
Prompt-Based Tuning of Transformer Models for Multi-Center Medical Image Segmentation of Head and Neck Cancer

Abstract
:1. Introduction
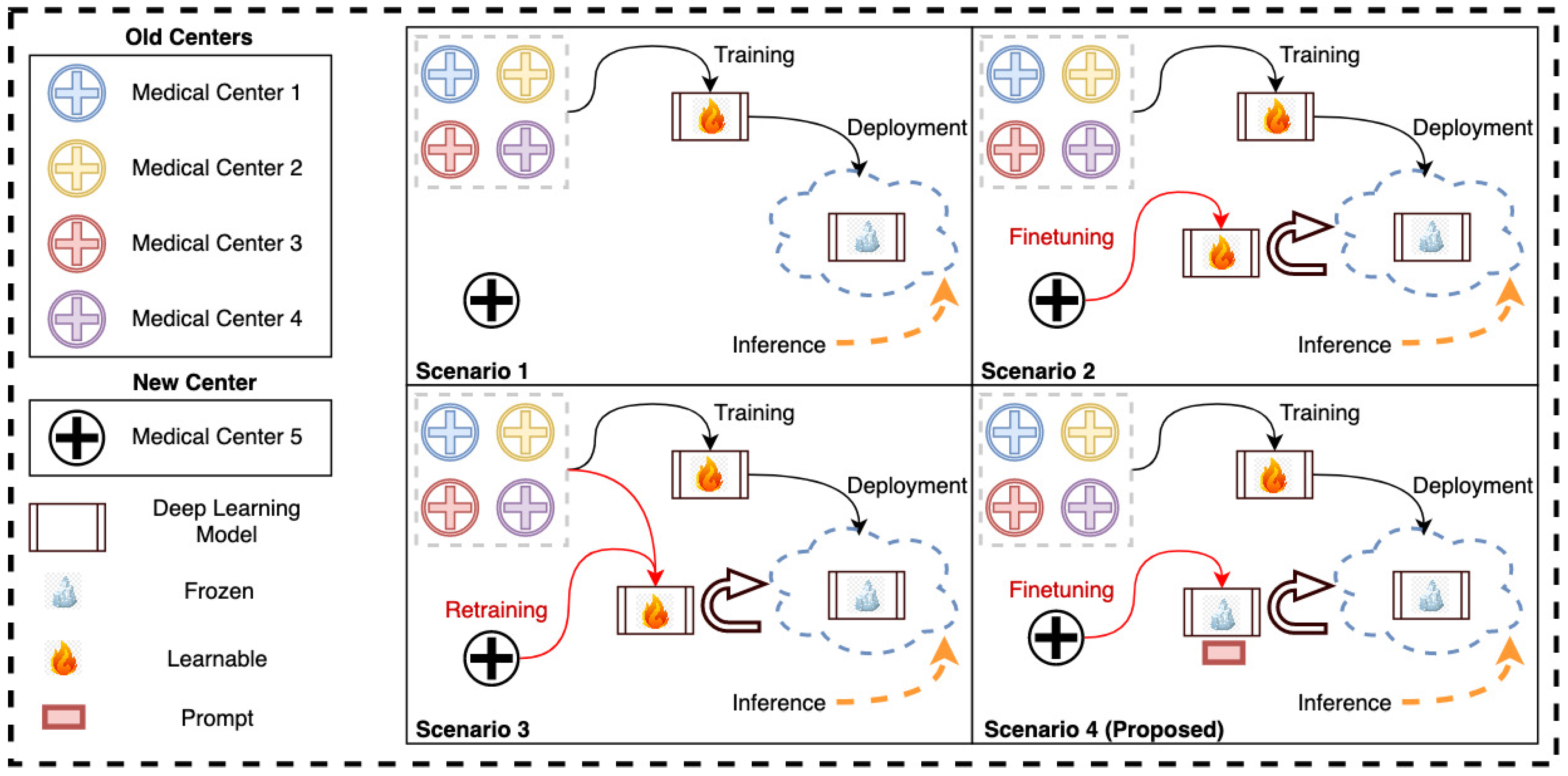
- We propose a new prompt-based fine-tuning technique for the transformer-based medical image segmentation models that reduces the fine-tuning time and the number of learnable parameters (less than 1% of the model parameters) to be stored for the new medical center.
- The proposed method achieves equivalent accuracy for new-center data compared to the full fine-tuning technique while mostly preserving the accuracy for the old-center data that compromises full fine-tuning.
- We showcase the efficacy of the proposed method on multi-class segmentation of head and neck cancer tumors using multi-channel computed tomography (CT) and positron emission tomography (PET) scans of patients obtained from multi-center (seven centers) sources.
2. Methodology
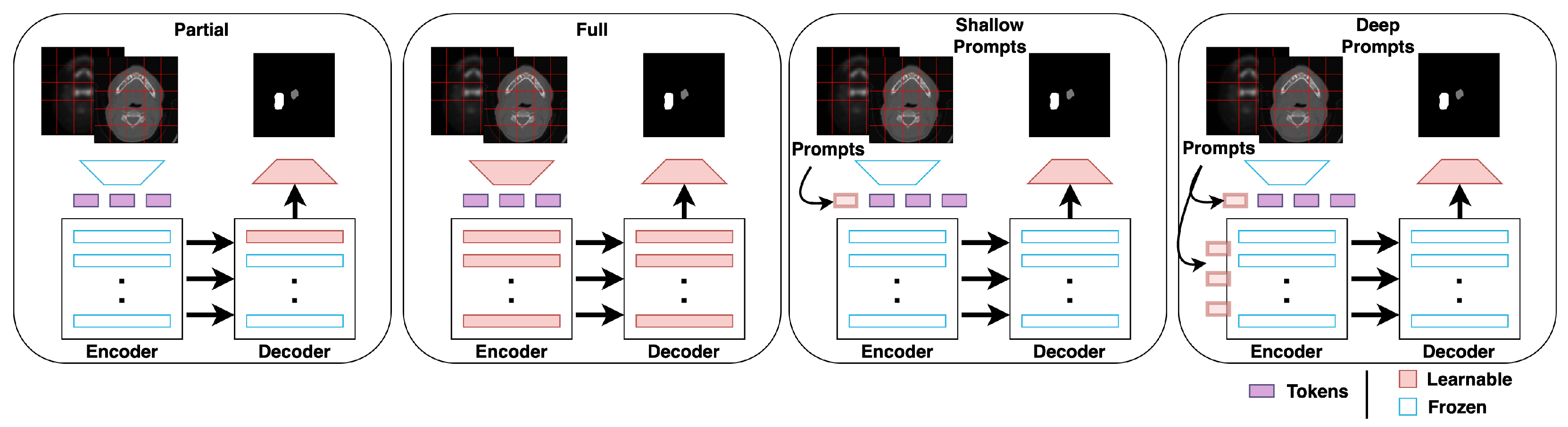
2.1. Shallow Prompt Tuning
2.2. Deep Prompt Tuning
3. Experiments
3.1. Dataset
3.2. Experimental Setup
3.3. Implementation Details
4. Results
- 1.
- All the different fine-tuning techniques yield better performance for the new centers than direct inference on the pre-trained models.
- 2.
- Shallow prompt-based fine-tuning achieves a higher or comparable Dice score on the new-center data, with nearly the same number of learnable parameters as partial fine-tuning (see Table 3). However, shallow prompts outperform partial and full fine-tuning techniques on the old-center data for all seven centers.
- 3.
- Deep prompt-based fine-tuning achieves the same Dice score as full fine-tuning on the new-center data but with significantly fewer learnable parameters. In addition, deep prompt-based fine-tuning outperforms the full fine-tuning on old-center data for all seven centers. Thus, even if the storage of model weights is not a concern, prompt-based fine-tuning is still a promising approach for fine-tuning models as it retains more knowledge related to old centers.
- 4.
- The prompt-based fine-tuning of Swin-UNETR exhibits a similar pattern to that of UNETR. However, the loss in performance on old-center data for the conventional fine-tuning methods is less prominent for some centers compared to that of UNETR. This can be explained by the inductive biases in Swin-UNETR, which employs MSA within local shifted windows and merges patch embeddings at deeper layers. Swin-UNETR requires further optimization with regard to prompt position to further improve its performance.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Fine-Tuning | None | Partial | Full | Shallow Prompts | Deep Prompts |
|---|---|---|---|---|---|---|
| UNETR | - | 0.025 M | 96 M | 0.038 M | 0.15 M | |
| Swin-UNETR | - | 0.055 M | 62 M | 0.073 M | - |
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CT | Computed tomography |
| PET | Positron emission tomography |
| ViT | Vision transformer |
| CNN | Convolutional neural networks |
| MSA | Multi-head self attention |
Appendix A
Appendix A.1. Experimental Settings and Augmentations
| Hyperparameters | Full | Shallow Prompt | Deep Prompt |
|---|---|---|---|
| Optimizer | AdamW | SGD | SGD |
| lr | 1 × 10 | 0.05 | 0.05 |
| Weight decay | 1 × 10 | 0 | 0 |
| Learning rate scheduler | - | cosine decay | cosine decay |
| Total epochs | 100 | 100 | 100 |
| Batch size | 3 | 3 | 3 |
| Augmentations | Axis | Probability | Size |
|---|---|---|---|
| Orientation | PLS | - | - |
| CT/PET Concatenation | 1 | - | - |
| Normalization | - | - | - |
| Random crop | - | 0.5 | |
| Random flip | x, y, z | 0.2 | - |
| Rotate by 90 (up to ) | x, y | 0.2 | - |
| Fine-Tuning | Runtime (min) | GPU Consumption (GB) |
|---|---|---|
| Partial | 75 | 15.060 |
| Full | 101 | 41.763 |
| Shallow prompt | 76 | 19.275 |
| Deep prompt | 78 | 19.361 |
Appendix A.2. Five-Fold Results per Center
| Fold | No Finetuning | Partial Finetuning | Full Finetuning | Shallow Prompt | Deep Prompt |
|---|---|---|---|---|---|
| 1 | 0.6112 | 0.6813 | 0.6307 | 0.6302 | 0.6344 |
| 2 | 0.7442 | 0.7917 | 0.7596 | 0.7519 | 0.7449 |
| 3 | 0.6399 | 0.6627 | 0.7285 | 0.6910 | 0.6926 |
| 4 | 0.6919 | 0.7241 | 0.7551 | 0.7417 | 0.7518 |
| 5 | 0.6663 | 0.7165 | 0.7753 | 0.7523 | 0.7751 |
| 0.6708 | 0.7153 | 0.7298 | 0.7134 | 0.7198 |
| Fold | No Finetuning | Partial Finetuning | Full Finetuning | Shallow Prompt | Deep Prompt |
|---|---|---|---|---|---|
| 1 | 0.7861 | 0.8061 | 0.8058 | 0.8035 | 0.8150 |
| 2 | 0.7825 | 0.7975 | 0.7884 | 0.7886 | 0.7842 |
| 3 | 0.6875 | 0.6981 | 0.6906 | 0.6903 | 0.6912 |
| 4 | 0.7947 | 0.8196 | 0.8125 | 0.8103 | 0.8176 |
| 5 | 0.7987 | 0.8047 | 0.8300 | 0.8107 | 0.8075 |
| 0.7699 | 0.7852 | 0.7855 | 0.7807 | 0.7831 |
| Fold | No Finetuning | Partial Finetuning | Full Finetuning | Shallow Prompt | Deep Prompt |
|---|---|---|---|---|---|
| 1 | 0.8009 | 0.8017 | 0.8089 | 0.8086 | 0.8133 |
| 2 | 0.7387 | 0.7343 | 0.7414 | 0.7410 | 0.7392 |
| 3 | 0.7626 | 0.7559 | 0.7541 | 0.7702 | 0.7733 |
| 4 | 0.7668 | 0.7690 | 0.7675 | 0.7697 | 0.7629 |
| 5 | 0.7882 | 0.7995 | 0.8077 | 0.7981 | 0.8048 |
| 0.7714 | 0.7721 | 0.7759 | 0.7775 | 0.7799 |
| Fold | No Finetuning | Partial Finetuning | Full Finetuning | Shallow Prompt | Deep Prompt |
|---|---|---|---|---|---|
| 1 | 0.6368 | 0.6496 | 0.6633 | 0.6555 | 0.6454 |
| 2 | 0.7516 | 0.7631 | 0.7667 | 0.7609 | 0.7682 |
| 3 | 0.7832 | 0.8014 | 0.8013 | 0.8091 | 0.8063 |
| 4 | 0.8243 | 0.8340 | 0.8422 | 0.8339 | 0.8413 |
| 5 | 0.6645 | 0.6812 | 0.6959 | 0.6910 | 0.7043 |
| 0.7321 | 0.7459 | 0.7539 | 0.7501 | 0.7531 |
| Fold | No Finetuning | Partial Finetuning | Full Finetuning | Shallow Prompt | Deep Prompt |
|---|---|---|---|---|---|
| 1 | 0.7258 | 0.7284 | 0.7750 | 0.7492 | 0.7571 |
| 2 | 0.7384 | 0.7457 | 0.7736 | 0.7464 | 0.7538 |
| 3 | 0.6843 | 0.6970 | 0.7159 | 0.6979 | 0.7000 |
| 4 | 0.7426 | 0.7500 | 0.7584 | 0.7504 | 0.7515 |
| 5 | 0.7207 | 0.7279 | 0.7434 | 0.7258 | 0.7271 |
| 0.7224 | 0.7298 | 0.7533 | 0.7339 | 0.7379 |
| Fold | No Finetuning | Partial Finetuning | Full Finetuning | Shallow Prompt | Deep Prompt |
|---|---|---|---|---|---|
| 1 | 0.7887 | 0.8024 | 0.8062 | 0.7994 | 0.7955 |
| 2 | 0.7511 | 0.7534 | 0.7622 | 0.7543 | 0.7566 |
| 3 | 0.8100 | 0.8031 | 0.8075 | 0.8125 | 0.8114 |
| 4 | 0.8035 | 0.8225 | 0.8262 | 0.8148 | 0.8191 |
| 5 | 0.7852 | 0.7935 | 0.7883 | 0.7878 | 0.7739 |
| 0.7877 | 0.7949 | 0.7981 | 0.7938 | 0.7913 |
| Fold | No Finetuning | Partial Finetuning | Full Finetuning | Shallow Prompt | Deep Prompt |
|---|---|---|---|---|---|
| 1 | 0.6632 | 0.6903 | 0.7132 | 0.7201 | 0.7453 |
| 2 | 0.7001 | 0.7188 | 0.7265 | 0.7076 | 0.7194 |
| 3 | 0.6796 | 0.6797 | 0.6933 | 0.6829 | 0.6854 |
| 4 | 0.5926 | 0.6229 | 0.6400 | 0.6299 | 0.6264 |
| 5 | 0.7203 | 0.7817 | 0.7762 | 0.7554 | 0.7632 |
| 0.6712 | 0.6987 | 0.7098 | 0.6992 | 0.708 |
Appendix A.3. Ablation for Prompt Position and Number of Prompts
| Position | Avg Dice | P-Tumor | Lymph |
|---|---|---|---|
| shallow | 0.6302 | 0.7778 | 0.4827 |
| 1 | 0.6307 | 0.7793 | 0.4820 |
| 2 | 0.6305 | 0.7775 | 0.4834 |
| 3 | 0.6303 | 0.7765 | 0.4840 |
| 4 | 0.6306 | 0.7774 | 0.4837 |
| 5 | 0.6293 | 0.7775 | 0.4811 |
| 6 | 0.6306 | 0.7792 | 0.4820 |
| 7 | 0.6295 | 0.7785 | 0.4806 |
| 8 | 0.6303 | 0.7783 | 0.4823 |
| 9 | 0.6306 | 0.7789 | 0.4823 |
| 10 | 0.6304 | 0.7785 | 0.4822 |
| 11 | 0.6304 | 0.7789 | 0.4819 |
| 12 | 0.6303 | 0.7786 | 0.4819 |
| Prompts on Skip Connections | Avg Dice | P-Tumor | Lymph |
|---|---|---|---|
| ✕ | 0.6342 | 0.7753 | 0.4931 |
| ✓ | 0.6289 | 0.7778 | 0.4810 |
| Number of Prompts | Avg Dice | P-Tumor | Lymph |
|---|---|---|---|
| 10 | 0.6292 | 0.7781 | 0.4802 |
| 30 | 0.6291 | 0.7766 | 0.4816 |
| 50 | 0.6302 | 0.7778 | 0.4827 |
| 70 | 0.6307 | 0.7788 | 0.4827 |
| 90 | 0.6300 | 0.7774 | 0.4827 |
| 100 | 0.6294 | 0.7774 | 0.4815 |
References
- Alalwan, N.; Abozeid, A.; ElHabshy, A.; Alzahrani, A. Efficient 3D Deep Learning Model for Medical Image Semantic Segmentation. Alex. Eng. J. 2021, 60, 1231–1239. [Google Scholar] [CrossRef]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical Transformer: Gated Axial-Attention for Medical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2021, Strasbourg, France, 27 September–1 October 2021; de Bruijne, M., Cattin, P.C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., Essert, C., Eds.; Springer International Publishing: Cham, Swizterland, 2021; pp. 36–46. [Google Scholar]
- Zhou, H.; Guo, J.; Zhang, Y.; Yu, L.; Wang, L.; Yu, Y. nnFormer: Interleaved Transformer for Volumetric Segmentation. arXiv 2021, arXiv:2109.03201. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. UNETR: Transformers for 3D Medical Image Segmentation. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; IEEE Computer Society: Los Alamitos, CA, USA, 2022; pp. 1748–1758. [Google Scholar] [CrossRef]
- Yan, Q.; Liu, S.; Xu, S.; Dong, C.; Li, Z.; Shi, J.Q.; Zhang, Y.; Dai, D. 3D Medical image segmentation using parallel transformers. Pattern Recognit. 2023, 138, 109432. [Google Scholar] [CrossRef]
- Yu, X.; Wang, J.; Hong, Q.Q.; Teku, R.; Wang, S.H.; Zhang, Y.D. Transfer learning for medical images analyses: A survey. Neurocomputing 2022, 489, 230–254. [Google Scholar] [CrossRef]
- Yu, Y.; Lin, H.; Meng, J.; Wei, X.; Guo, H.; Zhao, Z. Deep Transfer Learning for Modality Classification of Medical Images. Information 2017, 8, 91. [Google Scholar] [CrossRef] [Green Version]
- Karimi, D.; Warfield, S.K.; Gholipour, A. Transfer learning in medical image segmentation: New insights from analysis of the dynamics of model parameters and learned representations. Artif. Intell. Med. 2021, 116, 102078. [Google Scholar] [CrossRef]
- Wardi, G.; Carlile, M.; Holder, A.; Shashikumar, S.; Hayden, S.R.; Nemati, S. Predicting Progression to Septic Shock in the Emergency Department Using an Externally Generalizable Machine-Learning Algorithm. Ann. Emerg. Med. 2021, 77, 395–406. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2002, arXiv:2002.05709. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.B.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Lin, K.; Heckel, R. Vision Transformers Enable Fast and Robust Accelerated MRI. In Proceedings of the 5th International Conference on Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022; Konukoglu, E., Menze, B., Venkataraman, A., Baumgartner, C., Dou, Q., Albarqouni, S., Eds.; 2022; Volume 172, pp. 774–795. [Google Scholar]
- Glocker, B.; Robinson, R.; Castro, D.C.; Dou, Q.; Konukoglu, E. Machine Learning with Multi-Site Imaging Data: An Empirical Study on the Impact of Scanner Effects. arXiv 2019, arXiv:1910.04597. [Google Scholar] [CrossRef]
- Ma, Q.; Zhang, T.; Zanetti, M.V.; Shen, H.; Satterthwaite, T.D.; Wolf, D.H.; Gur, R.E.; Fan, Y.; Hu, D.; Busatto, G.F.; et al. Classification of multi-site MR images in the presence of heterogeneity using multi-task learning. Neuroimage Clin. 2018, 19, 476–486. [Google Scholar] [CrossRef] [PubMed]
- Barone, A.V.M.; Haddow, B.; Germann, U.; Sennrich, R. Regularization techniques for fine-tuning in neural machine translation. arXiv 2017, arXiv:1707.09920. [Google Scholar]
- Kumar, A.; Raghunathan, A.; Jones, R.; Ma, T.; Liang, P. Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution. arXiv 2022, arXiv:2202.10054. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.N. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 709–727. [Google Scholar]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.R.; Xu, D. Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. In Proceedings of the Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, Granada, Spain, 16 September 2018; Crimi, A., Bakas, S., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 272–284. [Google Scholar]
- Oreiller, V.; Andrearczyk, V.; Jreige, M.; Boughdad, S.; Elhalawani, H.; Castelli, J.; Vallières, M.; Zhu, S.; Xie, J.; Peng, Y.; et al. Head and neck tumor segmentation in PET/CT: The HECKTOR challenge. Med. Image Anal. 2022, 77, 102336. [Google Scholar] [CrossRef] [PubMed]
- Bertels, J.; Eelbode, T.; Berman, M.; Vandermeulen, D.; Maes, F.; Bisschops, R.; Blaschko, M.B. Optimizing the Dice Score and Jaccard Index for Medical Image Segmentation: Theory & Practice. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019. [Google Scholar]
- Wilcoxon, F. Individual Comparisons by Ranking Methods. In Breakthroughs in Statistics: Methodology and Distribution; Springer: New York, NY, USA, 1992; pp. 196–202. [Google Scholar]




| Center | City, Country | PET/CT Scanner | Number of Samples |
|---|---|---|---|
| HGJ | Montreal, Canada | Discovery ST, GE Healthcare | 55 |
| CHUS | Sherbrooke, Canada | GeminiGXL 16, Philips | 72 |
| HMR | Montreal, Canada | Discovery STE, GE Healthcare | 18 |
| CHUM | Montreal, Canada | Discovery STE, GE Healthcare | 56 |
| CHUV | Vaud, Switzerland | Discovery D690 TOF, GE Healthcare | 53 |
| CHUP | Poitiers, France | Biograph mCT 40 ToF, Siemens | 72 |
| MDA | Texas, USA | Discovery HR, RX, ST, and STE (GE Healthcare) | 197 |
| Model | Fine-Tuning | None | Partial | Full | Shallow Prompts | Deep Prompts | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Center(s) | Old | New () | Old | New () | Old | New () | Old | New () | Old | New () | |
| CHUP | 0.7869 | 0.6708 | 0.7027 | 0.7153 | 0.7048 | 0.7298 | 0.7507 | 0.7134 | 0.7644 | 0.7198 | |
| CHUS | 0.7665 | 0.7699 | 0.7574 | 0.7852 | 0.7574 | 0.7855 | 0.7683 | 0.7807 | 0.7688 | 0.7831 | |
| HGJ | 0.7674 | 0.7877 | 0.7479 | 0.7949 | 0.7439 | 0.7981 | 0.7607 | 0.7938 | 0.7639 | 0.7913 | |
| UNETR | MDA | 0.7659 | 0.7224 | 0.7635 | 0.7298 | 0.7609 | 0.7533 | 0.7667 | 0.7339 | 0.7657 | 0.7379 |
| CHUV | 0.7704 | 0.7321 | 0.7622 | 0.7459 | 0.7665 | 0.7539 | 0.7723 | 0.7501 | 0.7724 | 0.7531 | |
| CHUM | 0.7765 | 0.7714 | 0.7584 | 0.7721 | 0.7623 | 0.7759 | 0.7734 | 0.7775 | 0.7753 | 0.7799 | |
| HMR | 0.7731 | 0.6712 | 0.7629 | 0.6987 | 0.7726 | 0.7099 | 0.7769 | 0.6992 | 0.7760 | 0.7080 | |
| Swin- | CHUS | 0.7584 | 0.7695 | 0.7569 | 0.7890 | 0.7541 | 0.7905 | 0.7613 | 0.7797 | - | - |
| UNETR | CHUM | 0.7763 | 0.7684 | 0.7642 | 0.7685 | 0.7667 | 0.7706 | 0.7719 | 0.7698 | - | - |
| CHUP | 0.7835 | 0.6609 | 0.6960 | 0.7373 | 0.7026 | 0.7419 | 0.7320 | 0.7136 | - | - | |
| MDA | 0.7616 | 0.7291 | 0.7644 | 0.7413 | 0.7541 | 0.7522 | 0.7590 | 0.7352 | - | - | |
| Partial? | Full? | Shallow? | |
|---|---|---|---|
| Is the performance of deep prompt-based fine-tuned models on old centers statistically better than | ✓ | ✓ | ✕ |
| Is the performance of deep prompt-based fine-tuned models on new centers statistically better than | ✓ | ✕ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, N.; Ridzuan, M.; Majzoub, R.A.; Yaqub, M. Prompt-Based Tuning of Transformer Models for Multi-Center Medical Image Segmentation of Head and Neck Cancer. Bioengineering 2023, 10, 879. https://doi.org/10.3390/bioengineering10070879
Saeed N, Ridzuan M, Majzoub RA, Yaqub M. Prompt-Based Tuning of Transformer Models for Multi-Center Medical Image Segmentation of Head and Neck Cancer. Bioengineering. 2023; 10(7):879. https://doi.org/10.3390/bioengineering10070879
Chicago/Turabian StyleSaeed, Numan, Muhammad Ridzuan, Roba Al Majzoub, and Mohammad Yaqub. 2023. "Prompt-Based Tuning of Transformer Models for Multi-Center Medical Image Segmentation of Head and Neck Cancer" Bioengineering 10, no. 7: 879. https://doi.org/10.3390/bioengineering10070879