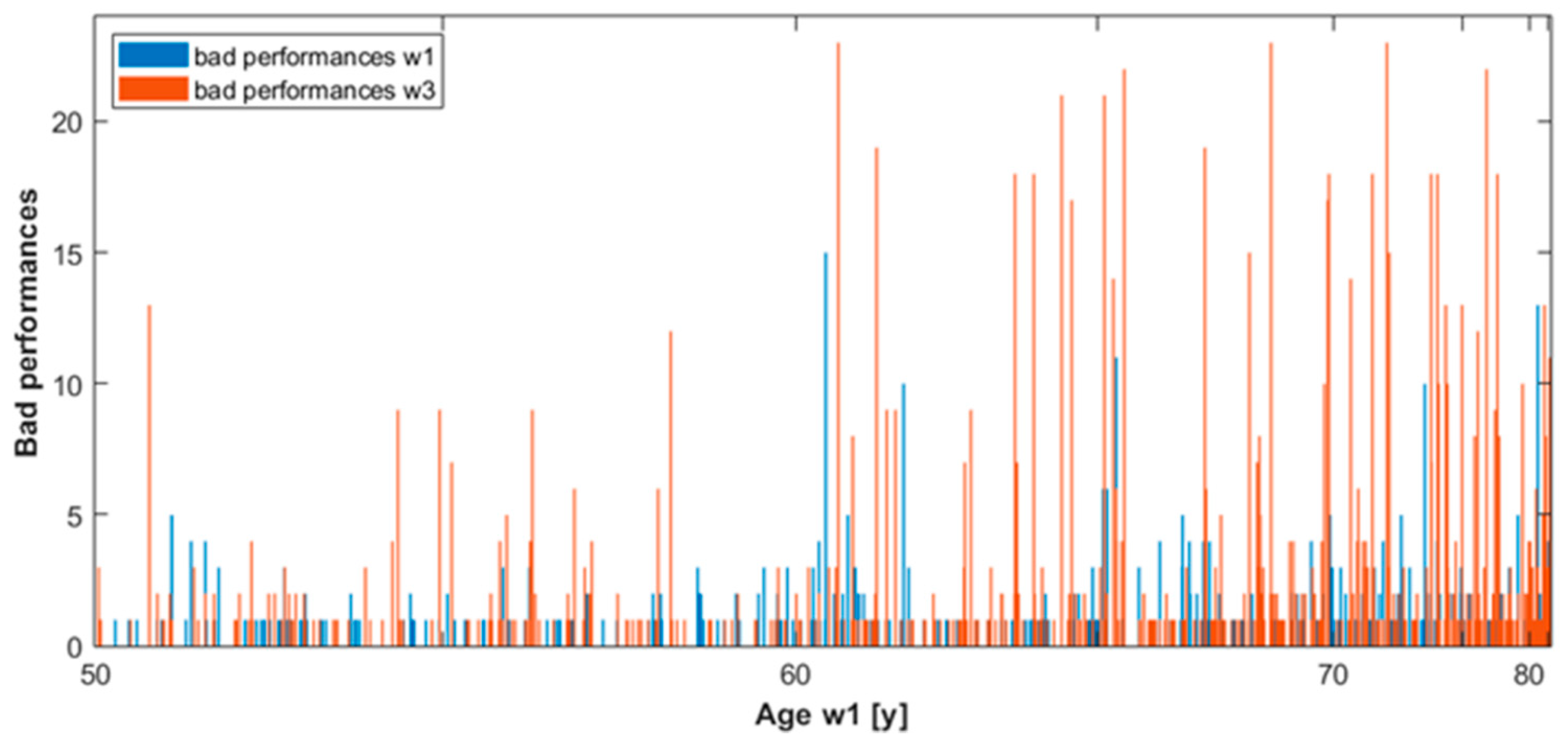
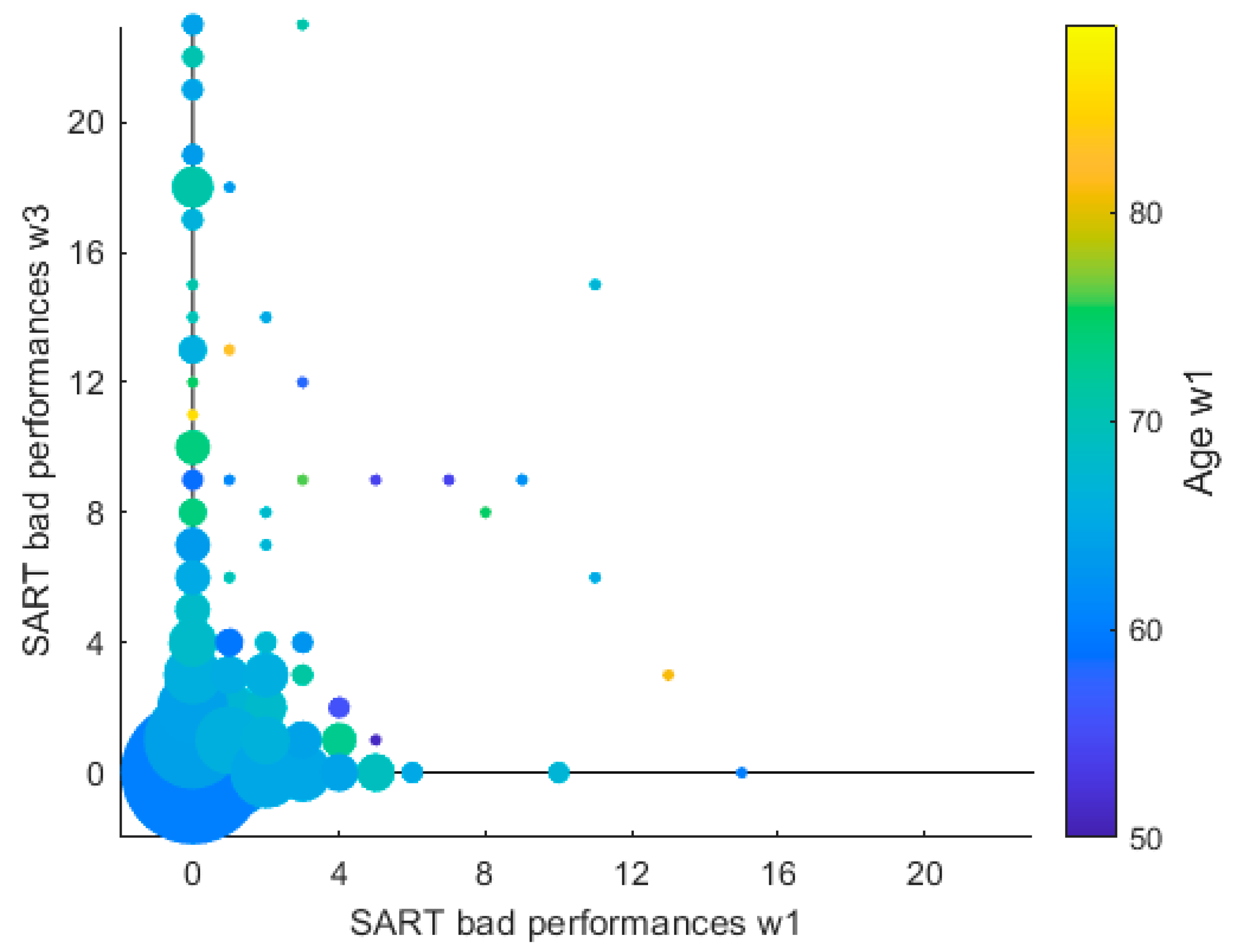
3.1. Longitudinal Multimodal Visualisation
3.2. SART Longitudinal Study
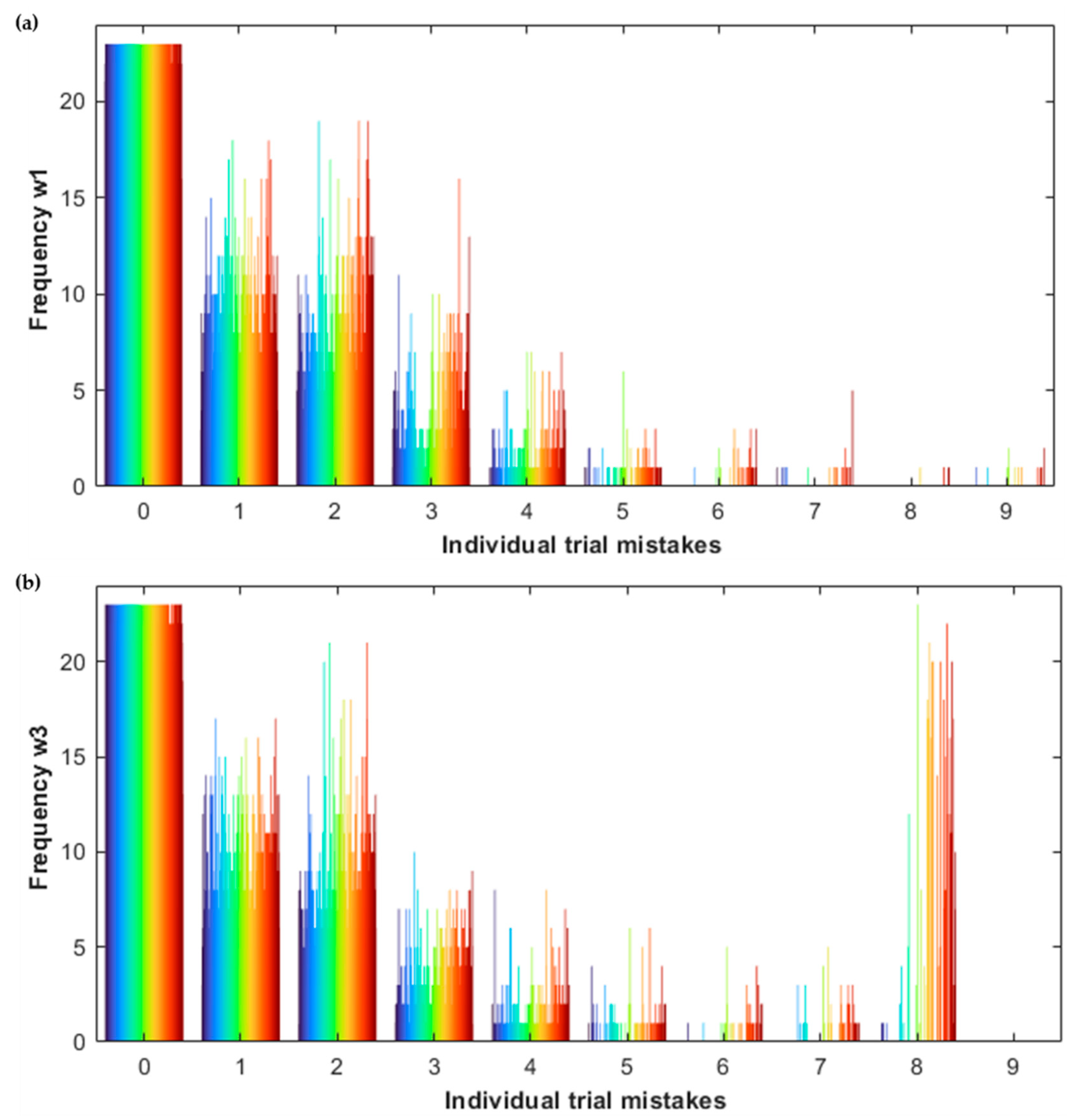
3.2.1. Histograms
3.2.2. Dynamic Graph
3.3. Predictive Model for SART Bad Performances
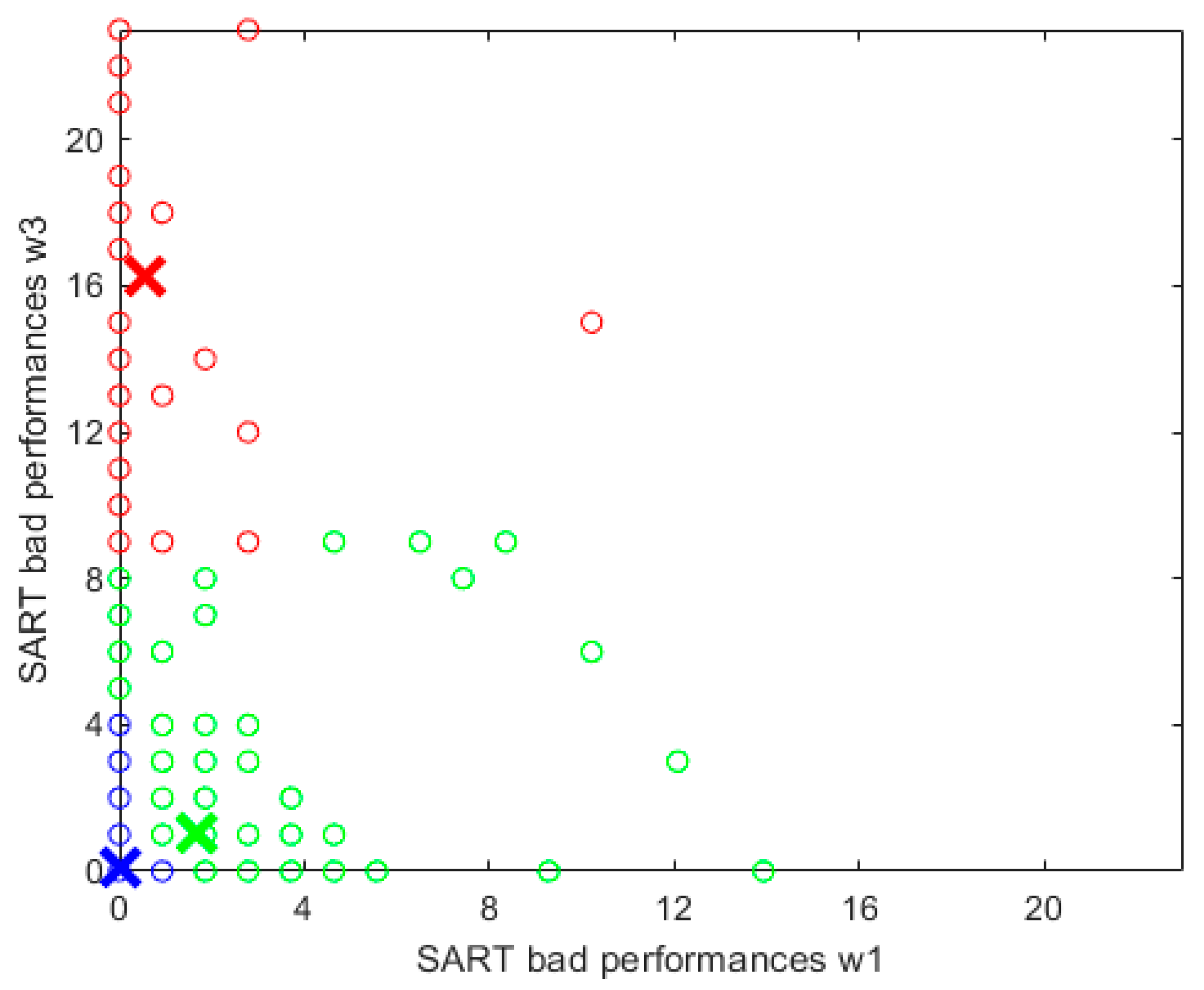
3.4. Fuzzy Clusters
3.4.1. Cluster Characterisation
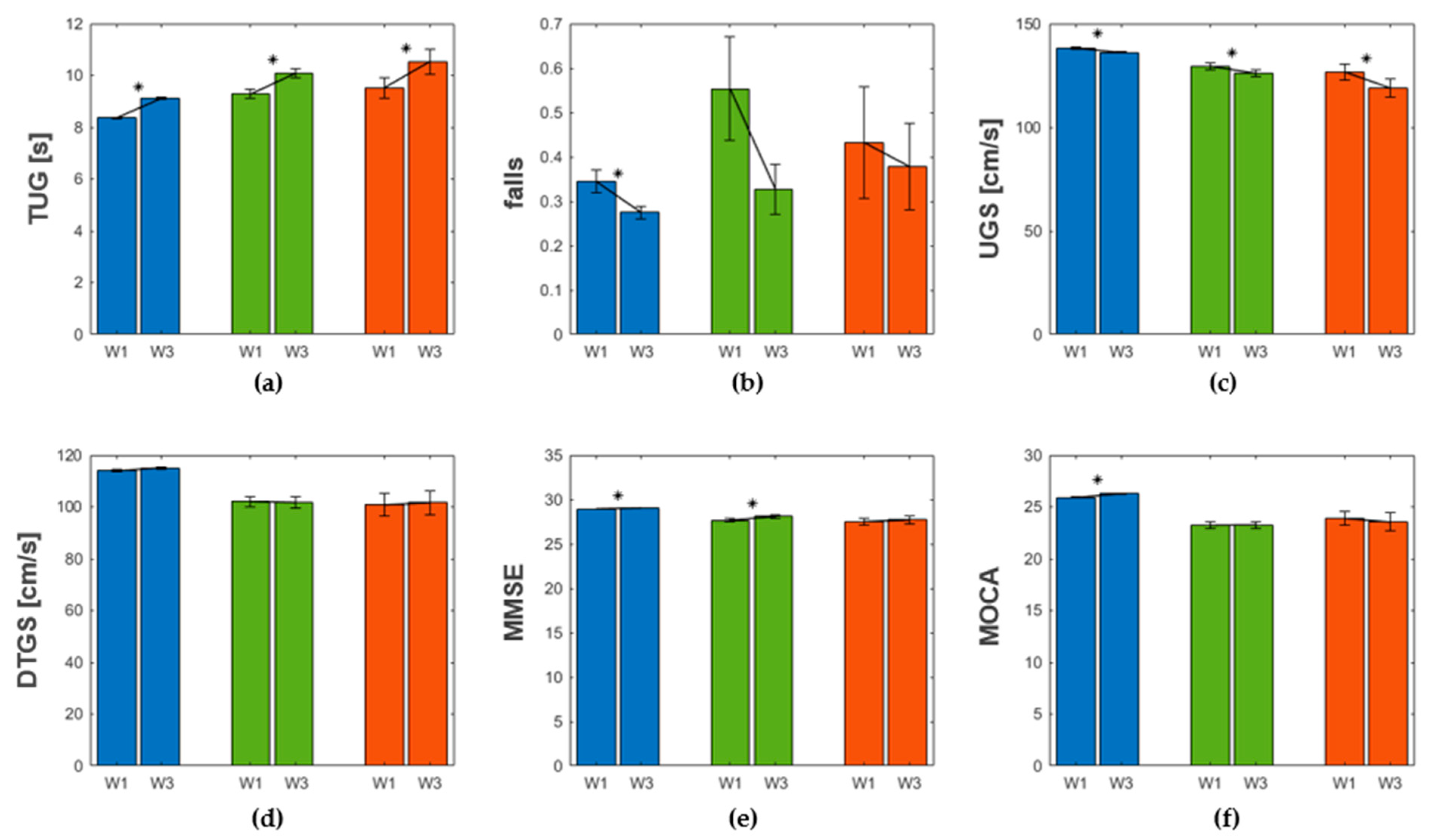
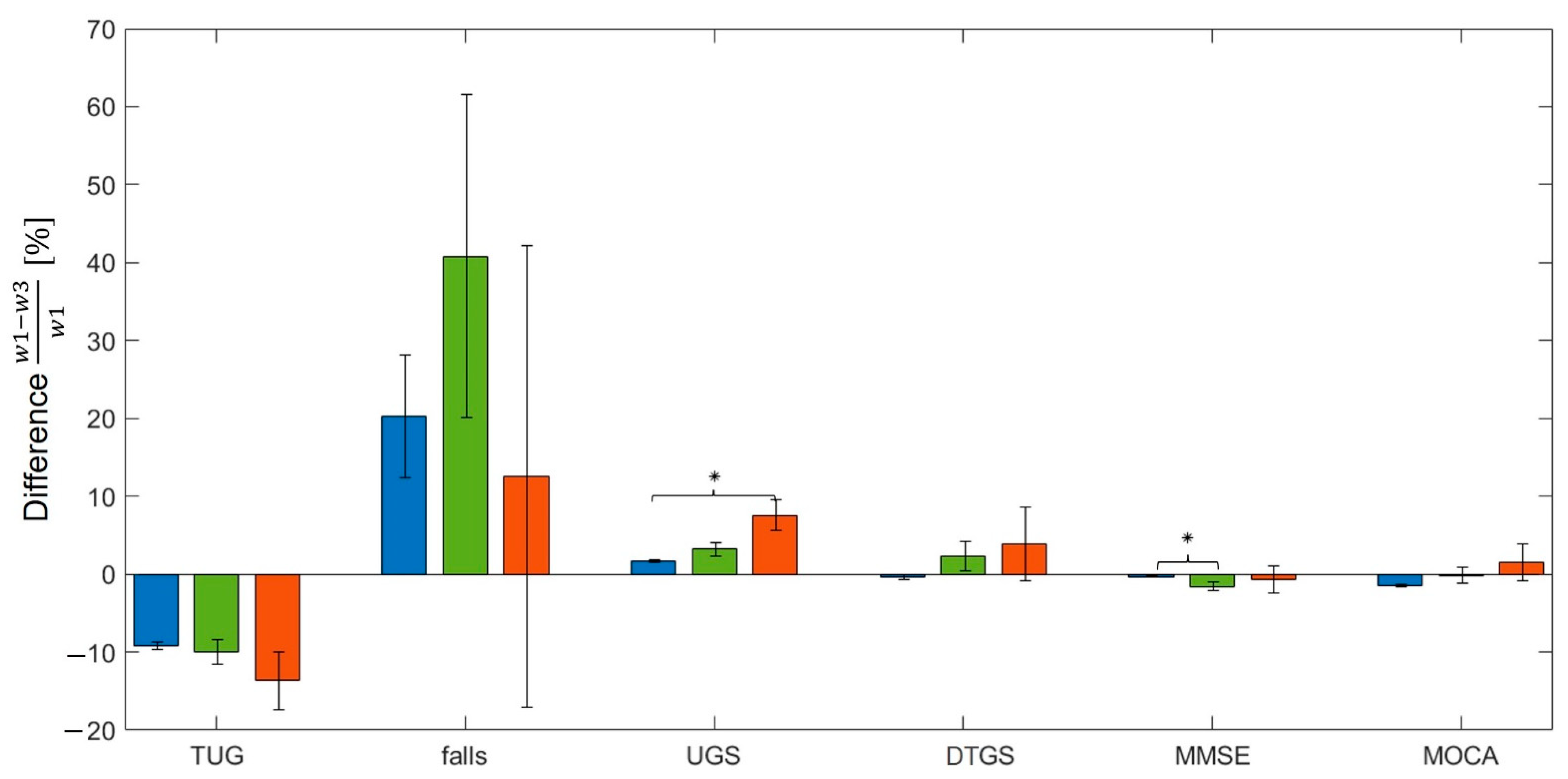
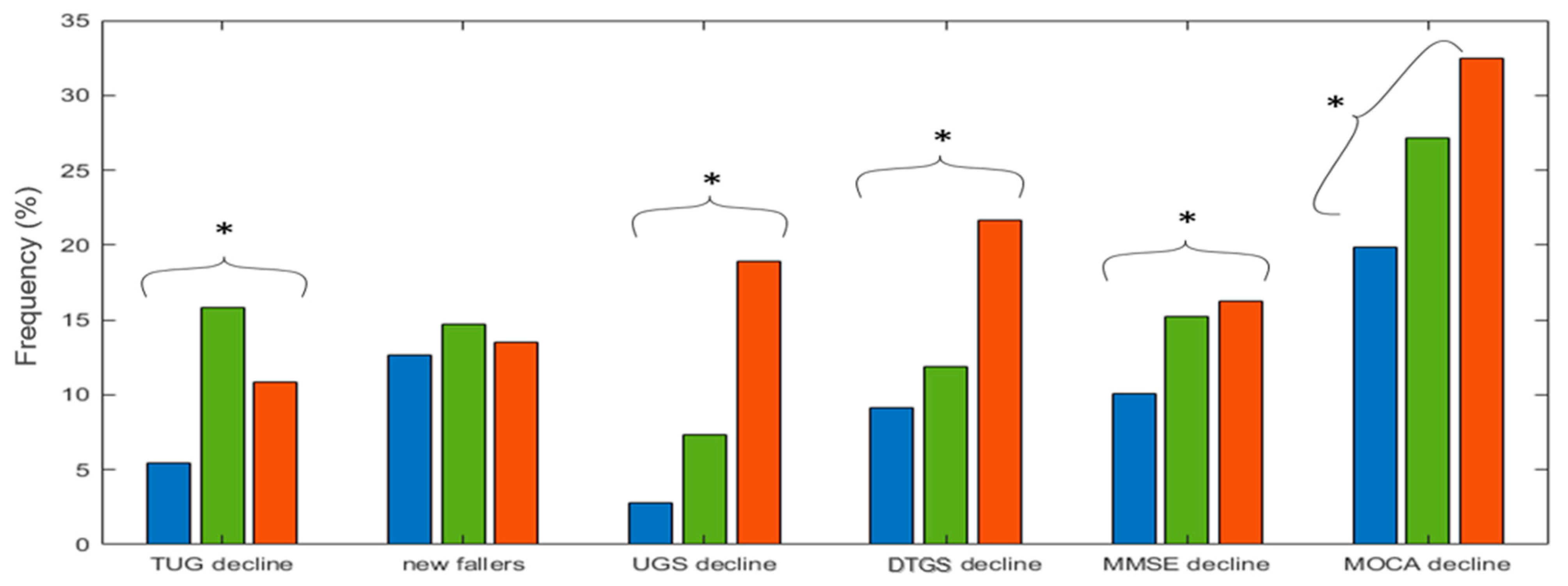
3.4.2. Mobility and Cognitive Decline across Clusters
4. Discussion
4.1. Longitudinal Study of SART
4.1.1. Longitudinal Multimodal Visualisation
4.1.2. Predictive Model for SART Performance after 4 Years
4.2. Fuzzy Clusters and the Three Degrees of Physiological Dysregulation
High Specificity for a Selective Group of High-Risk Participants
4.3. Strengths and Limitations of the Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- the objective function of FCM is minimised.
- the set of elements to partition is the merged cohort (wave 1 and 3) of participants
- the metric d has two components: the variable bad performances at wave 1 and the same variable at wave 3
- (as default in MATLAB)
References
- Gualtieri, C.T. Dementia Screening Using Computerized Tests. J. Insur. Med. 2004, 36, 213–227. [Google Scholar] [PubMed]
- Gates, N.J.; Vernooij, R.W.; di Nisio, M.; Karim, S.; March, E.; Martinez, G.; Rutjes, A.W. Computerised Cognitive Training for Preventing Dementia in People with Mild Cognitive Impairment. Cochrane Database Syst. Rev. 2019, 3, CD012279. [Google Scholar] [CrossRef] [PubMed]
- Ahn, W.Y.; Busemeyer, J.R. Challenges and Promises for Translating Computational Tools into Clinical Practice. Curr. Opin. Behav. Sci. 2016, 11, 1–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertacchini, F.; Rizzo, R.; Bilotta, E.; Pantano, P.; Luca, A.; Mazzuca, A.; Lopez, A. Mid-Sagittal Plane Detection for Advanced Physiological Measurements in Brain Scans. Physiol. Meas. 2019, 40, 115009. [Google Scholar] [CrossRef] [PubMed]
- O’Halloran, A.M.; Finucane, C.; Savva, G.M.; Robertson, I.H.; Kenny, R.A. Sustained Attention and Frailty in the Older Adult Population. J. Gerontol. B Psychol. Sci. Soc. Sci. 2014, 69, 147–156. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Joly-Burra, E.; van der Linden, M.; Ghisletta, P. Intraindividual Variability in Inhibition and Prospective Memory in Healthy Older Adults: Insights from Response Regularity and Rapidity. J. Intell. 2018, 6, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rizzo, R.; Knight, S.P.; Davis, J.R.C.; Newman, L.; Duggan, E.; Kenny, R.A.; Romero-Ortuno, R. Sart and Individual Trial Mistake Thresholds: Predictive Model for Mobility Decline. Geriatrics 2021, 6, 85. [Google Scholar] [CrossRef]
- Robertson, I.H.; Manly, T.; Andrade, J.; Baddeley, B.T.; Yiend, J. ‘Oops!’: Performance Correlates of Everyday Attentional Failures in Traumatic Brain Injured and Normal Subjects. Neuropsychologia 1997, 35, 747–758. [Google Scholar] [CrossRef]
- Paus, T.; Zatorre, R.J.; Hofle, N.; Caramanos, Z.; Gotman, J.; Petrides, M.; Evans, A.C. Time-Related Changes in Neural Systems Underlying Attention and Arousal During the Performance of an Auditory Vigilance Task. J. Cogn. Neurosci. 1997, 9, 392–408. [Google Scholar] [CrossRef]
- Helton, W.S.; Kern, R.P.; Walker, D.R. Conscious Thought and the Sustained Attention to Response Task. Conscious. Cogn. 2009, 18, 600–607. [Google Scholar] [CrossRef]
- Mackworth, N.H. Researches on the Measurement of Human Performance; The Stationery Office: London, UK, 1950; p. 156. [Google Scholar]
- Fassbender, C.; Murphy, K.; Foxe, J.J.; Wylie, G.R.; Javitt, D.C.; Robertson, I.H.; Garavan, H. A Topography of Executive Functions and Their Interactions Revealed by Functional Magnetic Resonance Imaging. Brain Res. Cogn. Brain Res. 2004, 20, 132–143. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- O’Connor, C.; Robertson, I.H.; Levine, B. The Prosthetics of Vigilant Attention: Random Cuing Cuts Processing Demands. Neuropsychology 2011, 25, 535–543. [Google Scholar] [CrossRef] [PubMed]
- Coull, J.T. Neural Correlates of Attention and Arousal: Insights from Electrophysiology, Functional Neuroimaging and Psychopharmacology. Prog. Neurobiol. 1998, 55, 343–361. [Google Scholar] [CrossRef]
- Sturm, W.; de Simone, A.; Krause, B.J.; Specht, K.; Hesselmann, V.; Radermacher, I.; Herzog, H.; Tellmann, L.; Müller-Gärtner, H.W.; Willmes, K. Functional Anatomy of Intrinsic Alertness: Evidence for a Fronto-Parietal-Thalamic-Brainstem Network in the Right Hemisphere. Neuropsychologia 1999, 37, 797–805. [Google Scholar] [CrossRef]
- Helton, W.S. Impulsive Responding and the Sustained Attention to Response Task. J. Clin. Exp. Neuropsychol. 2009, 31, 39–47. [Google Scholar] [CrossRef]
- Braver, T.S.; Barch, D.M.; Gray, J.R.; Molfese, D.L.; Snyder, A. Anterior Cingulate Cortex and Response Conflict: Effects of Frequency, Inhibition and Errors. Cereb. Cortex 2001, 11, 825–836. [Google Scholar] [CrossRef]
- Palermo, S.; Stanziano, M.; Morese, R. Commentary: Anterior Cingulate Cortex and Response Conflict: Effects of Frequency, Inhibition and Errors. Front. Behav. Neurosci. 2018, 12. [Google Scholar] [CrossRef] [Green Version]
- O’Keeffe, F.M.; Murray, B.; Coen, R.F.; Dockree, P.M.; Bellgrove, M.A.; Garavan, H.; Lynch, T.; Robertson, I.H. Loss of Insight in Frontotemporal Dementia, Corticobasal Degeneration and Progressive Supranuclear Palsy. Brain 2007, 130, 753–764. [Google Scholar] [CrossRef]
- O’Halloran, A.M.; Fan, C.W.; Kenny, R.A.; Penard, N.; Galli, A.; Robertson, I.H. Variability in Sustained Attention and Risk of Frailty. J. Am. Geriatr. Soc. 2011, 59, 2390–2392. [Google Scholar] [CrossRef]
- Romero-Ortuno, R.; Walsh, C.D.; Lawlor, B.A.; Kenny, R.A. A Frailty Instrument for Primary Care: Findings from the Survey of Health, Ageing and Retirement in Europe (Share). BMC Geriatr. 2010, 10, 57. [Google Scholar] [CrossRef] [Green Version]
- Dent, E.; Finbarr, C.M.; Bergman, H.; Woo, J.; Romero-Ortuno, R.; Walston, J.D. Management of Frailty: Opportunities, Challenges, and Future Directions. Lancet 2019, 394, 1376–1386. [Google Scholar] [CrossRef]
- O’Halloran, A.M.; Penard, N.; Galli, A.; Fan, C.W.; Robertson, I.H.; Kenny, R.A. Falls and Falls Efficacy: The Role of Sustained Attention in Older Adults. BMC Geriatr. 2011, 11, 85. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hart, E.P.; Dumas, E.M.; van Zwet, E.W.; van der Hiele, K.; Jurgens, C.K.; Middelkoop, H.A.M.; van Dijk, J.G.; Roos, R.A.C. Longitudinal Pilot-Study of Sustained Attention to Response Task and P300 in Manifest and Pre-Manifest Huntington’s Disease. J. Neuropsychol. 2015, 9, 10–20. [Google Scholar] [CrossRef]
- Hartley, P.; Monaghan, A.; Donoghue, O.A.; Kenny, R.A.; Romero-Ortuno, R. Exploring Bi-Directional Temporal Associations between Timed-up-and-Go and Cognitive Domains in the Irish Longitudinal Study on Ageing (Tilda). Arch. Gerontol. Geriatr. 2022, 99, 104611. [Google Scholar] [CrossRef]
- Bartsch, R.P.; Liu, K.K.; Bashan, A.; Ivanov, P.C. Network Physiology: How Organ Systems Dynamically Interact. PLoS ONE 2015, 10, e0142143. [Google Scholar] [CrossRef] [PubMed]
- Rizzo, R.; Zhang, X.; Wang, J.; Lombardi, F.; Ivanov, P.C. Network Physiology of Cortico-Muscular Interactions. Front. Physiol. 2020, 11, 558070. [Google Scholar] [CrossRef]
- Chintapalli, R.; Romero-Ortuno, R. Choice Reaction Time and Subsequent Mobility Decline: Prospective Observational Findings from the Irish Longitudinal Study on Ageing (Tilda). EClinicalMedicine 2021, 31, 100676. [Google Scholar] [CrossRef]
- Briggs, R.; Kennelly, S.P.; Kenny, R.A. Does Baseline Depression Increase the Risk of Unexplained and Accidental Falls in a Cohort of Community-Dwelling Older People? Data from the Irish Longitudinal Study on Ageing (Tilda). Int. J. Geriatr. Psychiatry 2018, 33, e205–e211. [Google Scholar] [CrossRef]
- Miller, M.E.; Magaziner, J.; Marsh, A.P.; Fielding, R.A.; Gill, T.M.; King, A.C.; Kritchevsky, S.; Manini, T.; McDermott, M.M.; Neiberg, R.; et al. Gait Speed and Mobility Disability: Revisiting Meaningful Levels in Diverse Clinical Populations. J. Am. Geriatr. Soc. 2018, 66, 954–961. [Google Scholar] [CrossRef]
- Donoghue, O.A.; Horgan, N.F.; Savva, G.M.; Cronin, H.; O’Regan, C.; Kenny, R.A. Association between Timed up-and-Go and Memory, Executive Function, and Processing Speed. J. Am. Geriatr. Soc. 2012, 60, 1681–1686. [Google Scholar] [CrossRef]
- Verghese, J.; Wang, C.; Lipton, R.B.; Holtzer, R.; Xue, X. Quantitative Gait Dysfunction and Risk of Cognitive Decline and Dementia. J. Neurol. Neurosurg. Psychiatry 2007, 78, 929–935. [Google Scholar] [CrossRef] [PubMed]
- Katsumata, Y.; Todoriki, H.; Yasura, S.; Dodge, H.H. Timed up and Go Test Predicts Cognitive Decline in Healthy Adults Aged 80 and Older in Okinawa: Keys to Optimal Cognitive Aging (Kocoa) Project. J. Am. Geriatr. Soc. 2011, 59, 2188–2189. [Google Scholar] [CrossRef] [PubMed]
- Rydalch, G.; Bell, H.B.; Ruddy, K.L.; Bolton, D.A.E. Stop-Signal Reaction Time Correlates with a Compensatory Balance Response. Gait Posture 2019, 71, 273–278. [Google Scholar] [CrossRef] [PubMed]
- Folstein, M.F.; Folstein, S.E.; McHugh, P.R. Mini-Mental State. A Practical Method for Grading the Cognitive State of Patients for the Clinician. J. Psychiatr. Res. 1975, 12, 189–198. [Google Scholar] [CrossRef]
- Nasreddine, Z.S.; Phillips, N.A.; Bédirian, V.; Charbonneau, S.; Whitehead, V.; Collin, I.; Cummings, J.L.; Chertkow, H. The Montreal Cognitive Assessment, Moca: A Brief Screening Tool for Mild Cognitive Impairment. J. Am. Geriatr. Soc. 2005, 53, 695–699. [Google Scholar] [CrossRef]
- Diday, E.; Simon, J.C. Clustering Analysis. In Digital Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 1976; pp. 47–94. [Google Scholar]
- Rokach, L.; Maimon, O. Clustering Methods. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005; pp. 321–352. [Google Scholar]
- Gurugubelli, Venkata Sukumar, Zhouzhou Li, Honggang Wang, and Hua Fang. Efcm: An Enhanced Fuzzy C-Means Algorithm for Longitudinal Intervention Data. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018.
- Romero-Ortuno, R.; Cogan, L.; Foran, T.; Kenny, R.A.; Fan, C.W. Continuous Noninvasive Orthostatic Blood Pressure Measurements and Their Relationship with Orthostatic Intolerance, Falls, and Frailty in Older People. J. Am. Geriatr. Soc. 2011, 59, 655–665. [Google Scholar] [CrossRef]
- Romero-Ortuno, R.; O’Connell, M.D.L.; Finucane, C.; Soraghan, C.; Fan, C.W.; Kenny, R.A. Insights into the Clinical Management of the Syndrome of Supine Hypertension—Orthostatic Hypotension (Sh-Oh): The Irish Longitudinal Study on Ageing (Tilda). BMC Geriatr. 2013, 13, 73. [Google Scholar] [CrossRef] [Green Version]
- Alashwal, H.; el Halaby, M.; Crouse, J.J.; Abdalla, A.; Moustafa, A.A. The Application of Unsupervised Clustering Methods to Alzheimer’s Disease. Front. Comput. Neurosci. 2019, 13, 31. [Google Scholar] [CrossRef]
- Omar, A.M.S.; Narula, S.; Mohamed, A.A.R.; Pedrizzetti, G.; Raslan, H.; Rifaie, O.; Narula, J.; Partho, P.S. Precision Phenotyping in Heart Failure And pattern Clustering of Ultrasound Data for the Assessment of Diastolic dysfunction. JACC Cardiovasc. Imaging 2017, 10, 1291–1303. [Google Scholar] [CrossRef]
- Lopez-Campos, J.L.; Centanni, S. Current Approaches for Phenotyping as a Target for Precision Medicine in Copd Management. COPD J. Chronic Obstr. Pulm. Dis. 2018, 15, 108–117. [Google Scholar] [CrossRef]
- Kearney, P.M.; Cronin, H.; O’Regan, C.; Kamiya, Y.; Savva, G.M.; Whelan, B.; Kenny, R. Cohort Profile: The Irish Longitudinal Study on Ageing. Int. J. Epidemiol. 2011, 40, 877–884. [Google Scholar] [CrossRef] [PubMed]
- Donoghue, O.A.; McGarrigle, C.A.; Foley, M.; Fagan, A.; Meaney, J.; Kenny, R.A. Cohort Profile Update: The Irish Longitudinal Study on Ageing (Tilda). Int. J. Epidemiol. 2018, 47, 1398–1398l. [Google Scholar] [CrossRef] [PubMed]
- Briggs, R.; Carey, D.; Kenny, R.A.; Kennelly, S.P. What Is the Longitudinal Relationship between Gait Abnormalities and Depression in a Cohort of Community-Dwelling Older People? Data from the Irish Longitudinal Study on Ageing (Tilda). Am. J. Geriatr. Psychiatry 2018, 26, 75–86. [Google Scholar] [CrossRef]
- Arnold, C.M.; Faulkner, R.A. The History of Falls and the Association of the Timed up and Go Test to Falls and near-Falls in Older Adults with Hip Osteoarthritis. BMC Geriatr. 2007, 7, 17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beauchet, O.; Fantino, B.; Allali, G.; Muir, S.W.; Montero-Odasso, M.; Annweiler, C. Timed up and Go Test and Risk of Falls in Older Adults: A Systematic Review. J. Nutr. Health Aging 2011, 15, 933–938. [Google Scholar] [CrossRef]
- Sudarsky, L. Gait Disorders in the Elderly. N. Engl. J. Med. 1990, 322, 1441–1446. [Google Scholar]
- Kenny, R.A.; Coen, R.F.; Frewen, J.; Donoghue, O.A.; Cronin, H.; Savva, G.M. Normative Values of Cognitive and Physical Function in Older Adults: Findings from the Irish Longitudinal Study on Ageing. J. Am. Geriatr. Soc. 2013, 61, S279–S290. [Google Scholar] [CrossRef]
- James, K.; Schwartz, A.W.; Orkaby, A.R. Mobility Assessment in Older Adults. N. Engl. J. Med. 2021, 385, e22. [Google Scholar] [CrossRef]
- Andrews, J.S.; Desai, U.; Kirson, N.Y.; Zichlin, M.L.; Ball, D.E.; Matthews, B.R. Disease Severity and Minimal Clinically Important Differences in Clinical Outcome Assessments for Alzheimer’s Disease Clinical Trials. Alzheimer’s Dement. Transl. Res. Clin. Interv. 2019, 5, 354–363. [Google Scholar] [CrossRef] [PubMed]
- Trzepacz, P.T.; Hochstetler, H.; Wang, S.; Walker, B.; Saykin, A.J. Relationship between the Montreal Cognitive Assessment and Mini-Mental State Examination for Assessment of Mild Cognitive Impairment in Older Adults. BMC Geriatr. 2015, 15, 107. [Google Scholar] [CrossRef] [Green Version]
- Krishnan, K.; Rossetti, H.; Hynan, L.S.; Carter, K.; Falkowski, J.; Lacritz, L.; Cullum, C.M.; Weiner, M. Changes in Montreal Cognitive Assessment Scores over Time. Assessment 2017, 24, 772–777. [Google Scholar] [CrossRef] [PubMed]
- Zigmond, A.S.; Snaith, R.P. The Hospital Anxiety and Depression Scale. Acta Psychiatr. Scand. 1983, 67, 361–370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weissman, M.M.; Sholomskas, D.; Pottenger, M.; Prusoff, B.A.; Locke, B.Z. Assessing Depressive Symptoms in Five Psychiatric Populations: A Validation Study. Am. J. Epidemiol. 1977, 106, 203–214. [Google Scholar] [CrossRef] [PubMed]
- Nahler, G. Anatomical Therapeutic Chemical Classification System (Atc). In Dictionary of Pharmaceutical Medicine; Springer: Berlin/Heidelberg, Germany, 2009; p. 8. [Google Scholar]
- Forde, C. Scoring the International Physical Activity Questionnaire (Ipaq). University of Dublin. 2018. Available online: https://ugc.futurelearn.com/uploads/files/bc/c5/bcc53b14-ec1e-4d90-88e3-1568682f32ae/IPAQ_PDF.pdf (accessed on 13 March 2022).
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms, Advanced Applications in Pattern Recognition; Plenum Press: New York, NY, USA, 1981. [Google Scholar]
- Gosain, A.; Dahiya, S. Performance Analysis of Various Fuzzy Clustering Algorithms: A Review. Procedia Comput. Sci. 2016, 79, 100–111. [Google Scholar] [CrossRef] [Green Version]
- Shi, C.; Wei, B.; Wei, S.; Wang, W.; Liu, H.; Liu, J. A Quantitative Discriminant Method of Elbow Point for the Optimal Number of Clusters in Clustering Algorithm. EURASIP J. Wirel. Commun. Netw. 2021, 31. [Google Scholar] [CrossRef]
- Tanatavikorn, H.; Yamashita, Y. Improving Data Reliability for Process Monitoring with Fuzzy Outlier Detection. In Computer Aided Chemical Engineering; Gernaey, K.V., Huusom, J.K., Gani, R., Eds.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 1595–1600. [Google Scholar]
- Zar, J.H. Spearman Rank Correlation. In Encyclopedia of Biostatistics; Wiley: Hoboken, NJ, USA, 2005; Volume 7. [Google Scholar]
- Croux, C.; Dehon, C. Influence Functions of the Spearman and Kendall Correlation Measures. Stat. Methods Appl. 2010, 19, 497–515. [Google Scholar] [CrossRef] [Green Version]
- Le Cessie, S.; Goeman, J.J.; Dekkers, O.M. Who Is Afraid of Non-Normal Data? Choosing between Parametric and Non-Parametric Tests. Eur. J. Endocrinol. 2020, 182, E1–E3. [Google Scholar] [CrossRef]
- Franke, T.M.; Ho, T.; Christie, C.A. The chi-square test: Often used and more often misinterpreted. Am. J. Eval. 2012, 33, 448–458. [Google Scholar] [CrossRef]
- McHugh, M.L. The Chi-Square Test of Independence. Biochem. Med. 2013, 23, 143–149. [Google Scholar] [CrossRef] [Green Version]
- Wilson, E.B.; Hilferty, M.M. The Distribution of Chi-Square. Proc. Natl. Acad. Sci. USA 1931, 17, 684. [Google Scholar] [CrossRef] [Green Version]
- Canevelli, M.; Cesari, M.; van Kan, G.A. Frailty and Cognitive Decline: How Do They Relate? Curr. Opin. Clin. Nutr. Metab. Care 2015, 18, 43–50. [Google Scholar] [CrossRef] [PubMed]
- Amanzio, M.; Palermo, S.; Zucca, M.; Rosato, R.; Rubino, E.; Leotta, D.; Bartoli, M.; Rainero, I. Neuropsychological Correlates of Pre-Frailty in Neurocognitive Disorders: A Possible Role for Metacognitive Dysfunction and Mood Changes. Front. Med. 2017, 4, 199. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tombaugh, T. Test-Retest Reliable Coefficients and 5-Year Change Scores for the Mmse and 3ms. Arch. Clin. Neuropsychol. 2005, 20, 485–503. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feeney, J.; O’Leary, N.; Kenny, R.A. Impaired Orthostatic Blood Pressure Recovery and Cognitive Performance at Two-Year Follow up in Older Adults: The Irish Longitudinal Study on Ageing. Clin. Auton. Res. 2016, 26, 127–133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altpeter, E.; Mackeben, M.; Trauzettel-Klosinski, S. The Importance of Sustained Attention for Patients with Maculopathies. Vis. Res. 2000, 40, 1539–1547. [Google Scholar] [CrossRef] [Green Version]
- Boyle, R.; Jollans, L.; Rueda-Delgado, L.M.; Rizzo, R.; Yener, G.G.; McMorrow, J.P.; Knight, S.P.; Carey, D.; Robertson, I.H.; Emek-Savaş, D.D.; et al. Brain-Predicted Age Difference Score Is Related to Specific Cognitive Functions: A Multi-Site Replication Analysis. Brain Imaging Behav. 2021, 15, 327–345. [Google Scholar] [CrossRef]
- Donoghue, O.; Feeney, J.; O’Leary, N.; Kenny, R.A. Baseline Mobility Is Not Associated with Decline in Cognitive Function in Healthy Community-Dwelling Older Adults: Findings from the Irish Longitudinal Study on Ageing (Tilda). Am. J. Geriatr. Psychiatry 2018, 26, 438–448. [Google Scholar] [CrossRef]
- Kearney, P.M.; Cronin, H.; O’Regan, C.; Kamiya, Y.; Whelan, B.J.; Kenny, R.A. Comparison of Centre and Home-Based Health Assessments: Early Experience from the Irish Longitudinal Study on Ageing (Tilda). Age Ageing 2011, 40, 85–90. [Google Scholar] [CrossRef] [Green Version]
- Zanaty, E.A. Determining the Number of Clusters for Kernelized Fuzzy C-Means Algorithms for Automatic Medical Image Segmentation. Egypt. Inform. J. 2012, 13, 39–58. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Continuous Variable | Wave 1: Mean (SD); Range | Wave 3: Mean (SD); Range |
|---|---|---|
| SART bad performances | 0.2 (0.8); | 0.4 (1.8); |
| 0–15 | 0–23 | |
| SART: Total mistakes | 9.6 (10.6); | 11.0 (16.0); |
| 0–92 | 0–184 | |
| SART: Mistakes in good performances | 8.8 (8.8); | 8.9 (8.6); |
| 0–60 | 0–51 | |
| SART: Mean RT (ms) | 381.4 (94.2); | 348.4 (84.8); |
| 168.9–836.5 | 156.0–842.0 | |
| SART: SD RT (ms) | 69.7 (40.1); | 71.0 (43.3); |
| 12.7–364.2 | 0.0–347.4 | |
| TUG (s) | 8.6 (1.7); | 9.2 (2.1); |
| 4.8–28.5 | 5.1–27.6 | |
| UGS (cm/s) | 137.6 (19.0); | 135.4 (20.2); |
| 43.1–207.5 | 47.5–207.5 | |
| DTGS (cm/s) | 113.2 (25.6); | 114.4 (25.6); |
| 28.4–203.4 | 26.2–203.3 | |
| Falls | 0.4 (1.4); | 0.1 (4.2); |
| 0–50 | 0–15 | |
| MMSE | 28.9 (1.6); | 29.0 (1.4); |
| 0–30 | 15–30 | |
| MOCA | 25.7 (2.9); | 26.9 (3.0); |
| 7–30 | 7–30 | |
| Age (years) | 61.0 (7.8); | 65.3 (7.7); |
| 50–89 | 53–94 | |
| Anxiety | 5.4 (3.5); | 8.0 (2.6); |
| 0–20 | 6–23 | |
| Depression | 5.3 (6.6); | 3.0 (3.6); |
| 0–48 | 0–24 | |
| Ordinal/Nominal Variable | Cohort 1 (Wave 1) Frequency (%) | Cohort 2 (Merged Wave 1–3) Frequency (%) |
| Female | 54.2 | 54.2 |
| Education level | ||
| - primary/none | 17.5 | 17.4 |
| - secondary | 41.9 | 39.9 |
| - third/higher | 40.6 | 42.7 |
| Anti-hypertensives | 30.4 | 39.3 |
| Diabetes | 5.4 | 7.0 |
| Smoker | ||
| - never | 47.3 | 47.1 |
| - past | 39.5 | 43.4 |
| - current | 13.2 | 9.5 |
| Drinking problem | 13.8 (7.4 *) | 12.4 (10.5 *) |
| IPAQ | ||
| - low | 26.2 | 33.0 |
| - medium | 36.6 | 36.4 |
| - high | 37.3 | 25.4 |
| Number of Mistakes within a Trial | Wave 1 | Wave 3 | Change between Wave 1 and Wave 3 [%] | |||
|---|---|---|---|---|---|---|
| N. Participants | Total | N. Participants | Total | N. Participants | Total | |
| 0 | 3444 | 60,346 | 3433 | 59,403 | −0.3% | −1.6% |
| 1 | 2736 | 9035 | 2764 | 9396 | +1.0% | +4.0% |
| 2 | 2522 | 7925 | 2599 | 7844 | +3.1% | −1.0% |
| 3 | 925 | 1854 | 964 | 1877 | +4.2% | +1.2% |
| 4 | 268 | 429 | 323 | 491 | +20.5% | +14.5% |
| 5 | 79 | 100 | 98 | 135 | +24.1% | +35.0% |
| 6 | 22 | 32 | 42 | 58 | +90.9% | +81.3% |
| 7 | 19 | 24 | 44 | 66 | +131.6% | +175.0% |
| 8 | 4 | 4 | 66 | 494 | +1550% | +12,250% |
| 9 | 13 | 15 | 0 | 0 | −100% | −100% |
| Bad Performances w3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Bad Performances | Total Mistakes | Mistakes in Good Performances | |||||||
| OR | 95% C.I. | p | OR | 95% C.I. | p | OR | 95% C.I. | p | |
| Model 1 | 1.673 | 1.476–1.896 | <0.001 | 1.065 | 1.056–1.074 | <0.001 | 1.077 | 1.067–1.088 | <0.001 |
| Model 2 | 1.364 | 1.216–1.530 | <0.001 | 1.054 | 1.043–1.065 | <0.001 | 1.063 | 1.049–1.077 | <0.001 |
| Model 3 | 1.301 | 1.159–1.461 | <0.001 | 1.045 | 1.033–1.057 | <0.001 | 1.051 | 1.036–1.066 | <0.001 |
| Model 4 | 1.326 | 1.167–1.506 | <0.001 | 1.044 | 1.032–1.057 | <0.001 | 1.049 | 1.033–1.065 | <0.001 |
| Bad Performances w3 | |||
|---|---|---|---|
| Independent Variable | OR | 95% C.I. | p-Value |
| Bad performances w1 | 1.326 | 1.167–1.506 | <0.001 |
| SART mean RT | 1.000 | 0.999–1.001 | 0.931 |
| SART SD RT | 1.009 | 1.006–1.011 | <0.001 |
| Age | 1.070 | 1.052–1.088 | <0.001 |
| Females | 0.939 | 0.727–1.212 | 0.629 |
| Education level | |||
| - primary/none | [ref] | ||
| - secondary | 0.920 | 0.679–1.245 | 0.588 |
| - third/higher | 0.580 | 0.417–0.805 | 0.001 |
| Anxiety | 1.057 | 1.017–1.099 | 0.005 |
| Depression | 1.001 | 0.981–1.022 | 0.926 |
| Anti-hypertensives | 0.888 | 0.681–1.158 | 0.381 |
| Diabetes | 1.399 | 0.877–2.233 | 0.158 |
| Smoker | |||
| - never | [ref] | ||
| - past | 1.021 | 0.786–1.325 | 0.877 |
| - current | 1.155 | 0.784–1.702 | 0.466 |
| Drinking problem | |||
| - “No” | [ref] | ||
| - “Don’t know” | 1.263 | 0.515–3.100 | 0.610 |
| - “Yes” | 0.740 | 0.498–1.100 | 0.136 |
| UGS at baseline | 0.994 | 0.987–1.001 | 0.081 |
| IPAQ | |||
| - low | [ref] | ||
| - medium | 1.173 | 0.868–1.586 | 0.300 |
| - high | 1.046 | 0.763–1.435 | 0.778 |
| Continuous Variable | Cluster Blue (N = 3254) | Cluster Green (N = 177) | Cluster Red (N = 37) | |||
|---|---|---|---|---|---|---|
| Wave 1: Mean (SD); Range | Wave 3: Mean (SD); Range | Wave 1: Mean (SD); Range | Wave 3: Mean (SD); Range | Wave 1: Mean (SD); Range | Wave 3: Mean (SD); Range | |
| Age (years) | 60.6 (7.6); | 65.0 (7.6); | 65.8 (8.5); | 70.2 (8.5); | 68.7 (7.5); | 73.0 (7.6); |
| 50–89 | 53–94 | 50–85 | 54–89 | 50–86 | 54–90 | |
| SART bad performances | 0.1 (0.2); | 0.1 (0.4); | 2.4 (2.2); | 1.8 (2.3); | 0.7 (2.0); | 15.5 (4.6); |
| 0–1 | 0–4 | 0–15 | 0–9 | 0–11 | 9–23 | |
| SART: Total mistakes | 8.2 (8.1); | 8.7 (8.9); | 33.5 (16.6); | 11.0 (16.0); | 17.7 (17.7); | 120.7 (36.3); |
| 0–64 | 0–55 | 2–92 | 0–184 | 0–74 | 64–184 | |
| SART: Mistakes in good performances | 8.8 (8.8); | 8.2 (8.0); | 22.7 (12.0); | 8.9 (8.6); | 14.7 (12.3); | 8.4 (8.6); |
| 0–60 | 0–51 | 0–51 | 0–51 | 0–46 | 0–32 | |
| SART: Mean RT (ms) | 376.7 (91.3); | 343.1 (81.1); | 459.6 (108.0); | 348.4 (84.8); | 422.6 (101.7); | 438.1 (95.6); |
| 168.9–794.7 | 156.0–842.0 | 232.6–836.5 | 156.0–842.0 | 238.5–625.9 | 246.9–668.4 | |
| SART: SD RT (ms) | 66.6 (37.1); | 63.3 (41.4); | 121.1 (50.7); | 71.0 (43.3); | 99.5 (59.6); | 110.3 (60.2); |
| 12.7–364.2 | 9.7–347.4 | 25.3–302.0 | 0.0–347.4 | 34.0–290.7 | 0.0–256.5 | |
| TUG (s) | 8.4 (1.6); | 9.1 (2.0); | 9.3 (2.3); | 10.1 (2.5); | 9.5 (2.3); | 10.5 (2.8); |
| 4.8–28.5 | 5.1–27.6 | 5.6–24.3 | 6.2–18.4 | 6.3–17.6 | 6.7–18.1 | |
| UGS (cm/s) | 138.2 (18.6); | 136.1 (19.9); | 129.5 (22.1); | 126.1 (21.7); | 126.7 (23.4); | 119.0 (25.3) |
| 43.1–207.5 | 47.5–207.5 | 46.0–181.3 | 63.8–177.6 | 64.2–164.3 | 67.4–161.6 | |
| DTGS (cm/s) | 113.9 (25.4); | 115.2 (25.3); | 102.1 (25.5); | 101.7 (28.2); | 100.8 (26.7); | 101.6 (24.0); |
| 28.4–203.4 | 26.2–203.3 | 34.4–167.6 | 26.2–179.3 | 39.9–140.5 | 51.2–146.5 | |
| Falls | 0.3 (1.4); | 0.3 (0.8); | 0.6 (1.6); | 0.3 (0.8); | 0.4 (0.8); | 0.4 (0.6); |
| 0–50 | 0–15 | 0–12 | 0–4 | 0–3 | 0–2 | |
| MMSE | 29.0 (1.5); | 29.0 (1.3); | 27.7 (2.6); | 28.1 (2.3); | 27.5 (2.5); | 27.7 (3.1); |
| 0–30 | 19–30 | 19–30 | 18–30 | 20–30 | 15–30 | |
| MOCA | 25.9 (2.7); | 26.3 (2.8); | 23.2 (4.0); | 23.3 (4.2); | 23.9 (4.2) | 23.5 (5.2); |
| 13–30 | 11–30 | 10–30 | 7–30 | 7–30 | 9–30 | |
| Anxiety | 5.4 (3.5); | 8.0 (2.6); | 5.7 (3.5); | 8.3 (2.7); | 5.2 (3.9); | 7.6 (1.7); |
| 0–20 | 6–23 | 0–19 | 6–21 | 0–15 | 6–11 | |
| Depression | 5.2 (6.6); | 3.0 (3.6); | 5.9 (6.6); | 3.3 (3.6); | 5.0 (7.2); | 3.6 (4.0); |
| 0–48 | 0–24 | 0–31 | 0–20 | 0–33 | 0–15 | |
| Ordinal/Nominal Variable | Wave 1 Frequency (%) | Wave 3 Frequency (%) | Wave 1 Frequency (%) | Wave 3 Frequency (%) | Wave 1 Frequency (%) | Wave 3 Frequency (%) |
| Female | 54.1 | 54.1 | 58.8 | 58.8 | 40.5 | 40.5 |
| Education level | ||||||
| - primary/none | 16.2 | 16.1 | 39.0 | 39.5 | 27.0 | 27.0 |
| - secondary | 42.1 | 40.0 | 37.3 | 36.7 | 48.6 | 45.9 |
| - third/higher | 41.7 | 43.9 | 23.7 | 23.7 | 24.3 | 27.0 |
| Anti-hypertensives | 29.8 | 38.8 | 35.0 | 42.4 | 56.8 | 70.3 |
| Diabetes | 5.3 | 6.8 | 6.2 | 7.9 | 13.5 | 16.2 |
| Smoker | ||||||
| - never | 47.1 | 46.9 | 51.4 | 51.4 | 43.2 | 40.5 |
| - past | 39.7 | 43.5 | 35.6 | 41.2 | 43.2 | 45.9 |
| - current | 13.2 | 9.6 | 13.0 | 7.3 | 13.5 | 13.5 |
| Drinking problem | 14.0 (7.2 *) | 12.6 (10.3 *) | 10.2 (10.7 *) | 9.6 (12.4 *) | 13.5 (5.4 *) | 2.7 (16.2 *) |
| IPAQ | ||||||
| - low | 25.9 | 34.4 | 31.4 | 41.4 | 27.0 | 38.9 |
| - medium | 36.5 | 38.5 | 37.1 | 36.4 | 35.1 | 41.7 |
| - high | 37.6 | 27.1 | 31.4 | 22.2 | 37.8 | 19.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rizzo, R.; Knight, S.P.; Davis, J.R.C.; Newman, L.; Duggan, E.; Kenny, R.A.; Romero-Ortuno, R. Longitudinal Study on Sustained Attention to Response Task (SART): Clustering Approach for Mobility and Cognitive Decline. Geriatrics 2022, 7, 51. https://doi.org/10.3390/geriatrics7030051
Rizzo R, Knight SP, Davis JRC, Newman L, Duggan E, Kenny RA, Romero-Ortuno R. Longitudinal Study on Sustained Attention to Response Task (SART): Clustering Approach for Mobility and Cognitive Decline. Geriatrics. 2022; 7(3):51. https://doi.org/10.3390/geriatrics7030051
Chicago/Turabian StyleRizzo, Rossella, Silvin P. Knight, James R. C. Davis, Louise Newman, Eoin Duggan, Rose Anne Kenny, and Roman Romero-Ortuno. 2022. "Longitudinal Study on Sustained Attention to Response Task (SART): Clustering Approach for Mobility and Cognitive Decline" Geriatrics 7, no. 3: 51. https://doi.org/10.3390/geriatrics7030051