
Evaluation of Machine Learning Algorithms for Early Diagnosis of Deep Venous Thrombosis

 , , ,
, , ,  , and
, and 
Abstract
:1. Introduction
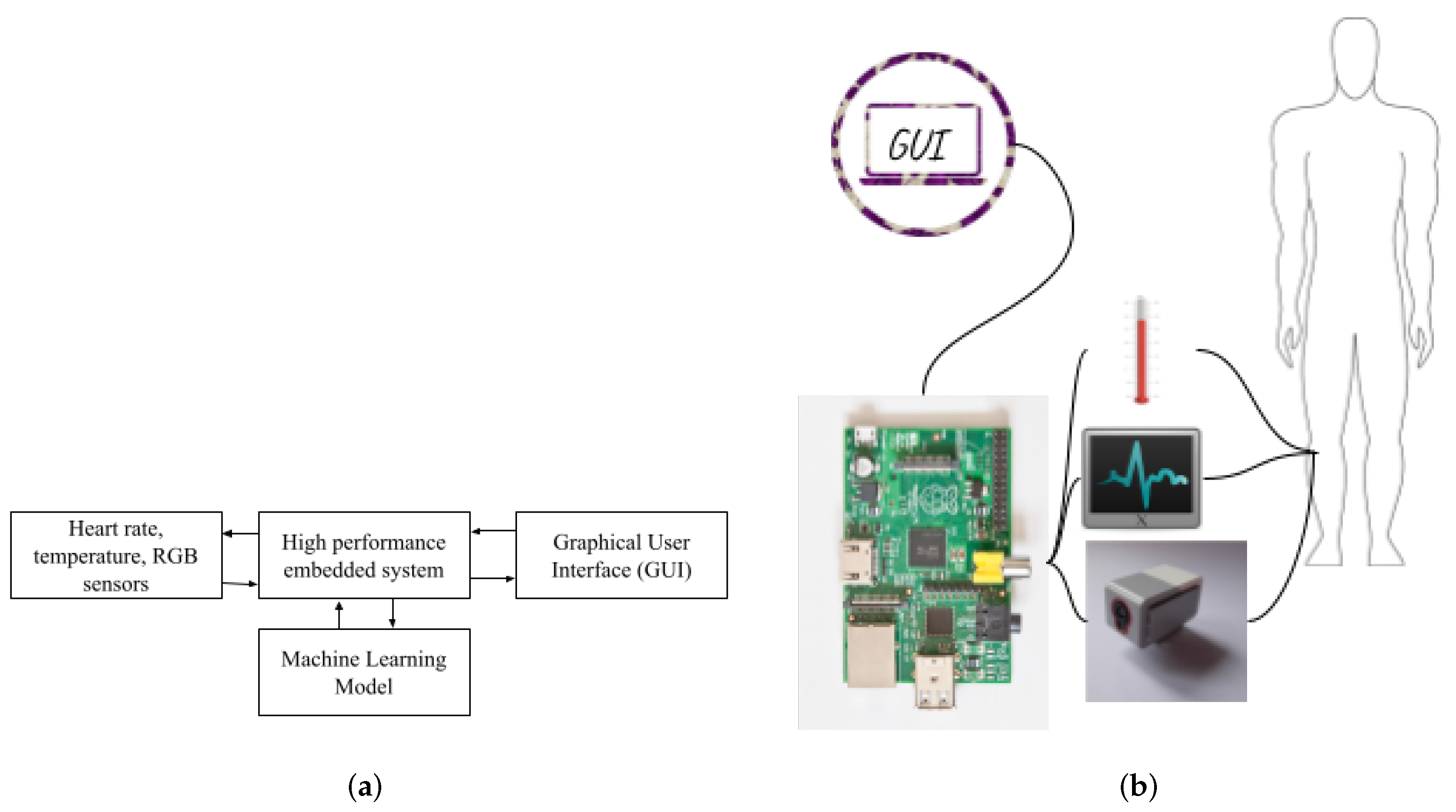
2. Materials and Methods
2.1. Machine Learning Algorithm Training
2.2. Pre-Processing Data
2.3. Hyperparameters of the ML Models
3. Results
Usage Scenario
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yang, M.; Tan, T. Formation of Thrombosis and Its Potential Diagnosis and Treatment with Optoacoustic Technology. In Proceedings of the Third International Conference on Medical and Health Informatics 2019 (ICMHI 2019), Xiamen, China, 17–19 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, K.; Chen, J.; Zhang, K.; Wang, S.; Li, X. A Diagnostic Prediction Model of Acute Symptomatic Portal Vein Thrombosis. Ann. Vasc. Surg. 2019, 61, 394–399. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Byyny, R.; Rice, C.; Faragher, J.; Nordenholz, K.; Haukoos, J.; Liao, M.; Kendall, J. Test Characteristics of Emergency Physician-Performed Limited Compression Ultrasound for Lower-Extremity Deep Vein Thrombosis. J. Emerg. Med. 2016, 51, 684–690. [Google Scholar] [CrossRef] [PubMed]
- Moore, R.D.; Pryce, W.I.J.; Todd, J.M. The use of the ultrasonic Doppler test in the detection of deep vein thrombosis. Phys. Med. Biol. 1973, 18, 142–143. [Google Scholar] [CrossRef]
- Penco, S.; Grossi, E.; Cheng, S.; Intraligi, M.; Maurelli, G.; Patrosso, M.; Marocchi, A.; Buscema, M. Assessment of Genetic Polymorphism Role in Venous Thrombosis Through Artificial Neural Networks. Ann. Hum. Genet. 2005, 69, 693–706. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Y.Q.; Liu, S.H.; Hong, X.Y.; Sun, X.F.; Shi, J.H. Comparing different venous thromboembolism risk assessment machine learning models in Chinese patients. J. Eval. Clin. Pract. 2019, 26, 26–34. [Google Scholar] [CrossRef]
- Luo, L.; Kou, R.; Feng, Y.; Xiang, J.; Zhu, W. Cost-Effective Machine Learning Based Clinical Pre-Test Probability Strategy for DVT Diagnosis in Neurological Intensive Care Unit. Clin. Appl. Thromb. 2021, 27, 10760296211008650. [Google Scholar] [CrossRef]
- Ferroni, P.; Zanzotto, F.M.; Scarpato, N.; Riondino, S.; Guadagni, F.; Roselli, M. Validation of a Machine Learning Approach for Venous Thromboembolism Risk Prediction in Oncology. Dis. Markers 2017, 2017, 8781379. [Google Scholar] [CrossRef] [Green Version]
- Riondino, S.; Ferroni, P.; Zanzotto, F.M.; Roselli, M.; Guadagni, F. Predicting VTE in cancer patients: Candidate biomarkers and risk assessment models. Cancers 2019, 11, 95. [Google Scholar] [CrossRef] [Green Version]
- Fong-Mata, M.; Garcia-Guerrero, E.; Mejia-Medina, D.; Lopez-Bonilla, O.; Villarreal-Gomez, L.; Zamora-Arellano, F.; Lopez-Mancilla, D.; Inzunza-Gonzalez, E. An Artificial Neural Network Approach and a Data Augmentation Algorithm to Systematize the Diagnosis of Deep-Vein Thrombosis by Using Wells’ Criteria. Electronics 2020, 9, 1810. [Google Scholar] [CrossRef]
- Segal, J.B.; Eng, J.; Tamariz, L.J.; Bass, E.B. Review of the Evidence on Diagnosis of Deep Venous Thrombosis and Pulmonary Embolism. Ann. Fam. Med. 2007, 5, 63. [Google Scholar] [CrossRef] [Green Version]
- Smyrnakis, E.; Symintiridou, D.; Andreou, M.; Dandoulakis, M.; Theodoropoulos, E.; Kokkali, S.; Manolaki, C.; Papageorgiou, D.I.; Birtsou, C.; Paganas, A.; et al. Primary care professionals’ experiences during the first wave of the COVID-19 pandemic in Greece: A qualitative study. BMC Fam. Pract. 2021, 22, 174. [Google Scholar] [CrossRef]
- da Silva, L.G.R.; da Silva Pinto, A.W.; de Queiroz, W.E.; Coelho, C.C.; Blatt, C.R.; Oliveira, M.G.; de Lima Pimentel, A.C.; Elseviers, M.; Baldoni, A.O. Deprescribing clonazepam in primary care older patients: A feasibility study. Int. J. Clin. Pharm. 2022. [Google Scholar] [CrossRef] [PubMed]
- Győrffy, Z.; Békási, S.; Döbrössy, B.; Bognár, V.K.; Radó, N.; Morva, E.; Zsigri, S.; Tari, P.; Girasek, E. Exploratory attitude survey of homeless persons regarding telecare services in shelters providing mid- and long-term accommodation: The importance of trust. PLoS ONE 2022, 17, e0261145. [Google Scholar] [CrossRef] [PubMed]
- Wells, P. Predictive analytics by deep machine learning: A call for next-gen tools to improve health care. Res. Pract. Thromb. Haemost. 2020, 4, 181–182. [Google Scholar] [CrossRef] [PubMed]
- Yokomichi, A.; Rodrigues, V.; Moroz, A.; Bertanha, M.; Ribeiro, S.; Defune, E.; Moraes, M. Detection of Factor VIII and D-dimer biomarkers for venous thromboembolism diagnosis using electrochemistry immunosensor. Talanta 2020, 219, 121241. [Google Scholar] [CrossRef]
- Kacmaz, S.; Ercelebi, E.; Zengin, S.; Cindoruk, S. The Use of Infrared Thermal Imaging in the Diagnosis of Deep Vein Thrombosis. Infrared Phys. Technol. 2017, 86, 120–129. [Google Scholar] [CrossRef]
- Tanno, R.; Makropoulos, A.; Arslan, S.; Oktay, O.; Mischkewitz, S.; Noor, F.; Oppenheimer, J.; Mandegaran, R.; Kainz, B.; Heinrich, M. AutoDVT: Joint Real-Time Classification for Vein Compressibility Analysis in Deep Vein Thrombosis Ultrasound Diagnostics. In Proceedings of the 21st International Conference, Granada, Spain, 16–20 September 2018; Part II. pp. 905–912. [Google Scholar] [CrossRef]
- Kainz, B.; Heinrich, M.P.; Makropoulos, A.; Oppenheimer, J.; Mandegaran, R.; Sankar, S.; Deane, C.; Mischkewitz, S.; Al-Noor, F.; Rawdin, A.C.; et al. Non-invasive diagnosis of deep vein thrombosis from ultrasound imaging with machine learning. NPJ Digit. Med. 2021, 4, 137. [Google Scholar] [CrossRef]
- Lewiss, R.E.; Kaban, N.L.; Turandot, S. Point-of-Care Ultrasound for a Deep Venous Thrombosis. Glob. Heart 2013, 8, 329–333. [Google Scholar] [CrossRef] [Green Version]
- Ly-Pen, D.; Penedo-Alonso, R.; Sánchez-Pérez, M. Comparison of the Accuracy of Emergency Department–Performed Point-of-Care Ultrasound in the Diagnosis of Lower-Extremity Deep Vein Thrombosis. J. Emerg. Med. 2018, 55, 716–717. [Google Scholar] [CrossRef]
- Huang, C.; Tian, J.; Yuan, C.; Zeng, P.; He, X.; Chen, H.; Huang, Y.; Huang, B. Fully Automated Segmentation of Lower Extremity Deep Vein Thrombosis Using Convolutional Neural Network. BioMed Res. Int. 2019, 2019, 3401683. [Google Scholar] [CrossRef] [Green Version]
- Willan, J.; Katz, H.; Keeling, D. The use of artificial neural network analysis can improve the risk-stratification of patients presenting with suspected deep vein thrombosis. Br. J. Haematol. 2019, 185, 289–296. [Google Scholar] [CrossRef] [PubMed]
- Fong-Mata, M.B.; Inzunza-Gonzalez, E.; Garcia-Guerrero, E.; Mejia-Medina, D.; Morales Contreras, O.; Gomez-Roa, A. Trombosis venosa profunda en extremidades inferiores: Revisión de las técnicas de diagnóstico actuales y su simbiosis con el aprendizaje automático para un diagnóstico oportuno. Rev. Cienc. Tecnol. 2020, 3, 23–34. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Ehteshami Bejnordi, B.; Adiyoso Setio, A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.W.M.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Agharezaei, L.; Agharezaei, Z.; Nemati, A.; Bahaadinbeigy, K.; Keynia, F.; Baneshi, M.; Iranpour, A.; Agharezaei, M. The Prediction of the Risk Level of Pulmonary Embolism and Deep Vein Thrombosis through Artificial Neural Network. Acta Inform. Med. 2016, 24, 354. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sukperm, A.; Rojnuckarin, P.; Akkawat, B.; Sa-Ing, V. Automatic Diagnosis of Venous Thromboembolism Risk based on Machine Learning. In Proceedings of the 2021 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Toronto, ON, Canada, 21–24 April 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, H.; Yuan, H.; Wang, Y.; Huang, W.; Xue, H.; Zhang, X. Prediction of venous thromboembolism with machine learning techniques in young-middle-aged inpatients. Sci. Rep. 2021, 11, 12868. [Google Scholar] [CrossRef]
- Ferroni, P.; Zanzotto, F.M.; Scarpato, N.; Riondino, S.; Nanni, U.; Roselli, M.; Guadagni, F. Risk Assessment for Venous Thromboembolism in Chemotherapy-Treated Ambulatory Cancer Patients: A Machine Learning Approach. Med. Decis. Mak. 2016, 37, 234–242. [Google Scholar] [CrossRef]
- Egwuche, O.S.; Ganiyu, M.; Ibiyomi, M.A. A survey of mobile edge computing in developing countries: Challenges and prospects. J. Phys. Conf. Ser. 2021, 2034, 012004. [Google Scholar] [CrossRef]
- Liu, L.; Chen, L.; Xu, S.; Xu, Y.; Shi, C. Design and implementation of intelligent monitoring terminal for distribution room based on edge computing. Energy Rep. 2021, 7, 1131–1138. [Google Scholar] [CrossRef]
- Andrawes, A.; Nordin, R.; Albataineh, Z.; Alsharif, M.H. Sustainable delay minimization strategy for mobile edge computing offloading under different network scenarios. Sustainability 2021, 13, 12112. [Google Scholar] [CrossRef]
- Teng, Y.; Cui, J.; Jiang, W. Research on application of edge computing in real-time environmental monitoring system. J. Phys. Conf. Ser. 2021, 2010, 012157. [Google Scholar] [CrossRef]
- Alessio, K.; Tischer, B.; Voss, M.; Teixeira, I.; Brendler, B.; Duarte, F.; Helfer, G.; Costa, A.; Barin, J. Open source, low-cost device for thermometric titration with non-contact temperature measurement. Talanta 2020, 216, 120975. [Google Scholar] [CrossRef] [PubMed]
- Nykvist, C.; Larsson, M.; Sodhro, A.; Gurtov, A. A lightweight portable intrusion detection communication system for auditing applications. Int. J. Commun. Syst. 2020, 33, e4327. [Google Scholar] [CrossRef]
- Zamora-Arellano, F.; López-Bonilla, O.R.; García-Guerrero, E.E.; Olguín-Tiznado, J.E.; Inzunza-González, E.; López-Mancilla, D.; Tlelo-Cuautle, E. Development of a Portable, Reliable and Low-Cost Electrical Impedance Tomography System Using an Embedded System. Electronics 2021, 10, 15. [Google Scholar] [CrossRef]
- Gautam, A.; Kumar, A.; Kinjalk, K.; Thangaraj, J.; Priye, V. A Low Cost FBG Based Online Weight Monitoring System. IEEE Sens. J. 2020, 20, 4207–4214. [Google Scholar] [CrossRef]
- Nirmala, M.; Malarvizhi, K. Internet of things based solar powered truck. Test Eng. Manag. 2020, 83, 9358–9365. [Google Scholar]
- Aguirre-Castro, O.; Inzunza-González, E.; García-Guerrero, E.; Tlelo-Cuautle, E.; López-Bonilla, O.; Olguín-Tiznado, J.; Cárdenas-Valdez, J. Design and Construction of an ROV for Underwater Exploration. Sensors 2019, 19, 5387. [Google Scholar] [CrossRef] [Green Version]
- Dhatri, M.P.; Shivram, R. Development of a Functional Testing System for Test Automation and Statistical Analysis of the behavior of health care device used to treat Deep Vein Thrombosis. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; pp. 1715–1719. [Google Scholar] [CrossRef]
- Cerrada, M.; Trujillo, L.; Hernández, D.E.; Correa Zevallos, H.A.; Macancela, J.C.; Cabrera, D.; Vinicio Sánchez, R. AutoML for Feature Selection and Model Tuning Applied to Fault Severity Diagnosis in Spur Gearboxes. Math. Comput. Appl. 2022, 27, 6. [Google Scholar] [CrossRef]
- Enríquez Zárate, J.; Gómez López, M.d.l.A.; Carmona Troyo, J.A.; Trujillo, L. Analysis and Detection of Erosion in Wind Turbine Blades. Math. Comput. Appl. 2022, 27, 5. [Google Scholar] [CrossRef]
- Esqueda-Elizondo, J.J.; Juarez-Ramirez, R.; Lopez-Bonilla, O.R.; Garcia-Guerrero, E.E.; Galindo-Aldana, G.M.; Jimenez-Beristain, L.; Serrano-Trujillo, A.; Tlelo-Cuautle, E.; Inzunza-Gonzalez, E. Attention Measurement of an Autism Spectrum Disorder User Using EEG Signals: A Case Study. Math. Comput. Appl. 2022, 27, 21. [Google Scholar] [CrossRef]
- Nwosisi, C.; Sung-Hyuk, C.; Yoo, J.A.; Tappert, C.C.; Lipsitz, E. Constructing Binary Decision Trees for Predicting Deep Venous Thrombosis. In Proceedings of the 2010 2nd International Conference on Software Technology and Engineering, San Juan, PR, USA, 3–5 October 2010; Volume 1, pp. V1-121–V1-124. [Google Scholar] [CrossRef]
- Nafee, T.; Gibson, C.M.; Travis, R.; Yee, M.K.; Kerneis, M.; Chi, G.; AlKhalfan, F.; Hernandez, A.F.; Hull, R.D.; Cohen, A.T.; et al. Machine learning to predict venous thrombosis in acutely ill medical patients. Res. Pract. Thromb. Haemost. 2020, 4, 230–237. [Google Scholar] [CrossRef] [Green Version]
- Ryan, L.; Mataraso, S.; Siefkas, A.; Pellegrini, E.; Barnes, G.; Green-Saxena, A.; Hoffman, J.; Calvert, J.; Das, R. A Machine Learning Approach to Predict Deep Venous Thrombosis Among Hospitalized Patients. Clin. Appl. Thromb. 2021, 27, 1076029621991185. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECMLPKDD 2013), Prague, Czech Republic, 23–27 September 2013; pp. 108–122. [Google Scholar]
- Liu, Z.; Cao, Y.; Li, Y.; Xiao, X.; Qiu, Q.; Yang, M.; Zhao, Y.; Cui, L. Automatic diagnosis of fungal keratitis using data augmentation and image fusion with deep convolutional neural network. Comput. Methods Programs Biomed. 2020, 187, 105019. [Google Scholar] [CrossRef] [PubMed]
- Zuluaga-Gomez, J.; Al Masry, Z.; Benaggoune, K.; Meraghni, S.; Zerhouni, N. A CNN-based methodology for breast cancer diagnosis using thermal images. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2020, 9, 131–145. [Google Scholar] [CrossRef]
- de Souza, L.A.; Passos, L.A.; Mendel, R.; Ebigbo, A.; Probst, A.; Messmann, H.; Palm, C.; Papa, J.P. Assisting Barrett’s esophagus identification using endoscopic data augmentation based on Generative Adversarial Networks. Comput. Biol. Med. 2020, 126, 104029. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Li, J.; Guo, J.; Chen, Y.; Yi, Z.; Zhong, J. Diagnosis of Diabetic Retinopathy Using Deep Neural Networks. IEEE Access 2019, 7, 3360–3370. [Google Scholar] [CrossRef]
- Wells, P.S.; Anderson, D.R.; Bormanis, J.; Guy, F.; Mitchell, M.; Gray, L.; Clement, C.; Robinson, K.S.; Lewandowski, B. Value of assessment of pretest probability of deep-vein thrombosis in clinical management. Lancet 1997, 350, 1795–1798. [Google Scholar] [CrossRef]
- Wells, P.S.; Owen, C.; Doucette, S.; Fergusson, D.; Tran, H. Does this patient have deep vein thrombosis? JAMA 2006, 295, 199–207. [Google Scholar] [CrossRef]
- Modi, S.; Deisler, R.; Gozel, K.; Reicks, P.; Irwin, E.; Brunsvold, M.; Banton, K.; Beilman, G.J. Wells criteria for DVT is a reliable clinical tool to assess the risk of deep venous thrombosis in trauma patients. World J. Emerg. Surg. 2016, 11, 24. [Google Scholar] [CrossRef] [Green Version]
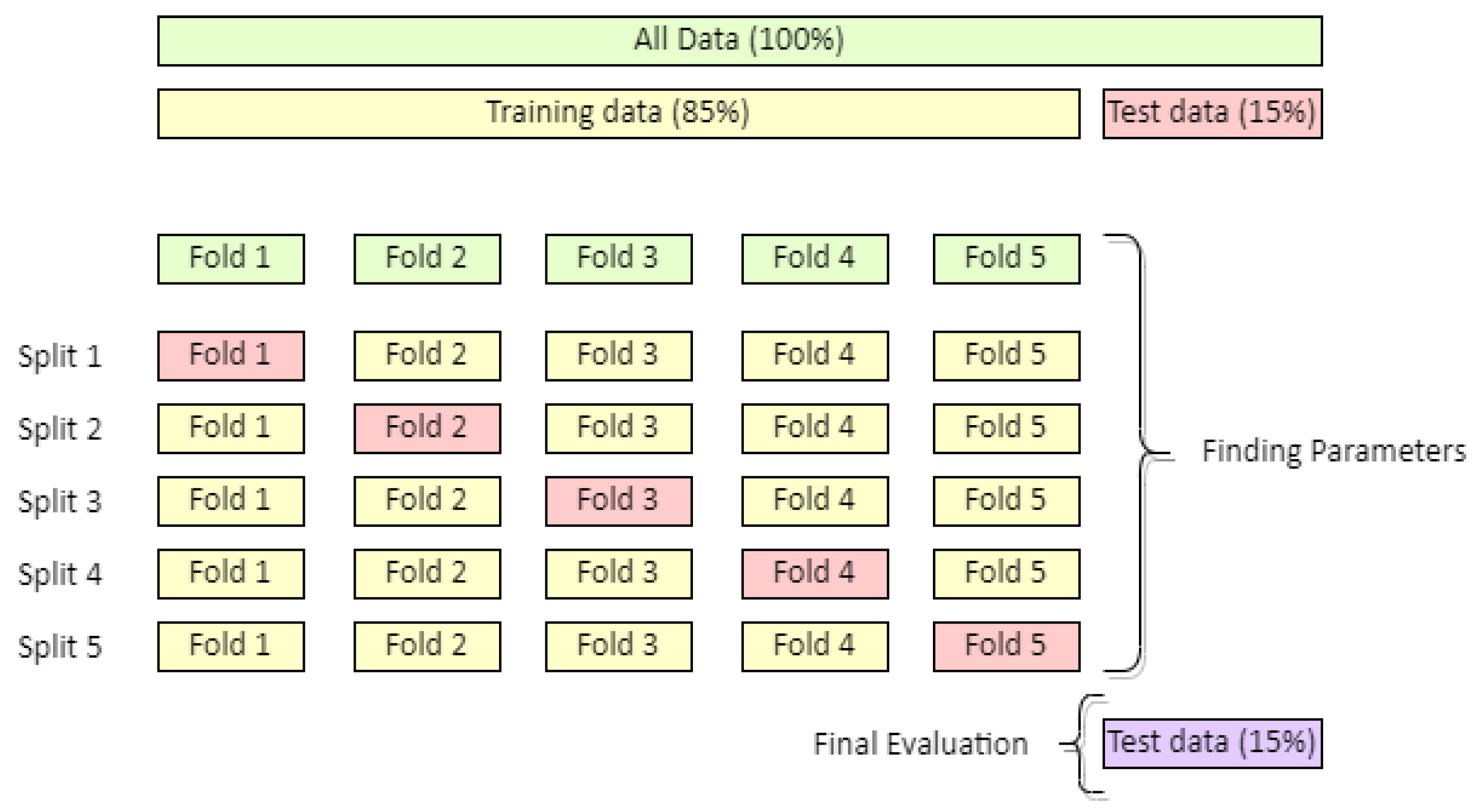
- Jung, Y. Multiple predicting K-fold cross-validation for model selection. J. Nonparametr. Stat. 2018, 30, 197–215. [Google Scholar] [CrossRef]
- Pano-Azucena, A.; Tlelo-Cuautle, E.; Tan, S.D.; Ovilla-Martinez, B.; De la Fraga, L. FPGA-Based Implementation of a Multilayer Perceptron Suitable for Chaotic Time Series Prediction. Technologies 2018, 6, 90. [Google Scholar] [CrossRef] [Green Version]
- Kaufmann, M. Practical Neural Networks Recipes in C++; Elsevier: Boston, MA, USA, 1993; p. 493. [Google Scholar] [CrossRef]
- Vávra, J.; Hromada, M.; Lukáš, L.; Dworzecki, J. Adaptive anomaly detection system based on machine learning algorithms in an industrial control environment. Int. J. Crit. Infrastruct. Prot. 2021, 34, 100446. [Google Scholar] [CrossRef]
- Sadrawi, M.; Sun, W.Z.; Ma, M.M.; Yeh, Y.T.; Abbod, M.; Shieh, J.S. Ensemble genetic fuzzy neuro model applied for the emergency medical service via unbalanced data evaluation. Symmetry 2018, 10, 71. [Google Scholar] [CrossRef] [Green Version]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In Proceedings of the 19th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; pp. 1015–1021. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | Raspberry Pi 4 | PC (Laptop) |
|---|---|---|
| Central Processing Unit (CPU) | Broadcom BCM2711 Quad Core 1.5 GHz | AMD Ryzen 7 4800H 2.9 GHz |
| Graphics Processing Unit (GPU) | Video Core VI 500 MHz | Nvidia GeForce GTX 1660ti |
| Random Access Memory (RAM) | 4 GB DDR4 | 8 GB DDR4 |
| Networking | WiFi, Ethernet, Bluetooth | WiFi, Ethernet, Bluetooth |
| Storage | 32 GB SD-Card | 512 GB SSD |
| Operating system | Raspbian | Windows 10 |
| Operating Voltage | 5 V | 19.5 V |
| Energy consumption | 3–7 Wh | 200 Wh |
| Weight | 46 g | 2.37 Kg |
| Cost (USD) | $55.00 | $1599.00 |
| Clinical Feature | Score |
|---|---|
| Lower extremity paralysis, paresis, or recent cast immobilization | 1 |
| Deep vein thrombosis has previously been observed | 1 |
| Active cancer (patients who are undergoing cancer therapy or who have been diagnosed with cancer within the last 6 months) | 1 |
| Pitting edema limited to the affected leg | 1 |
| Recently hospitalized for three or more days, or recently had major surgery Anesthesia is required for a total of 12 weeks | 1 |
| Tenderness in a specific area of the deep venous system’s distribution | 1 |
| Skinny veins on each sides (non-varicose) | 1 |
| The whole leg is swollen | 1 |
| Calf enlarged by at least 3 cm in comparison to the asymptomatic (ten centimeters below the tibial tuberosity) | 1 |
| Deep vein thrombosis is the most probable diagnosis; however, other possibilities exist. | −2 |
| When a patient has symptoms in both legs, the leg with the most severe symptoms is utilized. |
| Age (Years Old) | Life Stage | Numerical Value |
|---|---|---|
| 85–120 | Advanced old age | 9 |
| 70–84 | Intermediate old age | 8 |
| 60–69 | Initial old age | 7 |
| 50–59 | Mature adults | 6 |
| 40–49 | Average adults | 5 |
| 21–39 | Young adults | 4 |
| 13–20 | Youth | 3 |
| 6–12 | Middle childhood | 2 |
| 0–5 | Childhood | 1 |
| Input Layer with 11 Predictors | Hidden Layer | Output Layer |
|---|---|---|
| Gender, age, cancer, surgery, immobilization, tenderness, leg swollen, calf swollen, edema, superficial veins, previous DVT | 32–64–32–16 | DVT diagnosis |
| Hyperparameter | SVM | KNN | Decision Tree | Extra Trees | Random Forest |
|---|---|---|---|---|---|
| C | 1.0 | N/A | N/A | N/A | N/A |
| Kernel | “linear” | N/A | N/A | N/A | N/A |
| Degree | 3 | N/A | N/A | N/A | N/A |
| Gamma | “scale” | N/A | N/A | N/A | N/A |
| Random State | 42 | 42 | 42 | 42 | 42 |
| N Neighbors | N/A | 50 | N/A | N/A | N/A |
| Weights | N/A | “Distance” | N/A | N/A | N/A |
| Algorithm | SVM | “Ball tree” | DT | ET | RF |
| Criterion | N/A | N/A | “Entropy” | “gini” | “gini” |
| Splitter | N/A | N/A | “Random” | N/A | N/A |
| Min Samples Split | N/A | N/A | 2 | 2 | 2 |
| Min Samples Leaf | N/A | N/A | 1 | 1 | 1 |
| Max Features | N/A | N/A | “auto” | “auto” | “auto” |
| Max Depth | N/A | N/A | 80 | 80 | N/A |
| N Estimators | N/A | N/A | N/A | 200 | 480 |
| Bootstrap | N/A | N/A | N/A | N/A | True |
| Predicted Diagnostic | ||
|---|---|---|
| True Diagnostic | Negative DVT | Positive DVT |
| Negative DVT | True Negative | False Positive |
| Positive DVT | False Negative | True Positive |
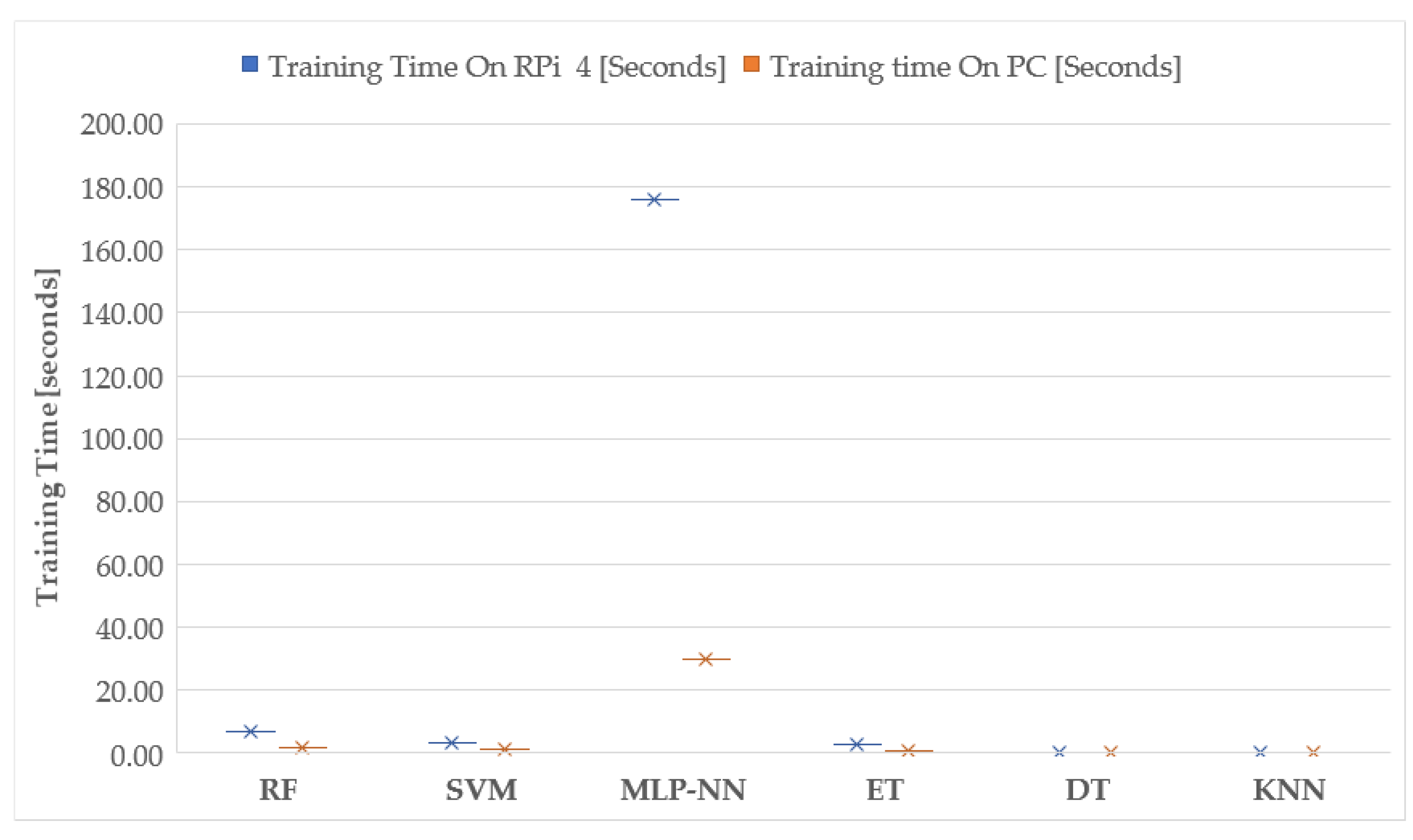
| Machine Learning Algorithm on PC | ||||||
| Scoring Parameters | SVM | Decision Trees | Extra Trees | RF | MLP-NN | KNN |
| True Positive | 265 | 262 | 268 | 274 | 274 | 292 |
| True Negative | 1017 | 1061 | 1060 | 1064 | 1067 | 1064 |
| False Positive | 117 | 73 | 74 | 70 | 67 | 70 |
| False Negative | 101 | 104 | 98 | 92 | 92 | 74 |
| Accuracy | 0.8546 | 0.8820 | 0.8853 | 0.8920 | 0.8940 | 0.9040 |
| F1 Score | 0.7085 | 0.7475 | 0.7570 | 0.7718 | 0.7751 | 0.8021 |
| Specificity/Precision | 0.6937 | 0.7820 | 0.7836 | 0.7965 | 0.8035 | 0.8066 |
| Sensitivity/Recall | 0.7240 | 0.7158 | 0.7322 | 0.7486 | 0.7486 | 0.7978 |
| Machine Learning Algorithm on RPi 4 | ||||||
| Scoring Parameters | SVM | Decision Trees | Extra Trees | RF | MLP-NN | KNN |
| True Positive | 265 | 262 | 268 | 274 | 274 | 292 |
| True Negative | 1017 | 1061 | 1060 | 1064 | 1067 | 1064 |
| False Positive | 117 | 73 | 74 | 70 | 67 | 70 |
| False Negative | 101 | 104 | 98 | 92 | 92 | 74 |
| Accuracy | 0.8546 | 0.8820 | 0.8853 | 0.8920 | 0.8940 | 0.9040 |
| F1 Score | 0.7085 | 0.7475 | 0.7570 | 0.7718 | 0.7751 | 0.8021 |
| Specificity/Precision | 0.6937 | 0.7820 | 0.7836 | 0.7965 | 0.8035 | 0.8066 |
| Sensitivity/Recall | 0.7240 | 0.7158 | 0.7322 | 0.7486 | 0.7486 | 0.7978 |
| ML Model | K-Fold Cross-Validation with K = 5 | ||||
|---|---|---|---|---|---|
| Accuracy | F1 Score | Specificity/Precision | Sensitivity/Recall | ROC-AUC | |
| SVM | 0.8468 | 0.6906 | 0.6804 | 0.7012 | 0.8589 |
| Decision Trees | 0.8677 | 0.7154 | 0.7528 | 0.6819 | 0.7562 |
| Extra Trees | 0.8710 | 0.7248 | 0.7552 | 0.6969 | 0.8831 |
| RF | 0.8744 | 0.7347 | 0.7576 | 0.7133 | 0.8830 |
| MLP-NN | 0.8632 | 0.7107 | 0.7347 | 0.6887 | 0.7924 |
| KNN | 0.8823 | 0.7586 | 0.7586 | 0.7586 | 0.8906 |
| Performance Metrics on PC | |||||
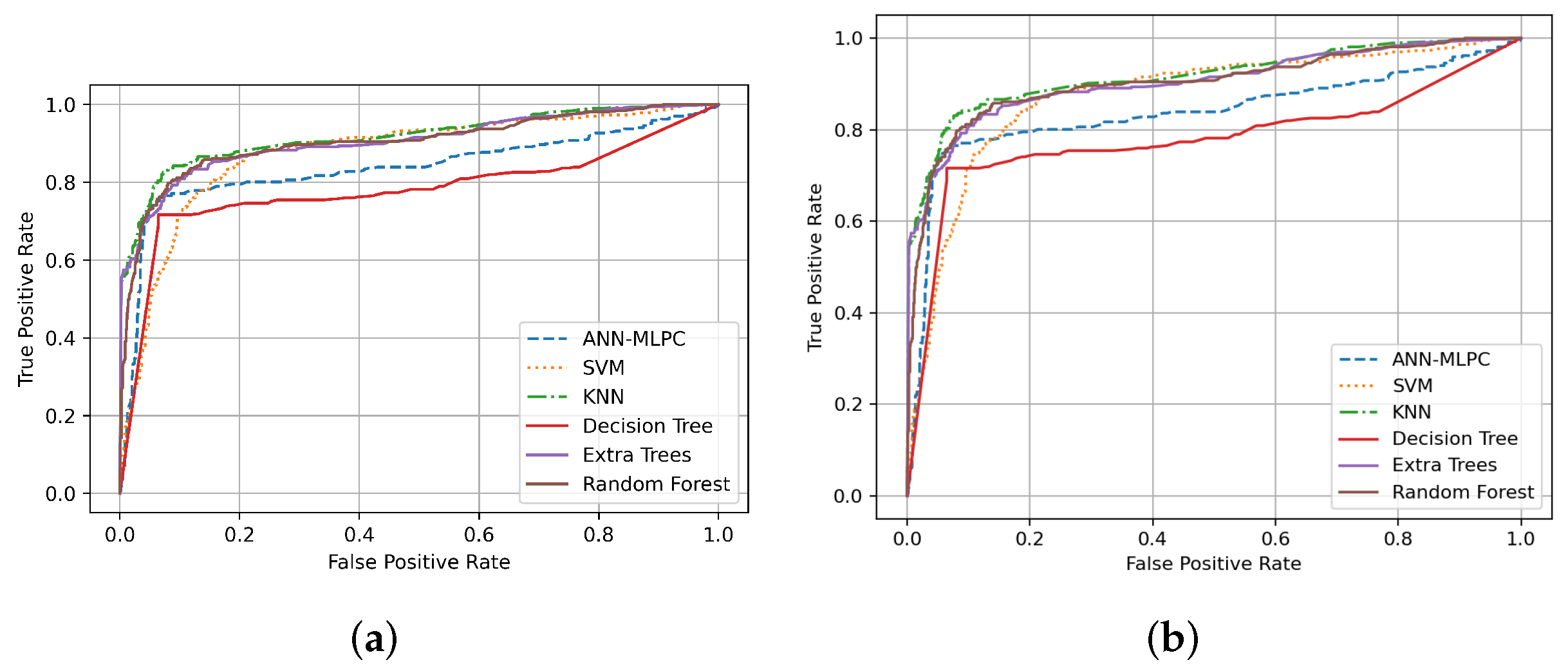
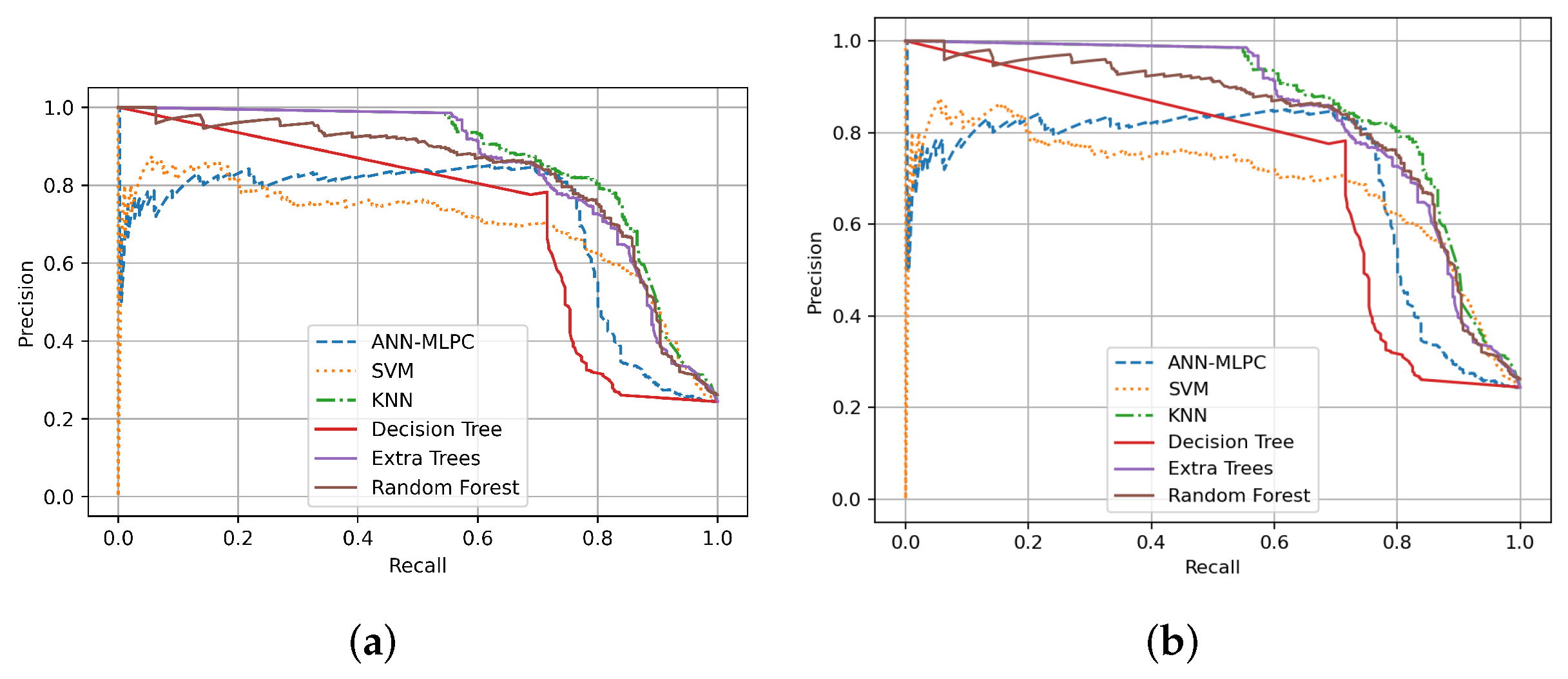
| Machine Learning Algorithm | ROC-AUC | PR-AUC | Cohen’s Kappa Coefficient | Hamming Loss | Matthew’s Correlation Coeficient |
| SVM | 0.8104 | 0.6960 | 0.6118 | 0.1453 | 0.6120 |
| Decision Trees | 0.8257 | 0.6432 | 0.6707 | 0.1180 | 0.6718 |
| Extra Trees | 0.8334 | 0.8461 | 0.6821 | 0.1146 | 0.6828 |
| Random Forest (RF) | 0.8434 | 0.8283 | 0.7011 | 0.1080 | 0.7017 |
| MLP-NN | 0.8447 | 0.7102 | 0.7058 | 0.1060 | 0.7066 |
| KNN | 0.8680 | 0.8619 | 0.7388 | 0.0960 | 0.7388 |
| Performance Metrics on RPi 4 | |||||
| Machine Learning Algorithm | ROC-AUC | PR-AUC | Cohen’s Kappa Coefficient | Hamming Loss | Matthew’s Correlation Coeficient |
| SVM | 0.8104 | 0.6954 | 0.6118 | 0.1453 | 0.6120 |
| Decision Trees | 0.8257 | 0.6432 | 0.6707 | 0.1180 | 0.6718 |
| Extra Trees | 0.8334 | 0.8461 | 0.6821 | 0.1146 | 0.6828 |
| Random Forest (RF) | 0.8434 | 0.8283 | 0.7011 | 0.1080 | 0.7017 |
| MLP-NN | 0.8447 | 0.7102 | 0.7058 | 0.1060 | 0.7066 |
| KNN | 0.8680 | 0.8619 | 0.7388 | 0.0960 | 0.7388 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Contreras-Luján, E.E.; García-Guerrero, E.E.; López-Bonilla, O.R.; Tlelo-Cuautle, E.; López-Mancilla, D.; Inzunza-González, E. Evaluation of Machine Learning Algorithms for Early Diagnosis of Deep Venous Thrombosis. Math. Comput. Appl. 2022, 27, 24. https://doi.org/10.3390/mca27020024
Contreras-Luján EE, García-Guerrero EE, López-Bonilla OR, Tlelo-Cuautle E, López-Mancilla D, Inzunza-González E. Evaluation of Machine Learning Algorithms for Early Diagnosis of Deep Venous Thrombosis. Mathematical and Computational Applications. 2022; 27(2):24. https://doi.org/10.3390/mca27020024
Chicago/Turabian StyleContreras-Luján, Eduardo Enrique, Enrique Efrén García-Guerrero, Oscar Roberto López-Bonilla, Esteban Tlelo-Cuautle, Didier López-Mancilla, and Everardo Inzunza-González. 2022. "Evaluation of Machine Learning Algorithms for Early Diagnosis of Deep Venous Thrombosis" Mathematical and Computational Applications 27, no. 2: 24. https://doi.org/10.3390/mca27020024