1. Introduction
During the beginning of the COVID-19 pandemic, humanity was isolated from workplaces, schools, recreational centers, parks, and sports venues, resulting in consequences for people’s mental health [
1]. Problems, such as stress, anxiety, fear, bad mood, irritability, frustration, and boredom, among others, have arisen with the emergence of the pandemic [
2]. At the start of the pandemic, there was very little information, leading many researchers to access data and information from various sources during the COVID-19 outbreak. All of this data reflected the point of view of individuals, organizations, and government agencies on the coronavirus [
3].
In parallel, there was a progressive increase worldwide in the use of the internet and its various tools for sharing information in recent years [
4]. Common people have shifted from consumers to producers of data through different sources, such as blogs, websites, social networks, and apps, among others [
5]. Nowadays, social media platforms are the most widely-used tools for spreading data, for example, Twitter, a social media platform with over 500 million users worldwide, is where opinions and comments about any topic, ranging from criticisms of or congratulations for products and services to sports and political issues, are most widely spread [
6].
During the pandemic, social media platforms began to play an important role in times of confinement, as they were tools that kept people connected with the world without leaving home [
7]. In the case of Twitter, it was used to share opinions about Covid, show points of view, and in some cases, write comments based on the sentiments people were feeling at that moment [
3]. For this reason, sentiment analysis techniques (SA) began to be applied to decipher and discover the emotions of different Twitter users [
8] during the pandemic. The techniques of SA have progressed in recent years, moving from dictionary strategies [
9], lexicon [
10], semantic similarity [
11], and machine learning [
12], to deep learning [
13].
Within deep learning, in the context of opinion classification, BERT architecture has been used. BERT (Bidirectional Encoder Representations from Transformers) is a state-of-the-art language model architecture developed by Google in 2018 [
14]. It is composed of a set of self-attention cells, similar to transformers, that enable the prediction of missing words in a sentence by using a bidirectional semantic representation of words, considering both the preceding and following context of the word. BERT uses a dynamic word representation system that adjusts to the context and produces a richer representation of words and their relationships.
As part of the fine-tuning process, the pre-trained BERT model is adapted to a specific dataset, in this case, a sentiment exploration dataset. During the fine-tuning process, the model is adjusted to predict the correct output for the training dataset. Once the fine-tuning process is complete, the model can be used to make predictions on new data. Fine-tuning BERT on a specific dataset is highly effective for managing many natural language processing tasks.
BERT with fine-tuning enables sentiment exploration because it allows the model to better understand the context in which language is used. The pre-trained model already has a deep understanding of language. Furthermore, the use of a bidirectional semantic representation allows the model to consider the context of words, which significantly improves the accuracy of sentiment exploration.
Regarding the language used in sentiment analysis systems, most current research has focused on performing analyses on COVID-19-related tweets in English using different techniques and methodologies [
15,
16,
17,
18,
19]. Few studies have been conducted in Spanish and particularly in Latin-American dialects [
15]. Therefore, this article seeks to show the results obtained from a sentiment analysis of six million comments obtained from Twitter between 2020 and 2021 by users based in Colombia. Throughout the process, web scraping extraction techniques, natural language processing, and deep learning were applied for sentiment classification. This study makes an important contribution to understanding the evolution of sentiments during the pandemic and how these sentiments are changing over time, which has implications for policymakers, health professionals, and social media users alike.
The rest of the article is organized as follows.
Section 2 addresses the background and similar work,
Section 3 describes the materials and methods,
Section 4 presents the experiments and results, and finally, the conclusions are provided in
Section 5.
2. Background
Currently, a large amount of data is produced worldwide that is attractive to various governmental, commercial, and industrial sectors. However, the manual extraction and processing of the information make this process very complex. Therefore, there have been efforts for some time to work on systems that allow for the automatic analysis of large amounts of data, based on advances in disciplines such as natural language processing (NLP), machine learning, data mining, and cloud computing, among others. Within NLP is sentiment analysis (SA), an area that seeks to analyze the opinions, sentiments, values, attitudes, and emotions of people towards entities, such as products, services, organizations, individuals, problems, events, themes, and their attributes [
16]. SA has shown a great research trend in recent years, mostly in the English language [
11,
17]. However, recent contributions have been made in other languages, such as Spanish [
18], French [
19], and Chinese [
13], among others.
The majority of SA approaches focus on detecting the general polarity (positive or negative) of a paragraph or complete text [
20]. Other approaches include sentence-level classification of the expressed sentiments in each sentence [
21] and aspect-based classification of sentiments to specific characteristics of an entity found in each sentence [
11].
The most-used technique to address SA is machine learning (ML), which depends on the existence of pre-labeled training documents, i.e., those that have already been assigned a polarity. Within the literature related to ML, there are works such as the one by De Freitas et al. [
22], which performed an ontology-supported analysis in the domain of movies and hotels in Portuguese. Other examples include the study by Steinberger et al. [
20], which presented a supervised approach to restaurant reviews in Czech, and the study by Manek et al. [
23], which proposed a system in the English language based on the GINI index of movies.
In recent years, more advanced and precise approaches have used deep learning [
24,
25,
26]. Deep learning consists of algorithms based on neural networks that represent a high-level of generalization regarding data processing; this is achieved via the multiple layers accumulated between themselves by alternating linear and non-linear transformations [
27].
Various social networks have been studied. The work by Bonifazi et al. [
28], using information based on Reddit data, the concept of scope in social network analysis was addressed, proposing a multidimensional view that included temporal scope. It introduced the concept of sentiment scope and developed a general framework for analyzing it on any social network platform. Bonifazi et al. [
29], presented three novel approaches to analyzing COVID-19 Reddit posts: dynamic classification, virtual subreddit creation, and user community identification, addressing gaps in the previous research.
Several works are found in the literature related to sentiment analysis on Twitter that revolves around COVID-19. There are works on English tweets [
30], where 500,000 tweets were analyzed in April 2020, finding that 36% of people had optimistic opinions, while only around 14% were negative. Likewise, an analysis was carried out in March 2020 on 50,000 tweets from several countries, resulting in most people having a positive and hopeful approach [
31]. However, there were cases of fear, sadness, and disgust worldwide. Another contribution is found in the study by Boon-Itt et al. [
32], where over 100,000 tweets were analyzed between December 2019 and March 2020, resulting in people having a negative perspective towards COVID-19, and the findings of predominant themes, such as pandemic emergency and learning how to control the disease.
In other languages, there are contributions, where more than 6 million comments in English and Portuguese were analyzed, resulting in finding sentiment trends and relationships with announced news, as well as a comparison of human behavior in two different geographical locations affected by the pandemic [
33]. In another study [
3], data were processed from users who shared their location as being “Nepal” between 21 May 2020 and 31 May 2020. The results of the study concluded that while most people in Nepal adopted a positive and hopeful approach, there were cases of fear, sadness, and disgust. Another contribution is found in a study [
34] where Twitter messages collected during the first months of the COVID-19 pandemic in Europe were analyzed, finding that lockdown announcements correlated with a deterioration of mood in almost all surveyed countries, recovering in a short time.
Other contributions have focused on a Twitter analysis considering several aspects, such as the impact of vaccines on the pandemic [
35,
36], the impact of COVID on the financial market [
37], the use or non-use of masks [
38], the effects of confinement [
39], and the relationship of COVID with announcements and news [
34], among others. In the case of Colombia, some contributions can be found, such as a study [
40] where 38,000 Twitter posts on COVID-19 vaccination were analyzed, highlighting opposition to the government with feelings of anger. In addition, a study analyzed the sentiments of 72,000 Twitter comments related to isolation, identifying the most frequent themes and words, resulting in fear as the predominant sentiment during the entire confinement period [
41].
In another study [
42], the researcher proposed a new approach to sentiment analysis of COVID-19 news headlines using deep neural networks, with high accuracy and an analysis of over 73,000 pandemic-related tweets from six global channels. In study by Kumari et al. [
43], the researcher proposed a deep learning mechanism for the sentiment analysis of COVID-19-related Twitter data, utilizing an intelligent lead-based BiLSTM and intelligent lead optimization to eliminate loss and improve accuracy. The proposed mechanism outperformed the baseline KNN technique, as assessed by metrics such as accuracy, sensitivity, and specificity.
Using pre-trained models for Spanish text has seen significant advancements in recent years. A BERT-based pre-trained language model (BETO) was introduced, which was trained exclusively on Spanish data from various sources, including Wikipedia [
44]. This model has been utilized in different applications for the sentiment analysis of Spanish tweets [
45], achieving accuracy levels of approximately 65%. Furthermore, another researcher presented the CaTrBETO model, which combines a caption transformer (CaTr) and BETO to understand the sentiments in tweets by jointly analyzing images and text [
46]. The impact of COVID-19 on mental and physical health was discussed in [
25], with social media found to be inducing fear and anxiety. The study analyzed Twitter data using a Hybrid Heterogeneous Support Vector Machine (H-SVM) for sentiment classification, outperforming RNN and SVM. In another paper [
47], the sentiment analysis of Twitter posts related to COVID-19 from March to mid-April 2020 was addressed, using natural language processing techniques and seven different LSTM-based deep learning models for analysis. The models were trained to classify tweets into three classes (negative, neutral, and positive), which is advanced compared with traditional machine learning classifiers. Similar works proposed different deep learning models. Jojoa et al. [
48], proposed a distilBERT transformer model for detecting positive and negative sentiments in open-text survey responses during the COVID-19 pandemic. The study aimed to contribute to understanding people’s sentiments during the pandemic and addressing future challenges related to lockdown. In another study [
49], a new approach to the sentiment analysis of Moroccan tweets related to COVID-19 was proposed. The model achieved high accuracy (86%) and outperformed well-known machine learning algorithms. The study showed that users’ sentiments change over time and are affected by the evolution of the epidemiological situation in Morocco.
In general, efforts have been made to develop systems that automatically analyze large amounts of data through natural language processing, machine learning, data mining, and cloud computing. The majority of the approaches focus on detecting polarity, while the more advanced techniques involve deep learning. There have been several contributions in various languages, including English, Spanish, French, and Chinese. Sentiment analysis has been applied to analyze tweets about COVID-19 in different languages, finding various sentiments such as fear, optimism, and disgust, among others.
3. Materials and Methods
Sentiment analysis has become an essential tool for understanding human behavior and its relation to relevant social events or phenomena, such as the COVID-19 pandemic. In this sense, the methodology described in this section is a significant contribution to the analysis of sentiments expressed in Spanish tweets collected on Twitter during the period of 2020–2021.
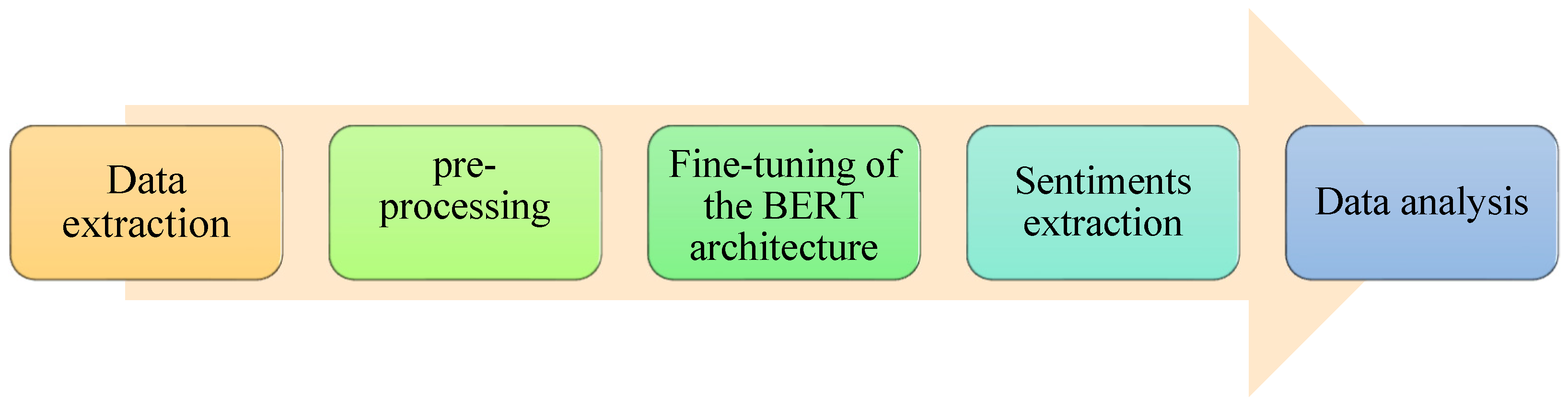
The methodology consisted of several phases (see
Figure 1), starting with data extraction through web-scraping techniques on the Twitter platform. Next, the pre-processing stage took place, which involved cleaning and filtering the collected data, and eliminating irrelevant or duplicated words or terms. Fine-tuning of the BERT architecture was then applied, a deep learning technique that allows for training a language model to identify and classify sentiments expressed in Spanish tweets. Once sentiment extraction had been carried out, the data analysis phase proceeded, which involved interpreting and visualizing the obtained results. The methodology described allowed for the identification of trends and patterns in the evolution of sentiments over time.
3.1. Data Extraction
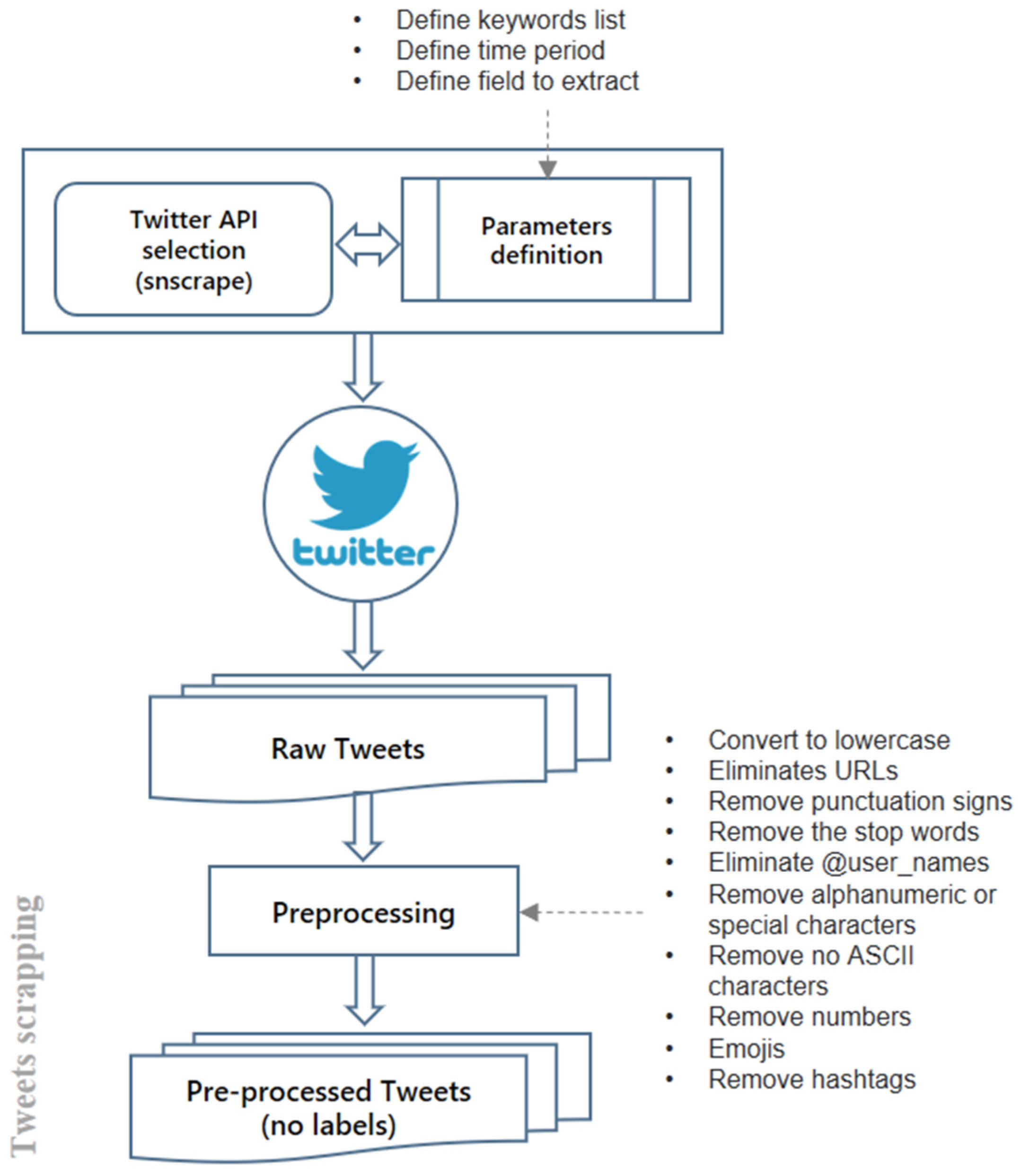
The data extraction process was carried out using data scraping on Twitter. Scraping is a technique for data gathering that transforms the unstructured data found into structured data, which is then stored locally for further analysis. We used the Python language. The general steps for data extraction are shown in
Figure 2. Algorithm 1 describes the general procedure applied in this phase.
| Algorithm 1 Data extraction |
| 1: | fields = [id, data, user, text, retuits, likes, reply, quote, retweeted, lang, …] |
| 2: | Keywords = [COVID, COVID19, COVID-19, Coronavirus, SARS-CoV-2] |
| 3: | max_tuits = 10.000 each day |
| 4: | for each day from 01/04/2020 to 30/12/2021 do: |
| 5: | search_str = “{} lang:{} since:{} until:{}”,keywords,’es’, day, day + 1 |
| 6: | tuits_generator = sntwitter.TwitterSearchScraper(search_str).get_items() |
| 7: | for count in range (0,max_tuits) do: |
| 8: | tuit = tuits_generator.next() |
| 9: | tuits_db = tuits.append(tuit[fields]) |
| 10: | save_on_file (tuits_db) |
3.2. Data Pre-Procesing
In this phase, a series of regular expressions were used to pre-process the text, removing irrelevant elements, such as mentions, links, Emojis, and punctuation marks. In addition, the hashtags were expanded and replaced by their corresponding text, removing the “#” symbol and separating the words that compose them. The hashtag expansion was carried out using a dictionary of 637,000 Spanish words. This pre-processing process permitted the analysis of sentiments in social networks since it allowed for reducing the complexity of the data by eliminating irrelevant elements and standardizing the information. We considered that expanding the hashtags and replacing them with their corresponding expanded text would permit us to hold key elements for sentiment identification. In this way, the application of sentiment analysis techniques, such as machine learning, natural language processing, and data mining, was facilitated.
3.3. Fine-Tuning of BERT Architecture
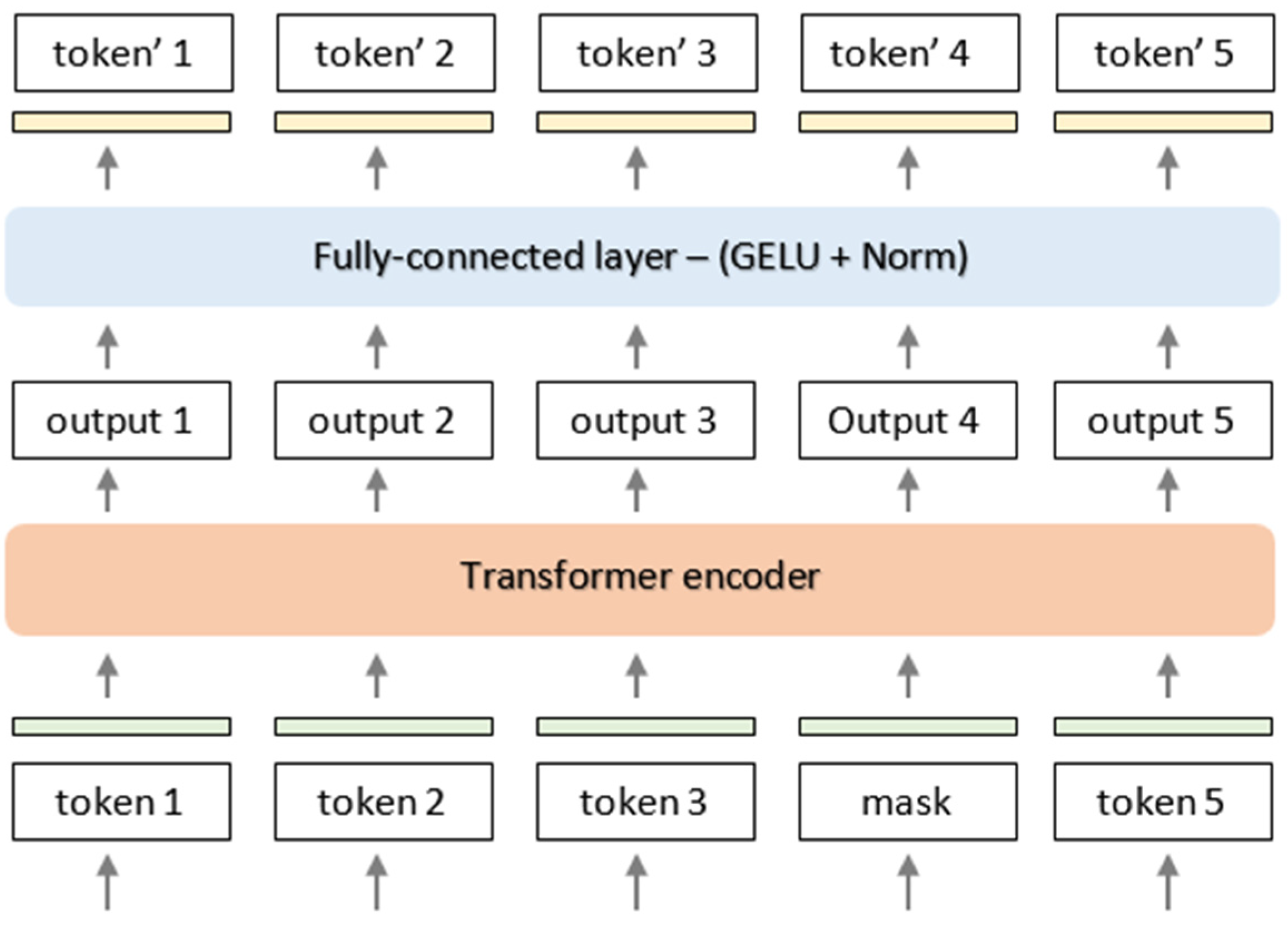
BERT has achieved state-of-the-art performance in various NLP tasks by employing a transformer-based architecture [
50] (see
Figure 3). The model is pre-trained on a large amount of text data and fine-tuned on a smaller labeled dataset for specific tasks [
14].
One of the most important aspects of the BERT architecture is that it allows researchers to capture a vast amount of contextual information from a large corpus of text, including bidirectional language models and masked language models. This permitted us to understand the context and relationships between the words and phrases better than what would be possible via other architectures. Unlike context-free models, such as Word2Vec and GloVe, BERT offers contextual embeddings for every word within a text, which is a crucial aspect of its architecture. Additionally, BERT’s ability to handle long-term dependencies and its bidirectional nature allows it to perform well on tasks that require more complex language understanding, such as sentiment analysis. Finally, BERT’s architecture is highly modular and can be fine-tuned for specific tasks with relative ease, making it a versatile tool for natural language processing applications. The BERT architecture comprises three primary components, including an embedding layer, several transformer layers [
51], and a task-specific output layer. During the embedding layer phase, an input word token would be transformed into a continuous vector space through an embedding matrix. In the subsequent Transformer layer, each word token would interact with all of the other word tokens via an attention mechanism, allowing for the exchange of information between them [
52,
53].
The main weakness of BERT is its inability to handle very long text sequences, as it considers only up to 512 tokens. This means that long sequences must be split into multiple short sequences of 512 tokens, which can limit the technique’s effectiveness for certain applications [
50]. However, in the case of Twitter analysis, the length of the sequence to be analyzed is not a significant limitation due to the inherent characteristics of tweets.
Fine-tuning BERT with tweets in Spanish was necessary to improve its performance in analyzing Spanish text, which has its own unique linguistic characteristics, such as differences in syntax, morphology, and vocabulary, compared to other languages. By fine-tuning BERT on Spanish tweets, the model could better capture the nuances of the sentiments in Spanish text, and therefore produce more accurate results.
The general methodology for carrying out the fine-tuning process of the BERT-based architecture followed the classical guidelines of this type of process in the area of machine learning. It began by selecting a pre-trained architecture. Next, the dataset that was to be used in the model adjustment phase was defined in order to train and validate the model. The dataset was selected based on criteria such as language, origin (Twitter), and the amount of available data.
3.4. Sentiment Extraction
Each tweet was fed into a classification model based on the BERT architecture for sentiment analysis. The input data was preprocessed using techniques such as tokenization, attention masks, and padding to create suitable input features for the model. To perform this task efficiently on large volumes of data, the processing was carried out using the CuDF library, which leverages the power of GPU acceleration. The resulting sentiment scores were then used to generate insights into the attitudes and opinions expressed in the tweets, which could be used for a variety of applications in fields such as social media analytics, market research, and public opinion monitoring.
3.5. Data Analysis
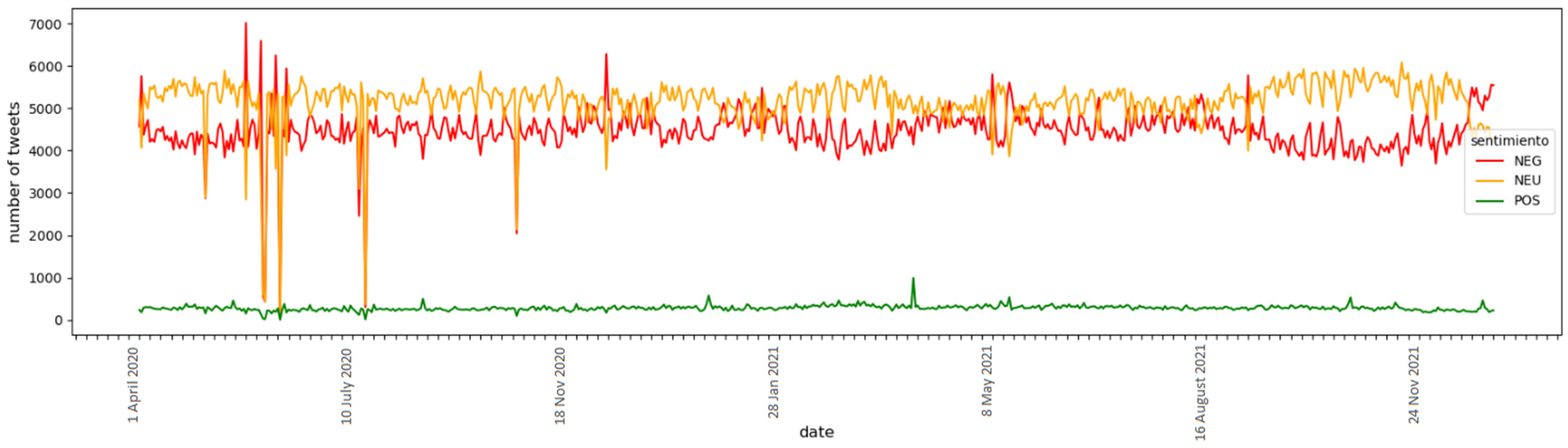
In the data analysis phase, we used the CuDF library to preprocess and manipulate the data. In this phase, sentiments were analyzed over time, discriminating by sentiment type. We performed an analysis of relevant events during the pandemic and searched for patterns to determine if they influenced the generation of sentiments analyzed in the collected data. To show and analyze the evolution of the sentiments, we created visualizations, such as time-series graphs and heatmaps, highlighting changes and trends in the sentiments over time. We also performed statistical analysis and hypothesis testing to identify significant differences in the sentiments between time periods, sentiment types, and other relevant variables.
5. Discussion
5.1. Bias and Representativeness of the Data on Twitter
The utilization of only Twitter as a data source in this research may incur a bias due to the platform’s characteristics and its usage patterns among users. It is noteworthy that Twitter does not encompass the entire Spanish-speaking population. The profiling of users based on variables such as age, gender, socioeconomic status, and education, among other factors, would be crucial in assessing the data’s representativeness on Twitter. Furthermore, certain users may exhibit a more dominant presence on the platform than others, thus impeding the generalizability of the findings to the broader population. Notably, the analysis of Twitter disregards individuals who do not utilize this platform, which may impart a bias on the results and generate incomplete or inaccurate conclusions. Consequently, the outcomes of this study may not be generalizable to the wider Spanish population and may not be a true reflection of reality.
Another interesting aspect regarding the data is the discrimination by country. However, Twitter’s own API reports that there is no guarantee that the reported location is accurate. In some cases, if the user has not granted location permissions, this value is often estimated and has low levels of precision.
Unfortunately, such discrimination against social groups accessing the platform is not possible through the API. In cases where it is possible, it may even have significant levels of imprecision, in the sense that some characteristics of users are reported but are also not validated by the social network itself.
Alternative social media and digital platforms may also be indicative of the general population, such as Facebook, Instagram, TikTok, and others. Each one has distinct attributes and attracts unique user groups, thereby resulting in potential variability in the biases based on the platforms employed.
5.2. Considering Emojis in Sentiment Analysis
We consider the fact that emojis play a significant role in modern communication, as they provide additional contextual information and can enrich the interpretations of text. However, we also recognize that the appropriate use of emojis in sentiment analysis is a challenging aspect and does not necessarily guarantee a significant improvement in the accuracy of classification models.
In our research, we have observed that emojis can be useful in certain contexts, as demonstrated by some researchers [
57,
58] who found that incorporating emojis in NLP models improved sentiment analysis performance. However, other studies have reported less conclusive results. For instance, in [
59], the use of emojis and hashtags was found not to significantly improve performance.
One of the most relevant aspects when including emojis is addressing the challenges that arise in sentiment analysis. These challenges include differences in emoji representations across different platforms, variations in emoji usage across cultures and social contexts, and how emojis can affect the polarity of a message. The sentiment of a tweet and the sentiment conveyed by an emoji should be analyzed independently; we should also consider how their combination affects the overall sentiment of the message [
60].
In another study [
61], the researchers established that emojis, while ubiquitous in modern digital communication, presented differences in their usage across languages and countries. The study analyzed the relationship between emoji usage and linguistic and geographic factors, using millions of tweets to do so. The results showed that the diversity in emoji usage varied across different languages and countries. Another researcher [
62] highlighted variations in the interpretations of emojis across different cultures and communities, which could impact the effectiveness of sentiment analysis when emojis are included. In a study carried out in two Spanish cities [
63], it was concluded that the overall semantics of the subset of emojis studied were preserved in both of these cities, but some of them were interpreted differently. In another study [
64], researchers discussed the ambiguity in the meaning of emojis and the need for a sense network for emojis, indicating that there may be difficulties in interpreting the meaning and sentiment of emojis in sentiment analysis.
In our study, we examined over six million Spanish-language tweets from diverse sources, ranging from Mexico to Argentina, and even including sources in Europe. Given the diversity of cultures represented, we believe that the appropriate use of semantic meaning in terms of emojis is an important topic. However, due to the scope of this study, we made the principal decision to exclude emojis to prevent the analysis from becoming overly complex. Nevertheless, we reported the results of processing the tweets with a model that includes emoji interpretation. The findings on the benefits are inconclusive, and a much deeper analysis is required in this regard. Further research into cultural differences in emoji use and interpretations could provide valuable insights into the effectiveness of incorporating emojis in sentiment analyses for various populations.
6. Conclusions
This study collected a total of 6,306,621 tweets in the Spanish language, using various search terms related to COVID-19. The data was stored using The Hierarchical Data Format version 5 (HDF5), an open-source file format suitable for handling large and complex data.
The collected tweets were pre-processed using the CuDF library for GPU acceleration. The sentiment analysis was performed using a BERT-base architecture trained on a dataset consisting of over 1.6 million tweets with positive, negative, and neutral labels. A balanced dataset of 45,000 tweets was used for fine-tuning the model, which was then evaluated on a test set of 9000 tweets.
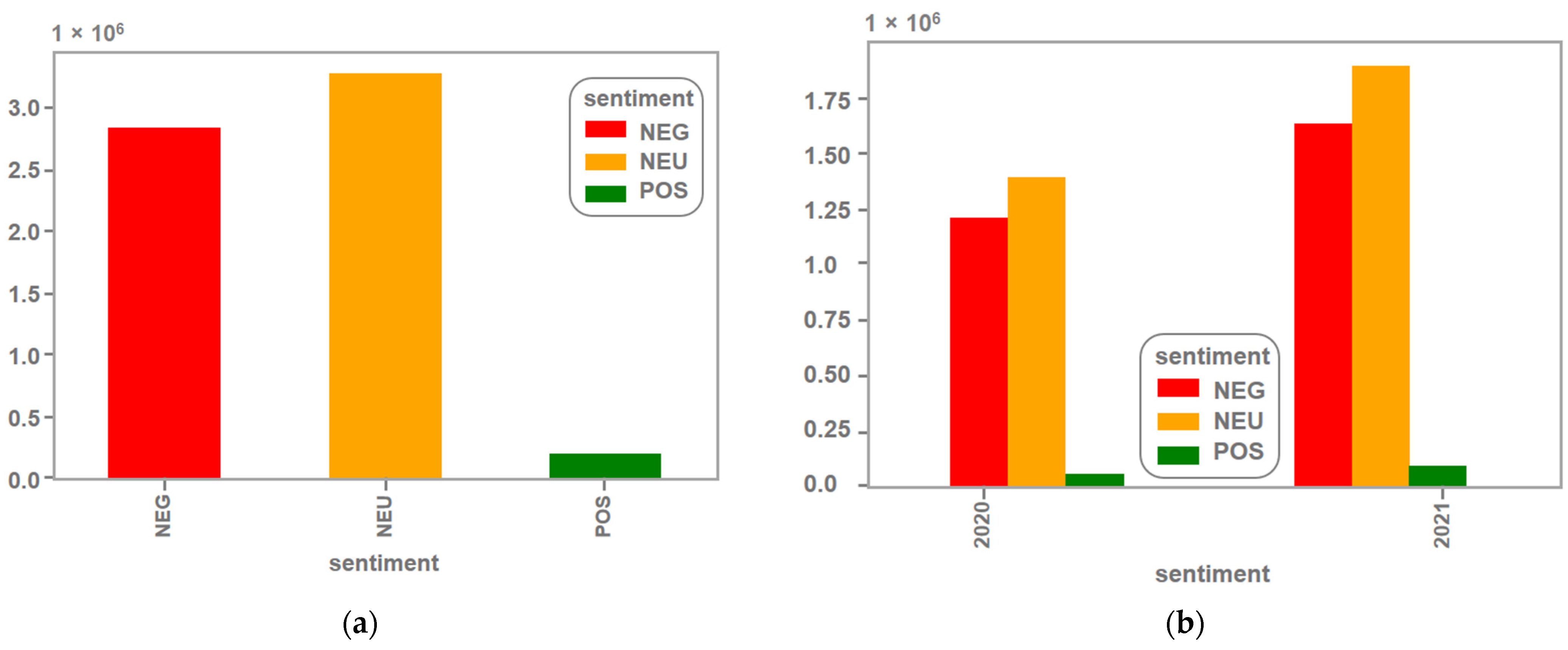
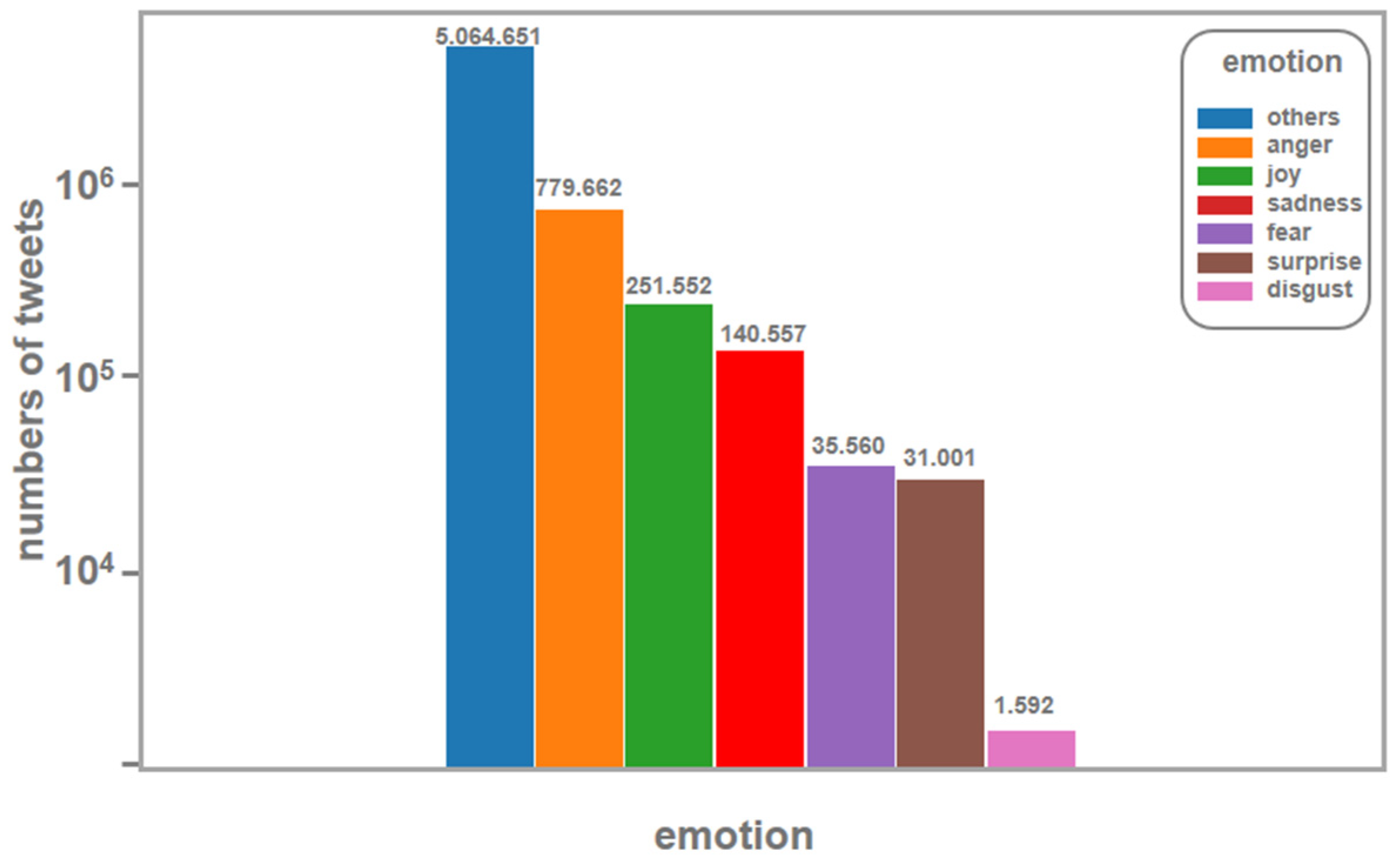
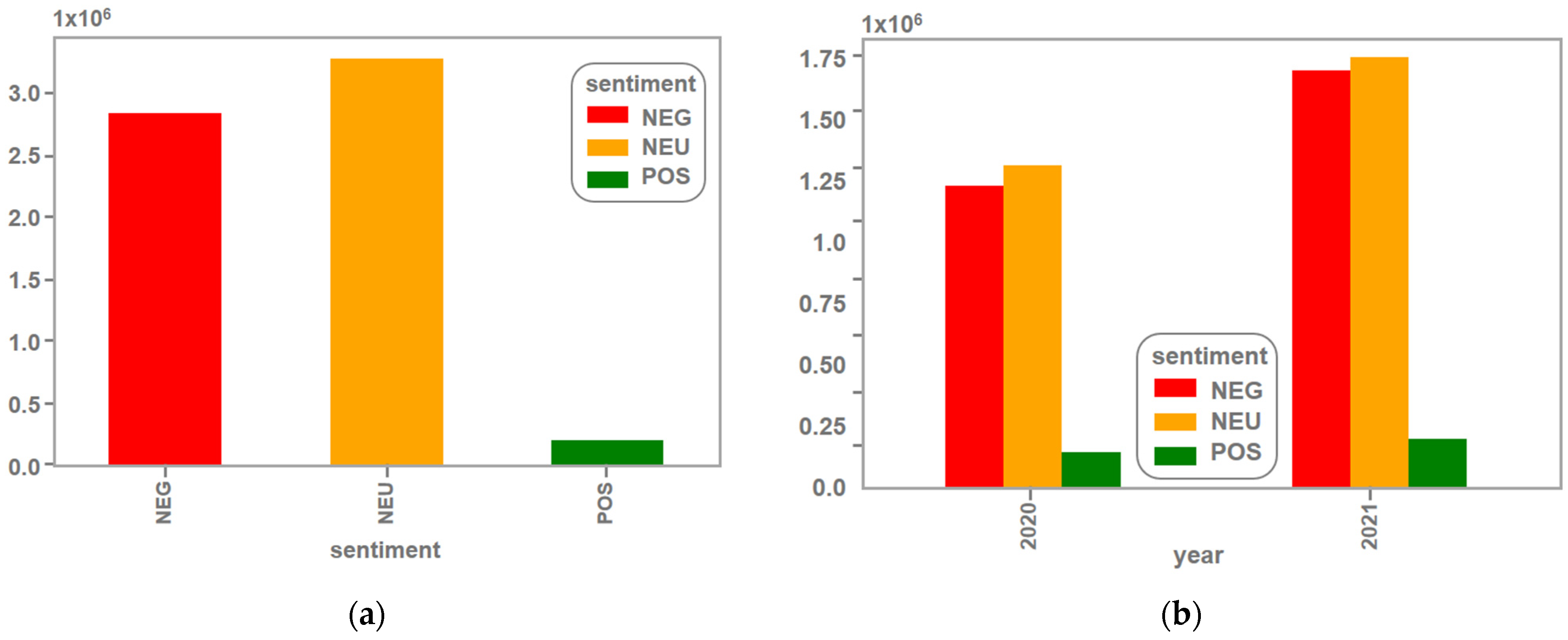
The results of this study revealed that the BERT-based model achieved an accuracy of 89%, with the neutral category having the highest number of tweets, followed by the negative category, while positive tweets were relatively few. This study also found that the predominant emotion expressed in the tweets was anger, followed by joy, while sadness and fear were also significant. The analysis of unique users revealed a high level of heterogeneity in the data collected.
Regarding future work, it is proposed that researchers should replace Emojis with words that correspond to the sentiments that they represent. Replacing Emojis with these words would prevent the loss of representative sentiment information. In the same sense, a sarcasm detector could decrease the false positive rate, considering that this type of text is frequently employed on a social network, such as Twitter.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}