
COVID-19 Detection and Diagnosis Model on CT Scans Based on AI Techniques

Abstract
:
1. Introduction
2. Materials and Methods
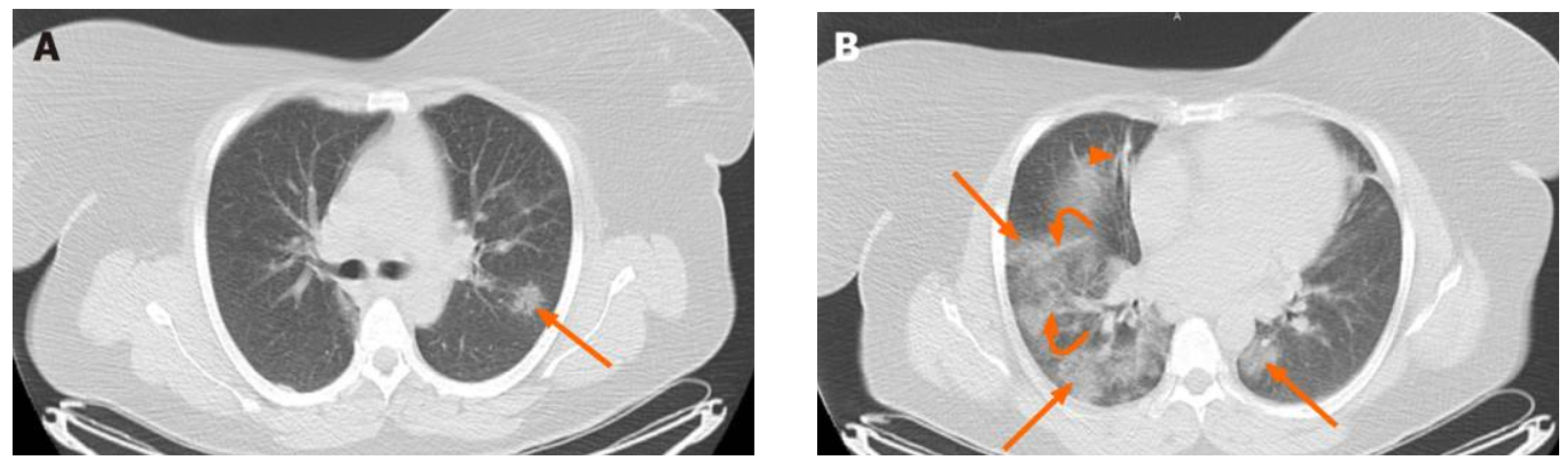
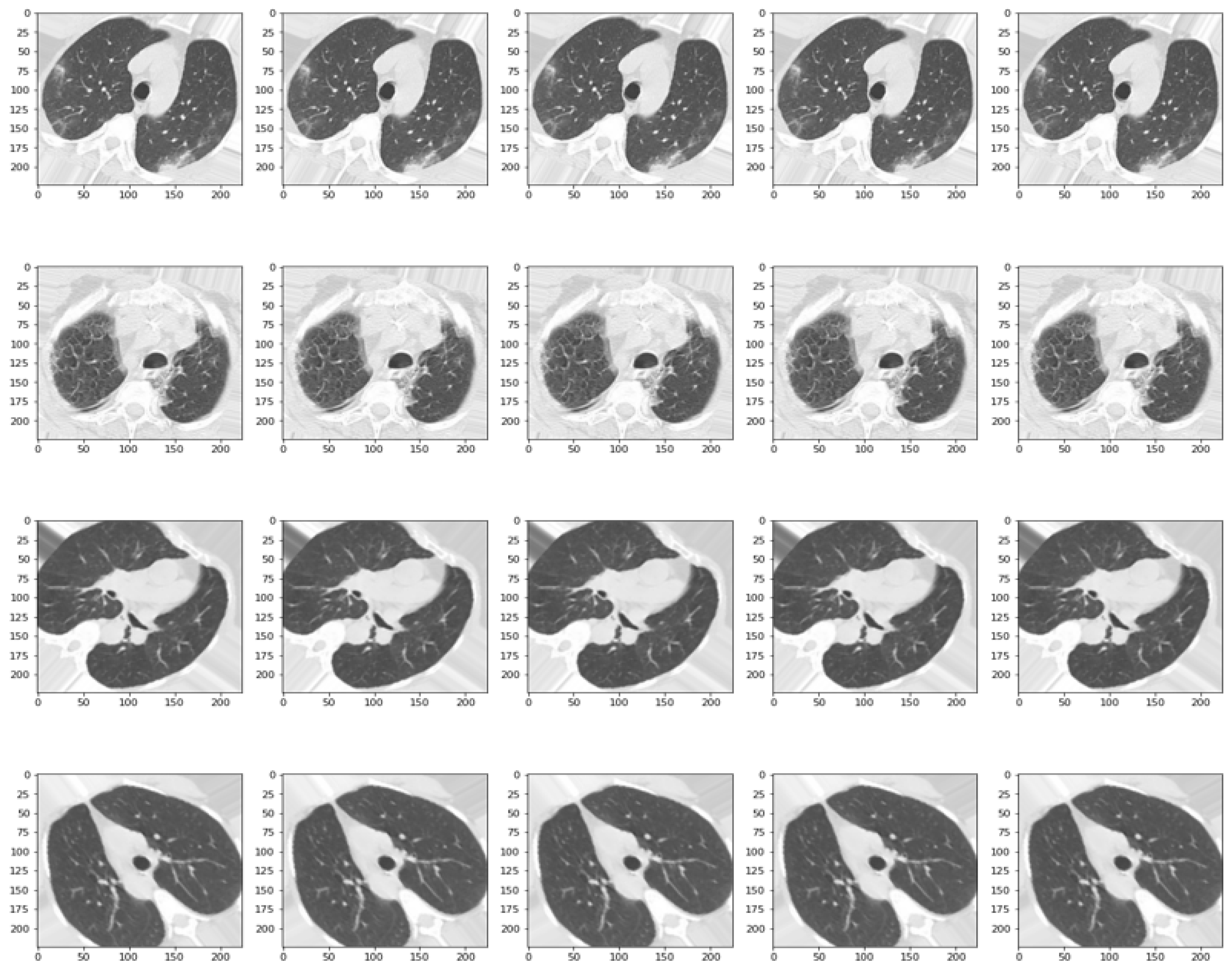
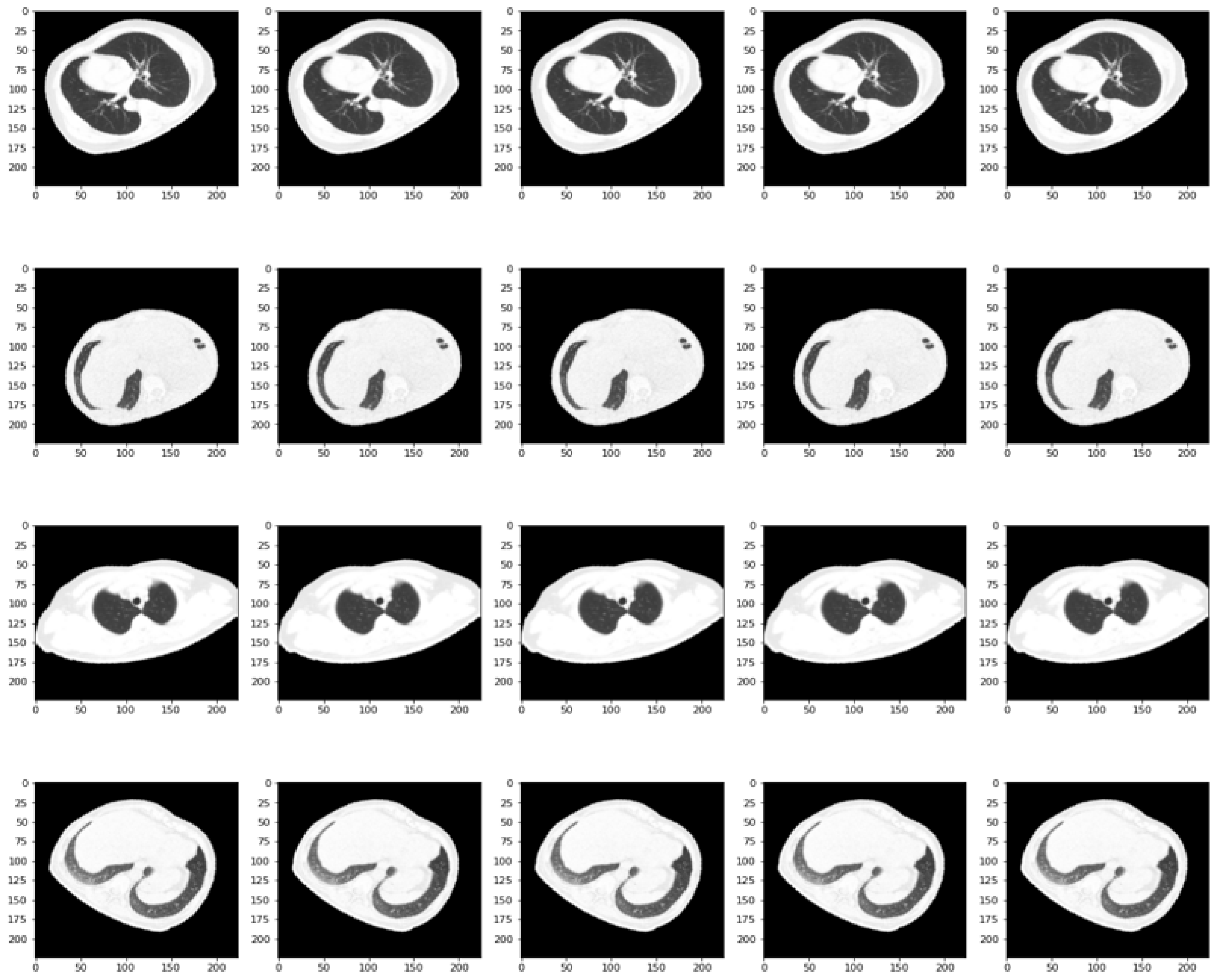
2.1. Data Collection and Pre-Processing
- CT-COV19 [22]—via IRB approval, CT-COV19 is a dataset of approximately 13,000 non-contrast lung CT scans in which chest cavity volume reconstructions are set at a slice thickness between 0.3 and 1 mm;
- COVID-19-CT [24]—all CT scans are classified into novel coronavirus pneumonia (NCP) due to the SARS-CoV-2 virus, common pneumonia, and normal controls being available globally to help clinicians and researchers fight the pandemic, where COVID-19 is making its presence felt;
- COVID-CT [25]—contains 349 CT samples belonging to 216 patients diagnosed positive for the COVID-19 virus and 397 CT images, with a negative diagnosis for COVID-19 having origins in bioRxiv and medRxiv servers;
- SARS-CoV-2 Ct-Scan-Dataset [26]—contains 1252 positive CT scans for SARS-CoV-2 (COVID-19) infection and 1230 CT scans for patients not infected with SARS-CoV-2, totaling 2482 samples collected from real patients in hospitals in Sao Paulo, Brazil.
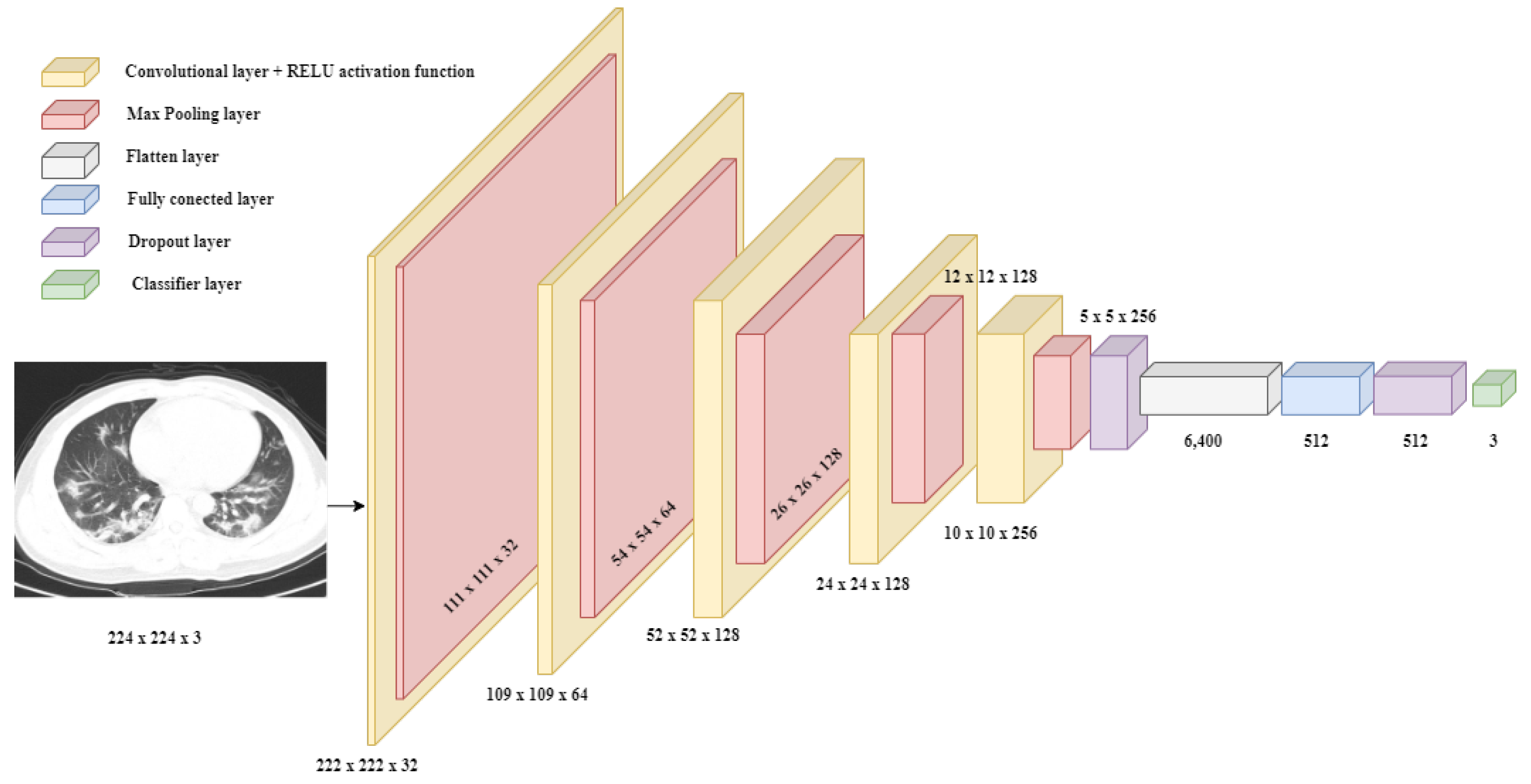
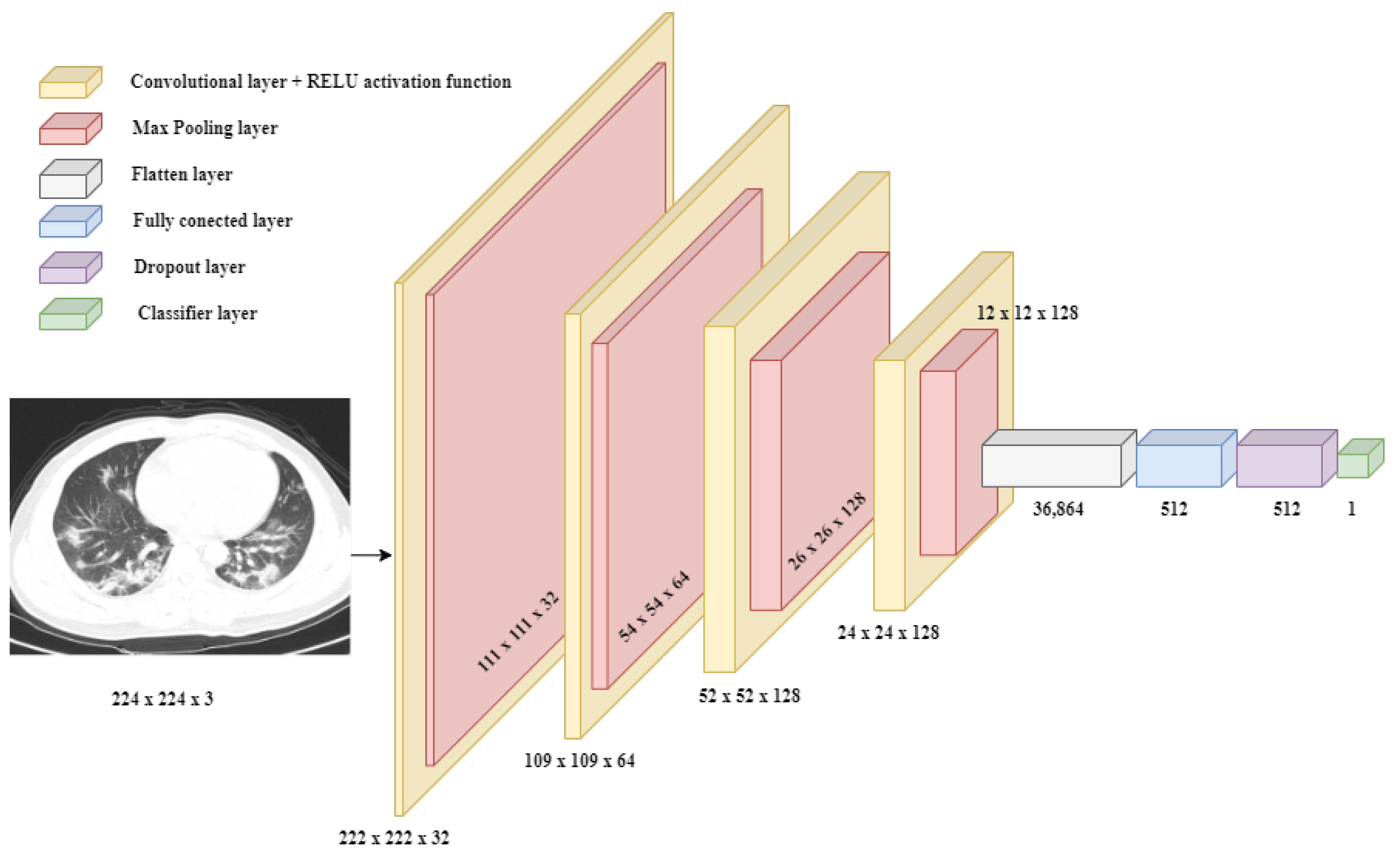
2.2. Convolutional Neural Network Conception Methodology
2.2.1. Binary Classification Approach
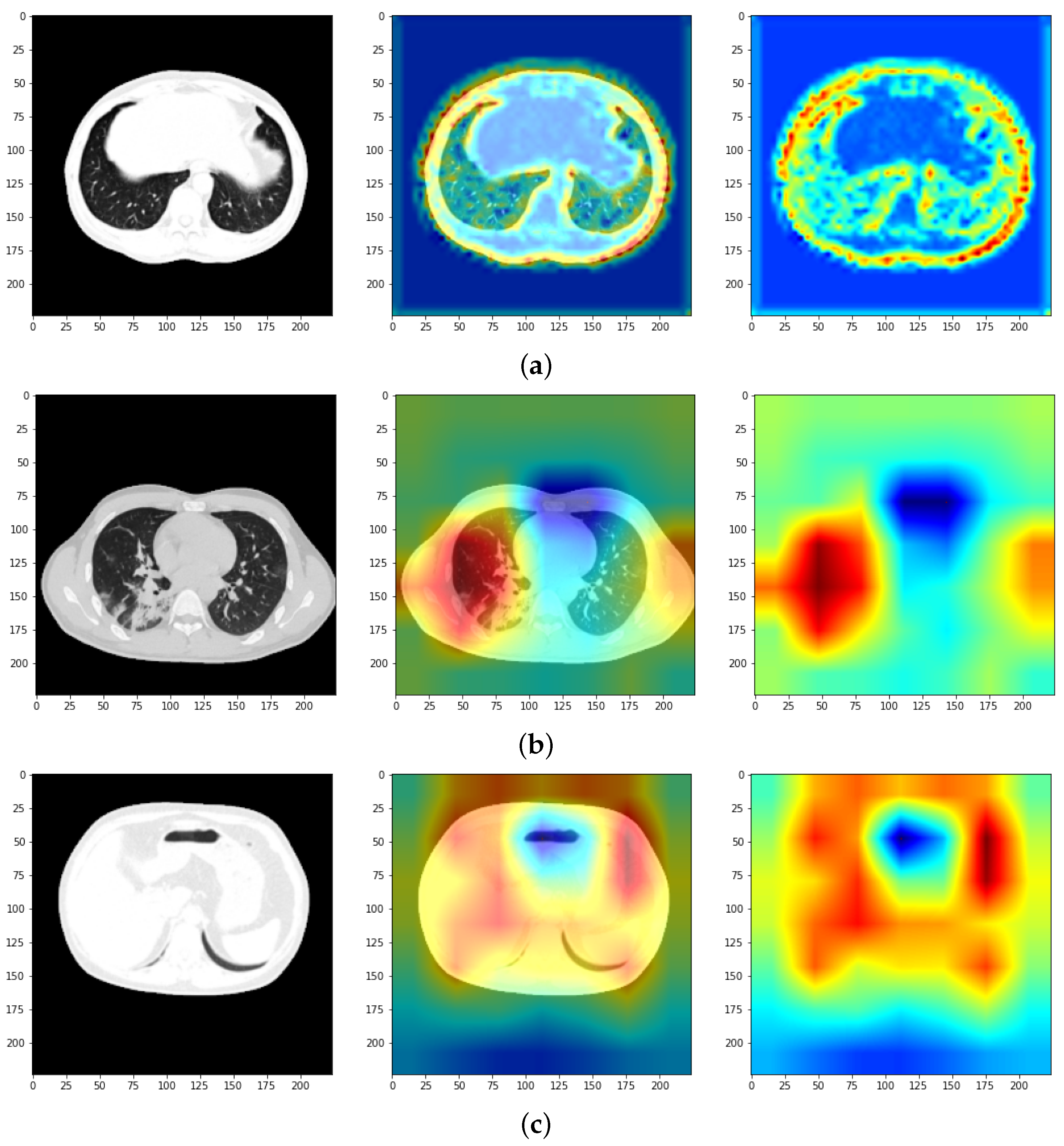
2.2.2. Multi-Class Classification Approach
2.2.3. Transfer Learning Approach
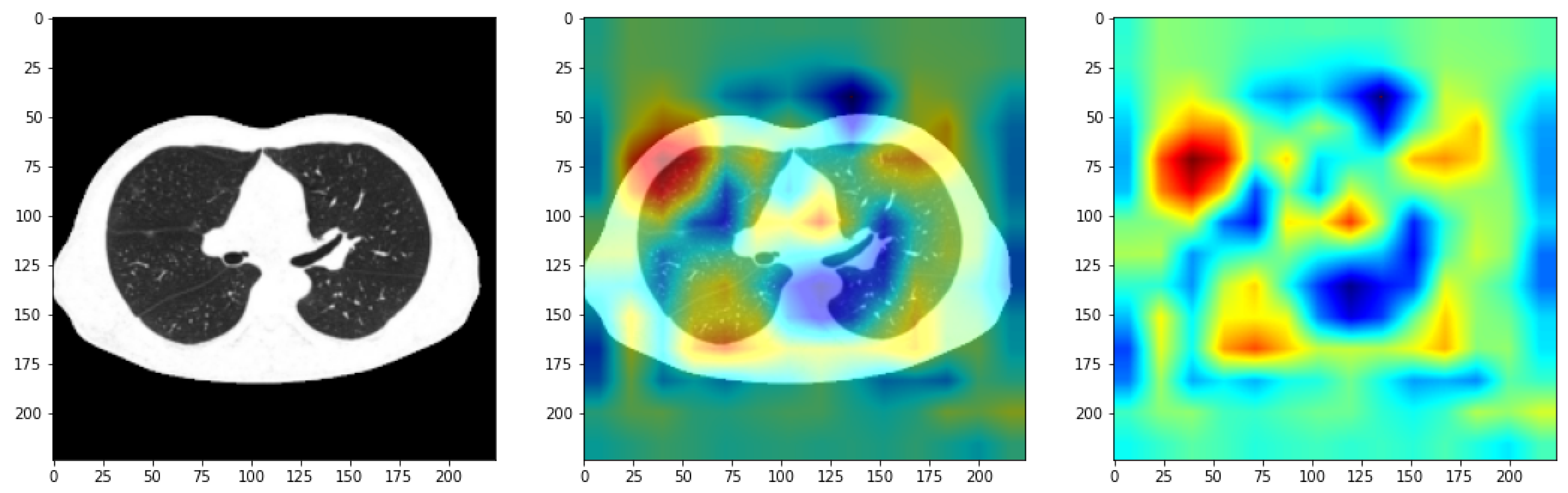
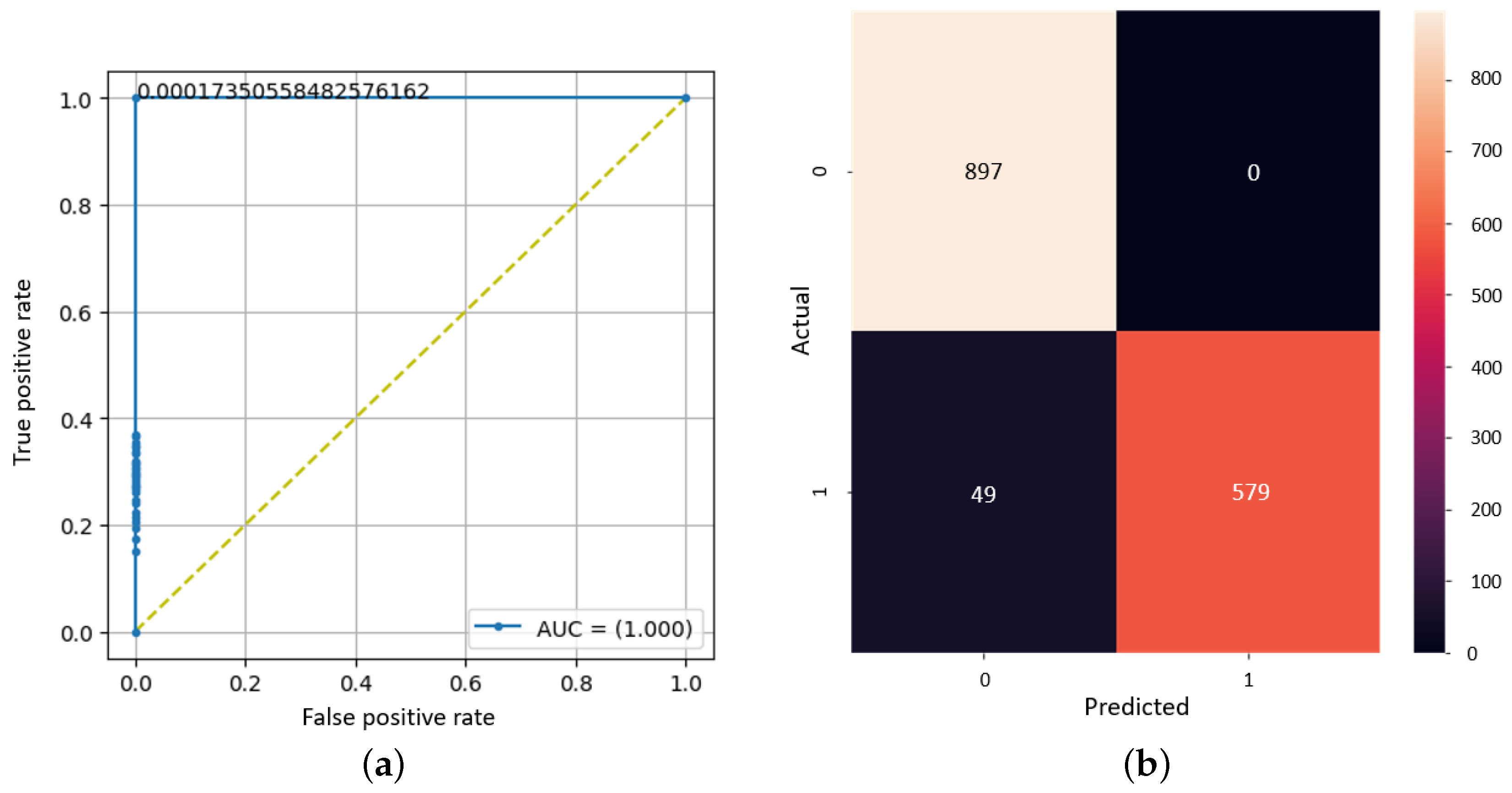
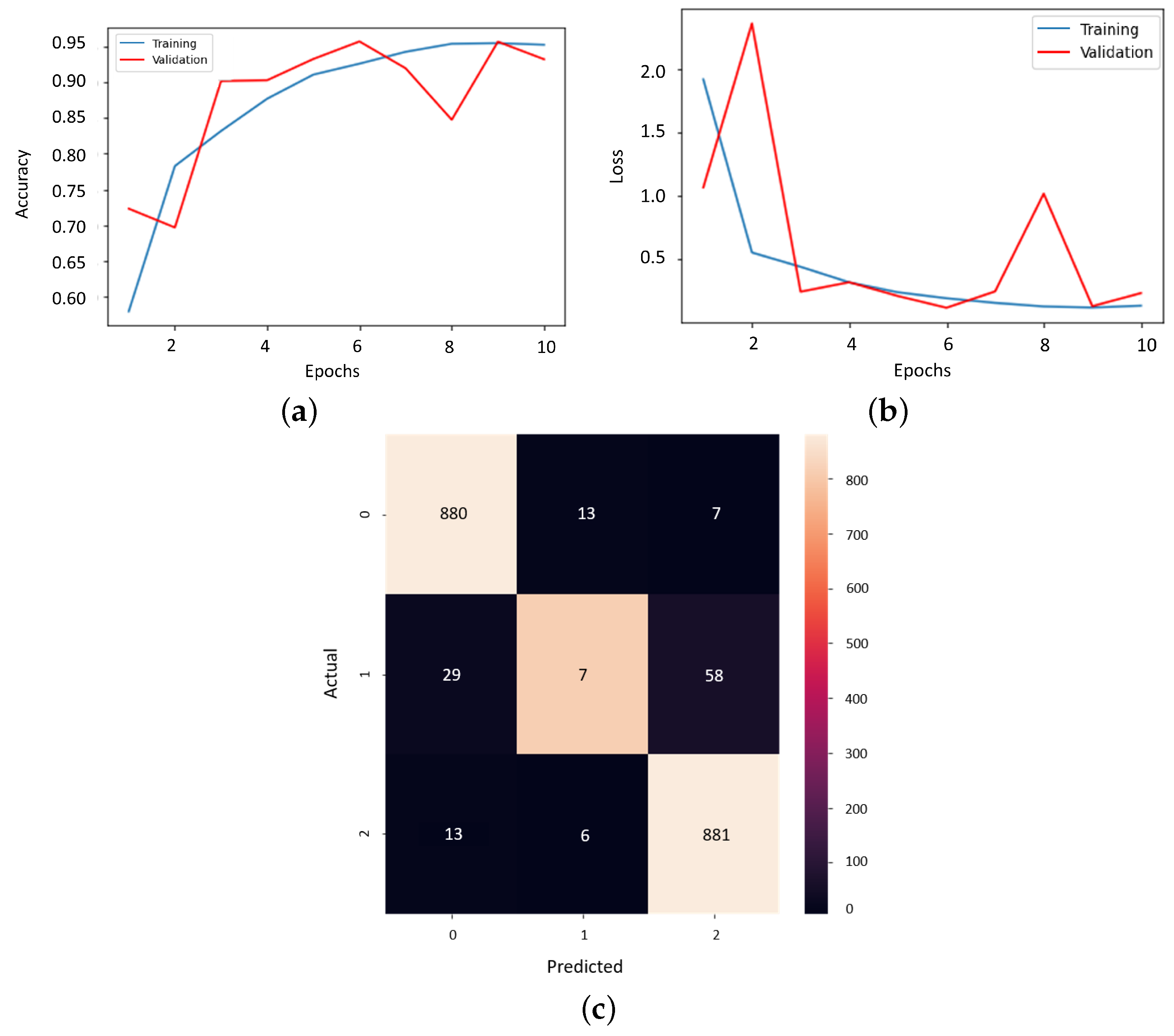
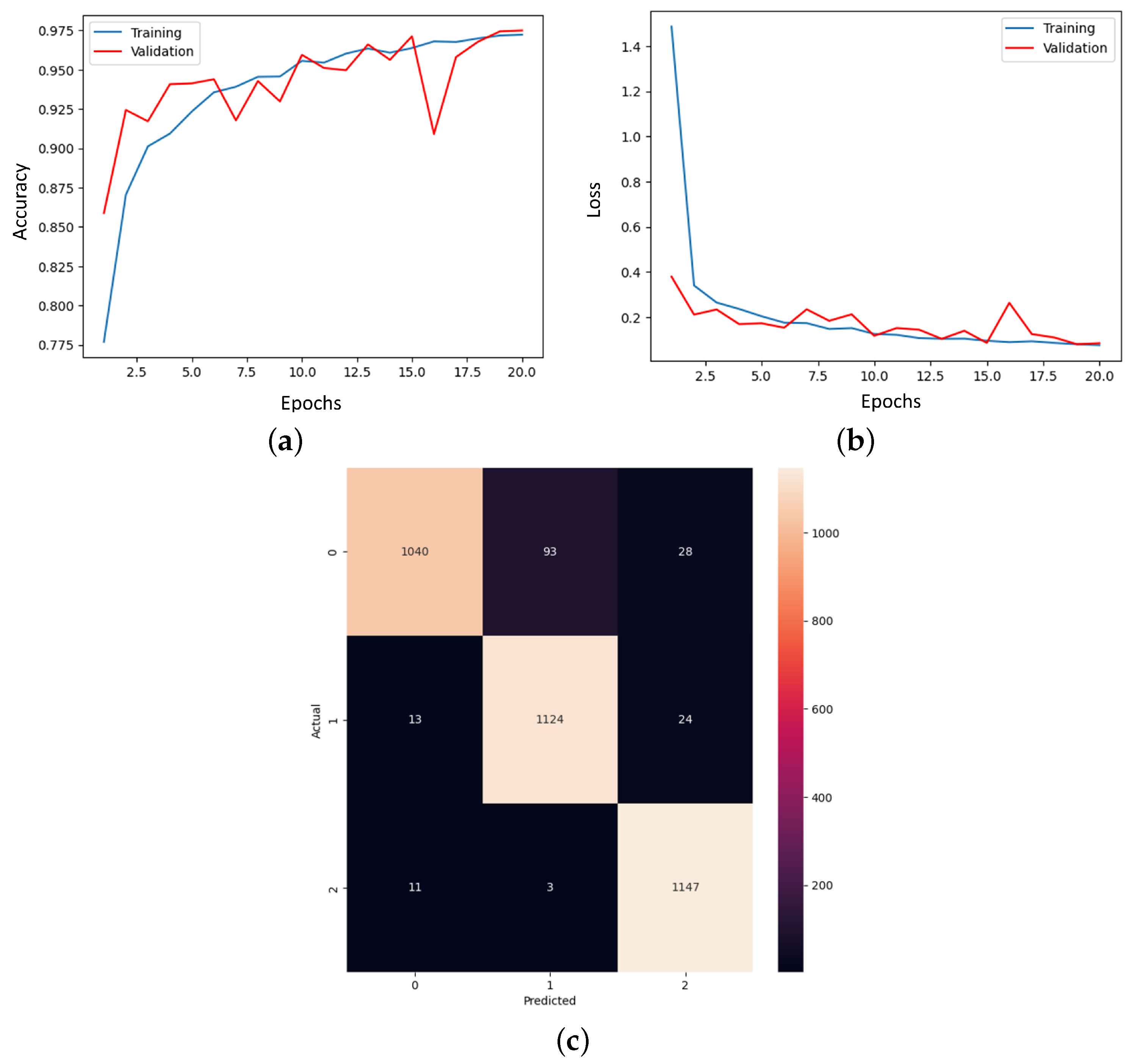
3. Results and Discussion
3.1. Binary CNN Model Outcomes
3.2. Multi-Class CNN Model Outcomes
3.3. Transfer Learning Model Outcomes
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Whitworth, J. COVID-19: A fast evolving pandemic. Trans. R. Soc. Trop. Med. Hyg. 2020, 114, 241. [Google Scholar] [CrossRef] [PubMed]
- McIntosh, K.; Dees, J.H.; Becker, W.B.; Kapikian, A.Z.; Chanock, R.M. Recovery in tracheal organ cultures of novel viruses from patients with respiratory disease. Proc. Natl. Acad. Sci. USA 1967, 57, 933–940. [Google Scholar] [CrossRef] [PubMed]
- Ludwig, S.; Zarbock, A.C. Coronaviruses and SARS-CoV-2: A brief overview. Anesth Analg 2020, in press. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Coronavirus Disease (COVID-19). 5 October 2020. Available online: https://www.who.int/health-topics/coronavirus (accessed on 22 August 2023).
- Wang, H.; Wei, R.; Rao, G.; Zhu, J.; Song, B. Characteristic CT findings distinguishing 2019 novel coronavirus disease (COVID-19) from influenza pneumonia. Eur. Radiol. 2020, 30, 4910–4917. [Google Scholar] [CrossRef]
- Ding, Q.; Lu, P.; Fan, Y.; Xia, Y.; Liu, M. The clinical characteristics of pneumonia patients coinfected with 2019 novel coronavirus and influenza virus in Wuhan, China. J. Med. Virol. 2020, 92, 1549–1555. [Google Scholar] [CrossRef] [PubMed]
- Nappi, F.; Avtaar Singh, S.S. SARS-CoV-2-Induced Myocarditis: A State-of-the-Art Review. Viruses 2023, 15, 916. [Google Scholar] [CrossRef] [PubMed]
- Kooraki, S.; Hosseiny, M.; Myers, L.; Gholamrezanezhad, A. Coronavirus (COVID-19) outbreak: What the department of radiology should know. J. Am. Coll. Radiol. 2020, 17, 447–451. [Google Scholar] [CrossRef]
- Eslambolchi, A.; Maliglig, A.; Gupta, A.; Gholamrezanezhad, A. COVID-19 or non-COVID viral pneumonia: How to differentiate based on the radiologic findings? World J. Radiol. 2020, 12, 289. [Google Scholar] [CrossRef]
- Pan, Y.; Guan, H.; Zhou, S.; Wang, Y.; Li, Q.; Zhu, T.; Hu, Q.; Xia, L. Initial CT findings and temporal changes in patients with the novel coronavirus pneumonia (2019-nCoV): A study of 63 patients in Wuhan, China. Eur. Radiol. 2020, 30, 3306–3309. [Google Scholar] [CrossRef]
- Han, R.; Huang, L.; Jiang, H.; Dong, J.; Peng, H.; Zhang, D. Early clinical and CT manifestations of coronavirus disease 2019 (COVID-19) pneumonia. AJR Am. J. Roentgenol. 2020, 215, 338–343. [Google Scholar] [CrossRef]
- Yang, W.; Sirajuddin, A.; Zhang, X.; Liu, G.; Teng, Z.; Zhao, S.; Lu, M. The role of imaging in 2019 novel coronavirus pneumonia (COVID-19). Eur. Radiol. 2020, 30, 4874–4882. [Google Scholar] [CrossRef] [PubMed]
- Malik, H.; Anees, T.; Din, M.; Naeem, A. CDC_Net: Multi-classification convolutional neural network model for detection of COVID-19, pneumothorax, pneumonia, lung Cancer, and tuberculosis using chest X-rays. Multimed. Tools Appl. 2023, 82, 13855–13880. [Google Scholar] [CrossRef] [PubMed]
- He, J.L.; Luo, L.; Luo, Z.D.; Lyu, J.X.; Ng, M.Y.; Shen, X.P.; Wen, Z. Diagnostic performance between CT and initial real-time RT-PCR for clinically suspected 2019 coronavirus disease (COVID-19) patients outside Wuhan, China. Respir. Med. 2020, 168, 105980. [Google Scholar] [CrossRef]
- Al-Shaibari, K.S.A.; Mousa, H.A.L.; Alqumber, M.A.A.; Alqfail, K.A.; Mohammed, A.; Bzeizi, K. The Diagnostic Performance of Various Clinical Specimens for the Detection of COVID-19: A Meta-Analysis of RT-PCR Studies. Diagnostics 2023, 13, 3057. [Google Scholar] [CrossRef] [PubMed]
- Rong, G.; Zheng, Y.; Chen, Y.; Zhang, Y.; Zhu, P.; Sawan, M. COVID-19 diagnostic methods and detection techniques. Encycl. Sens. Biosens. 2023, 17–32. [Google Scholar] [CrossRef]
- Sailunaz, K.; Özyer, T.; Rokne, J.; Alhajj, R. A survey of machine learning-based methods for COVID-19 medical image analysis. Med. Biol. Eng. Comput. 2023, 61, 1257–1297. [Google Scholar] [CrossRef]
- Santosh, K.; GhoshRoy, D.; Nakarmi, S. A systematic review on deep structured learning for COVID-19 screening using chest CT from 2020 to 2022. Healthcare 2023, 11, 2388. [Google Scholar] [CrossRef]
- Ker, J.; Wang, L.; Rao, J.; Lim, T. Deep learning applications in medical image analysis. IEEE Access 2017, 6, 9375–9389. [Google Scholar] [CrossRef]
- Aslani, S.; Jacob, J. Utilisation of deep learning for COVID-19 diagnosis. Clin. Radiol. 2023, 78, 150–157. [Google Scholar] [CrossRef]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.F.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation. Med. Image Anal. 2017, 36, 61–78. [Google Scholar] [CrossRef]
- Dialameh, M.; Hamzeh, A.; Rahmani, H.; Radmard, A.R.; Dialameh, S. Proposing a novel deep network for detecting COVID-19 based on chest images. Sci. Rep. 2022, 12, 3116. [Google Scholar] [CrossRef] [PubMed]
- Moore, C.L.; Broder, J.; Gunn, M.L.; Bhargavan-Chatfield, M.; Cody, D.; Cullison, K.; Daniels, B.; Gans, B.; Kennedy Hall, M.; Gaines, B.A.; et al. Comparative effectiveness research: Alternatives to “traditional” computed tomography use in the acute care setting. Acad. Emerg. Med. 2015, 22, 1465–1473. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Liu, X.; Shen, J.; Li, Z.; Sang, Y.; Wu, X.; Zha, Y.; Liang, W.; Wang, C.; Wang, K.; et al. Clinically applicable AI system for accurate diagnosis, quantitative measurements, and prognosis of COVID-19 pneumonia using computed tomography. Cell 2020, 181, 1423–1433. [Google Scholar] [CrossRef]
- Yang, X.; He, X.; Zhao, J.; Zhang, Y.; Zhang, S.; Xie, P. COVID-CT-dataset: A CT scan dataset about COVID-19. arXiv 2020, arXiv:2003.13865. [Google Scholar]
- Soares, E.; Angelov, P.; Biaso, S.; Froes, M.H.; Abe, D.K. SARS-CoV-2 CT-scan dataset: A large dataset of real patients CT scans for SARS-CoV-2 identification. MedRxiv 2020. medRxiv:2020.04.24.20078584. [Google Scholar]
- Serte, S.; Demirel, H. Deep learning for diagnosis of COVID-19 using 3D CT scans. Comput. Biol. Med. 2021, 132, 104306. [Google Scholar] [CrossRef]
- Mahoto, N.A.; Shaikh, A.; Sulaiman, A.; Al Reshan, M.S.; Rajab, A.; Rajab, K. A machine learning based data modeling for medical diagnosis. Biomed. Signal Process. Control. 2023, 81, 104481. [Google Scholar] [CrossRef]
- Ilhan, A.; Alpan, K.; Sekeroglu, B.; Abiyev, R. COVID-19 Lung CT image segmentation using localization and enhancement methods with U-Net. Procedia Comput. Sci. 2023, 218, 1660–1667. [Google Scholar] [CrossRef]
- Goceri, E. Evaluation of denoising techniques to remove speckle and Gaussian noise from dermoscopy images. Comput. Biol. Med. 2023, 152, 106474. [Google Scholar] [CrossRef]
- Yousefi, J. Image Binarization Using Otsu Thresholding Algorithm; University of Guelph: Guelph, ON, Canada, 2011; Volume 10. [Google Scholar]
- Reyad, M.; Sarhan, A.M.; Arafa, M. A modified Adam algorithm for deep neural network optimization. Neural Comput. Appl. 2023, 35, 17095–17112. [Google Scholar] [CrossRef]
- Abd El-Wahab, B.S.; Nasr, M.E.; Khamis, S.; Ashour, A.S. BTC-fCNN: Fast Convolution Neural Network for Multi-class Brain Tumor Classification. Health Inf. Sci. Syst. 2023, 11, 3. [Google Scholar] [CrossRef] [PubMed]
- Saeed, R.S.; Alwawi, B.K.O.C. A binary classification model of COVID-19 based on convolution neural network. Bull. Electr. Eng. Inform. 2023, 12, 1413–1417. [Google Scholar] [CrossRef]
- Kathamuthu, N.D.; Subramaniam, S.; Le, Q.H.; Muthusamy, S.; Panchal, H.; Sundararajan, S.C.M.; Alrubaie, A.J.; Zahra, M.M.A. A deep transfer learning-based convolution neural network model for COVID-19 detection using computed tomography scan images for medical applications. Adv. Eng. Softw. 2023, 175, 103317. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Nr. | Category Class | |||
|---|---|---|---|---|---|
| Name | Classes | COVID | Non-COVID | Pneumonia | Normal |
| CT-COV19 | 3 | ✓ | ✗ | ✓ | ✓ |
| COVID-19-CT | 3 | ✓ | ✗ | ✓ | ✓ |
| COVID-CT | 2 | ✓ | ✓ | ✗ | ✗ |
| SARS-CoV-2 Ct-Scan | 2 | ✓ | ✓ | ✗ | ✗ |
| Version and | Metrics’ Values | |||||
|---|---|---|---|---|---|---|
| Dropout | Loss | acc. | prec. | Recall | AUC | F1 Score |
| 1.0 (50%) | 1.1437 | 0.7530 | 0.7183 | 0.8259 | 0.8257 | 0.7683 |
| 1.0 (75%) | 1.7888 | 0.6165 | 0.6111 | 0.6235 | 0.6953 | 0.6172 |
| 1.1 (50%) | 0.0234 | 0.9954 | 0.9952 | 0.9936 | 0.9975 | 0.9943 |
| 1.1 (75%) | 0.0611 | 0.9882 | 0.9751 | 0.9968 | 0.9949 | 0.9858 |
| Model | Metrics’ Values | |||||
|---|---|---|---|---|---|---|
| Version | Loss | acc. | prec. | Recall | AUC | F1 Score |
| 1.4.1.0 | 0.02139 | 0.9226 | 0.9267 | 0.9207 | 0.9861 | 0.9263 |
| 1.4.1.1 | 0.0923 | 0.9678 | 0.9692 | 0.9674 | 0.9963 | 0.9683 |
| 1.4.2.0 | 0.3257 | 0.9300 | 0.9324 | 0.9293 | 0.9792 | 0.9308 |
| 1.4.2.1 | 0.1324 | 0.9533 | 0.9596 | 0.9511 | 0.9939 | 0.9554 |
| Model | Metrics’ Values | |||||
|---|---|---|---|---|---|---|
| Version | Loss | acc. | prec. | Recall | AUC | F1 Score |
| DenseNet201 | 0.2193 | 0.9467 | 0.9469 | 0.9460 | 0.9870 | 0.9465 |
| MobileNetV1 | 0.1007 | 0.9615 | 0.9635 | 0.9612 | 0.9970 | 0.9623 |
| ResNet50 | 0.0826 | 0.9701 | 0.9707 | 0.9699 | 0.9975 | 0.9750 |
| VGG16 | 0.0831 | 0.9676 | 0.9686 | 0.9653 | 0.9978 | 0.9669 |
| VGG19 | 0.0855 | 0.9758 | 0.9713 | 0.9710 | 0.9970 | 0.9707 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zolya, M.-A.; Baltag, C.; Bratu, D.-V.; Coman, S.; Moraru, S.-A. COVID-19 Detection and Diagnosis Model on CT Scans Based on AI Techniques. Bioengineering 2024, 11, 79. https://doi.org/10.3390/bioengineering11010079
Zolya M-A, Baltag C, Bratu D-V, Coman S, Moraru S-A. COVID-19 Detection and Diagnosis Model on CT Scans Based on AI Techniques. Bioengineering. 2024; 11(1):79. https://doi.org/10.3390/bioengineering11010079
Chicago/Turabian StyleZolya, Maria-Alexandra, Cosmin Baltag, Dragoș-Vasile Bratu, Simona Coman, and Sorin-Aurel Moraru. 2024. "COVID-19 Detection and Diagnosis Model on CT Scans Based on AI Techniques" Bioengineering 11, no. 1: 79. https://doi.org/10.3390/bioengineering11010079