
Extracting Features from Poincaré Plots to Distinguish Congestive Heart Failure Patients According to NYHA Classes

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Population
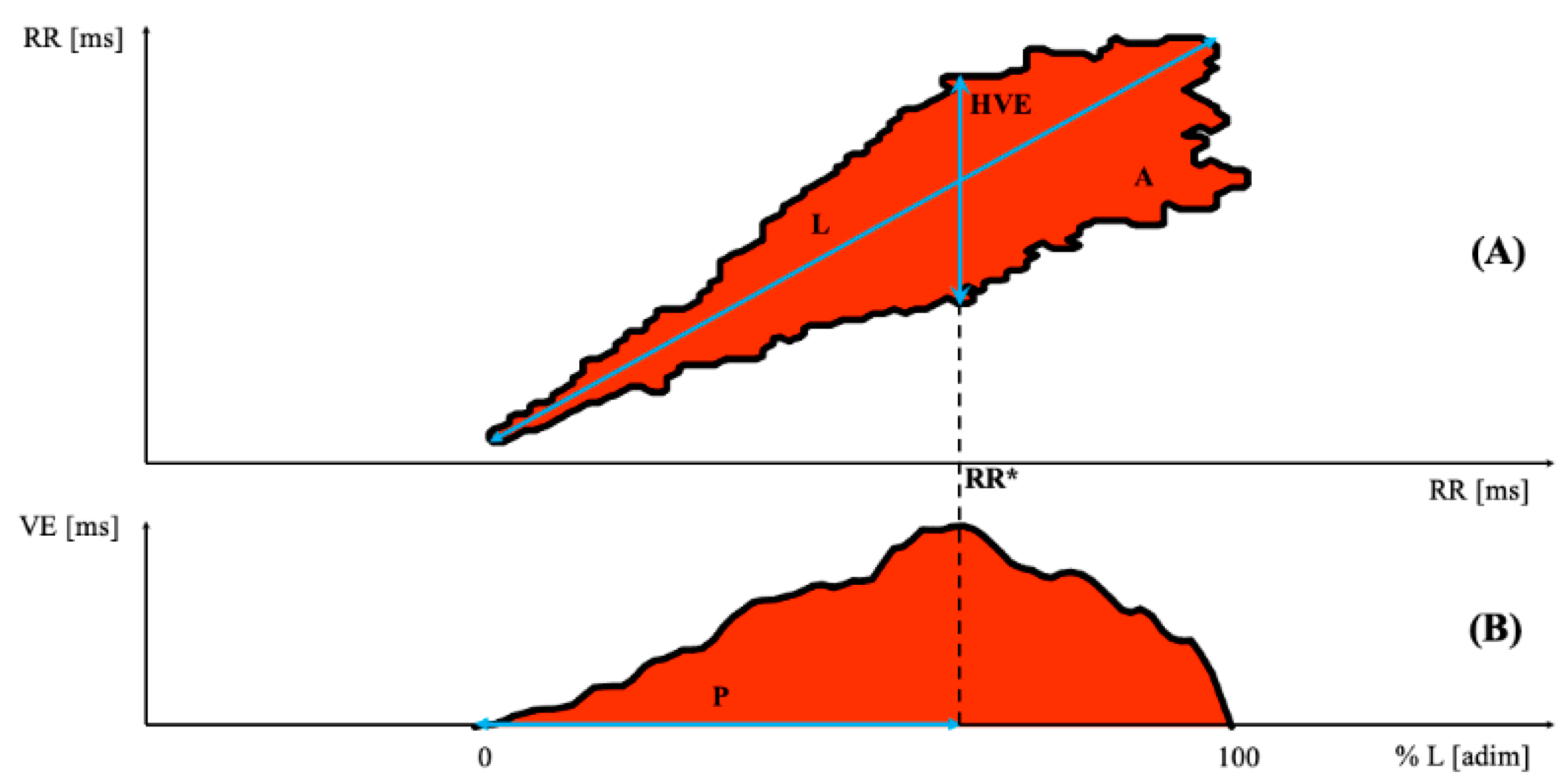
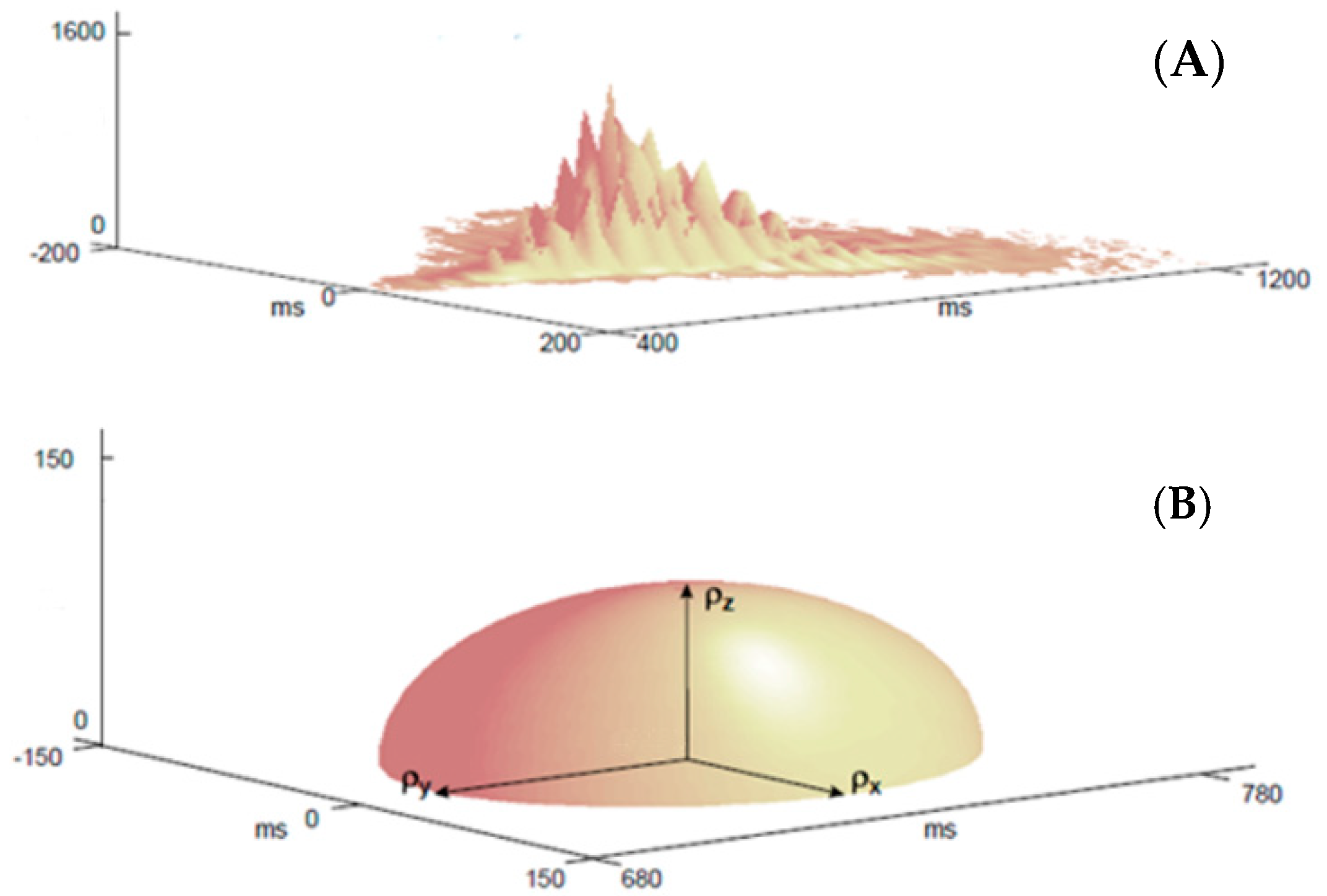
2.2. Poincaré Plot Analysis
2.3. Statistical Analysis
- The absence of multicollinearity.
- An outlier’s detection was performed by computing Cook’s distance and the Center Leverage Value adimensional coefficients.
- According to Van Smeden et al. [40], the ratio between the sample size of the smallest class and the number of independent variables should be greater than 10.
2.4. Machine Learning: Tool and Algorithms
3. Results
3.1. Statistical Analysis
3.1.1. Univariate Statistical Analysis
3.1.2. Multivariate Logistic Regression
- The multicollinearity was checked and Table S1 in the supplementary material shows the correlation among all the variables. At least one of the variables whose correlation was greater than 0.7 was removed from the model.
- 8 outliers were removed (Figure S1 in the Supplementary Materials).
- The ratio between the sample size of the smallest class and the number of independent variables was greater than 10 [40].
- Table 3 shows the results obtained from the MLR.
3.2. Machine-Learning Analysis
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Malik, M. Heart rate variability. Curr. Opin. Cardiol. 1998, 13, 36–44. [Google Scholar] [CrossRef]
- Işler, Y.; Kuntalp, M. Combining classical HRV indices with wavelet entropy measures improves to performance in diagnosing congestive heart failure. Comput. Biol. Med. 2007, 37, 1502–1510. [Google Scholar] [CrossRef] [PubMed]
- Cohn, J.N. The Management of Chronic Heart Failure. N. Engl. J. Med. 1996, 335, 490–498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nolan, J.; Batin, P.D.; Andrews, R.; Lindsay, S.J.; Brooksby, P.; Mullen, M.; Baig, W.; Flapan, A.D.; Cowley, A.; Prescott, R.J.; et al. Prospective Study of Heart Rate Variability and Mortality in Chronic Heart Failure. Circulation 1998, 98, 1510–1516. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stein, P.K.; Rich, M.W.; Rottman, J.N.; Kleiger, R.E. Stability of index of heart rate variability in patients with congestive heart failure-results of the United Kingdom heart failure evaluation and assessment of risk trial (UK-Heart). Am. Heart J. 1995, 129, 975–981. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol.-Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [Green Version]
- Bennett, J.A.; Riegel, B.; Bittner, V.; Nichols, J. Validity and reliability of the NYHA classes for measuring research outcomes in patients with cardiac disease. Heart Lung 2002, 31, 262–270. [Google Scholar] [CrossRef] [PubMed]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [CrossRef] [PubMed]
- Ricciardi, C.; Amboni, M.; De Santis, C.; Ricciardelli, G.; Improta, G.; D’Addio, G.; Cuoco, S.; Picillo, M.; Barone, P.; Cesarelli, M. Machine learning can detect the presence of mild cognitive impairment in patients affected by parkinson’s disease. In Proceedings of the IEEE International Symposium on Medical Measurements and Applications, Bari, Italy, 1 June–1 July 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Ricciardi, C.; Amboni, M.; De Santis, C.; Ricciardelli, G.; Improta, G.; Cesarelli, G.; D’Addio, G.; Barone, P. Classifying patients affected by parkinson’s disease into freezers or non-freezers through machine learning. In Proceedings of the IEEE International Symposium on Medical Measurements and Applications, Bari, Italy, 1 June–1 July 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Romeo, V.; Cuocolo, R.; Ricciardi, C.; Ugga, L.; Cocozza, S.; Verde, F.; Stanzione, A.; Napolitano, V.; Russo, D.; Improta, G.; et al. Prediction of tumor grade and nodal status in oropharyngeal and oral cavity squamous-cell carcinoma using a radiomic approach. Anticancer. Res. 2019, 40, 271–280. [Google Scholar] [CrossRef] [PubMed]
- Stanzione, A.; Ricciardi, C.; Cuocolo, R.; Romeo, V.; Petrone, J.; Sarnataro, M.; Mainenti, P.P.; Improta, G.; De Rosa, F.; Insabato, L.; et al. MRI radiomics for the prediction of fuhrman grade in clear cell renal cell carcinoma: A machine learning exploratory study. J. Digit. Imaging 2020, 33, 879–887. [Google Scholar] [CrossRef]
- Cuocolo, R.; Perillo, T.; De Rosa, E.; Ugga, L.; Petretta, M. Current applications of big data and machine learning in cardiology. J. Geriatr. Cardiol. 2019, 16, 601–607. [Google Scholar] [CrossRef]
- Ricciardi, C.; Cantoni, V.; Improta, G.; Iuppariello, L.; Latessa, I.; Cesarelli, M.; Triassi, M.; Cuocolo, A. Application of data mining in a cohort of Italian subjects undergoing myocardial perfusion imaging at an academic medical center. Comput. Methods Programs Biomed. 2020, 189, 105343. [Google Scholar] [CrossRef]
- Ricciardi, C.; Cantoni, V.; Green, R.; Improta, G.; Cesarelli, M. Is it possible to predict cardiac death? In Proceedings of the XV Mediterranean Conference on Medical and Biological Engineering and Computing, Coimbra, Portugal, 26–28 September 2019; Henriques, J., Neves, N., de Carvalho, P., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Ricciardi, C.; Edmunds, K.; Recenti, M.; Sigurdsson, S.; Gudnason, V.; Carraro, U.; Gargiulo, P. Assessing cardiovascular risks from a mid-thigh CT image: A tree-based machine learning approach using radiodensitometric distributions. Sci. Rep. 2020, 10, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isler, Y.; Narin, A.; Ozer, M.; Perc, M. Multi-stage classification of congestive heart failure based on short-term heart rate variability. Chaos Solitons Fractals 2019, 118, 145–151. [Google Scholar] [CrossRef]
- Isler, Y.; Narin, A.; Ozer, M. Comparison of the effects of cross-validation methods on determining performances of classifiers used in diagnosing congestive heart failure. Meas. Sci. Rev. 2015, 15, 196–201. [Google Scholar] [CrossRef] [Green Version]
- Gong, X.; Long, B.; Wang, Z.; Zhang, H.; Nandi, A.K. Faster Detection of abnormal electrocardiogram (ECG) signals using fewer features of Heart Rate Variability (HRV). J. Comput. Sci. Syst. Biol. 2018, 12, 19–27. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, C.; Wei, S.; Liu, C.; Li, J. Enhancing detection accuracy for clinical heart failure utilizing pulse transit time variability and machine learning. IEEE Access 2019, 7, 17716–17724. [Google Scholar] [CrossRef]
- Agliari, E.; Barra, A.; Barra, O.A.; Fachechi, A.; Vento, L.F.; Moretti, L. Detecting cardiac pathologies via machine learning on heart-rate variability time series and related markers. Sci. Rep. 2020, 10, 18. [Google Scholar] [CrossRef]
- Hua, Z.; Chen, C.; Zhang, R.; Liu, G.; Wen, W. Diagnosing Various Severity Levels of Congestive Heart Failure Based on Long-Term HRV Signal. Appl. Sci. 2019, 9, 2544. [Google Scholar] [CrossRef] [Green Version]
- Qu, Z.; Liu, Q.; Liu, C. Classification of congestive heart failure with different New York Heart association functional classes based on heart rate variability indices and machine learning. Expert Syst. 2019, 36, e12396. [Google Scholar] [CrossRef]
- Chen, W.; Zheng, L.; Li, K.; Wang, Q.; Liu, G.; Jiang, Q. A Novel and effective method for congestive heart failure detection and quantification using dynamic heart rate variability measurement. PLoS ONE 2016, 11, e0165304. [Google Scholar] [CrossRef] [PubMed]
- D’Addio, G.; Acanfora, D.; Pinna, G.D.; Maestri, R.; Furgi, G.; Picone, C.; Rengo, F. Reproducibility of short and long-term poincare plot parameters compared with frequency-domain hrv indexes in congestive heart failure. In Proceedings of the Computers in Cardiology, Cleveland, OH, USA, 13–16 September 1998; Murray, A., Swiryn, S., Eds.; IEEE: Piscataway, NJ, USA, 1998. [Google Scholar] [CrossRef]
- Donisi, L.; Ricciardi, C.; Cesarelli, G.; Pagano, G.; Amitrano, F.; D’Addio, G. Machine learning applied on poincaré analyisis to discriminate different cardiac issues. In Proceedings of the 2020 11th Conference of the European Study Group on Cardiovascular Oscillations (ESGCO), Pisa, Italy, 15–15 July 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Ricciardi, C.; Donisi, L.; Cesarelli, G.; Pagano, G.; Coccia, A.; D’Addio, G. Feasibility of machine learning applied to poincaré plot analysis on patients with CHF. In Proceedings of the 2020 11th Conference of the European Study Group on Cardiovascular Oscillations (ESGCO), Pisa, Italy, 15–15 July 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Maestri, R.; Pinna, G.D.; Balocchi, R.; D’Addio, G.; Ferrario, M.; Porta, A.; Sassi, R.; Signorini, M.G.; La Rovere, M.T. Clinical correlates of non-linear indices of heart rate variability in chronic heart failure patients. Biomed. Tech. 2006, 51, 220–223. [Google Scholar] [CrossRef]
- Kamen, P.W.; Tonkin, A.M. Application of the Poincaré plot to heart rate variability: A new measure of functional status in heart failure. Aust. N. Z. J. Med. 1995, 25, 18–26. [Google Scholar] [CrossRef]
- Woo, M.A.; Stevenson, W.G.; Moser, D.K.; Trelease, R.B.; Harper, R.M. Patterns of beat-to-beat heart rate variability in advanced heart failure. Am. Heart J. 1992, 123, 704–710. [Google Scholar] [CrossRef]
- Woo, M.A.; Stevenson, W.G.; Moser, D.K.; Middlekauff, H.R. Complex heart rate variability and serum norepinephrine levels in patients with advanced heart failure. J. Am. Coll. Cardiol. 1994, 23, 565–569. [Google Scholar] [CrossRef] [Green Version]
- Brouwer, J.; van Veldhuisen, D.J.; Man In’t Veld, A.J.; Haaksma, J.; Dijk, W.A.; Visser, K.R.; Boomsma, F.; Dunselman, P.H.; Lie, K. Prognostic value of heart rate variability during long-term follow-up in patients with mild to moderate heart failure. J. Am. Coll. Cardiol. 1996, 28, 1183–1189. [Google Scholar] [CrossRef] [Green Version]
- Marciano, F.; Migaux, M.L.; Acanfora, D.; Furgi, G.; Rengo, F. Quantification of poincare’ maps for the evaluation of heart rate variability. In Proceedings of the Computers in Cardiology, Bethesda, MD, USA, 25–28 September 1994. [Google Scholar] [CrossRef]
- D’Addio, G.; Pinna, G.D.; La Rovere, M.T.; Maestri, R.; Furgi, G.; Rengo, F. Prognostic value of poincare plot indexes in chronic heart failure patients. In Proceedings of the Computers in Cardiology, Rotterdam, The Netherlands, 23–26 September 2001; IEEE: Piscataway, NJ, USA, 2001. [Google Scholar] [CrossRef]
- Copie, X.; Le Heuzey, J.-Y.; Iliou, M.-C.; Khouri, R.; Lavergne, T.; Pousset, F.; Guize, L. Correlation between time-domain measures of heart rate variability and scatterplots in postinfarction patients. Pacing Clin. Electrophysiol. 1996, 19, 342–347. [Google Scholar] [CrossRef]
- Bigger, J.; Fleiss, J.L.; Rolnitzky, L.M.; Steinman, R.C. Stability over time of heart period variability in patients with previous myocardial infarction and ventricular arrhythmias. Am. J. Cardiol. 1992, 69, 718–723. [Google Scholar] [CrossRef]
- Corbi, G.; Cesarelli, M.; Ferrara, N.; D'Addio, G. Reproducibility of Non Linear Analysis Parameters in Chronic Heart Failure Patients. In Advances in Biomedicine and Health Science, Proceedings of the 2nd International Conference on Biomedicine and Health Engineering, Brasov, Romania, 1–3 June 2013; Marascu-Klein, V., Ed.; WSEAS Press: Athens, GR, USA, 2013. [Google Scholar]
- D’Addio, G.; Pinna, G.D.; Maestri, R.; Acanfora, D.; Ranaudo, E.; Furgi, G.; Rengo, F. Changes induced by tilting on Poincare plots and symbolic dynamic patterns of HRV compared to spectral indexes in post-MI and normal subjects. In Proceedings of the Computers in Cardiology, Cambridge, MA, USA, 24–27 September 2000. [Google Scholar] [CrossRef]
- Starkweather, J.; Moske, A.K. Multinomial Logistic Regression. Denton: University of North Texas; 2011 Aug. Available online: https://it.unt.edu/sites/default/files/mlr_jds_aug2011.pdf (accessed on 30 June 2021).
- Van Smeden, M.; Moons, K.G.; De Groot, J.A.; Collins, G.S.; Altman, D.G.; Eijkemans, M.J.; Reitsma, J.B. Sample size for binary logistic prediction models: Beyond events per variable criteria. Stat. Methods Med. Res. 2019, 28, 2455–2474. [Google Scholar] [CrossRef] [Green Version]
- Tougui, I.; Jilbab, A.; El Mhamdi, J. Heart disease classification using data mining tools and machine learning techniques. Health Technol. 2020, 10, 1137–1144. [Google Scholar] [CrossRef]
- Improta, G.; Ricciardi, C.; Amato, F.; D’Addio, G.; Cesarelli, M.; Romano, M. Efficacy of machine learning in predicting the kind of delivery by cardiotocography. In Proceedings of the XV Mediterranean Conference on Medical and Biological Engineering and Computing (MEDICON 2019), Coimbra, Portugal, 26–28 September 2019; Henriques, J., de Carvalho, P., Neves, N., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- D’Addio, G.; Ricciardi, C.; Improta, G.; Bifulco, P.; Cesarelli, M. Feasibility of machine learning in predicting features related to congenital nystagmus. In Proceedings of the XV Mediterranean Conference on Medical and Biological Engineering and Compu-ting (MEDICON 2019), Coimbra, Portugal, 26–28 September 2019; Henriques, J., de Carvalho, P., Neves, N., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Donisi, L.; Cesarelli, G.; Coccia, A.; Panigazzi, M.; Capodaglio, E.; D’Addio, G. Work-related risk assessment according to the revised niosh lifting equation: A preliminary study using a wearable inertial sensor and machine learning. Sensors 2021, 21, 2593. [Google Scholar] [CrossRef] [PubMed]
- Scrutinio, D.; Ricciardi, C.; Donisi, L.; Losavio, E.; Battista, P.; Guida, P.; Cesarelli, M.; Pagano, G.; D’Addio, G. Machine learning to predict mortality after rehabilitation among patients with severe stroke. Sci. Rep. 2020, 10, 1–10. [Google Scholar] [CrossRef]
- Donisi, L.; Moretta, P.; Coccia, A.; Amitrano, F.; Biancardi, A.; D’Addio, G. Distinguishing stroke patients with and without unilateral spatial neglect by means of clinical features: A tree-based machine learning approach. In Proceeding of the 2021 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Neuchâtel, Switzerland, 23–25 June 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Supervised machine learning: A review of classification techniques. In Proceedings of the 2007 Conference on Emerging Artificial Intelligence Applications in Computer Engineering: Real Word AI Systems with Applications in eHealth, HCI, Information Retrieval and Pervasive Technologies, Athens, Greece, 21–23 May 2007; Maglogiannis, I., Karpouzis, K., Wallace, M., Soldatos, J., Eds.; IOS Press: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Rish, I. An empirical study of the naive bayes classifier. In Proceedings of the 17th International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001. [Google Scholar]
- Frank, E.; Hall, M.; Pfahringer, B. Locally weighted naive bayes. In Proceedings of the Nineteenth Conference on Uncertainty in Artificial Intelligence, Acapulco, Mexico, 7–10 August 2003; Kjærulff, U., Meek, C., Eds.; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2003. [Google Scholar]
- Abraham, R.; Simha, J.B.; Iyengar, S.S. A comparative Analysis of discretization methods for medical datamining with naïve bayesian classifier. In Proceedings of the 9th International Conference on Information Technology, Bhubaneswar, India, 18–21 December 2006; Mohanti, S.P., Sahoo, A., Eds.; IEEE: Piscataway, NJ, USA, 2006. [Google Scholar] [CrossRef]
- Abraham, R.; Simha, J.B.; Iyengar, S.S. Medical datamining with a new algorithm for feature selection and naïve bayesian classifier. In Proceedings of the 10th International Conference on Information Technology, Rourkela, India, 17–20 December 2007; Patra, P., Panda, P.R., Eds.; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar] [CrossRef]
- Soni, J.; Ansari, U.; Sharma, D.; Soni, S. Predictive data mining for medical diagnosis: An overview of heart disease prediction. Int. J. Comput. Appl. 2011, 8, 43–48. [Google Scholar] [CrossRef]
- Nahar, J.; Imam, T.; Tickle, K.S.; Chen, Y.-P.P. Computational intelligence for heart disease diagnosis: A medical knowledge driven approach. Expert Syst. Appl. 2013, 40, 96–104. [Google Scholar] [CrossRef]
- Subbalakshmi, G.; Ramesh, K.; Chinna Rao, M. Decision support in heart disease prediction system using naive bayes. Indian J. Comp. Sci. Eng. 2011, 2, 170–176. [Google Scholar]
- Tripoliti, E.E.; Papadopoulos, T.G.; Karanasiou, G.S.; Naka, K.; Fotiadis, D.I. Heart failure: Diagnosis, severity estimation and prediction of adverse events through machine learning techniques. Comput. Struct. Biotechnol. J. 2017, 15, 26–47. [Google Scholar] [CrossRef] [Green Version]
- Gonçalves, A.R.; De Oliveira Camargo-Brunetto, M.A. Classification of poincaré plots for temporal series of heart rate varia-bility by using machine learning techniques. In Proceedings of the 2010 10th International Conference on Intelligent Systems Design and Applications, Cairo, Egypt, 29 November–1 December 2010; Ella Hassanien, A., Abraham, A., Marcelloni, F., Hagras, H., Antonelli, M., Hong, T., Eds.; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar] [CrossRef]
- Sepulveda-Suescun, J.P.; Murillo-Escobar, J.; Urda-Benitez, R.D.; Orrego-Metaute, D.A.; Orozco-Duque, A. Atrial fibrillation detection through heart rate variability using a machine learning approach and poincare plot features. In Proceedings of the 7th Latin American Congress on Biomedical Engineering, Bucaramanga, Colombia, 26–28 October 2016; Bustamante, J., Sierra, D.A., Torres, I., Eds.; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Rezaei, S.; Moharreri, S.; Abdollahpur, M.; Parvaneh, S. Heart arrhythmia classification using extracted features in poincare plot of RR intervals. In Proceedings of the Computing in Cardiology, Rennes, France, 24–27 September 2017; Pickett, C., Corsi, C., Laguna, P., MacLeod, R., Eds.; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Lever, J.; Krzywinski, M.; Altman, N. Classification evaluation. Nat. Methods 2016, 13, 603–604. [Google Scholar] [CrossRef]
- Cohn, J.; Hawkins, M.; Levine, H.; Naughton, J.; Rapaport, E.; Goldstein, S.; Pitt, B.; Cody, R.; Deedwania, P.; Dennick, L.; et al. Comparative effects of therapy with captopril and digoxin in patients with mild to moderate heart failure. JAMA 1988, 259, 539–544. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Age | Male | Cause [%] | LVEF | VPC | NSVT | ||
|---|---|---|---|---|---|---|---|
| [years] | [%] | Ischemic | Idiopathic | Other | % | n/h | % |
| 54 | 87 | 50 | 45 | 3 | 23 | 13 | 37 |
| Variables | NYHA = 1 | NYHA = 2 | NYHA = 3 | p-Value | Post-Hoc Classes p-Value |
|---|---|---|---|---|---|
| L | 631.14 ± 173.27 | 594.74 ± 174.79 | 512.05 ± 188.62 | 0.005 ‘ | 1–3, 0.024 2–3, 0.012 |
| HVE | 257.02 ± 96.37 | 235.74 ± 95.25 | 229.09 ±82.00 | 0.518 ^ | NA |
| A | 13,194.09 ± 7313.36 | 14,094.22 ± 10,389.57 | 10,975.41 ± 8714.27 | 0.040 ^ | 2–3, 0.041 |
| p | 61.72 ± 12.43 | 55.99 ± 14.39 | 56.70±13.49 | 0.210 ‘ | NA |
| 36.82 ± 29.40 | 27.79 ± 17.69 | 22.90 ± 18.30 | 0.010 ^ | 1–3, 0.019 | |
| 48.04 ± 9.60 | 53.89 ± 19.90 | 61.27 ± 22.10 | 0.025 ^ | 2–3, 0.047 | |
| 120.22 ± 32.81 | 113.51 ± 28.00 | 105.33 ± 23.25 | 0.069 ^ | NA | |
| 113.62 ± 39.06 | 105.54 ± 39.62 | 84.55 ± 37.49 | 0.001 ^ | 2–3, 0.002 1–3, 0.007 | |
| 798.46 ± 134.32 | 811.17 ± 118.53 | 773.51 ± 149.45 | 0.195 ‘ | NA |
| Variables | Odds Ratio (95% CI) | p-Value |
|---|---|---|
| L | NI | NI |
| HVE | 0.997 (0.993–1.002) | 0.229 |
| A | NI | NI |
| p | 0.983 (0.966–1.000) | 0.046 |
| NI | NI | |
| NI | NI | |
| NI | NI | |
| 1.027 (1.015–1.040) | 0.000 | |
| NI | NI |
| Algorithms | Accuracy [%] | Sensitivity [%] | Specificity [%] | Precision [%] | AUCROC [%] | Features Selected |
|---|---|---|---|---|---|---|
| ADA-B | 82.5 | 58.3 | 92.9 | 77.8 | 0.756 | L, P |
| KNN | 80.0 | 41.7 | 96.4 | 83.3 | 0.702 | |
| NB | 82.5 | 66.7 | 89.3 | 72.7 | 0.747 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Addio, G.; Donisi, L.; Cesarelli, G.; Amitrano, F.; Coccia, A.; La Rovere, M.T.; Ricciardi, C. Extracting Features from Poincaré Plots to Distinguish Congestive Heart Failure Patients According to NYHA Classes. Bioengineering 2021, 8, 138. https://doi.org/10.3390/bioengineering8100138
D’Addio G, Donisi L, Cesarelli G, Amitrano F, Coccia A, La Rovere MT, Ricciardi C. Extracting Features from Poincaré Plots to Distinguish Congestive Heart Failure Patients According to NYHA Classes. Bioengineering. 2021; 8(10):138. https://doi.org/10.3390/bioengineering8100138
Chicago/Turabian StyleD’Addio, Giovanni, Leandro Donisi, Giuseppe Cesarelli, Federica Amitrano, Armando Coccia, Maria Teresa La Rovere, and Carlo Ricciardi. 2021. "Extracting Features from Poincaré Plots to Distinguish Congestive Heart Failure Patients According to NYHA Classes" Bioengineering 8, no. 10: 138. https://doi.org/10.3390/bioengineering8100138