Genetic Engineering and Synthetic Genomics in Yeast to Understand Life and Boost Biotechnology


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Yeast 1.0 Evolution to Become a Fundamental Model Organism
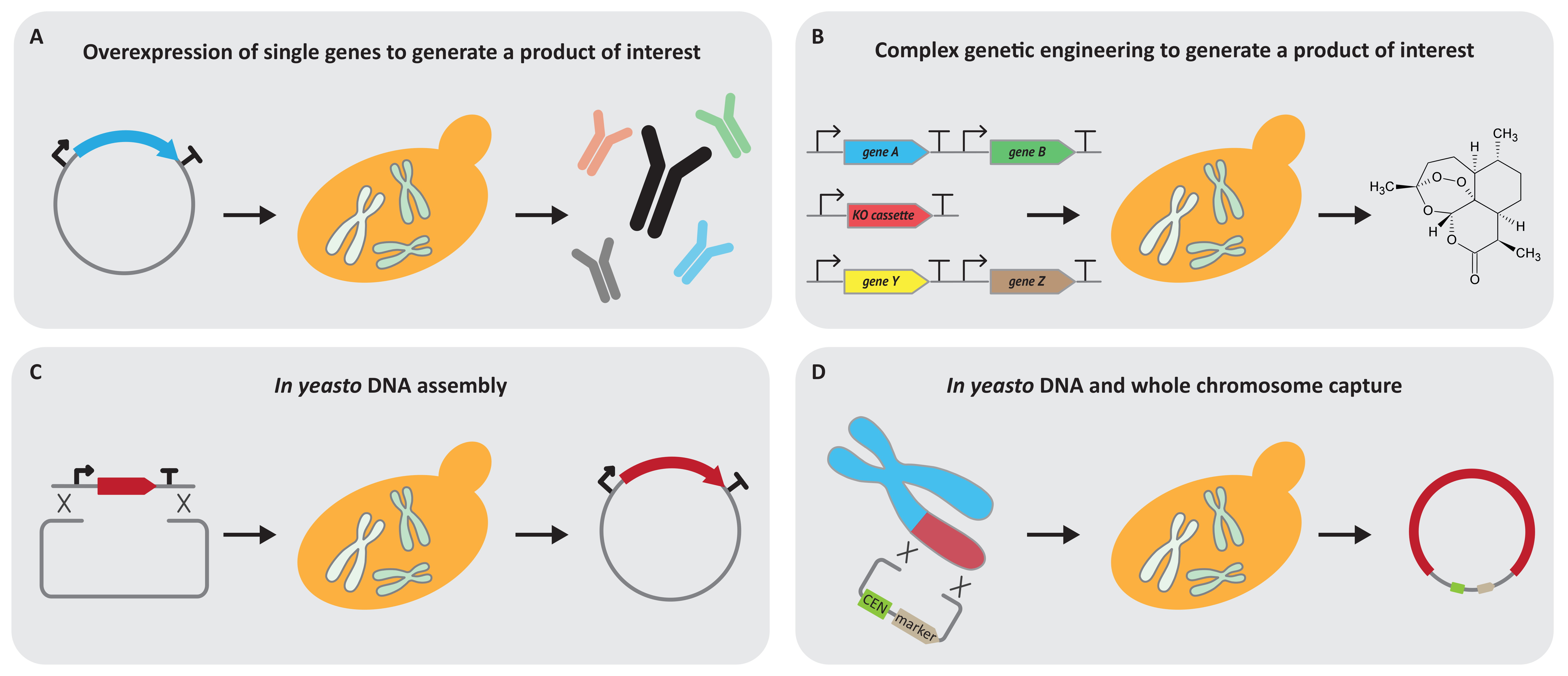
3. Yeast 1.0 as a Cell Factory to Produce Valuable Molecules
4. Yeast 1.0 as an Engineering Platform to Build and Manipulate DNA Up to Whole Chromosomes
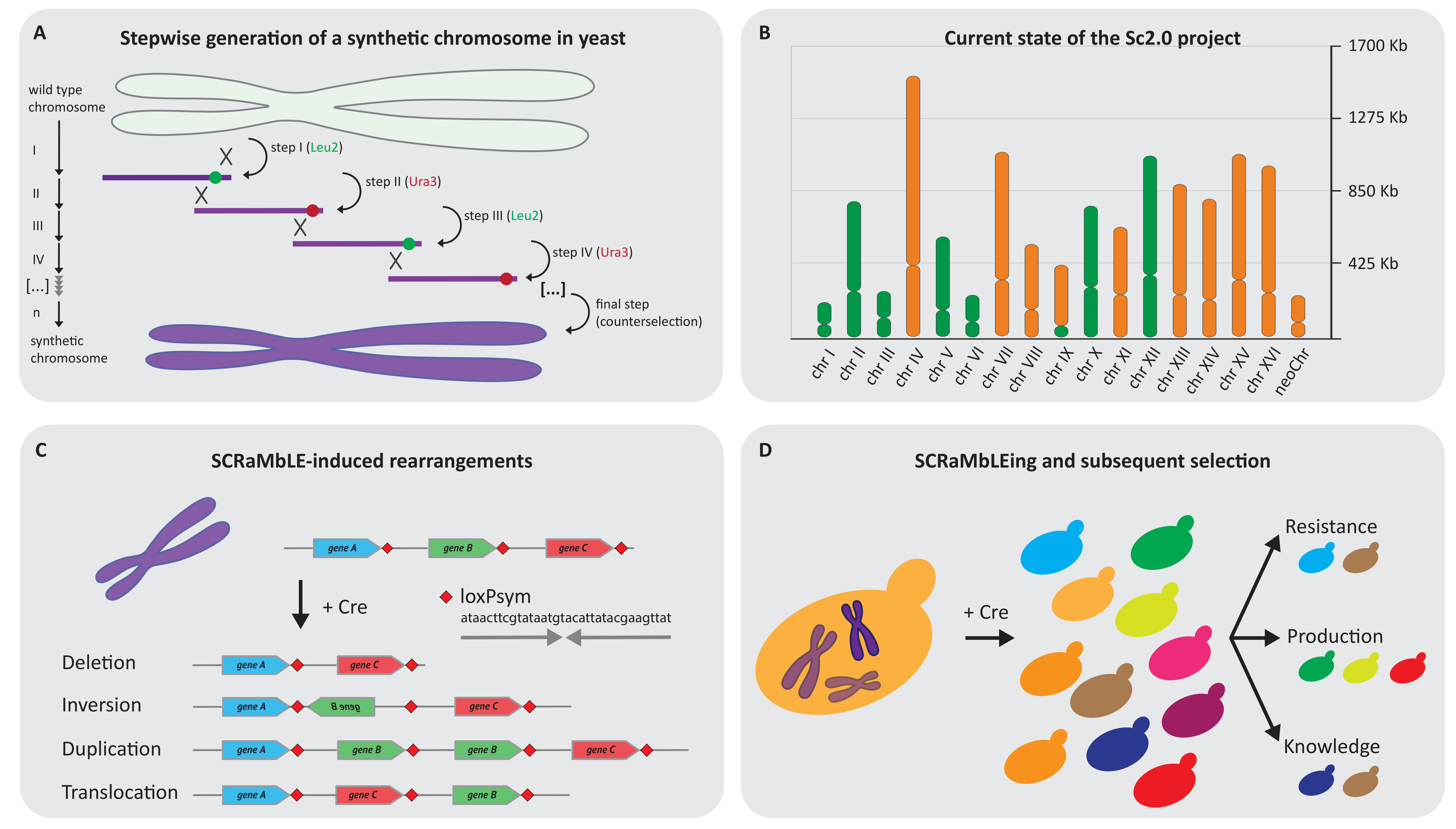
5. Yeast 2.0: Building the First Synthetic Designer Eukaryote
6. Yeast 2.0 Lessons and Application for the Future
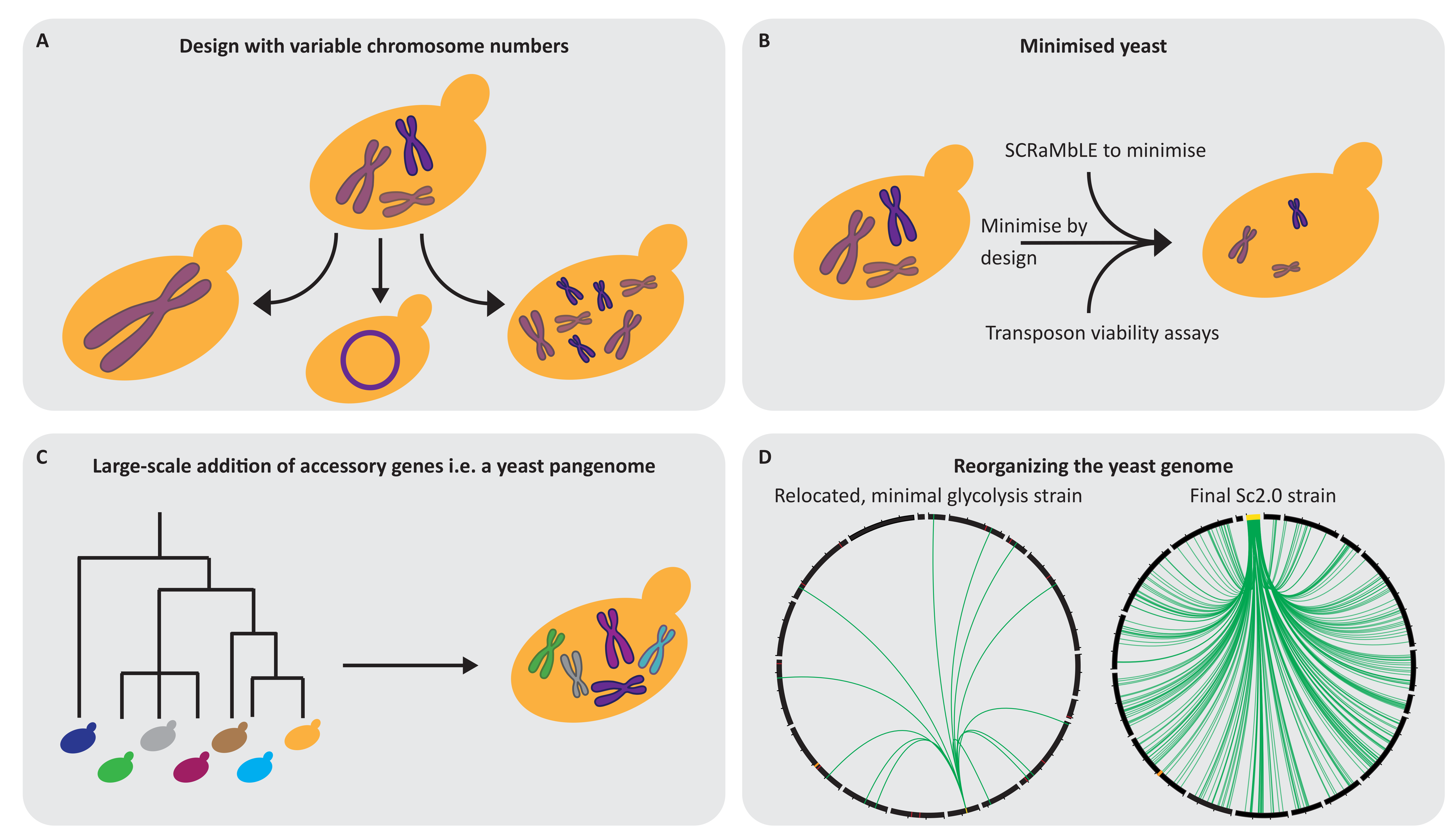
7. Yeast 3.0: What Could Be the Future Design Approach?
7.1. Varying the Number of Chromosomes and Their Confirmation
7.2. Creating a Simplified Yeast Genome
7.3. Implementing New Functions for Subsequent Adaptation
7.4. Changing the Genomic Landscape
8. From Yeast 1.0 to Yeast 3.0: Summary and Future Perspectives
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Griffith, F. The significance of Pneumococcal types. J. Hyg. (Lond.) 1928, 27, 113–159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Avery, O.T.; Macleod, C.M.; McCarty, M. Studies on the chemical nature of the substance inducing transformation of Pneumococcal types: Induction of transformation by a desoxyribonucleic acid fraction isolated from Pneumococcus type III. J. Exp. Med. 1944, 79, 137–158. [Google Scholar] [CrossRef] [PubMed]
- Jackson, D.A.; Symons, R.H.; Berg, P. Biochemical method for inserting new genetic information into DNA of Simian Virus 40: Circular SV40 DNA molecules containing lambda phage genes and the galactose operon of Escherichia coli. Proc. Natl. Acad. Sci. USA 1972, 69, 2904–2909. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cohen, S.N.; Chang, A.C.; Boyer, H.W.; Helling, R.B. Construction of biologically functional bacterial plasmids in vitro. Proc. Natl. Acad. Sci. USA 1973, 70, 3240–3244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hinnen, A.; Hicks, J.B.; Fink, G.R. Transformation of yeast. Proc. Natl. Acad. Sci. USA 1978, 75, 1929–1933. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goffeau, A.; Barrell, B.G.; Bussey, H.; Davis, R.W.; Dujon, B.; Feldmann, H.; Galibert, F.; Hoheisel, J.D.; Jacq, C.; Johnston, M.; et al. Life with 6000 genes. Science 1996, 274, 546–567. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sanger, F.; Coulson, A.R. A rapid method for determining sequences in DNA by primed synthesis with DNA polymerase. J. Mol. Biol. 1975, 94, 441–448. [Google Scholar] [CrossRef]
- Maxam, A.M.; Gilbert, W. A new method for sequencing DNA. Proc. Natl. Acad. Sci. USA 1977, 74, 560–564. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Staden, R. A strategy of DNA sequencing employing computer programs. Nucleic Acids Res. 1979, 6, 2601–2610. [Google Scholar] [CrossRef]
- Anderson, S. Shotgun DNA sequencing using cloned DNase I-generated fragments. Nucleic Acids Res. 1981, 9, 3015–3027. [Google Scholar] [CrossRef] [Green Version]
- Rohland, N.; Reich, D. Cost-effective, high-throughput DNA sequencing libraries for multiplexed target capture. Genome Res. 2012, 22, 939–946. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Check Hayden, E. Genome sequencing: The third generation. Nature 2009, 457, 768–769. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Levene, M.J.; Korlach, J.; Turner, S.W.; Foquet, M.; Craighead, H.G.; Webb, W.W. Zero-mode waveguides for single-molecule analysis at high concentrations. Science 2003, 299, 682–686. [Google Scholar] [CrossRef] [PubMed]
- Kasianowicz, J.J.; Brandin, E.; Branton, D.; Deamer, D.W. Characterization of individual polynucleotide molecules using a membrane channel. Proc. Natl. Acad. Sci. USA 1996, 93, 13770–13773. [Google Scholar] [CrossRef] [Green Version]
- Gowers, G.F.; Vince, O.; Charles, J.H.; Klarenberg, I.; Ellis, T.; Edwards, A. Entirely off-grid and solar-powered DNA sequencing of microbial communities during an ice cap traverse expedition. Genes 2019, 10, 902. [Google Scholar] [CrossRef] [Green Version]
- Castro-Wallace, S.L.; Chiu, C.Y.; John, K.K.; Stahl, S.E.; Rubins, K.H.; McIntyre, A.B.R.; Dworkin, J.P.; Lupisella, M.L.; Smith, D.J.; Botkin, D.J.; et al. Nanopore DNA sequencing and genome assembly on the international space station. Sci Rep. 2017, 7, 18022. [Google Scholar] [CrossRef] [Green Version]
- Awan, A.R.; Blount, B.A.; Bell, D.J.; Shaw, W.M.; Ho, J.C.H.; McKiernan, R.M.; Ellis, T. Biosynthesis of the antibiotic nonribosomal peptide penicillin in baker’s yeast. Nat. Commun 2017, 8, 15202. [Google Scholar] [CrossRef] [Green Version]
- Fleming, A. On the antibacterial action of cultures of a penicillium, with special reference to their use in the isolation of B. influenzæ. Br. J. Exp. Pathol. 1929, 10, 226–236. [Google Scholar] [CrossRef]
- van Nimwegen, K.J.; van Soest, R.A.; Veltman, J.A.; Nelen, M.R.; van der Wilt, G.J.; Vissers, L.E.; Grutters, J.P. Is the $1000 genome as near as we think? A cost analysis of Next-Generation Sequencing. Clin. Chem. 2016, 62, 1458–1464. [Google Scholar] [CrossRef] [Green Version]
- Perkel, J.M. The race for enzymatic DNA synthesis heats up. Nature 2019, 566, 565. [Google Scholar] [CrossRef]
- Richardson, S.M.; Mitchell, L.A.; Stracquadanio, G.; Yang, K.; Dymond, J.S.; DiCarlo, J.E.; Lee, D.; Huang, C.L.; Chandrasegaran, S.; Cai, Y.; et al. Design of a synthetic yeast genome. Science 2017, 355, 1040–1044. [Google Scholar] [CrossRef] [Green Version]
- Ostrov, N.; Landon, M.; Guell, M.; Kuznetsov, G.; Teramoto, J.; Cervantes, N.; Zhou, M.; Singh, K.; Napolitano, M.G.; Moosburner, M.; et al. Design, synthesis, and testing toward a 57-codon genome. Science 2016, 353, 819–822. [Google Scholar] [CrossRef] [Green Version]
- McAleer, W.J.; Buynak, E.B.; Maigetter, R.Z.; Wampler, D.E.; Miller, W.J.; Hilleman, M.R. Human hepatitis B vaccine from recombinant yeast. Nature 1984, 307, 178–180. [Google Scholar] [CrossRef]
- Saiki, R.K.; Scharf, S.; Faloona, F.; Mullis, K.B.; Horn, G.T.; Erlich, H.A.; Arnheim, N. Enzymatic amplification of beta-globin genomic sequences and restriction site analysis for diagnosis of sickle cell anemia. Science 1985, 230, 1350–1354. [Google Scholar] [CrossRef] [PubMed]
- Gibson, D.G.; Glass, J.I.; Lartigue, C.; Noskov, V.N.; Chuang, R.Y.; Algire, M.A.; Benders, G.A.; Montague, M.G.; Ma, L.; Moodie, M.M.; et al. Creation of a bacterial cell controlled by a chemically synthesized genome. Science 2010, 329, 52–56. [Google Scholar] [CrossRef] [Green Version]
- Fredens, J.; Wang, K.; de la Torre, D.; Funke, L.F.H.; Robertson, W.E.; Christova, Y.; Chia, T.; Schmied, W.H.; Dunkelmann, D.L.; Beranek, V.; et al. Total synthesis of Escherichia coli with a recoded genome. Nature 2019, 569, 514–518. [Google Scholar] [CrossRef] [PubMed]
- Schindler, D.; Dai, J.; Cai, Y. Synthetic genomics: A new venture to dissect genome fundamentals and engineer new functions. Curr. Opin. Chem. Biol. 2018, 46, 56–62. [Google Scholar] [CrossRef] [PubMed]
- Palluk, S.; Arlow, D.H.; de Rond, T.; Barthel, S.; Kang, J.S.; Bector, R.; Baghdassarian, H.M.; Truong, A.N.; Kim, P.W.; Singh, A.K.; et al. De novo DNA synthesis using polymerase-nucleotide conjugates. Nat. Biotechnol. 2018, 36, 645–650. [Google Scholar] [CrossRef]
- Jones, S. SCRaMbLE does the yeast genome shuffle. Nat. Biotechnol. 2018, 36, 503. [Google Scholar] [CrossRef]
- Boeke, J.D.; Church, G.; Hessel, A.; Kelley, N.J.; Arkin, A.; Cai, Y.; Carlson, R.; Chakravarti, A.; Cornish, V.W.; Holt, L.; et al. The Genome Project-Write. Science 2016, 353, 126–127. [Google Scholar] [CrossRef]
- Samuel, D. Investigation of ancient Egyptian baking and brewing methods by correlative microscopy. Science 1996, 273, 488–490. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barnett, J.A. Beginnings of microbiology and biochemistry: The contribution of yeast research. Microbiology 2003, 149, 557–567. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Botstein, D.; Fink, G.R. Yeast: An experimental organism for modern biology. Science 1988, 240, 1439–1443. [Google Scholar] [CrossRef]
- Botstein, D.; Fink, G.R. Yeast: An experimental organism for 21st Century biology. Genetics 2011, 189, 695–704. [Google Scholar] [CrossRef] [Green Version]
- Hohmann, S. Nobel yeast research. FEMS Yeast Res. 2016, 16, fow094. [Google Scholar] [CrossRef] [PubMed]
- Spencer, J.F.; Ragout de Spencer, A.L.; Laluce, C. Non-conventional yeasts. Appl. Microbiol. Biotechnol. 2002, 58, 147–156. [Google Scholar] [CrossRef] [PubMed]
- Rebello, S.; Abraham, A.; Madhavan, A.; Sindhu, R.; Binod, P.; Karthika Bahuleyan, A.; Aneesh, E.M.; Pandey, A. Non-conventional yeast cell factories for sustainable bioprocesses. FEMS Microbiol. Lett. 2018, 365, fny222. [Google Scholar] [CrossRef]
- Walker, R.S.K.; Pretorius, I.S. Applications of yeast synthetic biology geared towards the production of biopharmaceuticals. Genes 2018, 9, 340. [Google Scholar] [CrossRef] [Green Version]
- Petrovic, U. Next-generation biofuels: A new challenge for yeast. Yeast 2015, 32, 583–593. [Google Scholar] [CrossRef]
- Kavscek, M.; Strazar, M.; Curk, T.; Natter, K.; Petrovic, U. Yeast as a cell factory: Current state and perspectives. Microb. Cell Fact. 2015, 14, 94. [Google Scholar] [CrossRef] [Green Version]
- Paddon, C.J.; Westfall, P.J.; Pitera, D.J.; Benjamin, K.; Fisher, K.; McPhee, D.; Leavell, M.D.; Tai, A.; Main, A.; Eng, D.; et al. High-level semi-synthetic production of the potent antimalarial artemisinin. Nature 2013, 496, 528–532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Galanie, S.; Thodey, K.; Trenchard, I.J.; Filsinger Interrante, M.; Smolke, C.D. Complete biosynthesis of opioids in yeast. Science 2015, 349, 1095–1100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Srinivasan, P.; Smolke, C.D. Engineering a microbial biosynthesis platform for de novo production of tropane alkaloids. Nat. Commun. 2019, 10, 3634. [Google Scholar] [CrossRef] [Green Version]
- Srinivasan, P.; Smolke, C.D. Biosynthesis of medicinal tropane alkaloids in yeast. Nature 2020, 585, 614–619. [Google Scholar] [CrossRef]
- Denby, C.M.; Li, R.A.; Vu, V.T.; Costello, Z.; Lin, W.; Chan, L.J.G.; Williams, J.; Donaldson, B.; Bamforth, C.W.; Petzold, C.J.; et al. Industrial brewing yeast engineered for the production of primary flavor determinants in hopped beer. Nat. Commun. 2018, 9, 965. [Google Scholar] [CrossRef]
- Nielsen, J.; Keasling, J.D. Engineering Cellular Metabolism. Cell 2016, 164, 1185–1197. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borkowski, O.; Ceroni, F.; Stan, G.B.; Ellis, T. Overloaded and stressed: Whole-cell considerations for bacterial synthetic biology. Curr. Opin. Microbiol. 2016, 33, 123–130. [Google Scholar] [CrossRef] [PubMed]
- Rugbjerg, P.; Myling-Petersen, N.; Porse, A.; Sarup-Lytzen, K.; Sommer, M.O.A. Diverse genetic error modes constrain large-scale bio-based production. Nat. Commun. 2018, 9, 787. [Google Scholar] [CrossRef] [Green Version]
- Hillson, N.; Caddick, M.; Cai, Y.; Carrasco, J.A.; Chang, M.W.; Curach, N.C.; Bell, D.J.; Le Feuvre, R.; Friedman, D.C.; Fu, X.; et al. Building a global alliance of biofoundries. Nat. Commun. 2019, 10, 2040. [Google Scholar] [CrossRef]
- Gibson, D.G. Synthesis of DNA fragments in yeast by one-step assembly of overlapping oligonucleotides. Nucleic Acids. Res. 2009, 37, 6984–6990. [Google Scholar] [CrossRef] [Green Version]
- Ma, H.; Kunes, S.; Schatz, P.J.; Botstein, D. Plasmid construction by homologous recombination in yeast. Gene 1987, 58, 201–216. [Google Scholar] [CrossRef]
- Shao, Z.; Zhao, H.; Zhao, H. DNA assembler, an in vivo genetic method for rapid construction of biochemical pathways. Nucleic Acids. Res. 2009, 37, e16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ip, K.; Yadin, R.; George, K.W. High-throughput DNA assembly using yeast homologous recombination. Methods Mol. Biol. 2020, 2205, 79–89. [Google Scholar]
- Kouprina, N.; Larionov, V. TAR cloning: Insights into gene function, long-range haplotypes and genome structure and evolution. Nat. Rev. Genet. 2006, 7, 805–812. [Google Scholar] [CrossRef] [PubMed]
- Gibson, D.G.; Benders, G.A.; Andrews-Pfannkoch, C.; Denisova, E.A.; Baden-Tillson, H.; Zaveri, J.; Stockwell, T.B.; Brownley, A.; Thomas, D.W.; Algire, M.A.; et al. Complete chemical synthesis, assembly, and cloning of a Mycoplasma genitalium genome. Science 2008, 319, 1215–1220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gibson, D.G.; Benders, G.A.; Axelrod, K.C.; Zaveri, J.; Algire, M.A.; Moodie, M.; Montague, M.G.; Venter, J.C.; Smith, H.O.; Hutchison, C.A., 3rd. One-step assembly in yeast of 25 overlapping DNA fragments to form a complete synthetic Mycoplasma genitalium genome. Proc. Natl. Acad. Sci. USA 2008, 105, 20404–20409. [Google Scholar] [CrossRef] [Green Version]
- Benders, G.A.; Noskov, V.N.; Denisova, E.A.; Lartigue, C.; Gibson, D.G.; Assad-Garcia, N.; Chuang, R.Y.; Carrera, W.; Moodie, M.; Algire, M.A.; et al. Cloning whole bacterial genomes in yeast. Nucleic Acids Res. 2010, 38, 2558–2569. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, L.A.; Chuang, J.; Agmon, N.; Khunsriraksakul, C.; Phillips, N.A.; Cai, Y.; Truong, D.M.; Veerakumar, A.; Wang, Y.; Mayorga, M.; et al. Versatile genetic assembly system (VEGAS) to assemble pathways for expression in S. cerevisiae. Nucleic Acids Res. 2015, 43, 6620–6630. [Google Scholar] [CrossRef] [Green Version]
- Baby, V.; Labroussaa, F.; Brodeur, J.; Matteau, D.; Gourgues, G.; Lartigue, C.; Rodrigue, S. Cloning and transplantation of the Mesoplasma florum genome. ACS Synth. Biol. 2018, 7, 209–217. [Google Scholar] [CrossRef]
- Noskov, V.N.; Karas, B.J.; Young, L.; Chuang, R.Y.; Gibson, D.G.; Lin, Y.C.; Stam, J.; Yonemoto, I.T.; Suzuki, Y.; Andrews-Pfannkoch, C.; et al. Assembly of large, high G+C bacterial DNA fragments in yeast. ACS Synth. Biol. 2012, 1, 267–273. [Google Scholar] [CrossRef]
- Karas, B.J.; Molparia, B.; Jablanovic, J.; Hermann, W.J.; Lin, Y.C.; Dupont, C.L.; Tagwerker, C.; Yonemoto, I.T.; Noskov, V.N.; Chuang, R.Y.; et al. Assembly of eukaryotic algal chromosomes in yeast. J. Biol. Eng. 2013, 7, 30. [Google Scholar] [CrossRef] [PubMed]
- Karas, B.J.; Jablanovic, J.; Irvine, E.; Sun, L.; Ma, L.; Weyman, P.D.; Gibson, D.G.; Glass, J.I.; Venter, J.C.; Hutchison, C.A., 3rd; et al. Transferring whole genomes from bacteria to yeast spheroplasts using entire bacterial cells to reduce DNA shearing. Nat. Protoc. 2014, 9, 743–750. [Google Scholar] [CrossRef] [PubMed]
- Karas, B.J.; Suzuki, Y.; Weyman, P.D. Strategies for cloning and manipulating natural and synthetic chromosomes. Chromosome Res. 2015, 23, 57–68. [Google Scholar] [CrossRef]
- Lartigue, C.; Vashee, S.; Algire, M.A.; Chuang, R.Y.; Benders, G.A.; Ma, L.; Noskov, V.N.; Denisova, E.A.; Gibson, D.G.; Assad-Garcia, N.; et al. Creating bacterial strains from genomes that have been cloned and engineered in yeast. Science 2009, 325, 1693–1696. [Google Scholar] [CrossRef] [Green Version]
- Hutchison, C.A., 3rd; Chuang, R.Y.; Noskov, V.N.; Assad-Garcia, N.; Deerinck, T.J.; Ellisman, M.H.; Gill, J.; Kannan, K.; Karas, B.J.; Ma, L.; et al. Design and synthesis of a minimal bacterial genome. Science 2016, 351, aad6253. [Google Scholar] [CrossRef] [Green Version]
- Venetz, J.E.; Del Medico, L.; Wolfle, A.; Schachle, P.; Bucher, Y.; Appert, D.; Tschan, F.; Flores-Tinoco, C.E.; van Kooten, M.; Guennoun, R.; et al. Chemical synthesis rewriting of a bacterial genome to achieve design flexibility and biological functionality. Proc. Natl. Acad. Sci. USA 2019, 116, 8070–8079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thi Nhu Thao, T.; Labroussaa, F.; Ebert, N.; V’Kovski, P.; Stalder, H.; Portmann, J.; Kelly, J.; Steiner, S.; Holwerda, M.; Kratzel, A.; et al. Rapid reconstruction of SARS-CoV-2 using a synthetic genomics platform. Nature 2020, 582, 561–565. [Google Scholar] [CrossRef]
- Suzuki, Y.; Assad-Garcia, N.; Kostylev, M.; Noskov, V.N.; Wise, K.S.; Karas, B.J.; Stam, J.; Montague, M.G.; Hanly, T.J.; Enriquez, N.J.; et al. Bacterial genome reduction using the progressive clustering of deletions via yeast sexual cycling. Genome Res. 2015, 25, 435–444. [Google Scholar] [CrossRef] [Green Version]
- Tsarmpopoulos, I.; Gourgues, G.; Blanchard, A.; Vashee, S.; Jores, J.; Lartigue, C.; Sirand-Pugnet, P. In-yeast engineering of a bacterial genome using CRISPR/Cas9. ACS Synth. Biol. 2016, 5, 104–109. [Google Scholar] [CrossRef]
- Chandran, S.; Noskov, V.N.; Segall-Shapiro, T.H.; Ma, L.; Whiteis, C.; Lartigue, C.; Jores, J.; Vashee, S.; Chuang, R.Y. TREC-IN: Gene knock-in genetic tool for genomes cloned in yeast. BMC Genom. 2014, 15, 1180. [Google Scholar] [CrossRef] [Green Version]
- Schindler, D.; Waldminghaus, T. Synthetic chromosomes. FEMS Microbiol. Rev. 2015, 39, 871–891. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Remuzzi, A.; Remuzzi, G. COVID-19 and Italy: What next? Lancet 2020, 395, 1225–1228. [Google Scholar] [CrossRef]
- Esvelt, K.M. Inoculating science against potential pandemics and information hazards. PLoS Pathog. 2018, 14, e1007286. [Google Scholar] [CrossRef] [PubMed]
- DiEuliis, D.; Gronvall, G.K. A holistic assessment of the risks and benefits of the synthesis of horsepox virus. mSphere 2018, 3. [Google Scholar] [CrossRef] [PubMed]
- Noyce, R.S.; Lederman, S.; Evans, D.H. Construction of an infectious horsepox virus vaccine from chemically synthesized DNA fragments. PLoS ONE 2018, 13, e0188453. [Google Scholar] [CrossRef]
- Koblentz, G.D. The de novo synthesis of horsepox virus: Implications for biosecurity and recommendations for preventing the reemergence of smallpox. Health Secur. 2017, 15, 620–628. [Google Scholar] [CrossRef]
- Mitchell, L.A.; Ellis, T. Synthetic genome engineering gets infectious. Proc. Natl. Acad. Sci. USA 2017, 114, 11006–11008. [Google Scholar] [CrossRef] [Green Version]
- Lartigue, C.; Glass, J.I.; Alperovich, N.; Pieper, R.; Parmar, P.P.; Hutchison, C.A., 3rd; Smith, H.O.; Venter, J.C. Genome transplantation in bacteria: Changing one species to another. Science 2007, 317, 632–638. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Wu, R.; Xue, X.; Qin, Z. CasHRA (Cas9-facilitated Homologous Recombination Assembly) method of constructing megabase-sized DNA. Nucleic Acids Res. 2016, 44, e124. [Google Scholar] [CrossRef]
- Brumwell, S.L.; MacLeod, M.R.; Huang, T.; Cochrane, R.R.; Meaney, R.S.; Zamani, M.; Matysiakiewicz, O.; Dan, K.N.; Janakirama, P.; Edgell, D.R.; et al. Designer Sinorhizobium meliloti strains and multi-functional vectors enable direct inter-kingdom DNA transfer. PLoS ONE 2019, 14, e0206781. [Google Scholar] [CrossRef] [Green Version]
- Dohlemann, J.; Wagner, M.; Happel, C.; Carrillo, M.; Sobetzko, P.; Erb, T.J.; Thanbichler, M.; Becker, A. A family of single copy repABC-type shuttle vectors stably maintained in the alpha-Proteobacterium Sinorhizobium meliloti. ACS Synth. Biol. 2017, 6, 968–984. [Google Scholar] [CrossRef] [PubMed]
- Pretorius, I.S.; Boeke, J.D. Yeast 2.0-connecting the dots in the construction of the world’s first functional synthetic eukaryotic genome. FEMS Yeast Res. 2018, 18, foy032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dymond, J.S.; Richardson, S.M.; Coombes, C.E.; Babatz, T.; Muller, H.; Annaluru, N.; Blake, W.J.; Schwerzmann, J.W.; Dai, J.; Lindstrom, D.L.; et al. Synthetic chromosome arms function in yeast and generate phenotypic diversity by design. Nature 2011, 477, 471–476. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dymond, J.; Boeke, J. The Saccharomyces cerevisiae SCRaMbLE system and genome minimization. Bioeng. Bugs. 2012, 3, 168–171. [Google Scholar] [CrossRef] [Green Version]
- Eisenstein, M. How to build a genome. Nature 2020, 578, 633–635. [Google Scholar] [CrossRef] [Green Version]
- Mieczkowski, P.A.; Lemoine, F.J.; Petes, T.D. Recombination between retrotransposons as a source of chromosome rearrangements in the yeast Saccharomyces cerevisiae. DNA Repair (Amst.) 2006, 5, 1010–1020. [Google Scholar] [CrossRef]
- Maxwell, P.H.; Burhans, W.C.; Curcio, M.J. Retrotransposition is associated with genome instability during chronological aging. Proc. Natl. Acad. Sci. USA 2011, 108, 20376–20381. [Google Scholar] [CrossRef] [Green Version]
- Mularoni, L.; Zhou, Y.; Bowen, T.; Gangadharan, S.; Wheelan, S.J.; Boeke, J.D. Retrotransposon Ty1 integration targets specifically positioned asymmetric nucleosomal DNA segments in tRNA hotspots. Genome Res. 2012, 22, 693–703. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Alberts, B.M. Head-on collision between a DNA replication apparatus and RNA polymerase transcription complex. Science 1995, 267, 1131–1137. [Google Scholar] [CrossRef]
- Brewer, B.J.; Fangman, W.L. A replication fork barrier at the 3′ end of yeast ribosomal RNA genes. Cell 1988, 55, 637–643. [Google Scholar] [CrossRef]
- Dymond, J.S.; Scheifele, L.Z.; Richardson, S.; Lee, P.; Chandrasegaran, S.; Bader, J.S.; Boeke, J.D. Teaching synthetic biology, bioinformatics and engineering to undergraduates: The interdisciplinary Build-a-Genome course. Genetics 2009, 181, 13–21. [Google Scholar] [CrossRef] [Green Version]
- Annaluru, N.; Muller, H.; Mitchell, L.A.; Ramalingam, S.; Stracquadanio, G.; Richardson, S.M.; Dymond, J.S.; Kuang, Z.; Scheifele, L.Z.; Cooper, E.M.; et al. Total synthesis of a functional designer eukaryotic chromosome. Science 2014, 344, 55–58. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Zhao, G.; Luo, Z.; Lin, Y.; Wang, L.; Guo, Y.; Wang, A.; Jiang, S.; Jiang, Q.; Gong, J.; et al. Engineering the ribosomal DNA in a megabase synthetic chromosome. Science 2017, 355, eaaf3981. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mitchell, L.A.; Wang, A.; Stracquadanio, G.; Kuang, Z.; Wang, X.; Yang, K.; Richardson, S.; Martin, J.A.; Zhao, Y.; Walker, R.; et al. Synthesis, debugging, and effects of synthetic chromosome consolidation: synVI and beyond. Science 2017, 355, eaaf4831. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Wang, Y.; Chen, T.; Gao, F.; Gong, J.; Abramczyk, D.; Walker, R.; Zhao, H.; Chen, S.; Liu, W.; et al. Deep functional analysis of synII, a 770-kilobase synthetic yeast chromosome. Science 2017, 355, eaaf4791. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Y.; Li, B.Z.; Zhao, M.; Mitchell, L.A.; Xie, Z.X.; Lin, Q.H.; Wang, X.; Xiao, W.H.; Wang, Y.; Zhou, X.; et al. Bug mapping and fitness testing of chemically synthesized chromosome X. Science 2017, 355, eaaf4706. [Google Scholar] [CrossRef] [Green Version]
- Xie, Z.X.; Li, B.Z.; Mitchell, L.A.; Wu, Y.; Qi, X.; Jin, Z.; Jia, B.; Wang, X.; Zeng, B.X.; Liu, H.M.; et al. “Perfect” designer chromosome V and behavior of a ring derivative. Science 2017, 355, eaaf4704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, H.; Han, M.; Zhou, S.; Li, B.Z.; Wu, Y.; Yuan, Y.J. Chromosome drives via CRISPR-Cas9 in yeast. Nat. Commun. 2020, 11, 4344. [Google Scholar] [CrossRef]
- Mercy, G.; Mozziconacci, J.; Scolari, V.F.; Yang, K.; Zhao, G.; Thierry, A.; Luo, Y.; Mitchell, L.A.; Shen, M.; Shen, Y.; et al. 3D organization of synthetic and scrambled chromosomes. Science 2017, 355, eaaf4597. [Google Scholar] [CrossRef] [Green Version]
- Shen, Y.; Stracquadanio, G.; Wang, Y.; Yang, K.; Mitchell, L.A.; Xue, Y.; Cai, Y.; Chen, T.; Dymond, J.S.; Kang, K.; et al. SCRaMbLE generates designed combinatorial stochastic diversity in synthetic chromosomes. Genome Res. 2016, 26, 36–49. [Google Scholar] [CrossRef] [Green Version]
- Blount, B.A.; Gowers, G.F.; Ho, J.C.H.; Ledesma-Amaro, R.; Jovicevic, D.; McKiernan, R.M.; Xie, Z.X.; Li, B.Z.; Yuan, Y.J.; Ellis, T. Rapid host strain improvement by in vivo rearrangement of a synthetic yeast chromosome. Nat. Commun. 2018, 9, 1932. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Luo, Z.; Wang, Y.; Pham, N.T.; Tuck, L.; Perez-Pi, I.; Liu, L.; Shen, Y.; French, C.; Auer, M.; et al. Rapid pathway prototyping and engineering using in vitro and in vivo synthetic genome SCRaMbLE-in methods. Nat. Commun. 2018, 9, 1936. [Google Scholar] [CrossRef] [Green Version]
- Jin, J.; Jia, B.; Yuan, Y.J. Yeast chromosomal engineering to improve industrially-relevant phenotypes. Curr. Opin. Biotechnol. 2020, 66, 165–170. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Li, Y.; Chen, X.; Ding, M.; Wu, Y.; Yuan, Y.J. SCRaMbLE generates evolved yeasts with increased alkali tolerance. Microb. Cell Fact. 2019, 18, 52. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Boeke, J.D.; Luo, Z.; Jiang, S.; Cai, Y. Sc3.0: Revamping and minimizing the yeast genome. Genome Biol. 2020, 21, 205. [Google Scholar] [CrossRef] [PubMed]
- Hochrein, L.; Mitchell, L.A.; Schulz, K.; Messerschmidt, K.; Mueller-Roeber, B. L-SCRaMbLE as a tool for light-controlled Cre-mediated recombination in yeast. Nat. Commun. 2018, 9, 1931. [Google Scholar] [CrossRef] [PubMed]
- Luo, Z.; Wang, L.; Wang, Y.; Zhang, W.; Guo, Y.; Shen, Y.; Jiang, L.; Wu, Q.; Zhang, C.; Cai, Y.; et al. Identifying and characterizing SCRaMbLEd synthetic yeast using ReSCuES. Nat. Commun. 2018, 9, 1930. [Google Scholar] [CrossRef] [PubMed]
- Gowers, G.F.; Chee, S.M.; Bell, D.; Suckling, L.; Kern, M.; Tew, D.; McClymont, D.W.; Ellis, T. Improved betulinic acid biosynthesis using synthetic yeast chromosome recombination and semi-automated rapid LC-MS screening. Nat. Commun. 2020, 11, 868. [Google Scholar] [CrossRef]
- Hieter, P.; Pridmore, D.; Hegemann, J.H.; Thomas, M.; Davis, R.W.; Philippsen, P. Functional selection and analysis of yeast centromeric DNA. Cell 1985, 42, 913–921. [Google Scholar] [CrossRef]
- Pluta, A.F.; Mackay, A.M.; Ainsztein, A.M.; Goldberg, I.G.; Earnshaw, W.C. The centromere: Hub of chromosomal activities. Science 1995, 270, 1591–1594. [Google Scholar] [CrossRef]
- Shao, Y.; Lu, N.; Wu, Z.; Cai, C.; Wang, S.; Zhang, L.L.; Zhou, F.; Xiao, S.; Liu, L.; Zeng, X.; et al. Creating a functional single-chromosome yeast. Nature 2018, 560, 331–335. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Sun, X.; Cormack, B.P.; Boeke, J.D. Karyotype engineering by chromosome fusion leads to reproductive isolation in yeast. Nature 2018, 560, 392–396. [Google Scholar] [CrossRef] [PubMed]
- Shao, Y.; Lu, N.; Cai, C.; Zhou, F.; Wang, S.; Zhao, Z.; Zhao, G.; Zhou, J.Q.; Xue, X.; Qin, Z. A single circular chromosome yeast. Cell Res. 2019, 29, 87–89. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Widianto, D.; Yamamoto, E.; Sugiyama, M.; Mukai, Y.; Kaneko, Y.; Oshima, Y.; Nishizawa, M.; Harashima, S. Creating a Saccharomyces cerevisiae haploid strain having 21 chromosomes. J. Biosci. Bioeng. 2003, 95, 89–94. [Google Scholar] [CrossRef]
- Yamagishi, K.; Sugiyama, M.; Kaneko, Y.; Nishizawa, M.; Harashima, S. Construction and characterization of single-gene chromosomes in Saccharomyces cerevisiae. J. Biosci. Bioeng. 2008, 106, 563–567. [Google Scholar] [CrossRef]
- Kuijpers, N.G.; Solis-Escalante, D.; Luttik, M.A.; Bisschops, M.M.; Boonekamp, F.J.; van den Broek, M.; Pronk, J.T.; Daran, J.M.; Daran-Lapujade, P. Pathway swapping: Toward modular engineering of essential cellular processes. Proc. Natl. Acad. Sci. USA 2016, 113, 15060–15065. [Google Scholar] [CrossRef] [Green Version]
- Krzywinski, M.; Schein, J.; Birol, I.; Connors, J.; Gascoyne, R.; Horsman, D.; Jones, S.J.; Marra, M.A. Circos: An information aesthetic for comparative genomics. Genome Res. 2009, 19, 1639–1645. [Google Scholar] [CrossRef] [Green Version]
- Harari, Y.; Ram, Y.; Rappoport, N.; Hadany, L.; Kupiec, M. Spontaneous changes in ploidy are common in yeast. Curr. Biol. 2018, 28, 825–835.e4. [Google Scholar] [CrossRef] [Green Version]
- Fisher, K.J.; Buskirk, S.W.; Vignogna, R.C.; Marad, D.A.; Lang, G.I. Adaptive genome duplication affects patterns of molecular evolution in Saccharomyces cerevisiae. PLoS Genet. 2018, 14, e1007396. [Google Scholar] [CrossRef]
- Selmecki, A.M.; Maruvka, Y.E.; Richmond, P.A.; Guillet, M.; Shoresh, N.; Sorenson, A.L.; De, S.; Kishony, R.; Michor, F.; Dowell, R.; et al. Polyploidy can drive rapid adaptation in yeast. Nature 2015, 519, 349–352. [Google Scholar] [CrossRef]
- Harari, Y.; Ram, Y.; Kupiec, M. Frequent ploidy changes in growing yeast cultures. Curr. Genet. 2018, 64, 1001–1004. [Google Scholar] [CrossRef] [PubMed]
- Cliften, P.F.; Fulton, R.S.; Wilson, R.K.; Johnston, M. After the duplication: Gene loss and adaptation in Saccharomyces genomes. Genetics 2006, 172, 863–872. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Escalera-Fanjul, X.; Quezada, H.; Riego-Ruiz, L.; Gonzalez, A. Whole-genome duplication and yeast’s fruitful way of life. Trends Genet. 2019, 35, 42–54. [Google Scholar] [CrossRef] [PubMed]
- Costanzo, M.; VanderSluis, B.; Koch, E.N.; Baryshnikova, A.; Pons, C.; Tan, G.; Wang, W.; Usaj, M.; Hanchard, J.; Lee, S.D.; et al. A global genetic interaction network maps a wiring diagram of cellular function. Science 2016, 353, aaf1420. [Google Scholar] [CrossRef]
- Tong, A.H.; Lesage, G.; Bader, G.D.; Ding, H.; Xu, H.; Xin, X.; Young, J.; Berriz, G.F.; Brost, R.L.; Chang, M.; et al. Global mapping of the yeast genetic interaction network. Science 2004, 303, 808–813. [Google Scholar] [CrossRef] [Green Version]
- Giaever, G.; Chu, A.M.; Ni, L.; Connelly, C.; Riles, L.; Veronneau, S.; Dow, S.; Lucau-Danila, A.; Anderson, K.; Andre, B.; et al. Functional profiling of the Saccharomyces cerevisiae genome. Nature 2002, 418, 387–391. [Google Scholar] [CrossRef]
- Costanzo, M.; Baryshnikova, A.; Bellay, J.; Kim, Y.; Spear, E.D.; Sevier, C.S.; Ding, H.; Koh, J.L.; Toufighi, K.; Mostafavi, S.; et al. The genetic landscape of a cell. Science 2010, 327, 425–431. [Google Scholar] [CrossRef] [Green Version]
- Tong, A.H.; Evangelista, M.; Parsons, A.B.; Xu, H.; Bader, G.D.; Page, N.; Robinson, M.; Raghibizadeh, S.; Hogue, C.W.; Bussey, H.; et al. Systematic genetic analysis with ordered arrays of yeast deletion mutants. Science 2001, 294, 2364–2368. [Google Scholar] [CrossRef]
- Peter, J.; De Chiara, M.; Friedrich, A.; Yue, J.X.; Pflieger, D.; Bergstrom, A.; Sigwalt, A.; Barre, B.; Freel, K.; Llored, A.; et al. Genome evolution across 1,011 Saccharomyces cerevisiae isolates. Nature 2018, 556, 339–344. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Ji, B.; Nielsen, J. The pan-genome of Saccharomyces cerevisiae. FEMS Yeast Res. 2019, 19, foz064. [Google Scholar] [CrossRef]
- Preiss, R.; Tyrawa, C.; Krogerus, K.; Garshol, L.M.; van der Merwe, G. Traditional Norwegian Kveik are a genetically distinct group of domesticated Saccharomyces cerevisiae brewing yeasts. Front. Microbiol. 2018, 9, 2137. [Google Scholar] [CrossRef] [Green Version]
- Truong, D.M.; Boeke, J.D. Resetting the yeast epigenome with human nucleosomes. Cell 2017, 171, 1508–1519.e13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nutzmann, H.W.; Scazzocchio, C.; Osbourn, A. Metabolic gene clusters in eukaryotes. Annu. Rev. Genet. 2018, 52, 159–183. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Ptacin, J.L.; Fischer, E.C.; Aerni, H.R.; Caffaro, C.E.; San Jose, K.; Feldman, A.W.; Turner, C.R.; Romesberg, F.E. A semi-synthetic organism that stores and retrieves increased genetic information. Nature 2017, 551, 644–647. [Google Scholar] [CrossRef] [Green Version]
- Malyshev, D.A.; Dhami, K.; Lavergne, T.; Chen, T.; Dai, N.; Foster, J.M.; Correa, I.R., Jr.; Romesberg, F.E. A semi-synthetic organism with an expanded genetic alphabet. Nature 2014, 509, 385–388. [Google Scholar] [CrossRef] [Green Version]
- Dien, V.T.; Holcomb, M.; Romesberg, F.E. Eight-Letter DNA. Biochemistry 2019, 58, 2581–2583. [Google Scholar] [CrossRef] [PubMed]
- Wiltschi, B. Incorporation of non-canonical amino acids into proteins in yeast. Fungal Genet. Biol. 2016, 89, 137–156. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Agmon, N.; Choi, W.J.; Ubide, A.; Stracquadanio, G.; Caravelli, K.; Hao, H.; Bader, J.S.; Boeke, J.D. Intrinsic biocontainment: Multiplex genome safeguards combine transcriptional and recombinational control of essential yeast genes. Proc. Natl. Acad. Sci. USA 2015, 112, 1803–1808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Evans, B.R.; Kotsakiozi, P.; Costa-da-Silva, A.L.; Ioshino, R.S.; Garziera, L.; Pedrosa, M.C.; Malavasi, A.; Virginio, J.F.; Capurro, M.L.; Powell, J.R. Transgenic Aedes aegypti mosquitoes transfer genes into a natural population. Sci. Rep. 2019, 9, 13047. [Google Scholar] [CrossRef]
- Guadalupe-Medina, V.; Wisselink, H.W.; Luttik, M.A.; de Hulster, E.; Daran, J.M.; Pronk, J.T.; van Maris, A.J. Carbon dioxide fixation by Calvin-Cycle enzymes improves ethanol yield in yeast. Biotechnol. Biofuels 2013, 6, 125. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.J.; Wang, M.M.; Chen, Y.W.; Wang, M.; Fan, L.H.; Tan, T.W. Engineered yeast with a CO2-fixation pathway to improve the bio-ethanol production from xylose-mixed sugars. Sci. Rep. 2017, 7, 43875. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gonzalez de la Cruz, J.; Machens, F.; Messerschmidt, K.; Bar-Even, A. Core catalysis of the reductive glycine pathway demonstrated in yeast. ACS Synth. Biol. 2019, 8, 911–917. [Google Scholar] [CrossRef] [PubMed]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schindler, D. Genetic Engineering and Synthetic Genomics in Yeast to Understand Life and Boost Biotechnology. Bioengineering 2020, 7, 137. https://doi.org/10.3390/bioengineering7040137
Schindler D. Genetic Engineering and Synthetic Genomics in Yeast to Understand Life and Boost Biotechnology. Bioengineering. 2020; 7(4):137. https://doi.org/10.3390/bioengineering7040137
Chicago/Turabian StyleSchindler, Daniel. 2020. "Genetic Engineering and Synthetic Genomics in Yeast to Understand Life and Boost Biotechnology" Bioengineering 7, no. 4: 137. https://doi.org/10.3390/bioengineering7040137