
Continual Learning of a Transformer-Based Deep Learning Classifier Using an Initial Model from Action Observation EEG Data to Online Motor Imagery Classification
Abstract
:1. Introduction
2. Materials and Methods
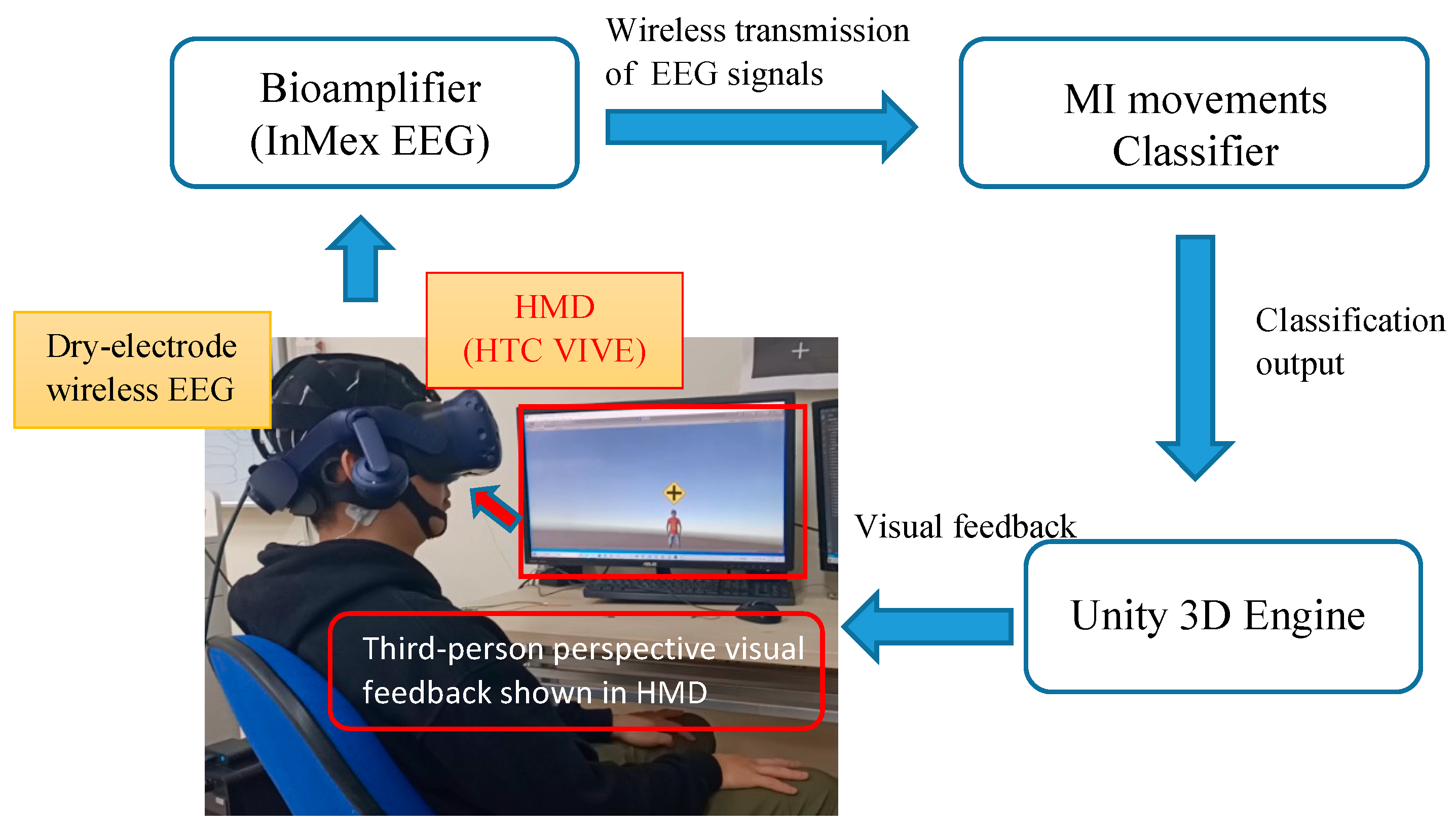
2.1. Subjects and EEG Recordings
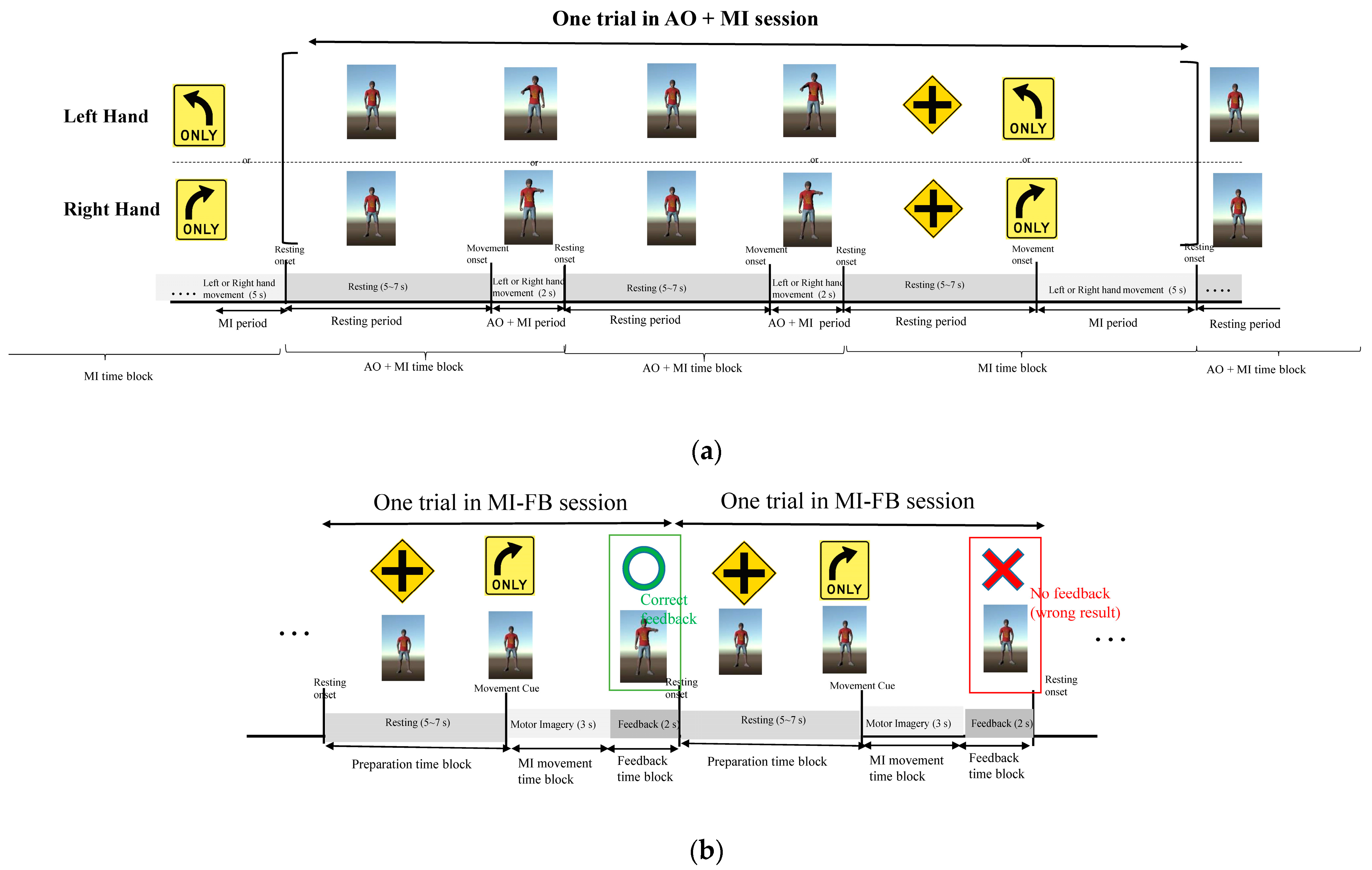
2.2. Experimental Task
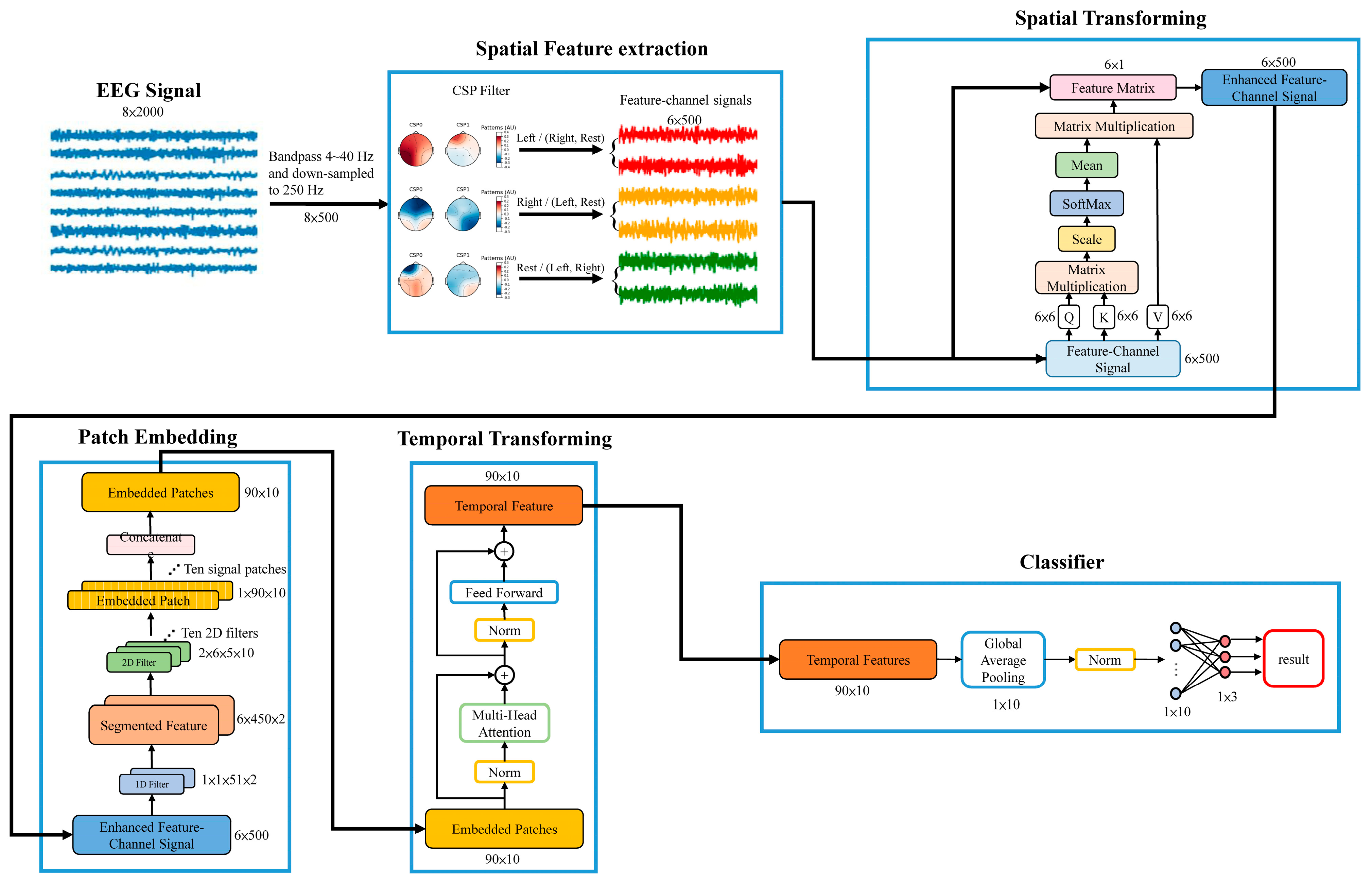
2.3. Transformer-Baed Spatial-Temporal Network (TSTN) for MI Classification
2.3.1. Spatial Filtering Using Common Spatial Pattern (CSP)
2.3.2. Spatial Transforming for the Enhancement of Feature-Channel Signals
2.3.3. Patch Embedding of Feature-Channel Signals
2.3.4. Temporal Transforming for Embedded Patches
2.3.5. Classifier
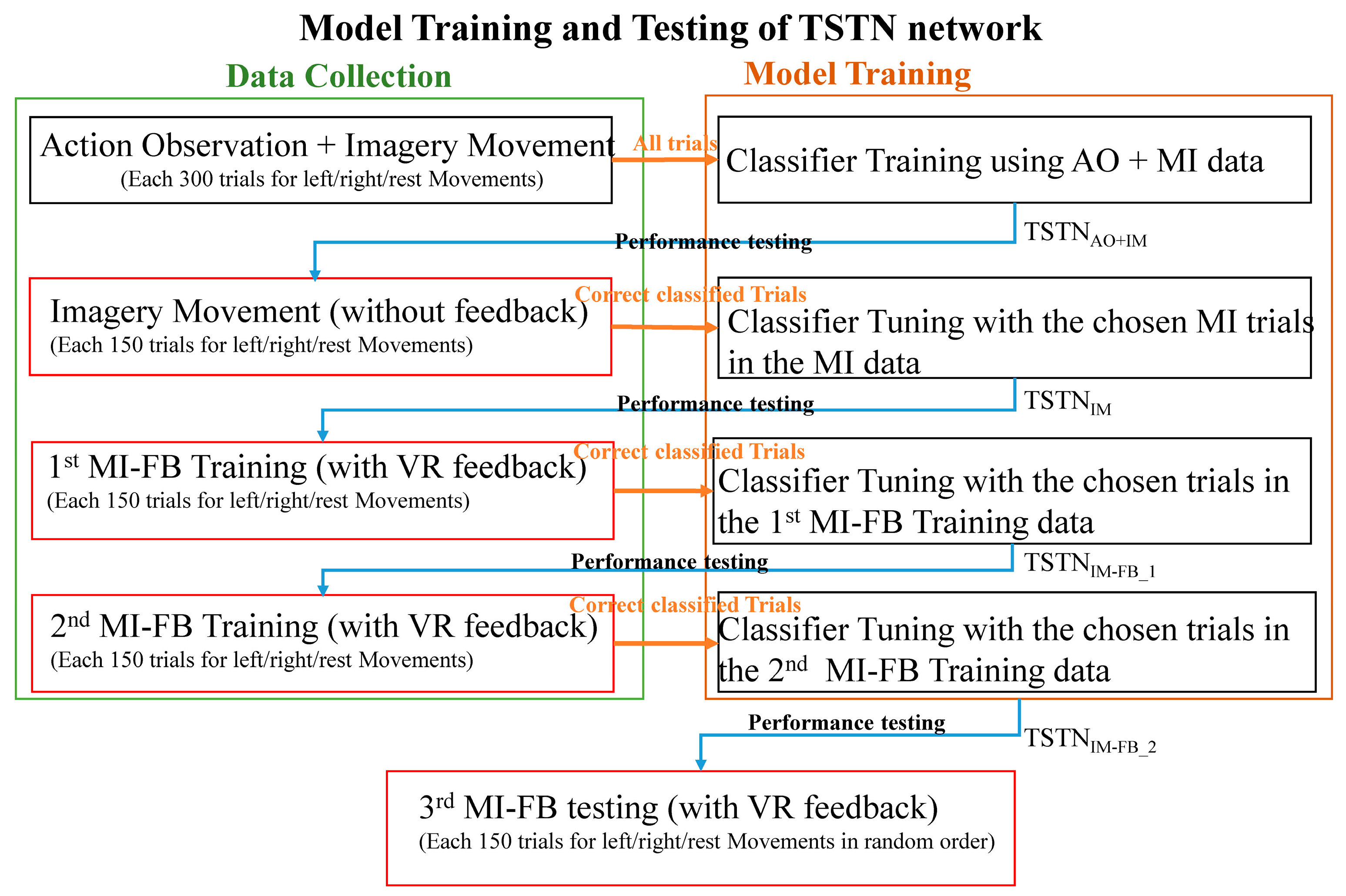
2.4. Training of the TSTN Classifier
2.5. Comparing the Detection Performance with Other Classifiers
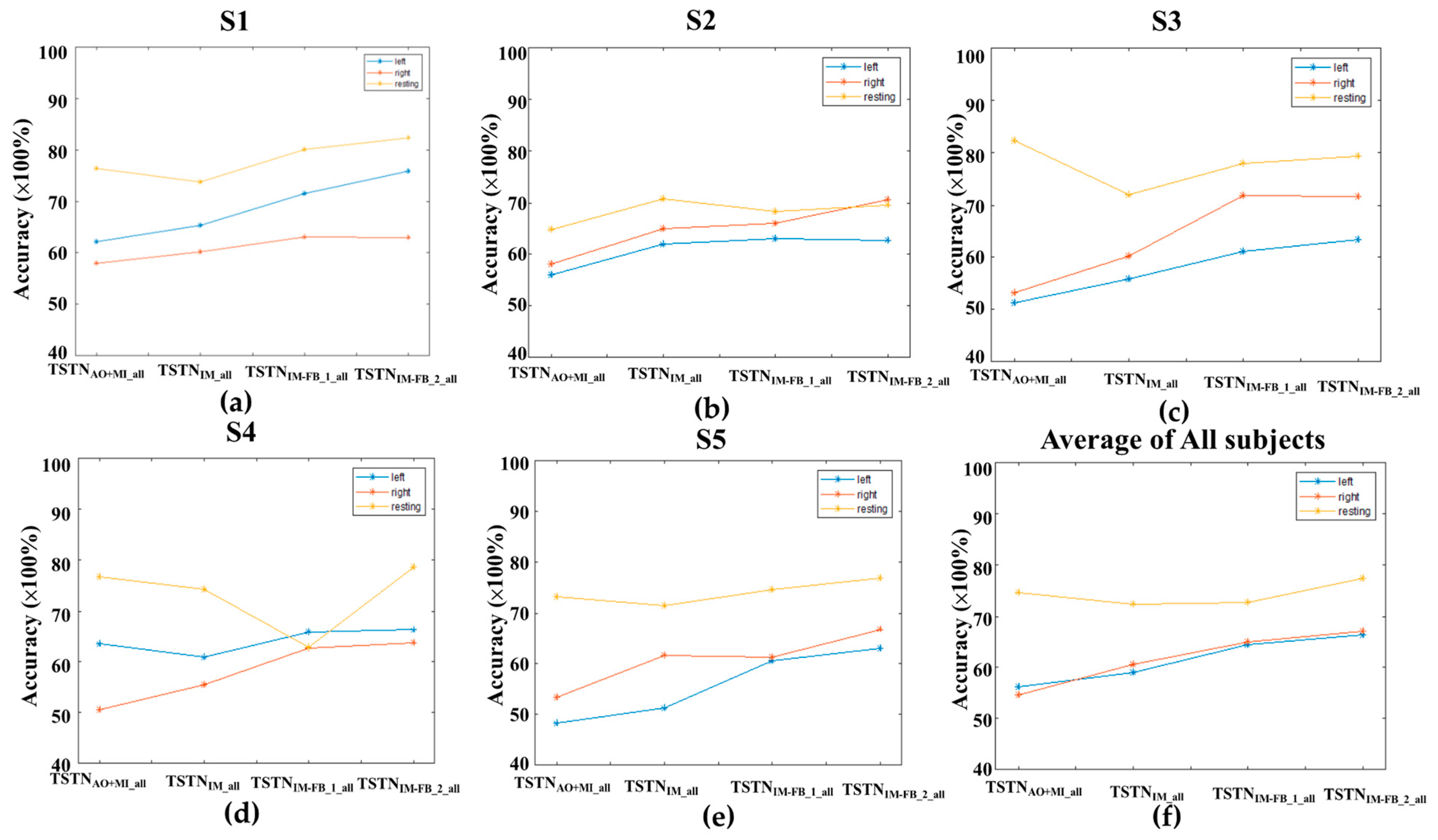
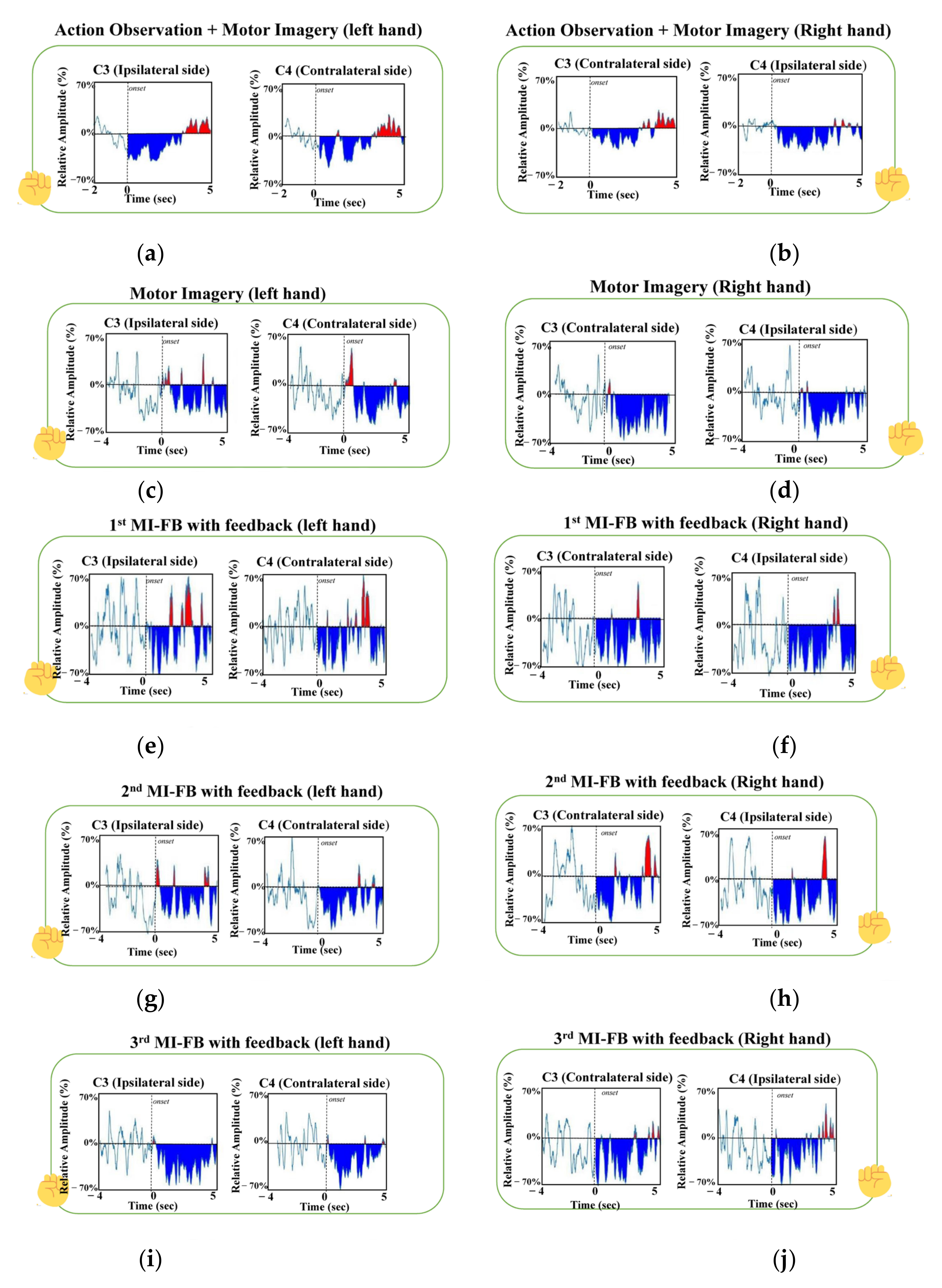
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Wolpaw, J.R. Brain-Computer Interfaces (BCIs) for Communication and Control. In Proceedings of the 9th International ACM SIGACCESS Conference on Computers and Accessibility, New York, NY, USA, 15–17 October 2007; pp. 1–2. [Google Scholar]
- Chen, C.-H.; Ho, M.-S.; Shyu, K.-K.; Hsu, K.-C.; Wang, K.-W.; Lee, P.-L. A noninvasive brain computer interface using visually-induced near-infrared spectroscopy responses. Neurosci. Lett. 2014, 580, 22–26. [Google Scholar] [CrossRef] [PubMed]
- Behzad, R.; Behzad, A. The Role of EEG in the Diagnosis and Management of Patients with Sleep Disorders. J. Behav. Brain Sci. 2021, 11, 257–266. [Google Scholar] [CrossRef]
- Follis, J.L.; Lai, D. Modeling Volatility Characteristics of Epileptic EEGs using GARCH Models. Signals 2020, 1, 26–46. [Google Scholar] [CrossRef]
- Ahmed, M.Z.I.; Sinha, N.; Phadikar, S.; Ghaderpour, E. Automated Feature Extraction on AsMap for Emotion Classification Using EEG. Sensors 2022, 22, 2346. [Google Scholar] [CrossRef]
- Phadikar, S.; Sinha, N.; Ghosh, R.; Ghaderpour, E. Automatic Muscle Artifacts Identification and Removal from Single-Channel EEG Using Wavelet Transform with Meta-Heuristically Optimized Non-Local Means Filter. Sensors 2022, 22, 2948. [Google Scholar] [CrossRef]
- Jiang, X.; Bian, G.-B.; Tian, Z. Removal of artifacts from EEG signals: A review. Sensors 2019, 19, 987. [Google Scholar] [CrossRef]
- Wolpaw, J.R.; Birbaumer, N.; Heetderks, W.J.; McFarland, D.J.; Peckham, P.H.; Schalk, G.; Donchin, E.; Quatrano, L.A.; Robinson, C.J.; Vaughan, T.M. Brain-computer interface technology: A review of the first international meeting. IEEE Trans. Rehabil. Eng. 2000, 8, 164–173. [Google Scholar] [CrossRef]
- Ahn, M.; Jun, S.C. Performance variation in motor imagery brain–computer interface: A brief review. J. Neurosci. Methods 2015, 243, 103–110. [Google Scholar] [CrossRef]
- Kaongoen, N.; Choi, J.; Jo, S. Speech-imagery-based brain–computer interface system using ear-EEG. J. Neural Eng. 2021, 18, 016023. [Google Scholar] [CrossRef]
- Dornhege, G.; Blankertz, B.; Curio, G. Speeding up classification of multi-channel brain-computer interfaces: Common spatial patterns for slow cortical potentials. In Proceedings of the First International IEEE EMBS Conference on Neural Engineering, Capri, Italy, 20–22 March 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 595–598. [Google Scholar]
- Lee, P.-L.; Sie, J.-J.; Liu, Y.-J.; Wu, C.-H.; Lee, M.-H.; Shu, C.-H.; Li, P.-H.; Sun, C.-W.; Shyu, K.-K. An SSVEP-actuated brain computer interface using phase-tagged flickering sequences: A cursor system. Ann. Biomed. Eng. 2010, 38, 2383–2397. [Google Scholar] [CrossRef]
- Lee, P.-L.; Hsieh, J.-C.; Wu, C.-H.; Shyu, K.-K.; Wu, Y.-T. Brain computer interface using flash onset and offset visual evoked potentials. Clin. Neurophysiol. 2008, 119, 605–616. [Google Scholar] [CrossRef]
- Hill, N.J.; Schölkopf, B. An online brain–computer interface based on shifting attention to concurrent streams of auditory stimuli. J. Neural Eng. 2012, 9, 026011. [Google Scholar] [CrossRef] [PubMed]
- Smith, E.; Delargy, M. Locked-in syndrome. BMJ 2005, 330, 406–409. [Google Scholar] [CrossRef] [PubMed]
- Padfield, N.; Zabalza, J.; Zhao, H.; Masero, V.; Ren, J. EEG-based brain-computer interfaces using motor-imagery: Techniques and challenges. Sensors 2019, 19, 1423. [Google Scholar] [CrossRef] [PubMed]
- Khare, S.K.; Gaikwad, N.; Bokde, N.D. An Intelligent Motor Imagery Detection System Using Electroencephalography with Adaptive Wavelets. Sensors 2022, 22, 8128. [Google Scholar] [CrossRef] [PubMed]
- Khare, S.K.; Bajaj, V. A facile and flexible motor imagery classification using electroencephalogram signals. Comput. Methods Programs Biomed. 2020, 197, 105722. [Google Scholar] [CrossRef]
- Stefano Filho, C.A.; Attux, R.; Castellano, G. Actual, sham and no-feedback effects in motor imagery practice. Biomed. Signal Process. Control 2022, 71, 103262. [Google Scholar] [CrossRef]
- Alimardani, M.; Nishio, S.; Ishiguro, H. Brain-computer interface and motor imagery training: The role of visual feedback and embodiment. Evol. BCI Ther.-Engag. Brain State Dyn. 2018, 2, 64. [Google Scholar]
- Friedman, D.; Leeb, R.; Pfurtscheller, G.; Slater, M. Human–computer interface issues in controlling virtual reality with brain–computer interface. Hum. Comput. Interact. 2010, 25, 67–94. [Google Scholar] [CrossRef]
- McCreadie, K.A.; Coyle, D.H.; Prasad, G. Sensorimotor learning with stereo auditory feedback for a brain–computer interface. Med. Biol. Eng. Comput. 2013, 51, 285–293. [Google Scholar] [CrossRef]
- Nijboer, F.; Furdea, A.; Gunst, I.; Mellinger, J.; McFarland, D.J.; Birbaumer, N.; Kübler, A. An auditory brain–computer interface (BCI). J. Neurosci. Methods 2008, 167, 43–50. [Google Scholar] [CrossRef] [PubMed]
- Ishihara, W.; Moxon, K.; Ehrman, S.; Yarborough, M.; Panontin, T.L.; Nathan-Roberts, D. Feedback modalities in brain–computer interfaces: A systematic review. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2020, 64, 1186–1190. [Google Scholar]
- Jo, S.; Choi, J.W. Effective motor imagery training with visual feedback for non-invasive brain computer interface. In Proceedings of the 2018 6th International Conference on Brain-Computer Interface (BCI), Gangwon, Korea, 15–17 January 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Ziadeh, H.; Gulyas, D.; Nielsen, L.D.; Lehmann, S.; Nielsen, T.B.; Kjeldsen, T.K.K.; Hougaard, B.I.; Jochumsen, M.; Knoche, H. “Mine Works Better”: Examining the Influence of Embodiment in Virtual Reality on the Sense of Agency During a Binary Motor Imagery Task with a Brain-Computer Interface. Front. Psychol. 2021, 12, 6174–6184. [Google Scholar] [CrossRef] [PubMed]
- Achanccaray, D.; Pacheco, K.; Carranza, E.; Hayashibe, M. Immersive virtual reality feedback in a brain computer interface for upper limb rehabilitation. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1006–1010. [Google Scholar]
- Braun, N.; Emkes, R.; Thorne, J.D.; Debener, S. Embodied neurofeedback with an anthropomorphic robotic hand. Sci. Rep. 2016, 6, 1–13. [Google Scholar] [CrossRef]
- Alimardani, M.; Nishio, S.; Ishiguro, H. Effect of biased feedback on motor imagery learning in BCI-teleoperation system. Front. Syst. Neurosci. 2014, 8, 52. [Google Scholar] [CrossRef]
- Kübler, A.; Neumann, N.; Wilhelm, B.; Hinterberger, T.; Birbaumer, N. Predictability of brain-computer communication. J. Psychophysiol. 2004, 18, 121–129. [Google Scholar] [CrossRef]
- Montemurro, N.; Condino, S.; Carbone, M.; Cattari, N.; D’Amato, R.; Cutolo, F.; Ferrari, V. Brain Tumor and Augmented Reality: New Technologies for the Future. Int. J. Environ. Res. Public Health 2022, 19, 6347. [Google Scholar]
- Sayadi, L.R.; Naides, A.; Eng, M.; Fijany, A.; Chopan, M.; Sayadi, J.J.; Shaterian, A.; Banyard, D.A.; Evans, G.R.; Vyas, R. The new frontier: A review of augmented reality and virtual reality in plastic surgery. Aesthetic Surg. J. 2019, 39, 1007–1016. [Google Scholar] [CrossRef]
- Buccino, G. Action observation treatment: A novel tool in neurorehabilitation. Philos. Trans. R. Soc. B Biol. Sci. 2014, 369, 20130185. [Google Scholar] [CrossRef]
- Altschuler, E.L.; Wisdom, S.B.; Stone, L.; Foster, C.; Galasko, D.; Llewellyn, D.M.E.; Ramachandran, V.S. Rehabilitation of hemiparesis after stroke with a mirror. Lancet 1999, 353, 2035–2036. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, Y.-W.; Lin, Y.-H.; Zhu, J.-D.; Wu, C.-Y.; Lin, Y.-P.; Chen, C.-C. Treatment effects of upper limb action observation therapy and mirror therapy on rehabilitation outcomes after subacute stroke: A pilot study. Behav. Neurol. 2020, 2020, e6250524. [Google Scholar] [CrossRef]
- Vogt, S.; Di Rienzo, F.; Collet, C.; Collins, A.; Guillot, A. Multiple roles of motor imagery during action observation. Front. Hum. Neurosci. 2013, 7, 807. [Google Scholar] [CrossRef]
- Hardwick, R.M.; Caspers, S.; Eickhoff, S.B.; Swinnen, S.P. Neural correlates of motor imagery, action observation, and movement execution: A comparison across quantitative meta-analyses. BioRxiv 2018, 94, 31–44. [Google Scholar]
- Eaves, D.L.; Riach, M.; Holmes, P.S.; Wright, D.J. Motor imagery during action observation: A brief review of evidence, theory and future research opportunities. Front. Neurosci. 2016, 10, 514. [Google Scholar] [CrossRef] [Green Version]
- Yu, T.; Xiao, J.; Wang, F.; Zhang, R.; Gu, Z.; Cichocki, A.; Li, Y. Enhanced motor imagery training using a hybrid BCI with feedback. IEEE Trans. Biomed. Eng. 2015, 62, 1706–1717. [Google Scholar] [CrossRef]
- Song, Y.; Jia, X.; Yang, L.; Xie, L. Transformer-based spatial-temporal feature learning for eeg decoding. arXiv 2021, arXiv:2106.11170. [Google Scholar]
- Wang, Y.; Gao, S.; Gao, X. Common spatial pattern method for channel selelction in motor imagery based brain-computer interface. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 1–4 September 2005; IEEE: Piscataway, NJ, USA, 2006; pp. 5392–5395. [Google Scholar]
- Fox, N.A.; Bakermans-Kranenburg, M.J.; Yoo, K.H.; Bowman, L.C.; Cannon, E.N.; Vanderwert, R.E.; Ferrari, P.F.; Van IJzendoorn, M.H. Assessing human mirror activity with EEG mu rhythm: A meta-analysis. Psychol. Bull. 2016, 142, 291. [Google Scholar] [CrossRef] [PubMed]
- Barbero, Á.; Grosse-Wentrup, M. Biased feedback in brain-computer interfaces. J. Neuroeng. Rehabil. 2010, 7, 34. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef]
- Choi, D.; Lee, Y.; Jeong, W.; Lee, S.; Kang, D.; Lee, M. Evaluation of Motor Imagery Using Combined Cue Based EEG-Brain Computer Interface. In Proceedings of the 5th Kuala Lumpur International Conference on Biomedical Engineering 2011, Kuala Lumpur, Malaysia, 20–23 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 516–518. [Google Scholar]
- Alimardani, M.; Gherman, D.-E. Individual Differences in Motor Imagery BCIs: A Study of Gender, Mental States and Mu Suppression. In Proceedings of the 2022 10th International Winter Conference on Brain-Computer Interface (BCI), Gangwon-do, Republic of Korea, 21–23 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–7. [Google Scholar]
- Hung, C.-I.; Lee, P.-L.; Wu, Y.-T.; Chen, L.-F.; Yeh, T.-C.; Hsieh, J.-C. Recognition of motor imagery electroencephalography using independent component analysis and machine classifiers. Ann. Biomed. Eng. 2005, 33, 1053–1070. [Google Scholar] [CrossRef]
- Cengiz, B.; Vurallı, D.; Zinnuroğlu, M.; Bayer, G.; Golmohammadzadeh, H.; Günendi, Z.; Turgut, A.E.; İrfanoğlu, B.; Arıkan, K.B. Analysis of mirror neuron system activation during action observation alone and action observation with motor imagery tasks. Exp. Brain Res. 2018, 236, 497–503. [Google Scholar] [CrossRef]
- Zhang, J.J.; Fong, K.N.; Welage, N.; Liu, K.P. The activation of the mirror neuron system during action observation and action execution with mirror visual feedback in stroke: A systematic review. Neural Plast. 2018, 2018, e2321045. [Google Scholar] [CrossRef] [PubMed]
- Villiger, M.; Estévez, N.; Hepp-Reymond, M.-C.; Kiper, D.; Kollias, S.S.; Eng, K.; Hotz-Boendermaker, S. Enhanced activation of motor execution networks using action observation combined with imagination of lower limb movements. PloS ONE 2013, 8, e72403. [Google Scholar] [CrossRef] [PubMed]
- Mouthon, A.; Ruffieux, J.; Wälchli, M.; Keller, M.; Taube, W. Task-dependent changes of corticospinal excitability during observation and motor imagery of balance tasks. Neuroscience 2015, 303, 535–543. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taube, W.; Mouthon, M.; Leukel, C.; Hoogewoud, H.-M.; Annoni, J.-M.; Keller, M. Brain activity during observation and motor imagery of different balance tasks: An fMRI study. Cortex 2015, 64, 102–114. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Kim, J.; Yeon, J.; Ryu, J.; Park, J.-Y.; Chung, S.-C.; Kim, S.-P. Neural activity patterns in the human brain reflect tactile stickiness perception. Front. Hum. Neurosci. 2017, 11, 445. [Google Scholar] [CrossRef]
- Hosman, T.; Vilela, M.; Milstein, D.; Kelemen, J.N.; Brandman, D.M.; Hochberg, L.R.; Simeral, J.D. BCI decoder performance comparison of an LSTM recurrent neural network and a Kalman filter in retrospective simulation. In Proceedings of the 2019 9th International IEEE/EMBS Conference on Neural Engineering (NER), San Francisco, CA, USA, 20–23 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1066–1071. [Google Scholar]
- Fadziso, T. Overcoming the Vanishing Gradient Problem during Learning Recurrent Neural Nets (RNN). Asian J. Appl. Sci. Eng. 2020, 9, 207–218. [Google Scholar]
- Winkens, I.; Van Heugten, C.M.; Wade, D.T.; Habets, E.J.; Fasotti, L. Efficacy of time pressure management in stroke patients with slowed information processing: A randomized controlled trial. Arch. Phys. Med. Rehabil. 2009, 90, 1672–1679. [Google Scholar] [CrossRef]
- Pfurtscheller, G.; Da Silva, F.L. Event-related EEG/MEG synchronization and desynchronization: Basic principles. Clin. Neurophysiol. 1999, 110, 1842–1857. [Google Scholar] [CrossRef]
- Ahn, M.; Cho, H.; Ahn, S.; Jun, S.C. High theta and low alpha powers may be indicative of BCI-illiteracy in motor imagery. PLoS ONE 2013, 8, e80886. [Google Scholar] [CrossRef]
- Lotte, F.; Rimbert, S. How ERD Modulations during Motor Imageries Relate to Users’ Traits and BCI Performances. In Proceedings of the 44th International Engineering in Medicine and Biology Conference, Glasgow, UK, 11–15 July 2022. [Google Scholar]
- Rizzolatti, G.; Sinigaglia, C. The functional role of the parieto-frontal mirror circuit: Interpretations and misinterpretations. Nat. Rev. Neurosci. 2010, 11, 264–274. [Google Scholar] [CrossRef]
- Benzy, V.; Vinod, A.; Subasree, R.; Alladi, S.; Raghavendra, K. Motor imagery hand movement direction decoding using brain computer interface to aid stroke recovery and rehabilitation. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 3051–3062. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Z.; Allison, B.Z.; Jin, J.; Zhang, Y.; Wang, X.; Li, W.; Cichocki, A. Optimized motor imagery paradigm based on imagining Chinese characters writing movement. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1009–1017. [Google Scholar] [CrossRef] [PubMed]
- Higuchi, S.; Holle, H.; Roberts, N.; Eickhoff, S.B.; Vogt, S. Imitation and observational learning of hand actions: Prefrontal involvement and connectivity. Neuroimage 2012, 59, 1668–1683. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier (Test Target)/ Subject | TSTNAO+MI (IM Data) | TSTNMI (1st IM-FB Data) | TSTNMI-FB_1 (2nd IM-FB Data) | TSTNMI-FB_2 (3rd IM-FB Data) |
|---|---|---|---|---|
| Acc/Spec/F1 | Acc/Spec/F1 | Acc/Spec/F1 | Acc/Spec/F1 | |
| S1 | 0.73/0.88/0.73 | 0.73/0.87/0.74 | 0.78/0.90/0.78 | 0.83/0.92/0.83 |
| S2 | 0.58/0.79/0.59 | 0.66/0.83/0.67 | 0.72/0.87/0.72 | 0.73/0.87/0.73 |
| S3 | 0.61/0.80/0.61 | 0.62/0.87/0.62 | 0.73/0.87/0.73 | 0.75/0.89/0.75 |
| S4 | 0.61/0.80/0.61 | 0.65/0.83/0.65 | 0.73/0.84/0.74 | 0.73/0.87/0.74 |
| S5 | 0.60/0.80/0.61 | 0.73/0.87/0.74 | 0.78/0.89/0.78 | 0.80/0.90/0.80 |
| Averaged accuracy | 0.63/0.81/0.63 | 0.68/0.84/0.68 | 0.75/0.87/0.75 | 0.77/0.89/0.77 |
| Classifier (Test Target)/ Subject | TSTNAO+IM_All (MI Data) | TSTNIM_All (1st MI-FB) | TSTNIM-FB_1_All (2nd MI-FB) | TSTNIM-FB_2_All (3rd MI-FB) |
|---|---|---|---|---|
| Acc/Spec/F1 | Acc/Spec/F1 | Acc/Spec/F1 | Acc/Spec/F1 | |
| S1 | 0.65/0.77/0.64 | 0.660.83/0.67 | 0.71/0.85/0.71 | 0.73/0.85/0.73 |
| S2 | 0.59/0.79/0.59 | 0.65/0.82/0.66 | 0.65/0.83/0.65 | 0.67/0.83/0.67 |
| S3 | 0.62/0.78/0.62 | 0.62/0.83/0.62 | 0.70/0.85/0.70 | 0.71/0.85/0.71 |
| S4 | 0.63/0.81/0.63 | 0.63/0.81/0.63 | 0.65/0.84/0.65 | 0.69/0.83/0.69 |
| S5 | 0.58/79/0.58 | 0.61/0.81/0.62 | 0.65/0.83/0.65 | 0.68/0.84/0.68 |
| Averaged accuracy | 0.61/0.78/0.61 | 0.63/0.82/0.64 | 0.67/0.84/0.67 | 0.70/0.84/0.70 |
| Classifier/ Test Task | TSTN | SVMlinear | SVMpoly | SVMRBF | EEGNet [44] | DeepConvNet [45] |
|---|---|---|---|---|---|---|
| MI | 0.63 | 0.55 | 0.48 | 0.52 | 0.53 | 0.58 |
| 1st MI-FB | 0.68 | 0.60 | 0.53 | 0.59 | 0.59 | 0.64 |
| 2nd MI-FB | 0.75 | 0.67 | 0.56 | 0.67 | 0.69 | 0.72 |
| 3rd MI-FB | 0.77 | 0.68 | 0.59 | 0.70 | 0.74 | 0.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, P.-L.; Chen, S.-H.; Chang, T.-C.; Lee, W.-K.; Hsu, H.-T.; Chang, H.-H. Continual Learning of a Transformer-Based Deep Learning Classifier Using an Initial Model from Action Observation EEG Data to Online Motor Imagery Classification. Bioengineering 2023, 10, 186. https://doi.org/10.3390/bioengineering10020186
Lee P-L, Chen S-H, Chang T-C, Lee W-K, Hsu H-T, Chang H-H. Continual Learning of a Transformer-Based Deep Learning Classifier Using an Initial Model from Action Observation EEG Data to Online Motor Imagery Classification. Bioengineering. 2023; 10(2):186. https://doi.org/10.3390/bioengineering10020186
Chicago/Turabian StyleLee, Po-Lei, Sheng-Hao Chen, Tzu-Chien Chang, Wei-Kung Lee, Hao-Teng Hsu, and Hsiao-Huang Chang. 2023. "Continual Learning of a Transformer-Based Deep Learning Classifier Using an Initial Model from Action Observation EEG Data to Online Motor Imagery Classification" Bioengineering 10, no. 2: 186. https://doi.org/10.3390/bioengineering10020186