
A Low Memory Requirement MobileNets Accelerator Based on FPGA for Auxiliary Medical Tasks

Abstract
:1. Introduction
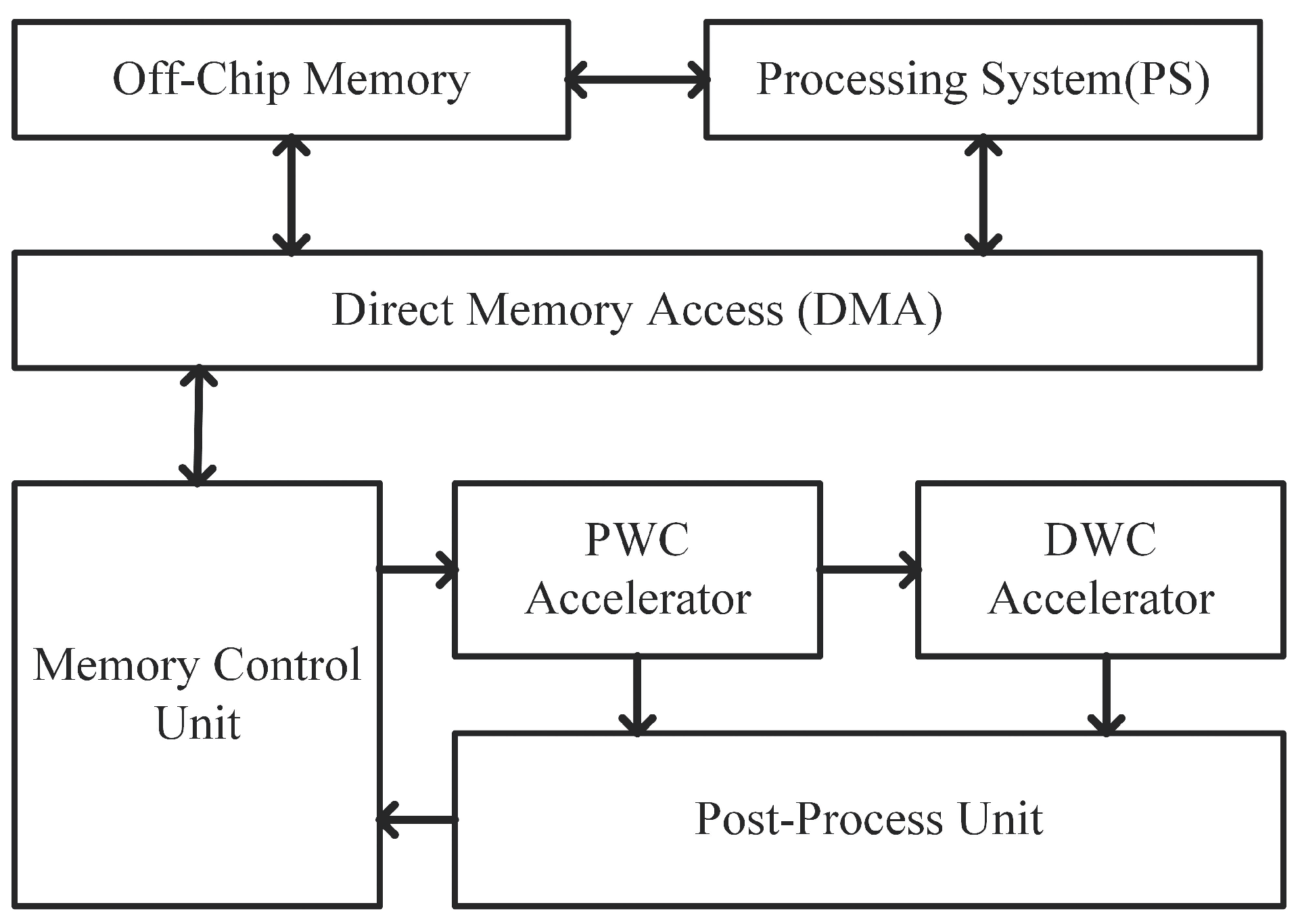
- A high-performance CNN hardware accelerator is proposed where operations are processed in parallel in the Pointwise Convolution Accelerator and Depthwise Convolution Accelerator individually. The Depthwise Convolution Accelerator could be pipelined after the Pointwise Convolution Accelerator or bypassed to match with depthwise separable convolutions in MobileNets, leading to less off-chip memory access and higher inference speed.
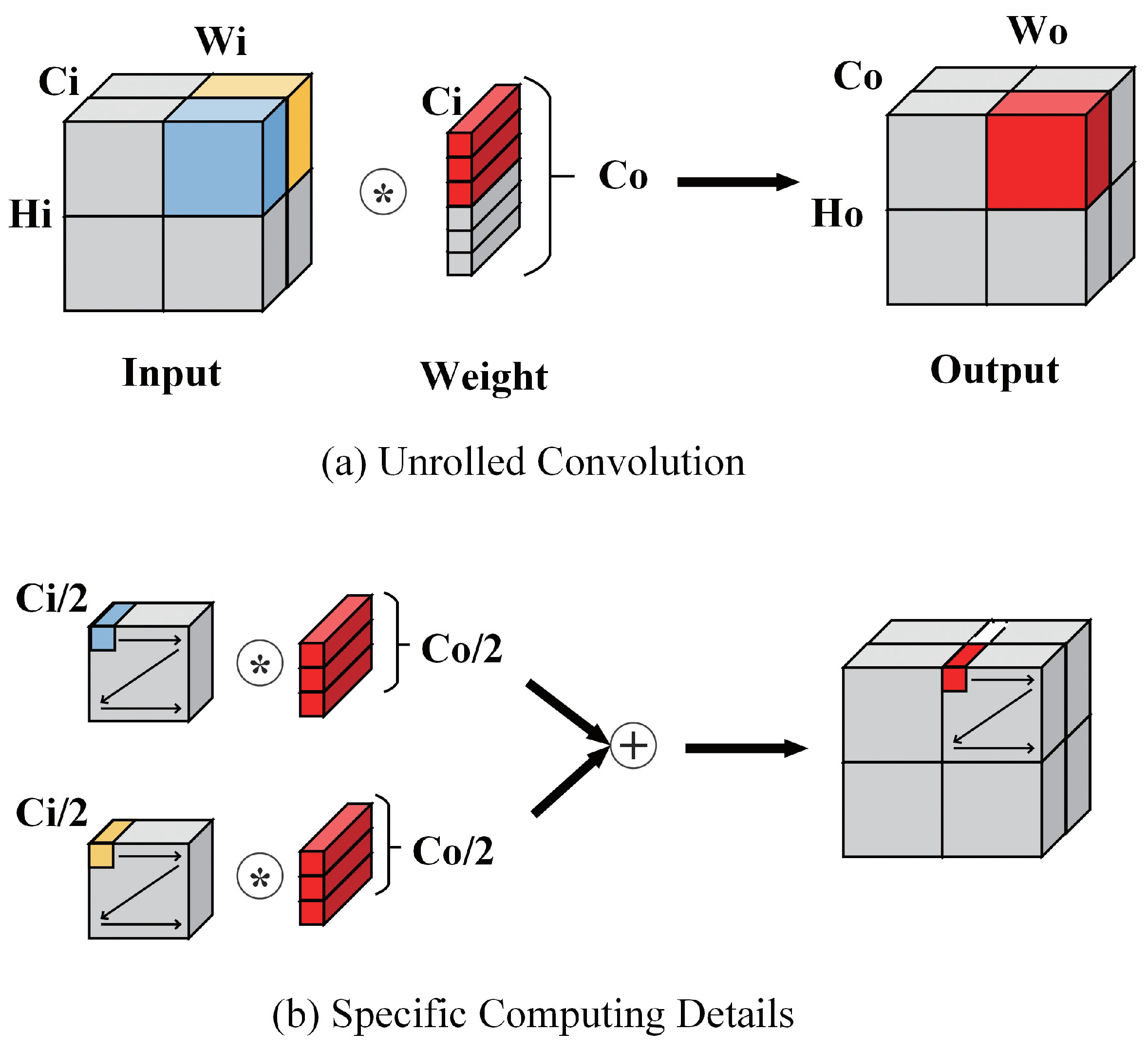
- A changeable number of channels in the Pointwise Convolution Accelerator could reduce both memory and computation resource requirement of blocks behind the Pointwise Convolution Accelerator and maximize utilization of existing resources.
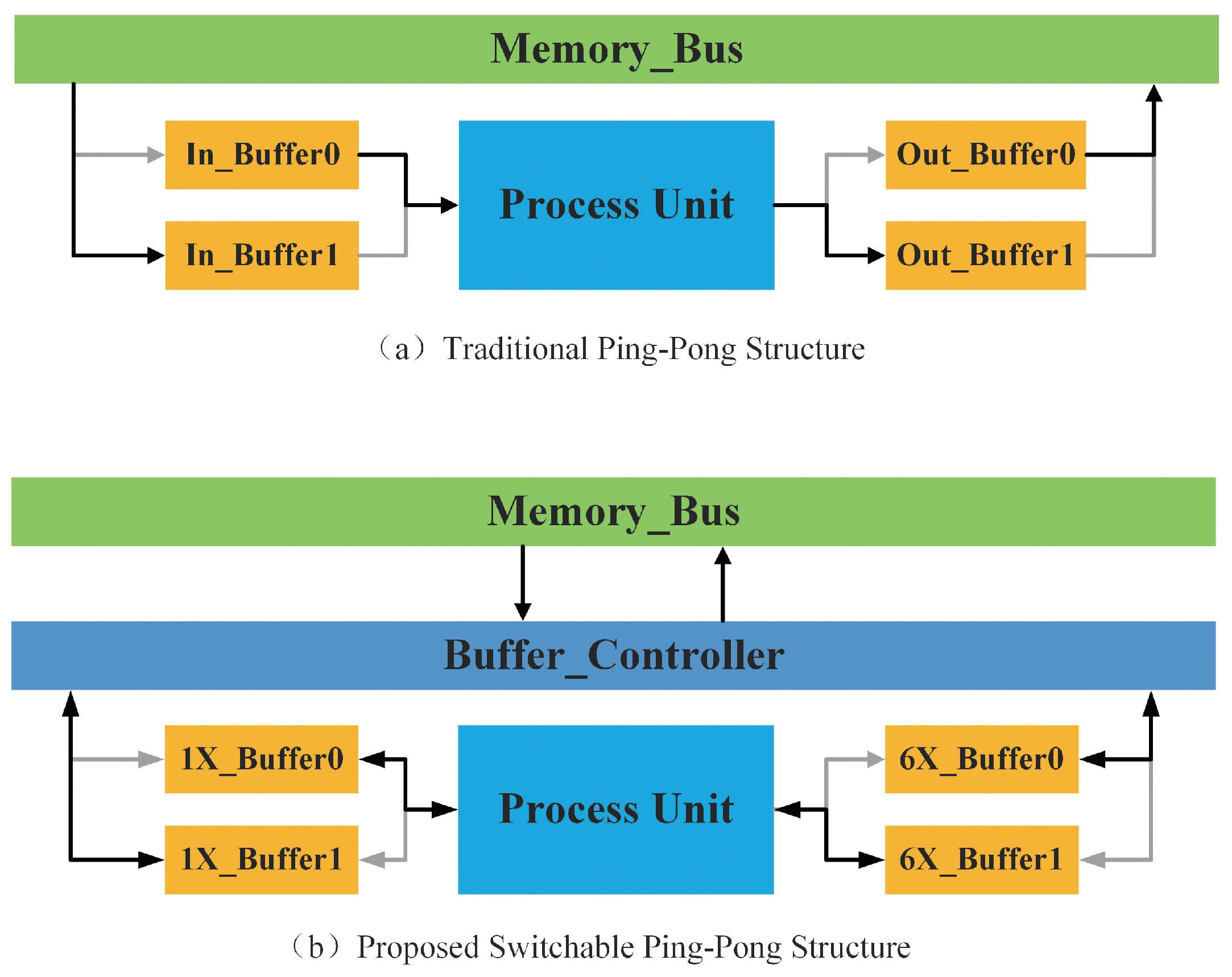
- The usage of on-chip memory and data interaction between on-chip memory and off-chip memory can be minimized by using a switchable ping-pong buffer structure and reorganized dataflow to further reduce memory requirement.
2. Related Works
3. Background
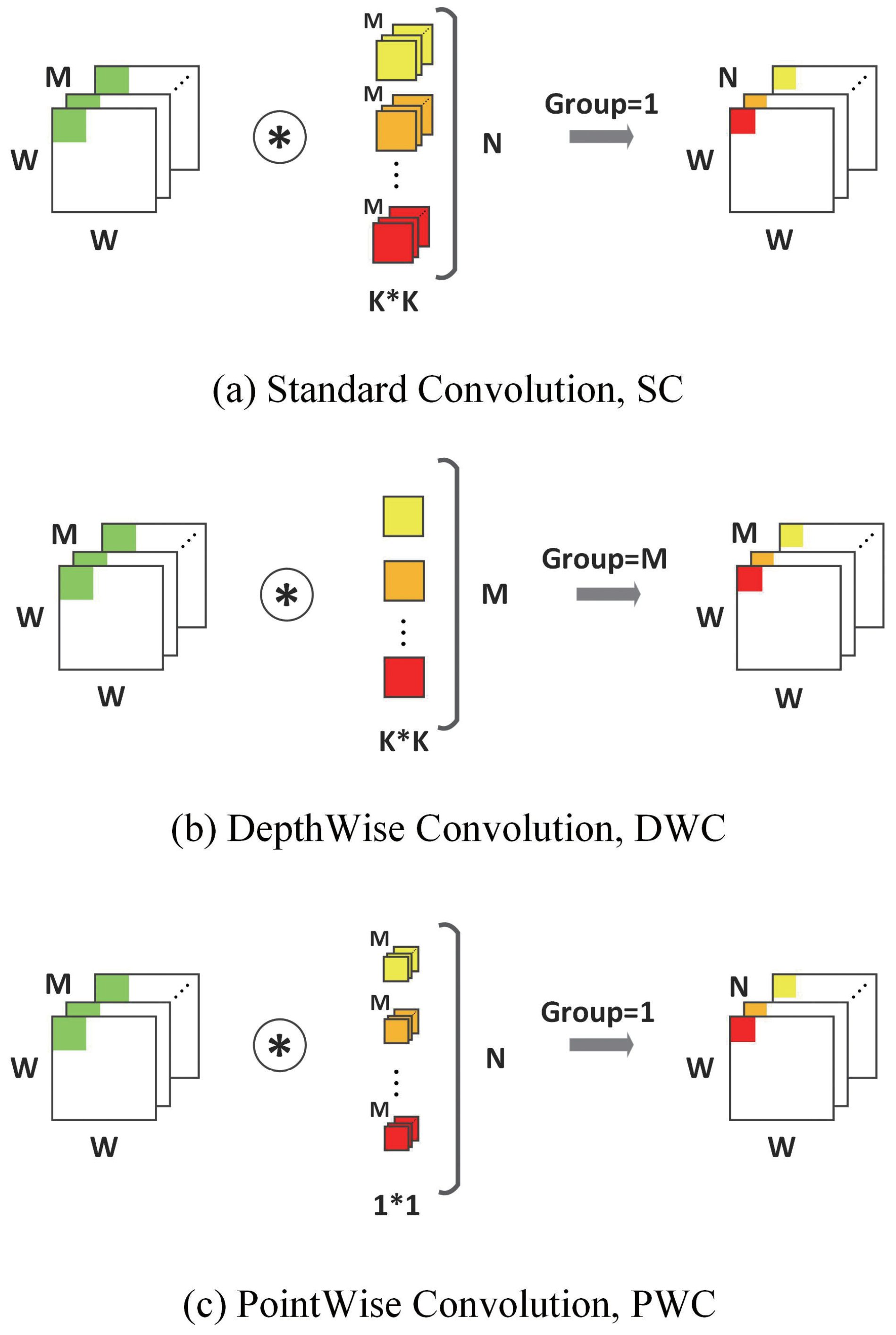
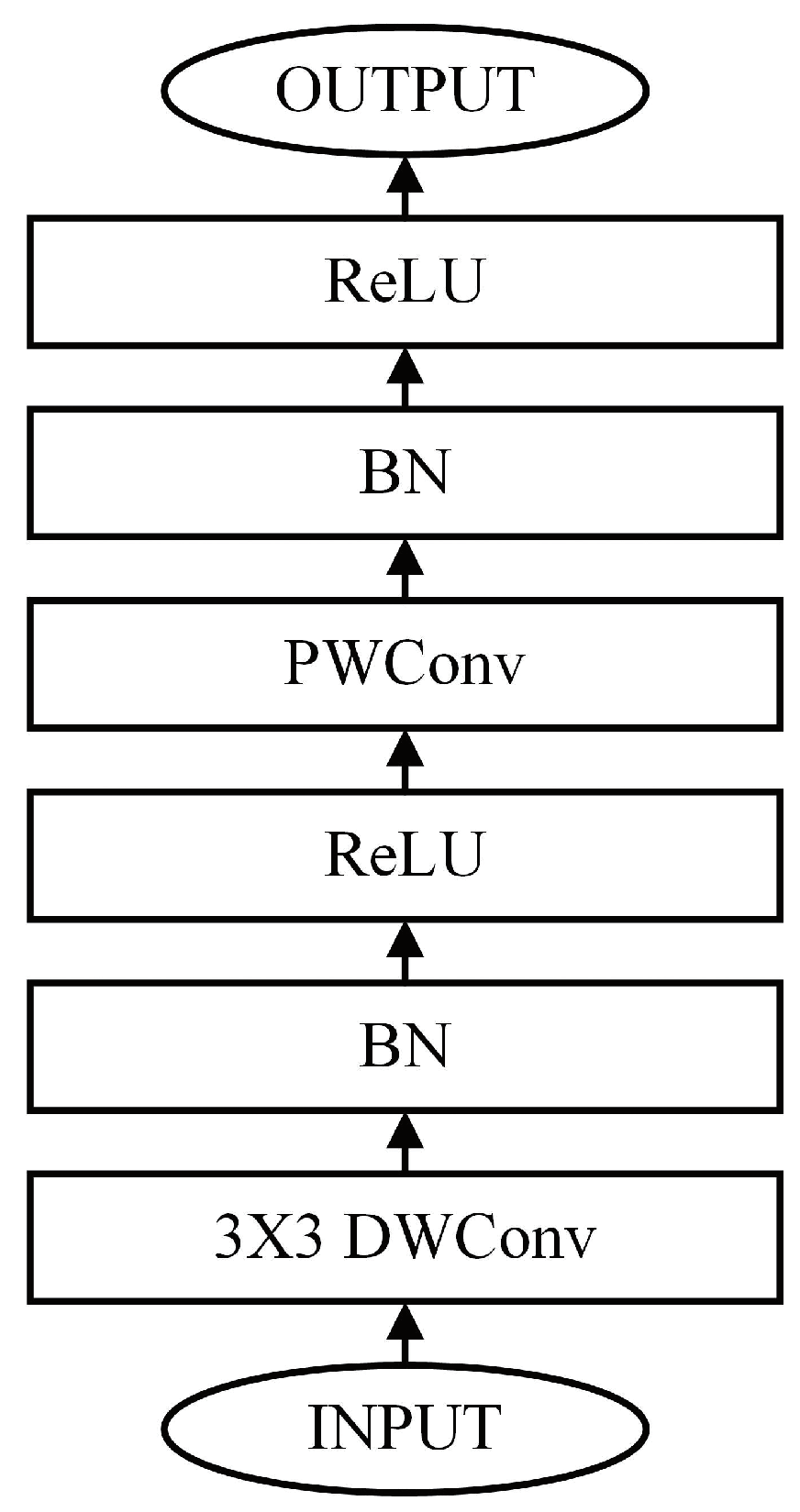
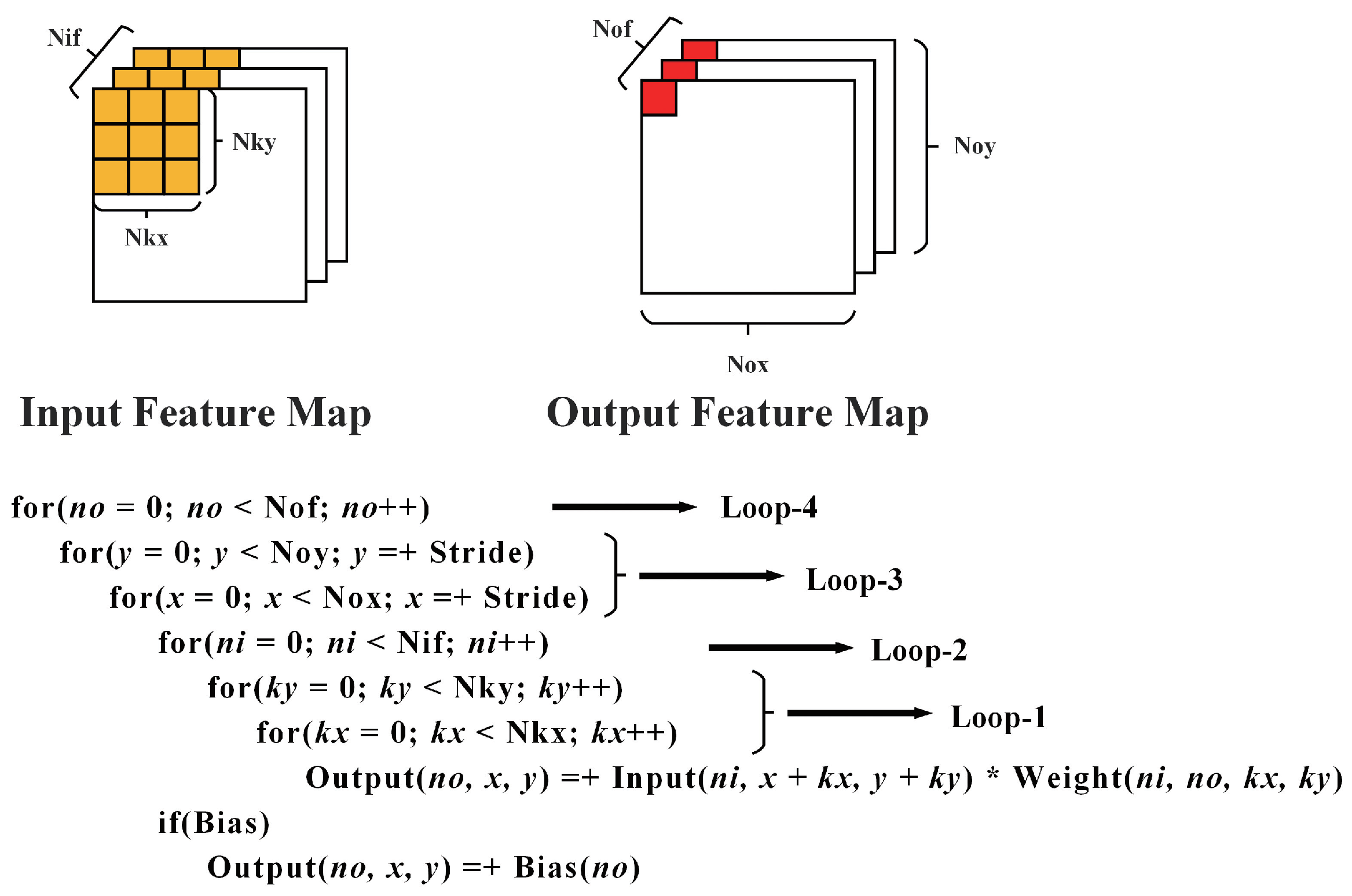
3.1. Depthwise Separable Convolution
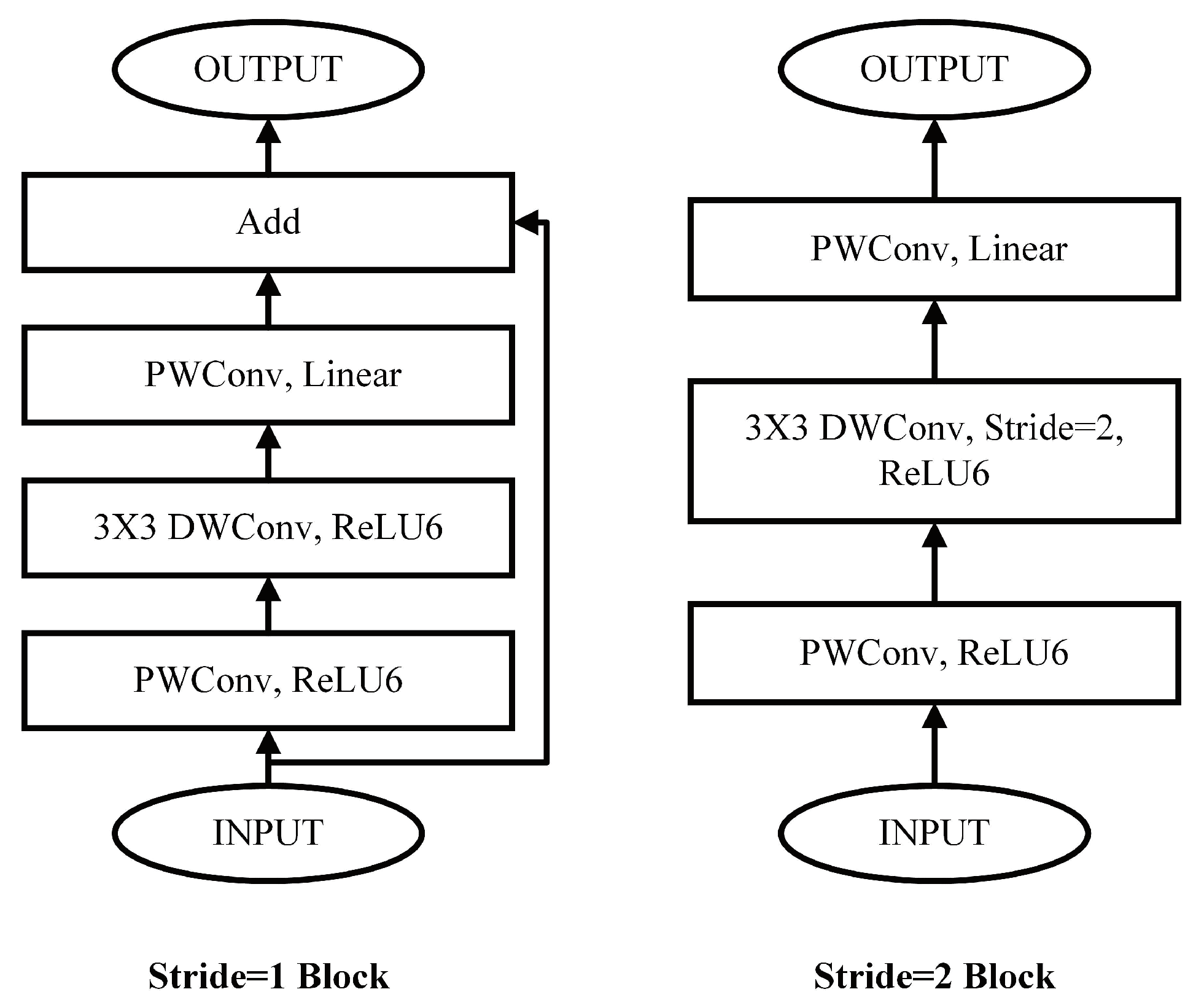
3.2. MobileNet and MobileNetV2
4. Hardware Design
4.1. Architecture Overview
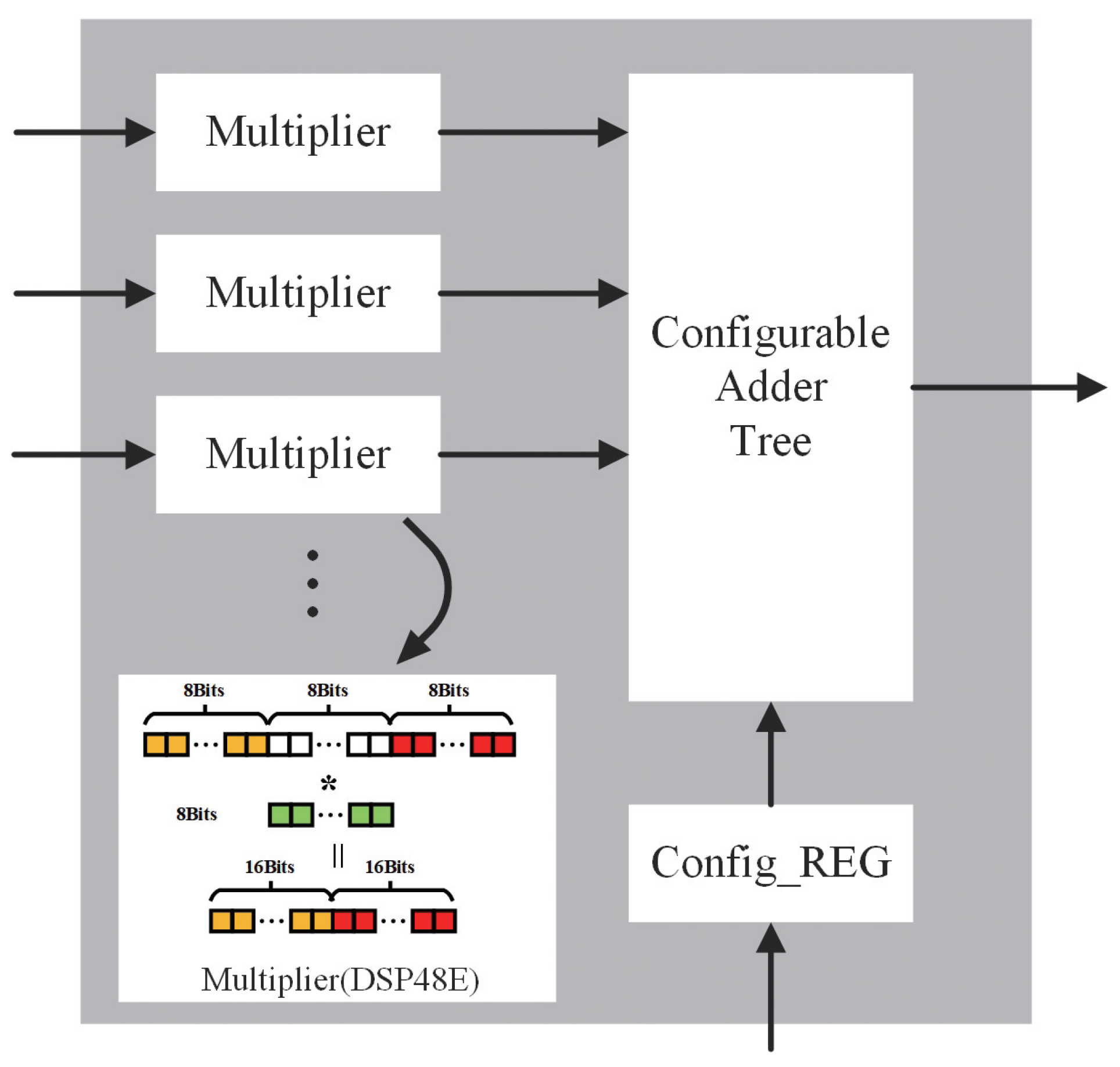
4.2. Compute Engine Design
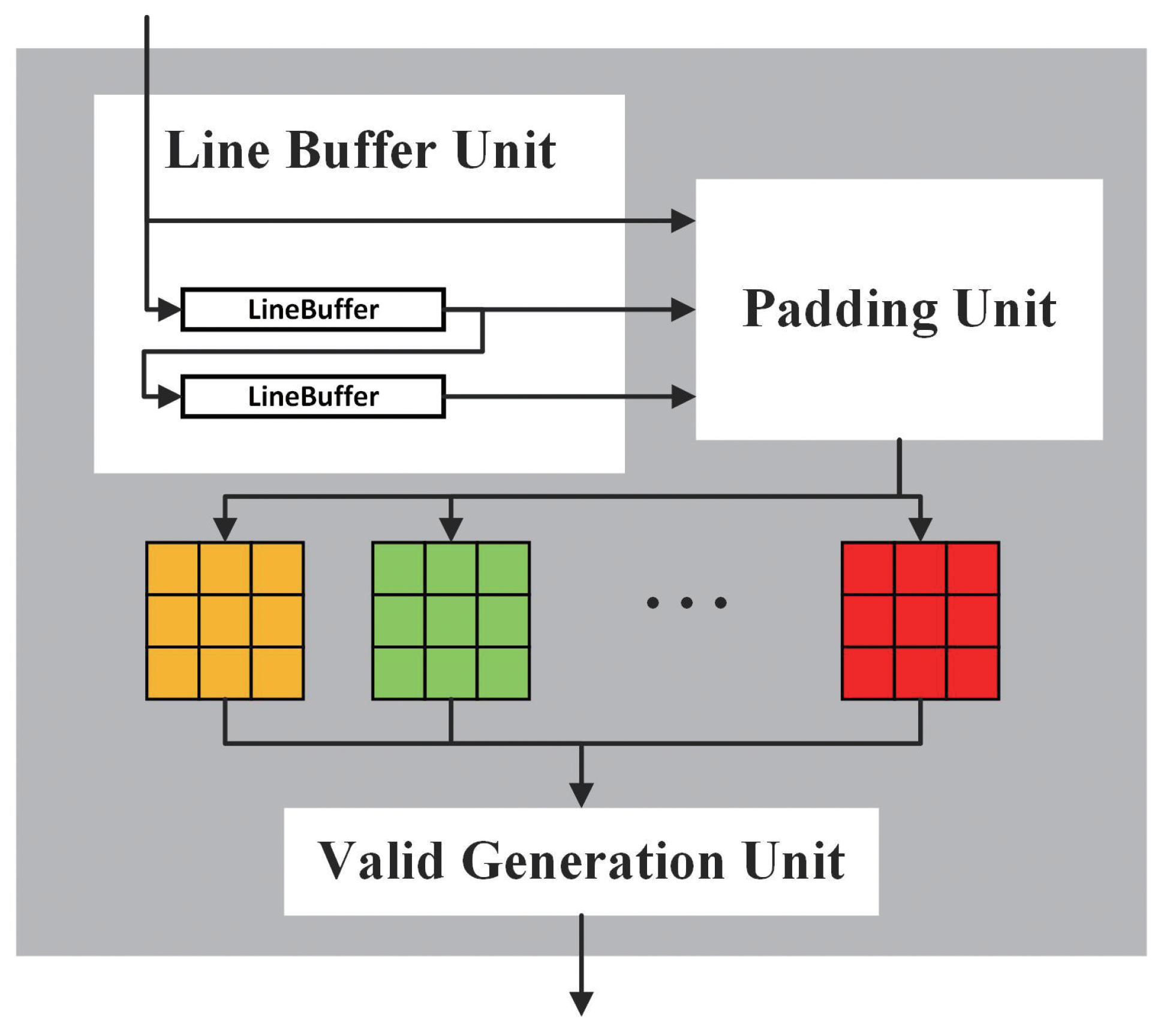
4.3. Dataflow Structure
4.4. On-Chip Memory Control Method
5. Results
5.1. Experimental Framework
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Montaha, S.; Azam, S.; Rafid, A.K.M.R.H.; Hasan, M.Z.; Karim, A.; Islam, A. Timedistributed-cnn-lstm: A hybrid approach combining cnn and lstm to classify brain tumor on 3d mri scans performing ablation study. IEEE Access 2022, 10, 60039–60059. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. 2014. Available online: https://arxiv.org/abs/1409.1556 (accessed on 14 December 2022).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical Guidelines for Efficient CNN Architecture Design; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ciobanu, A.; Luca, M.; Barbu, T.; Drug, V.; Olteanu, A.; Vulpoi, R. Experimental deep learning object detection in real-time colonoscopies. In Proceedings of the 2021 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 18–19 November 2021; pp. 1–4. [Google Scholar]
- Sae-Lim, W.; Wettayaprasit, W.; Aiyarak, P. Convolutional neural networks using mobilenet for skin lesion classification. In Proceedings of the 2019 16th International Joint Conference on Computer Science and Software Engineering (JCSSE), Chonburi, Thailand, 10–12 July 2019; pp. 242–247. [Google Scholar]
- Nurfirdausi, A.F.; Soekirno, S.; Aminah, S. Implementation of single shot detector (ssd) mobilenet v2 on disabled patient’s hand gesture recognition as a notification system. In Proceedings of the 2021 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, 23–25 October 2021; pp. 1–6. [Google Scholar]
- Fan, W.; Gao, Q.; Li, W. Face mask detection based on MobileNet with transfer learning. In Second IYSF Academic Symposium on Artificial Intelligence and Computer Engineering; Qin, W., Ed.; International Society for Optics and Photonics; SPIE: Bellingham, WA, USA, 2021; Volume 12079, p. 120792H. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Luo, T.; Liu, S.; Zhang, S.; He, L.; Wang, J.; Li, L.; Chen, T.; Xu, Z.; Sun, N.; et al. Dadiannao: A machine-learning supercomputer. In Proceedings of the 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; pp. 609–622. [Google Scholar]
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Li, L.; Luo, T.; Feng, X.; Chen, Y.; Temam, O. Shidiannao: Shifting vision processing closer to the sensor. In Proceedings of the 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; IEEE Computer Society: Los Alamitos, CA, USA, 2015; pp. 92–104. [Google Scholar]
- Yang, Y.; Huang, Q.; Wu, B.; Zhang, T.; Ma, L.; Gambardella, G.; Blott, M.; Lavagno, L.; Vissers, K.A.; Wawrzynek, J. Synetgy: Algorithm-hardware co-design for convnet accelerators on embedded fpgas. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019. [Google Scholar]
- Su, J.; Faraone, J.; Liu, J.; Zhao, Y.; Cheung, P.Y.K. Redundancy-Reduced Mobilenet Acceleration on Reconfigurable Logic for Imagenet Classification; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Bai, L.; Zhao, Y.; Huang, X. A cnn accelerator on fpga using depthwise separable convolution. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1415–1419. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Zhang, Y.; Jia, X.; Tian, L.; Shan, Y. A high-performance cnn processor based on fpga for mobilenets. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019. [Google Scholar]
- Knapheide, J.; Stabernack, B.; Kuhnke, M. A high throughput mobilenetv2 fpga implementation based on a flexible architecture for depthwise separable convolution. In Proceedings of the 2020 30th International Conference on Field-Programmable Logic and Applications (FPL), Gothenburg, Sweden, 31 August–4 September 2020. [Google Scholar]
- Ou, J.; Li, X.; Sun, Y.; Shi, Y. A configurable hardware accelerator based on hybrid dataflow for depthwise separable convolution. In Proceedings of the 2022 4th International Conference on Advances in Computer Technology, Information Science and Communications (CTISC), Suzhou, China, 22–24 April 2022; pp. 1–5. [Google Scholar]
- Guo, J.; Li, Y.; Lin, W.; Chen, Y.; Li, J. Network decoupling: From regular to depthwise separable convolutions. arXiv 2018, arXiv:1808.05517. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Lavin, A.; Gray, S. Fast algorithms for convolutional neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4013–4021. [Google Scholar]
- Yépez, J.; Ko, S.-B. Stride 2 1-d, 2-d, and 3-d winograd for convolutional neural networks. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 853–863. [Google Scholar] [CrossRef]
- Kwon, K.; Amid, A.; Gholami, A.; Wu, B.; Asanović, K.; Keutzer, K. Invited: Co-design of deep neural nets and neural net accelerators for embedded vision applications. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.B.K.; Sun Seo, J. Optimizing loop operation and dataflow in fpga acceleration of deep convolutional neural networks. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.G.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2704–2713. [Google Scholar]
- Yan, S.; Liu, Z.; Wang, Y.; Zeng, C.; Liu, Q.; Cheng, B.; Cheung, R.C. An fpga-based mobilenet accelerator considering network structure characteristics. In Proceedings of the 2021 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021; pp. 17–23. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | LUT | DSP (DSP48E) | BRAM |
|---|---|---|---|
| Accelerator | 32,956 (61.9%) | 176 (80%) | 107.5 (76.8%) |
| DMA | 2000 (3.8%) | 0 (0%) | 12 (8.6%) |
| Other | 1333 (2.5%) | 0 (0%) | 0 (0%) |
| Total | 36,289 (68.2%) | 176 (80%) | 119.5 (85.4%) |
| Layer (Input Size) | Operator | Stride | PWC+DWC | PWC | ||
|---|---|---|---|---|---|---|
| Communication Delay (us) | Computation Delay (us) | Communication Delay (us) | Computation Delay (us) | |||
| 224 × 224 × 3 | Conv2d | 2 | N/A | N/A | 24.56 | 405.81 |
| 112 × 112 × 32 | Bottleneck | 1 | 31.40 | 586.67 | 24.56 | 404.49 |
| 112 × 112 × 16 | Bottleneck | 2 | 34.01 | 1296.53 | 65.02 | 270.47 |
| 1 | 30.65 | 600.87 | 108.00 | 430.33 | ||
| 56 × 56 × 24 | Bottleneck | 2 | 30.65 | 522.08 | 106.08 | 129.47 |
| 1 | 24.07 | 265.79 | 127.01 | 150.92 | ||
| 28 × 28 × 32 | Bottleneck | 2 | 24.07 | 171.47 | 33.04 | 78.68 |
| 1 | 16.55 | 209.50 | 65.68 | 144.35 | ||
| 14 × 14 × 64 | Bottleneck | 1 | 16.55 | 209.47 | 65.79 | 216.36 |
| 1 | 24.71 | 412.38 | 98.43 | 314.83 | ||
| 14 × 14 × 96 | Bottleneck | 2 | 24.71 | 341.67 | 28.08 | 152.12 |
| 1 | 21.43 | 309.20 | 46.32 | 244.99 | ||
| 7 × 7 × 160 | Bottleneck | 1 | 21.43 | 309.17 | 46.85 | 489.72 |
| 7 × 7 × 320 | Conv2d | 1 | N/A | N/A | 19.65 | 670.02 |
| 1280 × 1000 | Conv2d | 1 | N/A | N/A | 9.77 | 1345.96 |
| [19] | [20] | [21] | [31] | This Paper | |
|---|---|---|---|---|---|
| Platform | Arria10 | ZU2 | Arria10 | Virtex7 | XC7Z020 |
| CNN Model | MobileNetV2 | ||||
| Frequency | 133 MHz | 430 MHz | 200 MHz | 150 MHz | 150 MHz |
| DSP Usage | 1278 | 212 | 1220 | 2160 | 176 (248 1) |
| On-Chip Memory Usage | 1844 M20K (3.07 MB) | 145 BRAM | 15.3 Mb (1.91 MB) | 941.5 BRAM | 119.5 BRAM (524.25 KB) |
| Speed | 266.2 FPS | 205.3 FPS | 1050 FPS (Throughput) | 302.3 FPS | 70.94 FPS |
| FPS/MHz per DSP per KB () | 0.50 | 3.54 | 2.20 | 0.23 | 5.13 (3.64 1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Zhang, Y.; Yang, X. A Low Memory Requirement MobileNets Accelerator Based on FPGA for Auxiliary Medical Tasks. Bioengineering 2023, 10, 28. https://doi.org/10.3390/bioengineering10010028
Lin Y, Zhang Y, Yang X. A Low Memory Requirement MobileNets Accelerator Based on FPGA for Auxiliary Medical Tasks. Bioengineering. 2023; 10(1):28. https://doi.org/10.3390/bioengineering10010028
Chicago/Turabian StyleLin, Yanru, Yanjun Zhang, and Xu Yang. 2023. "A Low Memory Requirement MobileNets Accelerator Based on FPGA for Auxiliary Medical Tasks" Bioengineering 10, no. 1: 28. https://doi.org/10.3390/bioengineering10010028