
Nondestructive Detection of Sunflower Seed Vigor and Moisture Content Based on Hyperspectral Imaging and Chemometrics

Abstract
:
1. Introduction
2. Materials and Methods
2.1. Seed Sample Preparation
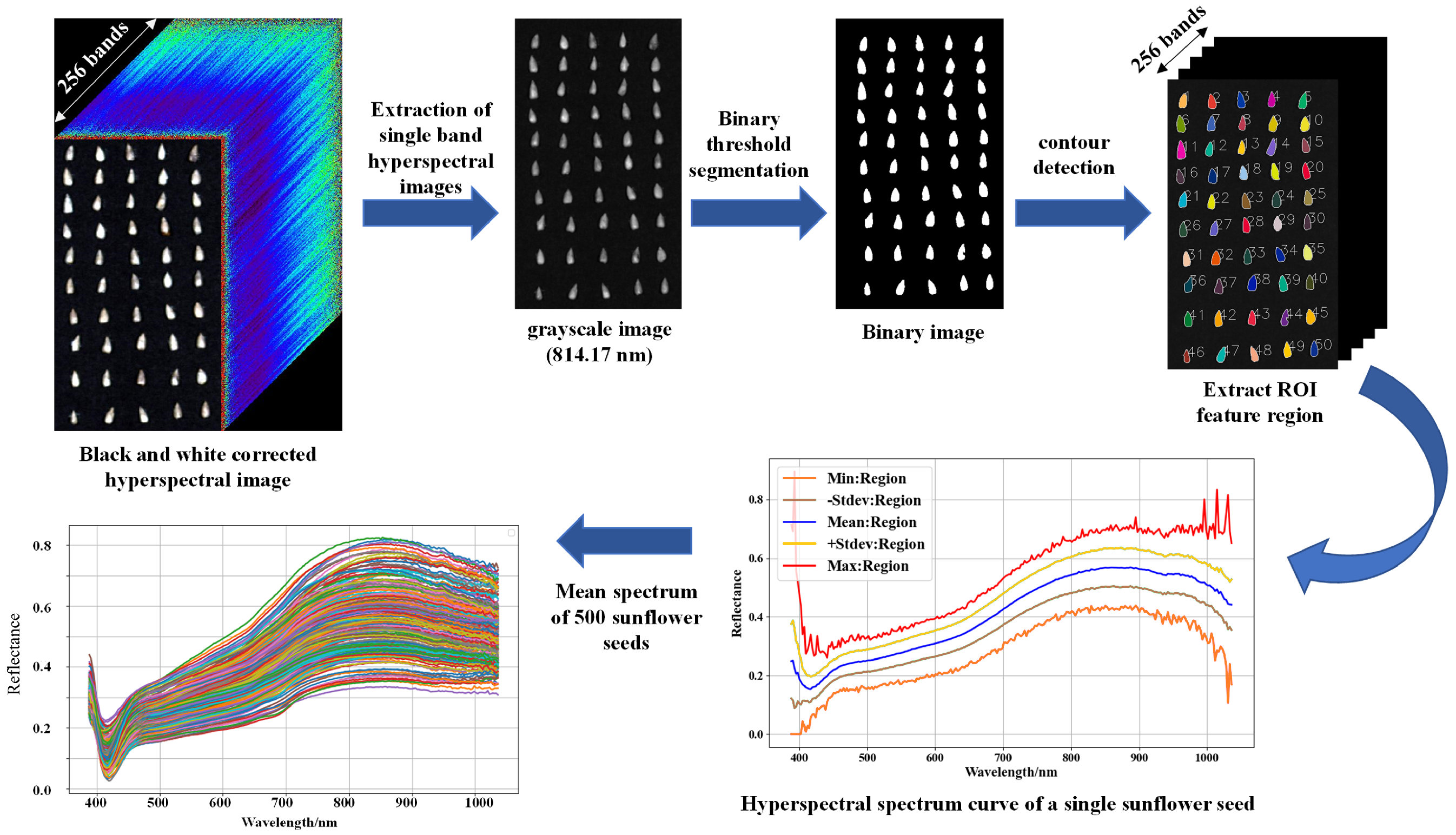
2.2. Hyperspectral Image Data Acquisition
2.3. Standard Germination Test
2.4. Moisture Content Determination
2.5. Data Analysis Method
2.5.1. Spectral Preprocessing
2.5.2. Sample Partition
2.5.3. Feature Dimension Reduction Algorithm
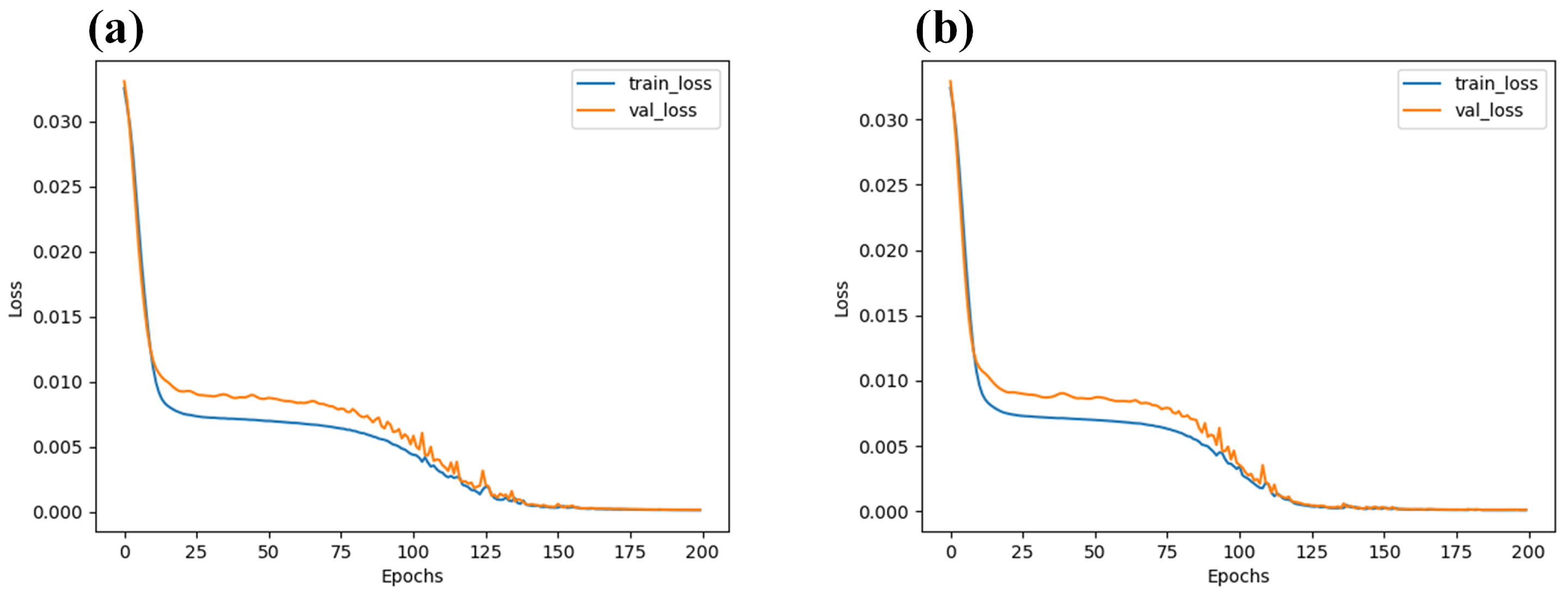
2.5.4. Modeling Method
2.5.5. Model Evaluation Metrics
3. Results and Discussion
3.1. Standard Germination Test Results
3.2. Results of Moisture Content Determination
3.3. Original Spectrum and Pretreatment Results
3.4. Feature Dimension Reduction Results
3.4.1. PCA
3.4.2. XGBoost
3.4.3. Stacked Autoencoder
3.5. Classification Results of Seed Vigor
3.6. Prediction Results of Seed Moisture Content
3.7. Correlation Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, X.; Feng, X.; Sun, D.; Liu, F.; Bao, Y.; He, Y. Rapid and Nondestructive Measurement of Rice Seed Vitality of Different Years Using Near-Infrared Hyperspectral Imaging. Molecules 2019, 24, 2227. [Google Scholar] [CrossRef] [PubMed]
- Ellis, R.H.; Nasehzadeh, M.; Hanson, J.; Ndiwa, N.; Woldemariam, Y. Medium-term seed storage of diverse genera of forage grasses, evidence-based genebank monitoring intervals, and regeneration standards. Genet. Resour. Crop. Evol. 2019, 66, 723–734. [Google Scholar] [CrossRef]
- Zheljazkov, V.D.; Vick, B.A.; Baldwin, B.S.; Buehring, N.; Coker, C.; Astatkie, T.; Johnson, B. Oil productivity and composition of sunflower as a function of hybrid and planting date. Ind. Crop. Prod. 2011, 33, 537–543. [Google Scholar] [CrossRef]
- Dode, J.D.; Meneghello, G.E.; Timm, F.C.; Moraes, D.M.D.; Peske, S.T. Respiration test soybean seed as related of physiological quality. Cienc. Rural. 2013, 43, 193–198. [Google Scholar] [CrossRef]
- Li, J.; Zhang, B.; Gao, H.; Mu, S.; Gao, J. Anatomical structural changes and correlation between moisture content and germination characteristics during seed germination of Phyllostachys edulis (Carriere) J. Houz. Propag. Ornam. Plants 2019, 19, 3–10. [Google Scholar]
- Matsuura, T.; Mori, I.C.; Himi, E.; Hirayama, T. Plant hormone profiling in developing seeds of common wheat (Triticum aestivum L.). Breed. Sci. 2019, 69, 601–610. [Google Scholar] [CrossRef] [PubMed]
- Jastrzebowski, S.; Kantorowicz, W.; Anisko, E.; Ukalska, J. Conductivity test for Scots pine (Pinus sylvestris L.) and Douglas fir (Pseudotsuga menziesii (Mirb.) Franco) seeds vitality assessment. Sylwan 2017, 161, 927–934. [Google Scholar]
- Carrillo-Reche, J.; Newton, A.C.; Quilliam, R.S. Using seed respiration as a tool for calculating optimal soaking times for `on-farm’ seed priming of barley (Hordeum vulgare). Seed Sci. Res. 2021, 31, 116–124. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, S.Q.; Xiao, S.Y.; Wang, Y.P. Determination of seed moisture content in ginseng (Panax ginseng CA Mey). Seed Sci. Technol. 2014, 42, 444–448. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, J.; Gu, Y.; Zhang, Y.; Chen, Y.; Song, P.; Yang, T. A Methodology Study on the Optimal Detection of Oil and Moisture Content in Soybeans Using LF-NMR and Its 2D Nuclear Magnetic Technology. Agronomy 2023, 13, 1102. [Google Scholar] [CrossRef]
- Carneiro, J.D.S.; Nogueira, R.M.; Martins, M.A.; Valladão, D.M.D.S.; Pires, E.M. The oven-drying method for determination of water content in Brazil nut. Biosci. J. 2018, 34, 1195–1202. [Google Scholar] [CrossRef]
- Mishra, S.N.; Kumari, N.; Mishra, N.N.; Mishra, K. Estimation of Hormonal Seed Treatments on Enzyme Activities after Accelerated Ageing (Artificial Ageing) in Chickpea (Cicer arietinum L.). Legume Res. 2023, 46, 421–427. [Google Scholar]
- Wang, X.M.; Zhang, H.; Song, R.; He, X.; Mao, P.; Jia, S. Non-Destructive Identification of Naturally Aged Alfalfa Seeds via Multispectral Imaging Analysis. Sensors 2021, 21, 5804. [Google Scholar] [CrossRef] [PubMed]
- Soares, S.F.C.; Medeiros, E.P.; Pasquini, C.; de Lelis Morello, C.; Galvão, R.K.H.; Araújo, M.C.U. Classification of individual cotton seeds with respect to variety using near-infrared hyperspectral imaging. Anal. Methods 2016, 8, 8498–8505. [Google Scholar] [CrossRef]
- Li, C.L.; Jiang, K.; Feng, Q.C.; Wang, X.; Meng, Z.J.; Wang, S.L.; Gao, Y.Y. Melon Seeds Variety Identification Based on Chlorophyll Fluorescence Spectrum and Reflectance Spectrum. Spectrosc. Spectr. Anal. 2018, 38, 151–156. [Google Scholar]
- Haruna, S.A.; Ivane, N.M.A.; Adade, S.Y.S.S.; Luo, X.F.; Geng, W.H.; Zareef, M.; Jargbah, J.; Li, H.H.; Chen, Q.S. Rapid and simultaneous quantification of phenolic compounds in peanut (Arachis hypogaea L.) seeds using NIR spectroscopy coupled with multivariate calibration. J. Food Compos. Anal. 2023, 123, 105516. [Google Scholar] [CrossRef]
- Liu, J.; Fan, S.; Cheng, W.M.; Yang, Y.; Li, X.H.; Wang, Q.; Liu, B.M.; Xu, Z.P.; Wu, Y.J. Non-Destructive Discrimination of Sunflower Seeds with Different Internal Mildew Grades by Fusion of Near-Infrared Diffuse Reflectance and Transmittance Spectra Combined with 1D-CNN. Foods 2023, 12, 295. [Google Scholar] [CrossRef] [PubMed]
- Silva, M.F.D.; Roque, J.V.; Soares, J.M.; Moura, L.D.O.; Medeiros, A.D.D.; Silva, F.L.D.; Silva, L.J.D. Near infrared spectroscopy for the classification of vigor level of soybean seed. Rev. Cienc. Agron. 2023, 55, e20238703. [Google Scholar] [CrossRef]
- Long, Y.; Wang, Q.Y.; Tang, X.Y.; Tian, X.; Huang, W.Q.; Zhang, B. Label-free detection of maize kernels aging based on Raman hyperspcectral imaging techinique. Comput. Electron. Agric. 2022, 200, 107229. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, L.; Zhou, X.; Yao, K.S.; Tian, Y.; Nirere, A. A method of information fusion for identification of rice seed varieties based on hyperspectral imaging technology. J. Food Process. Eng. 2021, 44, e13797. [Google Scholar] [CrossRef]
- An, J.L.; Zhang, C.; Zhou, L.; Jin, S.L.; Zhang, Z.Y.; Zhao, W.Y.; Pan, X.P.; Zhang, W.D. Tensor based low rank representation of hyperspectral images for wheat seeds varieties identification. Comput. Electr. Eng. 2023, 110, 108890. [Google Scholar] [CrossRef]
- Zou, Z.Y.; Chen, J.; Zhou, M.; Wang, Z.T.; Liu, K.; Zhao, Y.P.; Wang, Y.C.; Wu, W.J.; Xu, L.J. Identification of peanut storage period based on hyperspectral imaging technology. Food Sci. Technol. 2022, 42, e65822. [Google Scholar] [CrossRef]
- Cui, H.W.; Cheng, Z.S.; Li, P.; Miao, A.M. Prediction of Sweet Corn Seed Germination Based on Hyperspectral Image Technology and Multivariate Data Regression. Sensors 2020, 20, 4744. [Google Scholar] [CrossRef] [PubMed]
- Kandpal, L.M.; Lohumi, S.; Kim, M.S.; Kang, J.S.; Cho, B.K. Near-infrared hyperspectral imaging system coupled with multivariate methods to predict viability and vigor in muskmelon seeds. Sensors Actuators B-Chem. 2016, 229, 534–544. [Google Scholar] [CrossRef]
- Wang, Z.L.; Huang, W.Q.; Tian, X.; Long, Y.; Li, L.J.; Fan, S.X. Rapid and Non-destructive Classification of New and Aged Maize Seeds Using Hyperspectral Image and Chemometric Methods. Front. Plant Sci. 2022, 13, 849495. [Google Scholar] [CrossRef] [PubMed]
- Zohaib, A.; Tabassum, T.; Jabbar, A.; Anjum, S.A.; Abbas, T.; Mehmood, A.; Irshad, S.; Kashif, M.; Nawaz, M.; Farooq, N.; et al. Effect of Plant Density, Boron Nutrition and Growth Regulation on Seed Mass, Emergence and Offspring Growth Plasticity in Cotton. Sci. Rep. 2018, 8, 7953. [Google Scholar] [CrossRef]
- Du, W.F.; Zhu, W.H.; Ge, W.H.; Li, C.Y. Research on the effect of spleen-invigorating and anti-swelling active ingredients in crude and processed coix seed based on Spectrum–Effects relationship combined with chemometrics. J. Pharm. Biomed. Anal. 2021, 205, 114350. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.L.; Zhang, Y.F.; Fan, S.X.; Jiang, Y.L.; Li, J.B. Determination of Moisture Content of Single Maize Seed by Using Long-Wave Near-Infrared Hyperspectral Imaging (LWNIR) Coupled With UVE-SPA Combination Variable Selection Method. IEEE Access 2020, 8, 195229–195239. [Google Scholar] [CrossRef]
- Li, P.; Su, G.L.; Du, G.R.; Jiang, L.W.; Dong, Y.Q.; Shan, Y. Portable LWNIR and SWNIR spectroscopy with pattern recognition technology for accurate and nondestructive detection of hidden mold infection in citrus. Microchem. J. 2023, 193, 109203. [Google Scholar] [CrossRef]
- Patil, K.G.; Karjule, A.; Patel, D.A.; Sasidharan, N. Effect of accelerated ageing on viability and longevity of wheat (Triticum aestivum) seed. Indian J. Agric. Sci. 2019, 89, 920–928. [Google Scholar] [CrossRef]
- Wang, B.; Yang, R.C.; Ji, Z.Q.; Zhang, H.X.; Zheng, W.B.; Zhang, H.H.; Feng, F.Q. Evaluation of Biochemical and Physiological Changes in Sweet Corn Seeds under Natural Aging and Artificial Accelerated Aging. Agronomy 2022, 12, 1028. [Google Scholar] [CrossRef]
- Sghaier, A.H.; Khaeim, H.; Tarnawa, A.; Kovács, G.P.; Gyuricza, C.; Kende, Z. Germination and Seedling Development Responses of Sunflower (Helianthus annuus L.) Seeds to Temperature and Different Levels of Water Availability. Agriculture 2023, 13, 608. [Google Scholar] [CrossRef]
- Yuan, X.T.; Zhang, X.; Zhang, N.N.; Ma, R.; He, D.D.; Bao, H.; Sun, W.J. Hyperspectral Estimation of SPAD Value of Cotton Leaves under Verticillium Wilt Stress Based on GWO-ELM. Agriculture 2023, 13, 1779. [Google Scholar] [CrossRef]
- Yu, H.W.; Liu, H.Z.; Wang, N.; Yang, Y.; Shi, A.M.; Liu, L.; Hu, H.; Mzimbiri, R.I.; Wang, Q. Rapid and visual measurement of fat content in peanuts by using the hyperspectral imaging technique with chemometrics. Anal. Methods 2016, 8, 7482–7492. [Google Scholar] [CrossRef]
- Zhang, L.; Rao, Z.H.; Ji, H.Y. NIR Hyperspectral Imaging Technology Combined with Multivariate Methods to Study the Residues of Different Concentrations of Omethoate on Wheat Grain Surface. Sensors 2019, 19, 3147. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Zhang, D.J.; Zhan, S.Y.; Shen, Y.; Wang, H.Z.; Song, H.; Xu, J.; He, Y. Research on Sample Division and Modeling Method of Spectrum Detection of Moisture Content in Dehydrated Scallops. Spectrosc. Spectr. Anal. 2019, 39, 185–192. [Google Scholar]
- Chen, Y.S.; Lin, Z.H.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Loggenberg, K.; Strever, A.; Greyling, B.; Poona, N. Modelling Water Stress in a Shiraz Vineyard Using Hyperspectral Imaging and Machine Learning. Remote Sens. 2018, 10, 202. [Google Scholar] [CrossRef]
- Ge, X.Y.; Ding, J.L.; Jin, X.L.; Wang, J.Z.; Chen, X.Y.; Li, X.H.; Liu, J.; Xie, B.Q. Estimating Agricultural Soil Moisture Content through UAV-Based Hyperspectral Images in the Arid Region. Remote Sens. 2021, 13, 1562. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.C.; Zheng, J.B.; Zhao, H.M.; Qing, C.M.; Yang, Z.J.; Du, P.J.; Marshall, S. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing 2016, 185, 1–10. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Cao, G.; Li, X.S.; Wang, B.S. Cascaded Random Forest for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1082–1094. [Google Scholar] [CrossRef]
- Yoon, H.I.; Lee, H.; Yang, J.S.; Choi, J.H.; Jung, D.H.; Park, Y.J.; Park, J.E.; Kim, S.M.; Park, S.H. Predicting Models for Plant Metabolites Based on PLSR, AdaBoost, XGBoost, and LightGBM Algorithms Using Hyperspectral Imaging of Brassica juncea. Agriculture 2023, 13, 1477. [Google Scholar] [CrossRef]
- Padhi, D.K.; Padhy, N.; Bhoi, A.K.; Shafi, J.; Ijaz, M.F. A Fusion Framework for Forecasting Financial Market Direction Using Enhanced Ensemble Models and Technical Indicators. Mathematics 2021, 9, 2646. [Google Scholar] [CrossRef]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Tang, C.C.; Xiao, R.B.; Ling, B.H.; Wang, P.; Zheng, J.T.; Huang, F.; Liu, W.Z. Prediction of Cr and Ni contents in soil from hyperspectral data combined with Al-Fe minerals. Int. J. Remote Sens. 2023, 44, 2781–2797. [Google Scholar] [CrossRef]
- Zhao, W.; Zhao, X.N.; Luo, B.; Bai, W.W.; Kang, K.; Hou, P.C.; Zhang, H. Identification of wheat seed endosperm texture using hyperspectral imaging combined with an ensemble learning model. J. Food Compos. Anal. 2023, 121, 105398. [Google Scholar] [CrossRef]
- Cen, H.Y.; He, Y. Theory and application of near infrared reflectance spectroscopy in determination of food quality. Trends Food Sci. Technol. 2007, 18, 72–83. [Google Scholar] [CrossRef]
- Sasic, S.; Ozaki, Y. Short-wave near-infrared spectroscopy of biological fluids. 1. Quantitative analysis of fat, protein, and lactose in raw milk by partial least-squares regression and band assignment. Anal. Chem. 2001, 73, 64–71. [Google Scholar] [CrossRef]
- Zhang, H.; Hou, Q.L.; Luo, B.; Tu, K.L.; Zhao, C.P.; Sun, Q. Detection of seed purity of hybrid wheat using reflectance and transmittance hyperspectral imaging technology. Front. Plant Sci. 2022, 13, 1015891. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aging Class | Sample Count | Seed Vigor | Seed Inviability | GP | GR | GI | VI |
|---|---|---|---|---|---|---|---|
| NAA | 49 | 43 | 6 | 81.63% | 87.76% | 14.510 | 120.433 |
| 1AA | 47 | 33 | 14 | 59.57% | 70.21% | 9.641 | 53.026 |
| 2AA | 50 | 25 | 25 | 40.00% | 50.00% | 5.996 | 28.781 |
| 3AA | 50 | 18 | 32 | 20.00% | 36.00% | 3.769 | 14.699 |
| 4AA | 50 | 10 | 40 | 8.00% | 20.00% | 1.926 | 6.934 |
| Sample Type | Sample Size | Moisture Content (%) | |||
|---|---|---|---|---|---|
| Minimum | Maximum | Mean | Standard Deviation | ||
| Moisture content determination | 236 grains | 4.4799 | 24.6695 | 14.8082 | 4.9405 |
| Pretreatment | Feature Dimension Reduction | RF | LightGBM | ||
|---|---|---|---|---|---|
| Train | Test | Train | Test | ||
| RAW | All band | 98.84% | 91.89% | 94.77% | 94.59% |
| PCA | 95.93% | 85.14% | 97.67% | 95.95% | |
| XGBoost | 99.42% | 90.54% | 94.77% | 95.95% | |
| SAE | 97.09% | 86.49% | 97.09% | 95.95% | |
| SG | All band | 99.42% | 93.24% | 94.19% | 95.95% |
| PCA | 95.35% | 86.49% | 94.19% | 95.95% | |
| XGBoost | 98.84% | 97.30% | 95.35% | 93.24% | |
| SAE | 98.26% | 87.84% | 97.67% | 98.65% | |
| SNV | All band | 97.09% | 63.51% | 89.53% | 63.51% |
| PCA | 88.37% | 64.86% | 80.81% | 60.81% | |
| XGBoost | 95.93% | 66.22% | 86.63% | 68.92% | |
| SAE | 93.02% | 47.30% | 88.37% | 60.81% | |
| MSC | All band | 96.51% | 62.16% | 88.37% | 63.51% |
| PCA | 87.21% | 67.57% | 83.14% | 60.81% | |
| XGBoost | 94.19% | 60.81% | 87.79% | 67.57% | |
| SAE | 93.60% | 51.35% | 85.47% | 62.16% | |
| Pretreatment | Reduction Dimension | RF | LightGBM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RAW | All band | 0.9183 | 1.4063 | 0.8644 | 1.8226 | 0.9415 | 1.1894 | 0.9416 | 1.1952 |
| PCA | 0.9325 | 1.2778 | 0.8878 | 1.6572 | 0.8889 | 1.6394 | 0.9047 | 1.5271 | |
| XGBoost | 0.9344 | 1.2601 | 0.9012 | 1.5554 | 0.9320 | 1.2830 | 0.9438 | 1.1735 | |
| SAE | 0.8936 | 1.6044 | 0.8354 | 2.0075 | 0.9403 | 1.2016 | 0.9515 | 1.0889 | |
| SG | All band | 0.9151 | 1.4335 | 0.8699 | 1.7847 | 0.9345 | 1.2591 | 0.9383 | 1.2285 |
| PCA | 0.9275 | 1.3247 | 0.8824 | 1.6969 | 0.8889 | 1.6394 | 0.9031 | 1.5401 | |
| XGBoost | 0.9283 | 1.3171 | 0.8888 | 1.6498 | 0.9358 | 1.2458 | 0.9401 | 1.2111 | |
| SAE | 0.9164 | 1.4222 | 0.8684 | 1.7950 | 0.9210 | 1.3826 | 0.9191 | 1.4072 | |
| SNV | All band | 0.8849 | 1.6692 | 0.9080 | 1.5004 | 0.9213 | 1.3803 | 0.9476 | 1.1319 |
| PCA | 0.8650 | 1.8075 | 0.8790 | 1.7208 | 0.8458 | 1.9320 | 0.8515 | 1.9067 | |
| XGBoost | 0.8903 | 1.6293 | 0.9071 | 1.5082 | 0.9605 | 0.9776 | 0.9715 | 0.8349 | |
| SAE | 0.8569 | 1.8607 | 0.8688 | 1.7921 | 0.9156 | 1.4291 | 0.9321 | 1.2891 | |
| MSC | All band | 0.8903 | 1.6297 | 0.9043 | 1.5306 | 0.9221 | 1.3727 | 0.9348 | 1.2633 |
| PCA | 0.8684 | 1.7847 | 0.8874 | 1.6605 | 0.8452 | 1.9355 | 0.8548 | 1.8857 | |
| XGBoost | 0.8855 | 1.6645 | 0.9109 | 1.4769 | 0.9547 | 1.0468 | 0.9521 | 1.0058 | |
| SAE | 0.8803 | 1.7023 | 0.8911 | 1.6328 | 0.9166 | 1.4208 | 0.9392 | 1.2192 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, P.; Yuan, J.; Yang, P.; Xiao, F.; Zhao, Y. Nondestructive Detection of Sunflower Seed Vigor and Moisture Content Based on Hyperspectral Imaging and Chemometrics. Foods 2024, 13, 1320. https://doi.org/10.3390/foods13091320
Huang P, Yuan J, Yang P, Xiao F, Zhao Y. Nondestructive Detection of Sunflower Seed Vigor and Moisture Content Based on Hyperspectral Imaging and Chemometrics. Foods. 2024; 13(9):1320. https://doi.org/10.3390/foods13091320
Chicago/Turabian StyleHuang, Peng, Jinfu Yuan, Pan Yang, Futong Xiao, and Yongpeng Zhao. 2024. "Nondestructive Detection of Sunflower Seed Vigor and Moisture Content Based on Hyperspectral Imaging and Chemometrics" Foods 13, no. 9: 1320. https://doi.org/10.3390/foods13091320