
Improved Lightweight Convolutional Neural Network for Finger Vein Recognition System



Abstract
:1. Introduction
- This study proposes a lightweight model architecture, ILCNN, with only 1.23 million parameters, for finger vein recognition. The proposed architecture enables finger vein recognition in real-world scenarios with reduced parameter count, computational complexity, and inference time. Experimental results demonstrate that the lightweight model architecture outperforms other methods in terms of parameter count, computational complexity, and inference time.
- In this study, we introduce DBRB for finger vein recognition, which allows the model’s architecture to be equivalently transformed through a function, enabling the learning of richer and diverse feature maps at different scales. Experimental results indicate that the proposed DBRB effectively enhance the accuracy of finger vein recognition models in identity recognition.
- This study validates the effectiveness and generalization of the proposed lightweight model architecture by employing the finger-vein by university sains malaysia (FV-USM) and PLUSVein dorsal-palmar finger-vein (PLUSVein-FV3) databases. Furthermore, in-depth investigations are conducted to explore the impact of DBRB modules and the EML function on the proposed ILCNN model. Experimental results demonstrate that the proposed ILCNN model exhibits superior identity recognition capabilities compared to other methods across various finger vein databases.
2. Related Works
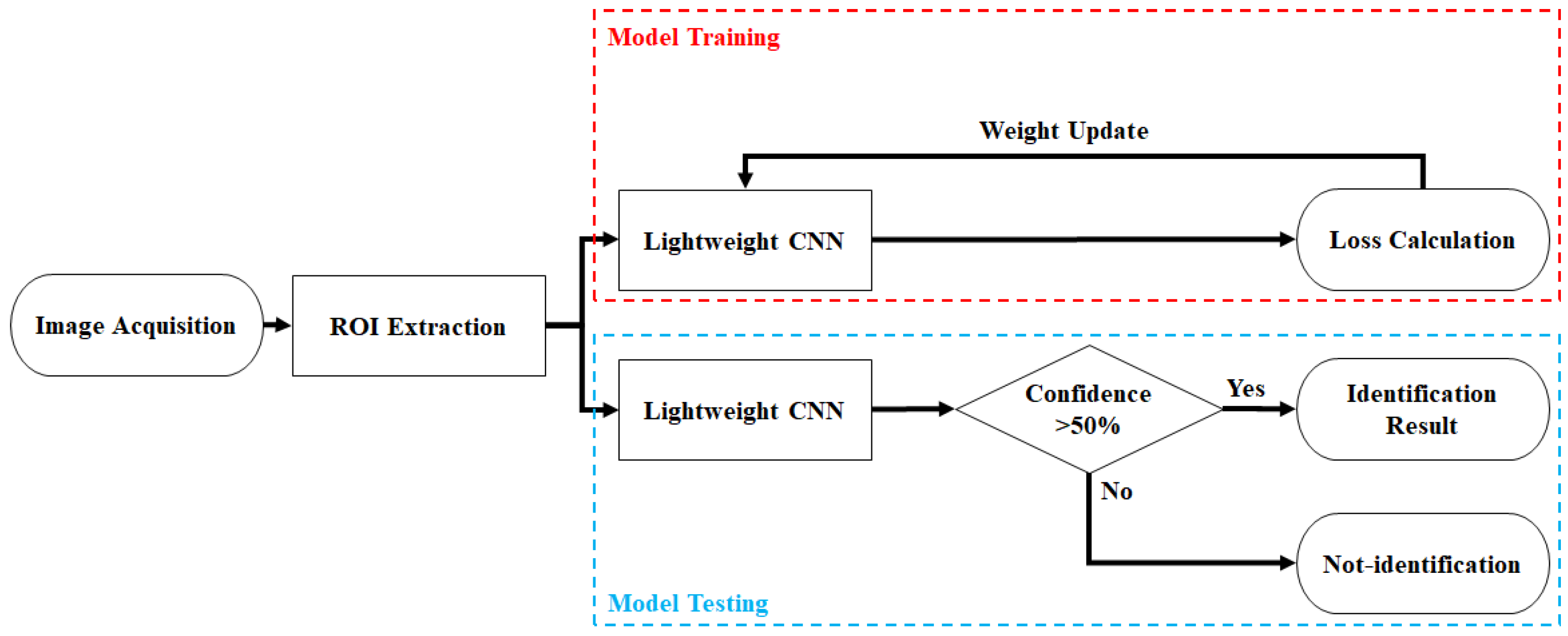
3. Materials and Methods
3.1. Model Compression
3.2. Attention Mechanism
3.3. Shift-Invariant Features
3.4. Margin-Based Loss Functions
3.5. Improved Lightweight Convolutional Neural Network
- Input flowThe input flow consists of a 3 × 3 DBB, ReLU activation function, CoAM, and APS sampling. First, to address the computational constraints of the ILCNN model architecture and mitigate distortions resulting from variations in the image scale, zero padding was applied to expand the finger vein images to a square shape. Additionally, the image size is scaled to 112 before being fed into the model for feature extraction. After feature extraction using the DBB, the ReLU activation function was applied to filter the features and provide the model with the ability to capture nonlinear characteristics. Finally, this study applies consecutive CoAM and APS sampling to focus on important regions within the feature maps while reducing their size. Note that the feature maps obtained from the input pipeline were transformed from 112 × 112 × 3 to 56 × 56 × 16, with the width and height of the feature maps being half those of the input images, thereby reducing the computational burden in the subsequent stages of the model.
- Middle flowAfter feature extraction and sampling of the input flow, four consecutive DBRBs were utilized to extract features. To mitigate the impact on the model parameters, this study avoided a significant increase in the channel dimensions of the feature maps. This is because the channel dimensions have a significant influence on the increase in the parameters. After feature extraction, the sizes of the extracted feature maps were transformed from 56 × 56 × 16 to 4 × 4 × 256. Simultaneously, the model gradually transformed the spatial information of the features into channel dimensions.
- Output flowFinally, in the output flow, we applied global average pooling to further compress the spatial information of the feature maps. This approach avoids the need for direct computations using fully connected layers, resulting in a reduction in computational load. Simultaneously, we obtained a feature vector of length 256 and fed it into a fully connected layer to obtain two different types of features: normalized features using feature normalization techniques and identification results without normalization. Normalized features were employed in the computation of the loss value within the EML loss function, enabling optimization of the model weights. However, the identification results directly indicate the predicted identity class and can be utilized for subsequent evaluation metric calculations. Note that this study incorporated a dropout layer as the final layer in the output process. According to [25], placing a dropout layer before batch normalization can affect the effectiveness of batch normalization. Therefore, following the solution proposed by Li et al. [25], this study placed the dropout layer before the output layer to address this issue. This retains the advantage of dropout in enhancing the generalization capabilities, allowing the model to further improve the recognition accuracy.
4. Results
4.1. Public Database
4.1.1. PLUSVein-FV3
4.1.2. FV-USM
4.2. Experimental Settings and Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hsia, C.-H.; Liu, C.-H. New hierarchical finger-vein feature extraction method for ivehicles. IEEE Sens. J. 2022, 22, 13612–13621. [Google Scholar] [CrossRef]
- Chen, Y.-Y.; Hsia, C.-H.; Chen, P.-H. Contactless multispectral palm-vein recognition with lightweight convolutional neural network. IEEE Access 2021, 9, 149796–149806. [Google Scholar] [CrossRef]
- Chen, Y.-Y.; Jhong, S.-Y.; Hsia, C.-H.; Hua, K.-L. Explainable AI: A multispectral palm-vein identification system with new augmentation features. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–21. [Google Scholar] [CrossRef]
- Albiero, V.; Krishnapriya, K.S.; Vangara, K.; Zhang, K.; King, M.C.; Bowyer, K.W. Analysis of gender inequality in face recognition accuracy. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops, Snowmass Village, CO, USA, 1–5 March 2020; pp. 81–89. [Google Scholar]
- Bisogni, C.; Nappi, M.; Pero, C.; Ricciardi, S. PIFS scheme for head pose estimation aimed at faster face recognition. IEEE Trans. Biom. Behav. Identity Sci. 2022, 4, 173–184. [Google Scholar] [CrossRef]
- Peña, A.; Morales, A.; Serna, I.; Fierrez, J.; Lapedriza, A. Facial expressions as a vulnerability in face recognition. In Proceedings of the IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 2988–2992. [Google Scholar]
- Zhang, L.; Sun, L.; Li, W.; Zhang, J.; Cai, W.; Cheng, C.; Ning, X. A joint bayesian framework based on partial least squares discriminant analysis for finger vein recognition. IEEE Sens. J. 2022, 22, 785–794. [Google Scholar] [CrossRef]
- Zhang, L.; Li, W.; Ning, X.; Sun, L.; Dong, X. A local descriptor with physiological characteristic for finger vein recognition. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 4873–4878. [Google Scholar]
- Zhang, Y.; Li, W.; Zhang, L.; Ning, X.; Sun, L.; Lu, Y. AGCNN: Adaptive gabor convolutional neural networks with receptive fields for vein biometric recognition. Concurr. Comput. Pract. Exp. 2020, 34, e5697. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, L.; Dong, X.; Yu, L.; Li, W.; Ning, X. An efficient joint bayesian model with soft biometric traits for finger vein recognition. In Proceedings of the Chinese Conference on Biometric Recognition, Shanghai, China, 10–12 September 2021; pp. 248–258. [Google Scholar]
- Liu, W.; Lu, H.; Li, Y.; Wang, Y.; Dang, Y. An improved finger vein recognition model with a residual attention mechanism. In Proceedings of the Chinese Conference on Biometric Recognition, Shanghai, China, 10–12 September 2021; pp. 231–239. [Google Scholar]
- Zhong, Y.; Li, J.; Chai, T.; Prasad, S.; Zhang, Z. Different dimension issues in deep feature space for finger-vein recognition. In Proceedings of the Chinese Conference on Biometric Recognition, Shanghai, China, 10–12 September 2021; pp. 295–303. [Google Scholar]
- Chai, T.; Li, J.; Prasad, S.; Lu, Q.; Zhang, Z. Shape-driven lightweight cnn for finger-vein biometrics. J. Inf. Secur. Appl. 2022, 67, 103211. [Google Scholar] [CrossRef]
- Chai, T.; Li, J.; Wang, Y.; Sun, G.; Guo, C.; Zhang, Z. Vascular enhancement analysis in lightweight deep feature space. Neural Process. Lett. 2022, 55, 2305–2320. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10886–10895. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, R. Making convolutional networks shift-invariant again. Int. Conf. Mach. Learn. 2019, 97, 7324–7334. [Google Scholar]
- Chaman, A.; Dokmanic, I. Truly shift-invariant convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3773–3783. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. ArcFace: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Boutros, F.; Damer, N.; Kirchbuchner, F.; Kuijper, A. ElasticFace: Elastic margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, New Orleans, LA, USA, 18–24 June 2022; pp. 1578–1587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–37 June 2016; pp. 770–778. [Google Scholar]
- Balduzzi, D.; Frean, M.; Leary, L.; Lewis, J.P.; Ma, K.W.-D.; McWilliams, B. The shattered gradients problem: If resnets are the answer, then what is the question? Int. Conf. Mach. Learn. 2017, 70, 342–350. [Google Scholar]
- Li, X.; Chen, S.; Hu, X.; Yang, J. Understanding the disharmony between dropout and batch normalization by variance shift. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2682–2690. [Google Scholar]
- Asaari, M.S.M.; Suandi, S.A.; Rosdi, B.A. Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics. Expert Syst. Appl. 2014, 41, 3367–3382. [Google Scholar] [CrossRef]
- Kauba, C.; Prommegger, B.; Uhl, A. The two sides of the finger—An evaluation on the recognition performance of dorsal vs. palmar finger-veins. In Proceedings of the International Conference of the Biometrics Special Interest Group, Darmstadt, Germany, 26–28 September 2018; pp. 1–5. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the IEEE International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | CIR (%) | |
|---|---|---|
| LED | Laser | |
| DenseNet-121 [30] | 93.06 | 93.19 |
| EfficientNet-B0 [31] | 95.82 | 92.22 |
| ILCNN | 95.90 | 93.52 |
| Methods | CIR (%) | Params (M) |
|---|---|---|
| W. Liu et al. [11] | 98.58 | 5.85 |
| LFVRN_CE + ACE [12] | 99.09 | 4.93 |
| Semi-PFVN [13] | 94.67 | 3.35 |
| LightFVN + ACE [14] | 96.17 | 2.65 |
| VGG-16 [29] | 86.16 | 136.28 |
| DenseNet-121 [30] | 93.54 | 7.46 |
| EfficientNet-B0 [31] | 99.70 | 4.64 |
| ILCNN | 99.82 | 1.23 |
| Methods | DBRB | EML | CIR (%) |
| ILCNN | w/o | w/o | 97.17 |
| w | w/o | 99.19 | |
| w | w | 99.82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsia, C.-H.; Ke, L.-Y.; Chen, S.-T. Improved Lightweight Convolutional Neural Network for Finger Vein Recognition System. Bioengineering 2023, 10, 919. https://doi.org/10.3390/bioengineering10080919
Hsia C-H, Ke L-Y, Chen S-T. Improved Lightweight Convolutional Neural Network for Finger Vein Recognition System. Bioengineering. 2023; 10(8):919. https://doi.org/10.3390/bioengineering10080919
Chicago/Turabian StyleHsia, Chih-Hsien, Liang-Ying Ke, and Sheng-Tao Chen. 2023. "Improved Lightweight Convolutional Neural Network for Finger Vein Recognition System" Bioengineering 10, no. 8: 919. https://doi.org/10.3390/bioengineering10080919