
SECP-Net: SE-Connection Pyramid Network for Segmentation of Organs at Risk with Nasopharyngeal Carcinoma

Abstract
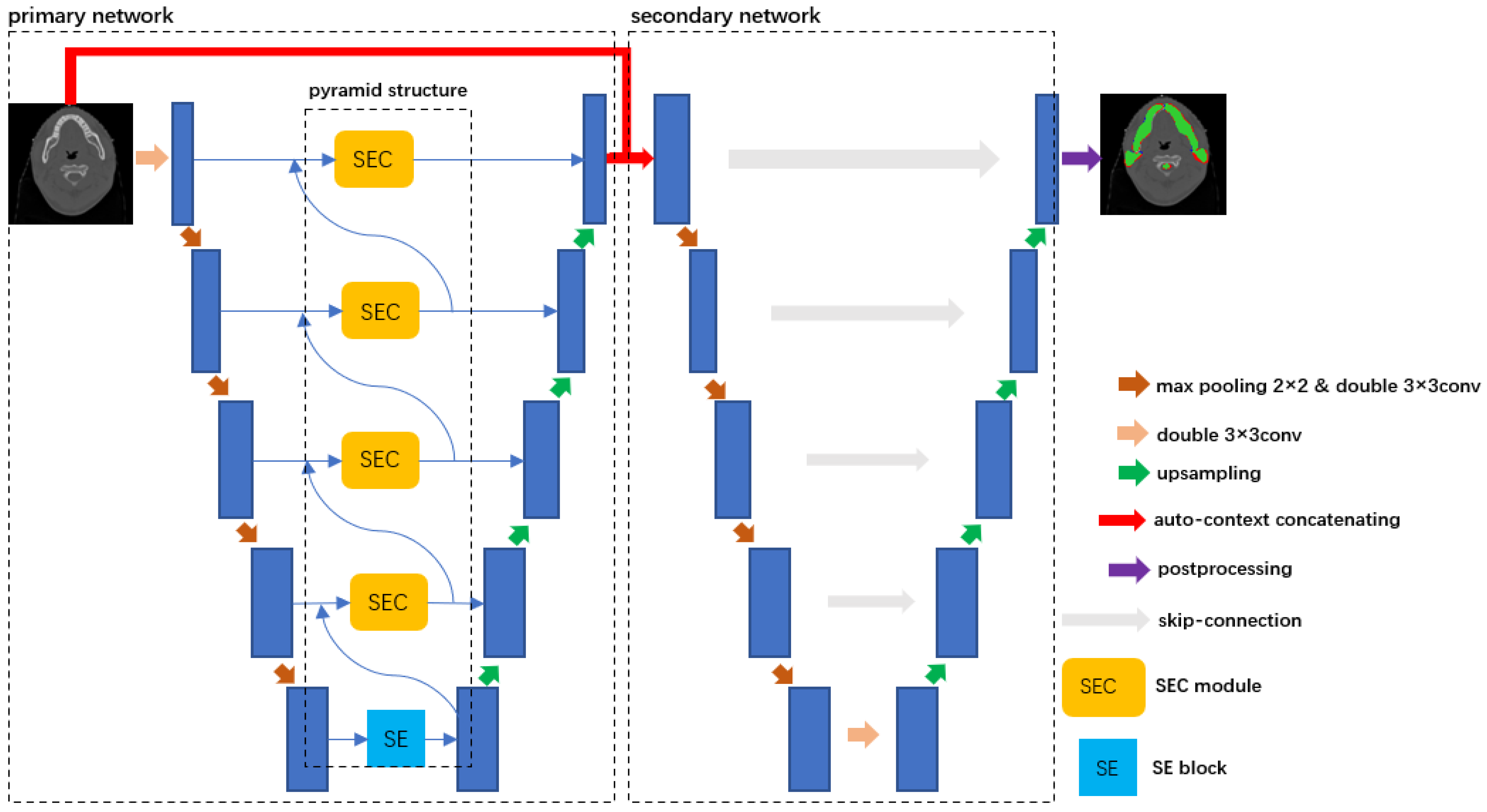
:1. Introduction
2. Method
3. Experiments
3.1. Dataset and Preprocessing
3.2. Experimental Setting
3.3. Evaluation Metrics
3.4. Training Scheme
3.5. Results
3.6. Ablation Study
- (a)
- Baseline-concat: This represents the two original cascaded U-Nets. The left U-Net is used for the rough segmentation of ROI. The output of the primary U-Net is sent to the secondary network to refine the results.
- (b)
- Baseline-auto-concat: We combine the classification probability from the primary network and original input images. Then, the combination is transmitted to the secondary network for more accurate segmentation, which achieves a better performance than a direct connection.
- (c)
- Baseline-SEC: The SEC is embedded in an original U-Net. For small organs, such as the spinal cord, left submandibular, and right submandibular, this method performs far better than the baseline, which reaches 1.53%, 3.78%, and 5.6% for Dice, respectively. Comparing UNet++ with Baseline-SEC, Baseline-SEC outperforms UNet++, especially in small organs like the spinal cord, submandibular, and thyroid. For the spinal cord, the improvement reached 1.18%; for submandibular_L, the improvement reached 0.84%; for submandibular_R, the improvement reached 0.87%; for thyroid, the improvement reached 1.91%. This proves that the SEC is effective.
- (d)
- Baseline-SEC-concat: Based on Baseline-SEC, we concatenate Baseline-SEC and an original U-Net. Baseline-SEC-concat achieves a better performance than Baseline-SEC. The network concatenation has a positive effect on the NPC segmentation task.
3.7. Visualization Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, W.; Yu, B.; Luo, Y.; Li, J.; Yuan, X.; Wu, S.; Liang, B.; Lv, Z.; Li, Y.; Peng, X.; et al. Survival Benefit of Induction Chemotherapy for Locally Advanced Nasopharyngeal Carcinoma: Prognosis Based on a New Risk Estimation Model. BMC Cancer 2021, 21, 639. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, G.; Afshari Mirak, S.; Hosseiny, M.; Azadikhah, A.; Zhong, X.; Reiter, R.E.; Lee, Y.; Raman, S.S.; Sung, K. Automatic Prostate Zonal Segmentation Using Fully Convolutional Network with Feature Pyramid Attention. IEEE Access 2019, 7, 163626–163632. [Google Scholar] [CrossRef]
- Zhou, K.; Gu, Z.; Liu, W.; Luo, W.; Cheng, J.; Gao, S.; Liu, J. Multi-Cell Multi-Task Convolutional Neural Networks for Diabetic Retinopathy Grading. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17 July 2018; pp. 2724–2727. [Google Scholar]
- Cireşan, D.C.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 3 December 2012; pp. 2843–2851. [Google Scholar]
- Sevastopolsky, A. Optic Disc and Cup Segmentation Methods for Glaucoma Detection with Modification of U-Net Convolutional Neural Network. Pattern Recognit. Image Anal. 2017, 27, 618–624. [Google Scholar] [CrossRef]
- Trullo, R.; Petitjean, C.; Ruan, S.; Dubray, B.; Nie, D.; Shen, D. Segmentation of Organs at Risk in Thoracic CT Images Using a SharpMask Architecture and Conditional Random Fields. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18 April 2017; pp. 1003–1006. [Google Scholar]
- Shen, X.; Wu, X.; Liu, R.; Li, H.; Yin, J.; Wang, L.; Ma, H. Accurate Segmentation of Breast Tumor in Ultrasound Images through Joint Training and Refined Segmentation. Phys. Med. Biol. 2022, 67, 175013. [Google Scholar] [CrossRef] [PubMed]
- Fu, J.; Lin, S.; Zhou, P.; Guo, Y.; Wang, Y. M3ResU-Net: A Deep Residual Network for Multi-Center Colorectal Polyp Segmentation Based on Multi-Scale Learning and Attention Mechanism. Phys. Med. Biol. 2022, 67, 205005. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Xi, X.; Yang, L.; Yang, X.; Song, Z.; Nie, X.; Zhang, L.; Zhang, Y.; Chen, X.; Yin, Y. Feature Enhancement Network for CNV Typing in Optical Coherence Tomography Images. Phys. Med. Biol. 2022, 67, 205007. [Google Scholar] [CrossRef] [PubMed]
- Pan, S.; Lei, Y.; Wang, T.; Wynne, J.; Chang, C.-W.; Roper, J.; Jani, A.B.; Patel, P.; Bradley, J.D.; Liu, T.; et al. Male Pelvic Multi-Organ Segmentation Using Token-Based Transformer Vnet. Phys. Med. Biol. 2022, 67, 205012. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Miao, Q.; Surawech, C.; Zheng, H.; Nguyen, D.; Yang, G.; Raman, S.S.; Sung, K. Deep Learning Enables Prostate MRI Segmentation: A Large Cohort Evaluation with Inter-Rater Variability Analysis. Front Oncol. 2021, 11, 801876. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.; Yang, G.; Fang, Y.; Li, R.; Xu, X.; Liu, Y.; Lai, X. 3D PBV-Net: An Automated Prostate MRI Data Segmentation Method. Comput. Biol. Med. 2021, 128, 104160. [Google Scholar] [CrossRef] [PubMed]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5 October 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16 June 2019; pp. 510–519. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Le Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Liu, Y.; Yang, G.; Hosseiny, M.; Azadikhah, A.; Mirak, S.A.; Miao, Q.; Raman, S.S.; Sung, K. Exploring Uncertainty Measures in Bayesian Deep Attentive Neural Networks for Prostate Zonal Segmentation. IEEE Access 2020, 8, 151817–151828. [Google Scholar] [CrossRef]
- Tu, Z. Auto-Context and Its Application to High-Level Vision Tasks. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 1–8. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. CE-Net: Context Encoder Network for 2D Medical Image Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11045, pp. 3–11. [Google Scholar] [CrossRef]
- Feng, S.; Zhao, H.; Shi, F.; Cheng, X.; Wang, M.; Ma, Y.; Xiang, D.; Zhu, W.; Chen, X. CPFNet: Context Pyramid Fusion Network for Medical Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 3008–3018. [Google Scholar] [CrossRef] [PubMed]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar] [CrossRef]
- Bilic, P.; Christ, P.; Li, H.B.; Vorontsov, E.; Ben-Cohen, A.; Kaissis, G.; Szeskin, A.; Jacobs, C.; Mamani, G.E.H.; Chartrand, G.; et al. The Liver Tumor Segmentation Benchmark (LiTS). Med. Image Anal. 2023, 84, 102680. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.-A. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed]
- Guan, S.; Khan, A.A.; Sikdar, S.; Chitnis, P.V. Fully Dense UNet for 2-D Sparse Photoacoustic Tomography Artifact Removal. IEEE J. Biomed. Health Inform. 2020, 24, 568–576. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Organ | Average Volume (cm3) | Organ | Average Volume (cm3) |
|---|---|---|---|
| left eye | 8.4 | parotid left | 21.8 |
| right eye | 8.8 | parotid right | 22.4 |
| left temporal lobe | 134.3 | spinal cord | 23.1 |
| right temporal lobe | 125.8 | submandibular left | 9.3 |
| left mandible | 35.9 | submandibular right | 8.9 |
| right mandible | 37.2 | thyroid gland | 12.8 |
| brain stem | 30.8 |
| Methods | U-Net | Attention U-Net | CE-Net | UNet++ | CPF-Net | Res-U-Net | Dense-U-Net | SECP-Net | |
|---|---|---|---|---|---|---|---|---|---|
| Organs | |||||||||
| Temporal Lobe_L | 86.55 ± 0.51 | 88.49 ± 0.60 | 86.01 ± 1.44 | 89.04 ± 0.47 | 88.17 ± 0.75 | 86.21 ± 0.45 | 86.63 ± 0.92 | 88.56 ± 0.66 | |
| Temporal Lobe_R | 86.16 ± 0.61 | 86.66 ± 0.59 | 85.45 ± 1.20 | 87.75 ± 0.50 | 87.18 ± 0.81 | 87.33 ± 0.53 | 86.37 ± 1.18 | 87.55 ± 0.61 | |
| Eye_L | 75.73 ± 0.73 | 77.46 ± 0.66 | 73.44 ± 1.11 | 79.92 ± 0.52 | 77.97 ± 0.63 | 77.52 ± 0.74 | 77.14 ± 0.46 | 81.19 ± 0.77 | |
| Eye_R | 75.68 ± 0.82 | 80.33 ± 0.67 | 75.61 ± 1.08 | 80.03 ± 0.56 | 79.39 ± 0.67 | 77.64 ± 0.58 | 78.28 ± 0.79 | 80.81 ± 0.71 | |
| Mandible_L | 86.17 ± 0.65 | 88.08 ± 0.53 | 84.82 ± 0.85 | 88.38 ± 0.57 | 87.70 ± 0.77 | 84.48 ± 0.82 | 85.37 ± 0.56 | 88.27 ± 0.58 | |
| Mandible_R | 86.52 ± 0.67 | 87.10 ± 0.61 | 85.42 ± 0.79 | 88.66 ± 0.49 | 88.04 ± 0.73 | 85.19 ± 0.86 | 85.61 ± 0.59 | 88.60 ± 0.52 | |
| Brainstem | 82.39 ± 0.68 | 84.08 ± 0.59 | 81.22 ± 0.73 | 84.38 ± 0.54 | 82.22 ± 0.56 | 80.40 ± 0.44 | 82.44 ± 0.64 | 85.55 ± 0.41 | |
| Parotid_L | 78.40 ± 0.78 | 79.48 ± 0.44 | 76.17 ± 0.77 | 80.87 ± 0.61 | 79.61 ± 0.48 | 79.25 ± 0.35 | 79.62 ± 0.32 | 80.35 ± 0.53 | |
| Parotid_R | 77.34 ± 0.74 | 78.89 ± 0.46 | 77.87 ± 0.84 | 80.53 ± 0.70 | 78.77 ± 0.56 | 77.28 ± 0.41 | 78.44 ± 0.38 | 80.61 ± 0.48 | |
| Spinal cord | 88.06 ± 0.35 | 87.94 ± 0.41 | 86.41 ± 0.60 | 88.41 ± 0.38 | 87.19 ± 0.53 | 88.17 ± 0.35 | 88.52 ± 0.65 | 89.77 ± 0.29 | |
| Submandibular_L | 72.32 ± 1.13 | 74.81 ± 0.65 | 69.46 ± 1.21 | 75.66 ± 0.87 | 72.81 ± 1.07 | 73.82 ± 0.71 | 72.85 ± 0.81 | 77.38 ± 0.89 | |
| Submandibular_R | 72.71 ± 1.24 | 78.13 ± 0.67 | 70.04 ± 1.31 | 77.64 ± 0.89 | 73.83 ± 1.16 | 74.10 ± 0.37 | 73.19 ± 0.42 | 79.19 ± 0.85 | |
| Thyroid | 69.77 ± 0.64 | 71.99 ± 0.71 | 68.88 ± 0.84 | 72.57 ± 0.59 | 70.98 ± 0.53 | 69.81 ± 0.84 | 68.61 ± 0.59 | 74.81 ± 0.39 | |
| Ave | 79.83 ± 0.73 | 81.80 ± 0.58 | 78.52 ± 0.98 | 82.68 ± 0.59 | 81.19 ± 0.63 | 80.09 ± 0.57 | 80.23 ± 0.64 | 83.28 ± 0.59 | |
| Vs U-Net | Vs Attention U-Net | Vs CE-Net | Vs UNet++ | Vs Res-U-Net | Vs Dense-U-Net | Vs CPF-Net | |
|---|---|---|---|---|---|---|---|
| Average improvement of SECP-Net | 3.45% | 1.48% | 4.76% | 0.6% | 3.19% | 3.05% | 2.09% |
| The significance of improvement | p < 0.5 | p < 0.5 | p < 0.5 | p < 0.5 | p < 0.5 | p < 0.5 | p < 0.5 |
| U-Net | Attention U-Net | CE-Net | UNet++ | CPF-Net | Res-U-Net | Dense-U-Net | SECP-Net | |
|---|---|---|---|---|---|---|---|---|
| Precision | 0.876 | 0.900 | 0.889 | 0.901 | 0.896 | 0.898 | 0.892 | 0.908 |
| Recall | 0.847 | 0.899 | 0.878 | 0.892 | 0.890 | 0.893 | 0.883 | 0.902 |
| Methods | U-Net | Attention U-Net | CE-Net | UNet++ | CPF-Net | SECP-Net | |
|---|---|---|---|---|---|---|---|
| Organs | |||||||
| Liver | 80.21 ± 1.38 | 81.59 ± 0.62 | 84.05 ± 1.26 | 84.73 ± 0.92 | 84.39 ± 0.83 | 85.47 ± 0.69 | |
| Liver Tumor | 62.12 ± 1.55 | 64.36 ± 0.74 | 65.66 ± 1.37 | 67.43 ± 0.53 | 69.63 ± 0.79 | 71.62 ± 0.78 | |
| Methods | U-Net | Attention U-Net | CE-Net | UNet++ | CPF-Net | SECP-Net | |
|---|---|---|---|---|---|---|---|
| Organs | |||||||
| Liver | 81.65 ± 1.23 | 82.73 ± 0.73 | 83.55 ± 1.34 | 85.43 ± 1.02 | 84.78 ± 0.76 | 87.82 ± 0.58 | |
| Liver Tumor | 68.06 ± 1.61 | 72.27 ± 0.81 | 74.66 ± 1.42 | 75.59 ± 0.51 | 76.68 ± 0.83 | 78.89 ± 0.69 | |
| Methods | Baseline | Baseline-Concat | Baseline-Auto-Concat | Baseline-SEC | UNet++ | Baseline-SEC-Concat | SECP-Net | |
|---|---|---|---|---|---|---|---|---|
| Organs | ||||||||
| Temporal Lobe_L | 86.55 ± 0.51 | 88.49 ± 0.66 | 88.54 ± 0.47 | 88.69 ± 0.41 | 89.04 ± 0.47 | 88.56 ± 0.58 | 88.56 ± 0.66 | |
| Temporal Lobe_R | 86.16 ± 0.61 | 87.54 ± 0.64 | 87.52 ± 0.53 | 87.38 ± 0.46 | 87.75 ± 0.50 | 87.78 ± 0.60 | 87.55 ± 0.61 | |
| Eye_L | 75.73 ± 0.73 | 79.78 ± 0.71 | 79.49 ± 0.74 | 79.52 ± 0.48 | 79.92 ± 0.52 | 81.06 ± 0.53 | 81.19 ± 0.77 | |
| Eye_R | 75.68 ± 0.82 | 79.05 ± 0.73 | 79.21 ± 0.69 | 80.63 ± 0.47 | 80.03 ± 0.56 | 80.30 ± 0.49 | 80.81 ± 0.71 | |
| Mandible_L | 86.17 ± 0.65 | 87.47 ± 0.42 | 87.54 ± 0.69 | 88.03 ± 0.73 | 88.38 ± 0.57 | 88.56 ± 0.66 | 88.27 ± 0.58 | |
| Mandible_R | 86.52 ± 0.67 | 87.33 ± 0.56 | 88.10 ± 0.74 | 88.55 ± 0.76 | 88.66 ± 0.49 | 88.16 ± 0.68 | 88.60 ± 0.52 | |
| Brainstem | 82.39 ± 0.68 | 84.06 ± 0.38 | 85.48 ± 0.70 | 84.72 ± 0.78 | 84.38 ± 0.54 | 85.18 ± 0.59 | 85.55 ± 0.41 | |
| Parotid_L | 78.40 ± 0.78 | 80.33 ± 0.47 | 80.47 ± 0.67 | 80.04 ± 0.72 | 80.87 ± 0.61 | 80.10 ± 0.54 | 80.35 ± 0.53 | |
| Parotid_R | 77.34 ± 0.74 | 79.16 ± 0.48 | 79.45 ± 0.61 | 80.31 ± 0.59 | 80.53 ± 0.70 | 80.20 ± 0.52 | 80.61 ± 0.48 | |
| Spinal cord | 88.06 ± 0.35 | 88.42 ± 0.59 | 88.71 ± 0.51 | 89.59 ± 0.57 | 88.41 ± 0.38 | 89.67 ± 0.31 | 89.77 ± 0.29 | |
| Submandibular_L | 72.32 ± 1.13 | 73.91 ± 0.67 | 75.44 ± 0.62 | 76.50 ± 0.78 | 75.66 ± 0.87 | 76.62 ± 0.91 | 77.38 ± 0.89 | |
| Submandibular_R | 72.71 ± 1.24 | 74.71 ± 0.69 | 75.96 ± 0.53 | 78.51 ± 0.80 | 77.64 ± 0.89 | 78.21 ± 0.83 | 79.19 ± 0.85 | |
| Thyroid | 69.77 ± 0.64 | 72.44 ± 0.49 | 71.84 ± 0.52 | 74.48 ± 0.60 | 72.57 ± 0.59 | 74.53 ± 0.43 | 74.81 ± 0.39 | |
| Ave | 79.83 ± 0.73 | 81.75 ± 0.58 | 82.13 ± 0.62 | 83.09 ± 0.63 | 82.68 ± 0.59 | 83.10 ± 0.59 | 83.28 ± 0.59 | |
| Main Techniques | Drawbacks | |
|---|---|---|
| Attention U-Net | The attention gate (AG) in skip-connection | It does not deal with global context information or multi-size information. |
| CE-Net | The dense atrous convolution block (DAC) and the residual multi-kernel pooling (RMP) | It does not pay attention to the global context information. |
| UNet++ | The dense connection from low to high-level stages in the network | skip-connection is more complex |
| CPF-Net | The global pyramid guidance (GPG) module | It is difficult to design dilated convolution kernels of various dilation rates for different kinds of organs. |
| Our SECP-Net | The SE-connection module and the pyramid structure | It needs more computation costs |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Yang, X.; Huang, S.; Guo, L. SECP-Net: SE-Connection Pyramid Network for Segmentation of Organs at Risk with Nasopharyngeal Carcinoma. Bioengineering 2023, 10, 1119. https://doi.org/10.3390/bioengineering10101119
Huang Z, Yang X, Huang S, Guo L. SECP-Net: SE-Connection Pyramid Network for Segmentation of Organs at Risk with Nasopharyngeal Carcinoma. Bioengineering. 2023; 10(10):1119. https://doi.org/10.3390/bioengineering10101119
Chicago/Turabian StyleHuang, Zexi, Xin Yang, Sijuan Huang, and Lihua Guo. 2023. "SECP-Net: SE-Connection Pyramid Network for Segmentation of Organs at Risk with Nasopharyngeal Carcinoma" Bioengineering 10, no. 10: 1119. https://doi.org/10.3390/bioengineering10101119