
Deoxynivalenol Detection beyond the Limit in Wheat Flour Based on the Fluorescence Hyperspectral Imaging Technique

Abstract
:1. Introduction
2. Materials and Methods
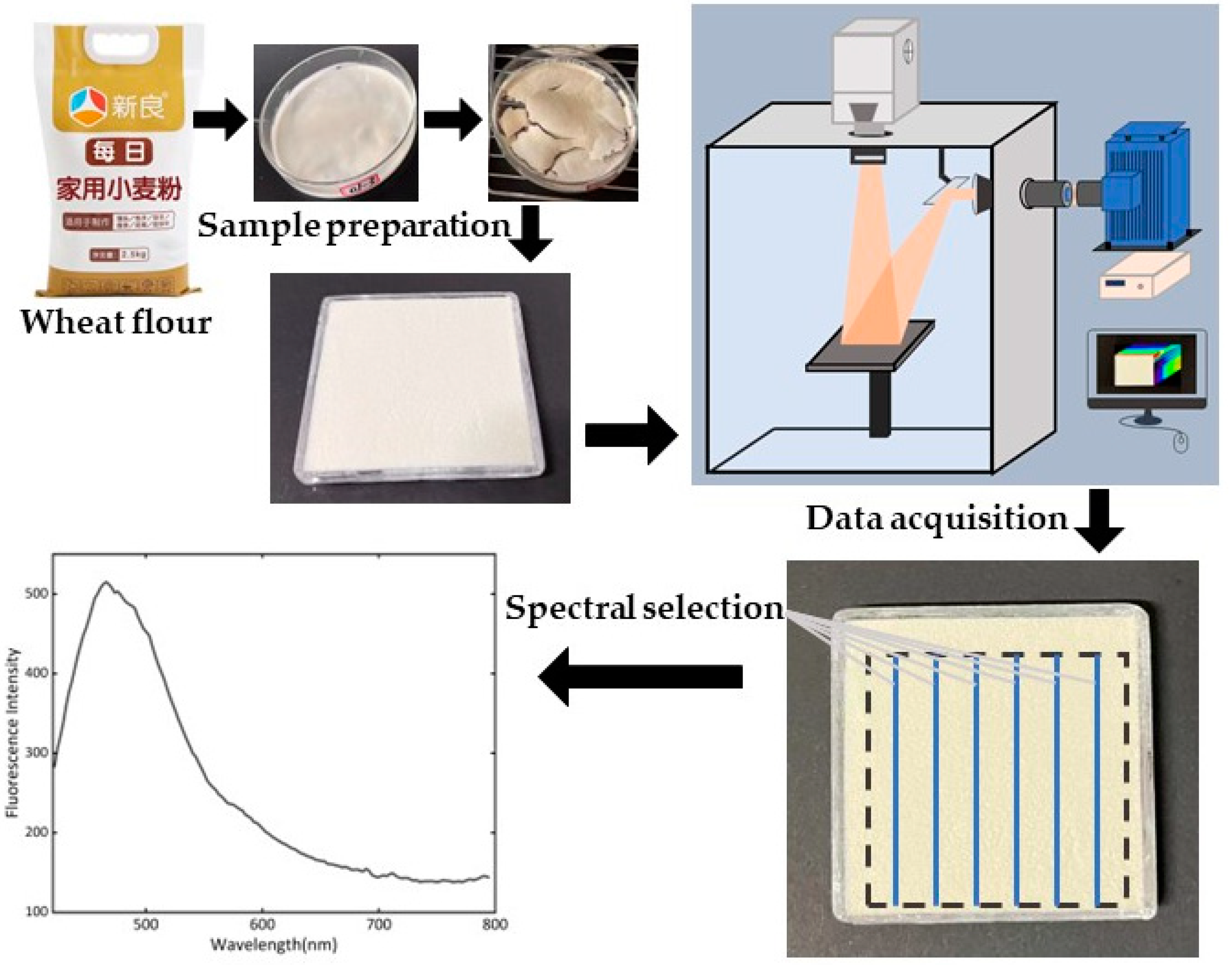
2.1. Sample Preparation
2.2. Hyperspectral System and Data Acquisition
2.3. Hyperspectral Data Preprocessing
2.4. Hyperspectral Data Analysis
2.4.1. Optimal Band Selection
2.4.2. Modeling Methods
2.4.3. Model Performance Evaluation and Spectral Feature Visualization
3. Results
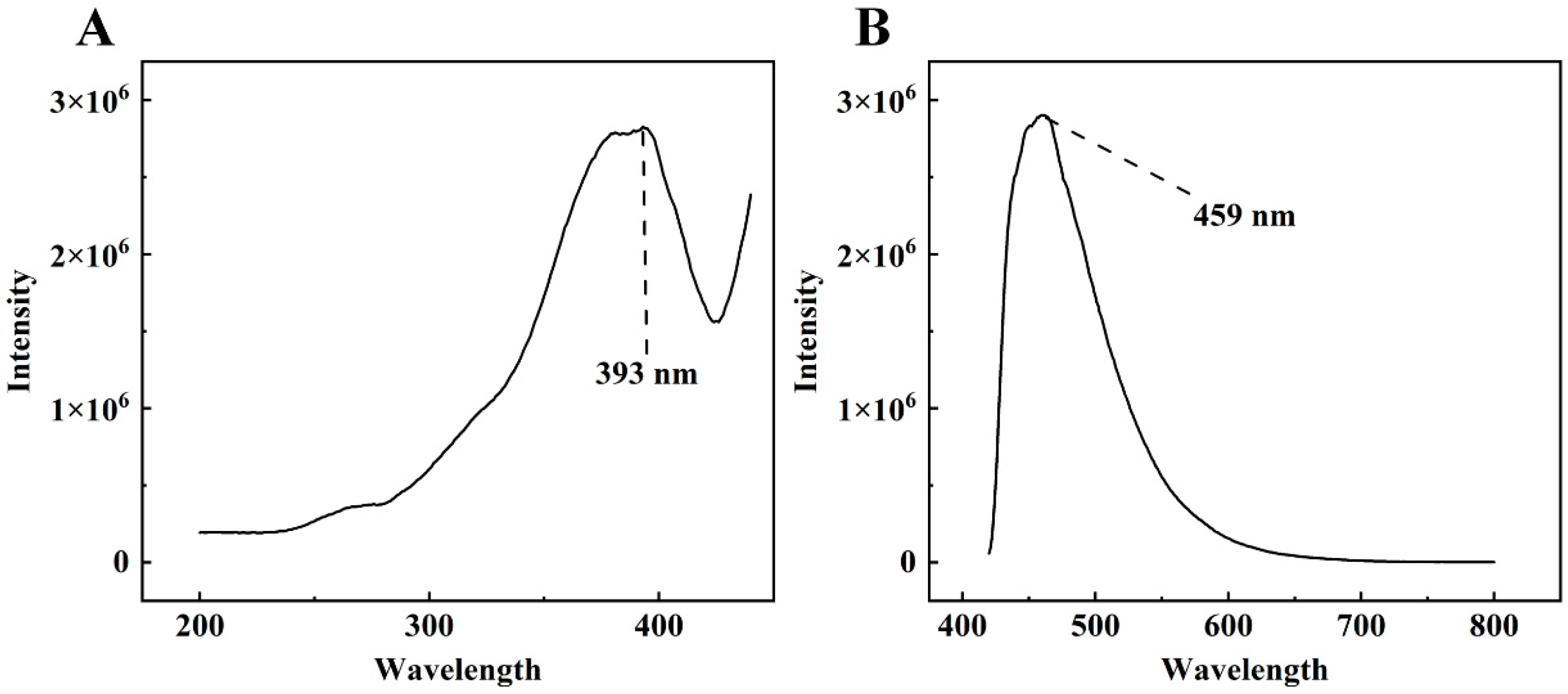
3.1. Determination of DON’s Excitation and Emission Wavelengths
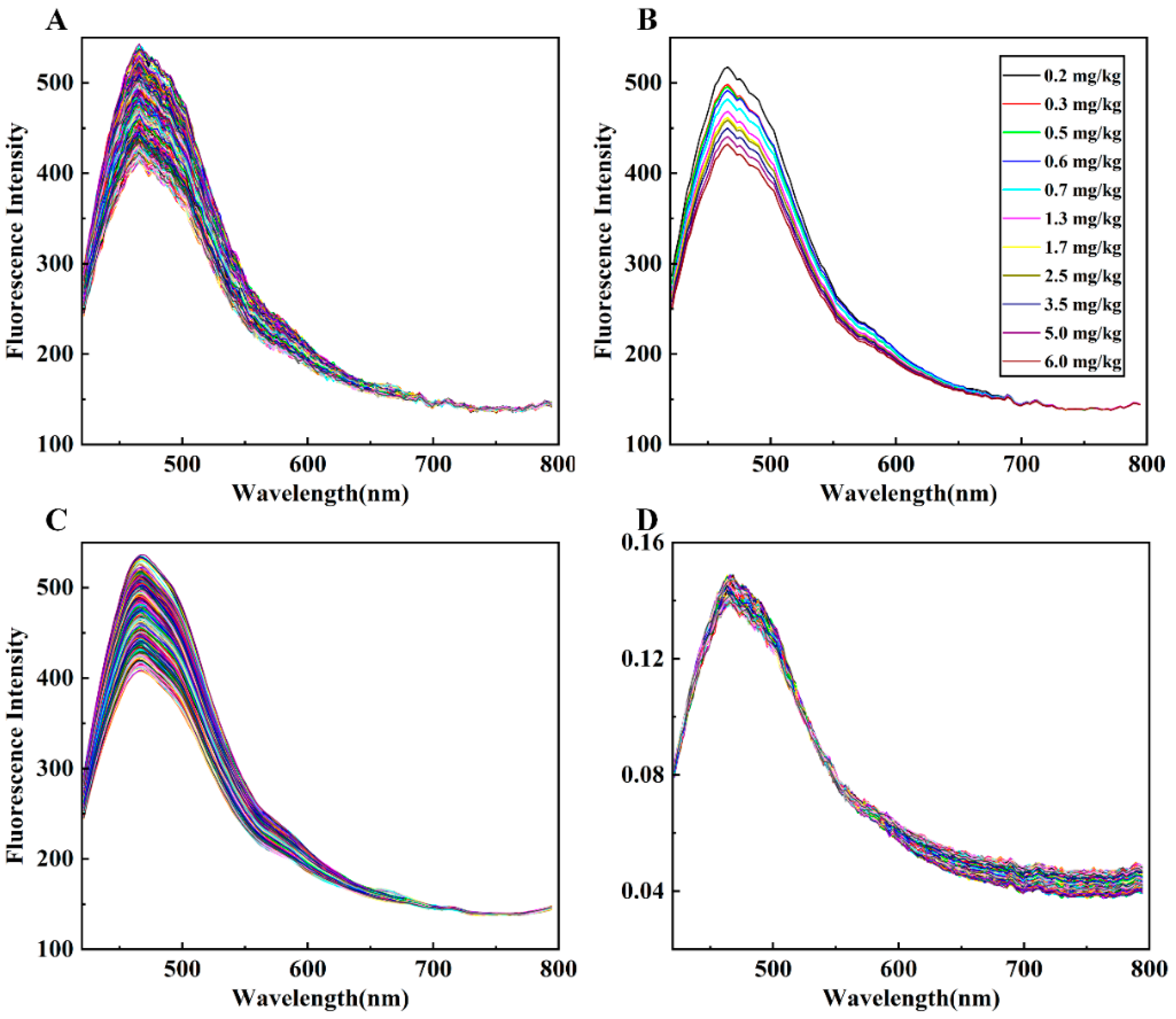
3.2. Fluorescence Spectra of Wheat Flour Containing Different Concentrations of DON
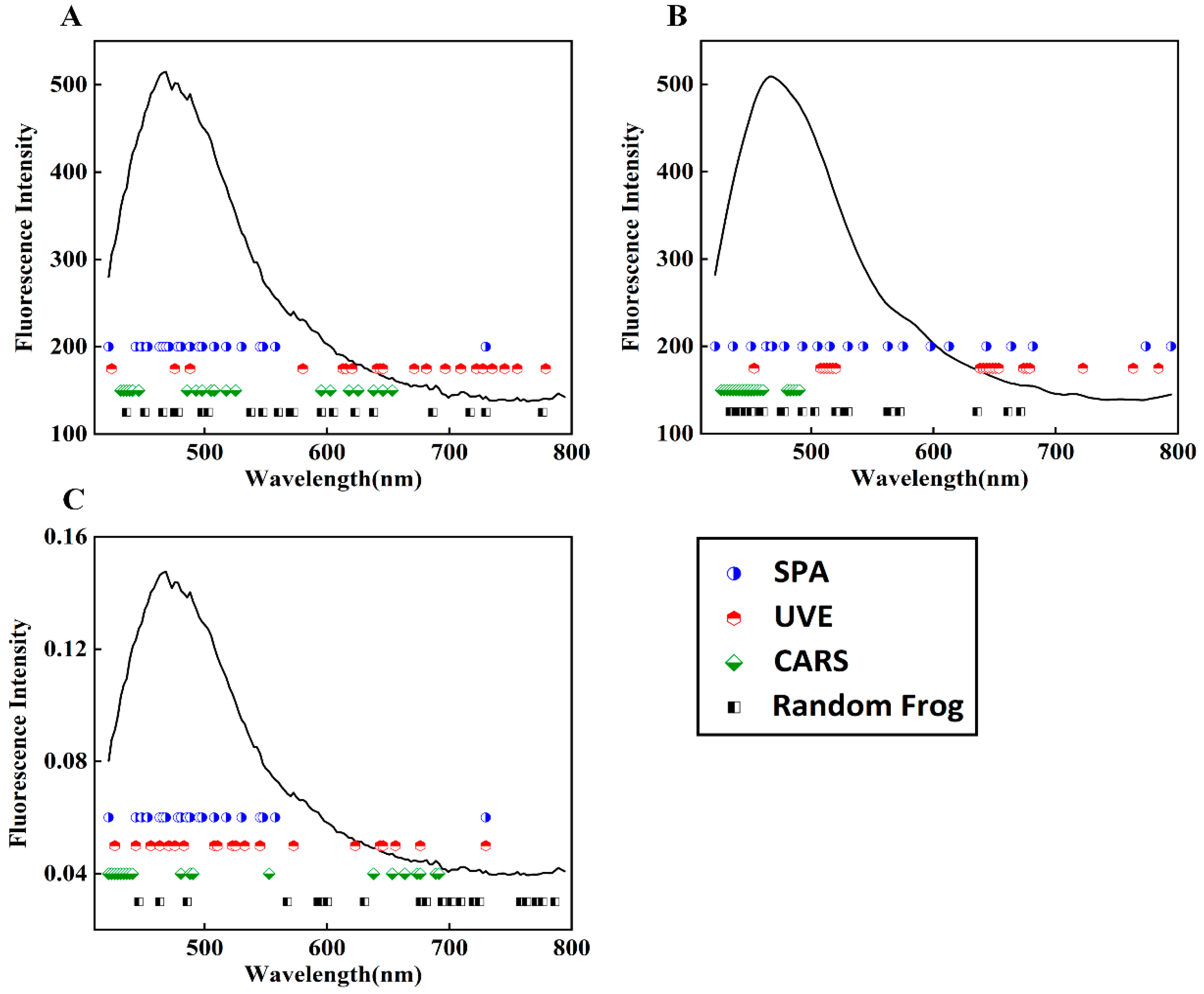
3.3. Feature Band Selection Results
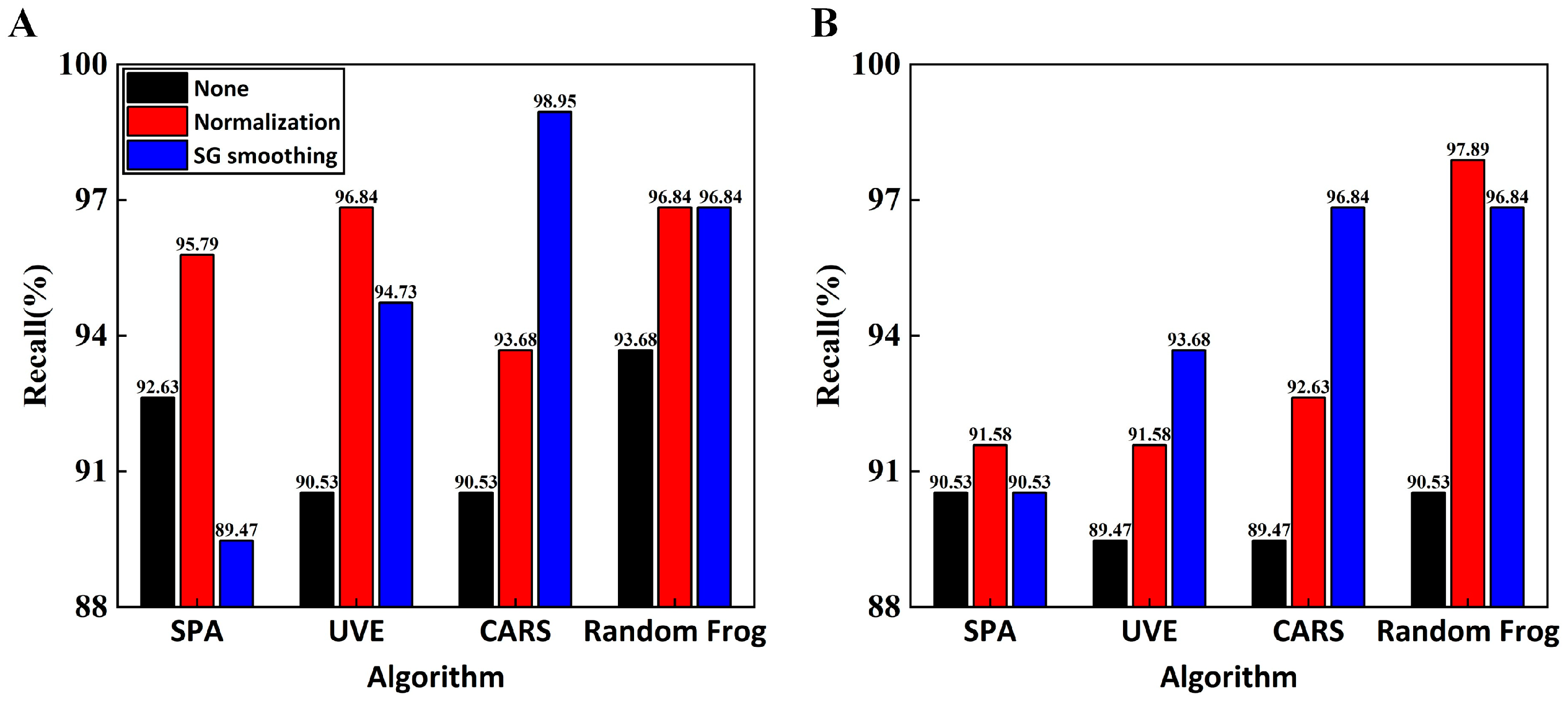
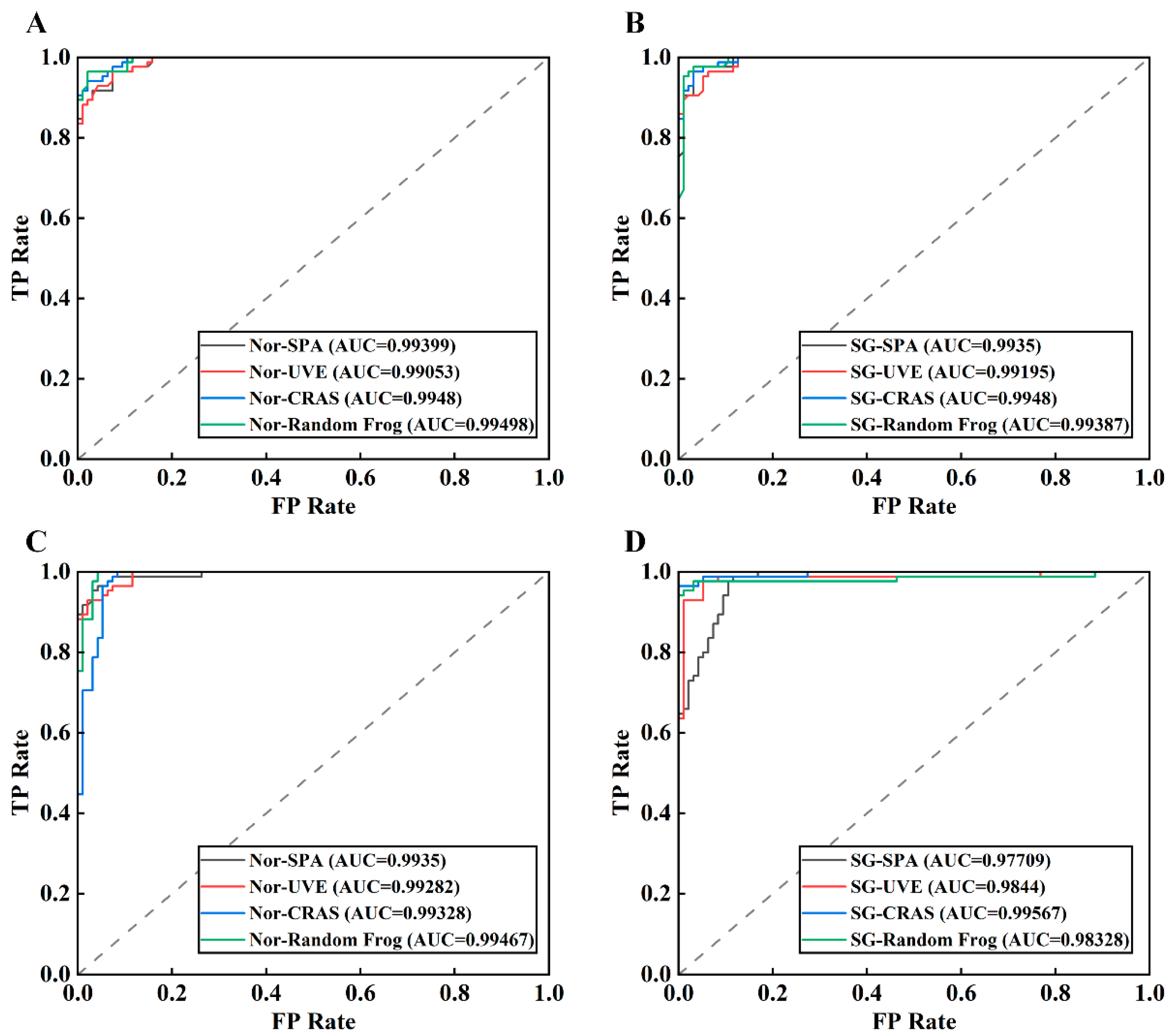
3.4. RF and SVM Modeling Results
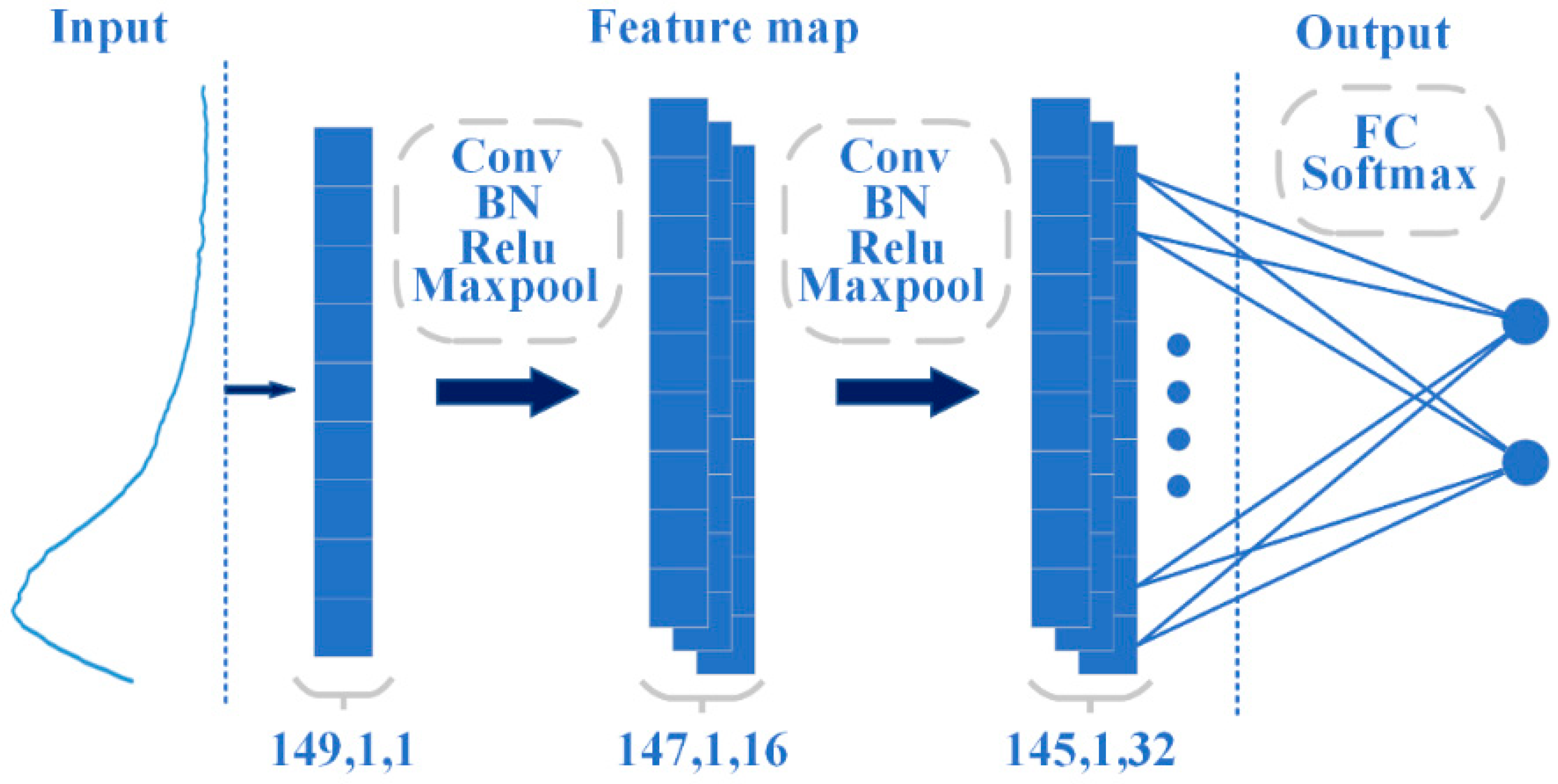
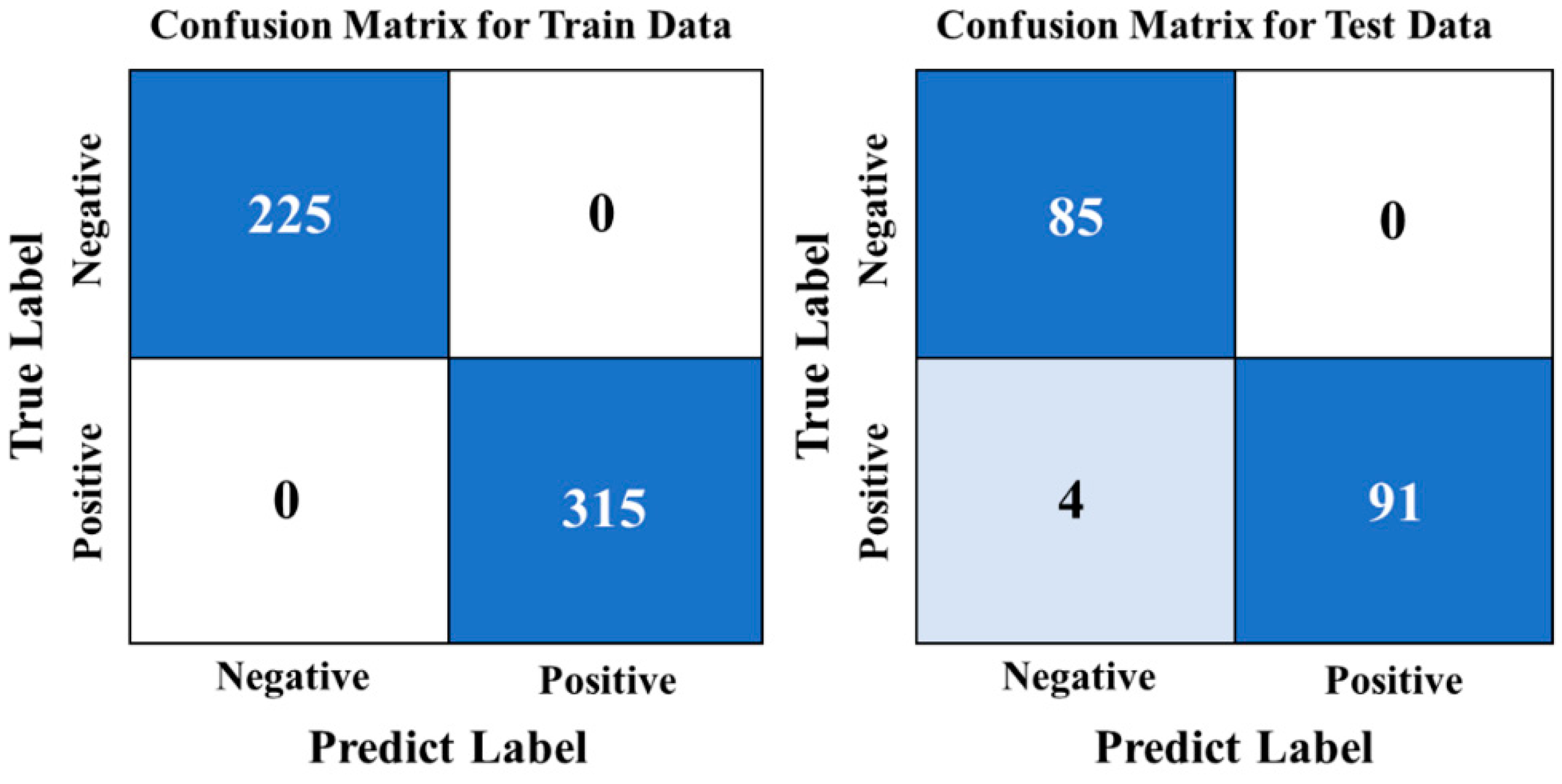
3.5. CNN Modeling Results
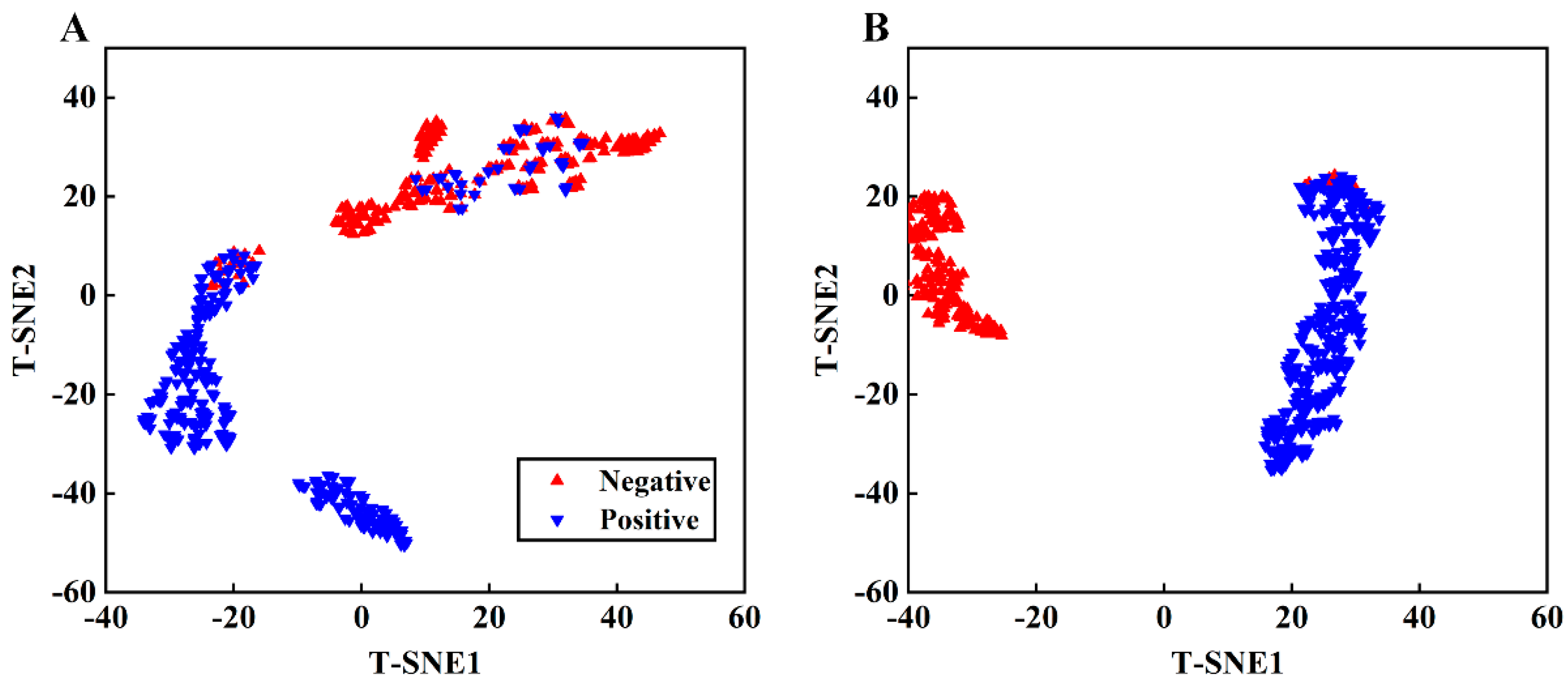
3.6. t-SNE Visualization
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bamidele, O.P.; Ogundele, O.M. Nutritional evaluation, microstructure, and storage stability of wheat (Triticum aestivum) and cocoyam (Colocasia esculenta) flour blends at different ratios. J. Food Process. Preserv. 2022, 46, e17248. [Google Scholar] [CrossRef]
- Beccari, G.; Caproni, L.; Tini, F.; Uhlig, S.; Covarelli, L. Presence of fusarium species and other toxigenic fungi in malting barley and multi-mycotoxin analysis by liquid chromatography–high-resolution mass spectrometry. J. Agric. Food Chem. 2016, 64, 4390–4399. [Google Scholar] [CrossRef]
- Khaneghah, A.M.; Martins, L.M.; Von Hertwig, A.M.; Bertoldo, R.; Sant’Ana, A.S. Deoxynivalenol and its masked forms: Characteristics, incidence, control and fate during wheat and wheat based products processing—A review. Trends Food Sci. Technol. 2018, 71, 13–24. [Google Scholar] [CrossRef]
- Simsek, S.; Burgess, K.; Whitney, K.L.; Gu, Y.; Qian, S.Y. Analysis of deoxynivalenol and deoxynivalenol-3-glucoside in wheat. Food Control 2012, 26, 287–292. [Google Scholar] [CrossRef]
- Lee, H.M.; Song, S.O.; Cha, S.H.; Wee, S.B.; Bischoff, K.; Park, S.W.; Son, S.W.; Kang, H.G.; Cho, M.H. Development of a monoclonal antibody against deoxynivalenol for magnetic nanoparticle-based extraction and an enzyme-linked immunosorbent assay. J. Vet. Sci. 2013, 14, 143–150. [Google Scholar] [CrossRef]
- Golge, O.; Kabak, B. Occurrence of deoxynivalenol and zearalenone in cereals and cereal products from Turkey. Food Control 2020, 110, 106982. [Google Scholar] [CrossRef]
- Zhu, F.; Zhang, B.; Zhu, L. An up-converting phosphor technology-based lateral flow assay for rapid detection of major mycotoxins in feed: Comparison with enzyme-linked immunosorbent assay and high-performance liquid chromatography-tandem mass spectrometry. PLoS ONE 2021, 16, e0250250. [Google Scholar] [CrossRef]
- Radi, A.E.; Eissa, A.; Wahdan, T. Impedimetric Sensor for Deoxynivalenol Based on Electropolymerised Molecularly Imprinted Polymer on the Surface of Screen-Printed Gold Electrode. Int. J. Environ. Anal. Chem. 2021, 101, 2586–2597. [Google Scholar] [CrossRef]
- Majer-Baranyi, K.; Székács, A.; Szendrő, I.; Kiss, A.; Adányi, N. Optical Waveguide Lightmode Spectroscopy Technique–Based Immunosensor Development for Deoxynivalenol Determination in Wheat Samples. Eur. Food Res. Technol. 2011, 233, 1041–1047. [Google Scholar] [CrossRef]
- Su, W.H.; Sun, D.W. Evaluation of spectral imaging for inspection of adulterants in terms of common wheat flour, cassava flour and corn flour in organic Avatar wheat (Triticum spp.) flour. J. Food Eng. 2017, 200, 59–69. [Google Scholar] [CrossRef]
- Wu, Q.; Xu, L.; Zou, Z.; Wang, J.; Zeng, Q.; Wang, Q.; Zhen, J.; Wang, Y.; Zhao, Y.; Zhou, M. Rapid nondestructive detection of peanut varieties and peanut mildew based on hyperspectral imaging and stacked machine learning models. Front. Plant Sci. 2022, 13, 1047479. [Google Scholar] [CrossRef]
- Wegulo, S. Factors Influencing Deoxynivalenol Accumulation in Small Grain Cereals. Toxins 2012, 4, 1157–1180. [Google Scholar] [CrossRef]
- Jin, F.; Bai, G.; Zhang, D.; Dong, Y.; Ma, L.; Bockus, W.; Dowell, F. Fusarium-damaged kernels and deoxynivalenol in fusarium -infected U.S. winter wheat. Phytopathology 2014, 104, 472–478. [Google Scholar] [CrossRef]
- Shen, G.; Cao, Y.; Yin, X.; Dong, F.; Xu, J.; Shi, J.; Lee, Y.W. Rapid and nondestructive quantification of deoxynivalenol in individual wheat kernels using near-infrared hyperspectral imaging and chemometrics. Food Control 2022, 131, 108420. [Google Scholar] [CrossRef]
- Liang, K.; Huang, J.; He, R.; Wang, Q.; Chai, Y.; Shen, M. Comparison of Vis-NIR and SWIR hyperspectral imaging for the non-destructive detection of DON levels in Fusarium head blight wheat kernels and wheat flour. Infrared Phys. Technol. 2020, 106, 103281. [Google Scholar] [CrossRef]
- Peng, Y.; Zhao, Y.; Yu, Z.; Zeng, J.; Xu, D.; Dong, J.; Ma, W. Wheat Quality Formation and Its Regulatory Mechanism. Front. Plant Sci. 2022, 13, 834654. [Google Scholar] [CrossRef]
- Femenias, A.; Gatius, F.; Ramos, A.J.; Sanchis, V.; Marín, S. Use of hyperspectral imaging as a tool for Fusarium and deoxynivalenol risk management in cereals: A review. Food Control 2020, 108, 106819. [Google Scholar] [CrossRef]
- Zhou, X.; Zhao, C.; Sun, J.; Yao, K.; Xu, M.; Cheng, J. Nondestructive testing and visualization of compound heavy metals in lettuce leaves using fluorescence hyperspectral imaging. Spectrochim. Acta A 2023, 291, 122337. [Google Scholar] [CrossRef]
- Fu, X.; Wang, M. Detection of early bruises on pears using fluorescence hyperspectral imaging technique. Food Anal. Method 2022, 15, 115–123. [Google Scholar] [CrossRef]
- Li, Y.; Sun, J.; Wu, X.; Chen, Q.; Lu, B.; Dai, C. Detection of viability of soybean seed based on fluorescence hyperspectra and CARS-SVM-AdaBoost model. J. Food Process. Preserv. 2019, 43, e14238. [Google Scholar] [CrossRef]
- Lee, A.; Park, S.; Yoo, J.; Kang, J.; Lim, J.; Seo, Y.; Kim, B.; Kim, G. Detecting bacterial biofilms using fluorescence hyperspectral imaging and various discriminant analyses. Sensors 2021, 21, 2213. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Yao, K.; Xu, M. Detection of heavy metal lead in lettuce leaves based on fluorescence hyperspectral technology combined with deep learning algorithm. Spectrochim. Acta A 2022, 266, 120460. [Google Scholar] [CrossRef]
- Delwiche, S.R.; Stommel, J.R.; Kim, M.S.; Vinyard, B.T.; Esquerre, C. Hyperspectral fluorescence imaging for shelf life evaluation of fresh-cut Bell and Jalapeno Pepper. Sci. Hortic. 2019, 246, 749–758. [Google Scholar] [CrossRef]
- Yao, H.; Hruska, Z.; Brown, R.L.; Cleveland, T.E. Hyperspectral bright greenish-yellow fluorescence (BGYF) imaging of aflatoxin contaminated corn kernels. In Proceedings of the SPIE Optics East 2006—Optics for Natural Resources, Agriculture, and Foods, Boston, MA, USA, 1 October 2006. [Google Scholar]
- Benalia, S.; Bernardi, B.; Cubero, S.; Leuzzi, A.; Larizza, M.; Blasco, J. Preliminary trials on hyperspectral imaging implementation to detect mycotoxins in dried figs. Chem. Eng. Trans. 2015, 44, 157–162. [Google Scholar]
- Han, Z.; Gao, J. Pixel-level aflatoxin detecting based on deep learning and hyperspectral imaging. Comput. Electron. Agric. 2019, 164, 104888. [Google Scholar] [CrossRef]
- Seo, Y.; Lee, A.; Kim, B.; Lim, J. Classification of rice and starch flours by using multiple hyperspectral imaging systems and chemometric methods. Appl. Sci. 2020, 10, 6724. [Google Scholar] [CrossRef]
- Seo, Y.; Lee, A.; Kim, B.G.; Lim, J. Discriminant analysis of grain flours for rice paper using fluorescence hyperspectral imaging system and chemometric methods. Korean J. Agric. Sci. 2020, 47, 633–644. [Google Scholar]
- National Health Commission of the People’s Republic of China. GB 2761-2011; Food Safety National Standard Limits of Mycotoxins in Foods. China Standards Press: Beijing, China, 2011.
- Siregar, T.H.; Ahmad, U.; Maddu, A. Mechanical damage detection of Indonesia local citrus based on fluorescence imaging. IOP Conf. Ser. Earth Environ. Sci. 2018, 147, 012006. [Google Scholar] [CrossRef]
- Ahmad, H.; Sun, J.; Nirere, A.; Shaheen, N.; Zhou, X.; Yao, K. Classification of tea varieties based on fluorescence hyperspectral image technology and ABC-SVM algorithm. J. Food Process. Preserv. 2021, 45, e15241. [Google Scholar] [CrossRef]
- Li, Y.; Sun, J.; Wu, X.; Lu, B.; Wu, M.; Dai, C. Grade Identification of Tieguanyin tea using fluorescence hyperspectra and different statistical algorithms. J. Food Sci. 2019, 84, 2234–2241. [Google Scholar] [CrossRef]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvão, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Centner, V.; Massart, D.L.; De Noord, O.E.; De Jong, S.; Vandeginste, B.M.; Sterna, C. Elimination of uninformative variables for multivariate calibration. Anal. Chem. 1996, 68, 3851–3858. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
- Li, H.D.; Xu, Q.S.; Liang, Y.Z. Random frog: An efficient reversible jump Markov Chain Monte Carlo-like approach for variable selection with applications to gene selection and disease classification. Anal. Chim. Acta 2012, 740, 20–26. [Google Scholar] [CrossRef]
- Ishwaran, H.; Malley, J.D. Synthetic learning machines. BioData Min. 2014, 7, 28. [Google Scholar] [CrossRef]
- Hu, Y.; Xu, L.; Huang, P.; Luo, X.; Wang, P.; Kang, Z. Reliable identification of Oolong tea species: Nondestructive testing classification based on fluorescence hyperspectral technology and machine learning. Agriculture 2021, 11, 1106. [Google Scholar] [CrossRef]
- Han, Z.; Deng, L. Application driven key wavelengths mining method for aflatoxin detection using hyperspectral data. Comput. Electron. Agric. 2018, 153, 248–255. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Int. Conf. Mach. Learn. 2015, 37, 448–456. [Google Scholar]
- Galvao, R.; Araujo, M.; Jose, G.; Pontes, M.; Silva, E.; Saldanha, T. A method for calibration and validation subset partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef]
- Koolstra, K.; Börnert, P.; Lelieveldt, B.P.F.; Webb, A.; Dzyubachyk, O. Stochastic neighbor embedding as a tool for visualizing the encoding capability of magnetic resonance fingerprinting dictionaries. Magn. Reson. Mater. Phys. 2022, 35, 223–234. [Google Scholar] [CrossRef]
- Copping, A.M. Riboflavin, vitamin B6 and filtrate factors in wheaten flours and offals. Biochem. J. 1943, 37, 12–17. [Google Scholar] [CrossRef]
- Ma, S.; Han, W.; Li, L.; Zheng, X.; Wang, X. The thermal stability, structural changeability, and aggregability of glutenin and gliadin proteins induced by wheat bran dietary fiber. Food Funct. 2019, 10, 172–179. [Google Scholar] [CrossRef]
- Saha, D.; Manickavasagan, A. Machine learning techniques for analysis of hyperspectral images to determine quality of food products: A review. Curr. Res. Food Sci. 2021, 4, 28–44. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Preprocessing Algorithms | Test Accuracy | Recall | FPR |
|---|---|---|---|---|
| RF | None | 93.33% | 90.53% | 3.53% |
| Normalization | 92.78% | 90.53% | 4.71% | |
| MSC | 72.22% | 91.58% | 49.41% | |
| D1 | 86.67% | 89.47% | 16.47% | |
| SG | 93.33% | 89.47% | 2.35% | |
| SG-1 | 90.00% | 90.53% | 10.59% | |
| SVM | None | 92.22% | 91.58% | 7.06% |
| Normalization | 95.56% | 95.79% | 4.71% | |
| MSC | 82.78% | 96.84% | 31.76% | |
| D1 | 90.00% | 91.58% | 10.59% | |
| SG | 92.78% | 91.58% | 5.88% | |
| SG-1 | 90.00% | 90.53% | 9.41% |
| Models | Preprocessing Algorithms | Band Selection Methods | Test Accuracy | Recall | FPR |
|---|---|---|---|---|---|
| RF | None | SPA | 93.33% | 92.63% | 5.88% |
| UVE | 92.78% | 90.53% | 10.59% | ||
| CARS | 91.67% | 90.53% | 7.06% | ||
| Random Frog | 93.89% | 93.68% | 5.88% | ||
| Normalization | SPA | 93.89% | 95.79% | 4.71% | |
| UVE | 93.33% | 96.84% | 4.71% | ||
| CARS | 93.33% | 93.68% | 4.71% | ||
| Random Frog | 93.89% | 96.84% | 2.35% | ||
| SG | SPA | 93.89% | 89.47% | 3.53% | |
| UVE | 95.00% | 94.73% | 7.06% | ||
| CARS | 96.11% | 98.95% | 3.53% | ||
| Random Frog | 97.22% | 96.84% | 4.71% | ||
| SVM | None | SPA | 94.44% | 90.53% | 3.53% |
| UVE | 90.50% | 89.47% | 3.53% | ||
| CARS | 95.00% | 89.47% | 4.71% | ||
| Random Frog | 93.89% | 90.53% | 2.35% | ||
| Normalization | SPA | 95.56% | 91.58% | 3.53% | |
| UVE | 96.11% | 91.58% | 4.71% | ||
| CARS | 95.00% | 92.63% | 5.88% | ||
| Random Frog | 97.22% | 97.89% | 3.53% | ||
| SG | SPA | 92.78% | 90.53% | 2.35% | |
| UVE | 93.89% | 93.68% | 3.53% | ||
| CARS | 97.78% | 96.84% | 1.18% | ||
| Random Frog | 96.11% | 96.84% | 2.35% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Fu, X.; Zhou, Y.; Fu, F. Deoxynivalenol Detection beyond the Limit in Wheat Flour Based on the Fluorescence Hyperspectral Imaging Technique. Foods 2024, 13, 897. https://doi.org/10.3390/foods13060897
Wang C, Fu X, Zhou Y, Fu F. Deoxynivalenol Detection beyond the Limit in Wheat Flour Based on the Fluorescence Hyperspectral Imaging Technique. Foods. 2024; 13(6):897. https://doi.org/10.3390/foods13060897
Chicago/Turabian StyleWang, Chengzhi, Xiaping Fu, Ying Zhou, and Feng Fu. 2024. "Deoxynivalenol Detection beyond the Limit in Wheat Flour Based on the Fluorescence Hyperspectral Imaging Technique" Foods 13, no. 6: 897. https://doi.org/10.3390/foods13060897