1. Introduction
Over recent years, one of the most concerning and time-consuming issues faced by both the scientific community and public institutions has been the development of tools for assessing the seismic vulnerability of existing buildings portfolios, with the aim to define reliable risk mitigation plans. To this end, several large-scale oriented approaches have been proposed, whose main concern has been to identify the most vulnerable parts of the existing building stock, starting from some consolidated procedures, such as [
1,
2] for the Italian case.
In general, four classes of methods are available: (a) empirical methods; (b) mechanical methods; (c) rapid visual screening methods; and (d) hybrid methods. Empirical methods allow to estimate a vulnerability function through statistical processing of observed data. Such methods are usually employed when the data collection of earthquake damages is available (e.g., [
3] for the Italian case) and, taking as reference a homogeneous samples of buildings, it is possible to extract the probability that a certain damage may occur. Several use cases have been explored, such as residential buildings [
4,
5,
6], school buildings [
7], and masonry churches [
8,
9]. Mechanical methods consist in the definition of a vulnerability function based on numerical models, which represent an ensemble or a class of buildings. Obviously, the performance of numerical models is strongly dependent from both data availability and the accurateness of the models themselves. Among the myriads of available examples, it is worth reminding about the methodologies developed for special classes of buildings, such as masonry aggregates [
10], school buildings [
11], and unreinforced masonry buildings [
12]. Still, rapid visual screening methods consist in the estimate of vulnerability indices by means of interview-based procedures, where data are collected and elaborated in a proper algorithm (e.g., [
13]). Finally, hybrid methods allow to mix the precedent methods.
In the very recent years, on the basis of these methodologies, new advanced techniques are under development, such as the ones based on the machine-learning (ML) paradigm. Concerning the structural engineering field, Ref. [
14] proposed a comprehensive review of the state of the art related to the use of ML, specifying several classes of interest, such as seismic hazard analysis, structural identification and damage detection, seismic fragility analysis and structural control. Looking at vulnerability analysis, Ref. [
15] proposed ML algorithms to support regression analysis in the prediction of damages on buildings. In [
16], authors proposed a method to estimate damages and vulnerability of traditional masonry through artificial neural networks. Using the same approach, in [
17], authors proposed a method to assess hazard safety, by optimising multi-layer perceptron neural networks. In [
18], authors proposed a mobile app prototype to predict vulnerability of buildings by observing their geometrical features. Still, other works on the use of ML in the seismic vulnerability field can be mentioned, such as the works by [
19,
20]. A recent proposal, named
VULMA (VULnerability analysis using MAchine-learning) [
21,
22], assigns a vulnerability index to a building on the base of a simple image. In detail,
VULMA is composed by four modules: (1)
Street VULMA, for processing raw data to extract photos of buildings within an area; (2)
Data VULMA, which allows domain experts to attribute labels to each photo and store the entire input; (3)
Bi VULMA, which is composed by some set of ML algorithms, based on convolutional neural networks (CNNs) [
23], capable to identify the labelled features of buildings on a photo; and (4)
In VULMA, which provides a simple vulnerability index, using the algorithm proposed in [
24].
It is clear that VULMA heavily relies on images, and CNNs need to be extensively trained for a reliable identification of the seismic vulnerability index. Hence, in this paper, the data set on which VULMA tools have been based, named View VULMA, is presented, along with solutions adopted to overcome some of the issues occurred during the acquisition of the images sample. It is worth pointing out that a large-scale image data set could represent a critical resource in automatising and developing advanced content-based systems for the automatic recognition of seismic vulnerability. As a matter of fact, several sophisticated and robust models and algorithms exploiting images freely available on the web have been recently proposed; this resulted in improved applications for users to index, retrieve, organise and interact with these data. Herein, we exploited the imagery acquired by Google during its surveys around the globe, along with more visual data automatically fetched from the Internet, to enrich the existing contextual data (e.g., interview-based surveys).
The rest of the paper is organised as follows. In
Section 2, the requirements that lead the creation of
View VULMA are described. In
Section 3, the process used to create
View VULMA is presented. In
Section 4, an application of
View VULMA is described. Finally, in
Section 5, conclusions and future developments are reported.
2. Requirements of View VULMA
The data set at the base of
VULMA [
21], named
View VULMA, has been initially created by means of the
VULMA submodule named
Street VULMA. The latter, thanks to a proper tool (accessible and usable at [
22]), allows users to download photos by Google Street View service (see
Section 3.1 for the detailed explanation), by varying three different parameters: (a) the vertical angle of the camera (defined, in this context, as
pitch); (b) the horizontal angle of the camera (defined, in this context, as
field of view); and (c) the angle where the camera is headed (defined, in this context, as
heading). Hence, considering a spatial granularity of 5 m, images of two consecutive points are downloaded in JPEG format and resized using a resolution of
pixels. As for other details, such as time of day and distance from the buildings, both vary from image to image, to ensure a proper heterogeneity in the dataset. Obviously, the only requirement which has led the selection of
View VULMA images is that the building itself should be clearly visible (see
Section 3.3 for more details).
Thus, View VULMA has been conceived, and subsequently designed, on the basis of three main requirements:
Scale: The first requirement is the scale, considering that View VULMA has the main aim to provide a comprehensive set of images covering all the typological features observable on buildings, independently from the type of building itself. In its current version, View VULMA contains almost 3000 pictures of different images; however, this quantity is constantly growing, as we plan to expand it to at least images.
Evaluation parameters: Most of the image data sets available in literature are labelled with a single and specific label. This was not the underlying idea of
View VULMA, considering that using a single label would result in an over-complicated, opinable and somehow
fuzzy class label. Instead, we characterised each image in terms of different aspects, using a modular approach. The same image can be used for different scopes: As an example, an image representing a four-storey building with pilotis (
Figure 1) can be used for training two networks, one for identifying the overall number of floors, and the other for detecting pilotis. To this end, 14 different parameters have been identified, making the data set able to be used in as many different independent classification tasks. A desirable side effect of this design choice is that the number of possible classes defined for each classification task is greatly reduced, and this can be seen as a way to mitigate the problem of the curse of dimensionality.
Diversity: The third requirement of View VULMA consists in a feature of the overall data set, which should be characterised by enough intra- and inter-class variations. In other words, for each parameter, different labels should be properly described accounting for the variation of appearance, position, viewpoint and pose. Furthermore, images with occlusions and noise are not discarded, in order to improve the overall diversity provided by the data set and, at the same time, to train and test classification methods under challenging conditions.
4. Applications and Availability of View VULMA
View VULMA has been used in [
21] as a basis for creating one of the modules by which the
VULMA toolset is composed, specifically
Bi VULMA. In the paper, it is shown that, despite the relatively small size of the early version of
View VULMA used, optimal results can be easily achieved on each parameter by using MobileNetV2 [
27] and transfer learning [
28]. Specifically, authors claim that an overall accuracy of
in cross validation can be achieved by using ADAM [
29] as the optimization algorithm and a standard cross-entropy loss function. In addition,
Bi VULMA offers several other network base models for comparison, such as Xception [
30], ResNet152v2, InceptionResNetV2 and MobileNetV2 [
31,
32].
From
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15, the comparison among six models of CNNs, specifically VGG19 [
33], ResNet50v2, InceptionV3, MobileNetV2, DenseNet [
34,
35] and NasNetMobile, is shown for each parameter. This comparison has been carried out using mainly
Bi VULMA but alsi including a specific integration for VGG19 and DenseNet, which are not currently available within the tool. It is worth noting that the selection of the CNNs models is not casual and it has been made according to two main principles: (i) They are the most recent models developed and available in the scientific literature; (ii) they have been selected according to the possible hardware at disposal to the authors, also considering the best performances available for these kinds of applications. As for results, in all Tables, both the loss and accuracy are shown for transfer learning (20 epochs) and fine tuning (10 epochs) with a learning rate of 0.001. Each base model has been pre-trained on ImageNet, and a standard train/validation/test ratio of 70/20/10 has been selected over each topological parameter. The tests took two days to be performed on an NVIDIA GeForce 3070 RTX with 10 GBs of RAM. As expected, fine tuning the entire model after a round of transfer learning further improves accuracy results, even in the most challenging problems, which are the classification of the total number of storeys and the classification of the total number of openings. Specifically, these parameters are challenging mainly due to the high number of possible classes, and probably require more data with respect to the other parameters. It is also interesting to underline how both ResNet and Inception outperform other models in almost any situation, hence further exploration of these architectures along with their successors may be required as the
View VULMA grows.
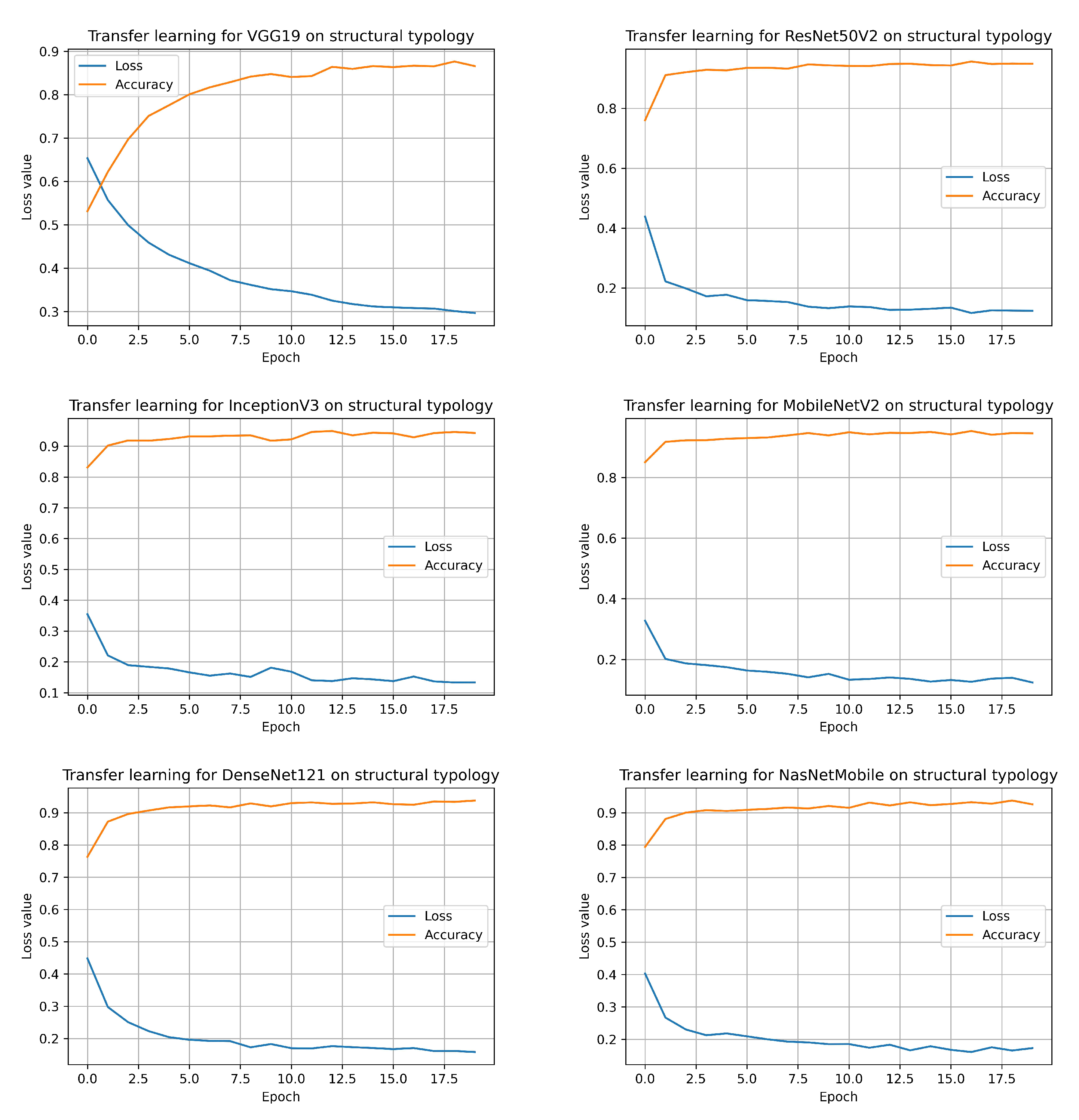
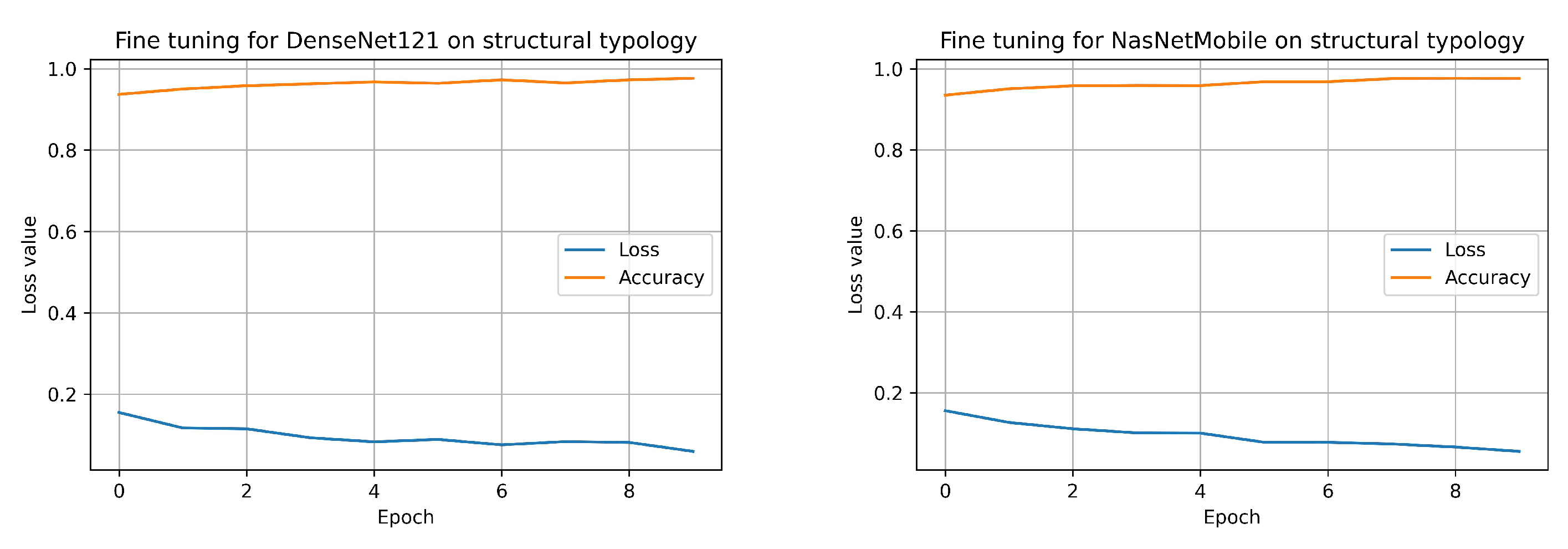
Still, only for the parameter structural typology, the graphs about the training for all employed CNNs models are reported, showing the trends of both loss and accuracy for transfer learning (
Figure 3) and fine tuning (
Figure 4) phases.
In the end, it is important to underline that transfer learning has been preferred as the quantity of data available in
View VULMA is still limited. However, results are promising, and show the potential of using this for developing an end-to-end ML tool for seismic assessment. As for its availability, we plan to publicly distribute
View VULMA as soon as possible; as already stated in
Section 2, our goal is to incorporate at least
images of different buildings before it is made available to a wider audience. However, interested researchers can contact the corresponding author to receive a preliminary version of the data set.
5. Conclusions
Currently, View VULMA constitutes only a restricted data set, which for making reliable a tool such as VULMA needs to be strongly improved, accounting for other typological parameters (e.g., steel and precasted buildings). Still, the improvements of the data set could be used to identify other sources of vulnerability, such as structural and non-structural elements decay. To further speed up the construction process of the data set, we will continue to explore more effective methods to evaluate user labels, by optimising the number of needful repetitions to accurately assess each image. In summary, to complete View VULMA, it is necessary: (1) to increase the number of labelled images and the number of parameters to label; (2) to deliver View VULMA to the research community directly by making it publicly available and readily accessible online; (3) to promote View VULMA through an online platform where everyone can contribute to increase the data samples and, at the same time, to benefit from View VULMA as a resource. In the end, View VULMA and in a particular way, VULMA, could become a central resource for a broad range of vision-based seismic vulnerability assessment research.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}