

Dense Multi-Scale Graph Convolutional Network for Knee Joint Cartilage Segmentation
 , , ,
, , , 
Abstract
:1. Introduction
1.1. Statistical Shape Methods
1.2. Machine Learning Methods
1.3. Multi-Atlas Patch-Based Segmentation Methods
1.4. Deep Learning Methods
1.5. Graph Convolutional Neural Networks
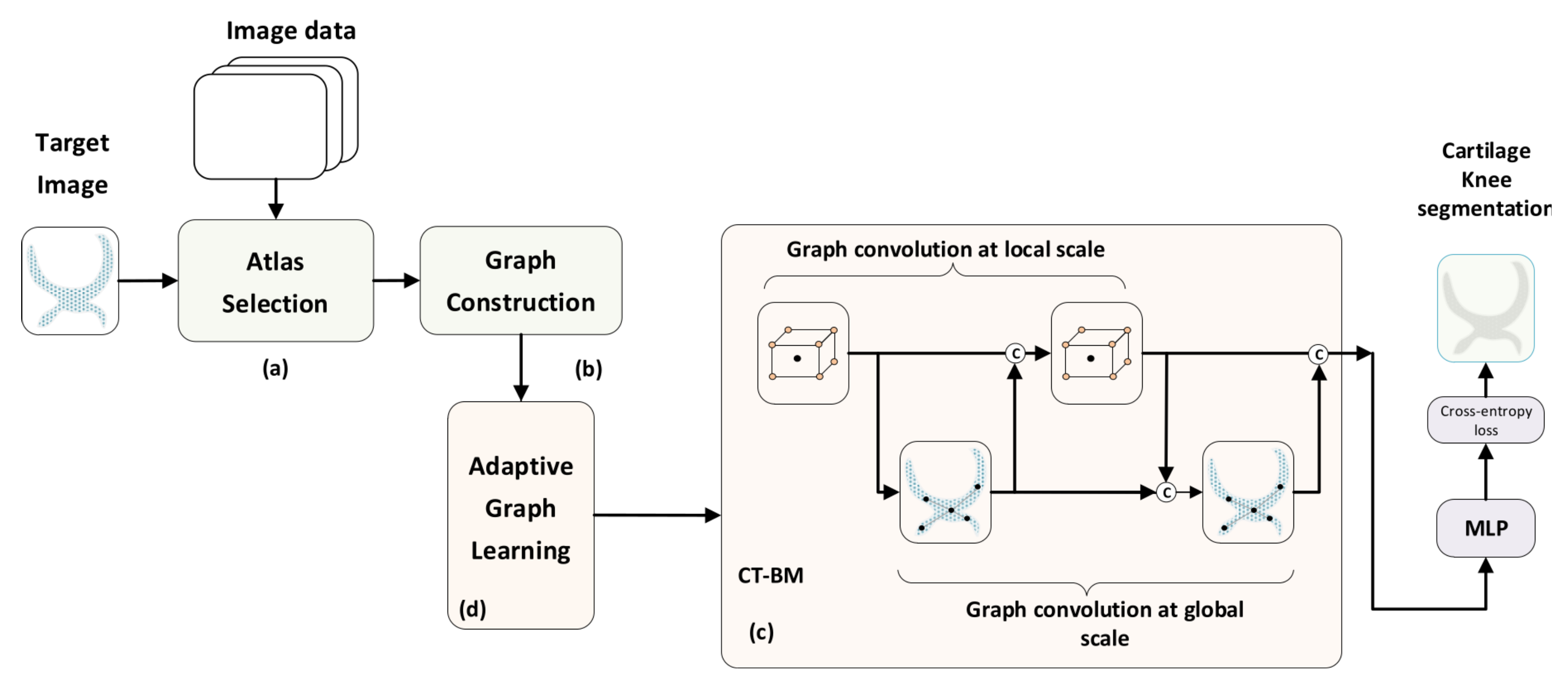
1.6. Outline of Proposed Method
- A novel multi-atlas approach is presented for knee cartilage segmentation from MRI images based on graph convolutional networks which operates under the semi-supervised learning paradigm.
- With the aim to generate expressive node representations, we propose a new learning scheme that integrates graph information at both local and global levels concurrently. The local branch exploits the relevant spatial information of neighboring nodes at multiple scales, while the global branch incorporates global contextual relationships among distant nodes.
- We propose two convolutional building models, the CT-BM and SEQ-BM. In the CT-BM, the local and global learning tasks are intertwined along the layer convolutions, while the SEQ-BM follows a sequential mode.
- Both local and global convolutional units, at each layer, are equipped with suitable attention mechanisms, which allows the network to automatically learn the graph connective relationships among nodes during training.
- Using the proposed CT-BM and SEQ-BM as block units, we finally present a novel densely connected model, the DMA-GCN. The network exhibits a deeper structure which leads to more enhanced segmentation results, while at the same time, it shares all salient properties of our approach.
- We have devised a thorough experimental setup to investigate the capabilities of the suggested segmentation framework. In this setting, we examine different test cases and provide an extensive comparative analysis with other segmentation methods.
2. Related Work
2.1. Graph Convolutional Network (GCN)
2.2. Graph Attention Network (GAT)
2.3. GraphSAGE
2.4. GraphSAINT
3. Materials
3.1. Image Dataset
3.2. Image Preprocessing
- Curvature flow filtering: A denoising curvature flow filter [39] was applied, with the aim of smoothing the homogeneous image regions, while simultaneously leaving the surface boundaries intact.
- Inhomogeneity correction: N3 intensity nonuniform bias field correction [40] was performed on all images, dealing with the issue of intrasubject variability within similar classes among subjects.
- Intensity standardization: MRI histograms were mapped to a common template, as described in [41], ensuring that all associated structures across the subjects shared a similar intensity profile.
- Nonlocal-means filtering: A final filtering process smoothed out any leftover artefacts and further reduced noise. The method presented in [42] offers a robust performance and is widely employed in similar medical imaging applications. Finally, the intensity range of all images was rescaled to .
3.3. Atlas Selection and ROI Extraction
4. Graph Constructions
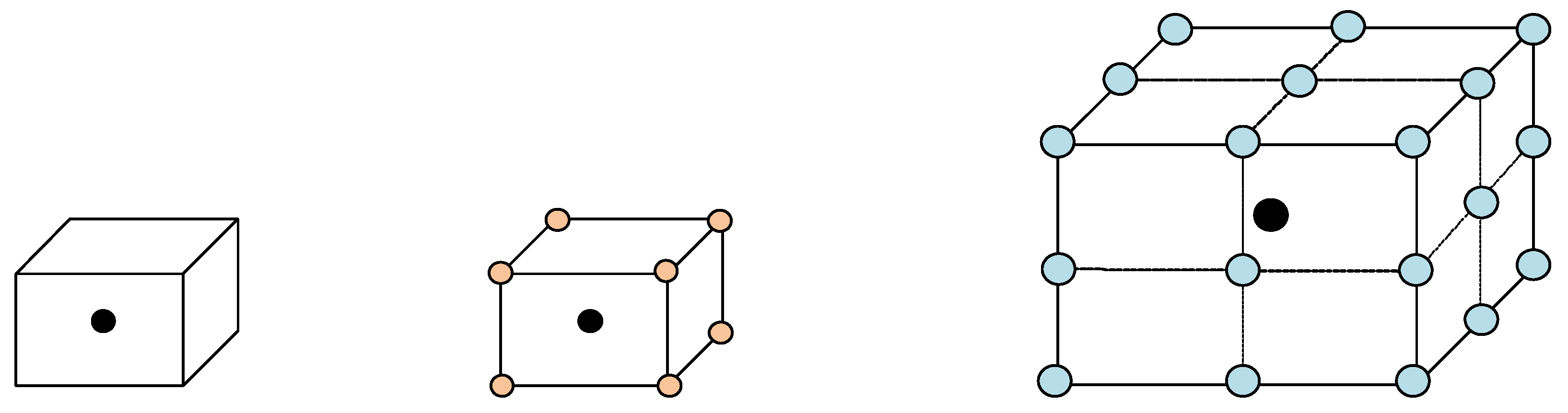
4.1. Node Representation
4.2. Aligned Image Graphs
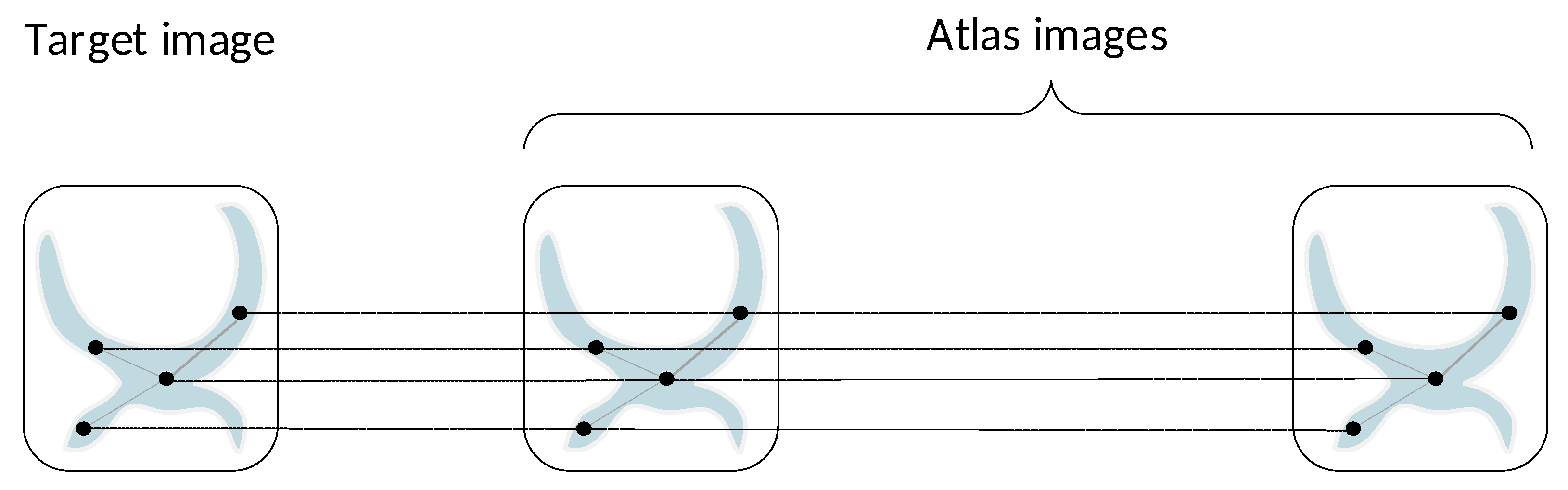
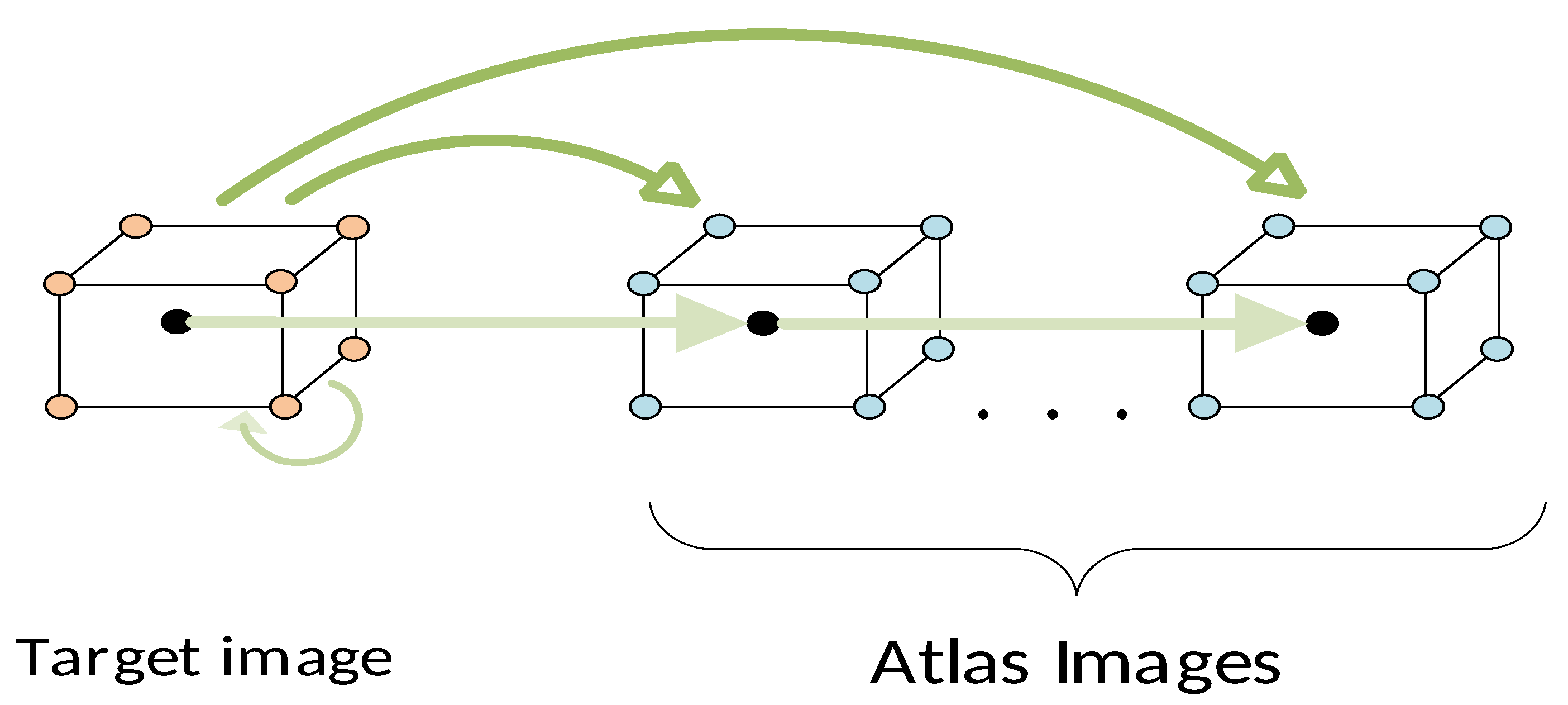
- Target graph construction: This step used a spatially stratified sampling method to generate an initial set of target voxels , where D denotes the feature dimensionality. To ensure a uniform spatial covering of all classes in the target ROI, we performed a spatial clustering step partitioning all contained voxels into clusters. After interpolating the cluster centers to the nearest grid point, we obtained the global dataset , which defined a corresponding target graph of root nodes . These target nodes served as reference points from which the aligned sequences were subsequently generated.
- Sequences of aligned data: For each , we defined a sequence of aligned nodes , containing the target node and its respective nodes from the atlas library, located at spatially correspondent positions:The entire global dataset of root nodes, containing all sampled target nodes and their associated atlas ones, was defined as the union of all those sequenceswhere contains a total number of root nodes, while and denote the datasets of root nodes sampled from the target and atlases, respectively. Accordingly, this led to a sequence of aligned graphs , , which is schematically shown in Figure 3. In this figure, we can distinguish two modes of pairwise relationships among root nodes that should be explored. Concretely, there are local spatial affinities across the horizontal axis between nodes belonging to a specific node sequence. On the other hand, there also exist global pairwise affinities between nodes of each image individually, as well as between nodes belonging to different images in the sequence. The latter type of search ensures that nodes of the same class located at different positions in the ROI volume and with different textural appearance are taken into consideration, thus leading to the extraction of more expressive node representations of the classes via learning.
4.3. Sequence Libraries
5. Convolutional Units
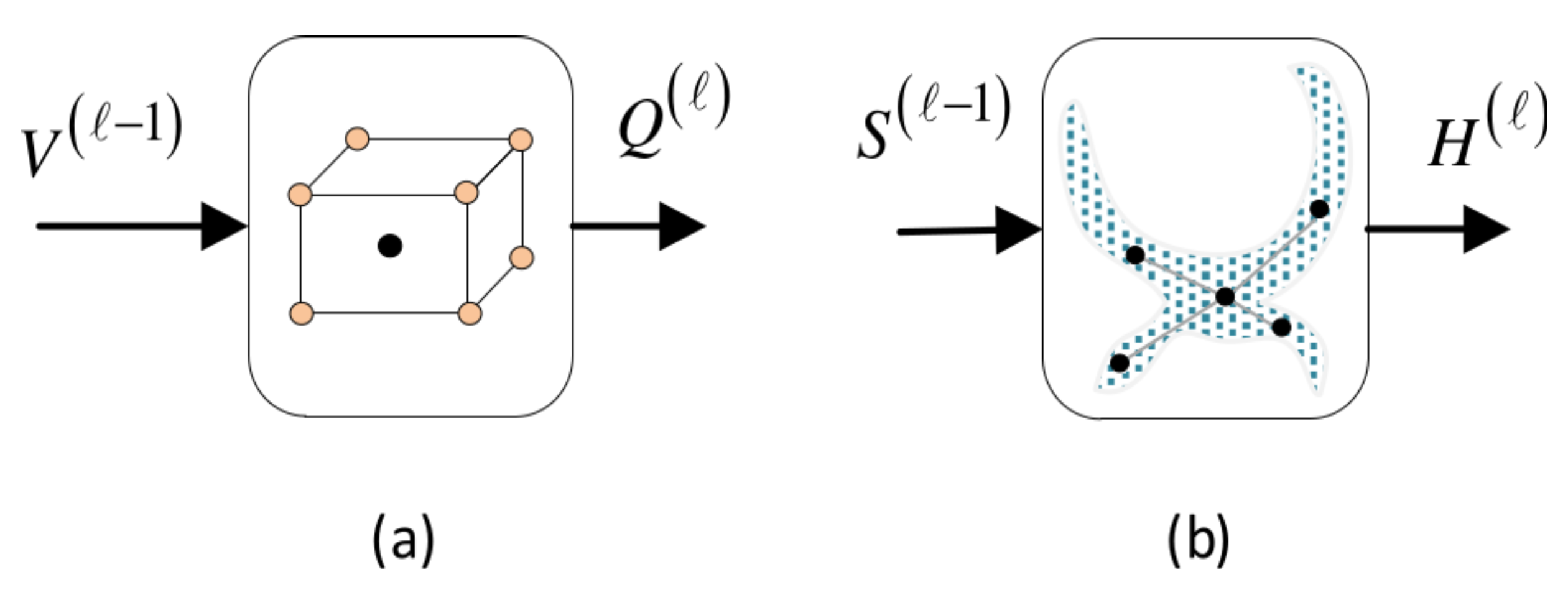
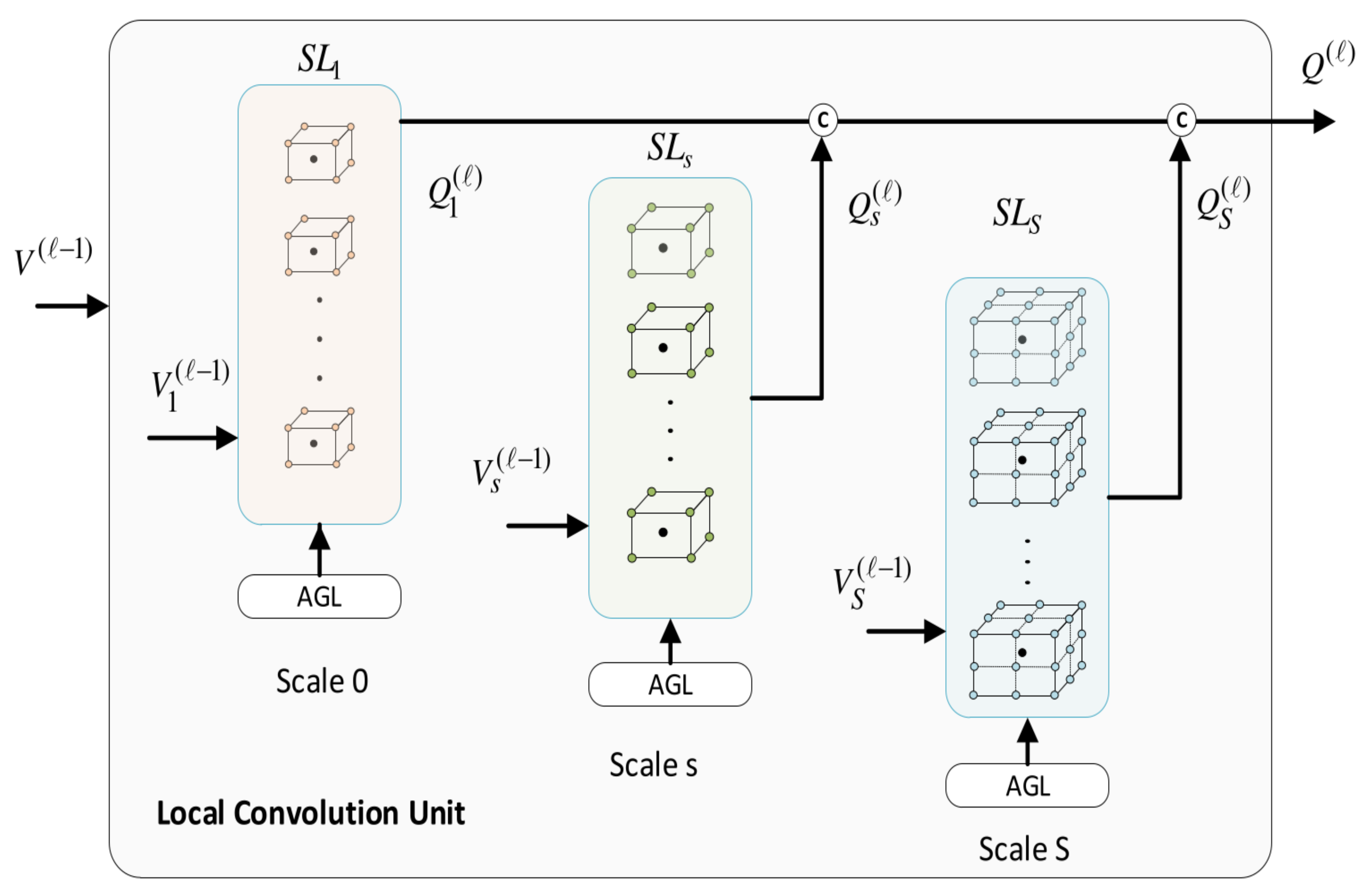
5.1. Local Convolutional Unit
5.2. Global Convolutional Unit
6. Proposed Convolutional Building Blocks
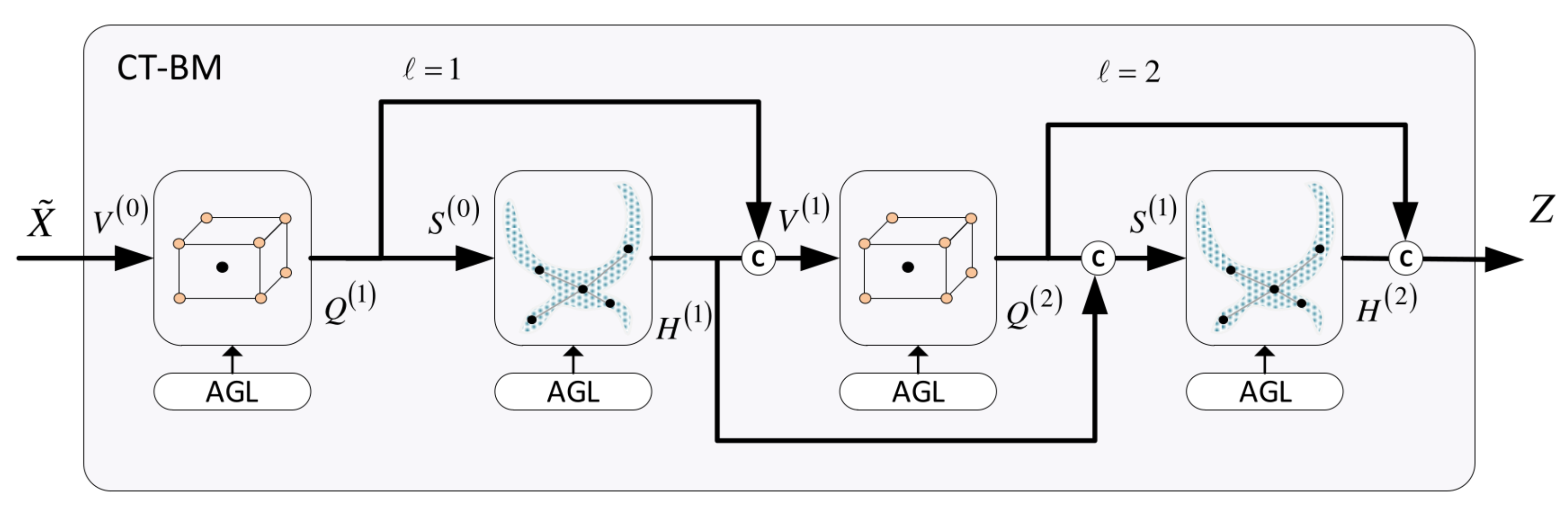
6.1. Cross-Talk Building Model (CT-BM)
- The first local unit yields
- The local unit’s output is passed to the first global unit to compute
- The second local unit receives an aggregated signal to provide its output,
- The second global unit produces
- The final output of the CT-BM is the obtained by
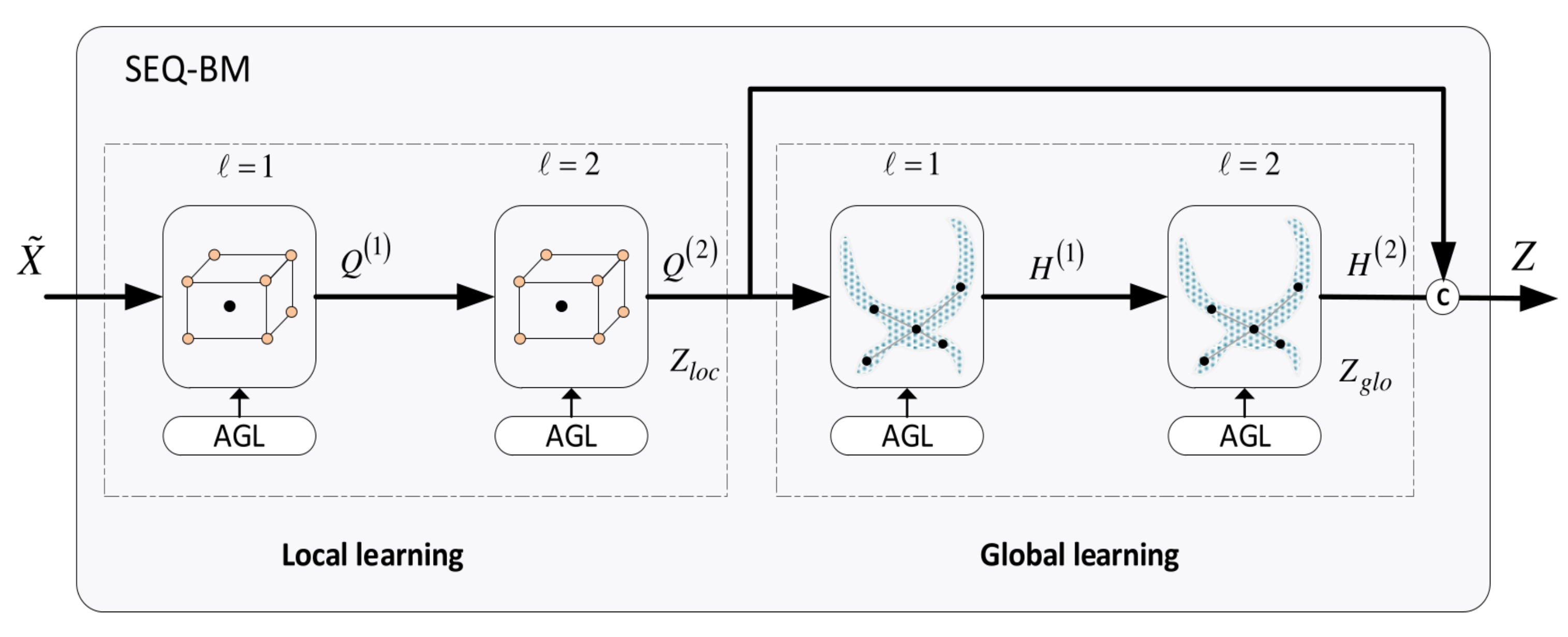
6.2. Sequential Building Model (SEQ-BM)
- The local learning task is described by
- The global learning task is described by
- The final output of the SEQ-BM is obtained by
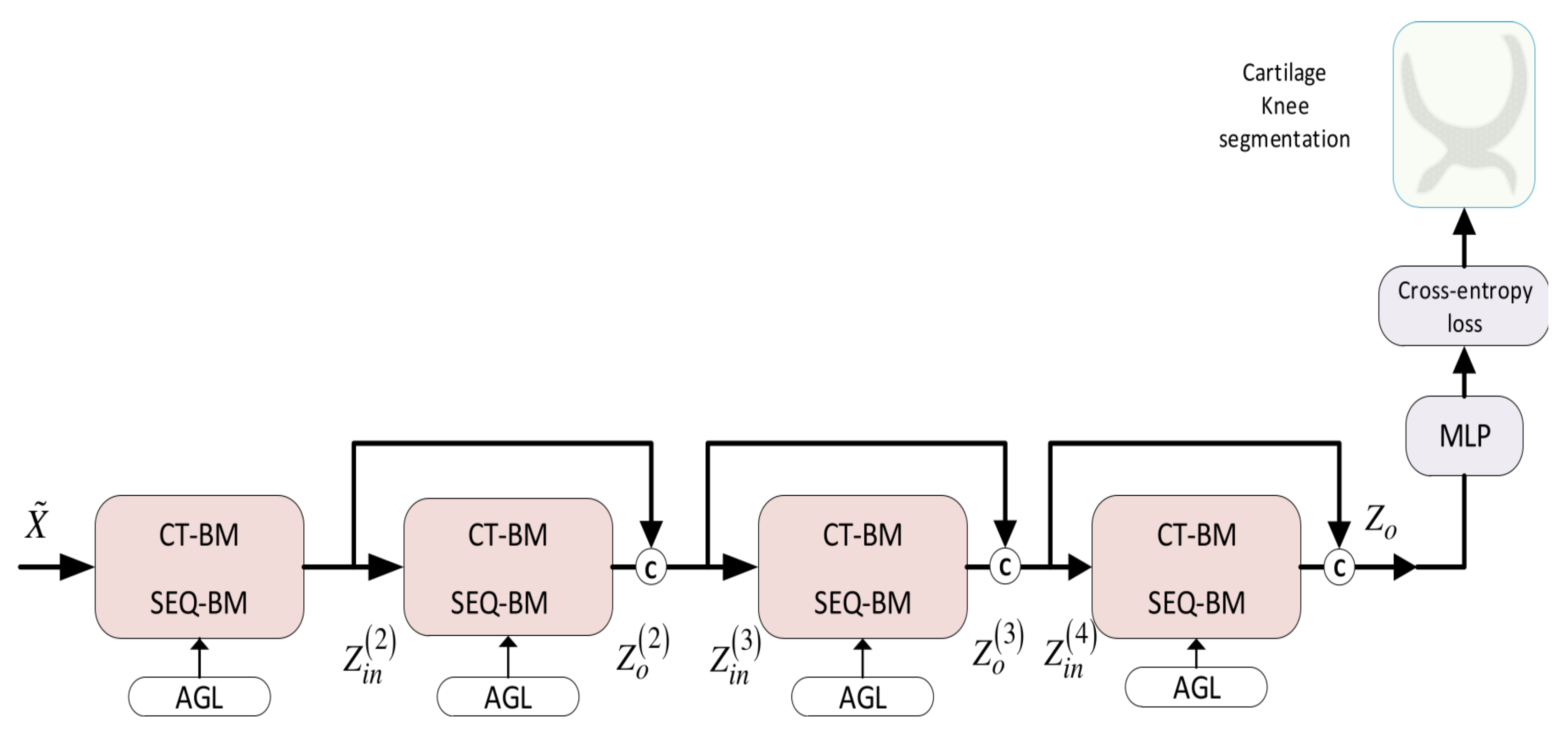
7. Proposed Dense Convolutional Networks
- The skip connections interconnect the blocks across the layers. Concretely, each block receives as input the outputs of blocks from all preceding layers:for , where ⊕ denotes the concatenation operator. This allows the generation of deeper GCN structures which can acquire more expressive node features. Overall, the DMA-GCN involves convolutional units. Within each block, two layers of local–global convolutions are internally performed; the resulting outputs are then integrated along the block layers to provide the final output:
- The other beneficial effect of skip connections is that they allow the final output to have direct access to the outputs of all blocks in the dense network. This assures a better reverse flow of information and facilitates the effective learning of parameters pertaining to the blocks. Since block operations are confined to two-layered local–global convolutions, overall, we can circumvent the gradient vanishing problem.
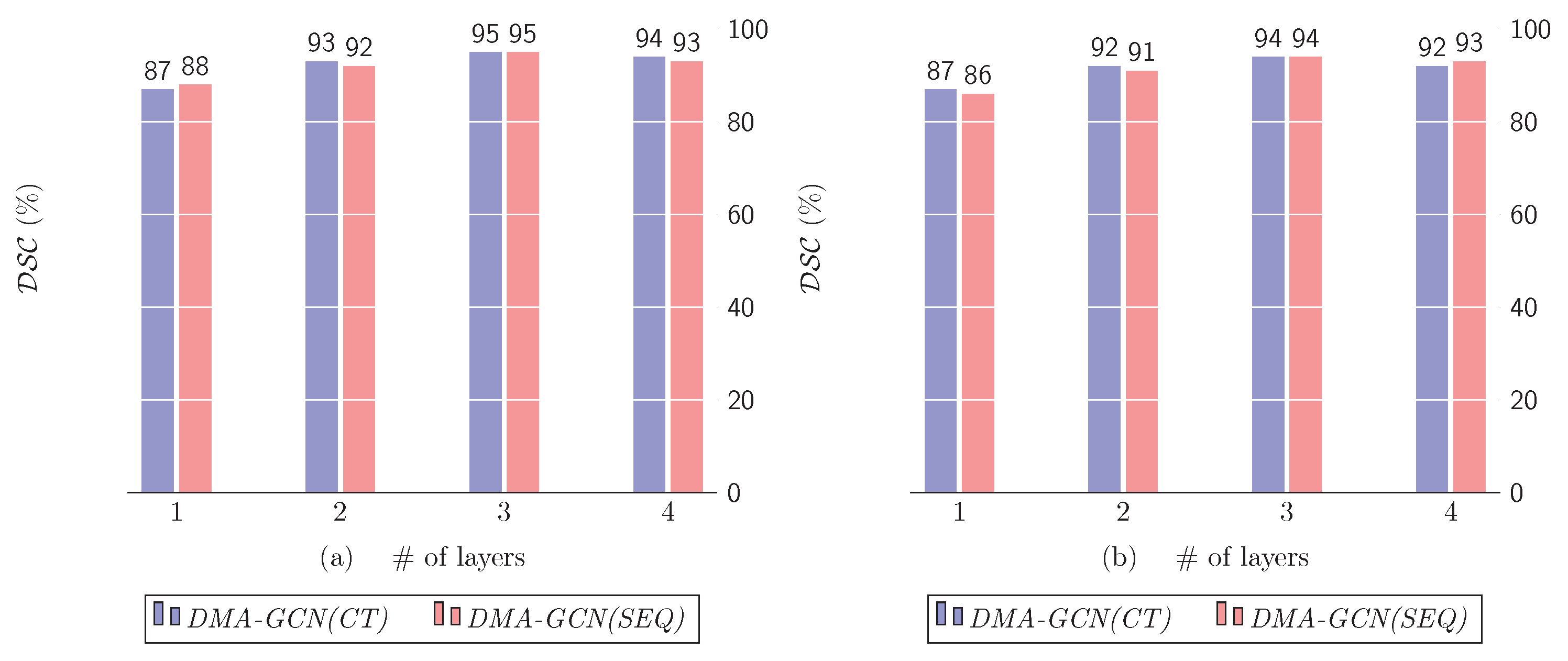
- In order to preserve the parametric complexity at a reasonable level, similar to [36], we define the feature dimensions of each block in DMA-GCN to be the same:The node feature growth rate caused by the aggregators can be defined as , . The input dimensions grow linearly as we proceed to deeper block layers, with the last block showing the largest increase . To prevent feature dimensionalities from receiving too large values, we considered initially a DMA-GCN model with blocks. The particular number of blocks in the above range was then decided after experimental validation (Section 10).
- Every block in DMA-GCN is supported with its corresponding AGL process to automatically learn the graph connective affinities at each layer. This is accomplished by applying an attention-based mechanism for local convolutional units (Section 5.1) and an adaptive construction of adjacency matrices from inputs node features (Section 5.2).
8. Network Learning
8.1. Transductive Learning (SSL)
8.2. Inductive Learning
9. Experimental Setup
9.1. Evaluation Metrics
9.2. Hyperparameter Setting and Validation
9.3. Experimental Test Cases
- Local vs. global learning: In this scenario, we aimed to observe the effect of performing local-level learning in addition to global learning. The goal here was to determine the potential boost in performance facilitated by the inclusion of the attention mechanism in our models.
- Transductive vs. inductive learning: The goal here was to ascertain whether the increased cost accompanying the transductive learning scheme could be justified in terms of performance, as compared to the less computationally demanding inductive learning.
- Sparse dense adjacency matrix: Here, we examined the effect of progressively sparsifying the adjacency matrix at each layer on the overall performance. We examined the following cases: (1) the default case with a dense and (2) thresholding so that each node was allowed connections to , or 20 spectrally adjacent ones.
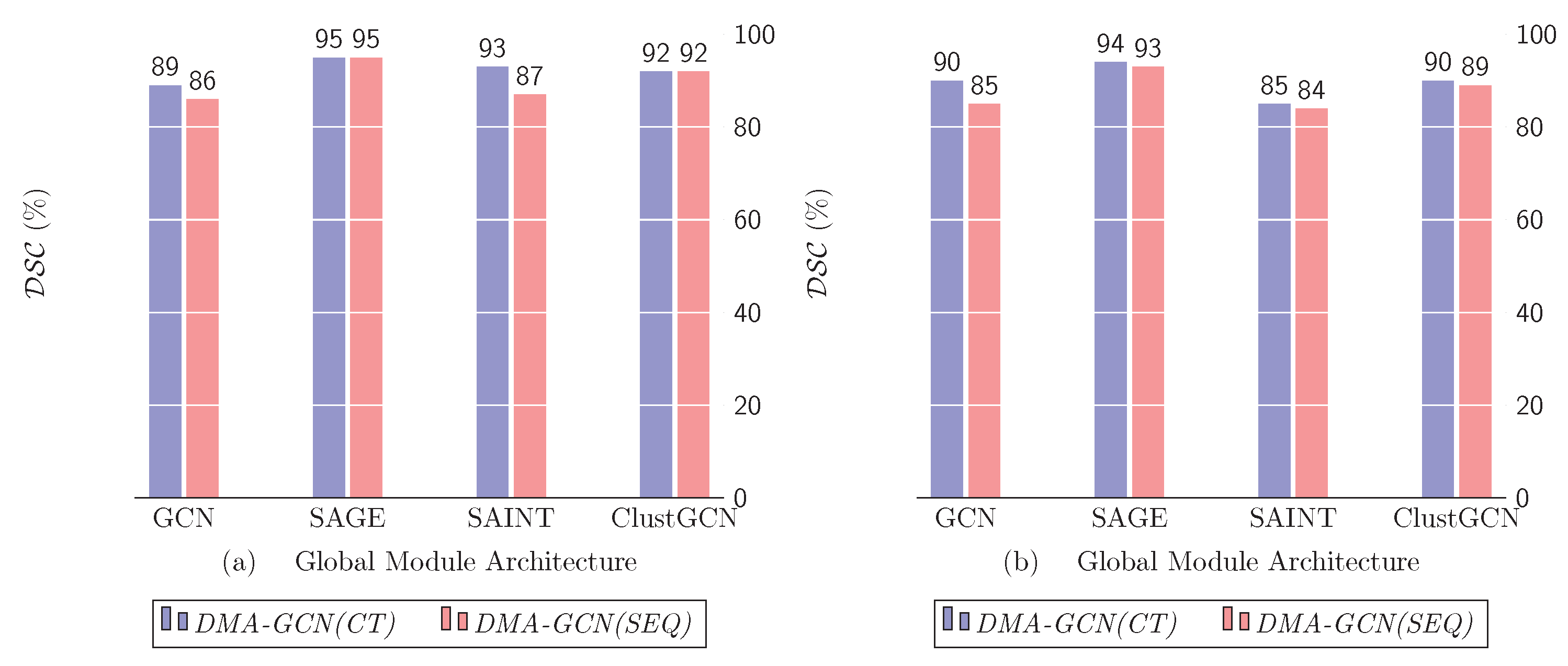
- Global convolution models: Finally, we tested the effect of varying the design of the global components by examining some prominent architectures, namely, GCN, ClusterGCN, GraphSAINT, and GraphSAGE
9.4. Competing Cartilage Segmentation Methods
9.4.1. Patch-Based Methods
9.4.2. Deep Learning Methods
9.4.3. Graph-Based Deep Learning Methods
9.5. Implementation Details
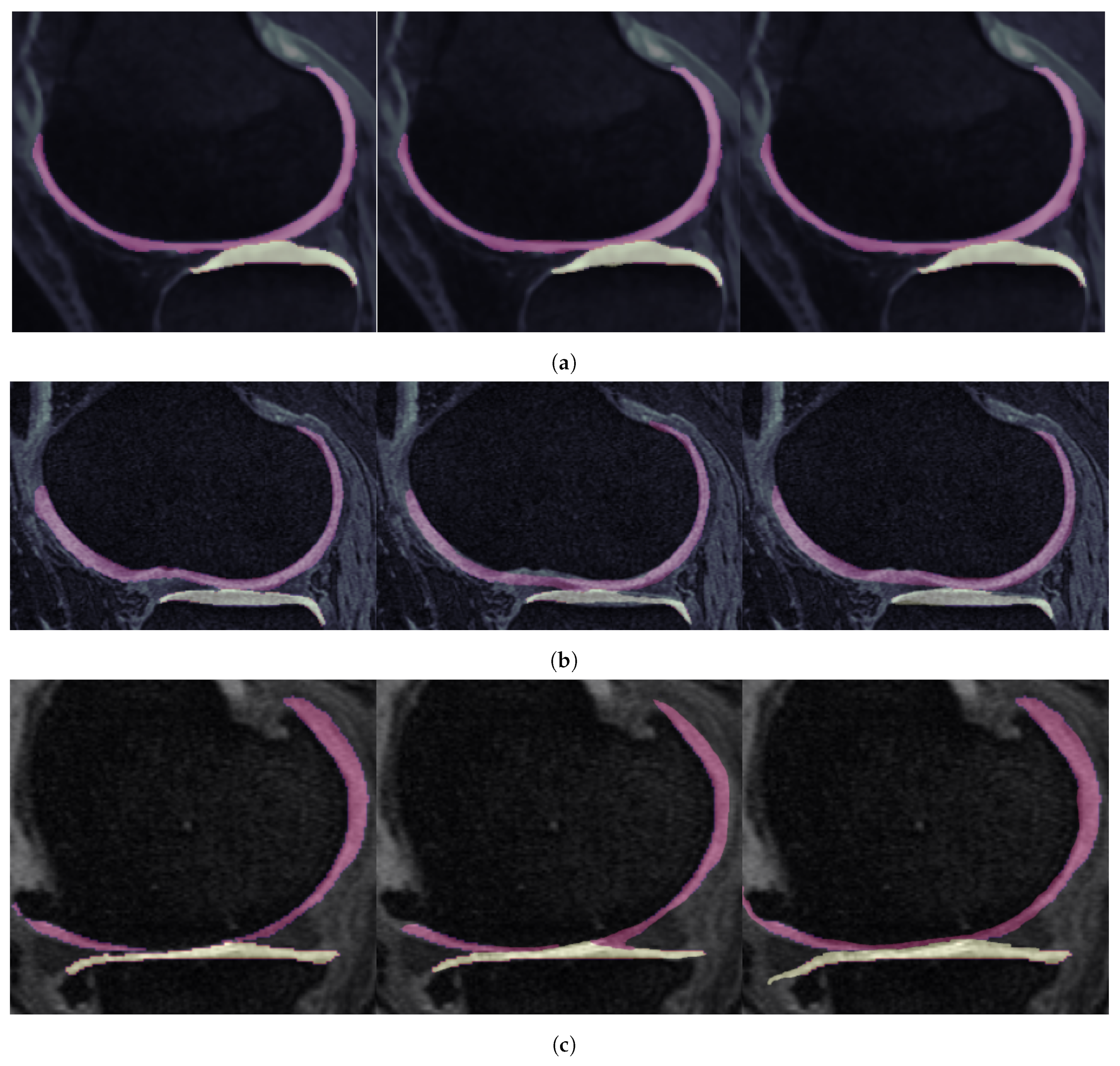
10. Experimental Results
10.1. Parameter Sensitivity Analysis
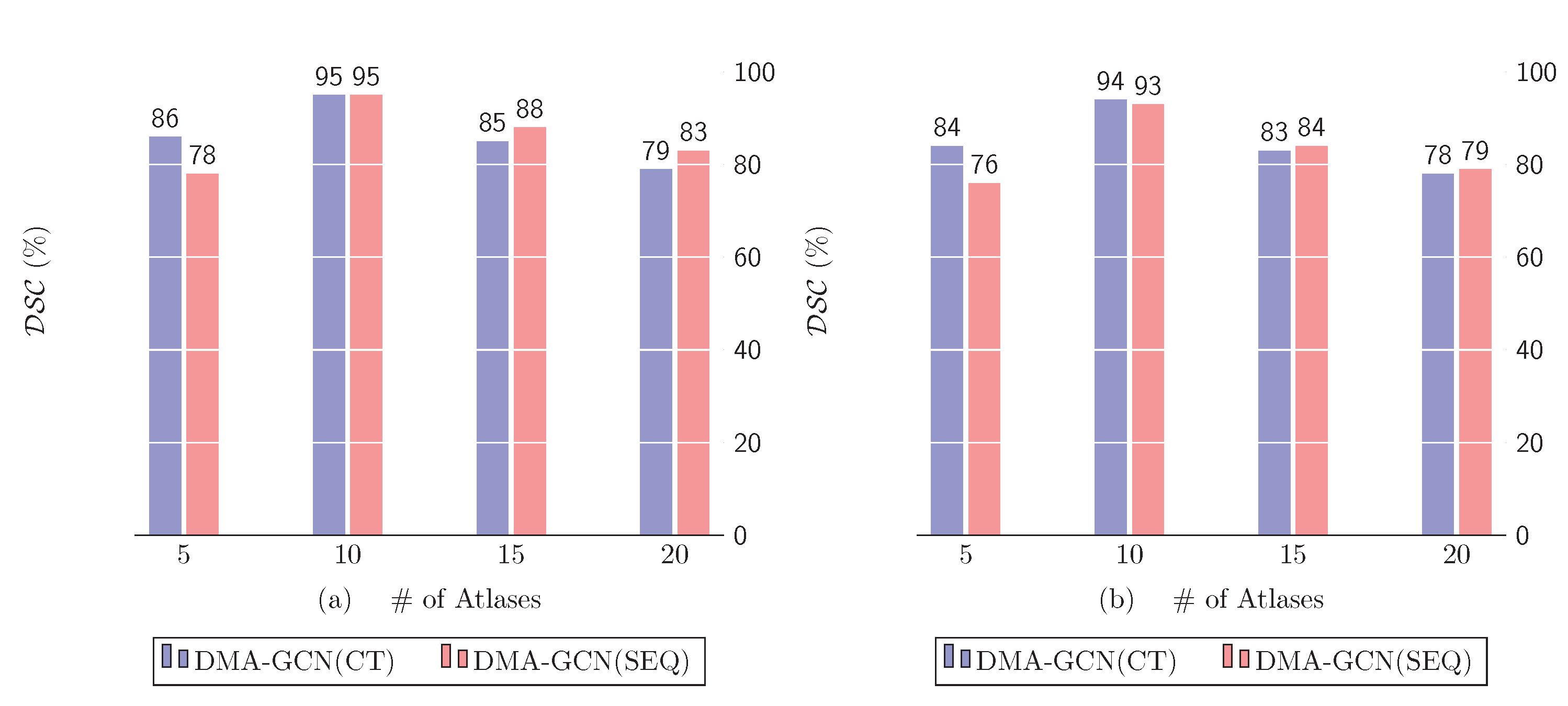
10.1.1. Number of Selected Atlases
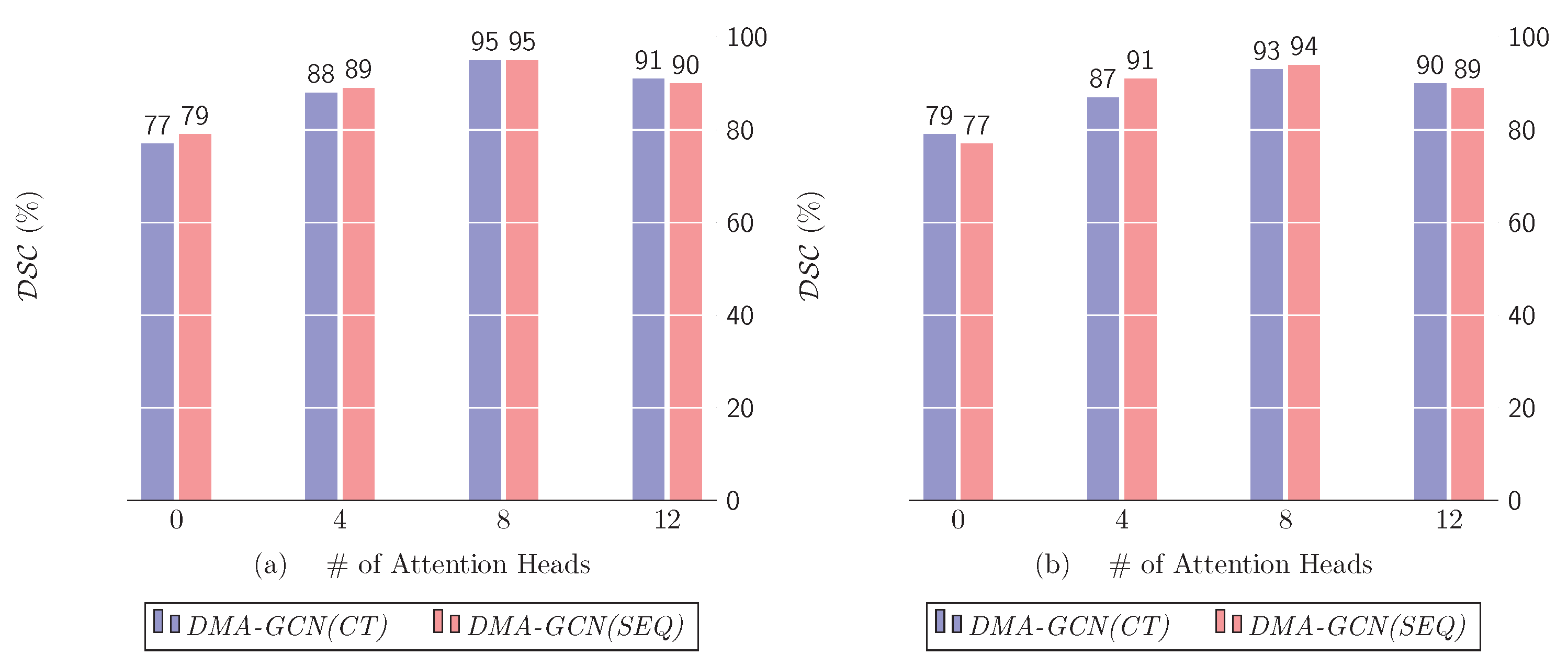
10.1.2. Number of Attention Heads
10.1.3. Sparsity of Adjacency Matrix
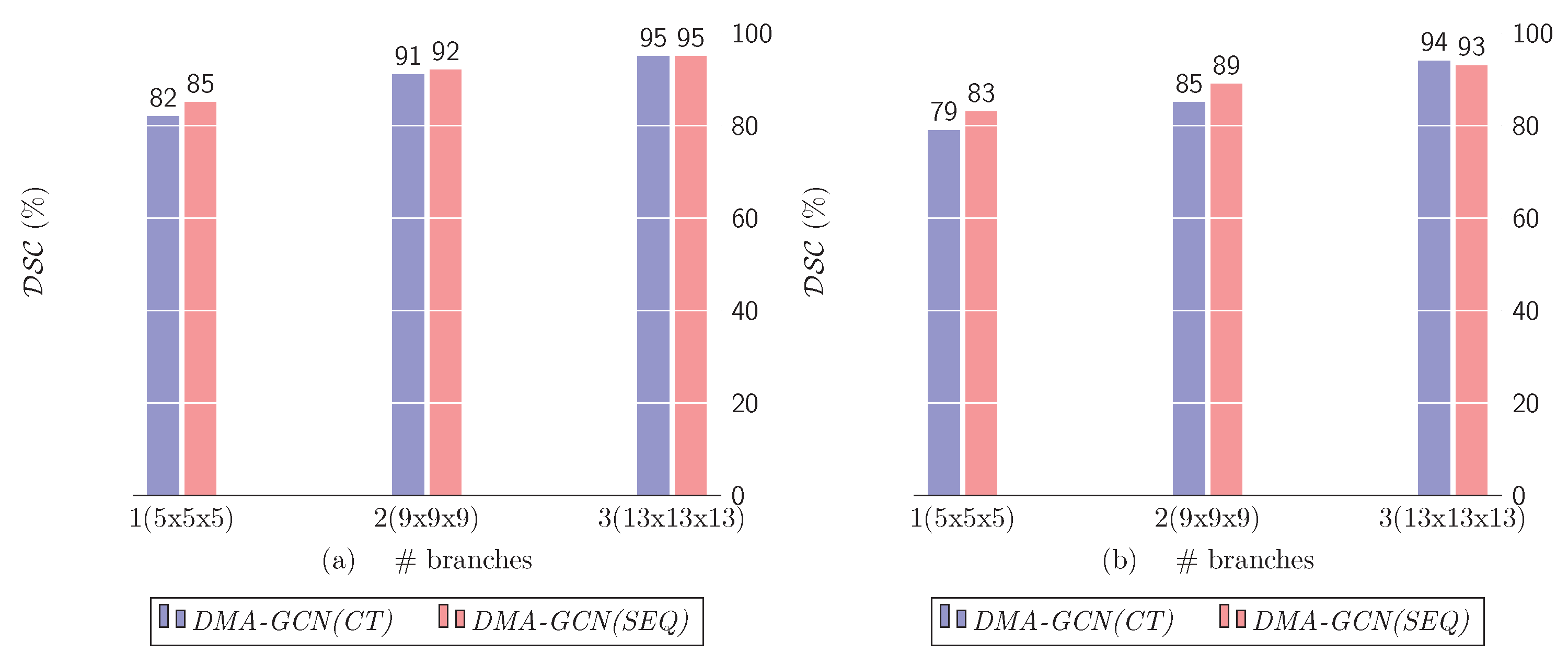
10.1.4. Number of Scales
10.2. Number of Dense Layers
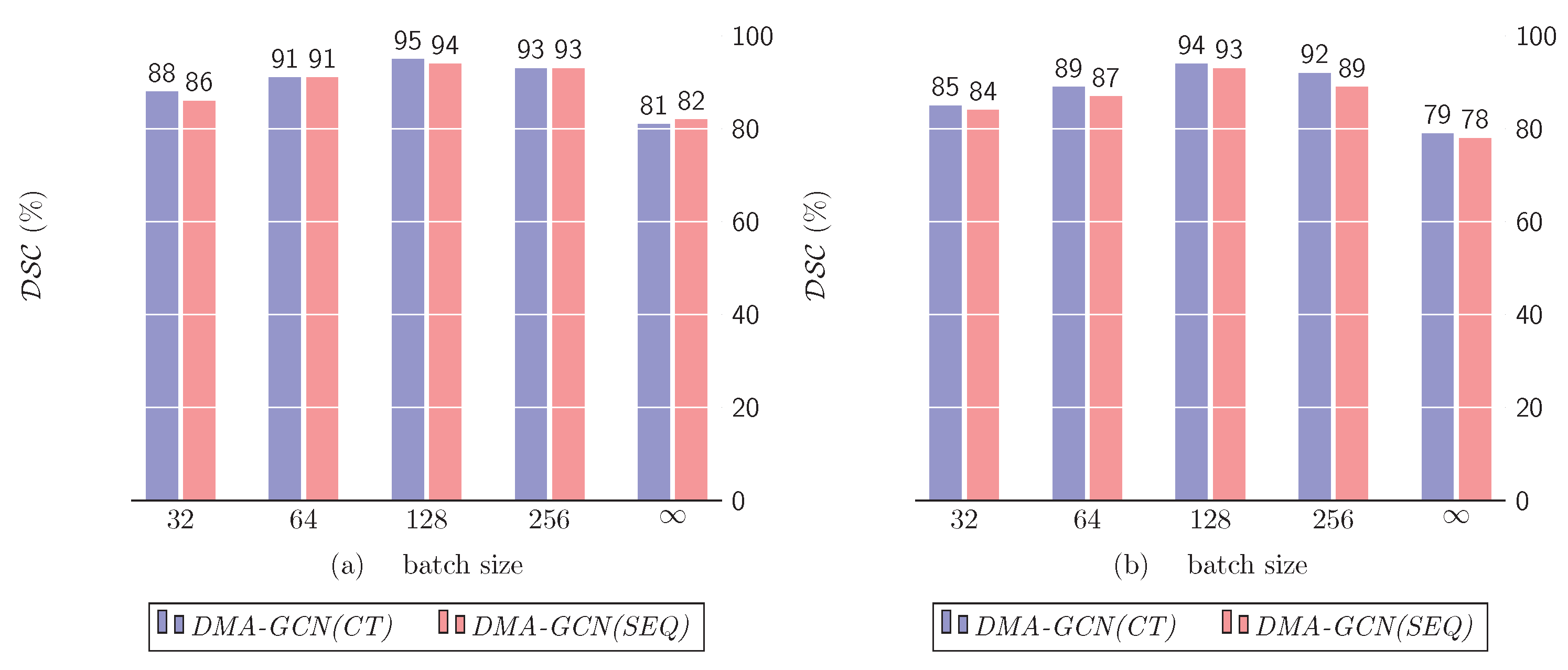
10.3. Mini-Batch vs. Full-Batch Training
10.4. Global Module Architecture
10.5. Transductive vs. Inductive Learning
10.6. Comparative Results
11. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Felipe, J.; McCombie, J. Burden of major musculoskeletal conditions. ERD Work. Pap. Ser. 2002, 81, 1–27. [Google Scholar]
- Ebrahimkhani, S.; Jaward, M.H.; Cicuttini, F.M.; Dharmaratne, A.; Wang, Y.; de Herrera, A.G. A review on segmentation of knee articular cartilage: From conventional methods towards deep learning. Artif. Intell. Med. 2020, 106, 101851. [Google Scholar] [CrossRef] [PubMed]
- Fripp, J.; Crozier, S.; Warfield, S.K.; Ourselin, S. Automatic segmentation of the bone and extraction of the bone-cartilage interface from magnetic resonance images of the knee. Phys. Med. Biol. 2007, 52, 1617–1631. [Google Scholar] [CrossRef]
- Ambellan, F.; Tack, A.; Ehlke, M.; Zachow, S. Automated segmentation of knee bone and cartilage combining statistical shape knowledge and convolutional neural networks: Data from the Osteoarthritis Initiative. Med. Image Anal. 2019, 52, 109–118. [Google Scholar] [CrossRef] [PubMed]
- Folkesson, J.; Dam, E.B.; Olsen, O.F.; Pettersen, P.C.; Christiansen, C. Segmenting articular cartilage automatically using a voxel classification approach. IEEE Trans. Med. Imaging 2007, 26, 106–115. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Lu, W.; Marziliano, P. Automatic knee cartilage segmentation from multi-contrast MR images using support vector machine classification with spatial dependencies. Magn. Reson. Imaging 2013, 31, 1731–1743. [Google Scholar] [CrossRef] [PubMed]
- Rousseau, F.; Habas, P.A.; Studholme, C. A supervised patch-based approach for human brain labeling. IEEE Trans. Med. Imaging 2011, 30, 1852–1862. [Google Scholar] [CrossRef]
- Zhang, D.; Guo, Q.; Wu, G.; Shen, D. Sparse patch-based label fusion for multi-atlas segmentation. In Multimodal Brain Image Analysis, Proceedings of the Multimodal Brain Image Analysis: Second International Workshop, MBIA 2012, Nice, France, 1–5 October 2012; Lecture Notes in Computer Science Series; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7509, pp. 94–102. [Google Scholar] [CrossRef]
- Hajnal, J.V.; Hill, D.L.; Hawkes, D.J. Medical image registration. Med. Image Regist. 2001, 46, 1–383. [Google Scholar] [CrossRef]
- Wang, R.; Lei, T.; Cui, R.; Zhang, B.; Meng, H.; Nandi, A.K. Medical image segmentation using deep learning: A survey. IET Image Process. 2022, 16, 1243–1267. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Cheng, J.Z.; Dou, Q.; Yang, X.; Chen, H.; Qin, J.; Heng, P.A. Automatic 3D cardiovascular MR segmentation with densely-connected volumetric convnets. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2017, Proceedings of the 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; Lecture Notes in Computer Science Series; Springer: Cham, Switzerland, 2017; Volume 10434, pp. 287–295. [Google Scholar] [CrossRef]
- Chen, H.; Dou, Q.; Yu, L.; Heng, P.A. VoxResNet: Deep Voxelwise Residual Networks for Volumetric Brain Segmentation. arXiv 2016, arXiv:1608.05895. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Xie, H.; Pan, Z.; Zhou, L.; Zaman, F.A.; Chen, D.Z.; Jonas, J.B.; Xu, W.; Wang, Y.X.; Wu, X. Globally optimal OCT surface segmentation using a constrained IPM optimization. Opt. Express 2022, 30, 2453. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 395–398. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, Toulon, France, 24–26 April 2017; pp. 1–14. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Zeng, H.; Zhou, H.; Srivastava, A.; Kannan, R.; Prasanna, V. GraphSAINT: Graph sampling based inductive learning method. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–19. [Google Scholar]
- Chen, J.; Ma, T.; Xiao, C. FastGCN: Fast learning with graph convolu-tional networks via importance sampling. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–15. [Google Scholar]
- Chiang, W.L.; Li, Y.; Liu, X.; Bengio, S.; Si, S.; Hsieh, C.J. Cluster-GCN: An efficient algorithm for training deep and large graph convolutional networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage AK USA, 4–8 August 2019; pp. 257–266. [Google Scholar] [CrossRef]
- Veličković, P.; Casanova, A.; Liò, P.; Cucurull, G.; Romero, A.; Bengio, Y. Graph attention networks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–12. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1025–1035. [Google Scholar]
- Qiu, J.; Tang, J.; Ma, H.; Dong, Y.; Wang, K.; Tang, J. DeepInf: Social influence prediction with deep learning. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 2110–2119. [Google Scholar] [CrossRef]
- Science, C. A Graph-to-Sequence Model for AMR-to-Text Generation. arXiv 2017, arXiv:1805.02473v3. [Google Scholar]
- Cao, N.D.; Kipf, T. MolGAN: An implicit generative model for small molecular graphs. arXiv 2019, arXiv:1805.11973v2. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. arXiv 2017, arXiv:1801.07455v2. [Google Scholar] [CrossRef]
- Wan, S.; Pan, S.; Zhong, S.; Yang, J.; Yang, J.; Zhan, Y.; Gong, C. Multi-level graph learning network for hyperspectral image classification. Pattern Recognit. 2022, 129, 108705. [Google Scholar] [CrossRef]
- Yang, P.; Tong, L.; Qian, B.; Gao, Z.; Yu, J.; Xiao, C. Hyperspectral Image Classification with Spectral and Spatial Graph Using Inductive Representation Learning Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 791–800. [Google Scholar] [CrossRef]
- Jia, S.; Jiang, S.; Zhang, S.; Xu, M.; Jia, X. Graph-in-Graph Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 1157–1171. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Chen, Y. Link prediction based on graph neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 5165–5175. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. IJCAI Int. Jt. Conf. Artif. Intell. 2018, 2018, 3634–3640. [Google Scholar]
- Guo, Z.; Li, X.; Huang, H.; Guo, N.; Li, Q. Deep learning-based image segmentation on multimodal medical imaging. IEEE Trans. Radiat. Plasma Med. Sci. 2019, 3, 162–169. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Tang, J. Deep Learning on Graphs; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Chadoulos, C.; Moustakidis, S.; Tsaopoulos, D.; Theocharis, J. Multi-atlas segmentation of knee cartilage by Propagating Labels via Semi-supervised Learning. In Proceedings of the IMIP 2022: 2022 4th International Conference on Intelligent Medicine and Image Processing, Tianjin, China, 18–21 March 2022; pp. 76–82. [Google Scholar] [CrossRef]
- Peterfy, C.G.; Schneider, E.; Nevitt, M. The osteoarthritis initiative: Report on the design rationale for the magnetic resonance imaging protocol for the knee. Osteoarthr. Cartil. 2008, 16, 1433–1441. [Google Scholar] [CrossRef]
- Sethian, J. Advancing interfaces: Level set and fast marching methods. In Level Set Methods and Fast Marching Methods, 2nd ed.; Cambridge Press: Cambridge, UK, 1999. [Google Scholar]
- Sled, J.G.; Zijdenbos, A.P.; Evans, A.C. A nonparametric method for automatic correction of intensity nonuniformity in mri data. IEEE Trans. Med. Imaging 1998, 17, 87–97. [Google Scholar] [CrossRef]
- Nyul, L.G.; Udupa, J.K. Standardizing the MR image intensity scales: Making MR intensities have tissue specific meaning. Med. Imaging 2000 Image Disp. Vis. 2000, 3976, 496–504. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. Non-Local Means Denoising. Image Process. Line 2011, 1, 208–212. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histogram of Oriented Gradients for Human Detection. IEEE Trans. Ind. Informatics 2020, 16, 4714–4725. [Google Scholar] [CrossRef]
- Klaser, A.; Marszalek, M.; Schmid, C. A spatio-temporal descriptor based on 3D-gradients. In Proceedings of the BMVC 2008—Proceedings of the British Machine Vision Conference 2008, Leeds, UK, September 2008. [Google Scholar]
- Liu, Q.; Xiao, L.; Yang, J.; Wei, Z. CNN-Enhanced Graph Convolutional Network with Pixel- and Superpixel-Level Feature Fusion for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8657–8671. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Peng, Y.; Zheng, H.; Liang, P.; Zhang, L.; Zaman, F.; Wu, X.; Sonka, M.; Chen, D.Z. KCB-Net: A 3D knee cartilage and bone segmentation network via sparse annotation. Med. Image Anal. 2022, 82, 102574. [Google Scholar] [CrossRef] [PubMed]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Schneider, E.; NessAiver, M.; White, D.; Purdy, D.; Martin, L.; Fanella, L.; Davis, D.; Vignone, M.; Wu, G.; Gullapalli, R. The osteoarthritis initiative (OAI) magnetic resonance imaging quality assurance methods and results. Osteoarthr. Cartil. 2008, 16, 994–1004. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
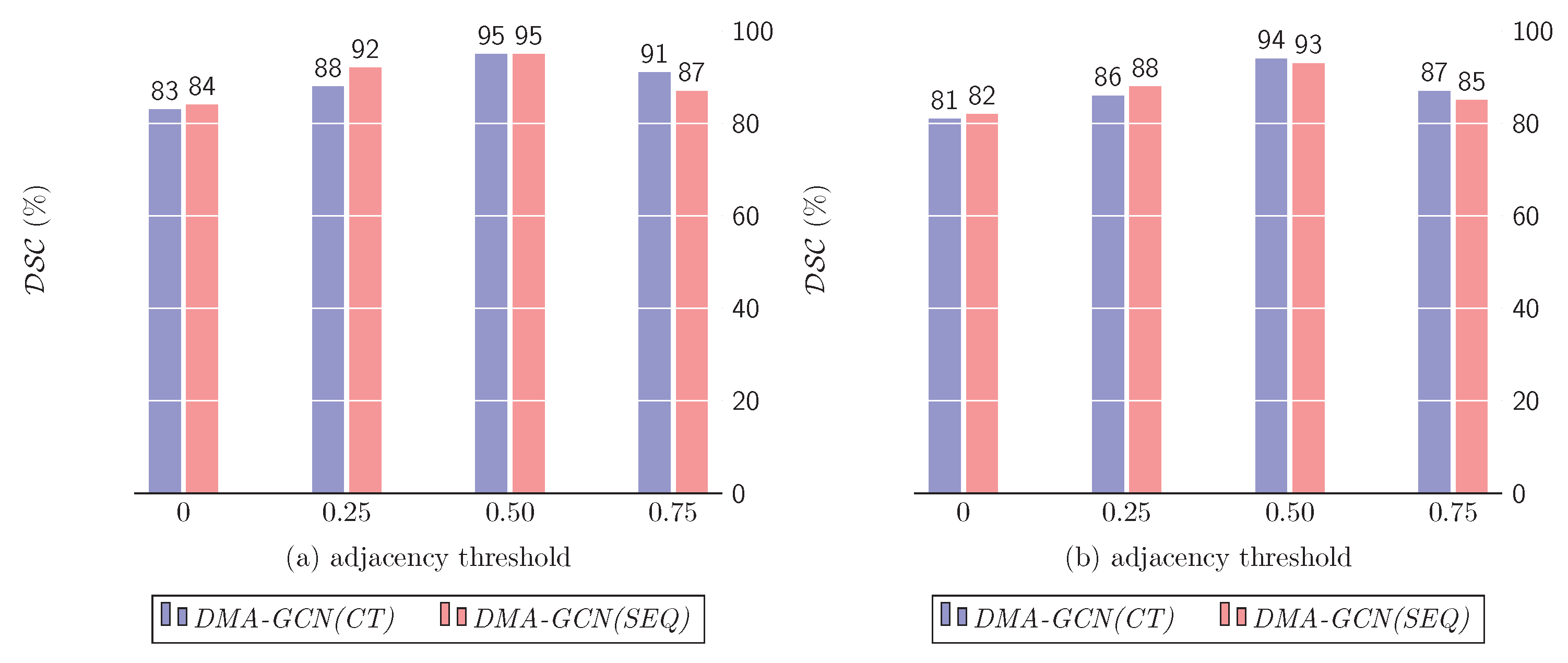{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Femoral Cartilage | Tibial Cartilage | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Module | CT | SEQ | Recall | Precision | Recall | Precision | ||||||
| GAT-GCN | ✓ | |||||||||||
| ✓ | ||||||||||||
| GAT-SAGE | ✓ | |||||||||||
| ✓ | ||||||||||||
| GAT-SAINT | ✓ | |||||||||||
| ✓ | ||||||||||||
| GAT-ClustGCN | ✓ | |||||||||||
| ✓ | ||||||||||||
| Femoral Cartilage | Tibial Cartilage | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Module | SEQ | CT | Recall | Precision | Recall | Precision | ||||||
| Inductive | ✓ | |||||||||||
| ✓ | ||||||||||||
| Transductive | ✓ | |||||||||||
| ✓ | ||||||||||||
| Femoral Cartilage | Tibial Cartilage | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Recall | Precision | Recall | Precision | |||||||||
| PBSC | |||||||||||||
| PBNLM | |||||||||||||
| HyLP | |||||||||||||
| SegNet | |||||||||||||
| DenseVoxNet | |||||||||||||
| VoxResNet | |||||||||||||
| KCB-Net | |||||||||||||
| CAN3D | |||||||||||||
| PointNet | |||||||||||||
| GCN | |||||||||||||
| SGC | |||||||||||||
| ClusterGCN | |||||||||||||
| GraphSAINT | |||||||||||||
| GraphSAGE | |||||||||||||
| GAT | |||||||||||||
| MGCN | |||||||||||||
| DMA-GCN (SEQ) | |||||||||||||
| DMA-GCN (CT) | |||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chadoulos, C.; Tsaopoulos, D.; Symeonidis, A.; Moustakidis, S.; Theocharis, J. Dense Multi-Scale Graph Convolutional Network for Knee Joint Cartilage Segmentation. Bioengineering 2024, 11, 278. https://doi.org/10.3390/bioengineering11030278
Chadoulos C, Tsaopoulos D, Symeonidis A, Moustakidis S, Theocharis J. Dense Multi-Scale Graph Convolutional Network for Knee Joint Cartilage Segmentation. Bioengineering. 2024; 11(3):278. https://doi.org/10.3390/bioengineering11030278
Chicago/Turabian StyleChadoulos, Christos, Dimitrios Tsaopoulos, Andreas Symeonidis, Serafeim Moustakidis, and John Theocharis. 2024. "Dense Multi-Scale Graph Convolutional Network for Knee Joint Cartilage Segmentation" Bioengineering 11, no. 3: 278. https://doi.org/10.3390/bioengineering11030278