1. Introduction
Multiobjective optimization plays an important role in many applications, e.g., in industry, medicine, or engineering. One of the mentioned examples is the minimization of costs with simultaneous quality optimization in production or the minimization of CO2 emission in energy generation and simultaneous cost minimization. These problems lead to multiobjective optimization problems (MOPs), where we want to achieve an optimal compromise with respect to all given objectives at the same time. Normally, the different objectives are contradictory such that there exists an infinite number of optimal compromises. The set of these compromises is called the Pareto set. The goal is to approximate the Pareto set in an efficient way, which turns out to be more expensive than solving a single objective optimization problem.
As multiobjective optimization problems are of great importance, there exist several algorithms to solve them. Among the most popular methods are scalarization methods, which transform MOPs into scalar problems. For example, in the weighted sum method [
1,
2,
3,
4], convex combinations of the original objectives are optimized. Another popular approach is to use non-deterministic methods like evolutionary algorithms, cf., e.g., [
5]. Furthermore, as multiobjective problems are generalizations of scalar problems, some solution methods can be generalized from the scalar to the multiobjective case [
6,
7,
8].
In addition to the classical methods above, there are set-based strategies for the solution of MOPs. Continuation methods [
9,
10,
11] use the fact that the Pareto set is typically (the projection of) a smooth manifold. Subdivision methods [
12,
13,
14,
15] use tools from the area of dynamical systems to generate a covering of the Pareto set via hypercubes. However, especially when the objective functions and their gradients are expensive to evaluate, e.g., as an underlying PDE has to be solved for every evaluation, the computational time of these methods can quickly become very large. In the presence of PDE constraints, surrogate models offer a promising tool to reduce the computational effort significantly [
16]. Examples are dimensional reduction techniques such as the Reduced Basis (RB) Method [
17,
18]. In an offline phase, a low-dimensional surrogate model of the PDE is constructed by using, e.g., the greedy algorithm, cf. [
17]. In the online phase, only the RB model is used to solve the PDE, which saves a lot of computing time.
In this article, we combine an extension of the set-oriented method presented in [
12] based on inexact gradient evaluations of the objective functions with an RB approach and a discrete empirical interpolation method (DEIM) [
19,
20] for semi-linear elliptic PDEs. In order to deal with the inexactness introduced by the surrogate model, we combine the first-order optimality conditions for multiobjective optimization problems with error estimates for the RB-DEIM method and derive an additional condition for the descent direction [
9] to get a tight superset of the Pareto set. This approach allows us to better control the quality of the result by controlling the errors for the objective functions independently. In order to obtain an even tighter superset of the Pareto set, we update these error estimates in our subdivision algorithm after each iteration step.
The article is organized as follows. In
Section 2, we recall the basic concepts of multiobjective optimization problems and review results on descent directions with exact and inexact gradients. Furthermore, we develop a set-oriented method to solve these problems, where only inexact gradient information is utilized. In
Section 3, the PDE-constrained multiobjective optimization problem and the underlying semi-linear PDE are introduced. Subsequently, we show how reduced-order modeling can be applied efficiently. In
Section 4, numerical results concerning both the subdivision and the modified algorithm are presented. Finally, we give a conclusion and discuss possible future work in
Section 5.
4. Numerical Experiments
In this section, we use our algorithm to solve multiobjective optimization problems with PDE constraints and interpret the numerical results. All computations were executed on a computer with a 2.9 GHz Intel Core i7 CPU, 8 GB of RAM, and an Intel HD Graphic 4000 1536 MB GPU. The algorithms were implemented in Matlab R2017b. For the subdivision method, we used the implementation from
https://math.uni-paderborn.de/en/ag/chair-of-applied-mathematics/research/software.
In this example, we will numerically investigate the application of the modified subdivision algorithm presented in
Section 2.5 to the PDE-constrained multiobjective optimization problem using the RB-DEIM solver from
Section 3.5. For the underlying PDE, we set
,
with elements
,
, and
; the right-hand side
,
,
, and
; and the boundary condition
. This leads to the following PDE:
In
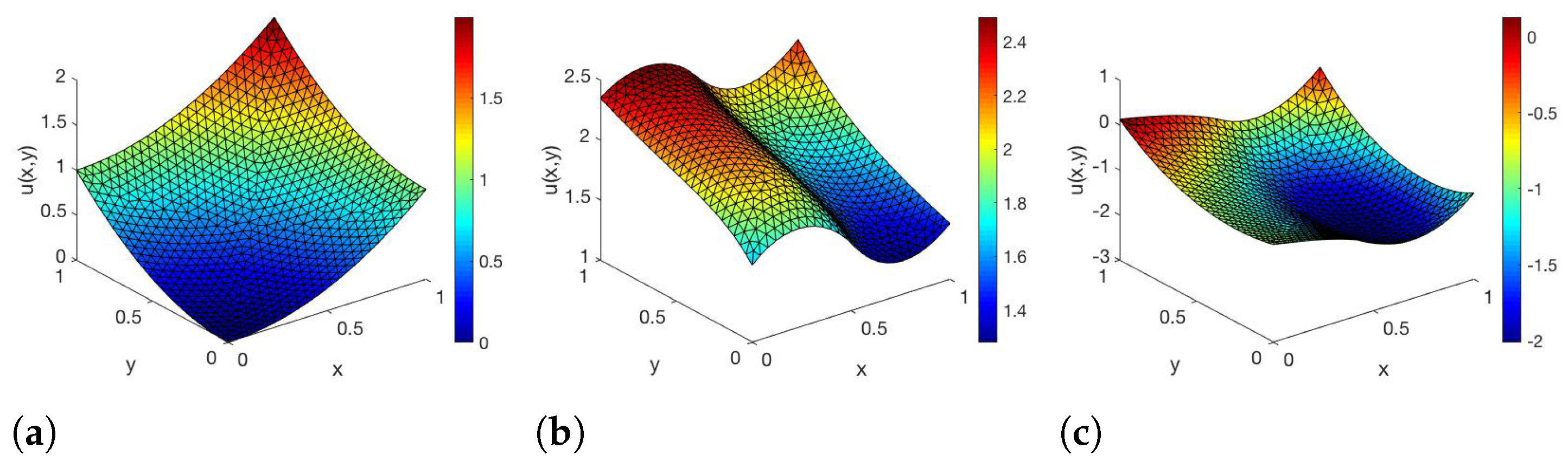
Figure 1, the corresponding solutions of the state equation are shown for three values of
.
In [
23], we have already observed that the error between the FE- and RB-DEIM-solution of the state and adjoint equation decreases if the FE grids get finer. We skip the detailed description here and refer the reader to ([
23] Section 5).
Notice that
solves (
25) for
. For the FE-solver, we used linear finite elements with
and the finite elements have 762 degrees of freedom. We choose the following two objective functions:
with
. For the desired state
, we take the FE solution for
, i.e.,
. Thus,
is a piecewise linear approximation of
. The associated FE objectives are now given as
with
. The gradients are
where
is the FE solution to (
15),
and
. The associated RB objective functions have the form
with
. In [
23], we have already observed good agreement between the approximated Pareto critical sets with the FE- and RB-DEIM-solver, if the error between the gradients is sufficiently small. However, we cannot always guarantee this agreement. Thus, we will instead use the supersets
and
from
Section 2.3 for the approximation of
(and
), which is only based on the reduced objective function
and the error bounds
. To generate
, we compute the steepest descent direction for all components of
. Similar to Algorithm 1, we first calculate
as solution of (
4) for
. Then, the descent direction is
. As a stopping condition, we choose
and set
if it holds that
To generate , we use Algorithm 2.
To save computational time during the modified subdivision algorithm, we calculate
before the algorithm starts (i.e., in an offline phase) on a training set
, which approximates
and store these errors. During the subdivision algorithm, we use them to generate the new
faster and without calculating the FE solution again.
To see a significant difference between the modified subdivision algorithm and the subdivision algorithm and
and
, we need to have a big error between the gradients. To achieve this, we choose a rough training set
with
. For the Greedy algorithm, we choose the tolerance
and the true error
as error indicator, for the DEIM algorithm we choose the tolerance
.
With these settings, we generate an RB-basis with six elements and a DEIM-basis with 18 elements. This leads to the following estimations for the gradients of
and
:
To generate these estimations, we chose a training set
with 3105 equally distributed test points and generate the error for these points. Thus, we have
Now, we test the subdivision and the modified subdivision algorithm with the following conditions. To compute the descent direction, we use the Matlab function
fmincon and solve (
4) or (
7). The algorithm stops when the box size is small enough, which is after 25 iteration steps in our case. In every step, we halve the boxes. We choose five sample points in each box during the first five iteration steps, four sample points in the next five iteration steps, three sample points for the iteration steps ten to 14, two sample points for the next five steps, and one sample points for the last five iteration steps, see Remark 4.
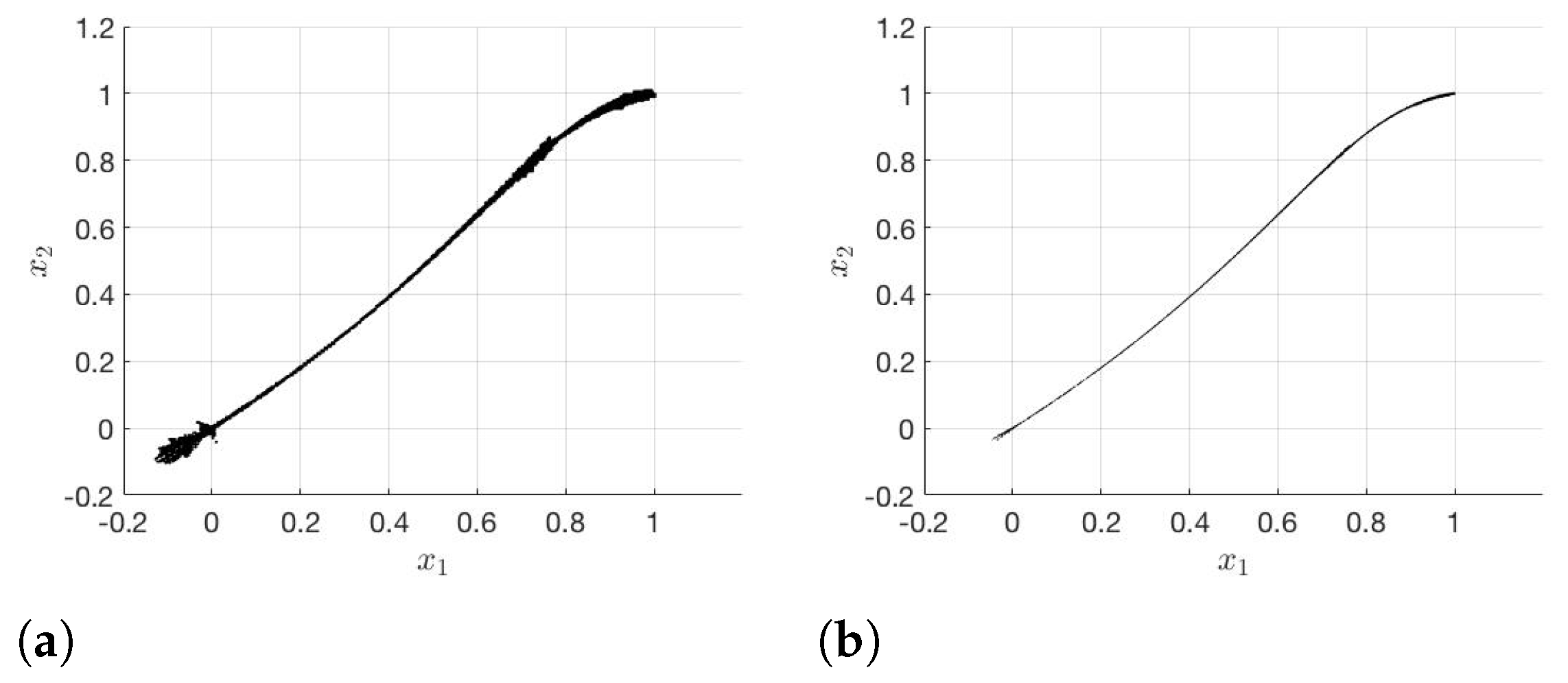
Figure 2 shows the generated approximated Pareto sets for the FE-solver after 20 and 25 iteration steps.
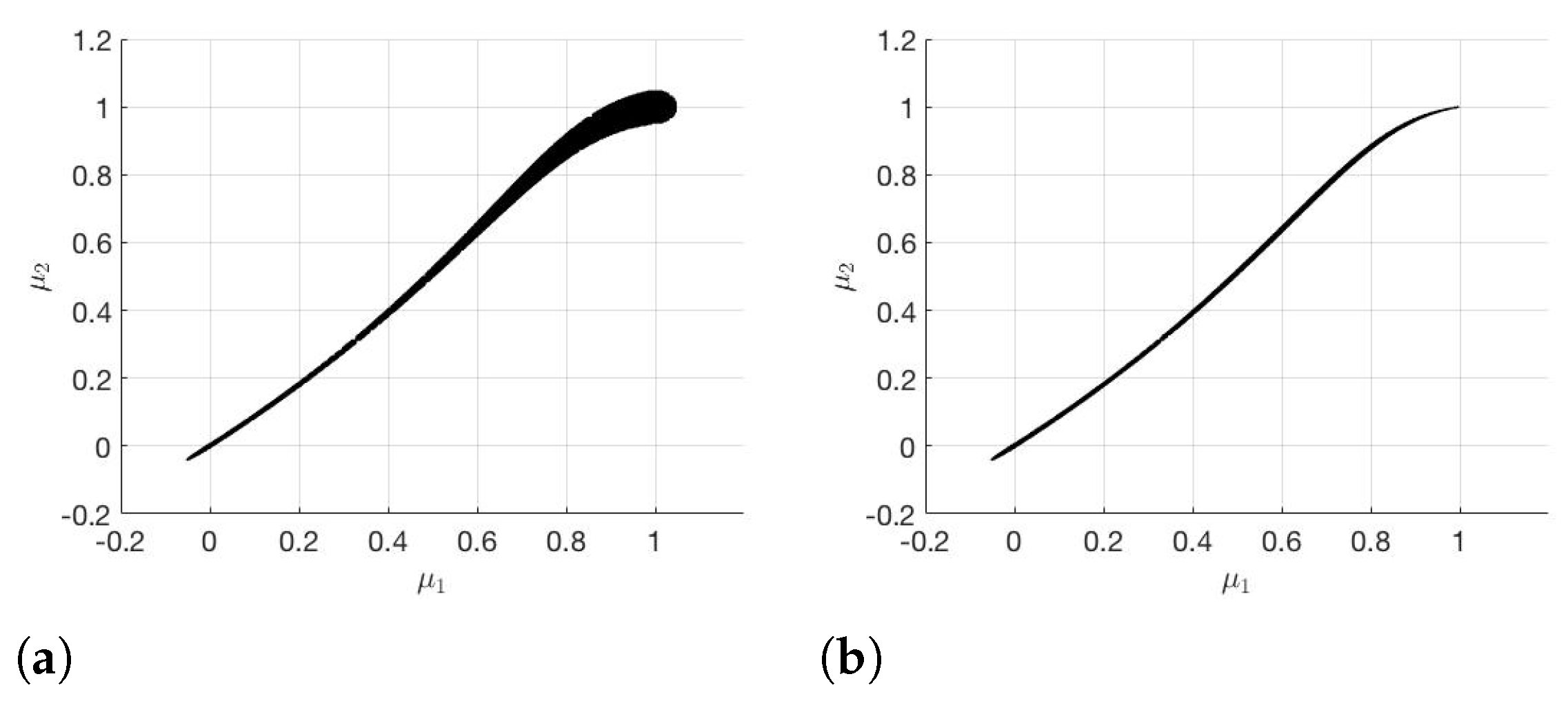
The results with the subdivision algorithm and RB-DEIM-solver are shown in
Figure 3.
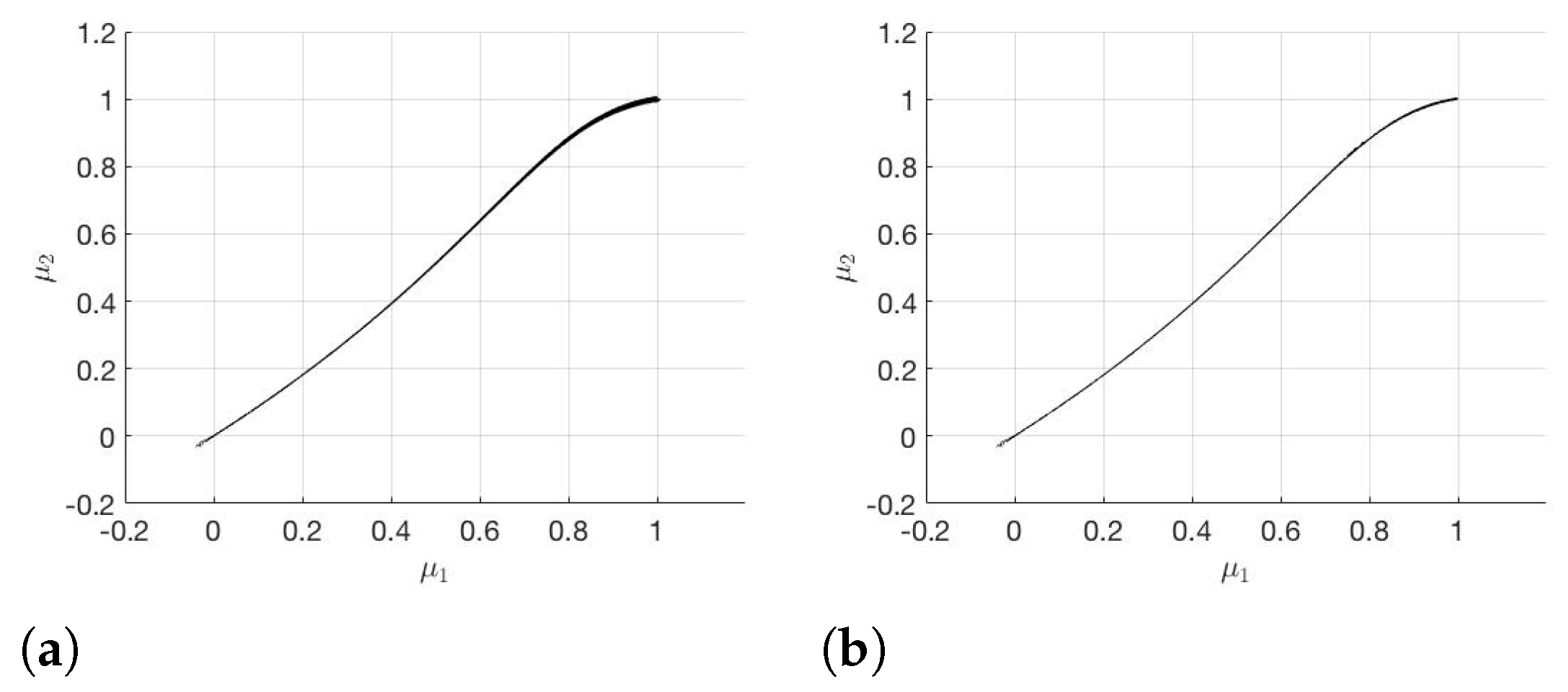
The modified subdivision algorithm and RB-DEIM-solver lead to the results plotted in
Figure 4.
The runtime, number of boxes and number of function and gradient evaluations needed in iteration step 10, 15, 20, and 25 are shown in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5. The total runtime and number of function and gradient evaluations needed for the different methods and the speed-up are shown in
Table 6.
The Greedy algorithm and DEIM together take 14.06 s in the offline phase. To ensure the error
(cf. (
5)) for the gradients on the training set
, it takes
s. It follows from
Figure 3 and
Figure 4 that
is significantly smaller than
for the subdivision algorithm as well as for the modified subdivision algorithm. Therefore, we have a much better approximation for
if we choose
instead of
. If we compare the two different subdivision algorithms, we notice that with the modified subdivision algorithm we have a better approximation of
than with the subdivision algorithm.
The reason for this is that in the modified subdivision algorithm we have a monotonically decreasing sequence
. In
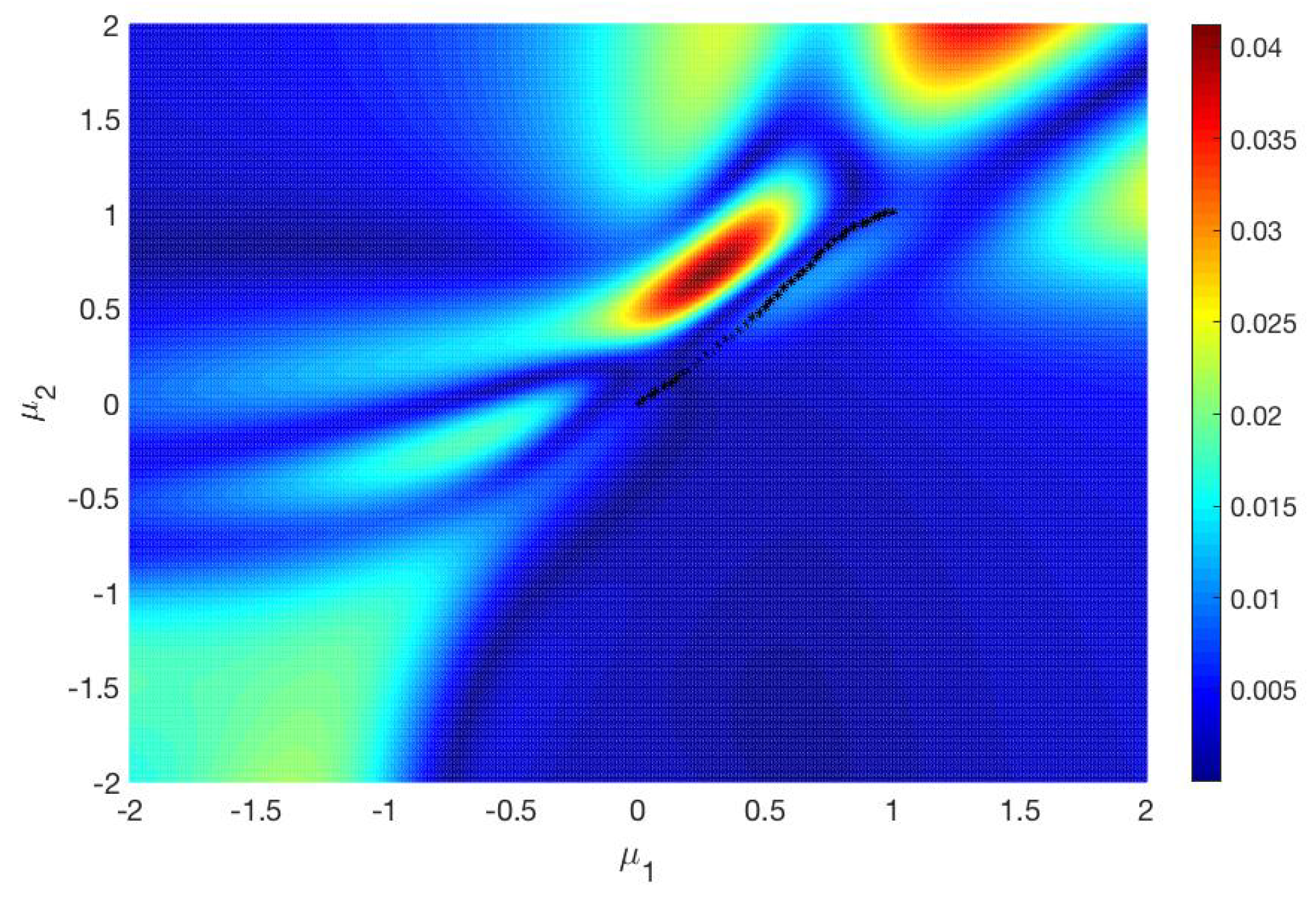
Figure 5, the error between
and
is plotted on the parameter set
. The black markers are some points on the Pareto critical set
. It turns out that the difference between the two gradients is significantly smaller near
than in other regions of
. Due to this, in the modified subdivision algorithm, the sequence
decreases noticeably so that it is useful to update
after each iteration step. As we have already mentioned,
is a better approximation of
. If
is generated by the modified subdivision algorithm, the result is even better. Comparing
Figure 2b and
Figure 4b, there is no significant difference between the two sets. Therefore, the modified subdivision algorithm yields a good approximation
for
, although the error
is not small.
Regarding the computational time (cf.
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6), we notice that in the first 20 iterations the four methods take almost the same time. In these iteration steps, the FE-solver takes between 19 and 30 times more time for one iteration step than the four RB-based methods. Only in the subsequent iteration steps a significant difference in the four RB-based methods appears. For these iteration steps, the FE-solver takes between
and
times as much time as one of the four methods for one iteration step. We notice that the computation of
takes around two times as much time as the computation of
with the subdivision algorithm. The main reason for this is the much larger number of function and gradient evaluations that we have for
. This, in turn, can be attributed to the significantly larger number of boxes for
. If we use the modified subdivision algorithm, the computation of
takes slightly more time than the computation of
. The main reason for this is again the larger number of function and gradient evaluations. Unlike the previous case, this can not be lead back to the number of boxes, but probably to the calculation of the modified descent method, which requires more function and gradient evaluations. Nevertheless, the difference in the computational time is marginal (a factor about
) for the modified subdivision algorithm. For
, we notice another behavior: Here, the generation of
with the modified subdivision algorithm is 2 times faster than with the subdivision algorithm. This is mainly because of the larger number of function evalutions, which is due to the larger number of boxes. The FE-solver takes approximately
times as much time as the computation of
and approximately
times as much as the time as the computation of
with the modified subdivsion. This is another advantage of the modified subdivision algorithm. As we get a better approximation in this algorithm, we have fewer boxes in the iteration steps, and therefore we have a smaller number of function and gradient evaluations than we have for the subdivision algorithm. Finally, we see that the modified subdivision algorithm works better and faster than the subdivision algorithm. As
is a tighter approximation of
, it is better to generate
rather than
.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}