

Comparing the Robustness of ResNet, Swin-Transformer, and MLP-Mixer under Unique Distribution Shifts in Fundus Images
Abstract
:1. Introduction
1.1. Background
1.2. Related Works
1.2.1. Discrimination and Calibration Abilities of Deep Learning Models
1.2.2. Robustness of Deep Learning Models
1.2.3. Distribution Shift of Fundus Image
1.3. Objective
2. Materials and Methods
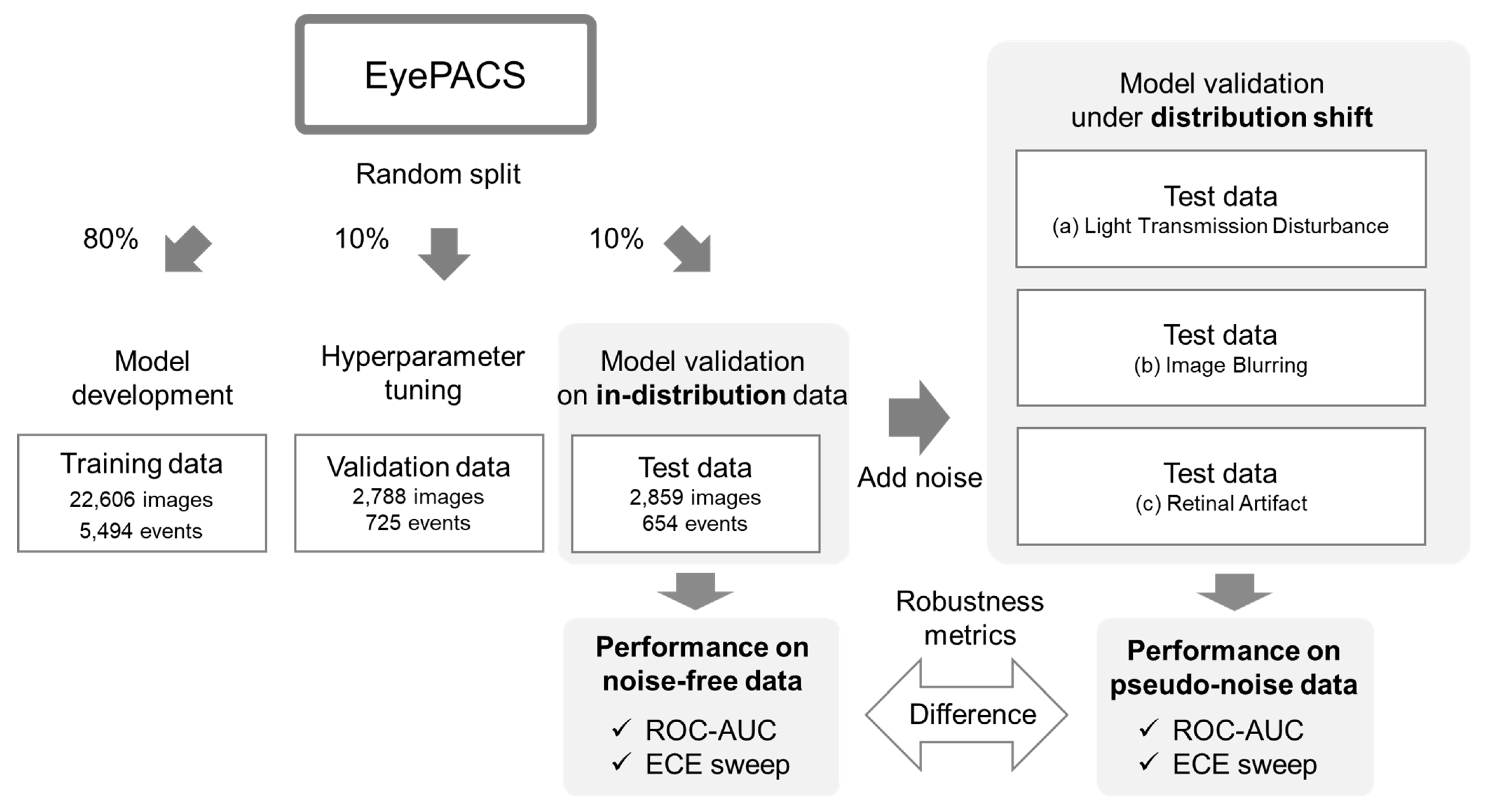
2.1. Dataset
2.2. Outcome
2.3. Experimental Pipeline
2.4. Preprocessing
2.5. Models
- ResNet [29] is a widely used model with a convolutional structure that incorporates residual connections. We used three ResNets with different model sizes: ResNet-50, ResNet-101, and ResNet-152.
- MLP-Mixer [32] is a model implemented using only a multilayer perceptron without a convolutional structure or attention mechanism. We used two MLP-Mixers with different model sizes: Base and Large.
2.6. Evaluation
Calibration Metrics
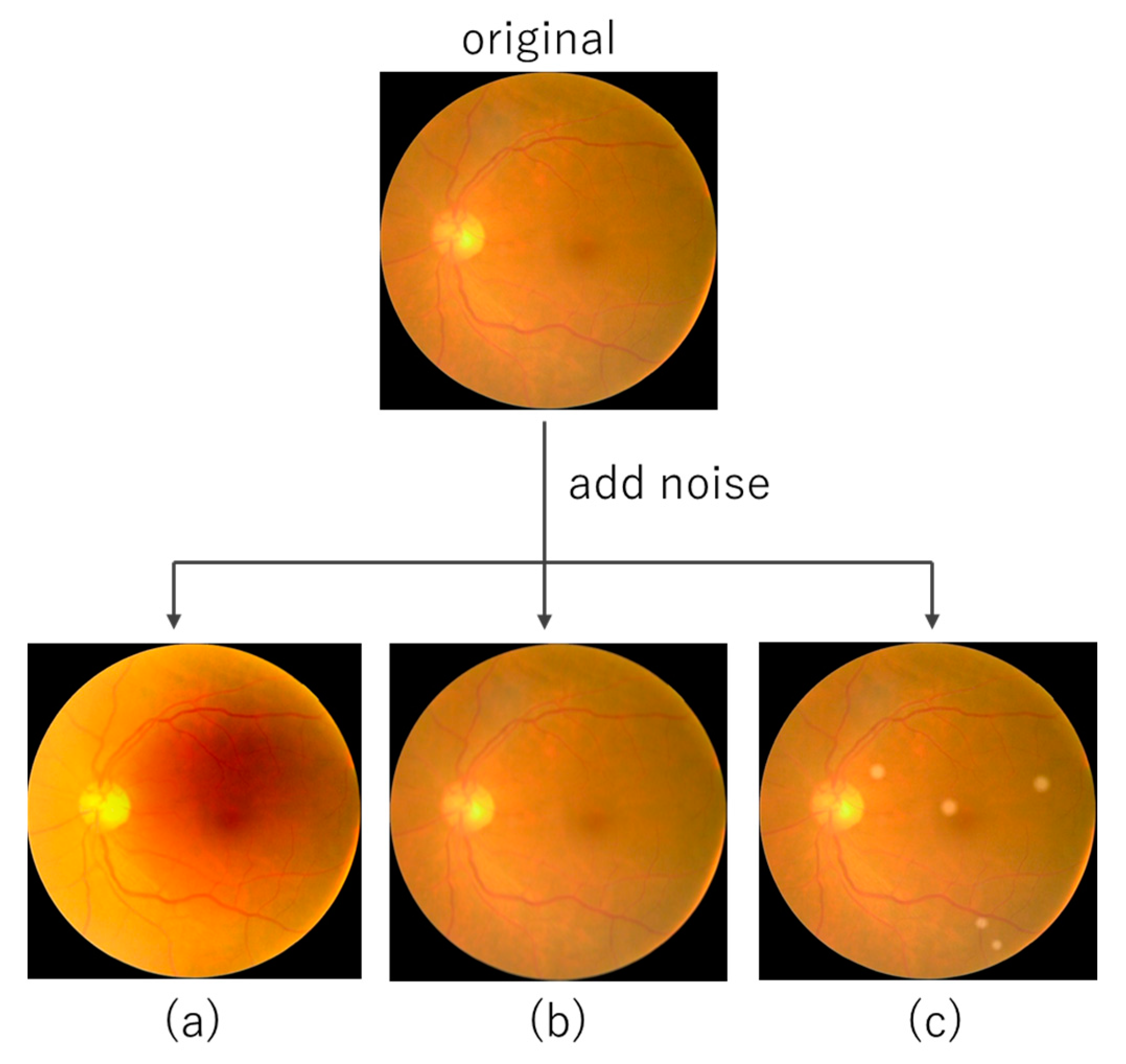
2.7. Distribution Shift of Fundus Image
2.7.1. Light Transmission Disturbance
2.7.2. Image Blurring
2.7.3. Retinal Artifact
3. Results
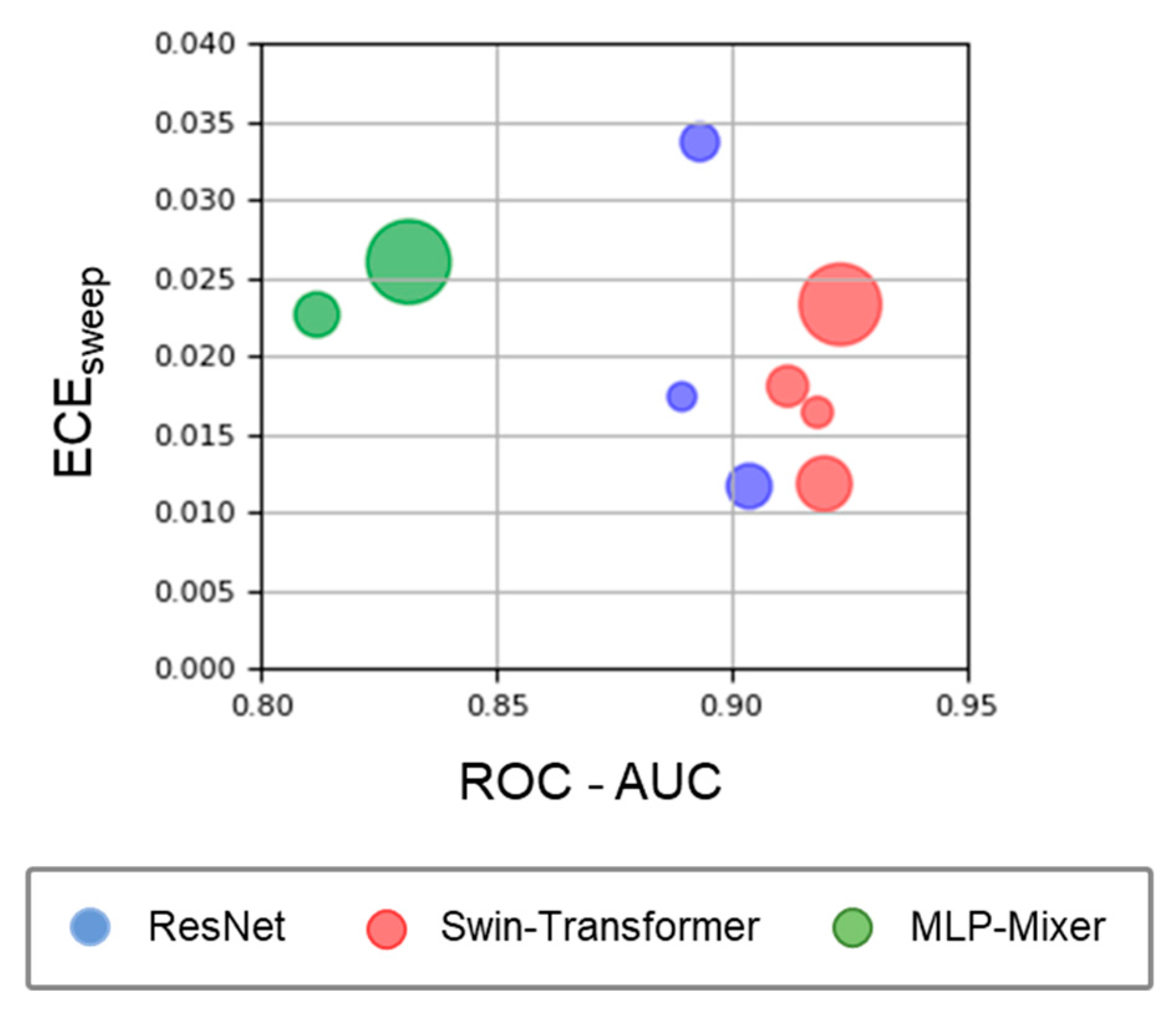
3.1. Model Performance on In-Distribution Data
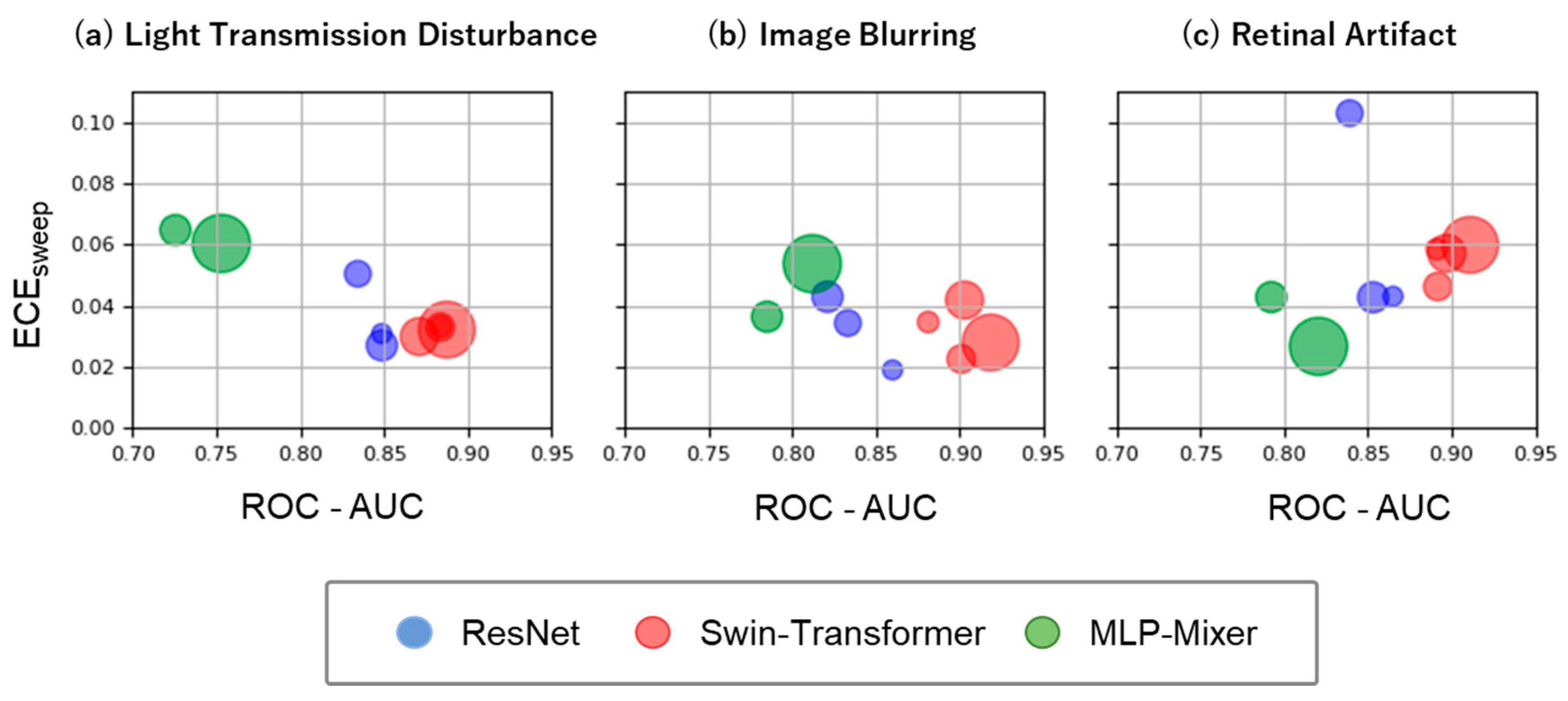
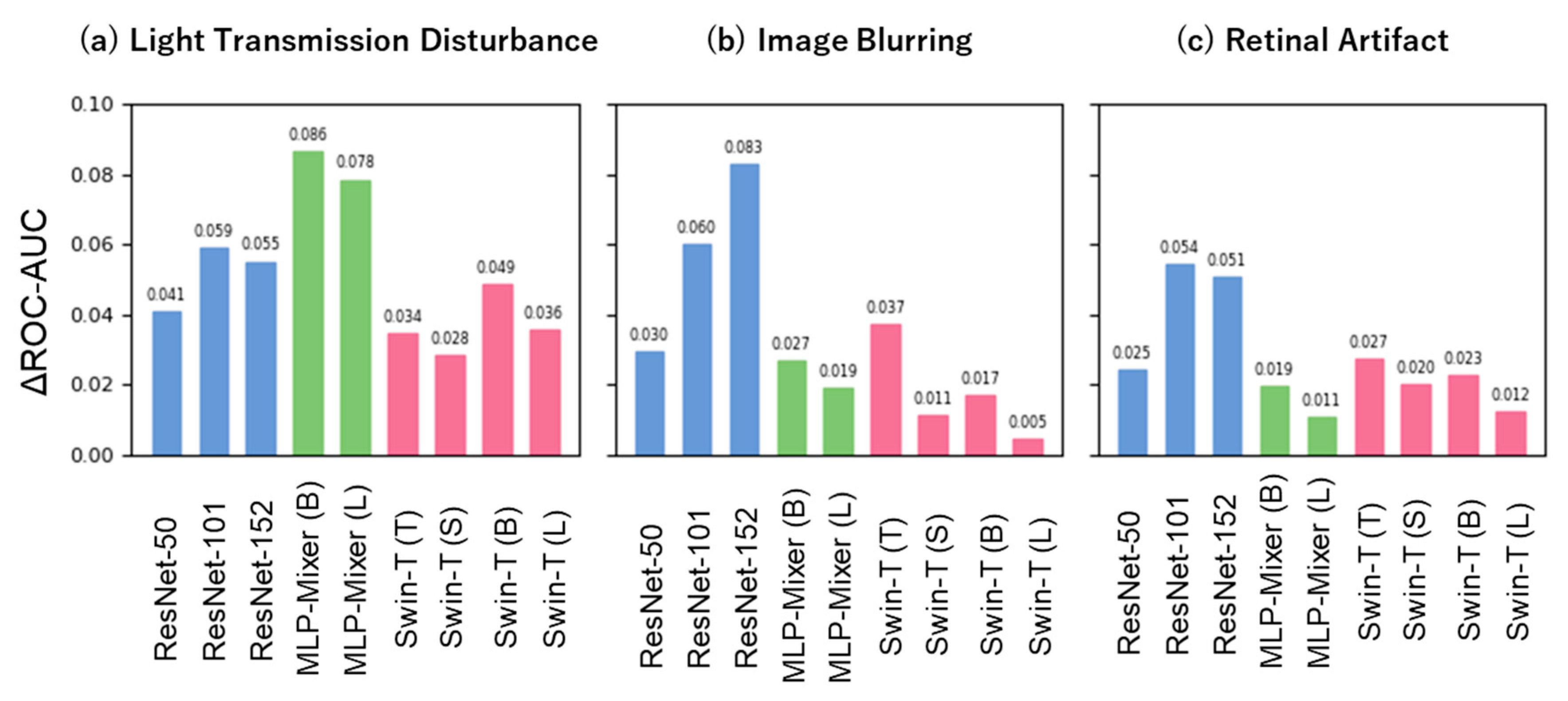
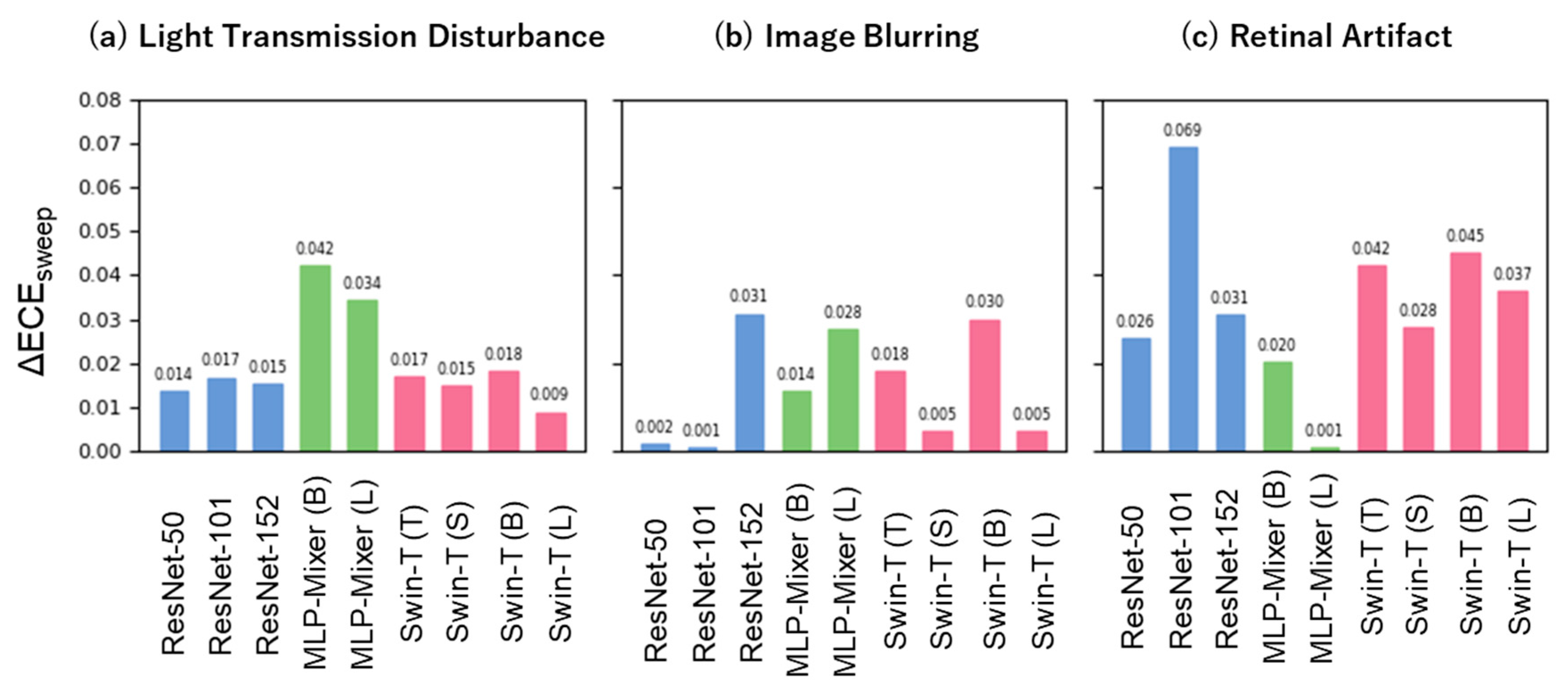
3.2. Model Performance under Distribution Shift
3.3. Difference in Model Performance between Noise-Free and Pseudo-Noise Data
4. Discussion
4.1. Model Discrimination and Calibration Ability
4.2. Model Robustness
4.3. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- International Diabetes Federation. IDF Diabetes Atlas, 10th ed.; 2021. Available online: https://www.ncbi.nlm.nih.gov/books/NBK581934/ (accessed on 22 October 2023).
- Gargeya, R.; Leng, T. Automated Identification of Diabetic Retinopathy Using Deep Learning. Ophthalmology 2017, 124, 962–969. [Google Scholar] [CrossRef] [PubMed]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Alyoubi, W.L.; Abulkhair, M.F.; Shalash, W.M. Diabetic retinopathy fundus image classification and lesions localization system using deep learning. Sensors 2021, 21, 3704. [Google Scholar] [CrossRef] [PubMed]
- Pires, R.; Avila, S.; Wainer, J.; Valle, E.; Abramoff, M.D.; Rocha, A. A data-driven approach to referable diabetic retinopathy detection. Artif. Intell. Med. 2019, 96, 93–106. [Google Scholar] [CrossRef] [PubMed]
- Hein, M.; Andriushchenko, M.; Bitterwolf, J. Why ReLU networks yield high-confidence predictions far away from the training data and how to mitigate the problem. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 41–50. [Google Scholar] [CrossRef]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, Q.K. On calibration of modern neural networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Taori, R.; Dave, A.; Shankar, V.; Carlini, N.; Recht, B.; Schmidt, L. Measuring robustness to natural distribution shifts in image classification. In Proceedings of the Neural Information Processing Systems, Virtual-Only, 6–12 December 2020. [Google Scholar]
- Recht, B.; Roelofs, R.; Schmidt, L.; Shankar, V.; ImageNet, D. Classifiers generalize to ImageNet? In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Minderer, M.; Djolonga, J.; Romijnders, R.; Hubis, F.; Zhai, X.; Houlsby, N.; Tran, D.; Lucic, M. Revisiting the calibration of modern neural networks. In Proceedings of the Neural Information Processing Systems, Virtual-Only, 6–14 December 2021. [Google Scholar]
- Ovadia, Y.; Fertig, E.; Ren, J.; Nado, Z.; Sculley, D.; Nowozin, S.; Dillon, J.; Lakshminarayanan, B.; Snoek, J. Can you trust your Model’s uncertainty? Evaluating predictive uncertainty under dataset shift. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wang, D.; Feng, L.; Zhang, M.L. Rethinking calibration of deep neural networks: Do not be afraid of overconfidence. In Proceedings of the Neural Information Processing Systems, Virtual-Only, 6–14 December 2021. [Google Scholar]
- Krishnan, R.; Tickoo, O. Improving model calibration with accuracy versus uncertainty optimization. In Proceedings of the Neural Information Processing Systems, Virtual-Only, 6–12 December 2020. [Google Scholar]
- Karandikar, A.; Cain, N.; Tran, D.; Lakshminarayanan, B.; Shlens, J.; Mozer, M.C.; Roelofs, B. Soft calibration objectives for neural networks. In Proceedings of the Neural Information Processing Systems, Virtual-Only, 6–14 December 2021. [Google Scholar]
- Mukhoti, J.; Kulharia, V.; Sanyal, A.; Golodetz, S.; Torr, P.; Dokania, P. Calibrating deep neural networks using focal loss. In Proceedings of the Neural Information Processing Systems, Virtual-Only, 6–12 December 2020. [Google Scholar]
- Pinto, F.; Torr, P.; Dokania, P. An impartial take to the CNN vs transformer robustness contest. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Paul, S.; Chen, P. Vision transformers are robust learners. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2022; Volume 36, pp. 2071–2081. [Google Scholar] [CrossRef]
- Bhojanapalli, S.; Chakrabarti, A.; Glasner, D.; Li, D.; Unterthiner, T.; Veit, A. Understanding robustness of transformers for image classification. In Proceedings of the International Conference on Computer Vision, Virtual-Only, 11–17 October 2021; pp. 10211–10221. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, M.; Zhang, S.; Jin, D.; Zhou, Q.; Cai, Z.; Zhao, H.; Liu, X.; Liu, Z. Delving deep into the generalization of vision transformers under distribution shifts. In Proceedings of the Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 7267–7276. [Google Scholar] [CrossRef]
- Naseer, M.; Ranasinghe, K.; Khan, S.; Hayat, M.; Khan, F.; Yang, M. Intriguing properties of vision transformers. In Proceedings of the Neural Information Processing Systems, Virtual-Only, 6–14 December 2021. [Google Scholar]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Morrison, K.; Gilby, B.; Lipchak, C.; Mattioli, A.; Kovashka, A. Exploring corruption robustness: Inductive biases in vision transformers and MLP-mixers. In Proceedings of the International Conference on Machine Learning, Virtual-Only, 18–24 July 2021. [Google Scholar]
- Hendrycks, D.; Dietterich, T. Benchmarking neural network robustness to common corruptions and perturbations. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Cuadros, J.; Bresnick, G. EyePACS: An adaptable telemedicine system for diabetic retinopathy screening. J. Diabetes Sci. Technol. 2009, 3, 509–516. [Google Scholar] [CrossRef]
- Ghanchi, F.; Bailey, C.; Chakravarthy, U.; Cohen, S.; Dodson, P.; Gibson, J.; Menon, G.; Muqit, M.; Pilling, R.; Olson, J.; et al. Diabetic Retinopathy Guidelines. 2012. Available online: https://www.rcophth.ac.uk/wp-content/uploads/2021/08/2012-SCI-267-Diabetic-Retinopathy-Guidelines-December-2012.pdf (accessed on 22 October 2023).
- Shen, Z.; Fu, H.; Shen, J.; Shao, L. Modeling and enhancing low-quality retinal fundus images. IEEE Trans. Med. Imaging 2021, 40, 996–1006. [Google Scholar] [CrossRef] [PubMed]
- Ratthachat, C. APTOS: Eye Preprocessing in Diabetic Retinopathy (Kaggke Report). 2019. Available online: https://www.kaggle.com/code/ratthachat/aptos-eye-preprocessing-in-diabetic-retinopathy/comments (accessed on 22 October 2023).
- Graham, B. Kaggle Diabetic Retinopathy Detection Competition Report. 2015. Available online: https://www.kaggle.com/c/diabetic-retinopathy-detection (accessed on 22 October 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the International Conference on Computer Vision, Virtual-Only, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Virtual-Only, 3–7 May 2021. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An all-MLP architecture for vision. In Proceedings of the Neural Information Processing Systems, Virtual-Only, 6–14 December 2021. [Google Scholar]
- Naeini, M.P.; Cooper, G.; Hauskrecht, M. Obtaining Well Calibrated Probabilities Using Bayesian Binning. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; p. 29. [Google Scholar] [CrossRef]
- Roelofs, R.; Cain, N.; Shlens, J.; Mozer, M.C. Mitigating bias in calibration error estimation. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual-Only, 28–30 March 2022. [Google Scholar]
- Nixon, J.; Dusenberry, M.W.; Zhang, L.; Jerfel, G.; Tran, D. Measuring calibration in deep learning. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 16–20 June 2019. [Google Scholar]
- Ma, X.; Niu, Y.; Gu, L.; Wang, Y.; Zhao, Y.; Bailey, J.; Lu, F. Understanding adversarial attacks on deep learning based medical image analysis systems. Pattern Recognit. 2021, 110, 107332. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Model Size (Parameters) |
|---|---|
| ResNet-50 | 23.5 M |
| ResNet-101 | 42.5 M |
| ResNet-152 | 58.1 M |
| Swin-Transformer (Tiny) | 27.5 M |
| Swin-Transformer (Small) | 48.8 M |
| Swin-Transformer (Base) | 86.7 M |
| Swin-Transformer (Large) | 195 M |
| MLP-Mixer (Base) | 59.1 M |
| MLP-Mixer (Large) | 207 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ishihara, K.; Matsumoto, K. Comparing the Robustness of ResNet, Swin-Transformer, and MLP-Mixer under Unique Distribution Shifts in Fundus Images. Bioengineering 2023, 10, 1383. https://doi.org/10.3390/bioengineering10121383
Ishihara K, Matsumoto K. Comparing the Robustness of ResNet, Swin-Transformer, and MLP-Mixer under Unique Distribution Shifts in Fundus Images. Bioengineering. 2023; 10(12):1383. https://doi.org/10.3390/bioengineering10121383
Chicago/Turabian StyleIshihara, Kazuaki, and Koutarou Matsumoto. 2023. "Comparing the Robustness of ResNet, Swin-Transformer, and MLP-Mixer under Unique Distribution Shifts in Fundus Images" Bioengineering 10, no. 12: 1383. https://doi.org/10.3390/bioengineering10121383