We approach the problem of learning ECG representation for stress detection using contrastive SSL. The application of contrastive SSL has become a popular option in computer vision, natural language processing (NLP) and other fields [
20]. Many frameworks have been proposed in the study of contrastive SSL, such as SimCLR, BYOL, and SimSiam [
20]. We base our experiments on the SimCLR framework due to its simplicity and dominance in computer vision [
12].
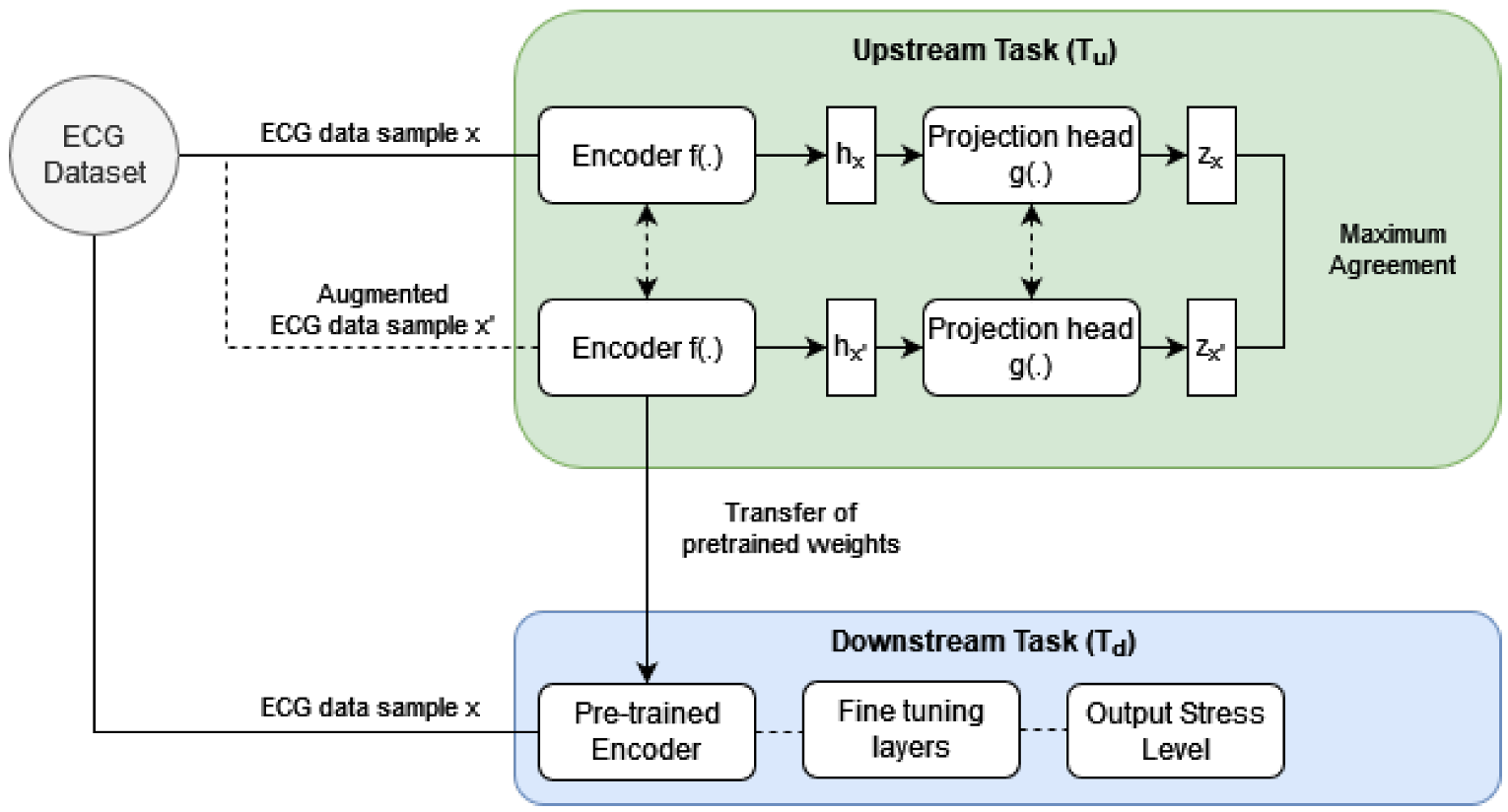
Contrastive SSL is a two-step training process that consists of an unsupervised pre-training upstream task () followed by a supervised downstream task (). In the , a neural network model is trained to learn a high-level representation of ECG data without depending on ground truth labels. Similar to the concept of transfer learning, in the following neural network weights from the are used as an initialization for training the model to predict stress from ECG data.
3.6. Dataset
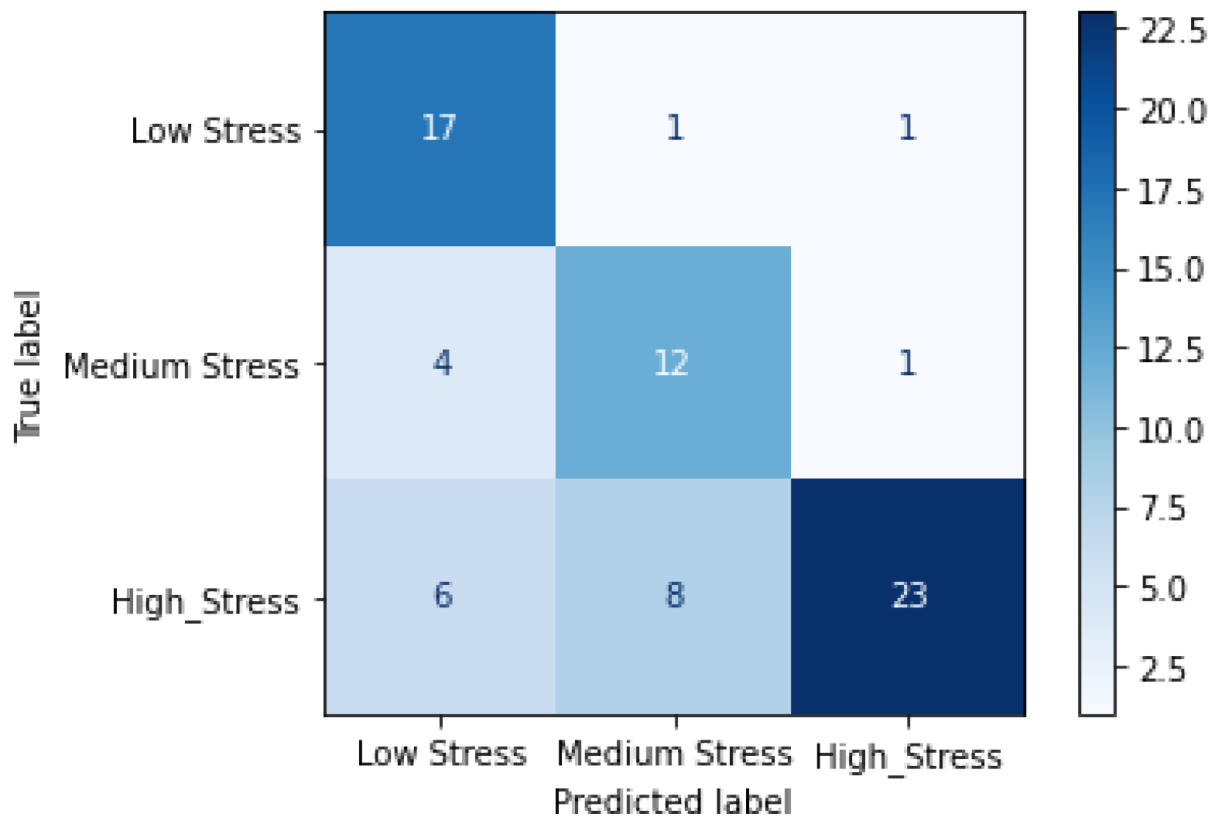
We evaluate our model on the WESAD (Wearable Stress and Affect Detection) [
23] and RML (Ryerson Multimedia Laboratory) [
24] datasets. The WESAD dataset includes data from 17 participants collected over four tasks, each aimed at inducing a different effect. The affect states studied are neutral, stressed, amused, and meditated. The duration of the collected data is around 33 min for each participant at a sampling rate of 700 Hz. The RML dataset includes ECG data from 12 participants collected during a stress-inducing experience in virtual reality (VR). Participants experienced a dynamic horror roller coaster ride in VR. The stress levels studied are low, medium, and high. The duration of the data collected for each participant is around 3 min at a sampling rate of 256 Hz.
We downsample the WESAD dataset to 256 Hz to match the sampling frequency of the RML dataset [
8]. We then remove baseline wander by applying a high-pass Chebyshev filter at a pass-band frequency of 0.8 Hz [
8]. Finally, we perform user-specific z-score normalization [
8] followed by clipping of the signal where ever saturation of the sensor was observed. Once the data is pre-processed, it is windowed into segments of equal duration. We use a 10 s window for the WESAD dataset. The total samples we obtained for the WESAD dataset are 4569. As the RML dataset is considerably small compared to WESAD, we use a 5 s window to segment the RML ECG signals to increase data points for training. Furthermore, we also apply a data augmentation method, Synthetic Minority Oversampling Technique (SMOTE), to balance out the class distribution in the RML dataset. The total samples we obtain for the RML dataset are 726.
3.7. Experimentation
We implement our proposed framework using Keras and train on an Nvidia GeForce RTX 2070. Through our experiments, we aim to evaluate the performance of contrastive SSL vs. non-contrastive SSL for ECG-based stress detection.
On the WESAD dataset, our upstream model is trained using the Adam optimizer with a learning rate of 0.0001 over 20 epochs. On the RML dataset, our upstream model is also trained using the Adam optimizer with a learning rate of 0.0001 over 25 epochs. The batch size used for upstream training on both datasets is 32. Similar to prior works such as [
8], the hyperparameters and model architecture for the upstream models were tuned based on the training set. The variety and combination of tuning parameters tested were based on empirical reasoning and a series of trial and error experiments. In particular, the learning rate, batch size, and training epochs were configured based on decreasing training loss. This is because the metric performance, i.e., accuracy, F1 score, etc., of the upstream model serves no purpose in stress detection. The purpose of the upstream model is to learn a high-level representation of the dataset is achieved based on the training performance.
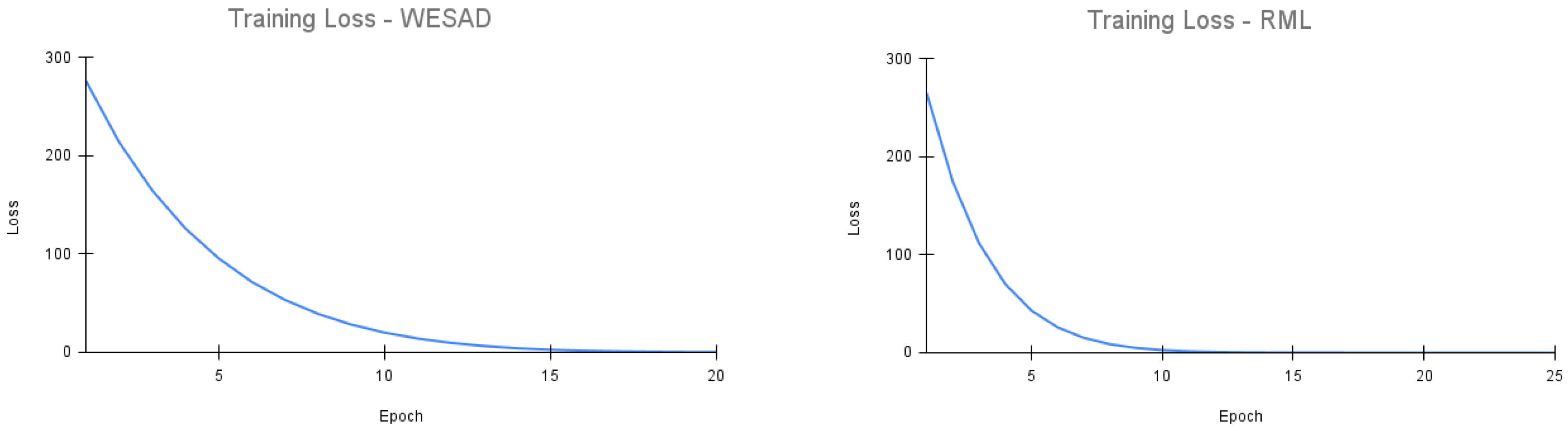
Figure 2 depicts the training loss of the upstream model for the WESAD and RML datasets, respectively. We see that the loss stabilizes well by the end of training. Furthermore, the upstream model was trained on the entire WESAD and RML dataset, respectively, for the WESAD and RML experiments. The use of the entire dataset for upstream training is seen in prior studies for self-supervised learning, for example, [
8]. As the upstream model does not use any actual ground truth labels but rather trains on pseudo or automatically generated labels, bias due to repetition of data is not a major concern.
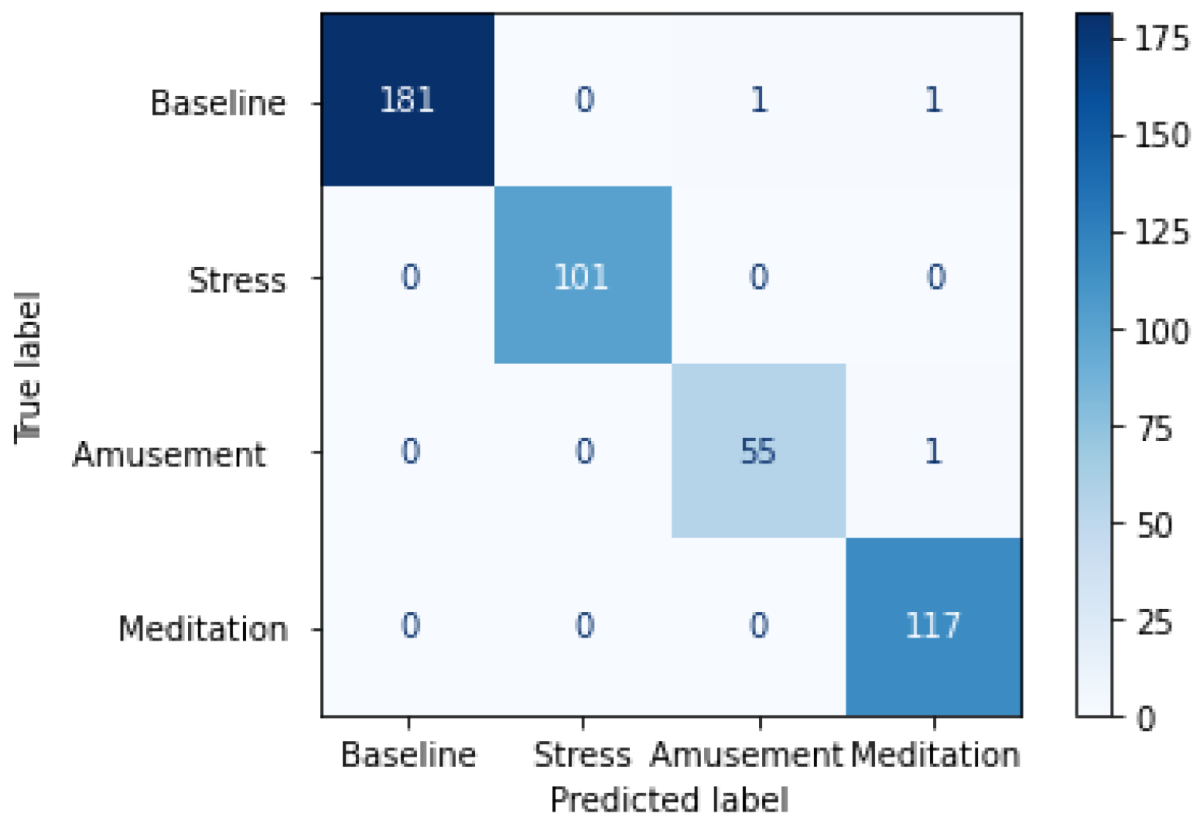
The downstream model is trained using the Adam optimizer with a learning rate of 0.001. The uses a batch size of 128 and is trained over 250 epochs for the WESAD and 150 epochs for the RML dataset. The hyperparameters for the downstream model are also fine-tuned based on decreasing training loss. Ideally, a validation set to tune the hyperparameters would have been a better experimental setup. However, with the RML dataset being limited in size, we chose to perform hyperparameter tuning based on the training performance. After hyperparameter tuning, we perform our downstream experiments in 10-folds, with random shuffling of data in each fold. In each fold, the data is split into a given train and test ratio. The downstream model is initialized using the weights of the upstream encoder and trained using the train set. The model’s performance is then tested on the test set.
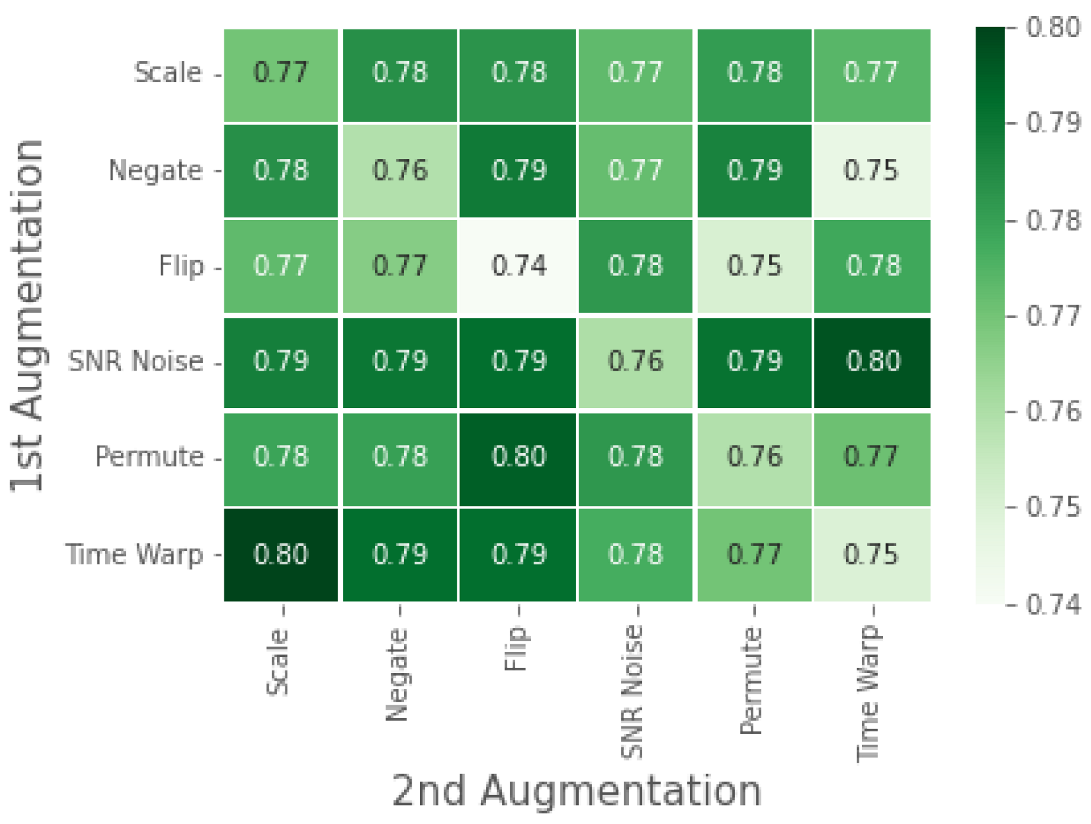
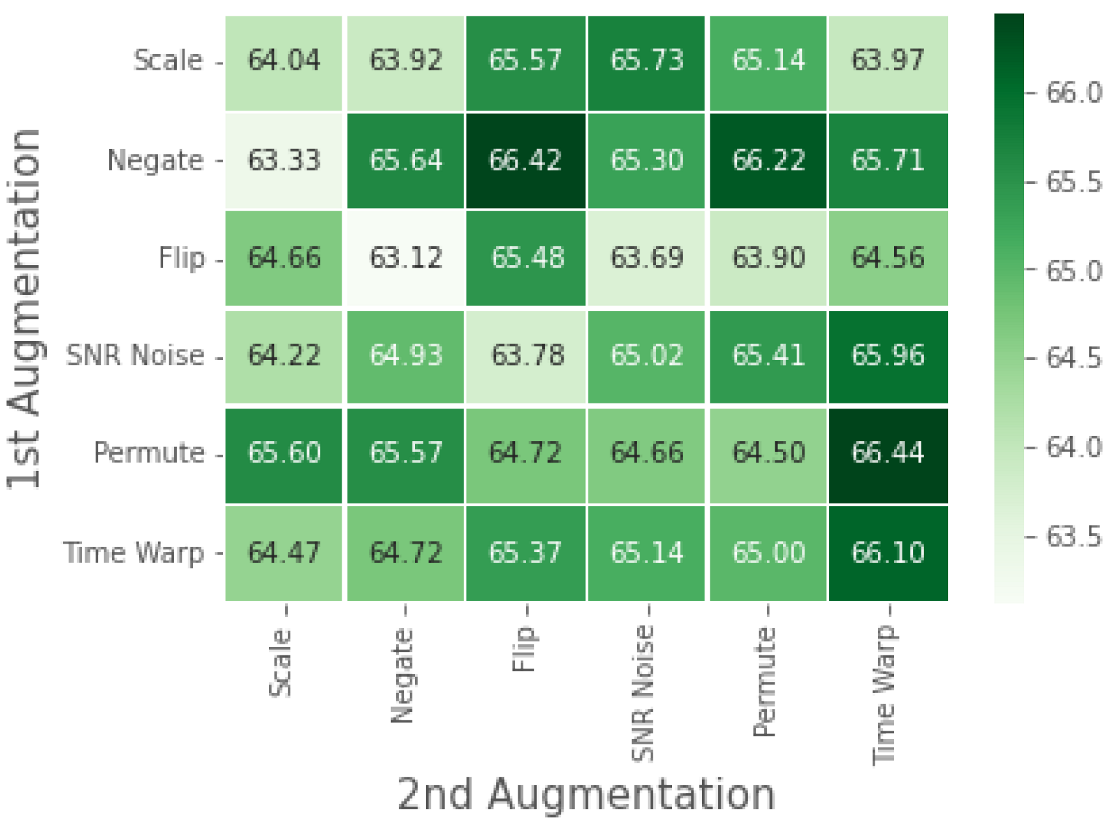
We perform a detailed ablation study to understand the impact of single augmentations versus using a composition of augmentations in
. Similar to the approach used in the SimCLR [
12] experiments, we analyze the downstream performance based on varying augmentation combinations used in
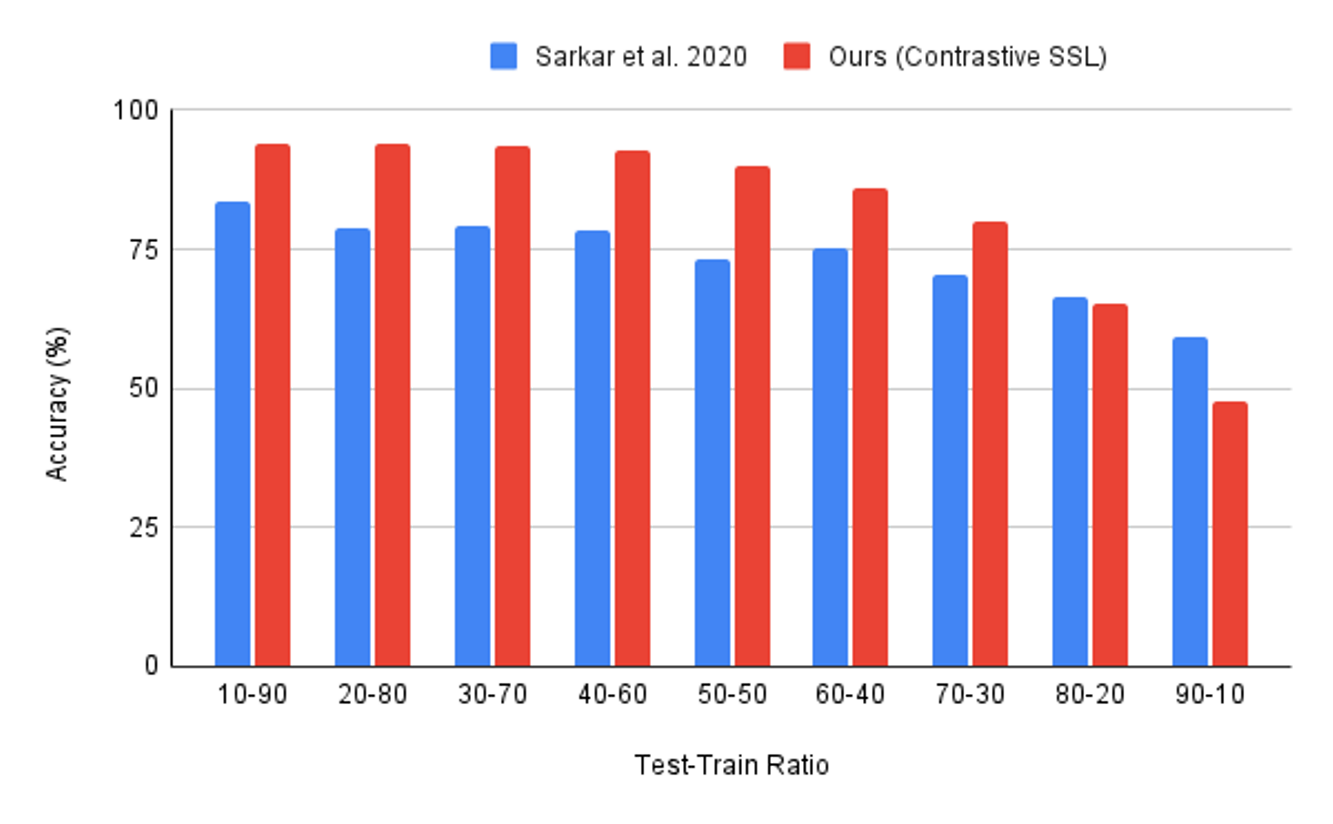
. Furthermore, we also study the impact of pre-training on varying ratios of the test to train data used in the
.
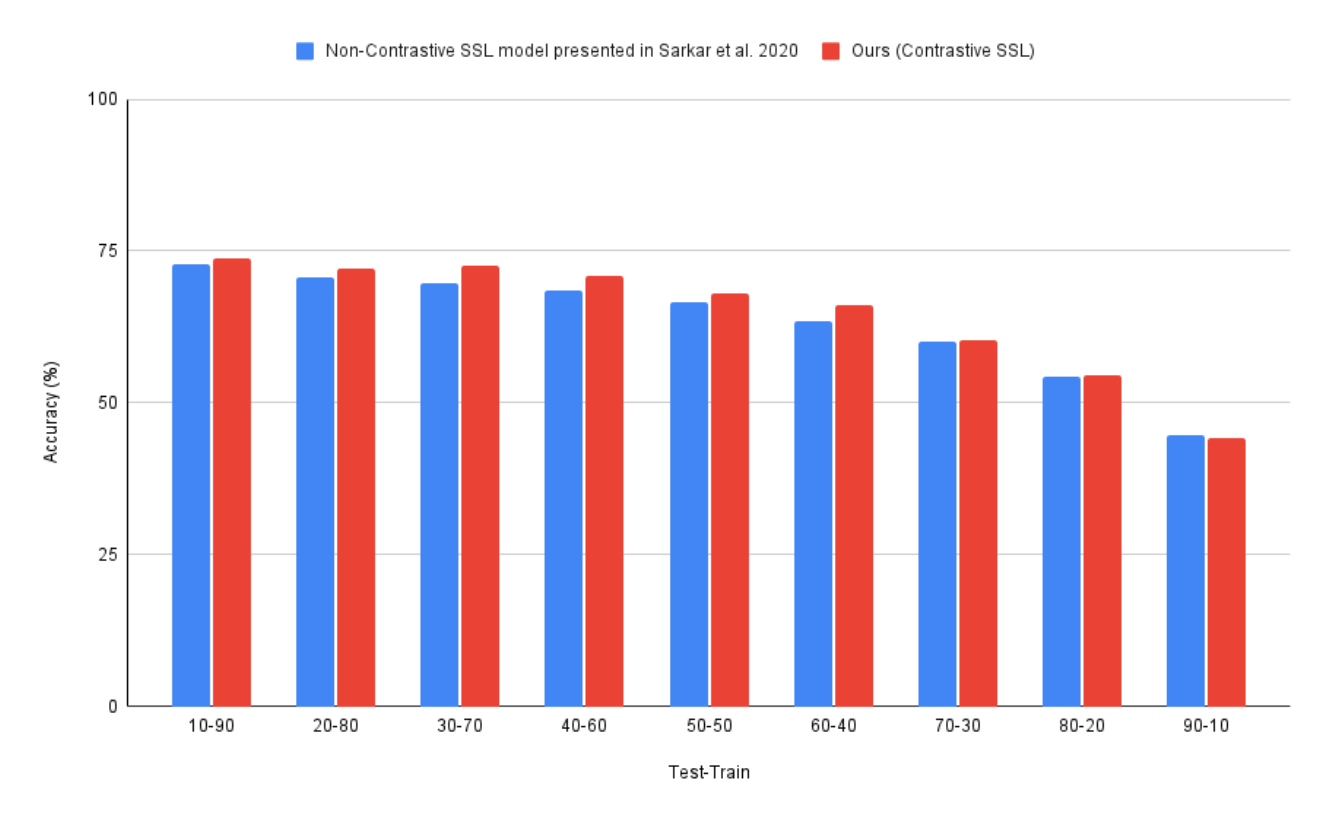
We compare our contrastive SSL model’s performance to that of three benchmarks: non-contrastive SSL, fully-supervised learning, and classical machine learning with extracted HRV features. The non-contrastive SSL benchmark used in our experiments is the one presented in [
8]. This is an auxiliary-based self-supervised learning model, which to our knowledge is the only other self-supervised learning approach used for stress prediction from ECG data. Comparing this benchmark allows us to assess the performance of contrastive vs. non-contrastive SSL for ECG-based stress detection. The fully supervised benchmark is identical to the 1D CNN described for the
. The only difference it has to our contrastive SSL framework is the lack of upstream pre-training. Essentially, this benchmark helps us assess the improvement in performance we see with upstream pertaining. Besides assessing stress from ECG data, the use of HRV features are widely used in literature and is considered the gold standard for stress assessment [
5,
25]. We train a support vector machine (SVM) on HRV features calculated from ECG data. We extracted the following HRV features, following the work [
26]: Heart Rate (HR), Root Mean Square of Successive Differences (RMSSD), Average Value of N-N Intervals (AVNN), Standard Deviation of N-N Intervals (SDNN), pNN50, Very Low Frequency (VLF), Low Frequency (LF), High Frequency (HF), and Total Power Spectrum (TP). These experiments were also performed in 10 folds with a random shuffling of data in each fold.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}