
An Improved YOLOv5 Model: Application to Mixed Impurities Detection for Walnut Kernels

Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples Used in the Experiments
2.2. Images Acquisition System and Dataset Creation
2.2.1. Images Acquisition System
2.2.2. Dataset Production
2.2.3. Experimental Equipment
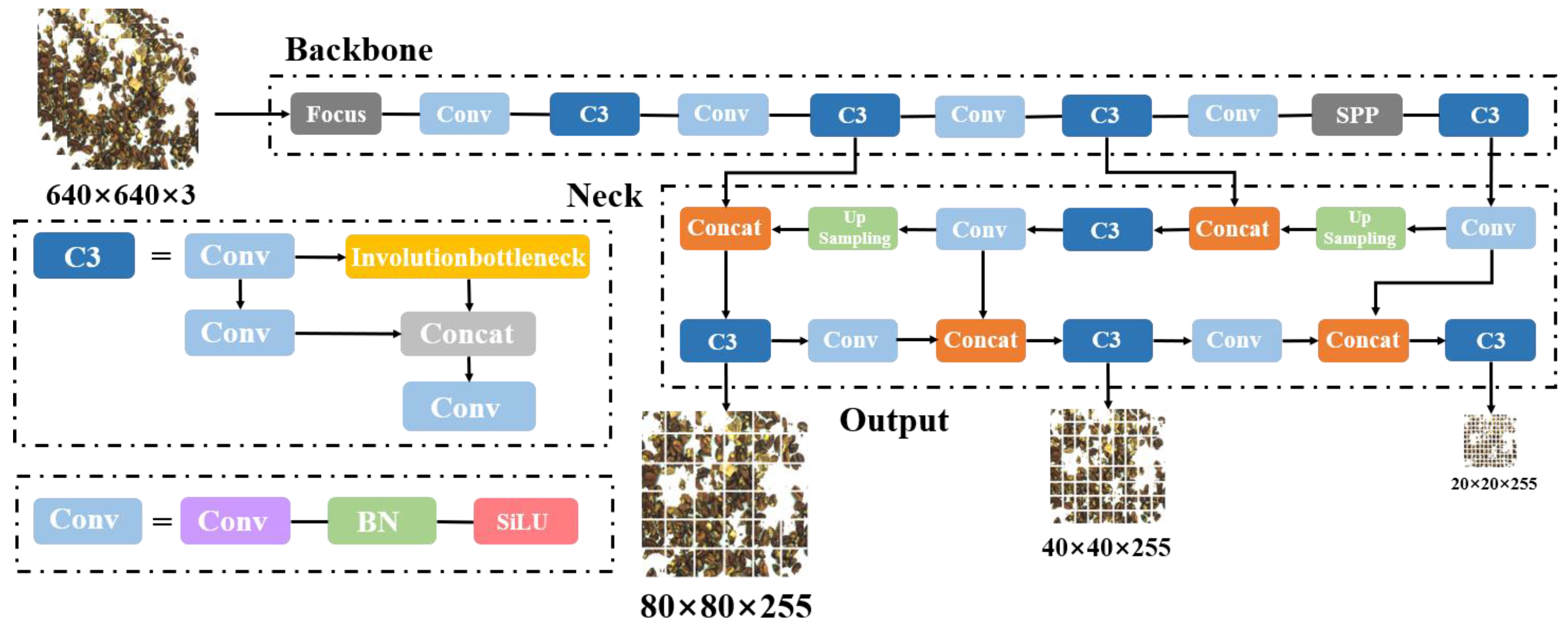
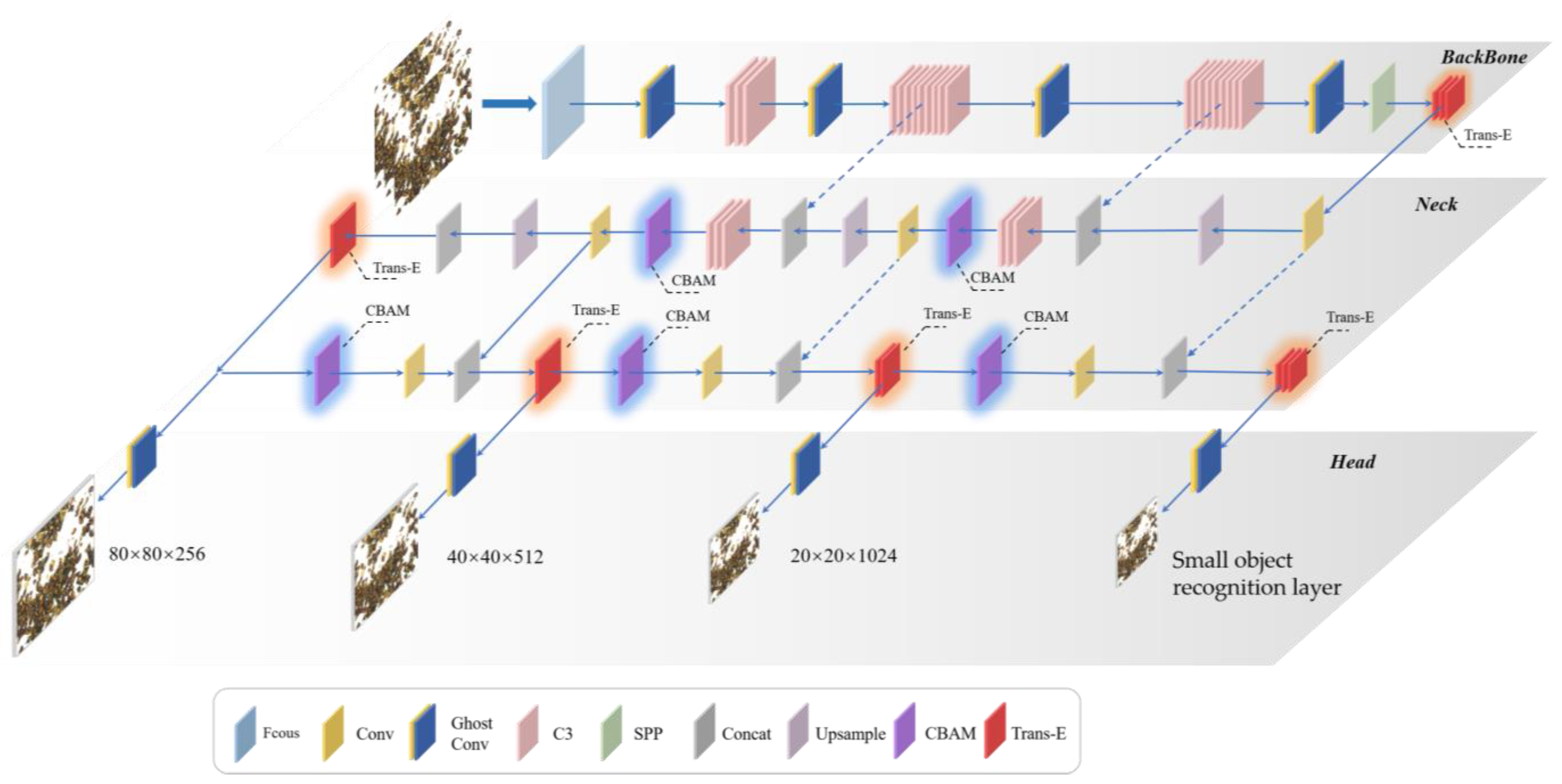
2.3. Walnut Kernel Impurity Detection Based on YOLOv5
2.4. Walnut Kernel Impurity Detection Based on YOLOv5
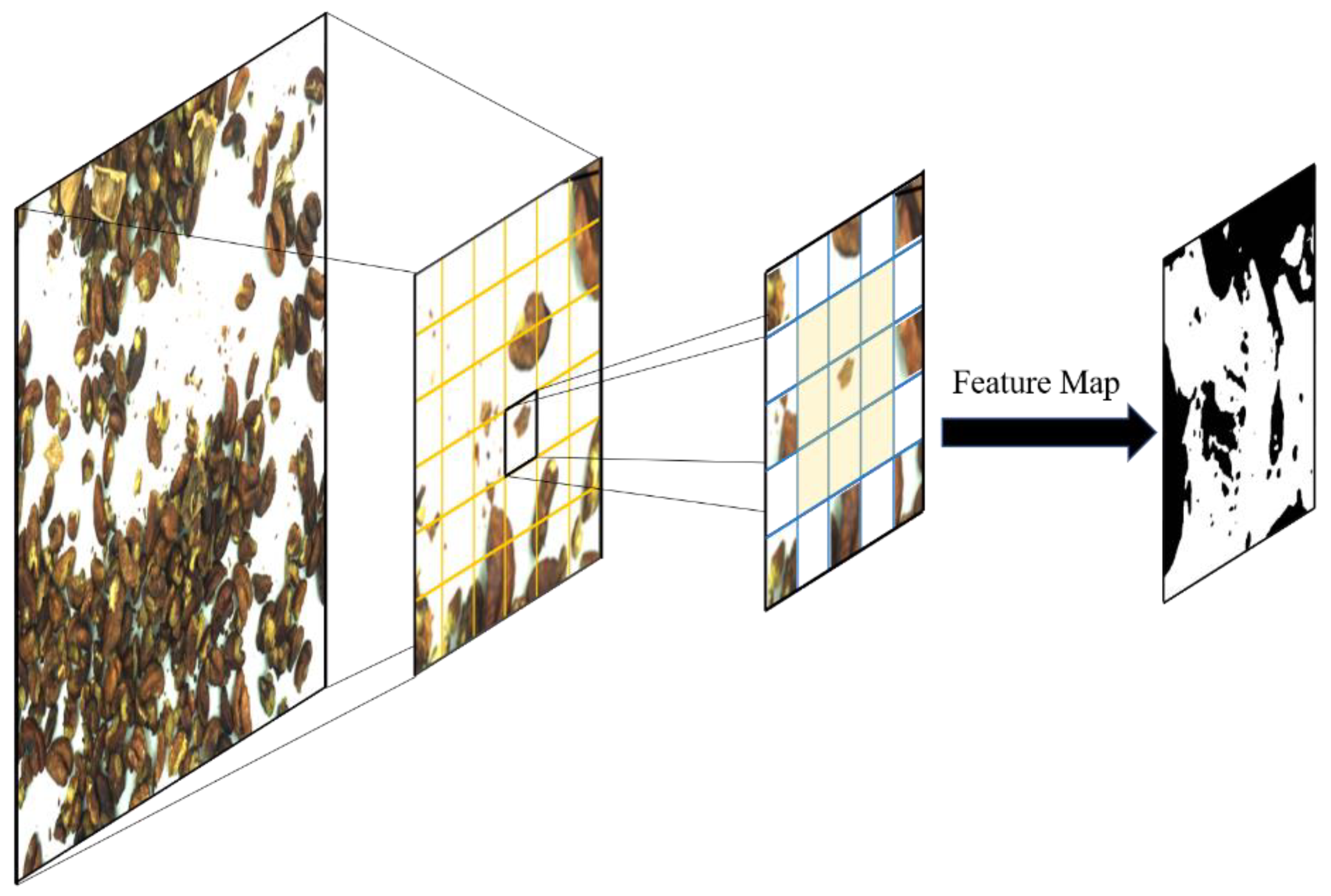
2.4.1. Small Object Recognition Layer
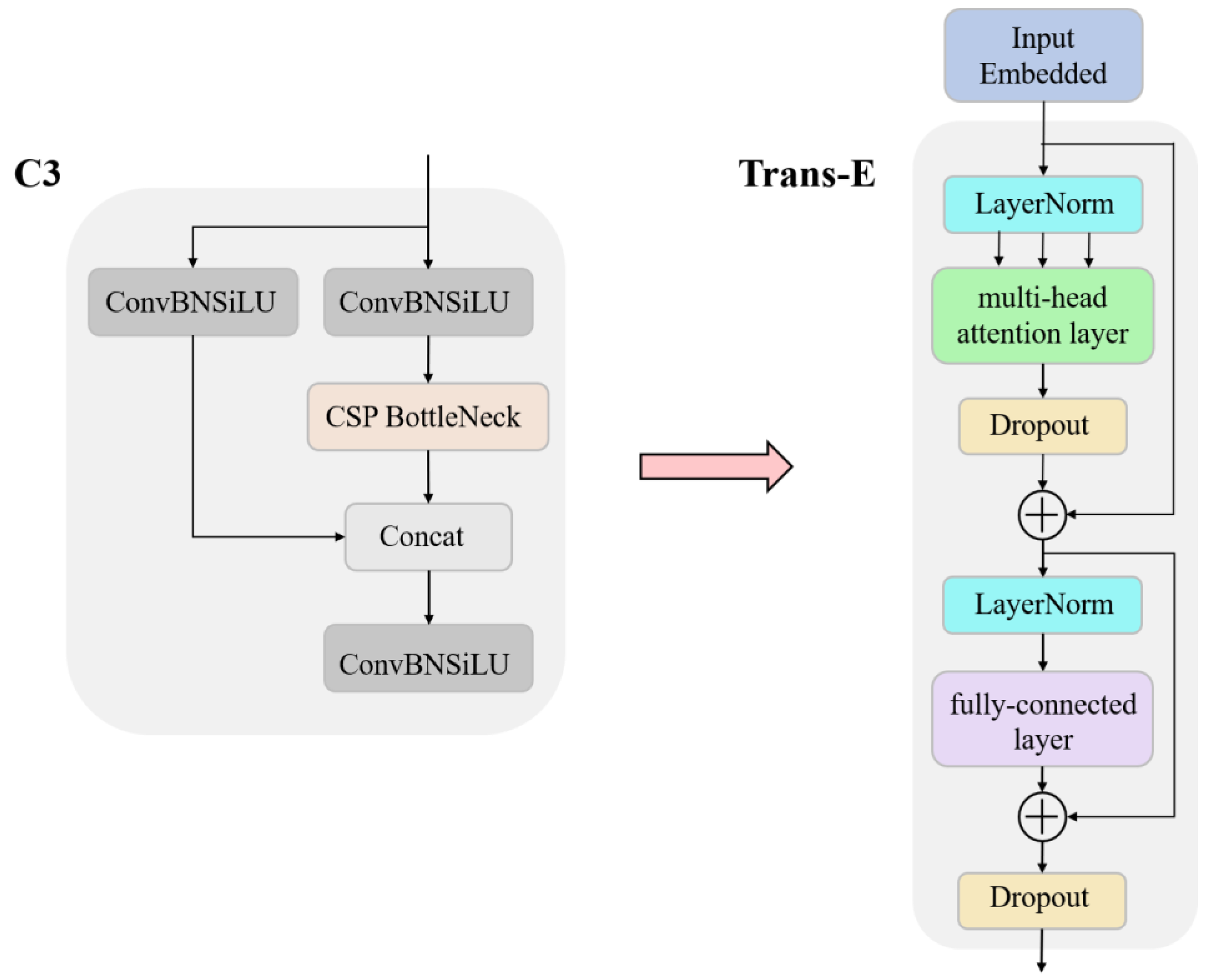
2.4.2. Trans-E Block
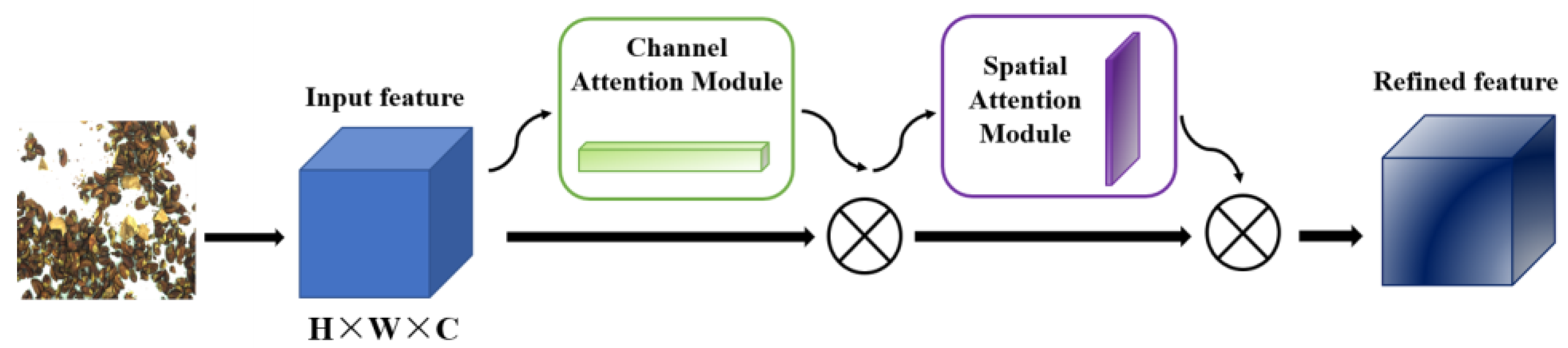
2.4.3. CBAM Attention Mechanism
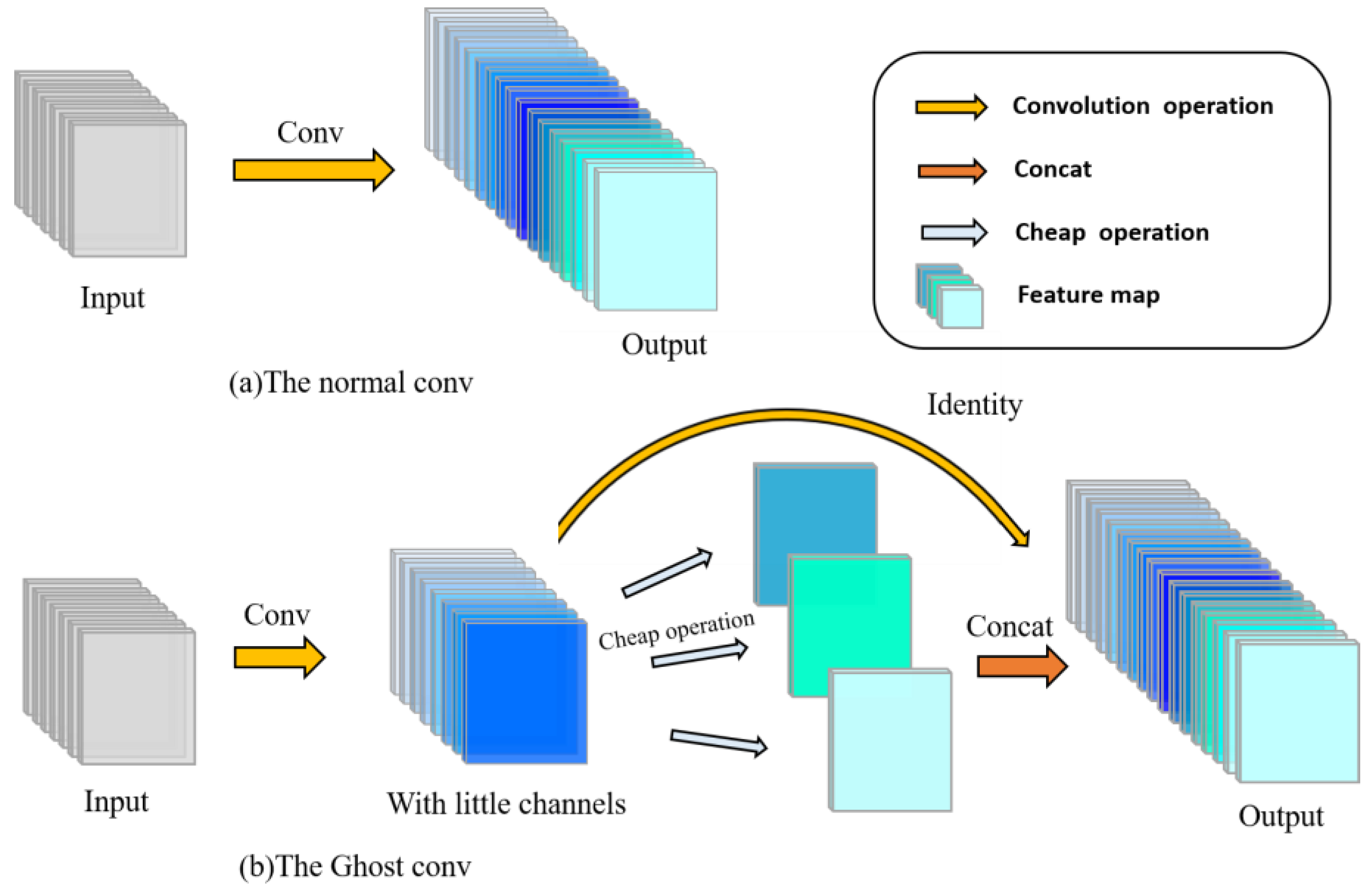
2.4.4. Ghostconv Makes Models Lightweight
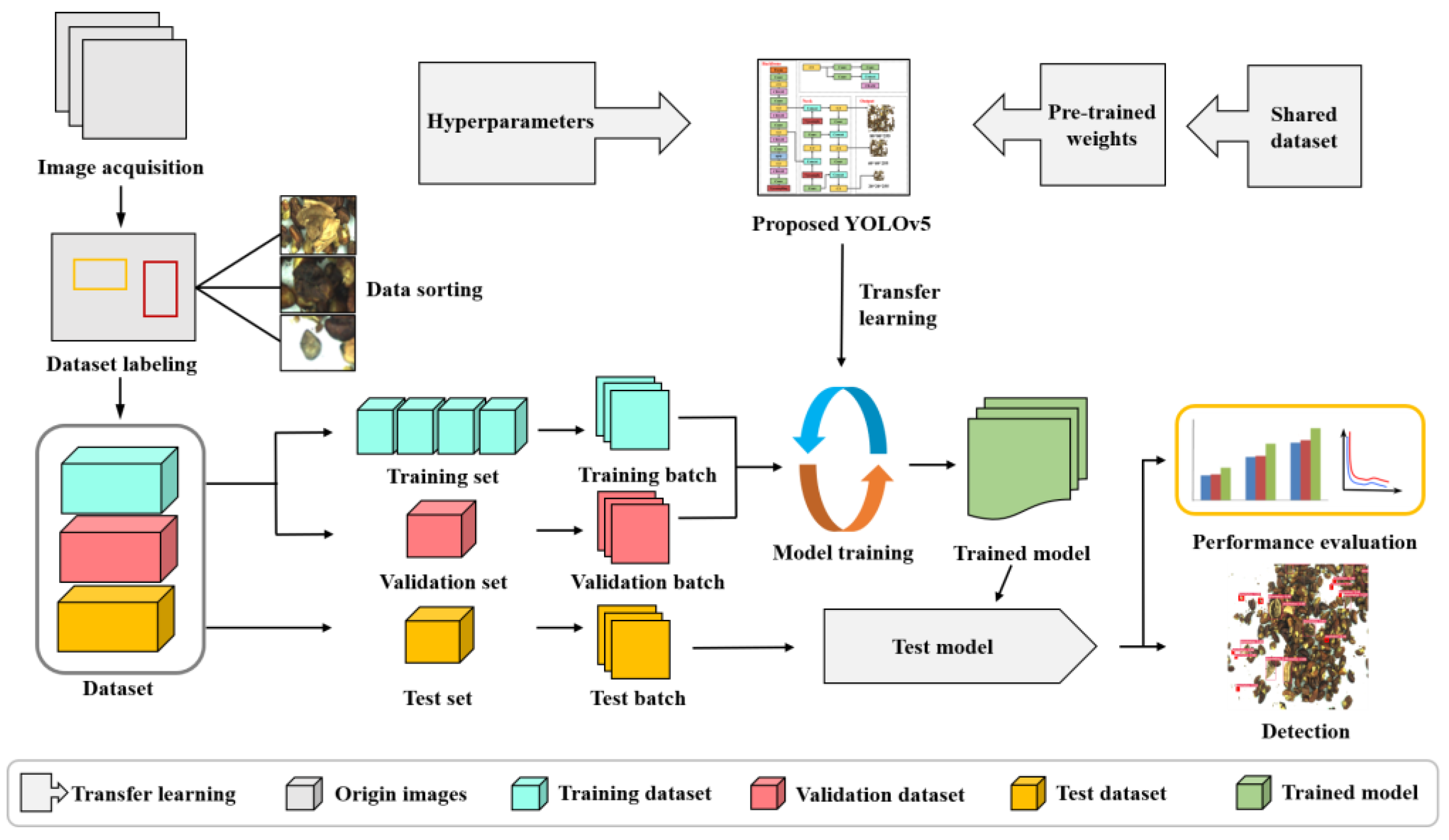
2.5. Experiment Process
2.6. Model Evaluation Index
3. Results and Discussion
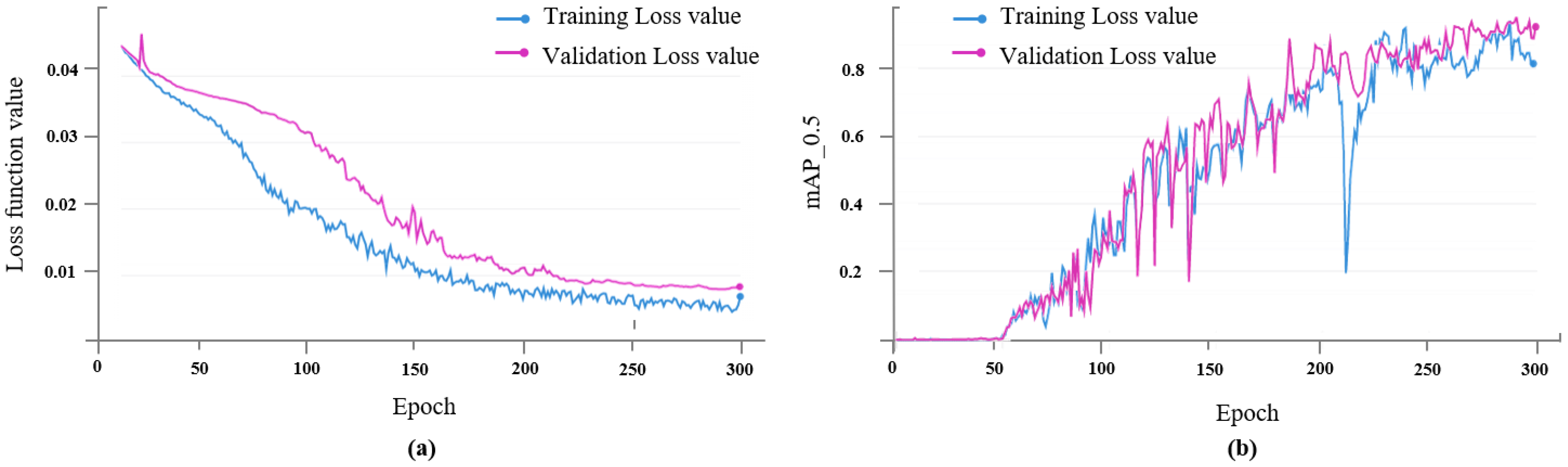
3.1. Model Training Results
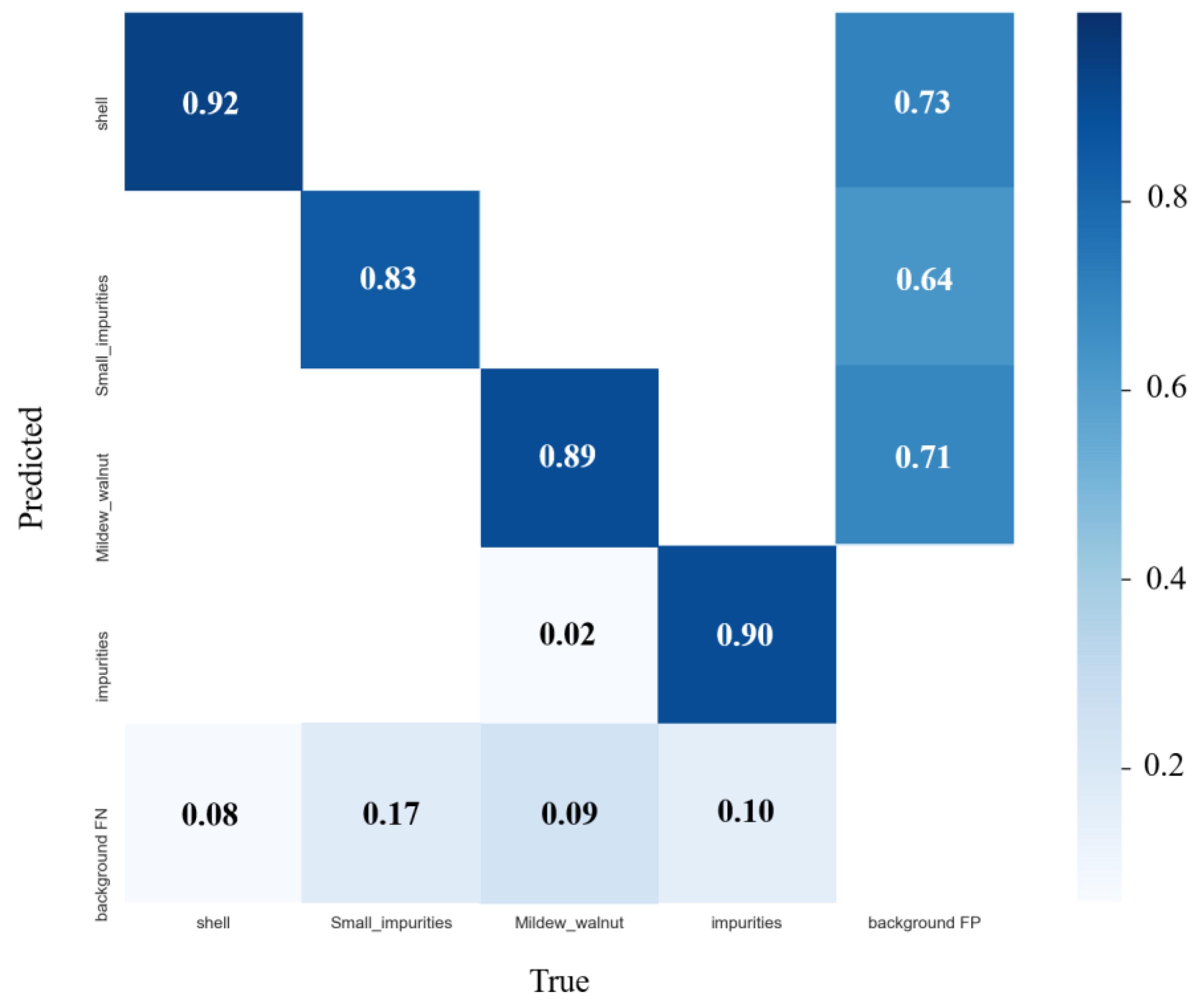
3.2. Model Test Results and Analysis
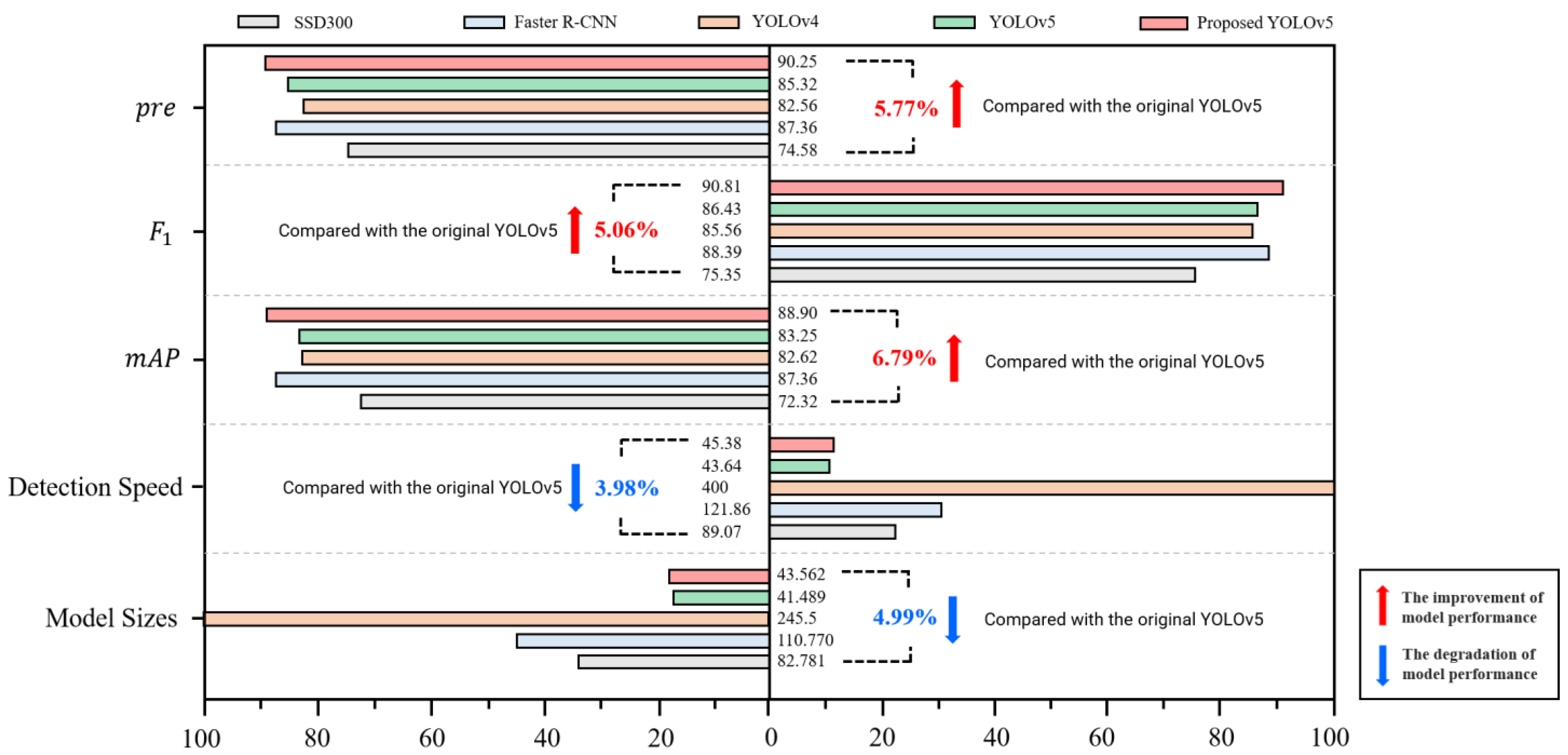
3.3. Performance Comparison of Different Models
3.4. Comparison of Recognition Result
4. Conclusions and Future Research
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Djekic, I.; Jankovic, D.; Rajkovic, A. Analysis of foreign bodies present in European food using data from Rapid Alert System for Food and Feed (RASFF). Food Control 2017, 79, 143–149. [Google Scholar] [CrossRef]
- Aladjadjiyan, A.; Luning, P.A.; Devlieghere, F.; Verhé, J.R. Physical hazards in the agri-food chain. Saf. Agric. 2006, 4, 1082. [Google Scholar]
- Rong, D.; Wang, H.; Xie, L.; Ying, Y.; Zhang, Y.J.C. Impurity detection of juglans using deep learning and machine vision. Comput. Electron. Agric. 2020, 178, 105764. [Google Scholar] [CrossRef]
- Ok, G.; Kim, H.J.; Chun, H.S.; Choi, S.W. Foreign-body detection in dry food using continuous sub-terahertz wave imaging. Food Control 2014, 42, 284–289. [Google Scholar] [CrossRef]
- Shen, Y.; Yin, Y.; Li, B.; Zhao, C.; Li, G. Detection of impurities in wheat using terahertz spectral imaging and convolutional neural networks. Comput. Electron. Agric. 2021, 181, 6781. [Google Scholar] [CrossRef]
- Xie, T.; Li, X.; Zhang, X.; Hu, J.; Fang, Y. Detection of Atlantic salmon bone residues using machine vision technology. Food Control 2020, 123, 107787. [Google Scholar] [CrossRef]
- Wang, C.; Xiao, Z. Potato Surface Defect Detection Based on Deep Transfer Learning. Agriculture 2021, 11, 863. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. In Detecting Apples in Orchards Using YOLOv3 and YOLOv5 in General and Close-Up Images; International Symposium on Neural Networks; Springer: Cairo, Egypt, 2020. [Google Scholar]
- Cengil, E.; Inar, A. Poisonous Mushroom Detection Using YOLOV5. Turk. J. Sci. Technol. 2021, 16, 119–127. [Google Scholar]
- Thuan, D. Evolution of Yolo Algorithm and Yolov5: The State-of-the-Art Object Detention Algorithm. Bachelor’s Thesis, Oulu University of Applied Sciences, Oulu, Finland, 2021. [Google Scholar]
- Shao, H.; Pu, J.; Mu, J. Pig-posture recognition based on computer vision: Dataset and exploration. Animals 2021, 11, 1295. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E.J.C.; Otto, A. Imagenet classification with deep convolutional neural networks. 2017, 60, 84–90. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, J.; Deng, H.; Zeng, X. Neuroscience, Food Image Recognition and Food Safety Detection Method Based on Deep Learning. Comput. Intell. 2021, 2021, 297. [Google Scholar]
- Jubayer, F.; Soeb, J.A.; Mojumder, A.N.; Paul, M.K.; Barua, P.; Kayshar, S.; Akter, S.S.; Rahman, M.; Islam, A. Mold Detection on Food Surfaces Using YOLOv5. Curr. Res. Food Sci. 2021, 4, 724–728. [Google Scholar] [CrossRef] [PubMed]
- Du, Z.; Fang, S.; Zhe, L.; Zheng, J. Tomato Leaf Disease Detection Based on Deep Feature Fusion of Convolutional Neural Network; China Science Paper: Beijing, China, 2020. [Google Scholar]
- Qi, J.; Liu, X.; Liu, K.; Xu, F.; Guo, H.; Tian, X.; Li, M.; Bao, Z.; Li, Y. An improved YOLOv5 model based on visual attention mechanism: Application to recognition of tomato virus disease. Comput. Electron. Agric. 2022, 194, 106780. [Google Scholar] [CrossRef]
- Han, W.; Jiang, F.; Zhu, Z. Detection of Cherry Quality Using YOLOV5 Model Based on Flood Filling Algorithm. Foods 2022, 11, 1127. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Li, C.; Cao, C.; Wang, L.; Li, X.; Che, J.; Yang, H.; Zhang, X.; Zhao, H.; He, G. Walnut fruit processing equipment: Academic insights and perspectives. Food Eng. Rev. 2021, 13, 822–857. [Google Scholar] [CrossRef]
- Glenn, J. Yolov5. Git Code. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 10 June 2021).
- Chen, Z.; He, L.; Ye, Y.; Chen, J.; Wang, R. Automatic sorting of fresh tea leaves using vision-based recognition method. J. Food Process Eng. 2020, 1, e13474. [Google Scholar] [CrossRef]
- Tzutalin, D. LabelImg. Git Code. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 10 June 2021).
- Li, S.; Zhang, S.; Xue, J.; Sun, H. Lightweight target detection for the field flat jujube based on improved YOLOv5. Comput. Electron. Agric. 2022, 202, 107391. [Google Scholar] [CrossRef]
- Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 2972. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation; 2017. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Fan, Y.; Zhang, S.; Feng, K.; Qian, K.; Wang, Y.; Qin, S. Strawberry maturity recognition algorithm combining dark channel enhancement and YOLOv5. Sensors 2022, 22, 419. [Google Scholar] [CrossRef]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A Small Target Object Detection Method for Fire Inspection. Sustainability 2022, 14, 288. [Google Scholar] [CrossRef]
- Ma, L.; Ma, J.; Han, J.; Li, Y. Research on target detection algorithm based on YOLOv5s. Comput. Knowl. Technol 2021, 17, 100–103. [Google Scholar]
- Ma, S.; Lu, H.; Wang, Y.; Xue, H. YOLOX-Mobile: A Target Detection Algorithm More Suitable for Mobile Devices. J. Phys. Conf. Ser. 2022, 2203, 012030. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Isa, I.S.; Rosli, M.S.A.; Yusof, U.K.; Maruzuki, M.I.F.; Sulaiman, S.N. Optimizing the Hyperparameter Tuning of YOLOv5 For Underwater Detection. IEEE Access 2022, 10, 52818–52831. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Configuration |
|---|---|
| Operating system | Windows 10 |
| Deep Learning Framework | Pytorch2.6 |
| Programming language | Python3.8 |
| GPU accelerated environment | CUDA 11.3 |
| GPU | GeForce RTX 3080 10 G |
| CPU | Intel®Core™ i7\11800H CPU@3.70 GHz |
| Class | Num | Pre (%) | Rec (%) | mAP (%) | F1 (%) |
|---|---|---|---|---|---|
| Shell | 2059 | 92.21 | 96.32 | 94.20 | 94.56 |
| Small_impurities | 2624 | 83.56 | 87.84 | 85.12 | 86.21 |
| metamorphic_walnut | 786 | 89.24 | 93.37 | 90.98 | 91.26 |
| Other impurities | 432 | 90.25 | 94.93 | 92.21 | 92.87 |
| Total | 5901 | 89.69 | 93.42 | 91.25 | 91.77 |
| Model | P (%) | R (%) | F1-Score (%) | mAP (%) | Dect. Time (ms) | ModelSizes (M) |
|---|---|---|---|---|---|---|
| Faster-RCNN | 87.36 | 89.25 | 88.39 | 81.62 | 121.86 | 110.770 |
| SSD300 | 67.75 | 75.38 | 65.43 | 69.36 | 89.07 | 82.781 |
| YOLOv4 | 82.56 | 90.14 | 85.56 | 85.62 | 400 | 245.5 |
| YOLOv5 | 85.32 | 88.97 | 86.43 | 83.25 | 43.64 | 41.489 |
| Proposed YOLOv5 | 90.25 | 91.56 | 90.81 | 88.9 | 45.38 | 43.562 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Qian, M.; Chen, Q.; Sun, F.; Pan, J. An Improved YOLOv5 Model: Application to Mixed Impurities Detection for Walnut Kernels. Foods 2023, 12, 624. https://doi.org/10.3390/foods12030624
Yu L, Qian M, Chen Q, Sun F, Pan J. An Improved YOLOv5 Model: Application to Mixed Impurities Detection for Walnut Kernels. Foods. 2023; 12(3):624. https://doi.org/10.3390/foods12030624
Chicago/Turabian StyleYu, Lang, Mengbo Qian, Qiang Chen, Fuxing Sun, and Jiaxuan Pan. 2023. "An Improved YOLOv5 Model: Application to Mixed Impurities Detection for Walnut Kernels" Foods 12, no. 3: 624. https://doi.org/10.3390/foods12030624