1. Introduction
In various fields, such as life testing, reliability, and biological and engineering sciences, there is a need for flexible lifetime distributions with various probability density and hazard rate properties. To this end, Mudholkar et al. (1995) [
1] introduced the exponentiated Weibull family of distributions, which includes unimodal distributions with bathtub hazard rates as well as a broader class of monotone hazard rates. Alternative distributions have been examined since, presenting slightly different features. Gupta and Kundu (1999) [
2] proposed a generalized exponential distribution. Olopade (2008) [
3] considered two distributions, named type-I and type-III generalized half-logistic distributions. Kantam et al. (2014) [
4] proposed a type-II generalized half-logistic distribution (GHLD-II for short). For the purpose of this paper, a brief presentation of the GHLD-II is necessary. On the mathematical plan, the probability density function (PDF), cumulative distribution function (CDF), and reliability function of the GHLD-II with scale parameter
and power parameter
are given by
and
Thus, the GHLD-II is developed through the exponentiation of the reliability function of the half-logistic distribution (see Balakrishnan (1985) [
5]).
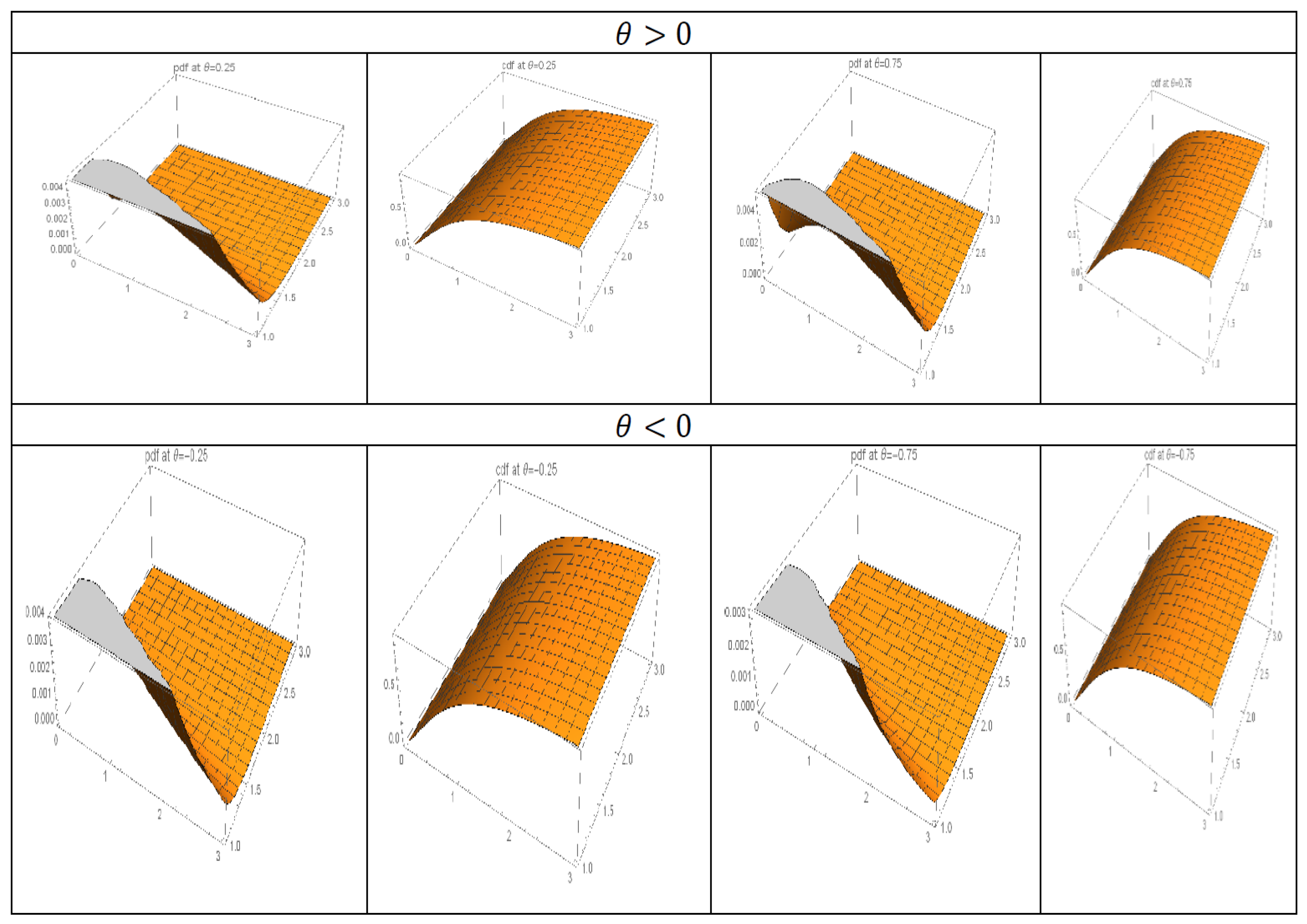
The flexibility of the GHLD-II is mainly in the mode and tail of the distribution, making it an interesting distribution for the modeling of lifetime phenomena. It is proven to define a better model than the exponential, Weibull, and half-logistic models (see Kantam et al. (2014) [
4]).
The first objective of this paper is to derive a comprehensive bivariate generalized half-logistic distribution (BGHLD for short) using the copula approach and study its statistical properties, such as PDF, CDF, product moments, moment generating function, and hazard rate function. Many authors discuss the same idea but other distributions; see Almetwally et al. (2020) [
6], Almetwally and Muhammed (2020) [
7], and Muhammed et al. (2021) [
8]. In view of the impact of the GHLD-II in the recent literature, we derive that bivariate versions have a promising future in terms of modeling and data analysis. Now, in order to detail and motivate the construction of our BGHLD, let us present some basics of the notion of the copula. As a first approach, we can say that a copula is a multivariate CDF for which the marginal distribution of each variable is uniform on the interval
. It describes the dependence between random variables. The definitions below provide more technical details.
Definition 1. Let us consider a random vector and the marginal CDFs denoted by , for . Then, using probability integral transform (PIT) for each component, the distribution of the random vector belongs to the family of distributions, and the copula related to is defined as the joint CDF of , i.e.,with . Definition 2. is a d-dimensional copula if it is a CDF withwith and . In the bivariate case, is a bivariate copula if and for all and . The Sklar theorem, established by Sklar (1959) [
9], is pivotal in copula theory. It states that, for two random variables
and
with marginal CDFs
and
and marginal PDFS
and
, respectively, the CDF and PDF of
are given by
and
respectively, where
denotes the copula density related to
, i.e.,
.
Gumbel (1960) [
10] discussed one of the most popular parametric families of copulas, called the Farlie Gumbel Morgenstern (FGM) copula. The FGM copula and its density are specified by
and
respectively. The parameter
can be thought of as a dependence parameter that is dependent on the underlying random variables, with the independent case being
. The FGM copula is thus simple, flexible, and can be adapted when dealing with the construction of bivariate distributions with complicated marginal distributions in terms of functions. It is used in our study to create our BGHLD, which we naturally call the FGMBGHLD.
The second objective is to develop the maximum likelihood (ML) estimation method of the FGMBGHLD parameters. Finally, the third goal is to derive the corresponding stress–strength model, but when and how this makes sense: in the dependent case, which can occur in engineering, operations research, quality control, education, economics, and insurance. Domma and Giordano (2013) [
11] provided an example. In this paper, we are interested in economics, where
X and
Y are household income and consumption, and
is a measure of household financial affordability.
This paper is organized as follows. In
Section 2, the FGMBGHLD is described. In
Section 3, we derive some statistical properties of the FGMBGHLD. In
Section 4, we exploit the copula approach to take into account the dependence of stress and strength variables in evaluating
R. In
Section 5, the ML estimation method for the FGMBGHLD parameters is discussed. In
Section 6, point and interval estimations for
R are elaborated. In
Section 7, a Monte Carlo simulation study is performed to study the behavior of different estimates. In
Section 8, the estimation of
R is applied to KSA data (year 2018) to measure the household financial affordability for Saudi households by administrative region, with comparison to a modern bivariate Weibull distribution. The conclusion of this paper appears in
Section 9.
5. Estimation Method for the Distribution Parameters
In this section, we present the ML method for estimating the FGMBHLD parameters.
Let
be a random sample from a random vector
following the FGMBHLD with the parameters
,
,
,
, and
. Hence, in particular,
X follows the GBHLD
and
Y follows the GBHLD
. Elaal and Jarwan (2017) [
14] introduced the ML estimation method for bivariate distributions based on copula. The basis consists of constructing the log-likelihood function as
where
and
are the CDFs of
X and
Y, and
and
are their respective PDFs, and
refers to the copula density. The ML estimates (MLEs) of the involved parameters are obtained by maximizing this function with respect to these parameters.
Under the setting of the FGMBHLD, we have
where
and
.
The MLEs of the parameters
,
,
,
and
, say
,
,
,
, and
, are those maximizing this function. They can be obtained by differentiation. To be more precise, by differentiating the log-likelihood with respect to the distribution parameters, we obtain
and
where
and
By setting the above first partial derivatives of to zero, we obtain and . Since we cannot obtain a closed form for these estimates, a numerical method must be used.
8. Application: Household Financial Affordability in KSA 2018
In this section, we introduce a real application of the stress–strength model in an economic data setting, where
X and
Y represent household income and consumption, respectively. Here,
is a household’s financial affordability. We use the data from the household income and expenditure survey of KSA 2018. The survey period was from 28 February 2017 to 31 March 2018 in each month. In this study, we are interested in studying the behavior of
R when
X represents the average household monthly income by administrative region for Saudi households and
Y represents the average household monthly consumption expenditure by administrative region for Saudi households, in order to measure the financial affordability for Saudi households by administrative region in 2018. The data are shown in
Table 2.
Table 3 presents the descriptive statistics for the data.
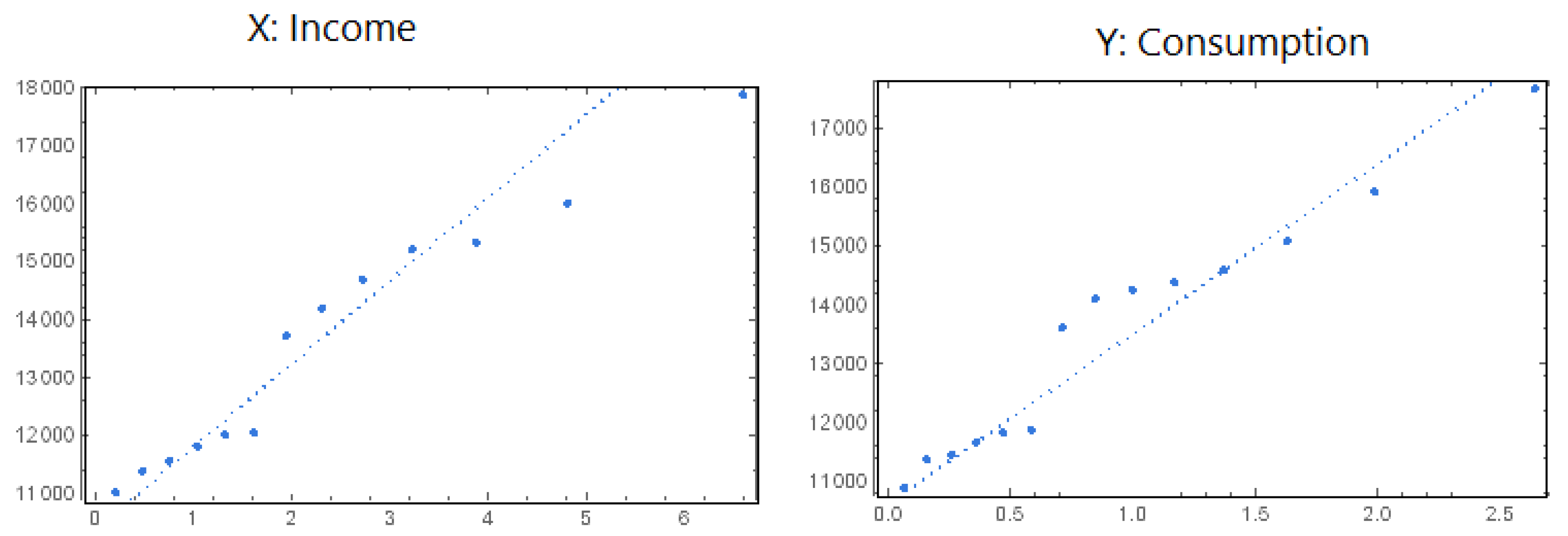
To achieve our aim, we demonstrate the practicability of our proposed model. The Anderson–Darling (AD) goodness of fit statistic value is used to confirm that the GHLD is suitable for the income and consumption data; the corresponding
p-values are almost equal to 1. Moreover, the quantile–quantile (Q–Q) plot is used to confirm this statement, as shown in
Figure 2.
Now, we evaluate in the following two cases:
Case 1: If X and Y are independent with X following the GHLD and Y following the GHLD, and the dependent parameter is set as 0;
Case 2: If X and Y are dependent with , following the FGMBGHLD.
We calculate, in both cases, the MLEs of the distribution parameters and
R, as well as the ACI and ACL. The results are shown in
Table 4.
From
Table 4, we can conclude that:
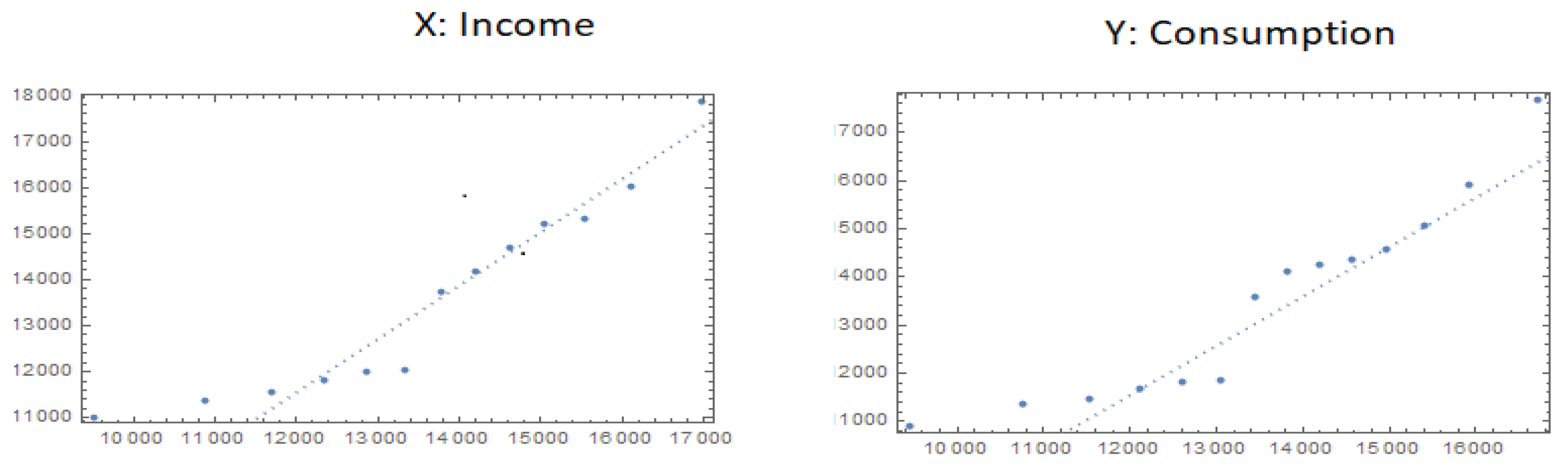
- 1.
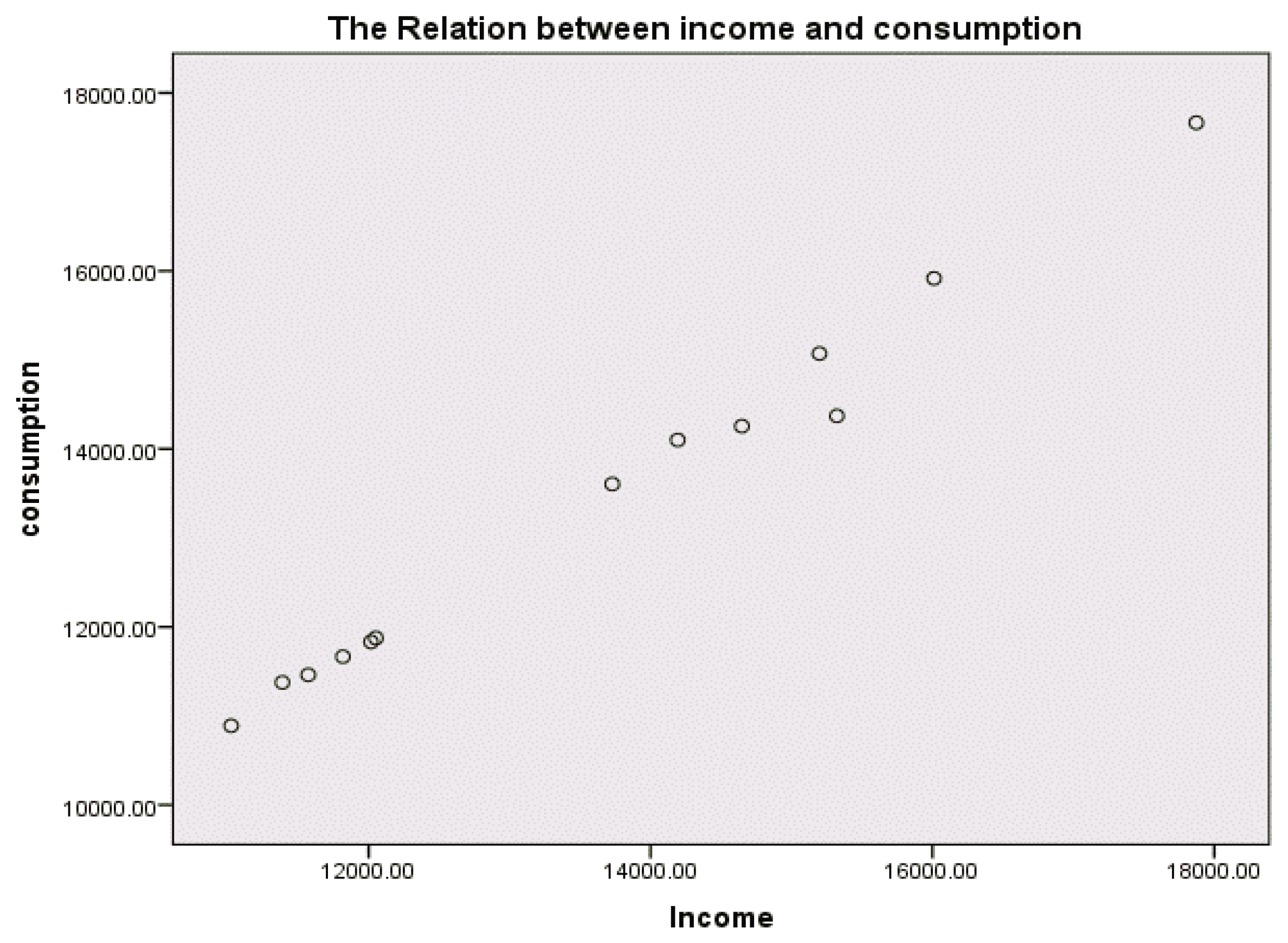
Since
is estimated as
, and is therefore positive, then the relation between
X and
Y is positive, as we see in
Figure 3.
- 2.
The measure of affordability when X and Y are dependent is less than when X and Y are independent, so the case of dependent variables is more realistic.
Figure 3.
The scatter plot for the income and consumption of KSA, year 2018.
Figure 3.
The scatter plot for the income and consumption of KSA, year 2018.
Finally,
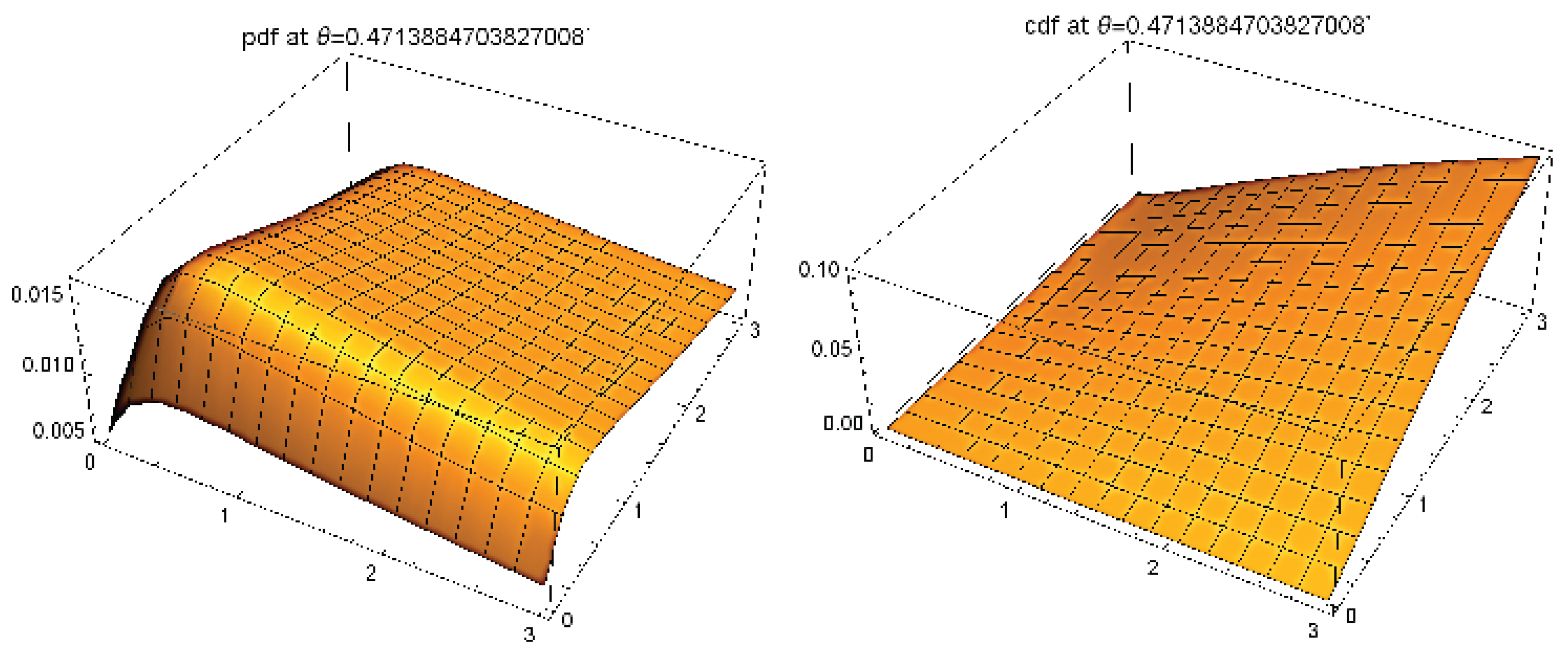
Figure 4 shows the (estimated) PDF and CDF of the FGMGBHLD with the estimated parameters from the considered data.
It can be noted that the PDF seems unimodal (bump effect) with a long two-dimensional tail. With the FGMBGHLD, the equation behind the calculated PDF and CDF can be employed for further modeling.
To conclude this section, in order to show the performance of our new distribution on KSA data, we compare it with the bivariate Weibull distribution (BWD) as presented in Almetwally et al. (2020) [
6]. First, we use the goodness of fit test and Q–Q plot to show that the BWD is a good fit to the KSA data. From the AD goodness of fit test, we find that the
p-value equals
and
for the two considered data sets, respectively. As a result, the BWD fits the KSA data well.
Figure 5 illustrates this conclusion.
Now, we repeat our application but replace our proposed distribution by the BWD.
Table 5 shows the result of the MLEs,
R, ACIs, and ACLs of the distribution parameters and stress–strength model in the following two cases:
Case 1: If X and Y are independent with X following the and Y following the ;
Case 2: If X and Y are dependent with , following the BWD.
Table 5.
The MLEs, ACIs, and ACLs of the BWD parameters for the income and consumption of KSA, year 2018.
Table 5.
The MLEs, ACIs, and ACLs of the BWD parameters for the income and consumption of KSA, year 2018.
| Case | MLE | MLE for R | ACI | ACL |
|---|
| Case 1 |
| | (0.4631, 0.6461) | 0.1820 |
| Case 2 |
| | (0.3456, 0.6058) | 0.2602 |
From the ACL viewpoint, we can compare the performance of our distribution and the BWD on the KSA data. Thus, from
Table 4 and
Table 5, we observe that the ACLs for our proposed distribution are lower than those of the BWD for both cases.
We complete this result by using the AD test for copula-based distributions as described in Genest et al. (2013) [
18].
Table 6 shows the
p-values of this AD test for our distribution and the BWD (dependent case for both).
The lower p-value is obtained for the FGMBGHLD distribution. Based on the results above, we can confirm that the proposed distribution is more suitable than the BWD for the considered KSA data.
9. Conclusions
In this paper, we introduced the bivariate distribution using the FGM copula approach, abbreviated as FGMBGHLD. We studied some of its statistical properties, such as the PDF, CDF, product moments, moment generating function, reliability function, and hazard rate function. In a multivariate statistical setting (and bivariate in particular), it is well known that the maximum likelihood estimation method gives unique estimates (under some regularity conditions) and guarantees their asymptotic performance from the unbiased and normality viewpoints. For these reasons, we developed it for the FGMBGHLD. We also applied the FGMBGHLD in a real-life data analysis scenario. We investigated the stress–strength model represented by
R when the stress and strength variables are dependent and have the FGMBGHLD as a joint distribution. A simulated study was performed to study the behavior of the maximum likelihood estimate of
R. Confidence intervals were constructed using two different techniques. Finally, we provided a real application of the considered (dependent) stress–strength model when
X and
Y measure the household financial affordability in KSA 2018 for Saudi households by administrative region. The obtained results are quite good and competitive with those of a valuable competitor (the bivariate Weibull distribution as introduced by [
6]). Research perspectives include the application of the FGMBGHLD to more different bivariate data types, its multivariate version, and the development of regression model types.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



