
A Topic Modeling Approach to Discover the Global and Local Subjects in Membrane Distillation Separation Process


Abstract
:1. Introduction
2. Data and Methods
2.1. Data
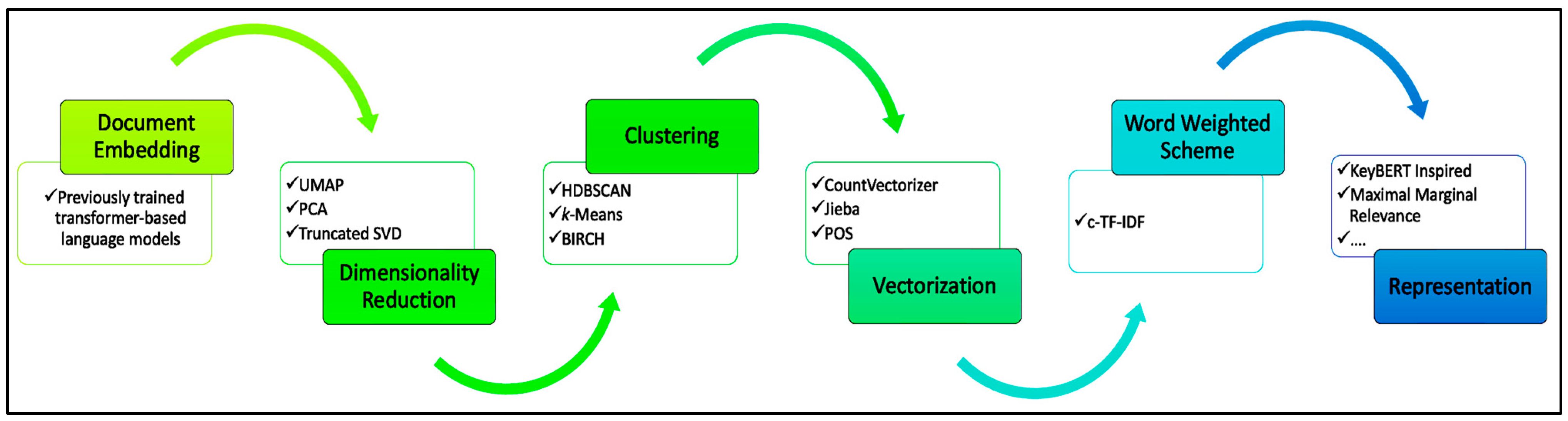
2.2. Methods
3. Results and Discussion
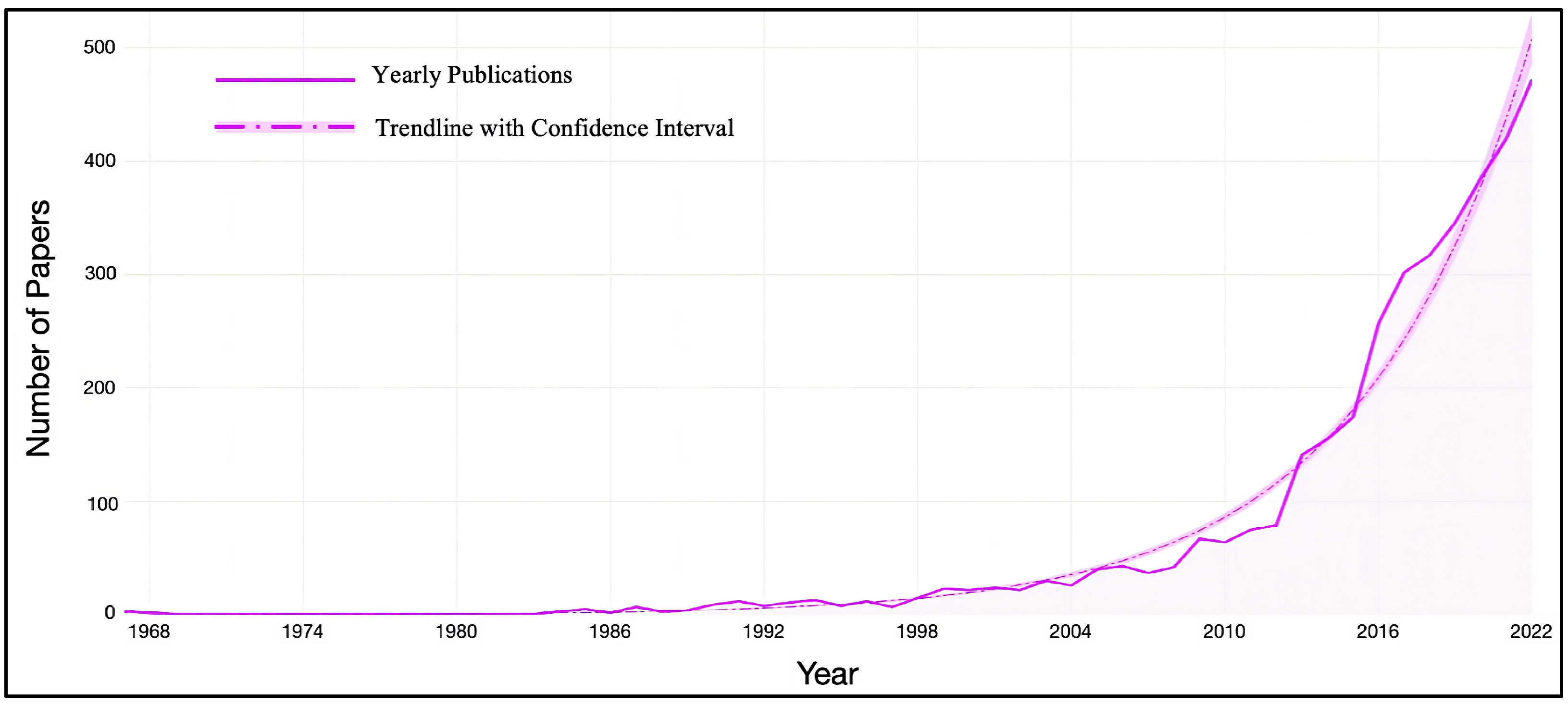
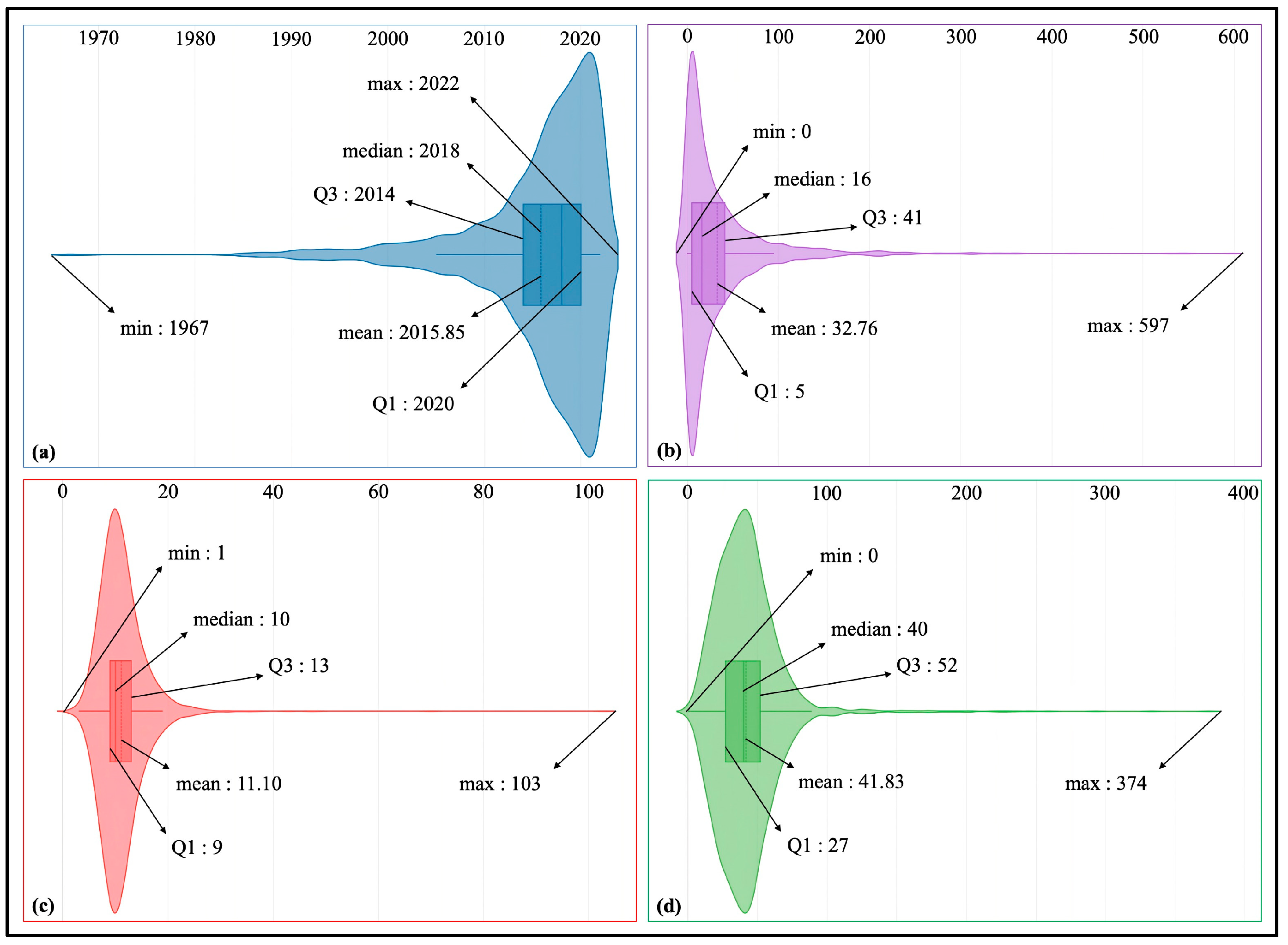
3.1. Outline of the MD Dataset
3.2. Terms Defining the MD Domain
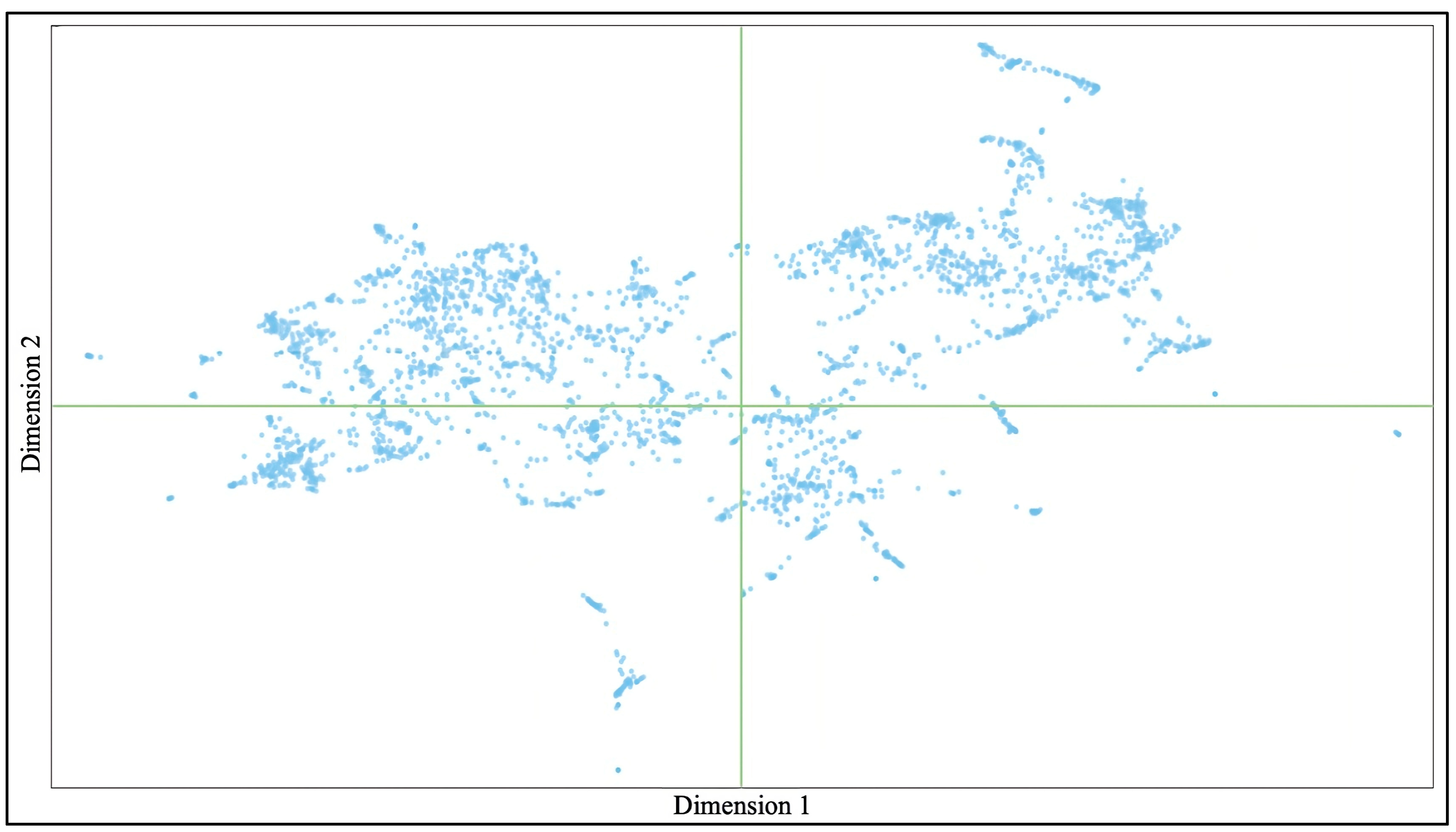
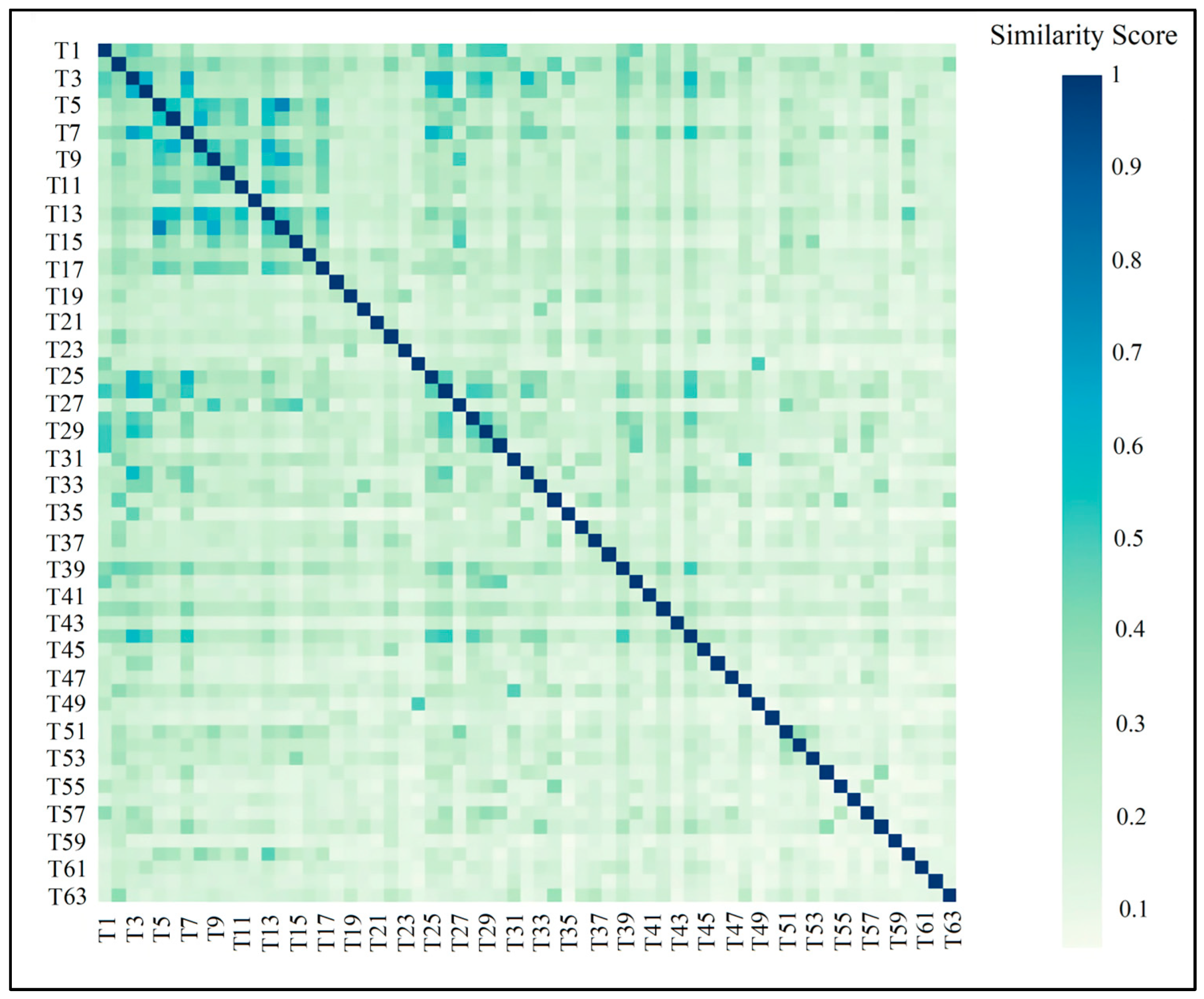
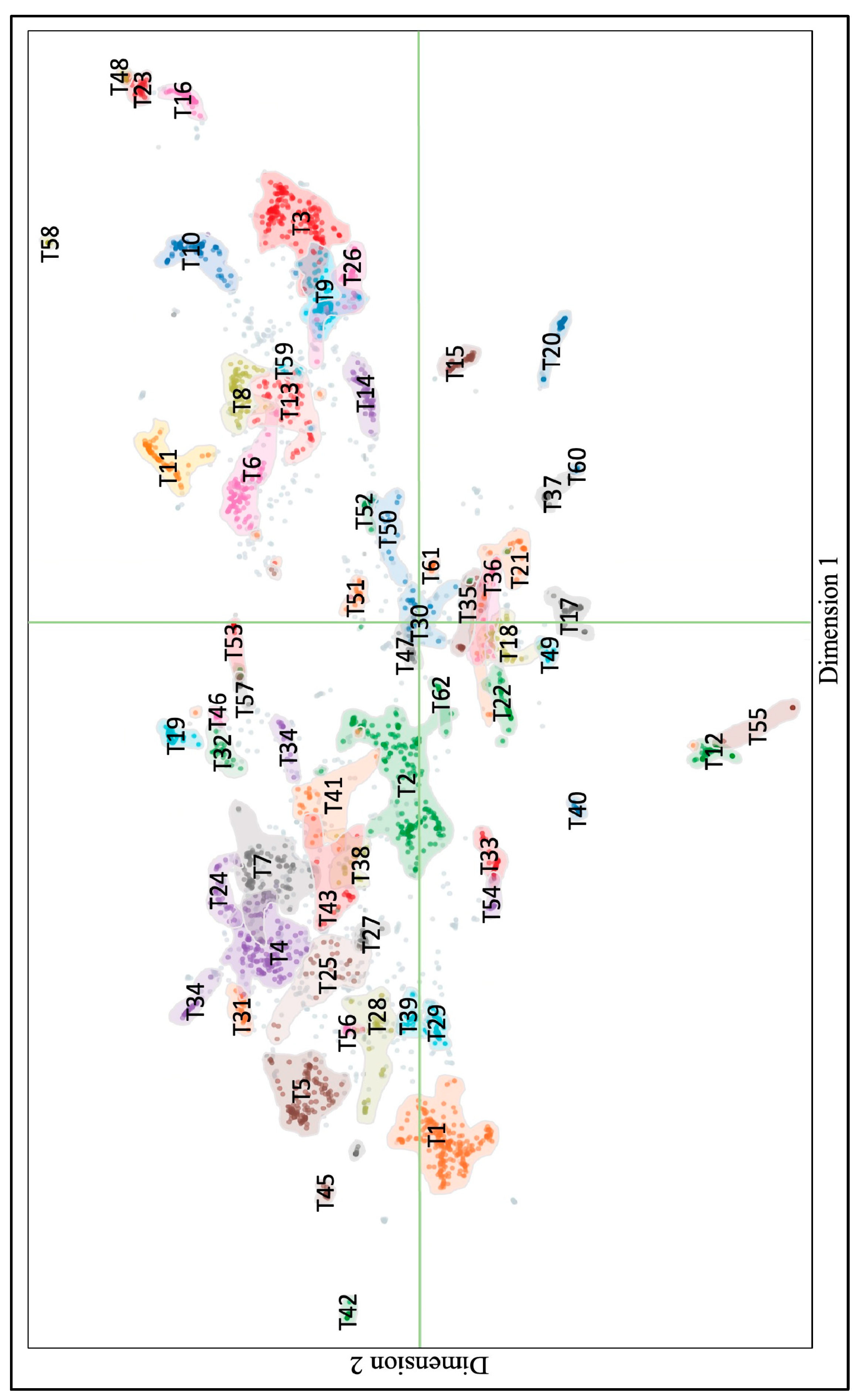
3.3. Global MD Subjects
3.4. Local MD Subjects
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shalaby, S.M.; Kabeel, A.E.; Abosheiasha, H.F.; Elfakharany, M.K.; El-Bialy, E.; Shama, A.; Vidic, R.D. Membrane distillation driven by solar energy: A review. J. Clean. Prod. 2022, 366, 132949. [Google Scholar] [CrossRef]
- Jiang, G.; Yu, W.; Lei, H. Novel solar membrane distillation system based on Ti3C2TX MXene nanofluids with high photothermal conversion efficiency. Desalination 2022, 539, 115930. [Google Scholar] [CrossRef]
- Boretti, A.; Rosa, L. Reassessing the projections of the World Water Development Report. NPJ Clean Water 2019, 2, 15. [Google Scholar] [CrossRef]
- Khayet, M.; Matsuura, T. Membrane Distillation-Principles and Applications; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Ansari, A.; Kavousi, S.; Helfer, F.; Millar, G.; Thiel, D.V. An Improved Modelling Approach for the Comprehensive Study of Direct Contact Membrane Distillation. Membranes 2021, 11, 308. [Google Scholar] [CrossRef]
- Chen, H.; Mao, Y.; Mo, B.; Pan, Y.; Xu, R.; Ji, W.; Chen, G.; Liu, G.; Jin, W. Plasma-assisted facile fabrication of omniphobic graphene oxide membrane with anti-wetting property for membrane distillation. J. Membr. Sci. 2023, 668, 121207. [Google Scholar] [CrossRef]
- Han, L.; Mao, J.; Xie, A.-Q.; Liang, Y.; Zhu, L.; Chen, S. Synergistic enhanced solar-driven water purification and CO2 reduction via photothermal catalytic membrane distillation. Sep. Purif. Technol. 2023, 309, 123003. [Google Scholar] [CrossRef]
- Ju, J.; Huang, Y.; Liu, M.; Xie, N.; Shi, J.; Fan, Y.; Zhao, Y.; Kang, W. Construction of electrospinning Janus nanofiber membranes for efficient solar-driven membrane distillation. Sep. Purif. Technol. 2023, 305, 122348. [Google Scholar] [CrossRef]
- Shafieian, A.; Khiadani, M.; Zargar, M. Performance analysis of tubular membrane distillation modules: An experimental and CFD analysis. Chem. Eng. Res. Des. 2022, 183, 478–493. [Google Scholar] [CrossRef]
- Liu, Z.; Lu, X.; Zhang, S.; Ma, R.; Gu, J.; Ren, K.; Liu, C. Study on the synergistic heat transfer of double boundary layers in the jacketed vacuum membrane distillation process. Desalination 2023, 549, 116356. [Google Scholar] [CrossRef]
- Mutlu-Salmanli, O.; Eryildiz, B.; Vatanpour, V.; Deliballi, Z.; Kiskan, B.; Koyuncu, I. Fabrication of novel hydrophobic electrospun nanofiber membrane using polybenzoxazine for membrane distillation application. Desalination 2023, 546, 116203. [Google Scholar] [CrossRef]
- Lin, J.; Du, J.; Xie, S.; Yu, F.; Fang, S.; Yan, Z.; Lin, X.; Zou, D.; Xie, M.; Ye, W. Durable superhydrophobic polyvinylidene fluoride membranes via facile spray-coating for effective membrane distillation. Desalination 2022, 538, 115925. [Google Scholar] [CrossRef]
- Zhang, Y.; Ji, Z.; Yan, H.; Wu, B.; Guo, Y.; Wang, H.; Li, C. Water recovery from cleaning wastewater of traditional Chinese medicine processing via vacuum membrane distillation: Parameters optimization and membrane fouling investigation. Chem. Eng. Res. Des. 2022, 188, 555–563. [Google Scholar] [CrossRef]
- Aytaç, E.; Khayet, M. A deep dive into membrane distillation literature with data analysis, bibliometric methods, and machine learning. Desalination 2023, 553, 116482. [Google Scholar] [CrossRef]
- Acevedo, L.; Uche, J.; Del-Amo, A. Improving the Distillate Prediction of a Membrane Distillation Unit in a Trigeneration Scheme by Using Artificial Neural Networks. Water 2018, 10, 310. [Google Scholar] [CrossRef]
- Dudchenko, A.V.; Mauter, M.S. Neural networks for estimating physical parameters in membrane distillation. J. Membr. Sci. 2020, 610, 118285. [Google Scholar] [CrossRef]
- Chamani, H.; Yazgan-Birgi, P.; Matsuura, T.; Rana, D.; Hassan Ali, M.I.; Arafat, H.A.; Lan, C.Q. CFD-based genetic programming model for liquid entry pressure estimation of hydrophobic membranes. Desalination 2020, 476, 114231. [Google Scholar] [CrossRef]
- Huang, J.; Tang, T.; He, Y. Numerical Simulation Study on the Mass and Heat Transfer in the Self-Heating Membrane Distillation Process. Ind. Eng. Chem. Res. 2021, 60, 12663–12674. [Google Scholar] [CrossRef]
- Ali, K.; Arafat, H.A.; Hassan Ali, M.I. Detailed numerical analysis of air gap membrane distillation performance using different membrane materials and porosity. Desalination 2023, 551, 116436. [Google Scholar] [CrossRef]
- Adel, K.; Elhakeem, A.; Marzouk, M. Decentralizing construction AI applications using blockchain technology. Expert Syst. Appl. 2022, 194, 116548. [Google Scholar] [CrossRef]
- Aytaç, E. Modeling Future Impacts on Land Cover of Rapid Expansion of Hazelnut Orchards: A Case Study on Samsun, Turkey. Eur. J. Sust. Dev. Res. 2022, 6, em0193. [Google Scholar] [CrossRef]
- Habuza, T.; Navaz, A.N.; Hashim, F.; Alnajjar, F.; Zaki, N.; Serhani, M.A.; Statsenko, Y. AI applications in robotics, diagnostic image analysis and precision medicine: Current limitations, future trends, guidelines on CAD systems for medicine. Inform. Med. Unlocked 2021, 24, 100596. [Google Scholar] [CrossRef]
- Aytaç, E. Exploring Electrocoagulation Through Data Analysis And Text Mining Perspectives. Environ. Eng. Man. J. 2022, 21, 671–685. [Google Scholar]
- Van Giffen, B.; Herhausen, D.; Fahse, T. Overcoming the pitfalls and perils of algorithms: A classification of machine learning biases and mitigation methods. J. Bus. Res. 2022, 144, 93–106. [Google Scholar] [CrossRef]
- Aytaç, E. Forecasting Turkey’s Hazelnut Export Quantities with Facebook’s Prophet Algorithm and Box-Cox Transformation. ADCAIJ Adv. Distrib. Comput. Artif. Intell. J. 2021, 10, 33–47. [Google Scholar] [CrossRef]
- Houssein, E.H.; Abohashima, Z.; Elhoseny, M.; Mohamed, W.M. Machine learning in the quantum realm: The state-of-the-art, challenges, and future vision. Expert Syst. Appl. 2022, 194, 116512. [Google Scholar] [CrossRef]
- Aytaç, E. Havzaların Benzerliklerini Tanımlamada Alternatif Bir Yaklaşım: Hiyerarşik Kümeleme Yöntemi Uygulaması. Afyon Kocatepe Üniversitesi Fen Ve Mühendislik Bilim. Derg. 2021, 21, 958–970. [Google Scholar] [CrossRef]
- Bao, J.; Chen, Y.; Yin, J.; Chen, X.; Zhu, D. Exploring topics and trends in Chinese ATC incident reports using a domain-knowledge driven topic model. J. Air Transp. Manag. 2023, 108, 102374. [Google Scholar] [CrossRef]
- Abdelrazek, A.; Eid, Y.; Gawish, E.; Medhat, W.; Hassan, A. Topic modeling algorithms and applications: A survey. Inf. Syst. 2023, 112, 102131. [Google Scholar] [CrossRef]
- Wang, F.; Zhou, R.; Feng, Y.; Lu, X. Bayesian sparse joint dynamic topic model with flexible lead-lag order. Inf. Sci. 2022, 616, 392–410. [Google Scholar] [CrossRef]
- Gencoglu, B.; Helms-Lorenz, M.; Maulana, R.; Jansen, E.P.W.A.; Gencoglu, O. Machine and expert judgments of student perceptions of teaching behavior in secondary education: Added value of topic modeling with big data. Comput. Educ. 2023, 193, 104682. [Google Scholar] [CrossRef]
- Feng, J.; Zhang, Z.; Ding, C.; Rao, Y.; Xie, H.; Wang, F.L. Context reinforced neural topic modeling over short texts. Inf. Sci. 2022, 607, 79–91. [Google Scholar] [CrossRef]
- Zhang, K.; Lin, N.; Tian, G.; Yang, J.; Wang, D.; Jin, Z. Unsupervised-learning based self-organizing neural network using multi-component seismic data: Application to Xujiahe tight-sand gas reservoir in China. J. Pet. Sci. Eng. 2022, 209, 109964. [Google Scholar] [CrossRef]
- Su, H.; Yang, X.; Xiang, L.; Hu, A.; Xu, Y. A novel method based on deep transfer unsupervised learning network for bearing fault diagnosis under variable working condition of unequal quantity. Knowl.-Based Syst. 2022, 242, 108381. [Google Scholar] [CrossRef]
- Dehghani, M.; Ebrahimi, F. ParsBERT topic modeling of Persian scientific articles about COVID-19. Inform. Med. Unlocked 2023, 36, 101144. [Google Scholar] [CrossRef] [PubMed]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar] [CrossRef]
- Jeon, E.; Yoon, N.; Sohn, S.Y. Exploring new digital therapeutics technologies for psychiatric disorders using BERTopic and PatentSBERTa. Technol. Forecast. Soc. Change 2023, 186, 122130. [Google Scholar] [CrossRef]
- Saidi, F.; Trabelsi, Z.; Thangaraj, E. A novel framework for semantic classification of cyber terrorist communities on Twitter. Eng. Appl. Artif. Intell. 2022, 115, 105271. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic Web Page. Available online: https://maartengr.github.io/BERTopic/index.html (accessed on 27 January 2023).
- López-Santillán, R.; Montes-Y-Gómez, M.; González-Gurrola, L.C.; Ramírez-Alonso, G.; Prieto-Ordaz, O. Richer Document Embeddings for Author Profiling tasks based on a heuristic search. Inf. Process. Manag. 2020, 57, 102227. [Google Scholar] [CrossRef]
- Rahimi, Z.; Homayounpour, M.M. Tens-embedding: A Tensor-based document embedding method. Expert Syst. Appl. 2020, 162, 113770. [Google Scholar] [CrossRef]
- Wei, C.; Luo, S.; Guo, J.; Wu, Z.; Pan, L. Discriminative locally document embedding: Learning a smooth affine map by approximation of the probabilistic generative structure of subspace. Knowl.-Based Syst. 2017, 121, 41–57. [Google Scholar] [CrossRef]
- Singh, K.N.; Devi, S.D.; Devi, H.M.; Mahanta, A.K. A novel approach for dimension reduction using word embedding: An enhanced text classification approach. Int. J. Inf. Manag. Data Insights 2022, 2, 100061. [Google Scholar] [CrossRef]
- Zhou, R.; Gao, W.; Ding, D.; Liu, W. Supervised dimensionality reduction technology of generalized discriminant component analysis and its kernelization forms. Pattern Recognit. 2022, 124, 108450. [Google Scholar] [CrossRef]
- Bibal, A.; Clarinval, A.; Dumas, B.; Frénay, B. IXVC: An interactive pipeline for explaining visual clusters in dimensionality reduction visualizations with decision trees. Array 2021, 11, 100080. [Google Scholar] [CrossRef]
- Wang, S.; Bai, L.; Chen, X.; Wang, Z.; Shao, Y.-H. Divergent Projection Analysis for Unsupervised Dimensionality Reduction. Procedia Comput. Sci. 2022, 199, 384–391. [Google Scholar] [CrossRef]
- Ao, Z.; Horváth, G.; Sheng, C.; Song, Y.; Sun, Y. Skill requirements in job advertisements: A comparison of skill-categorization methods based on wage regressions. Inf. Process. Manag. 2023, 60, 103185. [Google Scholar] [CrossRef]
- Ezugwu, A.E.; Ikotun, A.M.; Oyelade, O.O.; Abualigah, L.; Agushaka, J.O.; Eke, C.I.; Akinyelu, A.A. A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects. Eng. Appl. Artif. Intell. 2022, 110, 104743. [Google Scholar] [CrossRef]
- Aytaç, E. Unsupervised learning approach in defining the similarity of catchments: Hydrological response unit based k-means clustering, a demonstration on Western Black Sea Region of Turkey. Int. Soil Water Conserv. Res. 2020, 8, 321–331. [Google Scholar] [CrossRef]
- Ghasemi, Z.; Khorshidi, H.A.; Aickelin, U. Multi-objective Semi-supervised clustering for finding predictive clusters. Expert Syst. Appl. 2022, 195, 116551. [Google Scholar] [CrossRef]
- Zhou, Z.; Si, G.; Sun, H.; Qu, K.; Hou, W. A robust clustering algorithm based on the identification of core points and KNN kernel density estimation. Expert Syst. Appl. 2022, 195, 116573. [Google Scholar] [CrossRef]
- Zhu, M.-X.; Lv, X.-J.; Chen, W.-J.; Li, C.-N.; Shao, Y.-H. Local density peaks clustering with small size distance matrix. Procedia Comput. Sci. 2022, 199, 331–338. [Google Scholar] [CrossRef]
- Khayet, M.; Aytaç, E.; Matsuura, T. Bibliometric and sentiment analysis with machine learning on the scientific contribution of Professor Srinivasa Sourirajan. Desalination 2022, 543, 116095. [Google Scholar] [CrossRef]
- Zheng, W.; Gao, J.; Wu, X.; Liu, F.; Xun, Y.; Liu, G.; Chen, X. The impact factors on the performance of machine learning-based vulnerability detection: A comparative study. J. Syst. Softw. 2020, 168, 110659. [Google Scholar] [CrossRef]
- Qorib, M.; Oladunni, T.; Denis, M.; Ososanya, E.; Cotae, P. Covid-19 vaccine hesitancy: Text mining, sentiment analysis and machine learning on COVID-19 vaccination Twitter dataset. Expert Syst. Appl. 2023, 212, 118715. [Google Scholar] [CrossRef] [PubMed]
- Findley, M.E. Vaporization through Porous Membranes. Ind. Eng. Chem. Process Des. Dev. 1967, 6, 226–230. [Google Scholar] [CrossRef]
- Shome, S.; Hassan, M.K.; Verma, S.; Panigrahi, T.R. Impact investment for sustainable development: A bibliometric analysis. Int. Rev. Econ. Finance 2023, 84, 770–800. [Google Scholar] [CrossRef]
- Ng, J.Y.; Chiong, J.D.; Liu, M.Y.M.; Pang, K.K.Y. Characteristics of the Echinacea Spp. research literature: A bibliometric analysis. Eur. J. Integr. Med. 2023, 57, 102216. [Google Scholar] [CrossRef]
- SBERT. Pretrained Models. Available online: https://www.sbert.net/docs/pretrained_models.html (accessed on 28 January 2023).
- Yang, D.; Wei, V.; Jin, Z.; Yang, Z.; Chen, X. A UMAP-based clustering method for multi-scale damage analysis of laminates. Appl. Math. Model. 2022, 111, 78–93. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar] [CrossRef]
- Leonard, A.; Wheeler, S.; McCulloch, M. Power to the people: Applying citizen science and computer vision to home mapping for rural energy access. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102748. [Google Scholar] [CrossRef]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-Based Clustering Based on Hierarchical Density Estimates. In Proceedings of the Advances in Knowledge Discovery and Data Mining, Gold Coast, Australia, 14–17 April 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 160–172. [Google Scholar]
- Ghamarian, I.; Marquis, E.A. Hierarchical density-based cluster analysis framework for atom probe tomography data. Ultramicroscopy 2019, 200, 28–38. [Google Scholar] [CrossRef]
- Satrya, W.F.; Aprilliyani, R.; Yossy, E.H. Sentiment analysis of Indonesian police chief using multi-level ensemble model. Procedia Comput. Sci. 2023, 216, 620–629. [Google Scholar] [CrossRef]
- Li, Q.; Jin, Z.; Wang, C.; Zeng, D.D. Mining opinion summarizations using convolutional neural networks in Chinese microblogging systems. Knowl. -Based Syst. 2016, 107, 289–300. [Google Scholar] [CrossRef]
- Aytaç, E.; Fombona-Pascual, A.; Lado, J.J.; Quismondo, E.G.; Palma, J.; Khayet, M. Faradaic deionization technology: Insights from bibliometric, data mining and machine learning approaches. Desalination 2023, 563, 116715. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic Hyperparameter Tuning. Available online: https://maartengr.github.io/BERTopic/getting_started/parameter%20tuning/parametertuning.html (accessed on 15 March 2023).
- McInnes, L.; Healy, J.; Astels, S. hdbscan: Hierarchical density based clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- Guo, X.; Su, Q.-W.; Zhang, L.-Z. The measurement of permeate flux based on a noninvasive method for membrane distillation: Experiment and model validation. Int. J. Heat Mass Transfer 2021, 164, 120482. [Google Scholar] [CrossRef]
- Mustafa, I.; Kilibay, A.; Alhseinat, E.; Almarzooqi, F. Enhanced Membrane Distillation Water Flux through Electromagnetism. Chem. Eng. Process. Process Intensif. 2021, 169, 108597. [Google Scholar] [CrossRef]
- Parani, S.; Oluwafemi, O.S. Membrane Distillation: Recent Configurations, Membrane Surface Engineering, and Applications. Membranes 2021, 11, 934. [Google Scholar] [CrossRef]
- Mohammad Reza Shirzad, K.; Ahmad, R. Membrane Distillation: Basics, Advances, and Applications. In Advances in Membrane Technologies; Amira, A., Ed.; IntechOpen: Rijeka, Croatia, 2020; Chapter 4. [Google Scholar]
- Chen, L.; Xu, P.; Wang, H. Interplay of the Factors Affecting Water Flux and Salt Rejection in Membrane Distillation: A State-of-the-Art Critical Review. Water 2020, 12, 2841. [Google Scholar] [CrossRef]
- Ullah, R.; Khraisheh, M.; Esteves, R.J.; McLeskey, J.T.; AlGhouti, M.; Gad-el-Hak, M.; Vahedi Tafreshi, H. Energy efficiency of direct contact membrane distillation. Desalination 2018, 433, 56–67. [Google Scholar] [CrossRef]
- Belessiotis, V.; Kalogirou, S.; Delyannis, E. Chapter Four—Membrane Distillation. In Thermal Solar Desalination; Belessiotis, V., Kalogirou, S., Delyannis, E., Eds.; Academic Press: Cambridge, MA, USA, 2016; pp. 191–251. [Google Scholar]
- Anvari, A.; Azimi Yancheshme, A.; Kekre, K.M.; Ronen, A. State-of-the-art methods for overcoming temperature polarization in membrane distillation process: A review. J. Membr. Sci. 2020, 616, 118413. [Google Scholar] [CrossRef]
- Mortaheb, H.R.; Baghban Salehi, M.; Rajabzadeh, M. Optimized hybrid PVDF/graphene membranes for enhancing performance of AGMD process in water desalination. J. Ind. Eng. Chem. 2021, 99, 407–421. [Google Scholar] [CrossRef]
- Li, M.; Lu, K.J.; Wang, L.; Zhang, X.; Chung, T.-S. Janus membranes with asymmetric wettability via a layer-by-layer coating strategy for robust membrane distillation. J. Membr. Sci. 2020, 603, 118031. [Google Scholar] [CrossRef]
- Ursino, C.; Di Nicolò, E.; Gabriele, B.; Criscuoli, A.; Figoli, A. Development of a novel perfluoropolyether (PFPE) hydrophobic/hydrophilic coated membranes for water treatment. J. Membr. Sci. 2019, 581, 58–71. [Google Scholar] [CrossRef]
- Li, X.; Deng, L.; Yu, X.; Wang, M.; Wang, X.; García-Payo, C.; Khayet, M. A novel profiled core–shell nanofibrous membrane for wastewater treatment by direct contact membrane distillation. J. Mater. Chem. A 2016, 4, 14453–14463. [Google Scholar] [CrossRef]
- Peng, Y.; Dong, Y.; Fan, H.; Chen, P.; Li, Z.; Jiang, Q. Preparation of polysulfone membranes via vapor-induced phase separation and simulation of direct-contact membrane distillation by measuring hydrophobic layer thickness. Desalination 2013, 316, 53–66. [Google Scholar] [CrossRef]
- Chew, N.G.P.; Zhao, S.; Malde, C.; Wang, R. Superoleophobic surface modification for robust membrane distillation performance. J. Membr. Sci. 2017, 541, 162–173. [Google Scholar] [CrossRef]
- Madalosso, H.B.; Machado, R.; Hotza, D.; Marangoni, C. Membrane Surface Modification by Electrospinning, Coating, and Plasma for Membrane Distillation Applications: A State-of-the-Art Review. Adv. Eng. Mater. 2021, 23, 2001456. [Google Scholar] [CrossRef]
- Gryta, M. Surface modification of polypropylene membrane by helium plasma treatment for membrane distillation. J. Membr. Sci. 2021, 628, 119265. [Google Scholar] [CrossRef]
- Huang, Y.-X.; Liang, D.-Q.; Luo, C.-H.; Zhang, Y.; Meng, F. Liquid-like surface modification for effective anti-scaling membrane distillation with uncompromised flux. J. Membr. Sci. 2021, 637, 119673. [Google Scholar] [CrossRef]
- Hendren, Z.D.; Brant, J.; Wiesner, M.R. Surface modification of nanostructured ceramic membranes for direct contact membrane distillation. J. Membr. Sci. 2009, 331, 1–10. [Google Scholar] [CrossRef]
- Zuo, G.; Wang, R. Novel membrane surface modification to enhance anti-oil fouling property for membrane distillation application. J. Membr. Sci. 2013, 447, 26–35. [Google Scholar] [CrossRef]
- Kang, G.-d.; Cao, Y.-m. Application and modification of poly(vinylidene fluoride) (PVDF) membranes–A review. J. Membr. Sci. 2014, 463, 145–165. [Google Scholar] [CrossRef]
- Hebbar, R.S.; Isloor, A.M.; Ismail, A.F. Chapter 12—Contact Angle Measurements. In Membrane Characterization; Hilal, N., Ismail, A.F., Matsuura, T., Oatley-Radcliffe, D., Eds.; Elsevier: Amsterdam, The Netherlands, 2017; pp. 219–255. [Google Scholar]
- Akbari, R.; Antonini, C. Contact angle measurements: From existing methods to an open-source tool. Adv. Colloid Interface Sci. 2021, 294, 102470. [Google Scholar] [CrossRef]
- Warsinger, D.M.; Servi, A.; Connors, G.B.; Mavukkandy, M.O.; Arafat, H.A.; Gleason, K.K.; Lienhard, V.J.H. Reversing membrane wetting in membrane distillation: Comparing dryout to backwashing with pressurized air. Environ. Sci. Water Res. Technol. 2017, 3, 930–939. [Google Scholar] [CrossRef]
- Ismail, M.S.; Mohamed, A.M.; Poggio, D.; Pourkashanian, M. Direct contact membrane distillation: A sensitivity analysis and an outlook on membrane effective thermal conductivity. J. Membr. Sci. 2021, 624, 119035. [Google Scholar] [CrossRef]
- Ashoor, B.B.; Mansour, S.; Giwa, A.; Dufour, V.; Hasan, S.W. Principles and applications of direct contact membrane distillation (DCMD): A comprehensive review. Desalination 2016, 398, 222–246. [Google Scholar] [CrossRef]
- Wae AbdulKadir, W.A.F.; Ahmad, A.L.; Seng, O.B.; Che Lah, N.F. Biomimetic hydrophobic membrane: A review of anti-wetting properties as a potential factor in membrane development for membrane distillation (MD). J. Ind. Eng. Chem. 2020, 91, 15–36. [Google Scholar] [CrossRef]
- Goh, P.S.; Naim, R.; Rahbari-Sisakht, M.; Ismail, A.F. Modification of membrane hydrophobicity in membrane contactors for environmental remediation. Sep. Purif. Technol. 2019, 227, 115721. [Google Scholar] [CrossRef]
- Qtaishat, M.R.; Banat, F. Desalination by solar powered membrane distillation systems. Desalination 2013, 308, 186–197. [Google Scholar] [CrossRef]
- Ma, Q.; Xu, Z.; Wang, R. Distributed solar desalination by membrane distillation: Current status and future perspectives. Water Res. 2021, 198, 117154. [Google Scholar] [CrossRef] [PubMed]
- Gryta, M. Calcium sulphate scaling in membrane distillation process. Chem. Pap. 2009, 63, 146–151. [Google Scholar] [CrossRef]
- Gryta, M. Alkaline scaling in the membrane distillation process. Desalination 2008, 228, 128–134. [Google Scholar] [CrossRef]
- Liao, X.; Chou, S.; Gu, C.; Zhang, X.; Shi, M.; You, X.; Liao, Y.; Razaqpur, A.G. Engineering omniphobic corrugated membranes for scaling mitigation in membrane distillation. J. Membr. Sci. 2023, 665, 121130. [Google Scholar] [CrossRef]
- Ma, H.; Hsiao, B.S. Chapter 4—Electrospun Nanofibrous Membranes for Desalination. In Current Trends and Future Developments on (Bio-) Membranes; Basile, A., Curcio, E., Inamuddin, Eds.; Elsevier: Amsterdam, The Netherlands, 2019; pp. 81–104. [Google Scholar]
- Subrahmanya, T.M.; Arshad, A.B.; Lin, P.T.; Widakdo, J.; Makari, H.K.; Austria, H.F.M.; Hu, C.-C.; Lai, J.-Y.; Hung, W.-S. A review of recent progress in polymeric electrospun nanofiber membranes in addressing safe water global issues. RSC Adv. 2021, 11, 9638–9663. [Google Scholar] [CrossRef]
- Mengual, J.I.; Khayet, M.; Godino, M.P. Heat and mass transfer in vacuum membrane distillation. Int. J. Heat Mass Transf. 2004, 47, 865–875. [Google Scholar] [CrossRef]
- Orfi, J.; Loussif, N.; Davies, P.A. Heat and mass transfer in membrane distillation used for desalination with slip flow. Desalination 2016, 381, 135–142. [Google Scholar] [CrossRef]
- Bandini, S.; Gostoli, C.; Sarti, G.C. Role of heat and mass transfer in membrane distillation process. Desalination 1991, 81, 91–106. [Google Scholar] [CrossRef]
- Xu, L.; Xu, S.; Wu, X.; Wang, P.; Jin, D.; Hu, J.; Li, L.; Chen, L.; Leng, Q.; Wu, D. Heat and mass transfer evaluation of air-gap diffusion distillation by ε-NTU method. Desalination 2020, 478, 114281. [Google Scholar] [CrossRef]
- Qtaishat, M.; Matsuura, T.; Kruczek, B.; Khayet, M. Heat and mass transfer analysis in direct contact membrane distillation. Desalination 2008, 219, 272–292. [Google Scholar] [CrossRef]
- Alkhudhiri, A.; Hilal, N. 3-Membrane distillation—Principles, applications, configurations, design, and implementation. In Emerging Technologies for Sustainable Desalination Handbook; Gude, V.G., Ed.; Butterworth-Heinemann: Oxford, UK, 2018; pp. 55–106. [Google Scholar]
- Khayet, M.; Cojocaru, C. Air gap membrane distillation: Desalination, modeling and optimization. Desalination 2012, 287, 138–145. [Google Scholar] [CrossRef]
- Wan, C.F.; Yang, T.; Lipscomb, G.G.; Stookey, D.J.; Chung, T.-S. Design and fabrication of hollow fiber membrane modules. J. Membr. Sci. 2017, 538, 96–107. [Google Scholar] [CrossRef]
- Lu, K.-J.; Wang, P.; Chung, T.-S. Chapter 23—Hollow fiber membranes for membrane distillation applications. In Hollow Fiber Membranes; Chung, T.-S., Feng, Y., Eds.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 495–521. [Google Scholar]
- Pagliero, M.; Khayet, M.; García-Payo, C.; García-Fernández, L. Hollow fibre polymeric membranes for desalination by membrane distillation technology: A review of different morphological structures and key strategic improvements. Desalination 2021, 516, 115235. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criteria | Description |
|---|---|
| Title–Abstract–Keyword | Limit to Keyword List (Table 2) |
| Source Type | Limit to Journal |
| Document Type | Limit to Article |
| Publication Stage | Limit to Final |
| Language | Limit to English |
| Publication Year | Exclude 2023 |
| Keyword | Keyword |
|---|---|
| membrane distillation | MD |
| air gap membrane distillation | AGMD |
| direct contact membrane distillation | DCMD |
| vacuum membrane distillation | VMD |
| vacuum enhanced membrane distillation | VEMD |
| Sweeping/sweep gas membrane distillation | SGMD |
| membrane air stripping | MAS |
| thermostatic sweeping gas membrane distillation | TSGMD |
| permeate gap membrane distillation | PGMD |
| liquid gap membrane distillation | LGMD |
| water gap membrane distillation | WGMD |
| conductive gap membrane distillation | CGMD |
| material gap membrane distillation | MGMD |
| Rank | Term |
|---|---|
| 1 | membrane |
| 2 | water |
| 3 | distillation |
| 4 | flux |
| 5 | membranes |
| 6 | MD |
| 7 | feed |
| 8 | process |
| 9 | temperature |
| 10 | performance |
| Topic No. | Number of Papers | Topic Name |
|---|---|---|
| T-1 (Outliers) | 410 | membrane—water—distillation—process—concentration—membranes—flux—temperature—feed—using |
| T1 | 2121 | membrane—water—distillation—feed—md—flux—temperature—process—heat—energy |
| T2 | 1153 | membrane—membranes—surface—water—distillation—flux—PVDF—contact—MD—hydrophobic |
| Topic No | Number of Papers | Topic Name |
|---|---|---|
| T1 | 224 | solar—energy—water—desalination—production—collector—thermal—unit—plant—collectors |
| T2 | 175 | scaling—crystallization—brine—crystals—scale—MD—membrane—gypsum—recovery—RO |
| T3 | 159 | electrospun—nanofibrous—nanofiber—electrospinning—membranes—ENMs– superhydrophobic—layer—membrane—fabricated |
| T4 | 121 | heat—transfer—module—model—mass—temperature—DCMD– flow—feed—thermal |
| T5 | 119 | gap—AGMD—air—temperature—feed—flow—flux—coolant—module—permeate |
| T6 | 90 | hollow—fiber—PVDF—spinning—fibers—membranes—dope—polyvinylidene—outer—inner |
| T7 | 87 | gas—model—mass—vapor—flow—transport—transfer—diffusion—membrane—flux |
| T8 | 80 | PVDF—membranes—phase—pore—polymer—prepared—casting—structure—porosity—properties |
| T9 | 77 | superhydrophobic—surface—angle—membrane—PVDF– membranes—contact—super-hydrophobicity—modified—sliding |
| T10 | 70 | carbon—CNTs—CNT—nanotube—nanotubes—CNIM—immobilized—membranes—membrane—MWCNTs |
| T11 | 67 | ceramic—grafting—hydrophobic—membranes—alumina—modified—sintering—angle—contact—membrane |
| T12 | 60 | juice—aroma—concentration—osmotic—fruit—compounds—apple—OMD—juices—OD |
| T13 | 59 | membranes—plasma—composite—hydrophobic—membrane—hydrophilic—surface—pore—porous—prepared |
| T14 | 52 | janus—oil—fouling—underwater—surface—hydrophilic—wetting—membrane—composite—hydrophobic |
| T15 | 48 | dye—textile—dyeing—dyes—wastewater—disperse—reactive—permeate—color—process |
| T16 | 47 | graphene—oxide—membranes—membrane—RGO—water—PVDF—surface—rejection—composite |
| T17 | 45 | ammonia—pH—biogas—removal—slurry—nitrogen—NH3+—CO2—recovery—ammonium |
| T18 | 45 | bioreactor—anaerobic—MDBR—draw—sludge—wastewater—removal—organic—OMBR/MD—OMBR |
| T19 | 41 | fermentation—ethanol—broth—butanol—glucose—sugar—separation—yeast—broths—production |
| T20 | 35 | photocatalytic—TiO2—photocatalysis—photocatalyst—dye—degradation—PMR—catalyst—photodegradation –reactor |
| T21 | 34 | acid—metals—AMD—extraction—processes—recovery—mining—treatment—pickling—pH |
| T22 | 29 | FO—draw—DS—solute—FO/MD– solutes—forward—reverse—solution—hybrid |
| T23 | 29 | photothermal—solar—PMD—conversion—solar-driven—efficient—light—energy—desalination—SMD |
| T24 | 28 | separators—experimental—transfer—temperature—membrane—thermal—mass—PTFE—results—polarization |
| T25 | 28 | fiber—water—hollow—desalination—feed—module—model—flow—rate—temperature |
| T26 | 28 | omniphobic—surface—wetting—SiNPs—SDS—reentrant—tension—membrane—membranes—nanoparticles |
| T27 | 27 | VMD—vacuum—feed—energy—heat—consumption—exergy—MVR—temperature—pump |
| T28 | 26 | heat—cost—energy—dehumidification—pump—efficiency—cooling—MD—GOR—DCMD |
| T29 | 26 | desalination—energy—technologies—RO—environmental—entropy—hybrid—generation—cost—heat |
| T30 | 25 | fouling—HA—humic—vapor-pressure—layer—decline—BSA—silica—organic—flux |
| T31 | 25 | fiber—module—modules—hollow—transfer—mass—CFD—baffles—flow—promoters |
| T32 | 25 | ethanol—selectivity—Stefan-Maxwell—ethanol-water—feed—concentration—temperature—model—mixture—solutions |
| T33 | 24 | shale—electrocoagulation—pretreatment—gas—produced—wastewater—CSG—treatment—fracking—fracturing |
| T34 | 23 | spacer—spacer-filled—channels—spacers—filament—transfer—channel—CFD—heat—Reynolds |
| T35 | 22 | biofilm—bacteria—biofouling—microbial—community—micropollutants—biofilms—compounds—MD—fouling |
| T36 | 22 | leachate—landfill—treatment—concentrate—MD—NF—organic—wastewater—H2O2—AQP |
| T37 | 21 | arsenic—removal—As(III)—As(V)—rejection—ppb—groundwater—contaminated—pH—Hg+ |
| T38 | 20 | field—permeate—VMD—water—vacuum—flux—electromagnetic—feed—magnetic—salt |
| T39 | 20 | OHE—power—PRMD—PRO—electricity—low-grade—exergy—heat—energy—efficiency |
| T40 | 20 | radioactive—decontamination—wastes—nuclear—low-level—liquid—TeMs—waste—PET—LLRW |
| T41 | 19 | process—distillation—SGMD—MD—membrane—processes—technology—sodium—review—separation |
| T42 | 19 | regeneration—desiccant—regenerator—LiCl—liquid—solution—LDAC—concentration—polarisation—temperature |
| T43 | 18 | feed—vacuum—VMD—temperature—flow—operating—rate—desalination—pressure—velocity |
| T44 | 17 | acid—hydrochloric—concentration—HCl—sulfuric—HCl—solutions—rare—feed—earth |
| T45 | 16 | ANN—neural—model—artificial—data—network—learning—accuracy—index—error |
| T46 | 16 | column—separation—hybrid—membrane-distillation—processes—shortcut—design—area—propylene—optimisation |
| T47 | 15 | fouling—MF—foulants—colloidal—cleaning—MD—silica—model—vibration—cake |
| T48 | 15 | photothermal—NPs—plasmonic—NESMD—Ag+—NiSe—light—CoSe—conversion—solar |
| T49 | 15 | urine—human—urea—diversion—nutrients—FO—nitrogen—recovery—sanitation—nutrient |
| T50 | 15 | surfactant—wetting—SDS—surfactants—wetted—membrane—PAM—surface—omniphobic—Ca2+ |
| T51 | 15 | wetting—detection—pore—intrusion—wetted—liquid—pressure—sucrose—distillate—Tf |
| T52 | 15 | oil—oily—bilge—hexane—water—emulsion—SDS—wastewaters—nylon—produced |
| T53 | 13 | chloroform—MAS—mass—VOCs—air-stripping—transfer—removal—VOC—volatile—regime |
| T54 | 12 | shale—gas—fracturing—cost—management—treatment—produced—wastewater—energy—model |
| T55 | 12 | OMW—olive—polyphenols—phenolic—TF200—DCMD—activity—TOW—TF1000—antioxidant |
| T56 | 12 | TMD—cost—design—heat—district—optimization—MD—HEN—optimal—network |
| T57 | 11 | benzene—volatile—aqueous—separation—vacuum—organic—VMD—compounds—HOVs–VOC |
| T58 | 11 | lithium—Li+—extraction—brine—HMO—brines—NF—Na+—Mg2+—recovery |
| T59 | 11 | PES—SMMs—blended—spectroscopy—nSMM—PET—TeMs—membranes—synthesized—contact |
| T60 | 11 | boron—boric—removal—permeate—020—acid—VA-AGMD—concentration—AGMD—feed |
| T61 | 10 | whey—milk—skim—lactose—dairy—IW—fouling—components—beverage—concentration |
| T62 | 10 | nickel—FGDW—FGD—retentate—fouling—wastewater—desulfurization—PRO—Mg-Si—electroplating |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aytaç, E.; Khayet, M. A Topic Modeling Approach to Discover the Global and Local Subjects in Membrane Distillation Separation Process. Separations 2023, 10, 482. https://doi.org/10.3390/separations10090482
Aytaç E, Khayet M. A Topic Modeling Approach to Discover the Global and Local Subjects in Membrane Distillation Separation Process. Separations. 2023; 10(9):482. https://doi.org/10.3390/separations10090482
Chicago/Turabian StyleAytaç, Ersin, and Mohamed Khayet. 2023. "A Topic Modeling Approach to Discover the Global and Local Subjects in Membrane Distillation Separation Process" Separations 10, no. 9: 482. https://doi.org/10.3390/separations10090482