
Harnessing the Full Power of Chemometric-Based Analysis of Total Reflection X-ray Fluorescence Spectral Data to Boost the Identification of Seafood Provenance and Fishing Areas

 ,
,  ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
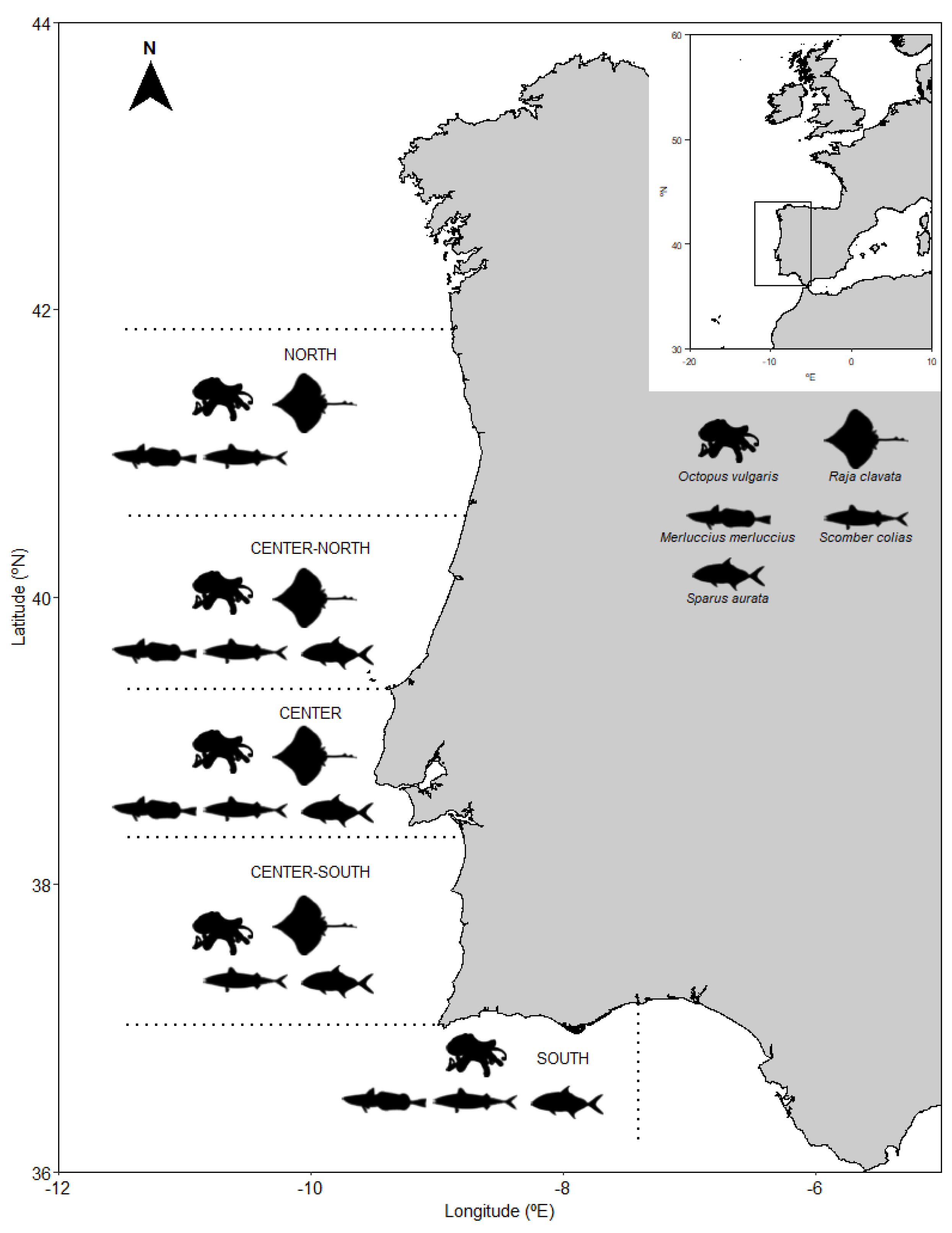
2.1. Sample Collection
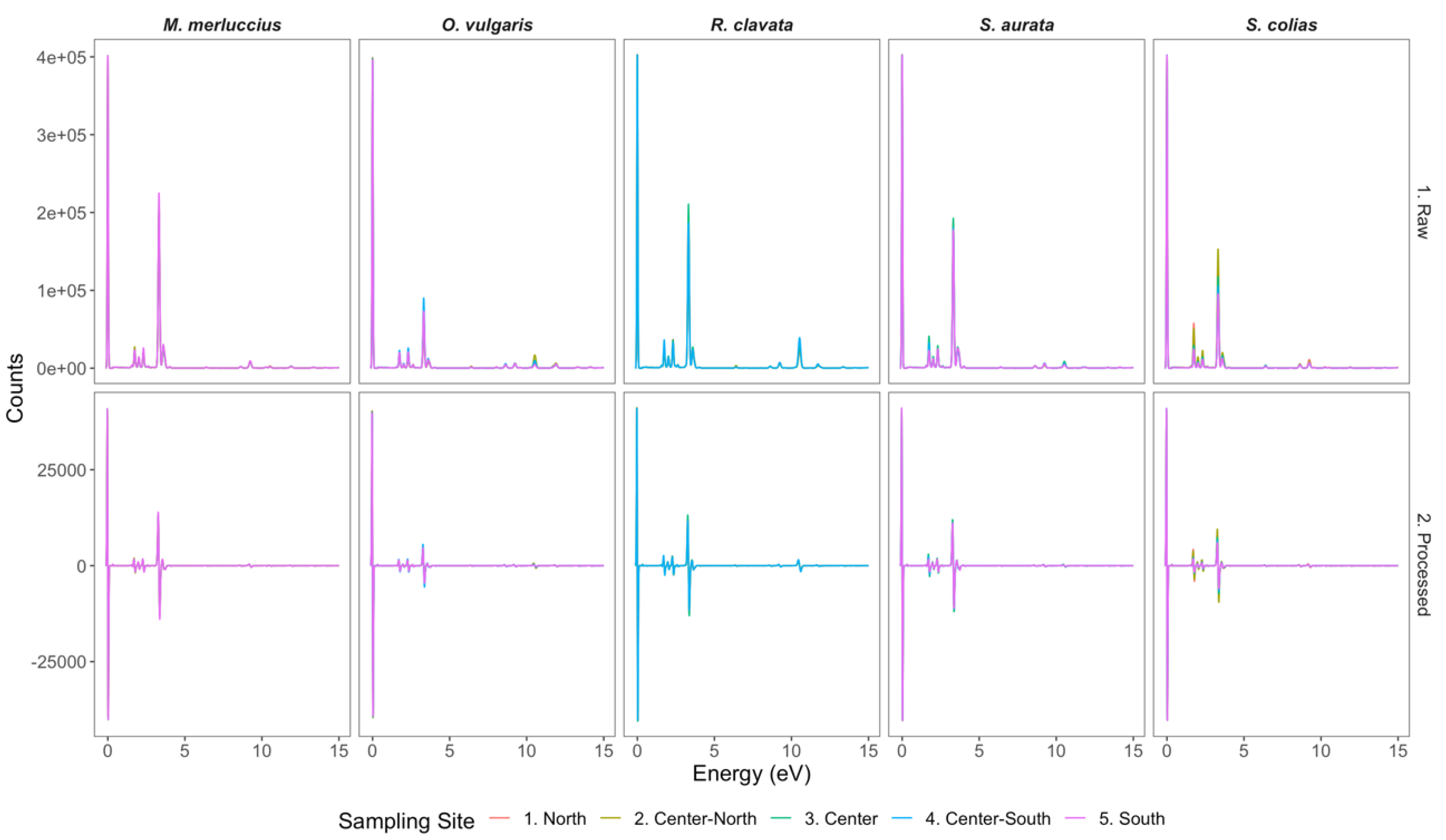
2.2. Sample Processing and TXRF Analysis
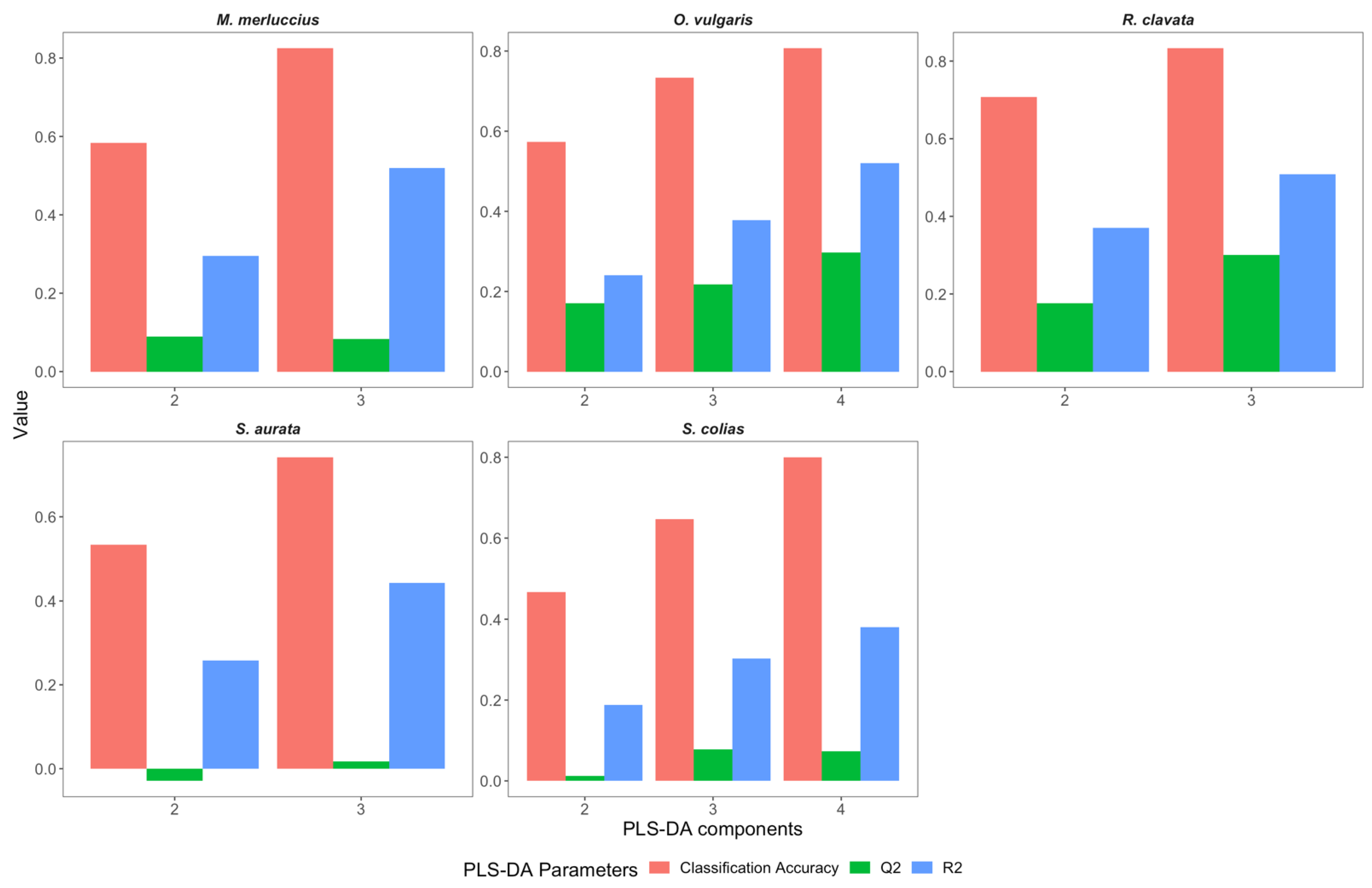
2.3. Spectrum Data Processing and Chemometric Analysis
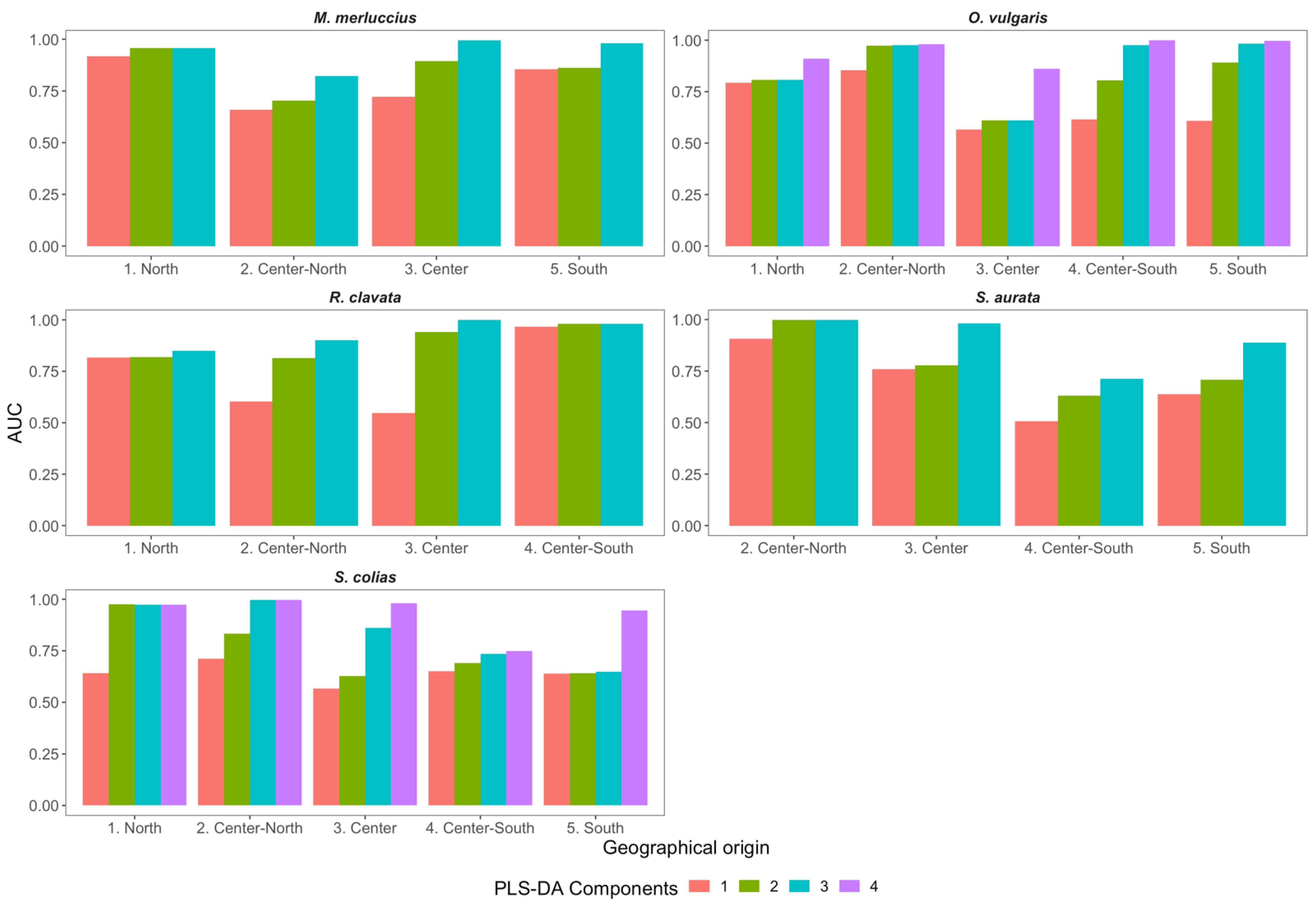
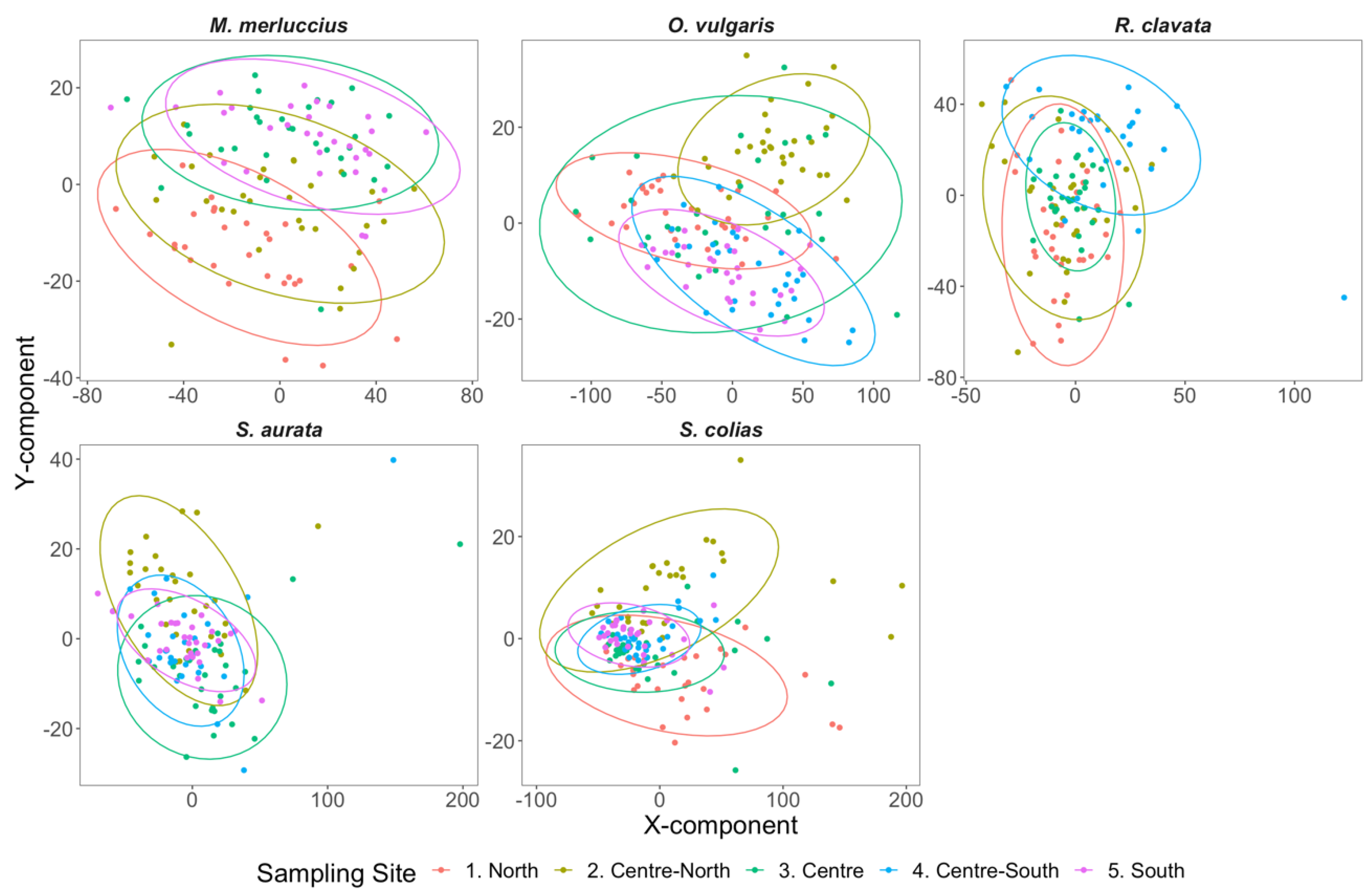
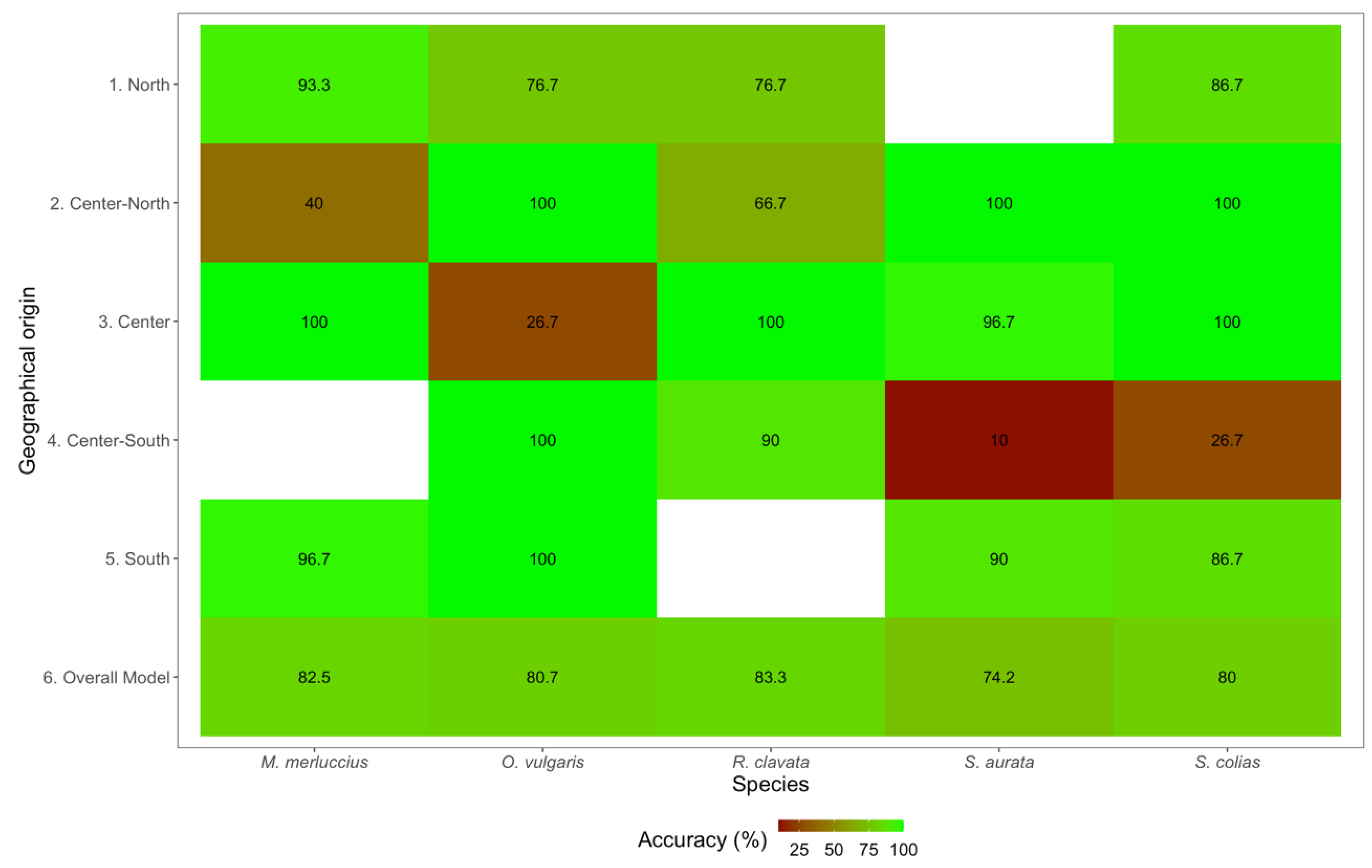
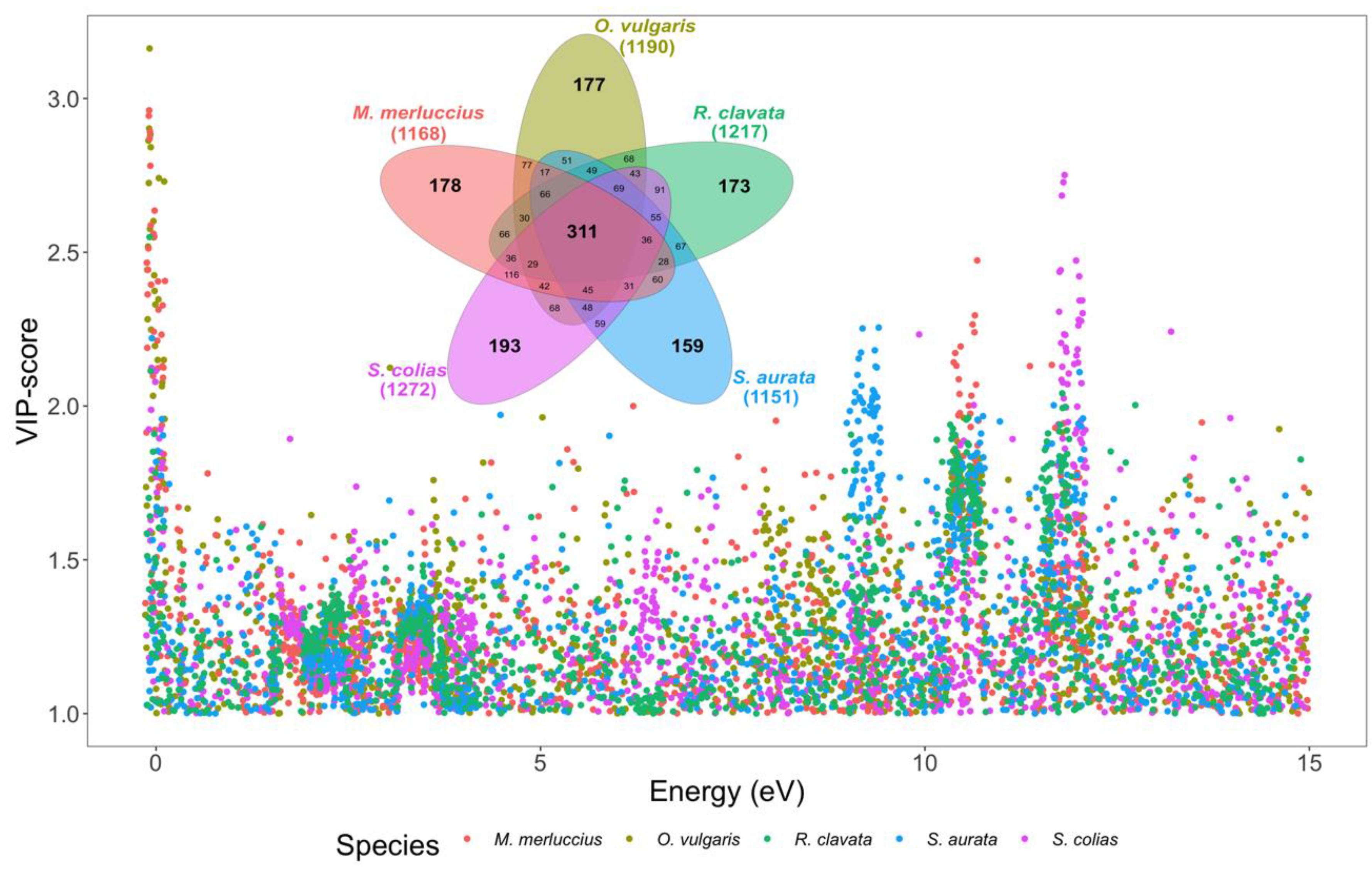
3. Results and Discussion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Leal, M.C.; Pimentel, T.; Ricardo, F.; Rosa, R.; Calado, R. Seafood Traceability: Current Needs, Available Tools, and Biotechnological Challenges for Origin Certification; Elsevier: Amsterdam, The Netherlands, 2015; Volume 33. [Google Scholar]
- European Commission. European Commission Regulation (EC) No. 178/2002 of the European Parliament and of the Council; European Commission: Brussels, Belgium, 2002; pp. L31/24–L31/31.
- Rasmussen, R.S.; Morrissey, M.T. DNA-Based Methods for the Identification of Commercial Fish and Seafood Species. Compr. Rev. Food Sci. Food Saf. 2008, 7, 280–295. [Google Scholar] [CrossRef] [PubMed]
- Cawthorn, D.-M.; Mariani, S. Global Trade Statistics Lack Granularity to Inform Traceability and Management of Diverse and High-Value Fishes. Sci. Rep. 2017, 7, 12852. [Google Scholar] [CrossRef] [PubMed]
- Barendse, J.; Roel, A.; Longo, C.; Andriessen, L.; Webster, L.M.I.; Ogden, R.; Neat, F. DNA Barcoding Validates Species Labelling of Certified Seafood. Curr. Biol. 2019, 29, R198–R199. [Google Scholar] [CrossRef] [PubMed]
- Christiansen, H.; Fournier, N.; Hellemans, B.; Volckaert, F.A.M. Seafood Substitution and Mislabeling in Brussels’ Restaurants and Canteens. Food Control 2018, 85, 66–75. [Google Scholar] [CrossRef]
- He, J. From Country-of-Origin Labelling (COOL) to Seafood Import Monitoring Program (SIMP): How Far Can Seafood Traceability Rules Go? Mar. Policy 2018, 96, 163–174. [Google Scholar] [CrossRef]
- Reilly, A. Overview of Food Fraud in the Fisheries Sector; Fisheries and Aquaculture Circular; Food and Agriculture Organization of the United Nations (FAO): Rome, Italy, 2018; p. 32. [Google Scholar]
- Albuquerque, R.; Queiroga, H.; Swearer, S.E.; Calado, R.; Leandro, S.M. Harvest Locations of Goose Barnacles Can Be Successfully Discriminated Using Trace Elemental Signatures. Sci. Rep. 2016, 6, 27787. [Google Scholar] [CrossRef]
- Arbuckle, N.S.M.; Wormuth, J.H. Trace Elemental Patterns in Humboldt Squid Statoliths from Three Geographic Regions. Hydrobiologia 2014, 725, 115–123. [Google Scholar] [CrossRef]
- Bennion, M.; Morrison, L.; Shelley, R.; Graham, C. Trace Elemental Fingerprinting of Shells and Soft Tissues Can Identify the Time of Blue Mussel (Mytilus Edulis) Harvesting. Food Control 2021, 121, 107515. [Google Scholar] [CrossRef]
- Duarte, B.; Carreiras, J.; Mamede, R.; Duarte, I.A.; Caçador, I.; Reis-Santos, P.; Vasconcelos, R.P.; Gameiro, C.; Rosa, R.; Tanner, S.E.; et al. Written in Ink: Elemental Signatures in Octopus Ink Successfully Trace Geographical Origin. J. Food Compos. Anal. 2022, 109, 104479. [Google Scholar] [CrossRef]
- Duarte, B.; Duarte, I.A.; Caçador, I.; Reis-Santos, P.; Vasconcelos, R.P.; Gameiro, C.; Tanner, S.E.; Fonseca, V.F. Elemental Fingerprinting of Thornback Ray (Raja Clavata) Muscle Tissue as a Tracer for Provenance and Food Safety Assessment. Food Control 2022, 133, 108592. [Google Scholar] [CrossRef]
- Duarte, B.; Mamede, R.; Duarte, I.A.; Caçador, I.; Tanner, S.E.; Silva, M.; Jacinto, D.; Cruz, T.; Fonseca, V.F. Elemental Chemometrics as Tools to Depict Stalked Barnacle (Pollicipes Pollicipes) Harvest Locations and Food Safety. Molecules 2022, 27, 1298. [Google Scholar] [CrossRef] [PubMed]
- Drivelos, S.A.; Georgiou, C.A. Multi-Element and Multi-Isotope-Ratio Analysis to Determine the Geographical Origin of Foods in the European Union. TrAC Trends Anal. Chem. 2012, 40, 38–51. [Google Scholar] [CrossRef]
- Kelly, S.; Heaton, K.; Hoogewerff, J. Tracing the Geographical Origin of Food: The Application of Multi-Element and Multi-Isotope Analysis. Trends Food Sci. Technol. 2005, 16, 555–567. [Google Scholar] [CrossRef]
- Varrà, M.O.; Ghidini, S.; Zanardi, E.; Badiani, A.; Ianieri, A. Authentication of European Sea Bass According to Production Method and Geographical Origin by Light Stable Isotope Ratio and Rare Earth Elements Analyses Combined with Chemometrics. Ital. J. Food Saf. 2019, 8, 7872. [Google Scholar] [CrossRef] [PubMed]
- Fonseca, V.F.; Duarte, I.A.; Matos, A.R.; Reis-Santos, P.; Duarte, B. Fatty Acid Profiles as Natural Tracers of Provenance and Lipid Quality Indicators in Illegally Sourced Fish and Bivalves. Food Control 2021, 134, 108735. [Google Scholar] [CrossRef]
- Mottese, A.F.; Albergamo, A.; Bartolomeo, G.; Bua, G.D.; Rando, R.; De Pasquale, P.; Saija, E.; Donato, D.; Dugo, G. Evaluation of Fatty Acids and Inorganic Elements by Multivariate Statistics for the Traceability of the Sicilian Capparis spinosa L. J. Food Compos. Anal. 2018, 72, 66–74. [Google Scholar] [CrossRef]
- Ricardo, F.; Gonçalves, D.; Pimentel, T.; Mamede, R.; Rosário, M.; Domingues, M.; Lillebø, A.I.; Calado, R. Prevalence of Phylogenetic over Environmental Drivers on the Fatty Acid Profiles of the Adductor Muscle of Marine Bivalves and Its Relevance for Traceability. Ecol. Indic. 2021, 129, 108017. [Google Scholar] [CrossRef]
- Ghidini, S.; Varrà, M.O.; Dall’Asta, C.; Badiani, A.; Ianieri, A.; Zanardi, E. Rapid Authentication of European Sea Bass (Dicentrarchus Labrax L.) According to Production Method, Farming System, and Geographical Origin by near Infrared Spectroscopy Coupled with Chemometrics. Food Chem. 2019, 280, 321–327. [Google Scholar] [CrossRef]
- Ghidini, S.; Varrà, M.O.; Zanardi, E. Approaching Authenticity Issues in Fish and Seafood Products by Qualitative Spectroscopy and Chemometrics. Molecules 2019, 24, 1812. [Google Scholar] [CrossRef]
- Varrà, M.O.; Ghidini, S.; Ianieri, A.; Zanardi, E. Near Infrared Spectral Fingerprinting: A Tool against Origin-Related Fraud in the Sector of Processed Anchovies. Food Control 2021, 123, 107778. [Google Scholar] [CrossRef]
- Bua, G.D.; Albergamo, A.; Annuario, G.; Zammuto, V.; Costa, R.; Dugo, G. High-Throughput ICP-MS and Chemometrics for Exploring the Major and Trace Element Profile of the Mediterranean Sepia Ink. Food Anal. Methods 2017, 10, 1181–1190. [Google Scholar] [CrossRef]
- Costas-Rodríguez, M.; Lavilla, I.; Bendicho, C. Classification of Cultivated Mussels from Galicia (Northwest Spain) with European Protected Designation of Origin Using Trace Element Fingerprint and Chemometric Analysis. Anal. Chim. Acta 2010, 664, 121–128. [Google Scholar] [CrossRef] [PubMed]
- Cozzolino, D. An Overview of the Use of Infrared Spectroscopy and Chemometrics in Authenticity and Traceability of Cereals. Food Res. Int. 2014, 60, 262–265. [Google Scholar] [CrossRef]
- Power, A.; Cozzolino, D. How Fishy Is Your Fish? Authentication, Provenance and Traceability in Fish and Seafood by Means of Vibrational Spectroscopy. Appl. Sci. 2020, 10, 4150. [Google Scholar] [CrossRef]
- Panchuk, V.; Yaroshenko, I.; Legin, A.; Semenov, V.; Kirsanov, D. Application of Chemometric Methods to XRF-Data—A Tutorial Review. Anal. Chim. Acta 2018, 1040, 19–32. [Google Scholar] [CrossRef]
- Environmental Protection Agency (EPA). Test Method 3052: Microwave Assisted Acid Digestion of Siliceous and Organically Based Matrices; Environmental Protection Agency (EPA): Washington, DC, USA, 1996; p. 20.
- Delwiche, S.R.; Reeves, J.B. A Graphical Method to Evaluate Spectral Preprocessing in Multivariate Regression Calibrations: Example with Savitzky—Golay Filters and Partial Least Squares Regression. Appl. Spectrosc. 2010, 64, 73–82. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Steinier, J.; Termonia, Y.; Deltour, J. Smoothing and Differentiation of Data by Simplified Least Square Procedure. Anal. Chem. 1972, 44, 1906–1909. [Google Scholar] [CrossRef]
- Kucheryavskiy, S. Mdatools—R Package for Chemometrics. Chemom. Intell. Lab. Syst. 2020, 198, 103937. [Google Scholar] [CrossRef]
- Sanchez, G. Package ‘DiscriMiner’. 2013. Available online: https://mran.microsoft.com/snapshot/2015-10-02/web/packages/DiscriMiner/DiscriMiner.pdf (accessed on 31 August 2022).
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- Molinaro, A.M.; Simon, R.; Pfeiffer, R.M. Prediction Error Estimation: A Comparison of Resampling Methods. Bioinformatics 2005, 21, 3301–3307. [Google Scholar] [CrossRef] [Green Version]
- Rohart, F.; Gautier, B.; Singh, A.; Lê Cao, K.-A. MixOmics: An R Package for ‘omics Feature Selection and Multiple Data Integration. bioRxiv 2017, 13, 108597. [Google Scholar] [CrossRef] [PubMed]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Zimmermann, B.; Kohler, A. Optimizing Savitzky–Golay Parameters for Improving Spectral Resolution and Quantification in Infrared Spectroscopy. Appl. Spectrosc. 2013, 67, 892–902. [Google Scholar] [CrossRef] [PubMed]
- Varrà, M.O.; Ghidini, S.; Fabrile, M.P.; Ianieri, A.; Zanardi, E. Country of Origin Label Monitoring of Musky and Common Octopuses (Eledone spp. and Octopus vulgaris) by Means of a Portable near-Infrared Spectroscopic Device. Food Control. 2022, 138, 109052. [Google Scholar] [CrossRef]
- Zareef, M.; Chen, Q.; Hassan, M.M.; Arslan, M.; Hashim, M.M.; Ahmad, W.; Kutsanedzie, F.Y.H.; Agyekum, A.A. An Overview on the Applications of Typical Non-Linear Algorithms Coupled With NIR Spectroscopy in Food Analysis. Food Eng. Rev. 2020, 12, 173–190. [Google Scholar] [CrossRef]
- Mamede, R.; Ricardo, F.; Gonçalves, D.; Ferreira da Silva, E.; Patinha, C.; Calado, R. Assessing the Use of Surrogate Species for a More Cost-Effective Traceability of Geographic Origin Using Elemental Fingerprints of Bivalve Shells. Ecol. Indic. 2021, 130, 108065. [Google Scholar] [CrossRef]
- Varrà, M.O.; Husáková, L.; Patočka, J.; Ghidini, S.; Zanardi, E. Multi-Element Signature of Cuttlefish and Its Potential for the Discrimination of Different Geographical Provenances and Traceability. Food Chem. 2021, 356, 129687. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | Geographical Origin | Group Precision | Overall Precision | Group Sensitivity | Overall Sensitivity | Group Specificity | Overall Specificity |
|---|---|---|---|---|---|---|---|
| M. merluccius | North | 70.0% | 82.5% | 93.3% | 82.5% | 85.5% | 82.5% |
| Center-North | 92.3% | 40.0% | 98.9% | ||||
| Center | 93.8% | 100.0% | 97.2% | ||||
| Center-South | - | - | - | ||||
| South | 82.9% | 96.7% | 92.1% | ||||
| O. vulgaris | North | 59.0% | 80.7% | 76.7% | 80.7% | 86.0% | 80.7% |
| Center-North | 83.3% | 100.0% | 93.8% | ||||
| Center | 53.3% | 26.7% | 94.2% | ||||
| Center-South | 100.0% | 100.0% | 100.0% | ||||
| South | 100.0% | 100.0% | 100.0% | ||||
| R. clavata | North | 76.7% | 83.3% | 76.7% | 83.3% | 91.7% | 83.3% |
| Center-North | 71.4% | 66.7% | 90.9% | ||||
| Center | 100.0% | 100.0% | 100.0% | ||||
| Center-South | 84.4% | 90.0% | 93.6% | ||||
| South | - | - | - | ||||
| S. aurata | North | 89.7% | 73.3% | 100.0% | 73.3% | 96.7% | 73.3% |
| Center-North | 88.2% | 96.7% | 89.4% | ||||
| Center | 73.2% | 10.0% | 97.7% | ||||
| Center-South | 88.9% | 86.7% | 74.7% | ||||
| South | - | - | - | ||||
| S. colias | North | 89.7% | 80.0% | 86.7% | 80.0% | 96.9% | 80.0% |
| Center-North | 88.2% | 100.0% | 95.7% | ||||
| Center | 73.2% | 100.0% | 89.1% | ||||
| Center-South | 88.9% | 26.7% | 99.1% | ||||
| South | 70.3% | 86.7% | 89.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duarte, B.; Mamede, R.; Carreiras, J.; Duarte, I.A.; Caçador, I.; Reis-Santos, P.; Vasconcelos, R.P.; Gameiro, C.; Ré, P.; Tanner, S.E.; et al. Harnessing the Full Power of Chemometric-Based Analysis of Total Reflection X-ray Fluorescence Spectral Data to Boost the Identification of Seafood Provenance and Fishing Areas. Foods 2022, 11, 2699. https://doi.org/10.3390/foods11172699
Duarte B, Mamede R, Carreiras J, Duarte IA, Caçador I, Reis-Santos P, Vasconcelos RP, Gameiro C, Ré P, Tanner SE, et al. Harnessing the Full Power of Chemometric-Based Analysis of Total Reflection X-ray Fluorescence Spectral Data to Boost the Identification of Seafood Provenance and Fishing Areas. Foods. 2022; 11(17):2699. https://doi.org/10.3390/foods11172699
Chicago/Turabian StyleDuarte, Bernardo, Renato Mamede, João Carreiras, Irina A. Duarte, Isabel Caçador, Patrick Reis-Santos, Rita P. Vasconcelos, Carla Gameiro, Pedro Ré, Susanne E. Tanner, and et al. 2022. "Harnessing the Full Power of Chemometric-Based Analysis of Total Reflection X-ray Fluorescence Spectral Data to Boost the Identification of Seafood Provenance and Fishing Areas" Foods 11, no. 17: 2699. https://doi.org/10.3390/foods11172699