Single Image Deblurring for Pulsed Laser Range-Gated Imaging System with Multi-Slice Integration

 , , and
, , and
Abstract
:1. Introduction
- A two-step method is proposed to deblur the blurred image caused by the combined effect of forward scatter and defocus.
- An imaging model is built to generate training data for the network, and this can enable the model to deal with different levels of blurred image. It makes use of merits of both knowledge of underwater imaging and deep neural networks.
- Our method outperforms two state-of-the-art methods on several experiments under different water conditions in terms of both visual quality and quantitative metrics.
2. Theory
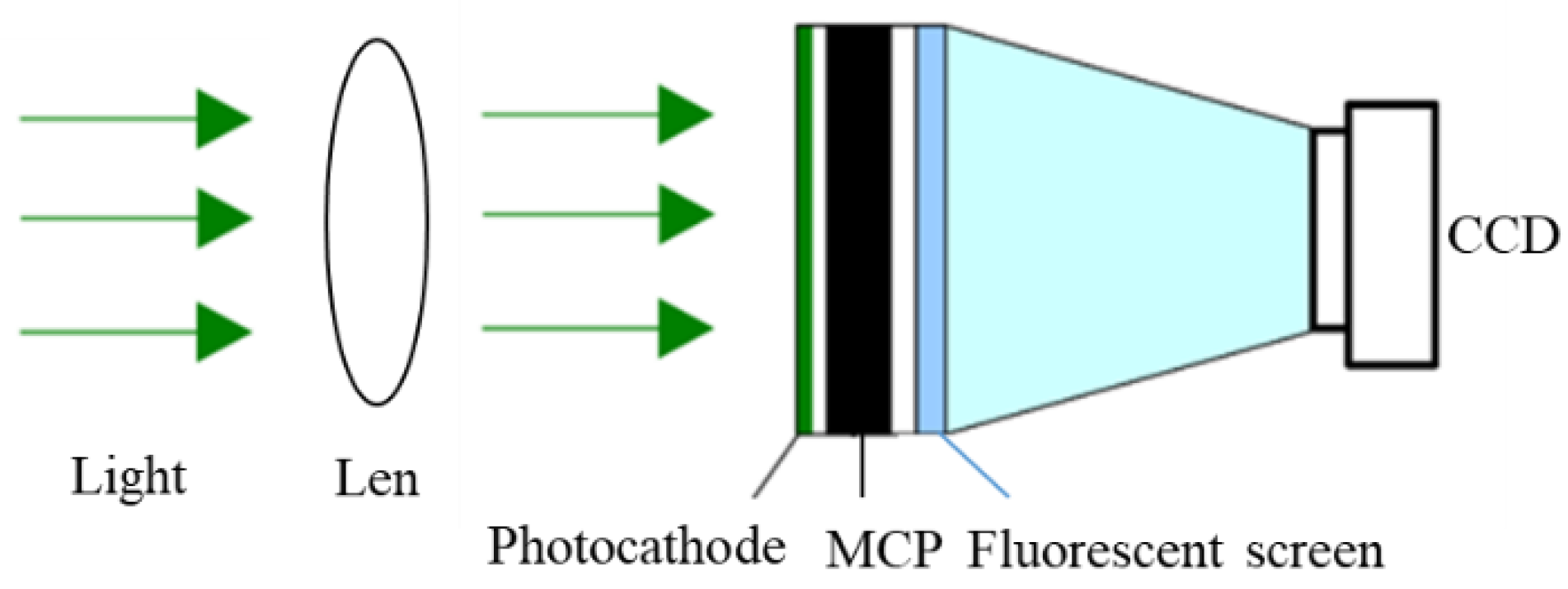
2.1. Multi-Slice Integration Method for PLRGI System
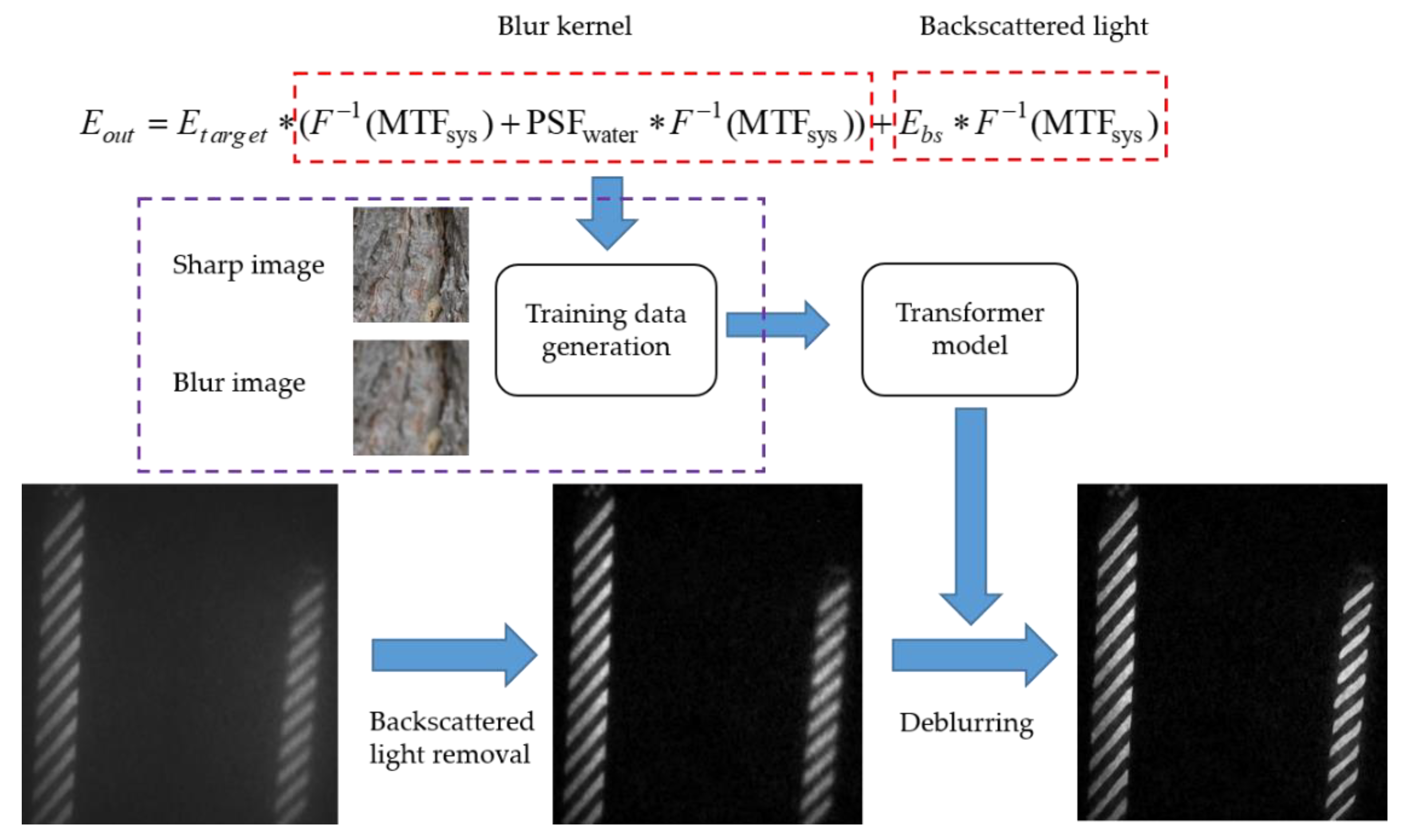
2.2. Imaging Model Based on Jaffe-McGlamery
3. Method
3.1. Backscattered Light Removal
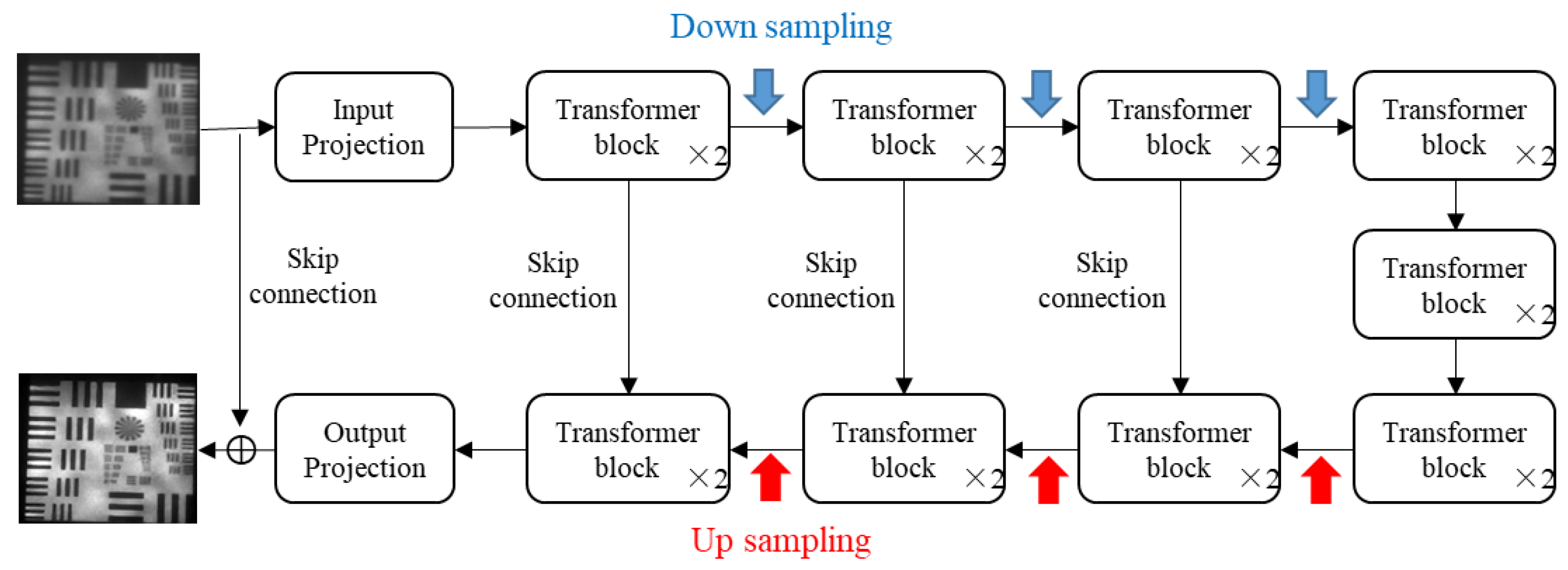
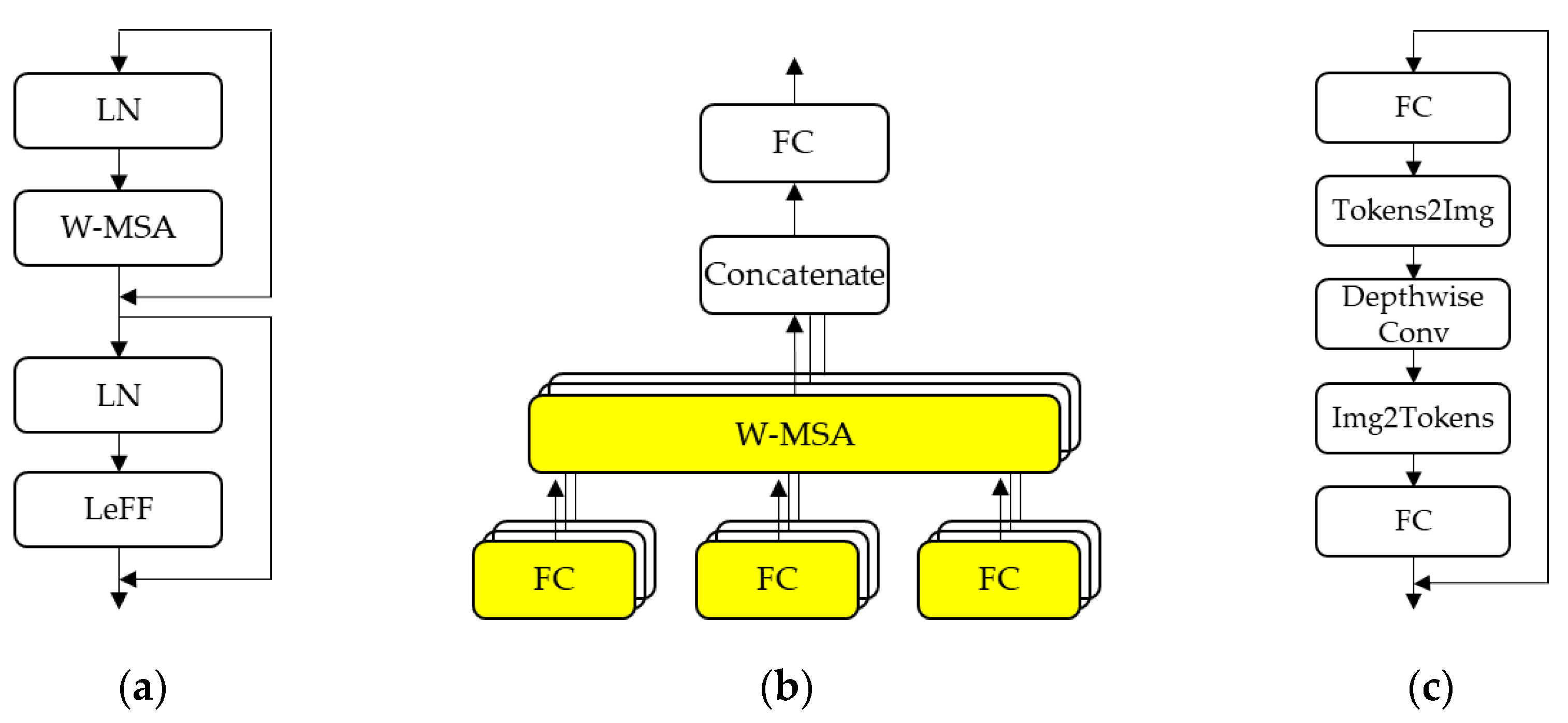
3.2. Image Deblurring Using Transformer
4. Results and Discussion
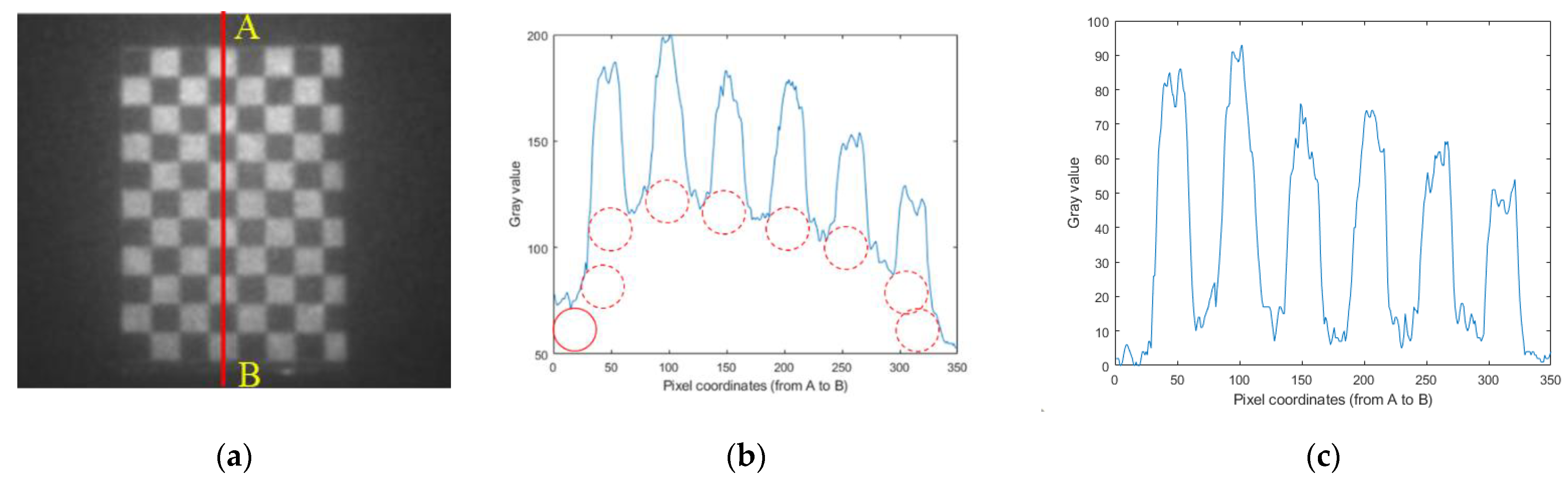
4.1. Experimental Setup
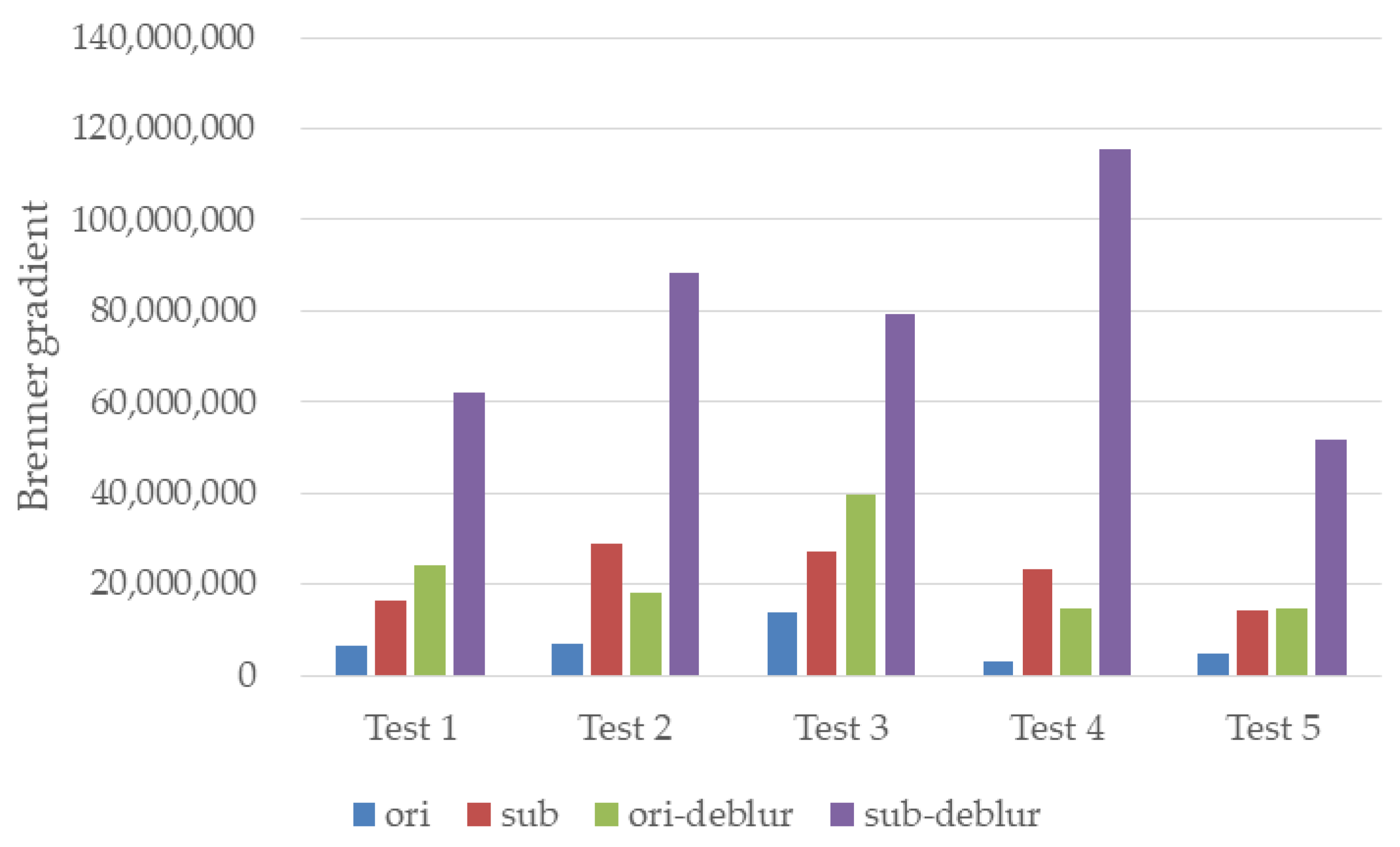
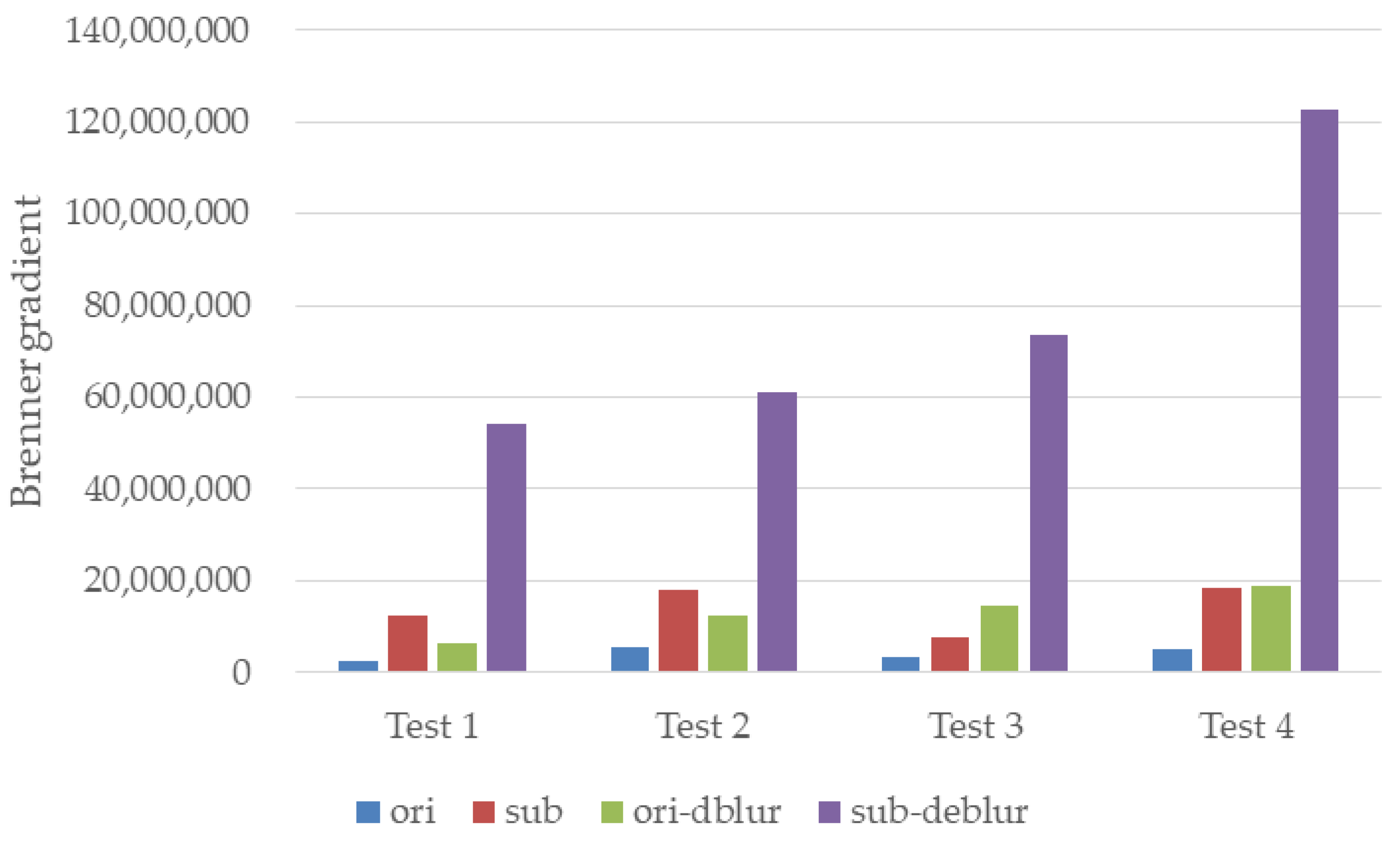
4.2. Experiments in the Water Tank
4.3. Experiments in the Boat Tank
4.4. Compare with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, X.; Wang, X.; Ren, P.; Cao, Y.; Zhou, Y.; Liu, Y. Automatic Fishing Net Detection and Recognition Based on Optical Gated Viewing for Underwater Obstacle Avoidance. Opt. Eng. 2017, 56, 83101. [Google Scholar] [CrossRef]
- Risholm, P.; Thorstensen, J.; Thielemann, J.T.; Kaspersen, K.; Tschudi, J.; Yates, C.; Softley, C.; Abrosimov, I.; Alexander, J.; Haugholt, K.H. Real-Time Super-Resolved 3D in Turbid Water Using a Fast Range-Gated CMOS Camera. Appl. Opt. 2018, 57, 3927–3937. [Google Scholar] [CrossRef] [PubMed]
- Sluzek, A. Model of Gated Imaging in Turbid Media. Opt. Eng. 2005, 44, 116002. [Google Scholar] [CrossRef]
- Ulich, B.L.; Lacovara, P.; Moran, S.E.; DeWeert, M.J. Recent Results in Imaging Lidar. In Proceedings of the Advances in Laser Remote Sensing for Terrestrial and Oceanographic Applications, Orlando, FL, USA, 21–22 April 1997; SPIE: Bellingham, WA, USA, 1997; Volume 3059, pp. 95–108. [Google Scholar]
- McLean, E.A.; Burris, H.R.; Strand, M.P. Short-Pulse Range-Gated Optical Imaging in Turbid Water. Appl. Opt. 1995, 34, 4343–4351. [Google Scholar] [CrossRef] [PubMed]
- Acharekar, M.A. Underwater Laser Imaging System (ULIS); Dubey, A.C., Barnard, R.L., Eds.; SPIE: Orlando, FL, USA, 1997; Volume 3079, pp. 750–761. [Google Scholar]
- Xinwei, W.; Youfu, L.; Yan, Z. Multi-Pulse Time Delay Integration Method for Flexible 3D Super-Resolution Range-Gated Imaging. Opt. Express 2015, 23, 7820–7831. [Google Scholar] [CrossRef]
- Lin, H.; Han, H.; Ma, L.; Ding, Z.; Jin, D.; Zhang, X. Range Intensity Profiles of Multi-Slice Integration for Pulsed Laser Range-Gated Imaging System. Photonics 2022, 9, 505. [Google Scholar] [CrossRef]
- Chen, Y. Model-Based Restoration and Reconstruction for Underwater Range-Gated Imaging. Opt. Eng. 2011, 50, 113203. [Google Scholar] [CrossRef]
- Murez, Z.; Treibitz, T.; Ramamoorthi, R.; Kriegman, D.J. Photometric Stereo in a Scattering Medium. IEEE Trans. Pattern. Anal. Mach. Intell. 2017, 39, 1880–1891. [Google Scholar] [CrossRef]
- Fujimura, Y.; Iiyama, M.; Hashimoto, A.; Minoh, M. Photometric Stereo in Participating Media Using an Analytical Solution for Shape-Dependent Forward Scatter. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 708–719. [Google Scholar] [CrossRef] [PubMed]
- Drews, P.L.J.; Nascimento, E.R.; Botelho, S.S.C.; Montenegro Campos, M.F. Underwater Depth Estimation and Image Restoration Based on Single Images. IEEE Comput. Graph. Appl. 2016, 36, 24–35. [Google Scholar] [CrossRef]
- Li, C.; Anwar, S.; Hou, J.; Cong, R.; Guo, C.; Ren, W. Underwater Image Enhancement via Medium Transmission-Guided Multi-Color Space Embedding. IEEE Trans. Image Process. 2021, 30, 4985–5000. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.-H.; Li, G.; Kwong, S.; Li, C. Underwater Image Enhancement via Minimal Color Loss and Locally Adaptive Contrast Enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Zhang, W.; Dong, L.; Xu, W. Retinex-Inspired Color Correction and Detail Preserved Fusion for Underwater Image Enhancement. Comput. Electron. Agric. 2022, 192, 106585. [Google Scholar] [CrossRef]
- Wang, R.; Wang, G. Single Image Recovery in Scattering Medium by Propagating Deconvolution. Opt. Express 2014, 22, 8114. [Google Scholar] [CrossRef]
- Risholm, P.; Thielemann, J.T.; Moore, R.; Haugholt, K.H. A Scatter Removal Technique to Enhance Underwater Range-Gated 3D and Intensity Images. In Proceedings of the OCEANS 2018 MTS/IEEE, Charleston, SC, USA, 22–25 October 2018; pp. 1–6. [Google Scholar]
- Cun, X.; Pun, C.-M. Defocus Blur Detection via Depth Distillation. In Computer Vision–ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 12358, pp. 747–763. ISBN 978-3-030-58600-3. [Google Scholar]
- Karaali, A.; Jung, C.R. Edge-Based Defocus Blur Estimation With Adaptive Scale Selection. IEEE Trans. Image Process. 2018, 27, 1126–1137. [Google Scholar] [CrossRef]
- Abuolaim, A.; Brown, M.S. Defocus Deblurring Using Dual-Pixel Data. In Proceedings of the Computer Vision–ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 12355, pp. 111–126. [Google Scholar]
- Son, H.; Lee, J.; Cho, S.; Lee, S. Single Image Defocus Deblurring Using Kernel-Sharing Parallel Atrous Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV); IEEE: Montreal, QC, Canada, 2021; pp. 2622–2630. [Google Scholar]
- Quan, Y.; Wu, Z.; Ji, H. Gaussian Kernel Mixture Network for Single Image Defocus Deblurring. arXiv 2021, arXiv:2111.00454. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A General U-Shaped Transformer for Image Restoration. arXiv 2021, arXiv:2106.03106. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient Transformer for High-Resolution Image Restoration. arXiv 2022, arXiv:2111.09881. [Google Scholar]
- Jaffe, J.S. Computer Modeling and the Design of Optimal Underwater Imaging Systems. IEEE J. Ocean. Eng. 1990, 15, 101–111. [Google Scholar] [CrossRef]
- McGlamery, B.L. A Computer Model for Underwater Camera Systems; Duntley, S.Q., Ed.; SPIE: Monterey, CA, USA, 1979; Volume 0208, pp. 221–231. [Google Scholar]
- Hou, W.; Gray, D.J.; Weidemann, A.D.; Arnone, R.A. Comparison and Validation of Point Spread Models for Imaging in Natural Waters. Opt. Express 2008, 16, 9958. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, H.; Zou, P.; Chen, Q.; Gu, G.; Zhang, L. Research on Modulation Transfer Function of the Electron Multiplying CCD. In Proceedings of the 2012 Symposium on Photonics and Optoelectronics, Shanghai, China, 21–23 May 2012; IEEE: Shanghai, China, 2012; pp. 1–4. [Google Scholar]
- Wu, L.; Shen, Y.; Li, G.; Chen, C.; Yang, H. Modeling and Simulation of Range-Gated Underwater Laser Imaging Systems; Amzajerdian, F., Gao, C., Xie, T., Eds.; SPIE: Beijing, China, 2009; Volume 7382, p. 73825B. [Google Scholar]
- Holst, G.C. CCD Arrays, Cameras, and Displays, 2nd ed.; SPIE Optical Engineering: Winter Park, CO, USA; JCD Publishing: Bellingham, FL, USA, 1998; ISBN 978-0-9640000-4-9. [Google Scholar]
- Csorba, I.P. Modulation Transfer Function (MTF) Of Image Intensifier Tubes; Williams, T.L., Ed.; SPIE: Reading, UK, 1981; Volume 0274, pp. 42–51. [Google Scholar]
- Sun, L.; Wang, X.; Liu, X.; Ren, P.; Lei, P.; He, J.; Fan, S.; Zhou, Y.; Liu, Y. Lower-Upper-Threshold Correlation for Underwater Range-Gated Imaging Self-Adaptive Enhancement. Appl. Opt. 2016, 55, 8248. [Google Scholar] [CrossRef]
- Kaiming He; Jian Sun; Xiaoou Tang Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [CrossRef]
- Rodrigues, M.; Militzer, M. Application of the Rolling Ball Algorithm to Measure Phase Volume Fraction from Backscattered Electron Images. Mater. Charact. 2020, 163, 110273. [Google Scholar] [CrossRef]
- Rashed, M. Rolling Ball Algorithm as a Multitask Filter for Terrain Conductivity Measurements. J. Appl. Geophys. 2016, 132, 17–24. [Google Scholar] [CrossRef]
- Sternberg Biomedical Image Processing. Computer 1983, 16, 22–34. [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 978-3-319-24573-7. [Google Scholar]
- Lin, H.; Zhang, X.; Ma, L.; Hu, Q.; Jin, D. Estimation of Water Attenuation Coefficient Byimaging Modeling of the Backscattered Lightwith the Pulsed Laser Range-Gated Imagingsystem. Opt. Contin. 2022, 1, 989–1002. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specifications | Characteristics |
|---|---|
| Dimensions | Φ150 mm × L280 mm |
| Weight in water | ≤1 kg |
| Depth range | Up to 200 m |
| Camera Lens | 8–48 mm focal length |
| Field Of View | 50° |
| Frame rate | 1–30 Hz |
| Visual range | Up to 5 attenuation lengths |
| Image | Original-Img | KPAC (2-Level) | GKMNet | Proposed |
|---|---|---|---|---|
| Test 1 | 6,332,717 | 11,105,332 | 16,595,901 | 60,484,160 |
| Test 2 | 1,859,769 | 2,309,726 | 4,788,044 | 12,987,654 |
| Test 3 | 1,711,670 | 3,133,317 | 4,259,167 | 22,433,318 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.; Ma, L.; Hu, Q.; Zhang, X.; Xiong, Z.; Han, H. Single Image Deblurring for Pulsed Laser Range-Gated Imaging System with Multi-Slice Integration. Photonics 2022, 9, 642. https://doi.org/10.3390/photonics9090642
Lin H, Ma L, Hu Q, Zhang X, Xiong Z, Han H. Single Image Deblurring for Pulsed Laser Range-Gated Imaging System with Multi-Slice Integration. Photonics. 2022; 9(9):642. https://doi.org/10.3390/photonics9090642
Chicago/Turabian StyleLin, Hongsheng, Liheng Ma, Qingping Hu, Xiaohui Zhang, Zhang Xiong, and Hongwei Han. 2022. "Single Image Deblurring for Pulsed Laser Range-Gated Imaging System with Multi-Slice Integration" Photonics 9, no. 9: 642. https://doi.org/10.3390/photonics9090642