1. Introduction
Respiratory diseases (RDs) are among the most common chronic diseases and a primary cause of morbidity and mortality, imposing an immense burden on health worldwide [
1]. COPD, acute lower tract infections, asthma, lung cancer, tuberculosis, and the recent COVID-19 infection are considered the most common acute respiratory diseases [
2]. Millions die due to chronic RDs every year because of the lack of timely and accurate diagnosis [
3]. The reliable diagnostic tests that are available for the detection of RDs are mostly laboratory-based, expensive, and time-consuming. For instance, a reverse transcriptase polymerase chain reaction (RT–PCR) test specific to SARS-CoV-2 virus is routinely used for reliable detection. This test cannot be used for continuous monitoring, since it can take up to 2 days for determining the diagnosis [
4]. Additionally, to rule out the possibility of false negative results, repetitive testing may be required. This underscores the pivotal need for devising alternative methods for rapid, cost-effective, and accurate diagnosis of RDs. Moreover, there exists a dearth of reliable instantaneous screening tools that can detect the RDs at their onset [
5]. Such tools are necessary for curbing the spread of the contagious RDs and averting the deterioration of public health.
As a pragmatic solution to this momentous problem, cough acoustic signals can play a crucial role in monitoring and detecting RD more effectively. Recent surveys [
5,
6] indicate that individuals with respiratory illness exhibit distinct features in their acoustic signals, representative of the vocal tracts, which can be extracted. Hence, features extracted from cough can help to continuously monitor and establish the health status of individuals at risk of RDs such as tuberculosis, asthma, COPD, and COVID-19 [
2,
5,
7]. Therefore, a smart, accessible, and cost-effective self-monitoring framework for continuous cough monitoring and quick disease diagnosis [
7] can be devised by incorporating the recording of cough sounds and implementing AI-based cough processing solutions [
8,
9].
Our seminal work on AI-enabled cough-based disease diagnosis has further triggered this interest, where RDs such as COVID-19 can be accurately diagnosed using cough. We demonstrated that it is possible to design advanced machine learning (ML) models to (1) discern cough from non-cough sounds recorded via a smartphone app, and (2) detect RDs such as COVID-19 infection, bronchitis, bronchiolitis, and pertussis from cough sounds recorded via the same app [
10,
11]. In recent years, a large number of independent studies have proposed solutions for digital cough monitoring and collection for timely diagnosis of RDs [
12,
13,
14,
15,
16,
17]. The current literature on SoTA cough-based RD detection leverages several ML and deep learning (DL) algorithms that can classify various temporal, spectral, and statistical cough features, including those that are perceptually indistinguishable to the human ear [
5]. The cough-acoustic AI-based RD diagnosis models include traditional methods like support vector machines [
18] for the classification of croup from pneumonia, asthma, bronchiolitis; random forest model used for COVID-19 diagnosis [
19]; logistic regression model for the classification of croup and pneumonia [
12]; and gradient boosting for COVID-19 classification [
20,
21]. Several DL models have also been leveraged for cough-based RD diagnosis including CNNs [
8] for COVID-19 diagnosis and for croup, pertussis, bronchitis, and asthma classification [
22]. Deep neural networks and spiking neural networks have also been used for the classification of COVID-19, asthma, bronchitis, and pertussis with remarkable accuracy [
16,
23]. Hybrid, e.g., CNN-LSTM, and ensemble models are also implemented in recent studies for RD diagnosis, achieving high accuracy [
17,
24,
25,
26,
27,
28,
29,
30,
31].
In the rapidly advancing field of AI-enabled automated cough sound monitoring and digital disease diagnosis, remarkable performance metrics have been achieved, as evidenced by several notable studies [
8,
10,
14,
32,
33,
34,
35,
36]. However, a critical concern remains unaddressed in the majority of these studies: the potential impact of confounding variables and data biases on the performance of the AI models they employ. These models tend to overestimate their classification performance and overfit to the training data biases, while falling short in terms of proper validation and generalization to unseen data. A recent investigation by the University of Cambridge in the UK underscored this glaring deficiency within a substantial body of research dedicated to accurately detecting and diagnosing COVID-19, highlighting the oversight of confounders in the evaluation of AI frameworks [
35]. The root issue is that confounding variables can distort the apparent relationship between input features and diagnostic outcomes, leading to erroneous predictions [
37,
38]. For instance, studies aiming to distinguish individuals with a disease from healthy controls often face the challenge of dealing with a substantial age difference between the two groups. In such cases, the AI model may inadvertently learn associations primarily influenced by age disparities rather than the genuine disease-related biomarkers and features, thus severely hindering its ability to generalize its findings. Importantly, these confounding factors can include a range of biases, such as those related to age, gender, race, and medical history, all of which can introduce systemic inaccuracies and pose potential threats to equitable healthcare assessment outcomes. Addressing these challenges is crucial for improving the reliability and fairness of AI models in the context of disease diagnosis and monitoring. The findings of our study highlight the importance for future studies to consider accounting for the effects of the confounding variables, similarly to RBF-Net, so that the reported results will be a realistic representation of classification expected in a real-world scenario.
To address this limitation in the existing studies on cough-based diagnosis, we propose an end-to-end generalized RD Bias-Free Network (RBF-Net) and evaluate its efficacy on a COVID-19 dataset. To the best of the authors’ knowledge, this is the first study that proposes a framework that is robust to the confounding variables for COVID-19 diagnosis, thus providing realistic and generalized performance. The proposed RBF-Net framework contains a bias predictor module that helps in identifying features from the cough recordings that are statistically invariant to confounding effects and mainly characterized by the effects of COVID-19, using an adversarial learning technique [
39].
The contributions of this work are summarized as follows:
In contrast to the majority of previous studies that rely on crowd-sourced cough audio databases for training AI models, this study curated a cough data set containing COVID-19 infection status. For each participant, the curated data set includes cough recordings tagged with reliable RT-PCR information and collected in a clinical setting. Hence, the data set used has extremely reliable ground truth labels, resulting in the accurate training of RBF-Net.
To demonstrate the impact of confounding variables, we train a SoTA DL model on different splits of biased training scenarios from the cough data set based on gender, age, and smoking status. Moreover, we present an insightful analysis on how model performances are often overestimated due to the underlying biased distribution of the training data and the use of cross-validation technique.
To overcome the impact of biases, we present an RBF-Net that learns features from cough recordings that are impacted by COVID-19. We perform a comparative analysis of the existing SoTA CNN-LSTM model with RBF-Net and demonstrate the improvement achieved by the proposed RBF-Net in terms of different performance metrics.
The remaining contents of this paper are organized as follows:
Section 2 discusses the details of the cough data acquisition and its pre-processing.
Section 3 presents the proposed RBF-Net architecture, and
Section 4 describes the methodology adopted for the study. The results for classification on data with various biases using the proposed RBF-Net and the existing SoTA CNN-LSTM are explained in
Section 5.
Section 6 discusses the impact of our work and future clinical deployment, and acknowledges some limitations of this work. Finally, the conclusions of the study are given in
Section 7.
2. Cough Data Acquisition and Pre-Processing
We have collected a corpus of high-fidelity audio data containing cough acoustics of normal and COVID-19 diagnosed patients. The notable feature about the data set is that rather than being collected through crowd-sourcing, it was curated to have a valid tagged RT-PCR test result for each sample. The audio data sample acquisition was performed during the time period of April–October 2020, in collaboration with Dow Medical College, Pakistan. For this research, the cough data samples were recorded from the subjects through our in-house developed AI4COVID app [
40], under the supervision of trained nurses, using one smartphone model to avoid the impact of device variability. Each participant recorded multiple coughs in a recording sample, with each recording duration varying from 3 to 12 s. An informed consent was obtained from each participant prior to acquiring the cough data. The guidelines to interact with the potential COVID-19 patients recommended by the WHO were strictly followed at all stages of the cough data collection. For instance, the healthcare professionals wore personal protective equipment (PPE) and followed a protocol for the smartphone disinfection before and after the sample was recorded. In total, the data were collected from 1094 participants with positive RT-PCR test results, labelled as COVID-19 positive, and 3761 participants with negative RT-PCR test results, labelled as normal. In addition, the anonymity of the users was preserved at all stages during the data collection.
Once the data acquisition process was complete, we performed the cough sound pre-processing steps, including noise removal, using the Audacity software package [
41]. The mono-channel cough data were sampled at 44.10 kHz before being stored as pulse-code modulation (PCM) WAV files. Silent periods at the beginning and at the end of each cough recording were clipped out. After the initial pre-processing, only the cough recordings that were longer than 2 s in duration were considered for further analysis. Thus, at the completion of the pre-processing step, we had a total of 1022 COVID-19 positive samples and 2656 normal samples.
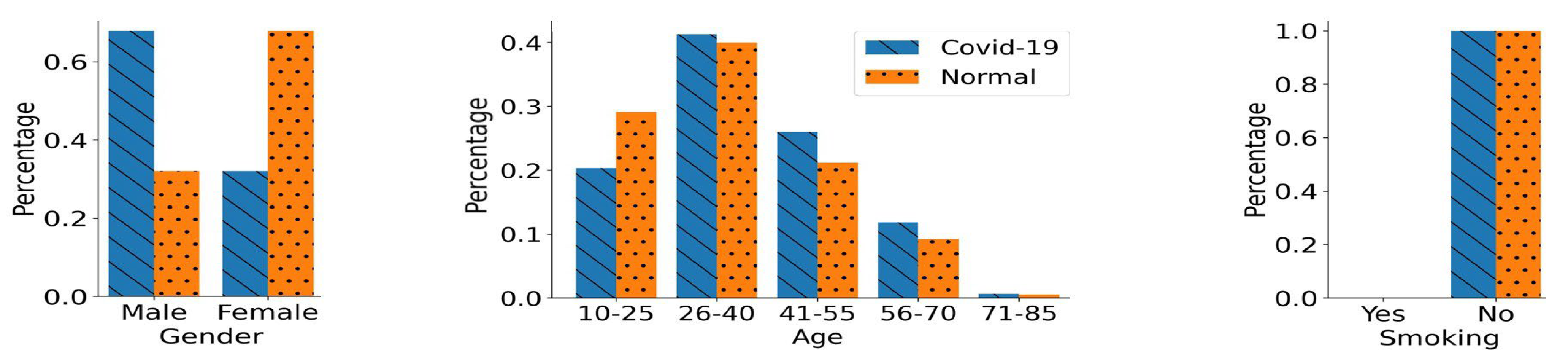
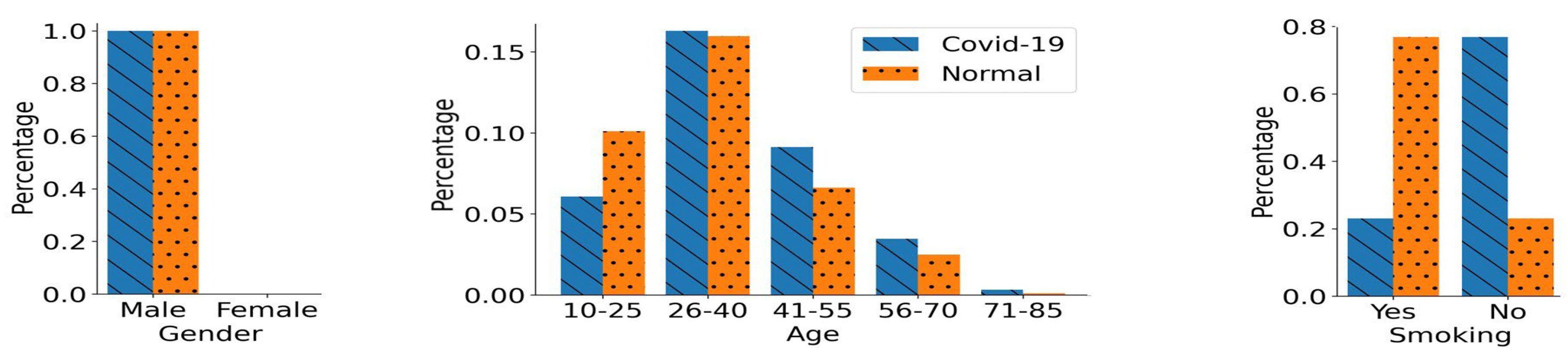
Figure 1 provides a summary of the demographics for the individuals constituting the cough audio data set. It illustrates the number of COVID-19 and normal participants with respect to their demographics, including gender, age, and smoking status. It can be observed from
Figure 1 that both normal samples and COVID-19 positive samples were skewed towards the male gender, i.e., the male cough samples were almost twice as numerous compared to the female samples. Similarly the age of the subjects in the data set fell in a broad age range from 10 to 85 years, with a significant number of the cough samples belonging to the younger and middle-aged population, 18–50 years old. A small fraction of the participants were smokers, 865 subjects who tested COVID-19 positive, and 2355 normal participants were non-smokers. On the other hand, there were a total of 156 COVID-19 positive smoking participants and 301 normal smoking participants.
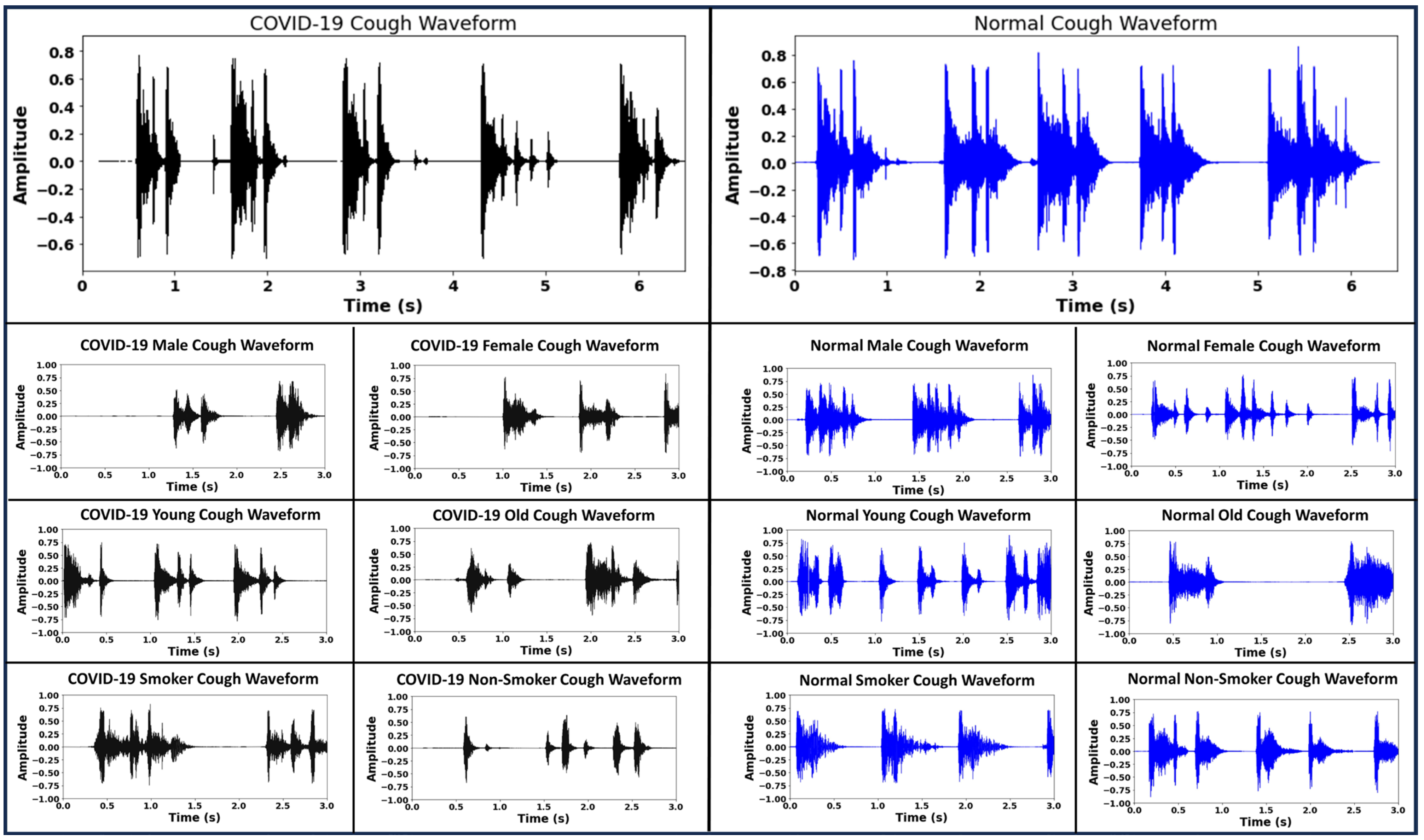
Figure 2 demonstrates the sample waveforms from the COVID-19 and normal classes. Respiratory disease affects the lungs and results in changes in the acoustic signature of the cough sound. These changes are not always clearly identifiable on inspection. Deep neural networks trained on audio data comprising coughs from respiratory disease can learn to identify cough acoustic features characterizing the respiratory disease [
5]. In addition to disease status, the cough waveforms have information like gender, age and smoking habits encoded within them that can lead the classifier to learn inaccurate representations for the disease labels. By incorporating the bias-free mechanism, the RBF-Net learns to disassociate the effects of the confounding factors like gender, age and smoking status from the disease status when classifying the cough recording. Further details are given in
Section 4.
3. RBF-Net Architecture
In this section, we present the detailed architecture of the proposed RBF-Net with a focus on COVID-19 classification. The CNN-LSTM model forms the main skeleton of the proposed framework architecture. The CNN-LSTM has proved to be the SoTA spectrogram-based COVID-19 classification DL model and has been widely used for classification tasks by the research community [
17,
24,
25,
26,
27,
28,
29,
30,
31]. We used this SoTA DL technique as both the benchmark for our framework and also the building block for the feature encoder module of the proposed RBF-Net. The architectural details of the implemented CNN-LSTM model are shown in
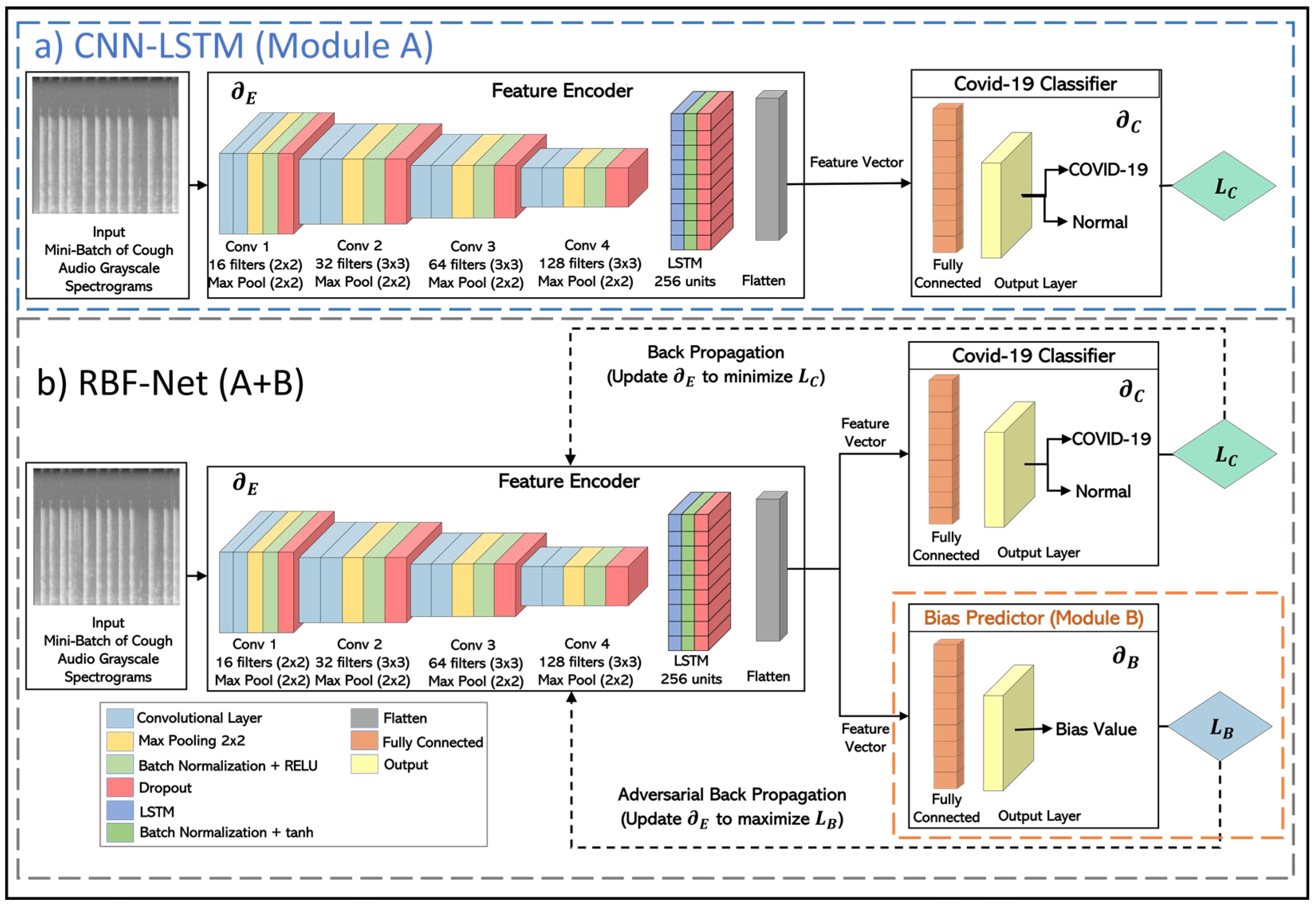
Figure 3a.
The CNN-LSTM architecture can primarily be divided into two blocks. The first block (feature encoder) uses a CNN architecture that receives grayscale spectrograms constructed from cough recordings as an input of shape 224 × 224. Then, the most relevant and informative features are extracted by the convolutional layers. These features are converted to the feature maps, which are passed on to the LSTM block, where the deep features that have high temporal correlation are selected to capture the more useful patterns. In the second block (COVID-19 classifier), a simple fully connected layer is used for the feature learning and COVID-19 classification. Both of these blocks are trained through the COVID-19 classification loss (Lc), which is chosen to be the binary cross-entropy loss. The Lc is backpropagated in a manner that the model parameters of the feature encoder (∂E) and COVID-19 classifier (∂C) are tuned to minimize.
Although this model works extremely well in learning the differences between the two classes in the target variable (COVID-19 or normal), as shown in
Section 5, it can not nullify the impact of the confounding variables. This model is prone to be affected by the impact of biases in its learned features; thus, the model cannot be truly representative of COVID-19’s impact on the cough sounds. To address the underlying biases and confounding variables in the data distribution, we made modifications to the CNN- LSTM inspired by the recent work in the machine learning fairness schemes [
39]. An additional bias predictor component is attached to the network architecture that helps the encoder module to decorrelate the extracted feature vector from the effects of confounding variables, as evidenced by the classification results for the RBF-Net framework in
Section 5. This decorrelation process is based on training the feature encoder through an adversarial learning technique similar to that of the conditional GAN (c-GAN). In this iterative training process, the bias predictor aims to predict the bias value from the feature vector created from a conditioned subset of normal samples from the input and then have an adversarial impact on the encoder to learn the features that are bias- free. In this manner, the RBF-Net framework learned features conditionally independent of the biases and carrying useful information for COVID-19 classification. Thus, the overall goal to create a bias-free and generalizable RD classifier for large-scale clinical deployment can be realized.
The RBF-Net architecture is composed of three key blocks, depicted in
Figure 3b, each undergoing distinct training phases. Initially, the COVID-19 classifier block focuses on precise dis ease classification, dynamically updating its model parameters
∂C. The gradient, propagated with respect to the COVID-19 classification loss
LC, refines the encoder parameters
∂E, ensuring feature extraction that minimizes
LC. In the subsequent phase, with frozen encoder parameters
∂E, the bias predictor module is trained. This involves updating parameters
∂B to minimize bias prediction loss
LB, determined by either inverse mean squared error or inverse binary cross-entropy based on the bias variable. In the final training step, with
∂B frozen, the feature encoder undergoes training. Adversarial back-propagation of gradients from
LB fortifies
∂E to extract features maximizing
LB, establishing a min-max game that cultivates bias-invariant features crucial for COVID-19 classification. This strategic training paradigm equips RBF-Net to accurately classify COVID-19 without succumbing to the influence of underlying biased data distributions.
5. Results
We trained the CNN-LSTM model on all of the biased training data sets to analyze the impact of confounding effects in the data distribution on this particular SoTA DL model. We utilized 10-fold cross-validation (CV) on the CNN-LSTM model; the data sets were divided into 10 equal folds. In each iteration of CV, one of these folds was used as a validation set, while the other nine folds were used for the training. This process was repeated 10 times, with each fold being used as the validation set once. During each iteration of the CV, we measured the accuracy, specificity, sensitivity, F1-score, and ROC-AUC for the model performance on the validation set. After all iterations were completed, the average of each performance metric across all iterations was calculated and reported. After this CV technique, the CNN-LSTM model architecture was trained on the biased data sets, and its performance was evaluated on the respective unseen balanced testing data sets to gauge if the unrealistic experiment design led to an inaccurate inflation of the model performance. Furthermore, in order to evaluate the efficacy of the RBF-Net framework in learning the features that were purely extracted through difference in cough spectrograms caused by the impact of COVID-19 respiratory disease, we trained it on the biased training data sets as well. We evaluated the performance of RBF-Net on the same unseen balanced testing data sets and performed a comparative analysis with the CNN-LSTM model. In the subsequent subsections, we evaluate the performance of both CNN-LSTM and RBF-Net on each of the biased training data sets individually.
5.1. Performance in Gender-Biased Training Scenario
The performance of the CNN-LSTM model in COVID-19 detection was inaccurately inflated under the influence of innate gender bias in the training scenario. From the results obtained through the CNN-LSTM model using the CV technique to the results obtained through the CNN-LSTM on the unseen testing data set, a major decline in performance metrics was observed, as reported in the
Table 2. The obtained accuracy dropped from 0.890 to 0.787. This clearly indicated that the CV technique led the CNN-LSTM model to learn the features impacted by the gender bias. Thus, the performance of the CNN- LSTM model in accurately diagnosing COVID-19 was highly overestimated. Another vital observation was the difference in the obtained specificity (0.860) and sensitivity (0.715) of the CNN-LSTM model on the testing data set. Since the samples from the normal class participants were over-represented by the female participants in the training data, the model tended to treat female participants as normal participants. On the other hand, the results of the RBF-Net model, when evaluated on the unseen testing data set, demonstrated a significant improvement over the CNN-LSTM, as measured by the five different performance metrics. We obtained an overall accuracy improvement of more than 5% through the RBF-Net model. The difference between the obtained specificity (0.887) and sensitivity (0.796) was also diminished in the RBF-Net model; thus, it is better suited to mitigate the effect of gender bias in the training scenario.
5.2. Performance in the Age-Biased Training Scenarios
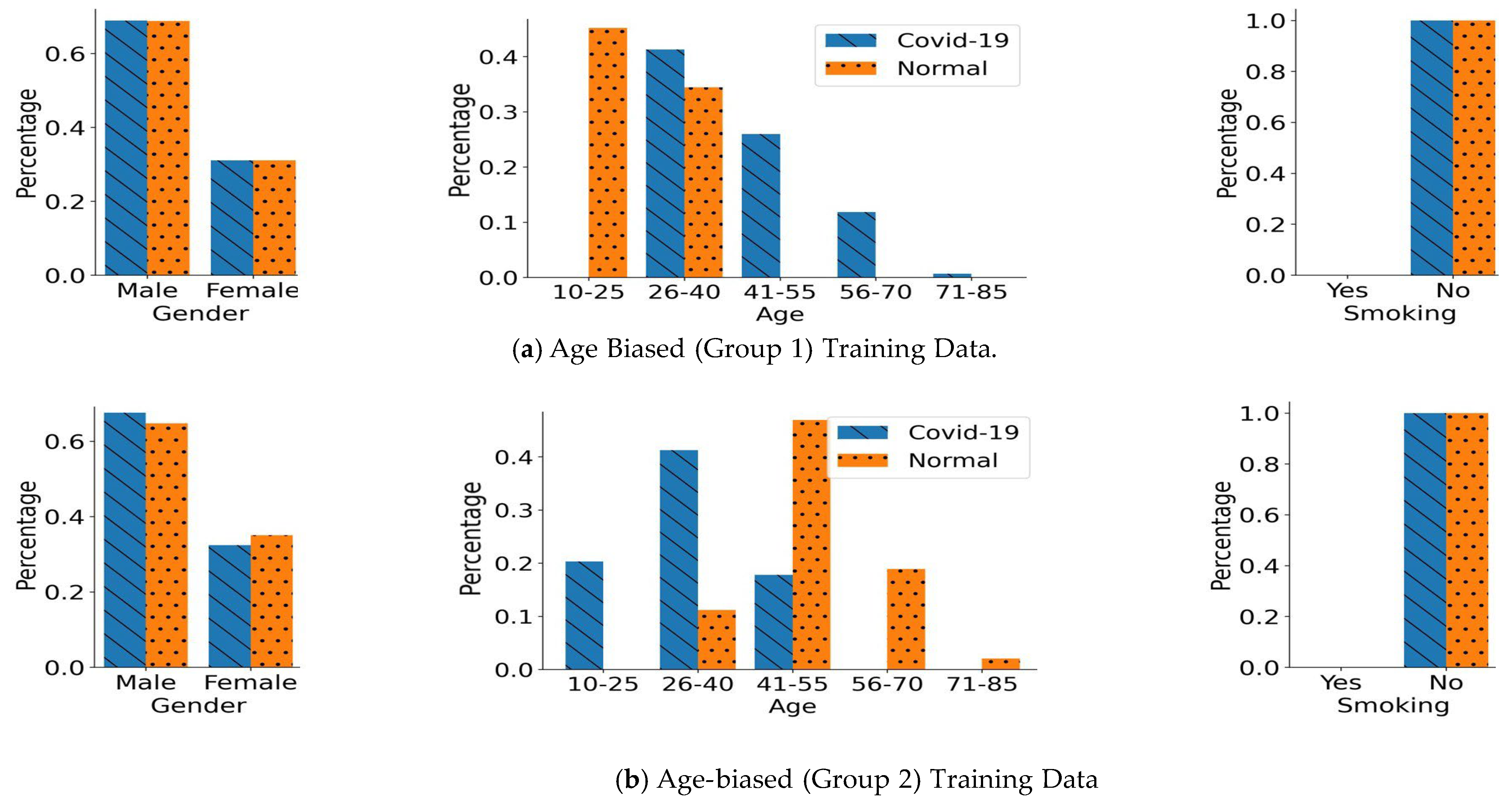
Similarly to the gender-biased data, the performance of the CNN- LSTM model in COVID-19 detection was overestimated in the presence of the underlying age distribution in the training scenario. Using 10-fold CV, the CNN-LSTM model obtained an average accuracy of 0.887 and 0.884 in the age-biased groups, respectively, as shown in
Table 3. On the other hand, when the CNN-LSTM model was trained on the same training data sets and evaluated on the unseen balanced testing data set, a substantial decline in the performance metrics, such as accuracy, specificity, sensitivity, F1-score, and ROC-AUC, was observed. It achieved an unseen testing accuracy of 0.774 and 0.756 when trained on both groups, respectively. As shown in the previous section (
Section 4.2), age-biased group 1 had an over-representation of a relatively younger population (aged under 40 years) in the normal participants. This led the model to treat younger participants as normal samples. This accounted for the significant difference between specificity (0.843) and sensitivity (0.706) obtained through the CNN-LSTM model on the testing data set. Similarly, in age-biased group 2, the normal participants were over-represented by a relatively older population (aged above 40 years). This led the model to treat elderly participants as normal participants, which was again shown by the difference in the obtained specificity (0.825) and sensitivity (0.687). This clearly indicated that CNN-LSTM is prone to learning features directly associated with the underlying age bias, which led to the overestimation of the COVID-19 detection performance. Unlike CNN-LSTM, RBF-Net is immune to the impact of biases in the training data sets. The results for the RBF-Net model demonstrated a major improvement over the CNN-LSTM model in all of the performance metrics when evaluated on the unseen testing data set. An accuracy of 0.845 and 0.818 was achieved across both training groups, respectively, and at the same time, the difference between sensitivity and specificity was also diminished. Thus, it demonstrates that the RBF-Net is also suitable for alleviating the age bias in real-world COVID-19 detection applications.
5.3. Performance in the Smoking Status-Biased Training Scenario
The impact of underlying bias in the smoking status distribution on the CNN-LSTM model, causing the inaccurately inflating COVID-19 detection performance, was analyzed. Using a 10-fold CV technique, the CNN-LSTM model obtained an average accuracy of 0.862, as shown in
Table 4, whereas, when evaluated on unseen testing data, its accuracy drops to 0.723, which was almost 14% less than that obtained with the CV technique. This clearly shows that the CNN-LSTM model learned features directly associated with the smoking status bias and its COVID-19 detection performance was again overestimated. On the contrary, RBF-Net showed its ability to eliminate the underlying impact of smoking status bias in the training scenario when it was evaluated on the unseen smoking status testing data set. The results for the RBF-Net model showed a major improvement over the CNN-LSTM model in all performance metrics. The obtained accuracy, F1-score, and ROC-AUC were almost 8% higher compared to the CNN-LSTM model.
5.4. Ablation Study
To further elucidate the novelty of our proposed approach, which involves integrating the bias predictor module (B) into the CNN-LSTM framework (module A) to address confounding variables, we conducted an additional experiment. In preceding sections, we methodically demonstrated how our RBF-Net (A + B) consistently outperformed the standalone CNN-LSTM model when trained on diverse sets of biased data. In this ablation study, we aimed to assess the specific influence of the bias predictor module (B) within the RBF-Net in comparison to the CNN and CNN-LSTM framework (A) under both unbiased and biased training conditions. The architecture used for constructing the CNN model is illustrated in [
27]. To achieve this, we created a new training dataset devoid of any inherent bias related to the confounding variables of age, gender, and smoking status. This dataset consisted of 900 samples for each target class, i.e., COVID-19 and normal. The gender distribution, age distribution, and smoking status distribution were kept roughly the same across both of these classes, thus eliminating any form of bias. Furthermore, we curated an additional balanced unseen testing dataset having 100 samples in both of the classes for evaluating the RBF-Net, CNN, and CNN-LSTM on the unbiased training data. In
Table 5 below, we present the testing performance metrics for the CNN model, CNN-LSTM model (Module A) and the RBF-Net (A + B) when trained on the unbiased, gender-biased, age-biased (group 1), and smoking status-biased training datasets and evaluated on their respective unseen testing datasets. This presentation was designed to highlight the discernible impact of the bias predictor (Module B) on the performance of RBF-Net.
The feature encoder module is a shared component in both CNN-LSTM and RBF-Net that plays a fundamental role in learning the distinctive features influenced by the presence of COVID-19. For this reason, the performance achieved by CNN-LSTM and RBF-Net was similar in the unbiased training setting. However, the vitality of the bias predictor (module B) in the RBF-Net was established when both models were trained and evaluated under biased training conditions. In these scenarios, the performance of the CNN-LSTM model experienced a significant decline, whereas the RBF-Net remained resilient, consistently maintaining its accuracy, as highlighted in the preceding sections. Consequently, the incorporation of the bias predictor module (module B) within the c-GAN framework significantly bolstered the RBF-Net’s capability to learn the nuanced impact of COVID-19 features. This enhancement not only contributed to its effectiveness but also rendered it more practical for deployment as a digital testing tool.
6. Discussion and Limitations
As discussed in the preceding sections, our investigation delved into the influence of three pivotal confounding variables: gender, age, and smoking status. These variables were meticulously considered to assess their impact on the CNN-LSTM model’s ability to detect COVID-19. Notably, the substantial performance degradation observed in the CNN-LSTM model—from the performance achieved during cross-validation to its subsequent evaluation on the balanced testing data—clearly demonstrated the adverse effects of data selection bias on the features learned by the model. Thus, the underlying demographic bias, that often exists in the distributions of real-world clinical data [
34,
35,
39], has to be addressed in future machine learning schemes, thereby making them practical and effective tools for validation by healthcare practitioners and clinicians in the realm of digital healthcare solutions.
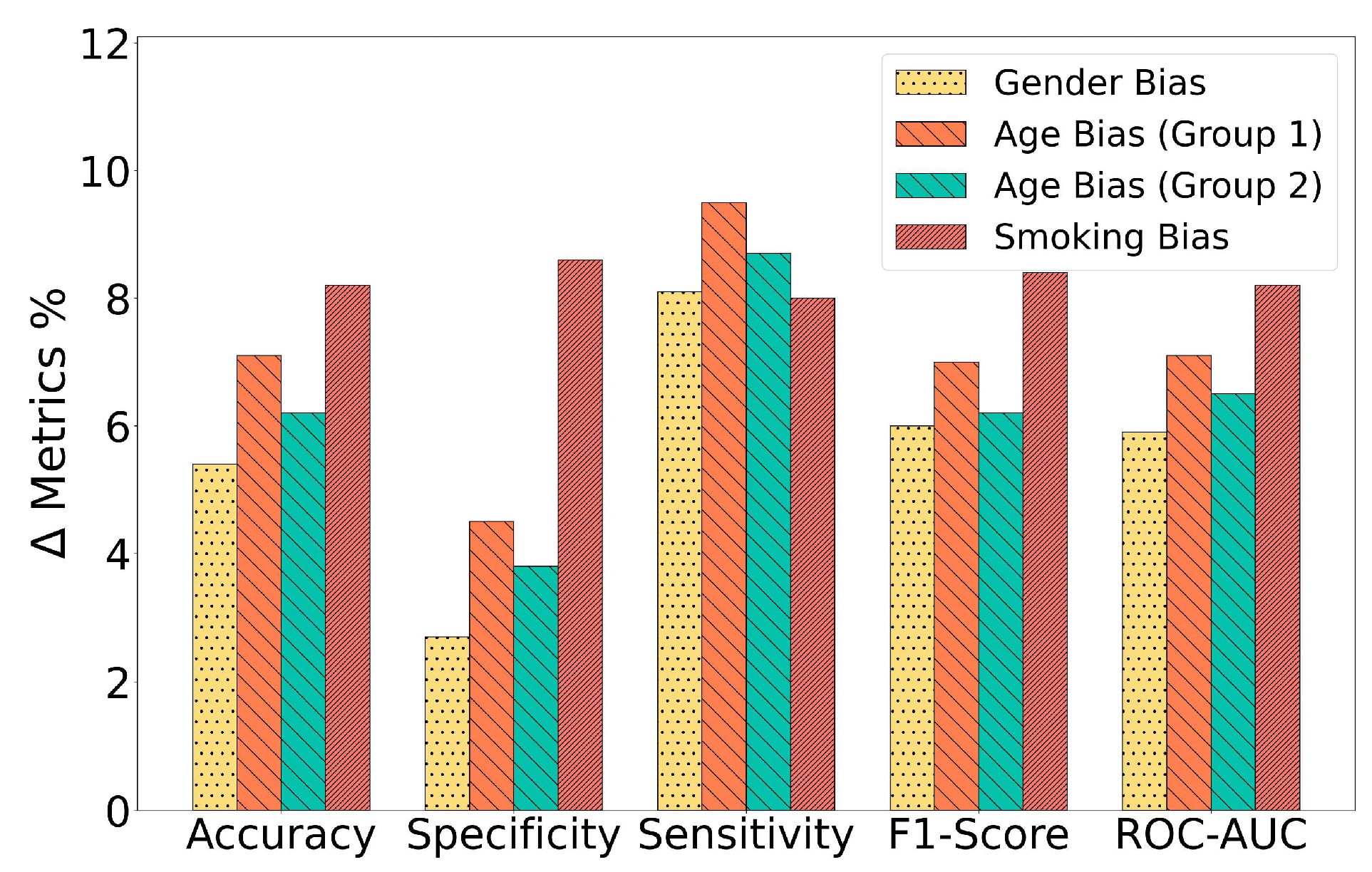
The RBF-Net model effectively mitigated the influence of inherent biases present in training data distributions by extracting meaningful features from them. This was vividly illustrated by the significant performance improvements exhibited by the RBF-Net framework when compared to the CNN-LSTM model across all confounding variables. The differences in performance metrics, including accuracy, specificity, sensitivity, F1-score, and ROC-AUC, across various biased training groups are depicted in
Figure 7. A noteworthy insight from the results is that the RBF-Net model achieved the most substantial improvement when dealing with the smoking status-biased training group. It achieved an approximately 8% increase in accuracy, F1-score, and ROC-AUC in this specific scenario. The architecture of the feature encoder module within the RBF-Net sheds light on the reason behind this remarkable improvement. The encoder comprises convolutional blocks and an additional LSTM block, which collectively identify features that hold spatial and temporal significance. This feature extraction capability enabled the RBF-Net model to effectively discern the impact of COVID-19 on cough spectrogram images, as COVID-19 often manifests respiratory symptoms that, in turn, influence the spatiotemporal features of these cough spectrograms, as observed in previous studies [
10]. Simultaneously, smoking also induces changes in human cough spectrograms in the spatiotemporal domain. This implies that the effect of smoking on the spectrograms bears some resemblance to the impact of COVID-19, especially when contrasted with the effects of gender and age on the spectrograms. Consequently, the RBF-Net framework yielded the maximum performance increase when mitigating the impact of the bias related to smoking status.
Another standout aspect of our study lies in the high-quality data used for training and testing the DL model, enhancing the credibility of our results and conclusions. Unlike many existing cough-acoustic datasets [
27,
29,
35,
48,
49], which often rely on crowd-sourced data, the data used in this paper were meticulously collected within a reputable medical facility under the supervision of trained healthcare professionals. Furthermore, the cough audio samples were obtained on the same day as the COVID-19 labels were assigned through standardized RT-PCR tests. This meticulous approach minimized the potential errors stemming from misreporting or participants’ lack of awareness regarding their COVID-19 status at the time of cough recording.
One limitation of our current scope of work is that the efficacy of the RBF-Net framework has thus far been validated solely on the COVID-19 cough dataset and has not yet been extended to other RDs such as tuberculosis, asthma, and COPD. The data collection process for these additional conditions is currently underway within a medical facility, a process that demands a considerable amount of time and resources while adhering to strict Institutional Review Board (IRB) protocols. Additionally, ensuring patient privacy, obtaining ground-truth diagnosis information via gold standard tests at the precise moment of cough sound collection, and maintaining consistency in the cough sound sample collection by minimizing device variability, background noise, and other environmental factors are integral to this endeavor. Our immediate future agenda revolves around evaluating RBF-Net’s capability to identify respiratory diseases akin to COVID-19 based on the acoustic signatures present in cough sounds. This assessment will be conducted once the data collection efforts are successfully concluded.
Our upcoming research will have a bi-fold objective. Firstly, we intend to broaden the spectrum of confounding variables by incorporating the common influenza virus, a respiratory tract ailment. This addition will allow us to explore how the presence of the influenza virus might impact the performance of our RBF-Net in the detection of COVID-19 and other RDs. By doing so, we can unravel potential interactions between these respiratory conditions, thus improving the accuracy of our models. Secondly, we plan to delve into the influence of other common confounding factors, such as race and geographical location. These factors can play a pivotal role in shaping the prevalence of various diseases and introduce biases in data distributions. Examining and accounting for these variables will not only bolster the resilience of the RBF-Net framework but will also make it adaptable for global-scale screening efforts. This comprehensive approach will enhance our understanding of the interplay between various confounding factors and the performance of our model, ultimately facilitating more accurate and globally relevant disease detection and screening.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}