
Dual-Guided Brain Diffusion Model: Natural Image Reconstruction from Human Visual Stimulus fMRI

Abstract
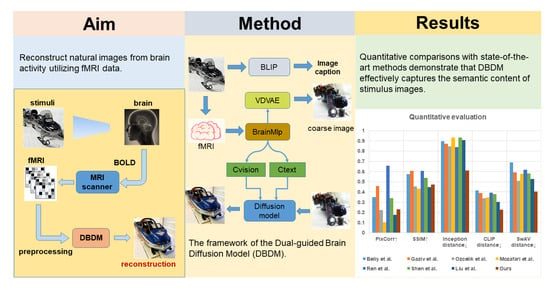
:
1. Introduction
- We introduce the Dual-guided Brain Diffusion Model (DBDM), which leverages the powerful generative capabilities of VD to reconstruct brain-perceived images that are semantically consistent with real images while retaining precise details, guided by both visual and semantic features;
- We generate text descriptions for each training image using BLIP to introduce semantic content. Additionally, we design the BrainMlp model with residual connections to learn the mapping of fMRI data to CLIP-extracted visual and semantic features, employing the well-trained model to predict the corresponding feature vectors from test fMRI data. Subsequently, we use the predicted visual and semantic features to modulate the inverse diffusion process of VD, providing sufficient guidance for reconstructing images similar to the original stimulus;
- We conduct comprehensive experiments on a publicly available dataset to evaluate the effectiveness of our proposed method. The experimental results demonstrate that DBDM achieves advanced results in both qualitative and quantitative comparisons with existing methods, enabling the reconstruction of high-resolution and high-fidelity images from fMRI signals.
2. Materials and Methods
2.1. Dataset
2.2. Overview
2.3. Stage I: Obtain the Initial Guess Using VDVAE
2.4. Stage II: Generate Text Description Using BLIP
2.5. Stage III: Image Reconstruction
2.6. Statistical Analysis
- Pixel-wise correlation (PixCorr): This metric is used to measure the pixel-level similarity between the reconstructed and original images.
- Structural similarity index measure (SSIM): This provides a metric for the structural similarity between the reconstructed and original images.
- Inception distance: This metric evaluates the quality of generated images through feature space statistics.
- CLIP distance: This metric assesses the consistency between the reconstructed images and textual descriptions using the CLIP model.
- SwAV distance: This metric quantifies the alignment of image embeddings with respect to semantic content using SwAV.
3. Results
3.1. Implementation Details
3.2. Examples of Visual Reconstruction
3.3. Comparison with Other Methods
3.3.1. Visual Comparison
3.3.2. Quantitative Comparison
3.4. Ablation Studies
3.5. Effectiveness of BrainMlp for Neural Decoding
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thirion, B.; Duchesnay, E.; Hubbard, E.; Dubois, J.; Poline, J.B.; Lebihan, D.; Dehaene, S. Inverse retinotopy: Inferring the visual content of images from brain activation patterns. Neuroimage 2006, 33, 1104–1116. [Google Scholar] [CrossRef] [PubMed]
- Haynes, J.D.; Rees, G. Predicting the orientation of invisible stimuli from activity in human primary visual cortex. Nat. Neurosci. 2005, 8, 686–691. [Google Scholar] [CrossRef] [PubMed]
- Haxby, J.V.; Gobbini, M.I.; Furey, M.L.; Ishai, A.; Schouten, J.L.; Pietrini, P. Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science 2001, 293, 2425–2430. [Google Scholar] [CrossRef]
- Cox, D.D.; Savoy, R.L. Functional magnetic resonance imaging (fMRI)“brain reading”: Detecting and classifying distributed patterns of fMRI activity in human visual cortex. Neuroimage 2003, 19, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Rakhimberdina, Z.; Jodelet, Q.; Liu, X.; Murata, T. Natural image reconstruction from fmri using deep learning: A survey. Front. Neurosci. 2021, 15, 795488. [Google Scholar] [CrossRef]
- Belliveau, J.W.; Kennedy, D.N.; McKinstry, R.C.; Buchbinder, B.R.; Weisskoff, R.M.; Cohen, M.S.; Vevea, J.; Brady, T.J.; Rosen, B.R. Functional mapping of the human visual cortex by magnetic resonance imaging. Science 1991, 254, 716–719. [Google Scholar] [CrossRef] [PubMed]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef]
- Horikawa, T.; Tamaki, M.; Miyawaki, Y.; Kamitani, Y. Neural decoding of visual imagery during sleep. Science 2013, 340, 639–642. [Google Scholar] [CrossRef]
- Huth, A.G.; Lee, T.; Nishimoto, S.; Bilenko, N.Y.; Vu, A.T.; Gallant, J.L. Decoding the semantic content of natural movies from human brain activity. Front. Syst. Neurosci. 2016, 10, 81. [Google Scholar] [CrossRef]
- Damarla, S.R.; Just, M.A. Decoding the representation of numerical values from brain activation patterns. Hum. Brain Mapp. 2013, 34, 2624–2634. [Google Scholar] [CrossRef]
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef] [PubMed]
- Schoenmakers, S.; Barth, M.; Heskes, T.; Van Gerven, M. Linear reconstruction of perceived images from human brain activity. Neuroimage 2013, 83, 951–961. [Google Scholar] [CrossRef] [PubMed]
- Mozafari, M.; Reddy, L.; VanRullen, R. Reconstructing natural scenes from fmri patterns using bigbigan. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Seeliger, K.; Güçlü, U.; Ambrogioni, L.; Güçlütürk, Y.; van Gerven, M.A. Generative adversarial networks for reconstructing natural images from brain activity. Neuroimage 2018, 181, 775–785. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Jing, H.; Wang, J.; Wu, W.; Ma, Y. Images Structure Reconstruction from fMRI by Unsupervised Learning Based on VAE. In Artificial Neural Networks and Machine Learning, Proceedings of the ICANN 2022, Bristol, UK, 6–9 September 2022; Pimenidis, E., Angelov, P., Jayne, C., Papaleonidas, A., Aydin, M., Eds.; Springer: Cham, Switzerland, 2022; pp. 137–148. [Google Scholar]
- Han, K.; Wen, H.; Shi, J.; Lu, K.H.; Zhang, Y.; Fu, D.; Liu, Z. Variational autoencoder: An unsupervised model for encoding and decoding fMRI activity in visual cortex. Neuroimage 2019, 198, 125–136. [Google Scholar] [CrossRef] [PubMed]
- Ozcelik, F.; VanRullen, R. Brain-diffuser: Natural scene reconstruction from fmri signals using generative latent diffusion. arXiv 2023, arXiv:2303.05334. [Google Scholar]
- Chen, Z.; Qing, J.; Xiang, T.; Yue, W.L.; Zhou, J.H. Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding. arXiv 2023, arXiv:2211.06956. [Google Scholar]
- Ferrante, M.; Boccato, T.; Toschi, N. Semantic Brain Decoding: From fMRI to conceptually similar image reconstruction of visual stimuli. arXiv 2022, arXiv:2212.06726. [Google Scholar]
- Liu, Y.; Ma, Y.; Zhou, W.; Zhu, G.; Zheng, N. BrainCLIP: Bridging Brain and Visual-Linguistic Representation Via CLIP for Generic Natural Visual Stimulus Decoding. arXiv 2023, arXiv:2302.12971. [Google Scholar]
- VanRullen, R.; Reddy, L. Reconstructing faces from fMRI patterns using deep generative neural networks. Commun. Biol. 2019, 2, 193. [Google Scholar] [CrossRef]
- Dado, T.; Güçlütürk, Y.; Ambrogioni, L.; Ras, G.; Bosch, S.E.; van Gerven, M.A.J.; Güųlü, U. Hyperrealistic neural decoding for reconstructing faces from fMRI activations via the GAN latent space. Sci. Rep. 2022, 12, 141. [Google Scholar] [CrossRef]
- Shen, G.; Dwivedi, K.; Majima, K.; Horikawa, T.; Kamitani, Y. End-to-end deep image reconstruction from human brain activity. Front. Comput. Neurosci. 2019, 13, 21. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.; Sprague, T.; Singh, A.K. Mind reader: Reconstructing complex images from brain activities. Adv. Neural Inf. Process. Syst. 2022, 35, 29624–29636. [Google Scholar]
- Takagi, Y.; Nishimoto, S. High-resolution image reconstruction with latent diffusion models from human brain activity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14453–14463. [Google Scholar]
- Shen, G.; Horikawa, T.; Majima, K.; Kamitani, Y. Deep image reconstruction from human brain activity. PLoS Comput. Biol. 2019, 15, e1006633. [Google Scholar] [CrossRef] [PubMed]
- Beliy, R.; Gaziv, G.; Hoogi, A.; Strappini, F.; Golan, T.; Irani, M. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Gaziv, G.; Beliy, R.; Granot, N.; Hoogi, A.; Strappini, F.; Golan, T.; Irani, M. Self-supervised Natural Image Reconstruction and Large-scale Semantic Classification from Brain Activity. Neuroimage 2022, 254, 119121. [Google Scholar] [CrossRef] [PubMed]
- Ren, Z.; Li, J.; Xue, X.; Li, X.; Yang, F.; Jiao, Z.; Gao, X. Reconstructing seen image from brain activity by visually-guided cognitive representation and adversarial learning. Neuroimage 2021, 228, 117602. [Google Scholar] [CrossRef]
- Donahue, J.; Simonyan, K. Large scale adversarial representation learning. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Ozcelik, F.; Choksi, B.; Mozafari, M.; Reddy, L.; VanRullen, R. Reconstruction of perceived images from fmri patterns and semantic brain exploration using instance-conditioned gans. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Xu, X.; Wang, Z.; Zhang, E.; Wang, K.; Shi, H. Versatile diffusion: Text, images and variations all in one diffusion model. arXiv 2022, arXiv:2211.08332. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Child, R. Very deep vaes generalize autoregressive models and can outperform them on images. arXiv 2020, arXiv:2011.10650. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Ferrante, M.; Ozcelik, F.; Boccato, T.; VanRullen, R.; Toschi, N. Brain Captioning: Decoding human brain activity into images and text. arXiv 2023, arXiv:2305.11560. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Schuhmann, C.; Vencu, R.; Beaumont, R.; Kaczmarczyk, R.; Mullis, C.; Katta, A.; Coombes, T.; Jitsev, J.; Komatsuzaki, A. LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs. arXiv 2021, arXiv:2111.02114. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 9912–9924. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Quantitative Measures | ||||
|---|---|---|---|---|---|
| Low-Level↑ | High-Level↓ | ||||
| PixCorr | SSIM | Inception Distance | CLIP Distance | SwAV Distance | |
| Beliy et al., 2019 [27] | 0.351 | 0.575 | 0.896 | 0.415 | 0.690 |
| Gaziv et al., 2022 [28] | 0.459 | 0.607 | 0.871 | 0.389 | 0.592 |
| Ozcelik et al., 2022 [31] | 0.223 | 0.453 | 0.846 | 0.340 | 0.510 |
| Mozafari et al., 2020 [13] | 0.103 | 0.431 | 0.932 | 0.346 | 0.577 |
| Ren et al., 2021 [29] | 0.657 | 0.605 | 0.838 | 0.393 | 0.617 |
| Shen et al., 2019 [26] | 0.339 | 0.539 | 0.933 | 0.379 | 0.581 |
| Liu et al., 2023 [20] | 0.175 | 0.448 | 0.908 | 0.301 | 0.527 |
| Ours | 0.231 | 0.473 | 0.611 | 0.225 | 0.405 |
| Model | Quantitative Measures | ||||
|---|---|---|---|---|---|
| Low-Level↑ | High-Level↓ | ||||
| PixCorr | SSIM | Inception Distance | CLIP Distance | SwAV Distance | |
| without initial guess | 0.136 | 0.316 | 0.789 | 0.337 | 0.522 |
| without CLIP-text | 0.222 | 0.376 | 0.977 | 0.476 | 0.636 |
| without CLIP-vision | 0.248 | 0.446 | 0.827 | 0.345 | 0.542 |
| full method | 0.234 | 0.386 | 0.748 | 0.305 | 0.468 |
| Model | Quantitative Measures | ||||
|---|---|---|---|---|---|
| Low-Level↑ | High-Level↓ | ||||
| PixCorr | SSIM | Inception Distance | CLIP Distance | SwAV Distance | |
| CLIP text regression | 0.204 | 0.348 | 0.922 | 0.430 | 0.566 |
| CLIP vision regression | 0.222 | 0.357 | 0.880 | 0.398 | 0.536 |
| VDVAE regression | 0.213 | 0.434 | 0.962 | 0.433 | 0.644 |
| VDVAE–BrainMlp | 0.254 | 0.447 | 0.960 | 0.435 | 0.631 |
| full method | 0.234 | 0.386 | 0.748 | 0.305 | 0.468 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, L.; Yang, C. Dual-Guided Brain Diffusion Model: Natural Image Reconstruction from Human Visual Stimulus fMRI. Bioengineering 2023, 10, 1117. https://doi.org/10.3390/bioengineering10101117
Meng L, Yang C. Dual-Guided Brain Diffusion Model: Natural Image Reconstruction from Human Visual Stimulus fMRI. Bioengineering. 2023; 10(10):1117. https://doi.org/10.3390/bioengineering10101117
Chicago/Turabian StyleMeng, Lu, and Chuanhao Yang. 2023. "Dual-Guided Brain Diffusion Model: Natural Image Reconstruction from Human Visual Stimulus fMRI" Bioengineering 10, no. 10: 1117. https://doi.org/10.3390/bioengineering10101117