
Research on Automatic Classification and Detection of Mutton Multi-Parts Based on Swin-Transformer
Abstract
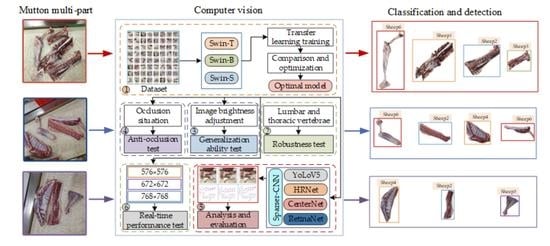
:
1. Introduction
2. Materials and Methods
2.1. Test Materials and Image Acquisition
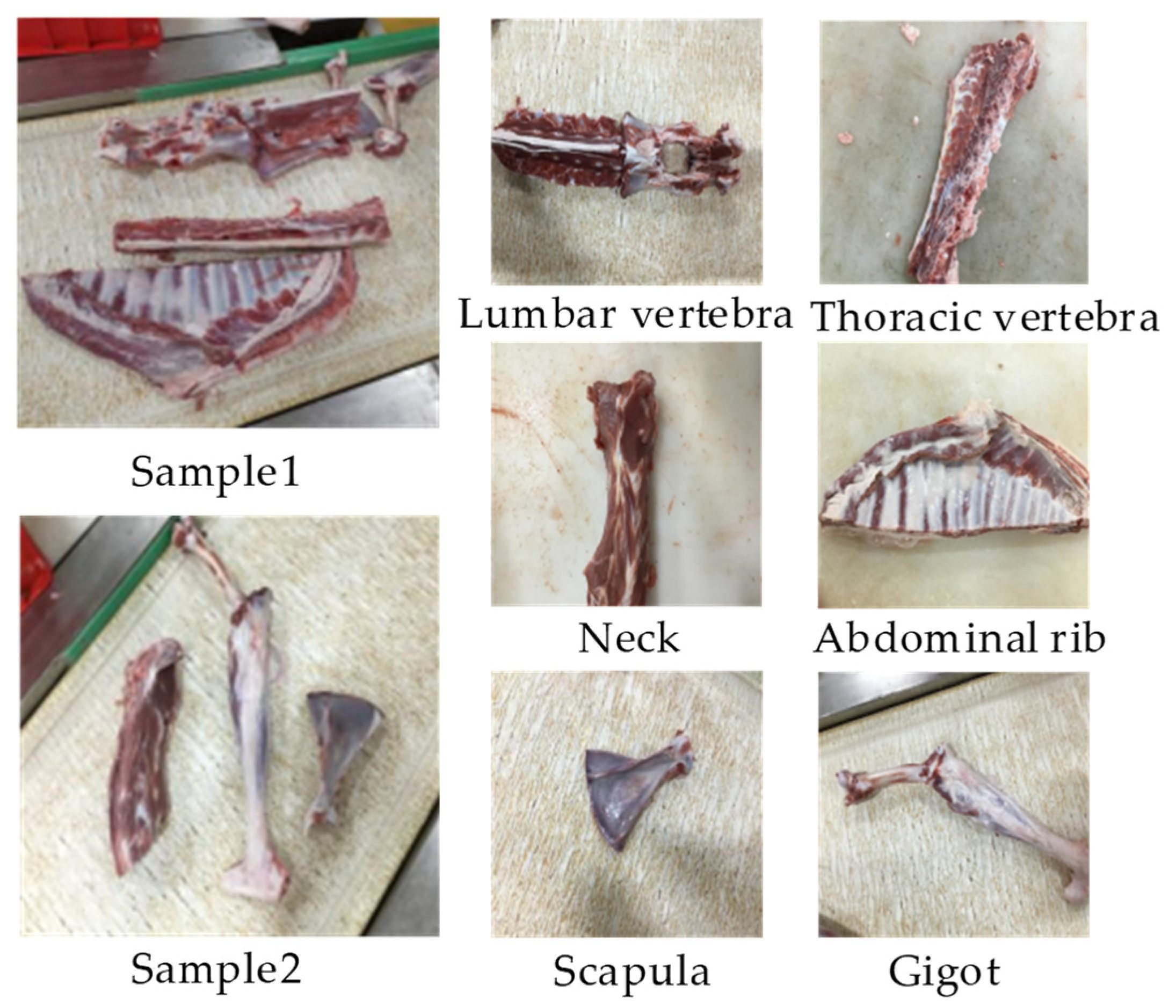
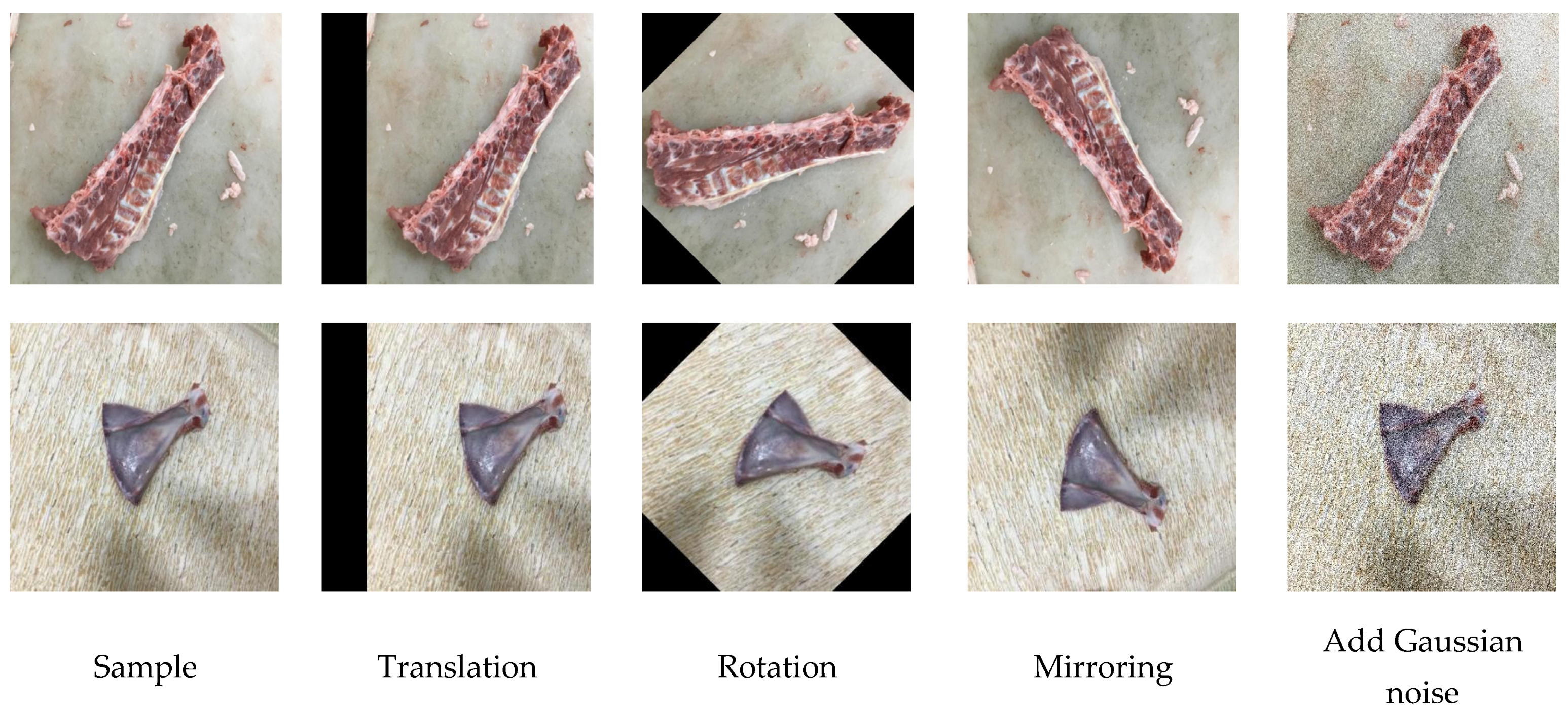
2.2. Sample Pretreatment and Establish Dataset
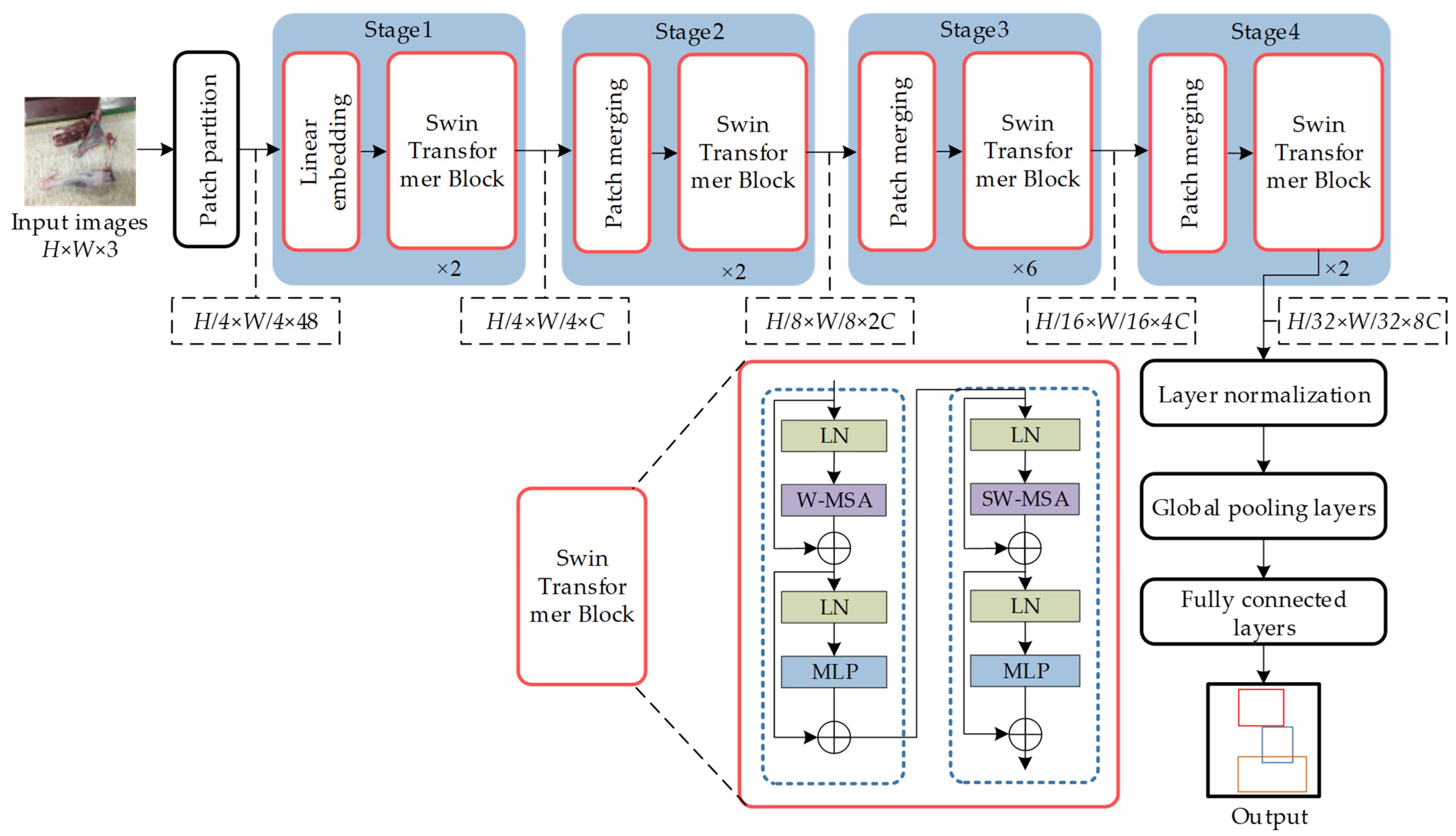
2.3. Principle of Swin-Transformer Algorithm
2.3.1. Swin-Transformer Network Structure
2.3.2. Swin-Transformer Attention Mechanisms
2.4. Evaluation Index
2.5. Method of Adjusting Image Brightness
2.6. Test Environment
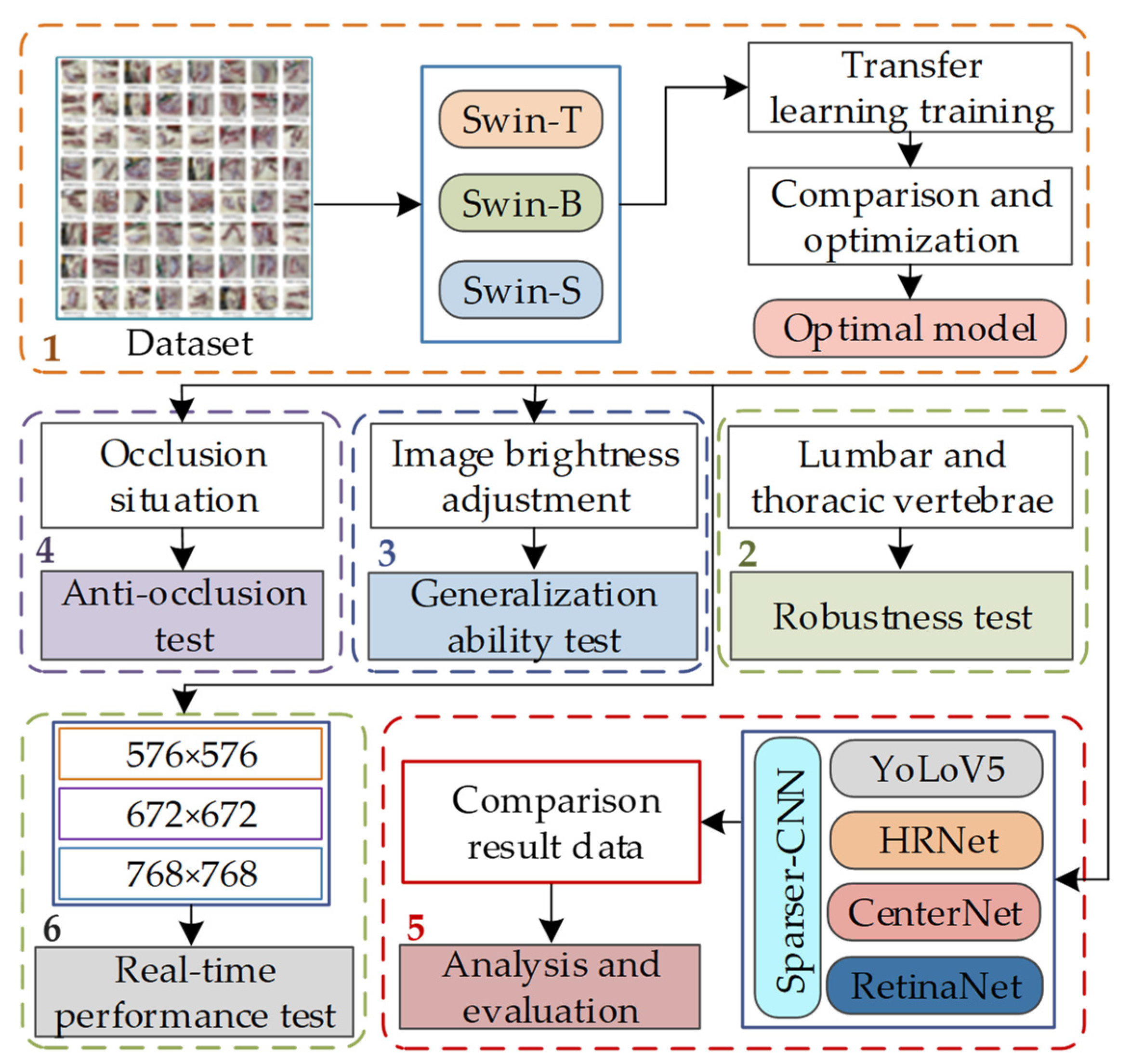
3. Experiment and Results
- For the mutton multi-part image dataset, three types of Swin-Transformer network, namely Swin-T, Swin-B, and Swin-S, are introduced to conduct model training and comparison, and obtain the optimal mutton multi-part classification and detection model.
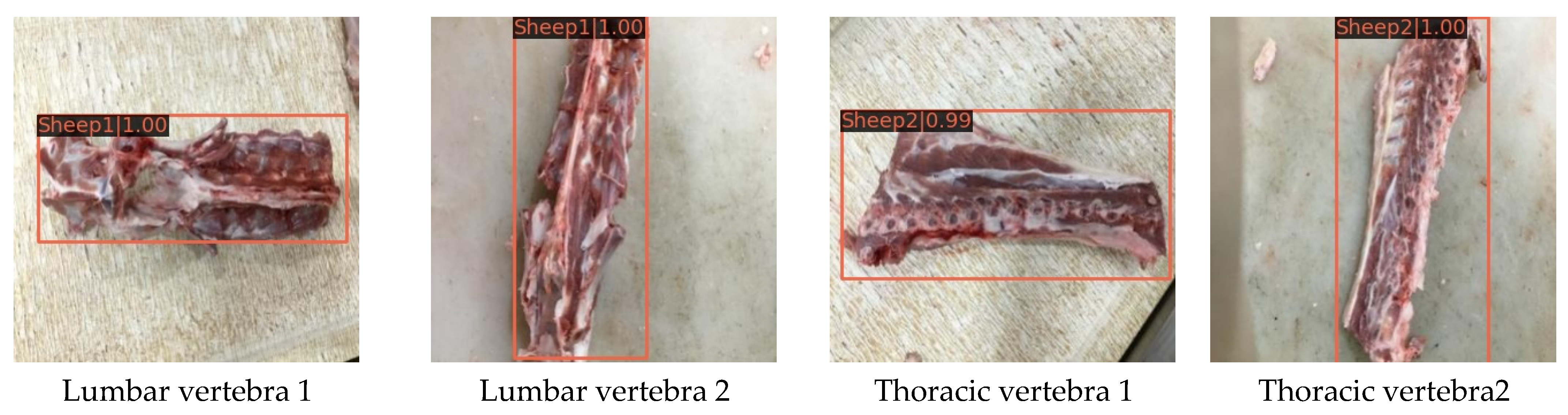
- The generalization ability of the model is tested for the lumbar vertebrae and thoracic vertebrae of mutton with obvious multi-scale features.
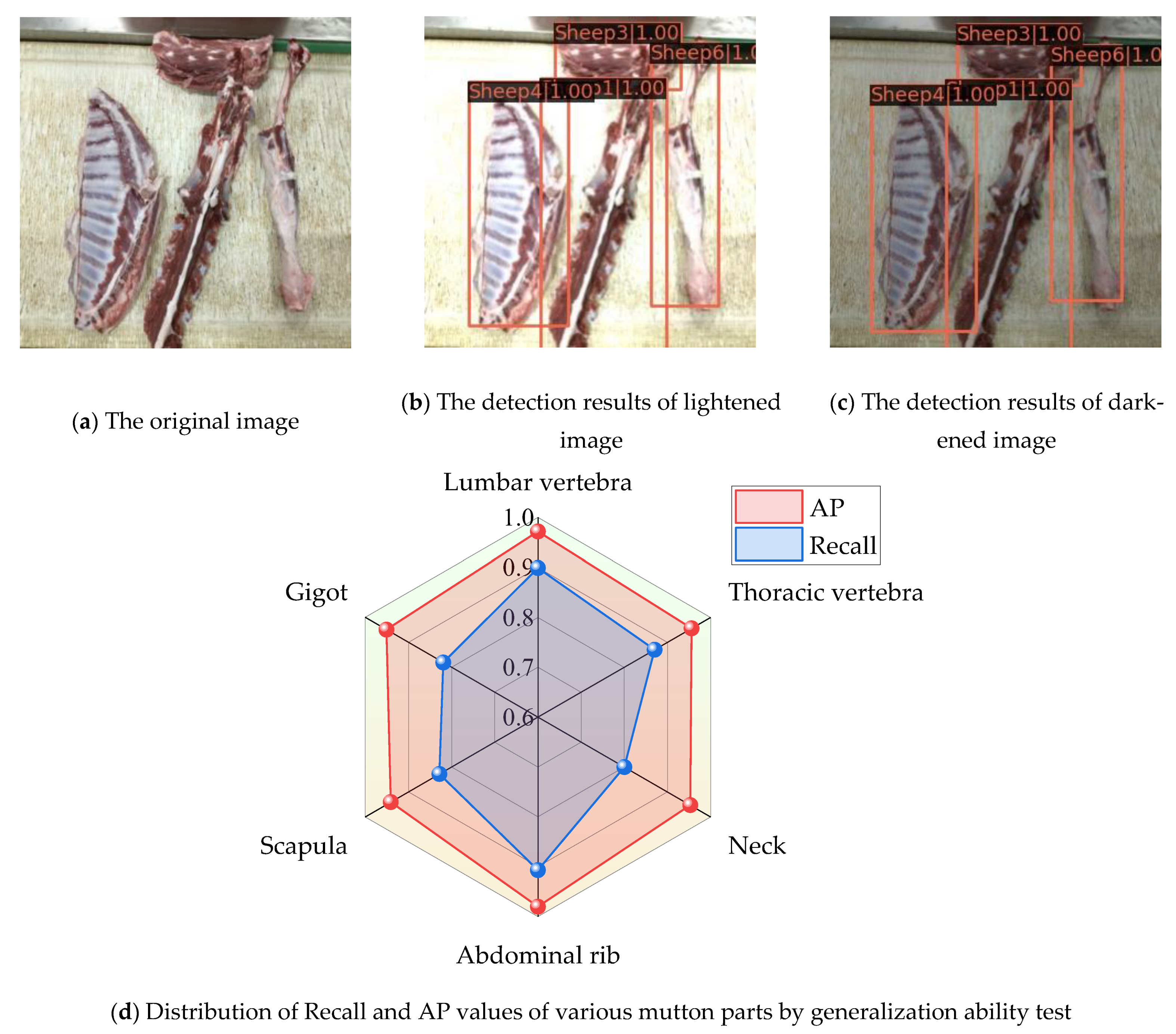
- The generalization ability of the model is tested by adjusting the brightness of the mutton multi-part image.
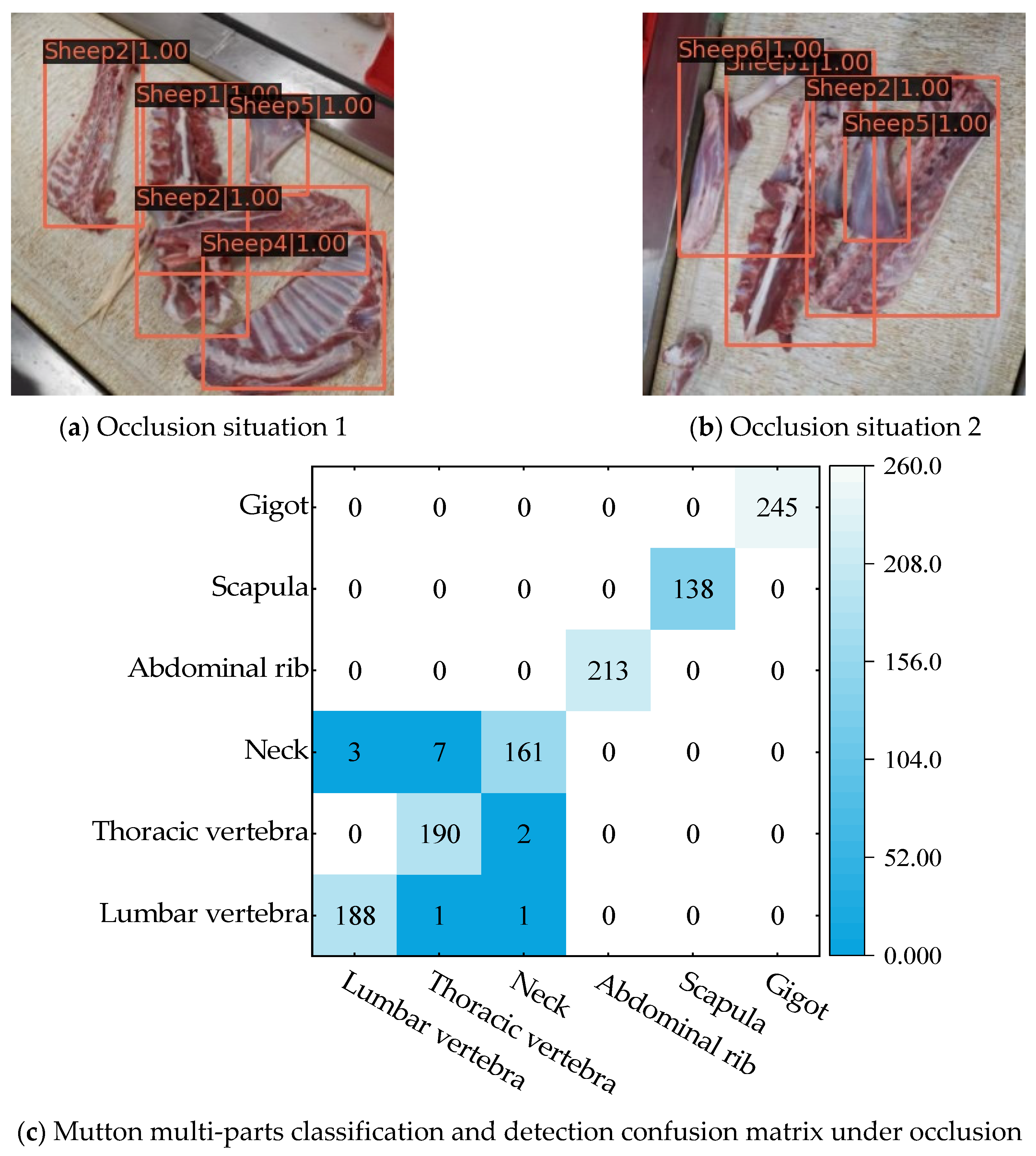
- Mutton multi-part images with occlusion scenarios are selected to test the anti-occlusion ability of the model.
- Other common object detection algorithms are introduced for comparative analysis in order to judge the advantages and disadvantages of the model.
- The image resolution is adjusted and the real-time performance of the model is tested. The test flow is shown in Figure 7.
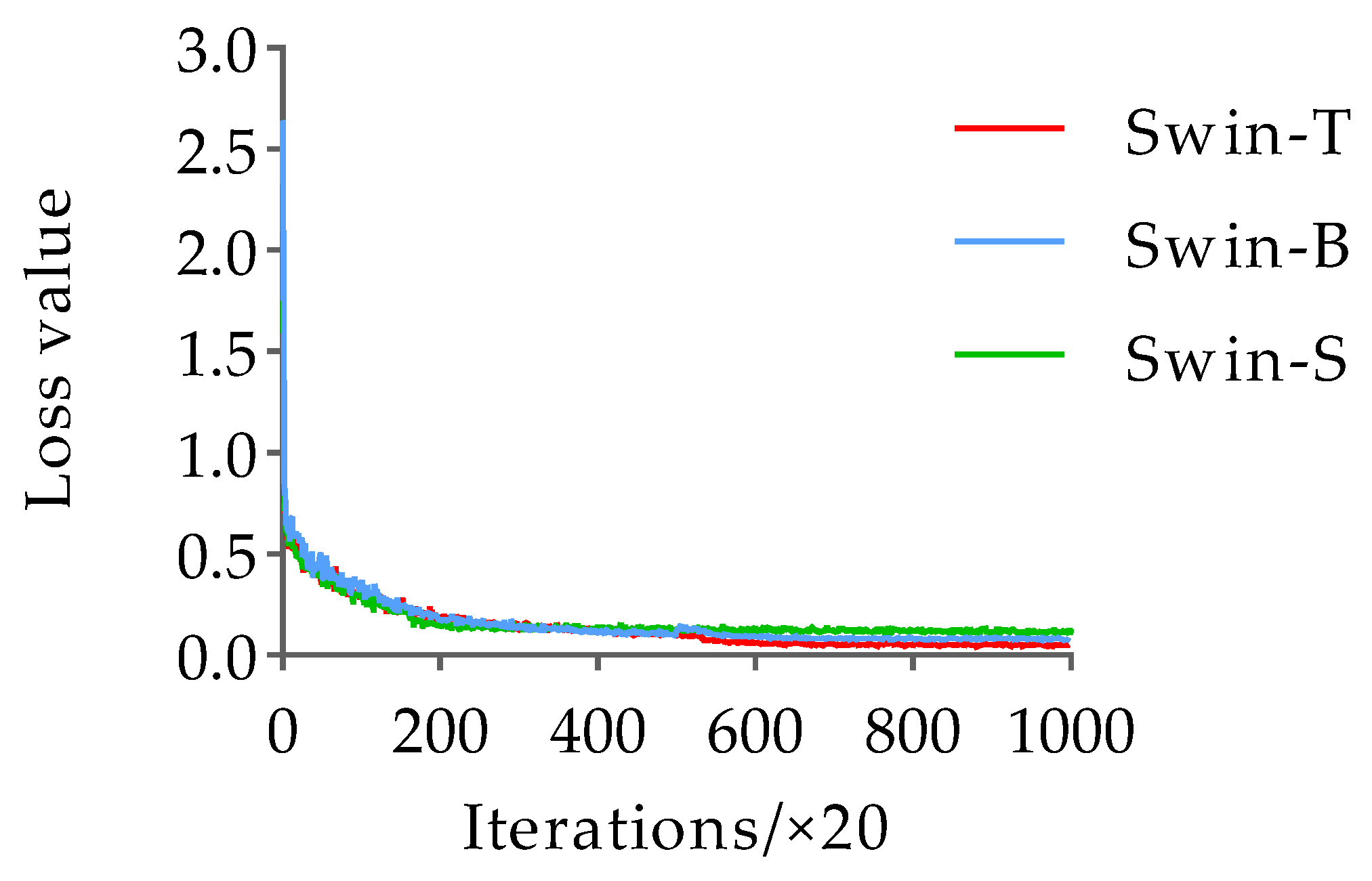
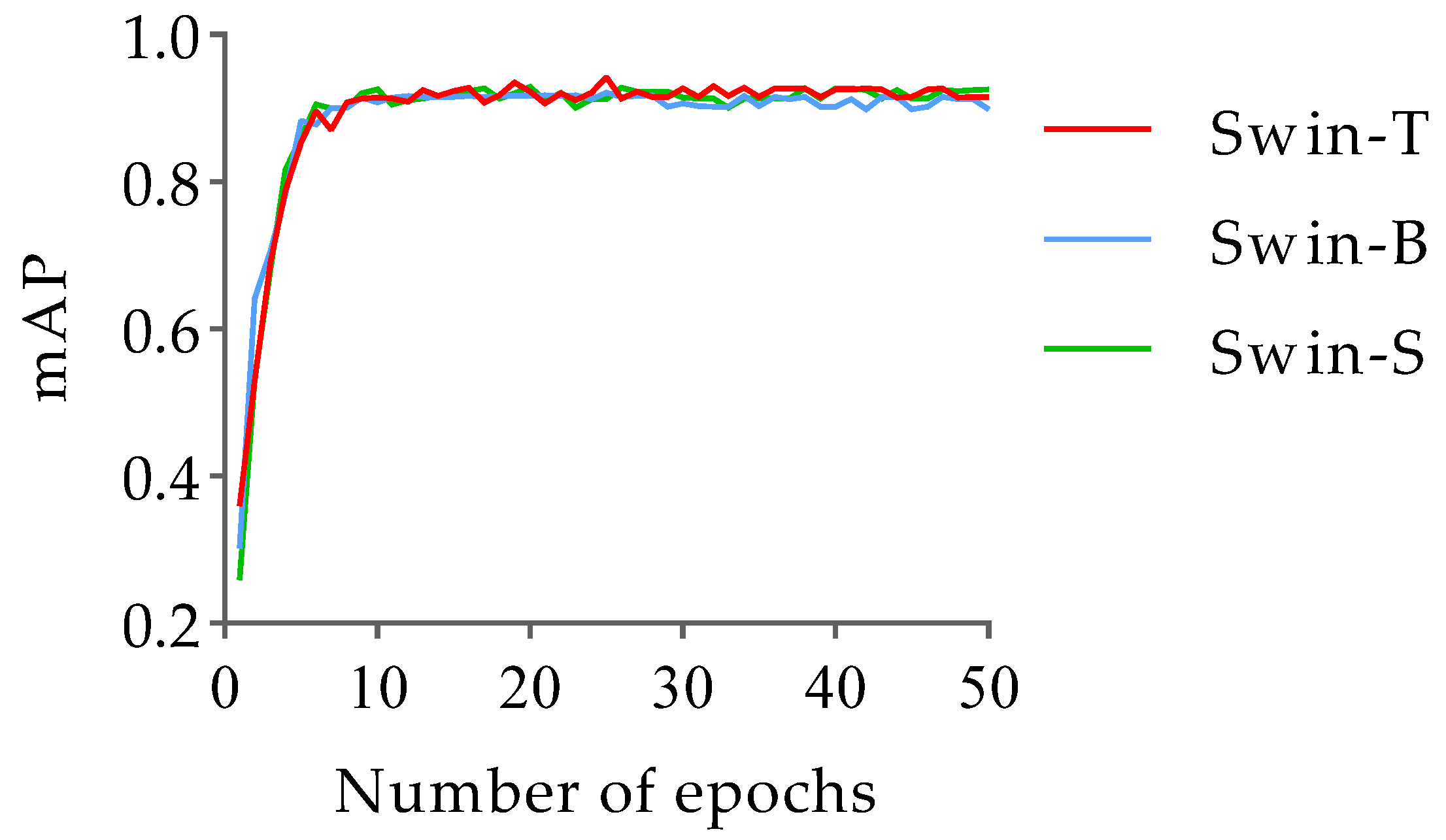
3.1. Classification and Detection of Mutton Multi-Part Based on Swin-Transformer
3.2. Robustness Testing
3.3. Generalization Testing
3.4. Anti-Occlusion Testing
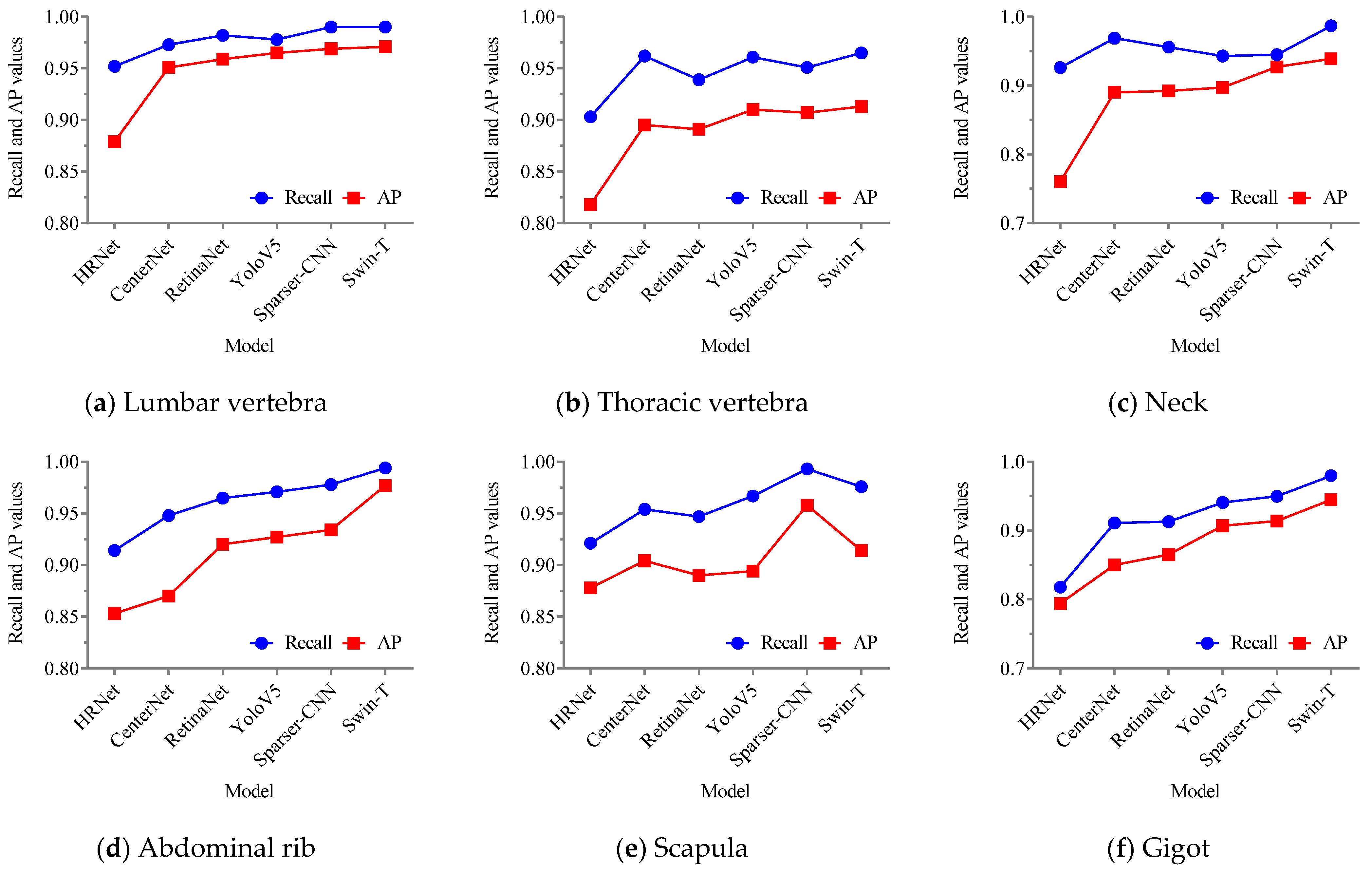
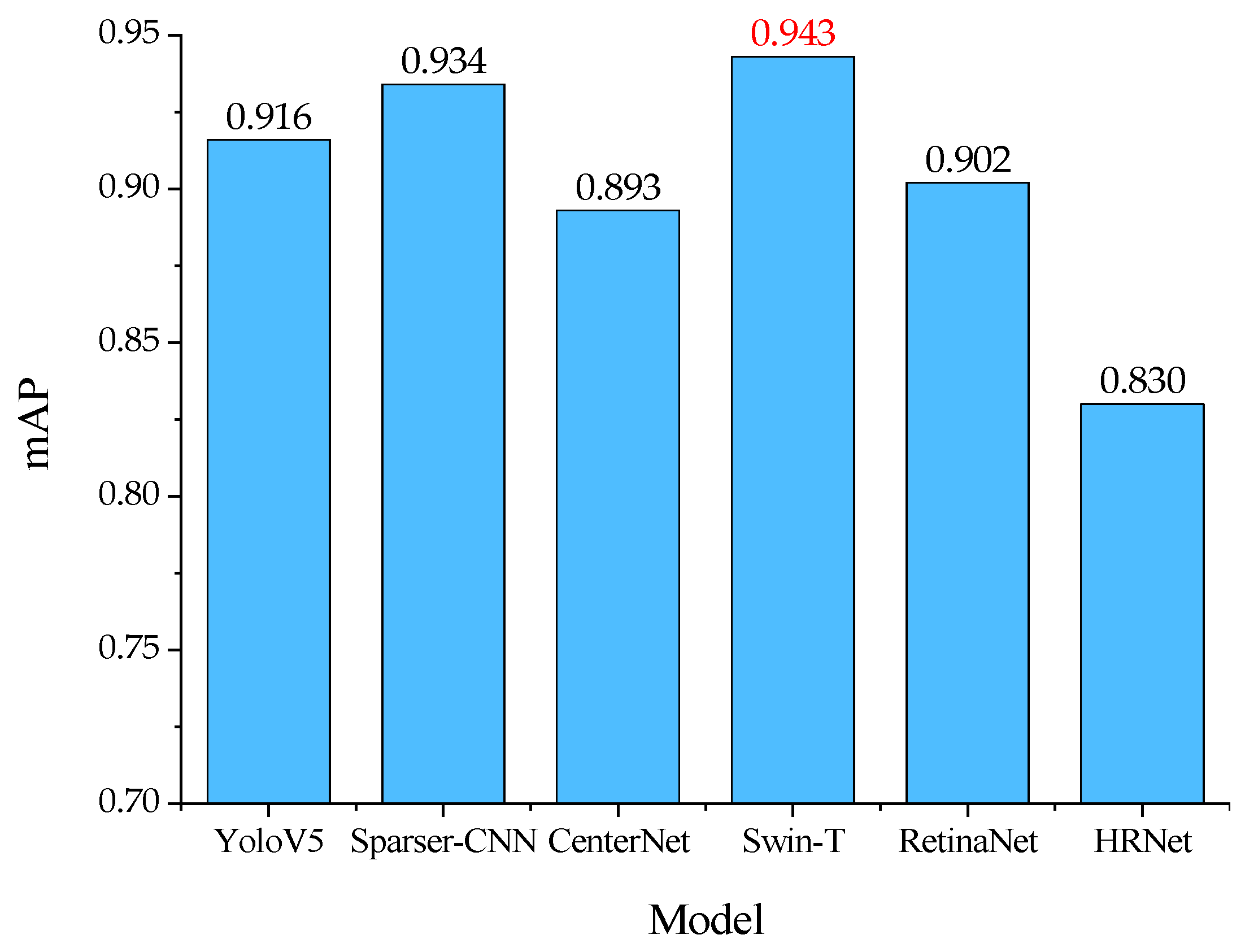
3.5. Comparison and Analysis with Other Methods
3.6. Real-Time Performance Test
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gan, C.; Li, J.; Jin, H. 2021 Development Overview, Future Development Trend and Suggestions of China’s Mutton Sheep Industry in 2021. Chin. J. Anim. Sci. 2022, 58, 258–263. [Google Scholar] [CrossRef]
- NY/T1564-2007; Agricultural Industry Standards of the People’s Republic of China-Cutting Technical Specification of Mutton. Ministry of Agriculture and Rural Affairs of the People’s Republic of China: Beijing, China, 2008.
- Zhao, S.; Hao, G.; Zhang, Y.; Wang, S. A real-time classification and detection method for mutton parts based on single shot multi-box detector. J. Food Process Eng. 2021, 44, e13749. [Google Scholar] [CrossRef]
- Li, Z.; Wang, S.; Zhao, S.; Bai, Y. Cutting Methods of Sheep’s Trunk Based on Improved DeepLabv3+ and XGBoost. Comput. Eng. Appl. 2021, 57, 263–269. [Google Scholar] [CrossRef]
- Li, J.; Xie, B.; Zhai, Z.; Zhang, P.; Hou, S. Research Progress of Intelligent Equipment and Technology for Livestock and Poultry Slaughter and Processing. Food Mach. 2021, 37, 226–232. [Google Scholar] [CrossRef]
- Jiang, X.; Xue, H.; Gao, X.; Zhang, L.; Zhou, Y.; Du, Y. Study on Detection of Chilled Mutton Freshness Based on Hyperspectral Imaging Technique and Sparse Kernel Canonical Correlation Analysis. Spectrosc. Spectr. Anal. 2018, 38, 2498–2504. [Google Scholar] [CrossRef]
- Jiang, X.; Xue, H.; Zhang, L.; Gao, X.; Wu, G.; Bai, J. Nondestructive detection of chilled mutton freshness based on multi-label information fusion and adaptive BP neural network. Comput. Electron. Agric. 2018, 155, 371–377. [Google Scholar] [CrossRef]
- Liu, C.; Chu, Z.; Weng, S.; Zhu, G.; Han, K.; Zhang, Z.; Huang, L.; Zhu, Z.; Zheng, S. Fusion of electronic nose and hyperspectral imaging for mutton freshness detection using input-modified convolution neural network. Food Chem. 2022, 385, 132651. [Google Scholar] [CrossRef]
- Chen, J.; Gu, J.; Zhang, R.; Mao, Y.; Tian, S. Freshness Evaluation of Three Kinds of Meats Based on the Electronic Nose. Sensors 2019, 19, 605. [Google Scholar] [CrossRef] [Green Version]
- Zhu, R.; Yao, X.; Duan, H.; Ma, B.; Tang, M. Study on the Rapid Evaluation of Total Volatile Basic Nitrogen (TVB-N) of Mutton by Hyperspectral Imaging Technique. Spectrosc. Spectr. Anal. 2016, 36, 806–810. [Google Scholar] [CrossRef]
- Zheng, K.; Yin, Y.; Cao, Y.; Guo, L.; Li, P.; Jiang, J.; Huang, X.; Jiang, Y.; Wu, J. Proteomic and parallel reaction monitoring approaches to evaluate biomarkers of mutton tenderness. Food Chem. 2022, 397, 133746. [Google Scholar] [CrossRef]
- Liu, G.; Zhang, C.; Fan, N.; Cheng, L.; Yu, J.; Yuang, R. Hyperspectral Model Optimization for Tenderness of Chilled Tan-Sheep Mutton Based on IVISSA. Spectrosc. Spectr. Anal. 2020, 40, 2558–2563. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, M.; Zhu, R.; Ma, R. Adulteration discrimination and analysis of fresh and frozen-thawed minced adulterated mutton using hyperspectral images combined with recurrence plot and convolutional neural network. Meat Sci. 2022, 192, 108900. [Google Scholar] [CrossRef]
- Fan, B.; Zhu, R.; He, D.; Wang, S.; Cui, X.; Yao, X. Evaluation of Mutton Adulteration under the Effect of Mutton Flavour Essence Using Hyperspectral Imaging Combined with Machine Learning and Sparrow Search Algorithm. Foods 2022, 11, 2278. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Hao, G.; Zhao, S.; Sun, S. A method for Determining the Optimal Maturity Time of Sheep Carcass Based on Point Cloud Deformation Analysis. J. Anhui Agric. Univ. 2022, 49, 103–111. [Google Scholar] [CrossRef]
- Ren, Y.; Liu, G.; Zhang, J.; Bai, J. Near-infrared Hyperspectral Kinetic Models for the pH of Tan Mutton at Different Storage Temperatures. Chin. J. Lumin. 2019, 40, 396–403. [Google Scholar] [CrossRef]
- Wang, W.; Wang, S.; He, X.; He, J. Non-Destructive Detection of Refrigerated Time and Moisture Content in Chilled Mutton Using Hyperspectral Imaging. Food Sci. 2016, 36, 112–116. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, S.; Bai, Y.; Hao, G.; Tu, B. Real-time Semantic Segmentation of Sheep Skeleton Image Based on Generative Adversarial Network and ICNet. Trans. Chin. Soc. Agric. Mach. 2021, 52, 329–339+380. [Google Scholar] [CrossRef]
- Meng, L.; Zhu, R.; Bai, Z.; Zheng, M.; Gu, J.; Ma, B. Discrimination of Chilled Lamb from Different Carcass Parts at Different Storage Times Based on Mobile Phone Images. Food Sci. 2020, 41, 21–26. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, J.; Xuan, C.; Han, D.; Wang, J. Design and Experiment of Non-stress Measuring System for Sheep’s Conformation Parameters. Trans. Chin. Soc. Agric. Mach. 2016, 47, 307–315. [Google Scholar] [CrossRef]
- Liu, K.; Xie, B.; Zhai, Z.; Wen, C.; Hou, S.; Li, J. Target Muscle Region Recognition in Ovine Hind Leg Segmentation Based on R2U-Net and Atrous Convolution Algorithm. Trans. Chin. Soc. Agric. Mach. 2020, 51, 507–514. [Google Scholar] [CrossRef]
- Wang, S.; Bai, Y.; Zhao, S.; Yang, H. Point Cloud Segmentation of Sheep Carcess Based on Surface Convexity. Trans. Chin. Soc. Agric. Mach. 2022, 53, 387–394. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, J.; Yang, H.; Liu, Y.; Liu, H. A Small-Target Forest Fire Smoke Detection Model Based on Deformable Transformer for End-to-End Object Detection. Forests 2023, 14, 162. [Google Scholar] [CrossRef]
- Geng, H.; Jiang, J.; Shen, J.; Hou, M. Cascading Alignment for Unsupervised Domain-Adaptive DETR with Improved DeNoising Anchor Boxes. Sensors 2022, 22, 9629. [Google Scholar] [CrossRef]
- Wang, D.; Li, Z.; Du, X.; Ma, Z.; Liu, X. Farmland Obstacle Detection from the Perspective of UAVs Based on Non-local Deformable DETR. Agriculture 2022, 12, 1983. [Google Scholar] [CrossRef]
- Yu, M.; Qin, F. Research on the Applicability of Transformer Model in Remote-Sensing Image Segmentation. Appl. Sci. 2023, 13, 2261. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Diao, W.; Yan, Z.; Yin, D.; Fu, K. Transformer-induced graph reasoning for multimodal semantic segmentation in remote sensing. ISPRS J. Photogramm. Remote Sens. 2022, 193, 90–103. [Google Scholar] [CrossRef]
- Niu, B.; Feng, Q.; Chen, B.; Ou, C.; Liu, Y.; Yang, J. HSI-TransUNet: A transformer based semantic segmentation model for crop mapping from UAV hyperspectral imagery. Comput. Electron. Agric. 2022, 201, 0168–1699. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. PVT v2: Improved Baselines with Pyramid Vision Transformer. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar] [CrossRef]
- Okolo, G.I.; Katsigiannis, S.; Ramzan, N. IEViT: An enhanced vision transformer architecture for chest X-ray image classification. Comput. Methods Programs Biomed. 2022, 226, 107141. [Google Scholar] [CrossRef]
- Naveen, S.; Kiran, M.R.; Indupriya, M.; Manikanta, T.; Sudeep, P. Transformer models for enhancing AttnGAN based text to image generation. Image Vis. Comput. 2021, 155, 104284. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar] [CrossRef]
- Dhanya, V.; Subeesh, A.; Kushwaha, N.; Vishwakarma, D.K.; Kumar, T.N.; Ritika, G.; Singh, A. Deep learning based computer vision approaches for smart agricultural applications. Artif. Intell. Agric. 2022, 6, 211–229. [Google Scholar] [CrossRef]
- Liu, X.; Wang, Z.; Wan, J.; Zhang, J.; Xi, Y.; Liu, R.; Miao, Q. RoadFormer: Road Extraction Using a Swin Transformer Combined with a Spatial and Channel Separable Convolution. Remote Sens. 2023, 15, 1049. [Google Scholar] [CrossRef]
- Luo, H.; Li, J.; Cai, L.; Wu, M. STrans-YOLOX: Fusing Swin Transformer and YOLOX for Automatic Pavement Crack Detection. Appl. Sci. 2023, 13, 1999. [Google Scholar] [CrossRef]
- Jiang, F.; Sui, C.; Ou, S.; Wang, Z.; Hu, G.; Yang, G.; Pan, Y.; Hu, J. Wild Animal Detection Based on Swin-Transformer. Artif. Intell. Robot. Res. 2021, 10, 281–291. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, S.; Yan, Y.; Tang, S.; Zhao, S. Identification and Analysis of Emergency Behavior of Cage-Reared Laying Ducks Based on YoloV5. Agriculture 2022, 12, 485. [Google Scholar] [CrossRef]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krahenbuhl, P. Objects as Points. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
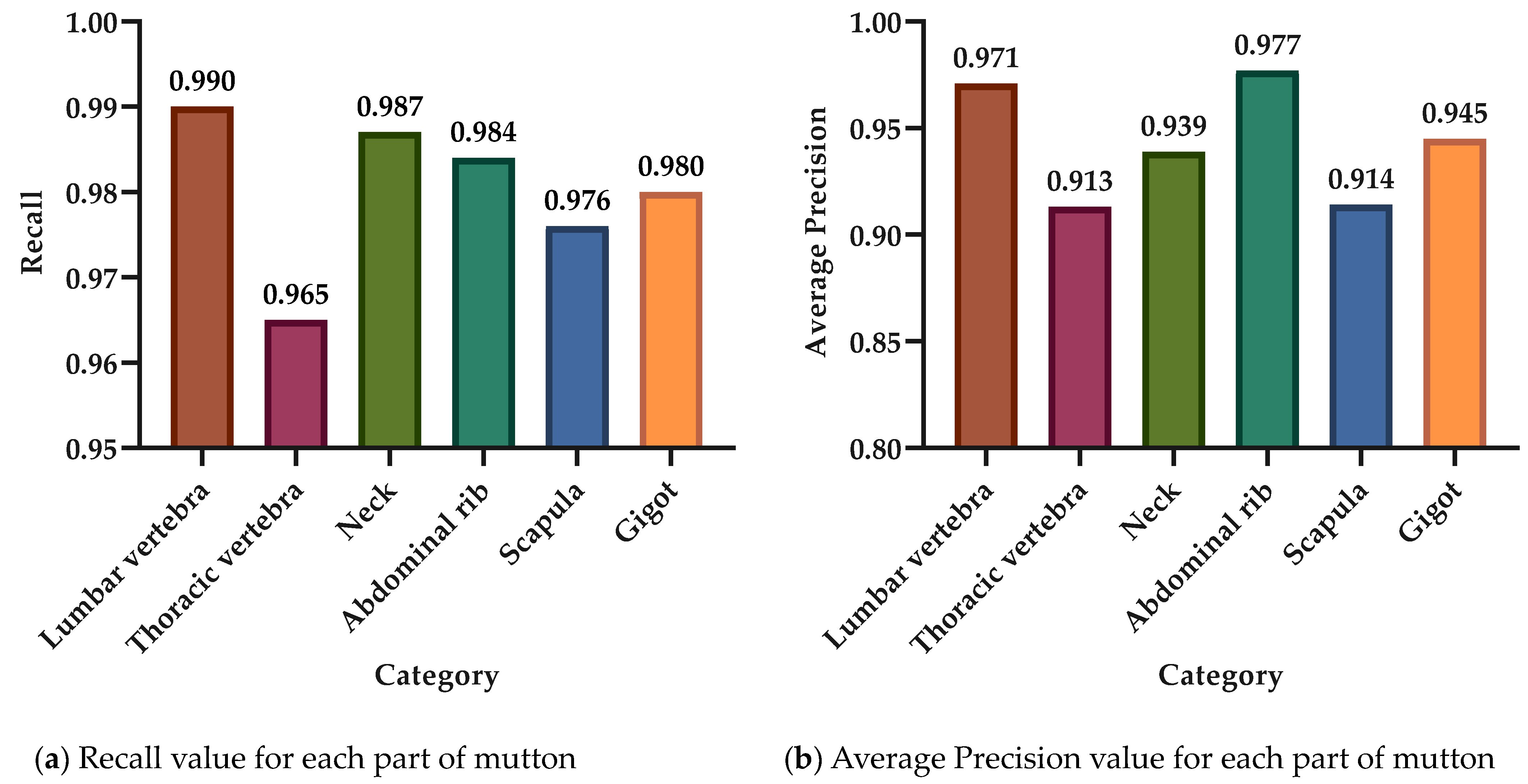{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Training Set | Test Set | Validation Set |
|---|---|---|---|
| Lumbar vertebrae | 3127 | 935 | 412 |
| Thoracic vertebrae | 3283 | 1066 | 467 |
| Neck | 3015 | 1149 | 334 |
| Abdominal ribs | 4398 | 1439 | 538 |
| Scapulae | 2490 | 981 | 359 |
| Gigot | 5329 | 1862 | 564 |
| Total | 21,642 | 7432 | 2674 |
| Network | Image Size (Pixel) | C | Number of Stage1 | Number of Stage2 | Number of Stage3 | Number of Stage4 |
|---|---|---|---|---|---|---|
| Swin-T | 512 × 512 | 96 | 2 | 2 | 6 | 2 |
| Swin-B | 512 × 512 | 96 | 2 | 2 | 18 | 2 |
| Swin-S | 512 × 512 | 128 | 2 | 2 | 18 | 2 |
| Image Resolution | Average Total Detection Time Consuming/s | Average Processing Time of Single Image/s |
|---|---|---|
| 576 × 576 | 73.33 | 0.24 |
| 672 × 672 | 76.33 | 0.25 |
| 768 × 768 | 80.65 | 0.27 |
| Mean | 76.77 | 0.25 |
| References | Test Objects | Category | Method | Result |
|---|---|---|---|---|
| Zhang et al. [17] | Lamb leg, Duck leg, Pork leg, and chicken breast | 4 | CNN | AP > 0.940 |
| Zhao et al. [18] | Neck, Spine, and caudal vertebra | 3 | ICNet | MIoU = 0.858, 0.906, 0.757 |
| Meng et al. [19] | Back meat, Hind Leg, and front Leg | 3 | Image Processing and BP | ACC = 0.914 |
| Zhang et al. [20] | Sheep’s Conformation Parameters | 4 | Image Processing | σ < 6 cm |
| Liu et al. [21] | Muscle region in hind leg | 1 | R2U-NET | AP = 0.982 |
| Wang et al. [22] | Sheep carcass | 1 | PCL | Average overall ACC = 0.921 |
| Proposed model | Lumbar vertebrae, Thoracic vertebrae, Neck, Abdominal rib, Scapulae, and gigot | 6 | Swin-Transformer | mAP = 0.943 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, S.; Bai, Z.; Wang, S.; Gu, Y. Research on Automatic Classification and Detection of Mutton Multi-Parts Based on Swin-Transformer. Foods 2023, 12, 1642. https://doi.org/10.3390/foods12081642
Zhao S, Bai Z, Wang S, Gu Y. Research on Automatic Classification and Detection of Mutton Multi-Parts Based on Swin-Transformer. Foods. 2023; 12(8):1642. https://doi.org/10.3390/foods12081642
Chicago/Turabian StyleZhao, Shida, Zongchun Bai, Shucai Wang, and Yue Gu. 2023. "Research on Automatic Classification and Detection of Mutton Multi-Parts Based on Swin-Transformer" Foods 12, no. 8: 1642. https://doi.org/10.3390/foods12081642