
Improved NSGA-III with Second-Order Difference Random Strategy for Dynamic Multi-Objective Optimization


Abstract
:1. Introduction
2. Background and Related Work
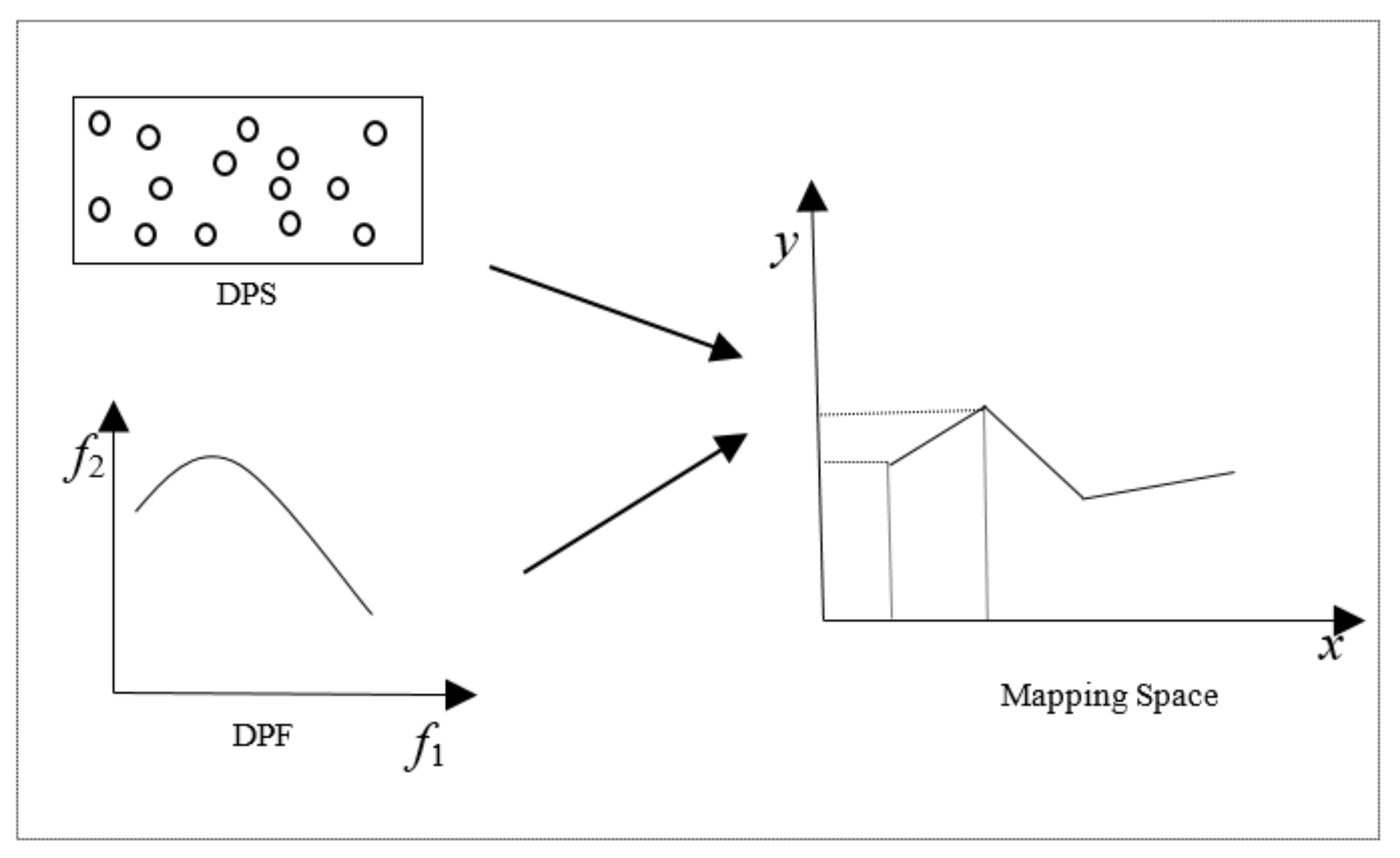
2.1. Problem Formulation
2.2. Evolutionary Algorithms for DMOPs
| Algorithm 1 The main frame of DMOEA |
| Input: the number of generations, g; the time window, T; Output: optimal solution x* at every time step; 1: Initialize population POP0; 2: while stop criterion is not met do 3: if change is detected then 4: Update the population using some strategies: reuse memory, tune parame-ters, or predict solutions; 5: T = T + 1; 6: end if 7: Optimize T-th population with an MOEA for one generation and get optimal solution x*; 8: end while 9: g = g+1; 10: return x*. |
3. NSGA-III and Proposed Strategies
3.1. NSGA-III
| Algorithm 2 The procedure of NSGA-III |
| Input: parent population, Pt; the archive population, St; i-th non-dominated front, Fi; Output: the next population, Pt+1; 1: Define a set of reference points z*; 2: Generate offspring Qt through cross and mutation using GA operator; 3: Non-dominated sorting (Rt = Pt ∪ Qt); 4: while |St| < N do 5: St = St ∪ Fi; 6: i = i + 1; 7: end while 8: Fl = Fi; 9: if |St| = N then 10: Pt+1 = St; 11: else 12: Pt+1 = F1 ∪ F2 ∪ … ∪ Fl−1; 13: end if 14: Normalize objectives and associate each solution with one reference point; 15: Calculate the number of the associated solutions; 16: Choose K = N − |Pt+1| solutions one by one from Fl; 17: return Pt+1. |
3.2. Change Detection
| Algorithm 3 Change detection |
| Input: the initial population, PT; the current number of iterations, g; the number of objective functions, F; the individual in population, p; stored individuals from past environment, Ps; the current time window, t; Output: the sign indicating whether a change occurs, flag; 1: flag = 0; 2: Select randomly individuals from population PT, and store individuals into Ps; 3: for every p∈Ps, i∈F do 4: Caculate fi(p, t); 5: fi(Ps) = fi(p, t); 6: end for 7: g = g + 1; 8: for every p∈Ps do 9: Caculate fi(p, t); 10: if fi(p, t) ≠ fi(Ps) then 11: flag = 1; 12: t = t + 1; 13: break; 14: end if 15: end for 16: return flag. |
3.3. Second-Order Difference and Random Strategies
| Algorithm 4 Second-order random strategy combined with NSGA-III |
| Input: the current population, PT; the time window, T; the number of individuals in population, N; the historic centroid points, CT−1; the centroid of time window T, CT; Output: the next population PT+1; 1: Initialize population PT and evaluate the inital population PT; 2: Change detection (PT); 3: if change is detected then 4: while the maximum number of iterations is not reached do 5: for i = 1:N do 6: if mod(i, 3) == 0 then 7: ; 8: Random perturbation around ; 9: else 10: ; 11: end if 12: Use NSGA-III to optimize and get the next generation population PT+1; 13: end for 14: end while 15: end if 16: T = T + 1; 17: return PT+1. |
4. Experiments
4.1. Benchmark Problems and Performance Metrics
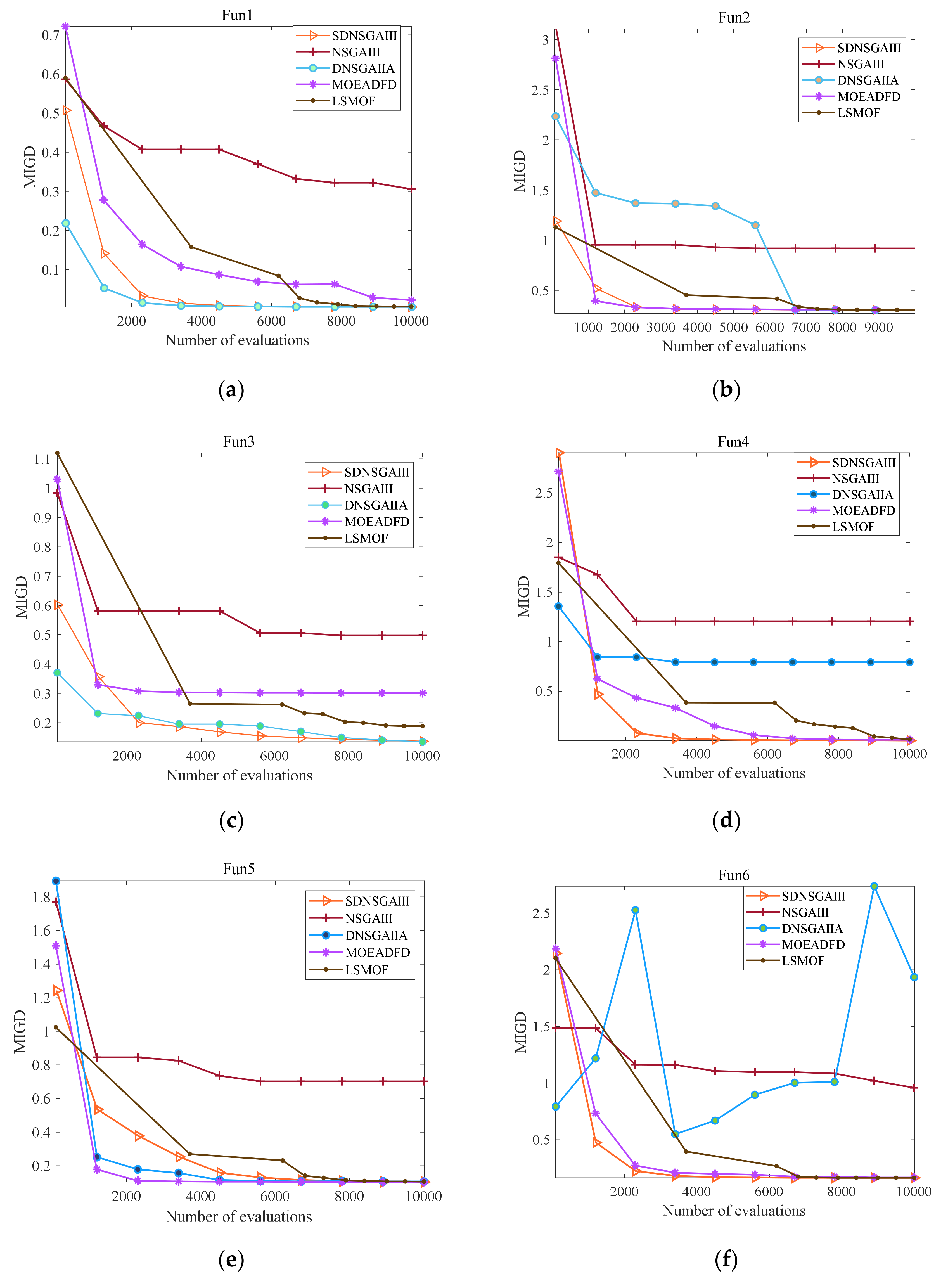
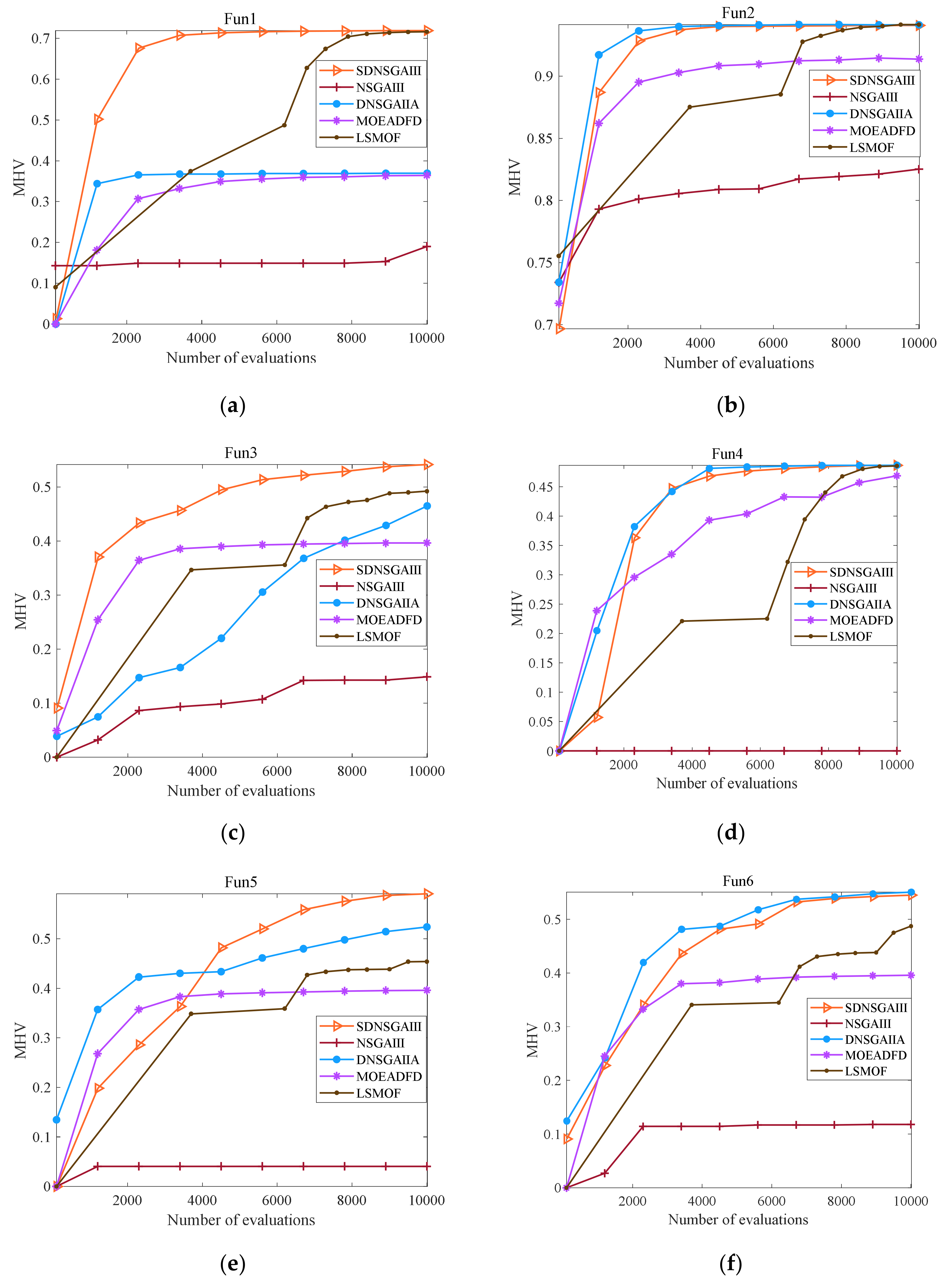
4.2. Comparative Study for the Proposed Algorithm
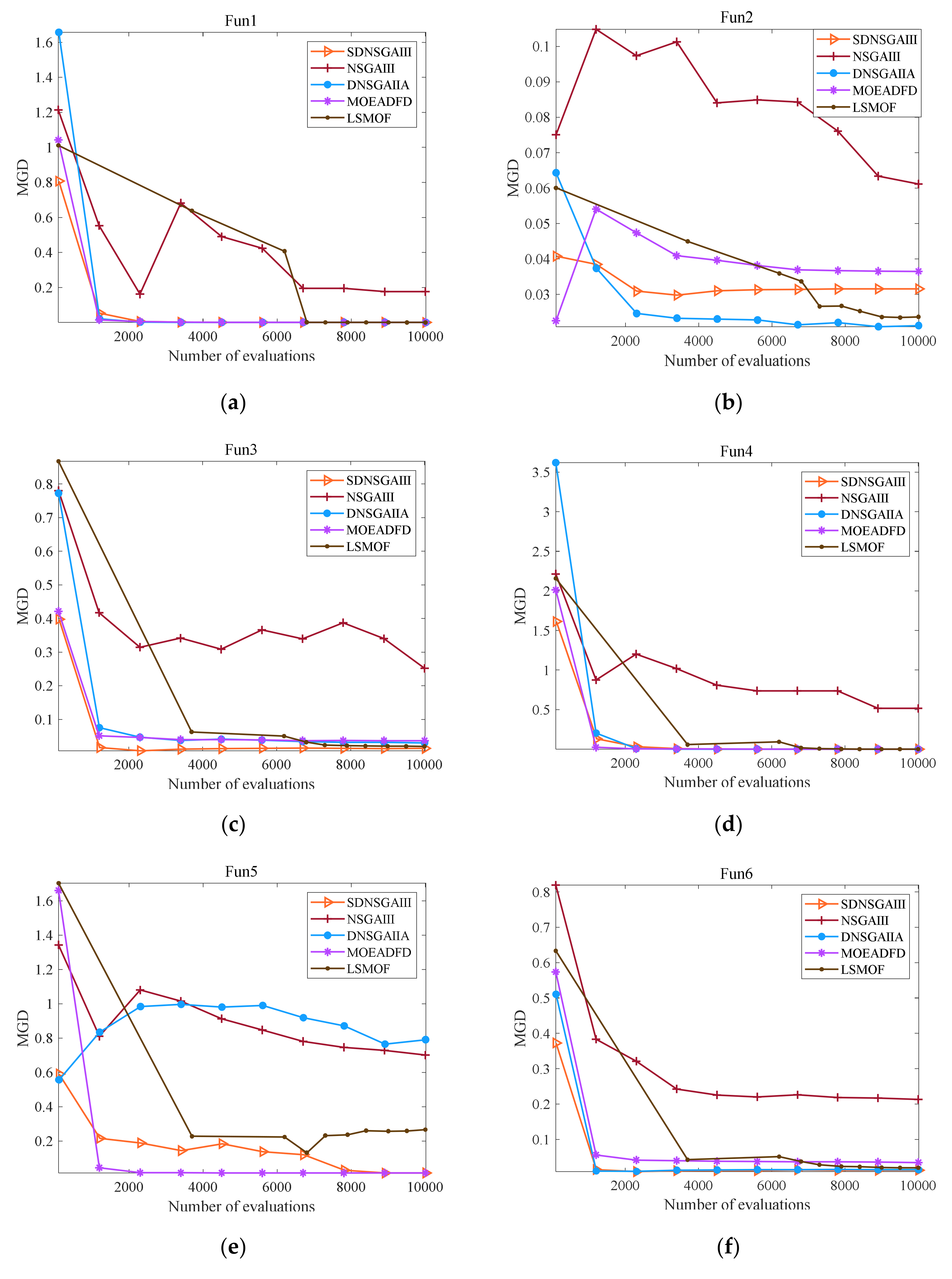
4.3. Comparative Study for Two Proposed Strategies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem | (nt, τT) | SDNSGA-III | NSGA-III | DNSGA-II-A | MOEA/D-FD | LSMOF | Percentage Difference |
|---|---|---|---|---|---|---|---|
| Fun1 | (5,5) | 9.7641e-5 (2.05e-5) | 8.3088e−1 (2.10e−1) − | 1.8830e−4 (2.55e−5) − | 5.9543e−4 (1.26e−4) − | 3.4402e−4 (8.51e−5) − | 99.99%, 48.15%, 83.60%, 71.62% |
| (5,10) | 1.0885e−4 (2.53e−5) | 2.5769e−1 (1.35e−1) − | 1.9373e−4 (3.34e−5) − | 6.2599e−4 (1.63e−4) − | 3.3416e−4 (5.25e−5) − | 99.96%, 43.81%, 82.61%, 67.43% | |
| (5,20) | 7.2249e−5 (1.40e−5) | 8.3223e−1 (2.49e−1) − | 1.5780e−4 (2.44e−5) − | 4.6507e−4 (9.94e−5) − | 1.6833e−4 (3.98e−5) − | 99.99%, 54.21%, 84.46%, 57.08% | |
| (10,5) | 9.2895e−5 (2.21e−5) | 1.6212e−1 (3.82e−2) − | 1.8772e−4 (3.37e−5) − | 6.2374e−4 (1.69e−4) − | 2.9641e−4 (7.04e−5) − | 99.94%, 50.51%, 85.11%, 68.66% | |
| (10,10) | 9.4192e−5 (1.79e−5) | 1.8184e−1 (5.75e−2) − | 1.9987e−4 (3.70e−5) − | 6.0922e−4 (1.70e−4) − | 3.5548e−4 (9.81e−5) − | 99.95%, 52.87%, 84.54%, 73.50% | |
| (10,20) | 9.6531e−5 (1.98e−5) | 2.7691e−1 (9.54e−2) − | 1.9788e−4 (3.50e−5) − | 6.2510e−4 (1.48e−4) − | 3.2505e−4 (7.25e−5) − | 99.97%, 51.22%, 84.56%, 70.30% | |
| Fun2 | (5,5) | 1.5312e−2 (3.99e−5) | 1.3209e+0 (3.64e−1) − | 5.6395e−2 (7.95e−4) − | 5.6148e−2 (2.25e−3) − | 1.5518e−2 (2.13e−4) − | 98.84%, 72.85%, 72.73%, 1.33% |
| (5,10) | 2.9755e−2 (4.91e−4) | 1.1544e+0 (2.13e−1) − | 4.9951e−2 (3.24e−4) + | 5.4658e−2 (4.02e−3) − | 3.0794e−2 (4.69e−4) − | 97.42%, 40.43%, 45.56%, 3.37% | |
| (5,20) | 1.2032e−4 (1.26e−4) | 2.7577e−1 (7.57e−2) − | 1.6799e−4 (7.21e−5) − | 8.6767e−4 (7.26e−4) − | 5.0816e−2 (1.39e−4) − | 99.96%, 28.38%, 86.13%, 99.76% | |
| (10,5) |
5.1443e−2 (4.63e−6) | 1.2241e+0 (3.38e−1) − | 5.6449e−2 (5.87e−4) − | 5.4444e−2 (2.26e−3) − | 7.9690e−3 (1.07e−4) + | 95.80%, 8.87%, 5.51%, −545.54% | |
| (10,10) | 1.5329e−2 (8.66e−5) | 2.2435e−1 (4.74e−2) − | 1.5834e−2 (1.26e−4) − | 1.6239e−2 (3.13e−4) − | 1.6044e−2 (2.18e−4) − | 93.17%, 3.19%, 5.60%, 4.46% | |
| (10,20) | 2.9301e−2 (2.01e−5) | 5.0671e−1 (1.11e−1) − | 3.1420e−2 (3.74e−4) − | 3.2043e−2 (5.79e−4) − | 3.1609e−2 (3.73e−4) − | 94.22%, 6.74%, 8.56%, 7.30% | |
| Fun3 | (5,5) | 1.4966e−2 (7.01e−3) | 2.2557e−1 (3.44e−2) − | 1.5307e−2 (7.32e−3) − | 3.8589e−2 (6.69e−4) − | 2.1146e−2 (4.48e−3) − | 93.37%, 2.23%, 61.22%, 29.23% |
| (5,10) |
1.8975e−2 (3.09e−3) | 2.2439e−1 (3.65e−2) − | 1.8150e−2 (5.22e−4) = | 4.0220e−2 (5.76e−4) − | 2.2850e−2 (3.70e−3) − | 91.54%, −4.55% 52.82%, 16.96% | |
| (5,20) | 1.4379e−2 (3.98e−3) | 2.2734e−1 (5.27e−2) − | 4.0261e−2 (1.07e−3) − | 3.4202e−2 (7.02e−3) − | 2.0892e−2 (3.83e−3) − | 93.68%, 64.29%, 57.96%, 31.17% | |
| (10,5) | 1.4928e−2 (5.67e−3) | 2.0592e−1 (4.43e−2) − | 3.7969e−2 (5.04e−4) − | 3.2770e−2 (5.84e−3) − | 2.0691e−2 (3.76e−3) − | 92.75%, 60.68%, 54.45%, 27.85% | |
| (10,10) | 1.3473e−2 (6.74e−4) | 2.1656e−1 (5.06e−2) − | 1.6858e−2 (8.05e−3) − | 3.2085e−2 (8.06e−3) − | 2.8596e−2 (4.29e−3) − | 93.78%, 20.08%, 58.01%, 52.89% | |
| (10,20) | 1.4165e−2 (5.29e−4) | 2.2959e−1 (6.38e−2) − | 1.6997e−2 (8.25e−3) = | 3.5214e−2 (5.84e−3) − | 2.1800e−2 (1.92e−3) − | 93.83%, 16.66%, 59.77%, 35.02% | |
| Fun4 | (5,5) | 5.7478e−5 (3.03e−5) | 3.0586e+0 (5.11e−1) − | 1.2177e−4 (2.95e−5) − | 5.9951e−4 (2.18e−4) − | 1.2788e−4 (1.11e−4) − | 100.00%, 52.80%, 90.41%, 55.05% |
| (5,10) | 9.8560e−6 (6.66e−6) | 3.0143e+0 (5.17e−1) − | 8.7865e−5 (3.11e−5) − | 7.3340e−4 (2.66e−4) − | 1.1863e−4 (3.68e−5) − | 100.00%, 88.78%, 98.66%, 91.69% | |
| (5,20) | 1.7514e−4 (3.61e−5) | 1.1872e+0 (4.54e−1) − | 2.0144e−4 (3.60e−5) − | 1.3375e−3 (3.92e−4) − | 3.3894e−4 (1.37e−4) − | 99.99%, 13.06%, 86.91%, 48.33% | |
| (10,5) | 8.6286e−6 (4.66e−6) | 3.2288e+0 (7.88e−1) − | 1.0346e−4 (3.86e−5) − | 8.5105e−4 (4.65e−4) − | 1.0690e−4 (3.37e−5) − | 100.00%, 91.66%, 98.99%, 91.93% | |
| (10,10) | 1.7192e−4 (3.61e−5) | 8.0273e−1 (2.86e−1) − | 1.9120e−4 (2.72e−5) − | 1.2319e−3 (5.49e−4) − | 3.0479e−4 (1.20e−4) − | 99.98%, 10.08%, 86.04%, 43.59% | |
| (10,20) | 1.5884e−4 (4.62e−5) | 6.9277e−1 (2.27e−1) − | 2.0395e−4 (2.67e−5) − | 1.3210e−3 (3.97e−4) − | 2.8649e−4 (8.88e−5) − | 99.98%, 22.12%, 87.98%, 44.56% | |
| Fun5 | (5,5) |
2.2038e−1 (2.09e−1) | 6.9385e−1 (1.30e−1) − | 8.8662e−1 (2.03e−1) − | 1.3465e−2 (5.94e−5) + | 9.6630e−1 (1.22e−1) − | 68.24%, 75.14% −1536.69%, 77.19% |
| (5,10) | 1.3050e−2 (5.39e−5) | 2.2280e−1 (5.30e−2) − | 1.3435e−2 (2.36e−4) − | 1.3153e−2 (2.04e−4) − | 1.3589e−2 (1.58e−4) − | 94.14%, 2.87%, 0.78%, 3.97% | |
| (5,20) |
1.2587e−2 (2.49e−5) | 9.3152e−1 (1.74e−1) − | 1.2475e−2 (2.03e−4) + | 1.2611e−2 (2.55e−5) − | 1.2590e−2 (2.18e−4) = | 98.65%, −0.90%, 0.19%, 0.02% | |
| (10,5) | 1.3049e−2 (4.49e−5) | 2.0971e−1 (3.26e−2) − | 1.3518e−2 (1.89e−4) − | 1.3240e−2 (2.93e−4) − | 1.3537e−2 (2.81e−4) − | 93.78%, 3.47%, 1.44%, 3.60% | |
| (10,10) | 8.0280e−3 (2.85e−6) | 1.4576e+0 (2.94e−1) − | 1.0723e+0 (1.56e−1) − | 8.0422e−3 (1.63e−5) − | 4.3435e−1 (2.46e−1) − | 99.45%, 99.25%, 0.18%, 98.15% | |
| (10,20) | 1.3176e−2 (1.01e−3) | 8.7853e−1 (1.33e−1) − | 7.4932e−1 (8.50e−2) − | 1.3472e−2 (9.12e−5) = | 4.1628e−1 (2.99e−1) − | 98.50%, 98.24%, 2.20%, 96.83% | |
| Fun6 | (5,5) | 1.4959e−2 (5.61e−3) | 2.2469e−1 (5.33e−2) − | 1.7703e−2 (8.50e−3) − | 3.7265e−2 (6.28e−4) − | 2.1705e−2 (2.33e−3) − | 93.34%, 15.50%, 59.86%, 31.08% |
| (5,10) | 1.3725e−2 (5.89e−4) | 2.1227e−1 (3.26e−2) − | 1.8282e−2 (9.14e−3) − | 3.7403e−2 (6.66e−4) − | 2.1408e−2 (1.84e−3) − | 93.53%, 24.93%, 63.31%, 35.89% | |
| (5,20) | 1.3892e−2 (7.75e−4) | 2.2927e−1 (7.10e−2) − | 1.8479e−2 (8.87e−3) − | 3.6830e−2 (3.22e−3) − | 2.1563e−2 (2.41e−3) − | 93.94%, 24.82%, 62.28%, 35.57% | |
| (10,5) | 1.4122e−2 (1.49e−3) | 2.1570e−1 (3.32e−2) − | 1.5653e−2 (5.02e−3) − | 3.5765e−2 (5.70e−3) − | 2.2094e−2 (2.74e−3) − | 93.45%, 9.78%, 60.51%, 36.08% | |
| (10,10) | 1.4963e−2 (6.00e−3) | 2.1200e−1 (3.18e−2) − | 1.6425e−2 (6.86e−3) − | 3.6488e−2 (4.24e−3) − | 2.1332e−2 (2.62e−3) − | 92.94%, 8.90%, 58.99%, 29.86% | |
| (10,20) | 1.3778e−2 (6.56e−4) | 2.1564e−1 (3.12e−2) − | 1.6983e−2 (7.13e−3) − | 3.6915e−2 (2.32e−3) − | 2.1979e−2 (2.30e−3) − | 93.61%, 18.87%, 62.68%, 7.31% |
| Problem | (nt, τT) | SDNSGA-III | NSGA-III | NSGA-IIIs | NSGA-IIIr | Percentage Difference |
|---|---|---|---|---|---|---|
| Fun1 | (5,5) | 4.1173e−3 (7.59e−5) | 1.0619× 10+0 (3.04e−1) − | 5.4190e−3 (7.05e−3) − | 4.4643e−3 (2.05e−3) − | 99.61%, 24.02%, 7.77% |
| (5,10) | 4.1621e−3 (1.09e−4) | 3.1543e−1 (6.21e−2) − | 4.1246e−3 (6.60e−5) + | 4.7086e−3 (9.61e−4) − | 98.68%, −0.91%, 11.61% | |
| (5,20) | 4.0346e−3 (6.50e−5) | 9.0279e−1 (2.77e−1) − | 4.0621e−3 (1.80e−4) − | 4.0917e−3 (2.52e−4) − | 99.55%, 0.68%, 1.40% | |
| (10,5) | 4.1143e−3 (1.10e−4) | 3.1175e−1 (4.65e−2) − | 4.1199e−3 (5.87e−5) − | 4.1204e−3 (7.92e−5) − | 98.68%, 0.14%, 0.15% | |
| (10,10) | 4.1051e−3 (7.77e−5) | 2.9676e−1 (4.29e−2) − | 4.1788e−3 (2.68e−4) − | 4.1059e−3 (6.46e−5) − | 98.62%, 1.76%, 0.02% | |
| (10,20) | 4.1219e−3 (8.22e−5) | 3.2164e−1 (6.44e−2) − | 4.1977e−3 (7.97e−5) − | 4.1297e−3 (8.09e−5) − | 98.72%, 1.81%, 0.19% | |
| Fun2 | (5,5) | 5.2642e−1 (3.66e−6) | 1.8119e+0 (4.16e−1) − | 5.2047e−1 (4.95e−3) + | 5.2795e−1 (5.98e−3) − | 70.95%, −1.14%, 0.29% |
| (5,10) | 5.2642e−1 (7.13e−6) | 1.5026e+0 (2.98e−1) − | 3.0454e−1 (1.22e−3) + | 3.0438e−1 (1.73e−3) + | 64.97%, −72.86%,72.95% | |
| (5,20) | 4.1727e−3 (1.60e−4) | 6.5787e−1 (1.70e−1) − | 5.2028e−1 (4.53e−3) − | 5.2708e−1 (6.02e−3) − | 99.37%, 99.20%, 99.21% | |
| (10,5) | 5.2642e−1 (3.09e−6) | 1.8949e+0 (2.94e−1) − | 7.8633e−2 (1.47e−4) + | 7.8664e−2 (1.37e−4) + | 72.22%, −569.46%, −569.20% | |
| (10,10) | 1.5659e−1 (1.74e−4) | 5.1829e−1 (6.53e−2) − | 1.5659e−1 (1.79e−4) = | 1.5660e−1 (1.74e−4) − | 69.79%, 0.00%, 0.01% | |
| (10,20) | 3.0300e−1 (1.75e−4) | 9.4884e−1 (1.59e−1) − | 3.0392e−1 (1.08e−4) − | 3.0397e−1 (1.69e−4) − | 68.07%, 0.30%, 0.32% | |
| Fun3 | (5,5) | 1.3632e−1 (7.43e−3) | 5.6611e−1 (4.71e−2) − | 3.2547e−1 (5.79e−4) − | 1.3567e−1 (6.25e−3) + | 75.92%, 58.12%, −0.48% |
| (5,10) | 1.7548e−1 (4.89e−3) | 6.6592e−1 (5.97e−2) − | 2.8207e−1 (8.26e−4) − | 1.2592e−1 (6.82e−3) + | 73.65%, 37.79%, −39.36% | |
| (5,20) | 1.1587e−1 (3.98e−3) | 5.2969e−1 (6.02e−2) − | 2.7057e−1 (5.31e−4) − | 2.1101e−1 (4.50e−3) − | 78.12%, 57.18%, 45.09% | |
| (10,5) | 1.2918e−1 (4.39e−3) | 5.6899e−1 (4.38e−2) − | 3.2018e−1 (2.57e−4) − | 1.6741e−1 (4.48e−2) − | 77.30%, 59.65%, 22.84% | |
| (10,10) | 1.1544e−1 (3.43e−3) | 5.3525e−1 (4.65e−2) − | 3.8872e−1 (3.76e−4) − | 1.8442e−1 (2.78e−3) − | 78.43%, 70.30%, 37.40% | |
| (10,20) | 1.3219e−1 (2.41e−3) | 5.2812e−1 (4.92e−2) − | 3.0209e−1 (4.61e−4) − | 1.3372e−1 (3.65e−3) − | 74.97%, 56.24%, 1.14% | |
| Fun4 | (5,5) | 5.5170e−3 (6.27e−3) | 3.8735e+0 (1.09e+0) − | 5.0968e−3 (6.25e−3) + | 8.4618e−3 (1.82e−2)− | 99.86%, −8.24%, 34.80% |
| (5,10) | 3.8147e−3 (5.02e−6) | 3.9172e+0 (8.90e−1) − | 7.7584e−3 (1.18e−2) − | 3.8147e−3 (5.56e−6) = | 99.90%, 50.83%, 0.00% | |
| (5,20) | 4.4876e−3 (2.97e−4) | 1.2906e+0 (4.14e−1) − | 7.0802e−3 (1.09e−2) − | 4.4741e−3 (2.72e−4) + | 99.65%, 36.62%, −0.30% | |
| (10,5) | 3.8136e−3 (3.49e−6) | 3.8130e+0 (1.09e+0) − | 7.0585e−3 (6.68e−3) − | 3.8357e−3 (1.05e−4) − | 99.90%, 45.97%, 0.58% | |
| (10,10) | 6.7897e−3 (1.31e−2) | 1.0657e+0 (2.65e−1) − | 4.7422e−3 (2.40e−3) + | 4.9961e−3 (2.52e−3) + | 99.36%, −43.18%, −35.90% | |
| (10,20) | 4.2404e−3 (2.54e−4) | 9.7821e−1 (2.73e−1) − | 4.3661e−3 (4.04e−4) − | 4.7208e−3 (2.26e−3) − | 99.57%, 2.88%, 10.18% | |
| Fun5 | (5,5) | 1.3278e−1 (3.93e−2) | 5.1958e−1 (9.60e−2) − | 1.0330e−1 (7.55e−4) + | 1.1789e−1 (1.56e−2) + | 74.44%, −28.54%, −12.63% |
| (5,10) | 1.0815e−1 (9.75e−5) | 4.6938e−1 (7.18e−2) − | 1.0816e−1 (1.38e−4) − | 1.0816e−1 (1.08e−4)− | 76.96%, 0.01%, 0.01% | |
| (5,20) | 1.1799e−1 (8.65e−6) | 1.5532e+0 (2.29e−1) − | 1.1814e−1 (7.71e−5) − | 1.1899e−1 (3.72e−6) − | 92.40%, 0.13%, 0.84% | |
| (10,5) | 1.0815e−1 (1.04e−4) | 4.6754e−1 (6.52e−2) − | 1.0816e−1 (1.27e−4) − | 1.0813e−1 (1.07e−4) + | 76.87%, 0.01%, −0.02% | |
| (10,10) | 7.0561e−2 (3.46e−5) | 1.2441e+0 (3.16e−1) − | 8.1913e−2 (3.05e−2) − | 7.0571e−2 (4.43e−5) − | 94.33%, 13.86%, 0.01% | |
| (10,20) | 1.0723e−1 (1.59e−2) | 6.1270e−1 (1.42e−1) − | 1.0480e−1 (7.60e−3) + | 1.0624e−1 (8.21e−3) + | 82.50%, −2.32%, −0.93% | |
| Fun6 | (5,5) | 1.3247e−1 (2.20e−3) | 5.4546e−1 (5.54e−2) − | 3.0250e−1 (1.09e−3) − | 1.3344e−1 (4.59e−3) − | 75.71%, 56.21%, 0.73% |
| (5,10) | 1.3335e−1 (2.65e−3) | 5.5036e−1 (5.77e−2) − | 3.0202e−1 (6.73e−4) − | 1.3311e−1 (3.58e−3) + | 75.77%, 55.85%, −0.18% | |
| (5,20) | 1.3316e−1 (3.31e−3) | 5.2619e−1 (3.90e−2) − | 3.0203e−1 (1.57e−3) − | 1.3299e−1 (2.78e−3) + | 74.69%, 55.91%, −0.13% | |
| (10,5) | 1.3188e−1 (2.01e−3) | 5.4484e−1 (4.25e−2) − | 3.0142e−1 (3.73e−3) − | 1.3242e−1 (1.94e−3) − | 75.79%, 56.25%, 0.41% | |
| (10,10) | 1.3393e−1 (3.40e−3) | 5.4706e−1 (4.81e−2) − | 3.0204e−1 (5.06e−4) − | 1.3588e−1 (1.54e−2) − | 75.52%, 55.66%, 1.44% | |
| (10,20) | 1.3261e−1 (2.65e−3) | 5.3520e−1 (5.56e−2) − | 3.0204e−1 (7.68e−4) − | 1.3396e−1 (4.10e−3) − | 75.22%, 56.10%, 1.01% |
References
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.-G.; Tan, Y. Improving metaheuristic algorithms with information feedback models. IEEE Trans. Cybern. 2019, 49, 542–555. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.-G.; Guo, L.; Gandomi, A.H.; Hao, G.-S.; Wang, H. Chaotic krill herd algorithm. Inf. Sci. 2014, 274, 17–34. [Google Scholar] [CrossRef]
- Gao, D.; Wang, G.-G.; Pedrycz, W. Solving fuzzy job-shop scheduling problem using DE algorithm improved by a selection mechanism. IEEE Trans. Fuzzy Syst. 2020, 28, 3265–3275. [Google Scholar] [CrossRef]
- Wang, G.-G.; Deb, S.; Cui, Z. Monarch butterfly optimization. Neural Comput. Appl. 2019, 31, 1995–2014. [Google Scholar] [CrossRef] [Green Version]
- Jing, S.; Zhuang, M.; Gong, D.; Zeng, X.; Li, J.; Wang, G.-G. Interval multi-objective optimization with memetic algorithms. IEEE Trans. Cybern. 2020, 50, 3444–3457. [Google Scholar]
- Chen, S.; Chen, R.; Wang, G.-G.; Gao, J.; Sangaiah, A.K. An adaptive large neighborhood search heuristic for dynamic vehicle routing problems. Comput. Electr. Eng. 2018, 67, 596–607. [Google Scholar] [CrossRef]
- Hu, Y.; Ou, J.; Zheng, J.; Zou, J.; Yang, S.; Ruan, G. Solving dynamic multi-objective problems with an evolutionary multi-directional search approach. Knowl.-Based Syst. 2020, 194, 105175. [Google Scholar] [CrossRef]
- Luo, W.; Sun, J.; Bu, C.; Liang, H. Species-based Particle Swarm optimizer enhanced by memory for dynamic optimization. Appl. Soft Comput. 2016, 47, 130–140. [Google Scholar] [CrossRef]
- Nakano, H.; Kojima, M.; Miyauchi, A. An artificial bee colony algorithm with a memory scheme for dynamic optimization problems. In Proceedings of the IEEE Congress on Evolutionary Computation (IEEE CEC), Sendai, Japan, 25–28 May 2015; pp. 2657–2663. [Google Scholar]
- Rong, M.; Gong, D.; Zhang, Y.; Jin, Y.; Pedrycz, W. Multidirectional prediction approach for dynamic multiobjective optimization problems. IEEE Trans. Cybern. 2019, 49, 3362–3374. [Google Scholar] [CrossRef]
- Rong, M.; Gong, D.; Pedrycz, W.; Wang, L. A multimodel prediction method for dynamic multiobjective evolutionary optimization. IEEE Trans. Evol. Comput. 2019, 24, 290–304. [Google Scholar] [CrossRef]
- Wu, X.; Wang, S.; Pan, Y.; Shao, H. A knee point-driven multi-objective artificial flora optimization algorithm. Wirel. Netw. 2020, 1–11. [Google Scholar] [CrossRef]
- Peng, Z.; Zheng, J.; Zou, J. A population diversity maintaining strategy based on dynamic environment evolutionary model for dynamic multiobjective optimization. In Proceedings of the IEEE Congress on Evolutionary Computation (IEEE CEC), Beijing, China, 6–11 July 2014; pp. 274–281. [Google Scholar]
- Liu, M.; Zheng, J.; Wang, J.; Liu, Y.; Lei, J. An adaptive diversity introduction method for dynamic evolutionary multiobjective optimization. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (IEEE CEC), Beijing, China, 6–11 July 2014; pp. 3160–3167. [Google Scholar]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, Part I: Solving problems with box constraints. IEEE Trans. Evol. Comput. 2013, 18, 577–601. [Google Scholar] [CrossRef]
- Farina, M.; Deb, K.; Amato, P. Dynamic multiobjective optimization problems: Test cases, approximations, and applications. IEEE Trans. Evol. Comput. 2004, 8, 425–442. [Google Scholar] [CrossRef]
- Emmerich, M.T.M.; Deutz, A.H. A tutorial on multiobjective optimization: Fundamentals and evolutionary methods. Nat. Comput. 2018, 17, 585–609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, L.; Xu, L.; Goodman, E.D.; Li, H. A first-order difference model-based evolutionary dynamic multiobjective optimization. In Proceedings of the Asia-Pacific Conference on Simulated Evolution and Learning, Shenzhen, China, 10–13 November 2017; pp. 644–655. [Google Scholar]
- Deb, K.; Karthik, S. Dynamic multi-objective optimization and decision-making using modified NSGA-II: A case study on hydro-thermal power scheduling. In Proceedings of the International Conference Evolutionary Multi-Criterion Optimization, Matsushima, Japan, 5–8 March 2007; pp. 803–817. [Google Scholar]
- Yen, G.; Lu, H. Dynamic multiobjective evolutionary algorithm: Adaptive cell-based rank and density estimation. IEEE Trans. Evol. Comput. 2003, 7, 253–274. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, J.; Yang, S.; Jiang, S.; Zhao, S. Evolutionary dynamic constrained optimization: Test suite construction and algorithm comparisons. Swarm Evol. Comput. 2019, 50, 100559. [Google Scholar] [CrossRef]
- Macias-Escobar, T.; Cruz-Reyes, L.; Fraire, H.; Dorronsoro, B. Plane separation: A method to solve dynamic multi-objective optimization problems with incorporated preferences. Future Gener. Comp. Syst. 2019, 110, 864–875. [Google Scholar] [CrossRef]
- Zou, F.; Yen, G.G.; Tang, L. A knee-guided prediction approach for dynamic multi-objective optimization. Inf. Sci. 2020, 509, 193–209. [Google Scholar] [CrossRef]
- Zhou, A.; Jin, Y.; Zhang, Q.; Sendhoff, B.; Tsang, E. Prediction-based population re-initialization for evolutionary dynamic multi-objective optimization. In Proceedings of the International Conference Evolutionary Multi-Criterion Optimization, Matsushima, Japan, 5–8 March 2007; pp. 832–846. [Google Scholar]
- Hatzakis, I.; Wallace, D. Dynamic multi-objective optimization with evolutionary algorithms: A forward-looking approach. In Proceedings of the Genetic and Evolutionary Computation Conference, Seattle, WA, USA, 8–12 July 2006; pp. 1201–1208. [Google Scholar]
- Liu, X.-F.; Zhou, Y.-R.; Yu, X.; Lin, Y. Dual-archive-based particle swarm optimization for dynamic optimization. Appl. Soft Comput. 2019, 85, 105876. [Google Scholar] [CrossRef]
- Gong, D.; Xu, B.; Zhang, Y.; Guo, Y.; Yang, S. A similarity-based cooperative co-evolutionary algorithm for dynamic interval multiobjective optimization problems. IEEE Trans. Evol. Comput. 2020, 24, 142–156. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Yen, G.G.; Jiang, M. A grey prediction-based evolutionary algorithm for dynamic multiobjective optimization. Swarm Evol. Comput. 2020, 56, 100695. [Google Scholar] [CrossRef]
- Chang, R.-I.; Hsu, H.-M.; Lin, S.-Y.; Chang, C.-C.; Ho, J.-M. Query-based learning for dynamic Particle Swarm optimization. IEEE Access 2017, 5, 7648–7658. [Google Scholar] [CrossRef]
- Liang, Z.; Wu, T.; Ma, X.; Zhu, Z.; Yang, S. A dynamic multiobjective evolutionary algorithm based on decision variable classification. IEEE Trans. Cybern. 2020, 1–14. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Yang, S. An improved particle Swarm optimization algorithm for dynamic job shop scheduling problems with random job arrivals. Swarm Evol. Comput. 2019, 51, 100594. [Google Scholar] [CrossRef]
- Luna, F.; Zapata-Cano, P.H.; González-Macías, J.C.; Valenzuela-Valdés, J.F. Approaching the cell switch-off problem in 5G ultra-dense networks with dynamic multi-objective optimization. Future Gener. Comput. Syst. 2020, 110, 876–891. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, X.; Huang, T.; Yang, C. Hybrid intelligence assisted sample average approximation method for chance constrained dynamic optimization. IEEE Trans. Ind. Inform. 2020, 1. [Google Scholar] [CrossRef]
- Chang, L.; Piao, S.; Leng, X.; Hu, Y.; Ke, W. Study on falling backward of humanoid robot based on dynamic multi objective optimization. Peer Peer Netw. Appl. 2020, 13, 1236–1247. [Google Scholar] [CrossRef]
- Cabrera, A.; Acosta, A.; Almeida, F.; Blanco, V.; Perez, A.C. A dynamic multi-objective approach for dynamic load balancing in heterogeneous systems. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2421–2434. [Google Scholar] [CrossRef]
- Zitzler, E.; Deb, K.; Thiele, L. Comparison of multiobjective evolutionary algorithms: Empirical results. Evol. Comput. 2000, 8, 173–195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kong, W.; Chai, T.; Yang, S.; Ding, J. A hybrid evolutionary multiobjective optimization strategy for the dynamic power supply problem in magnesia grain manufacturing. Appl. Soft Comput. 2013, 13, 2960–2969. [Google Scholar] [CrossRef]
- Jiang, S.; Yang, S. Evolutionary dynamic multiobjective optimization: Benchmarks and algorithm comparisons. IEEE Trans. Cybern. 2016, 47, 198–211. [Google Scholar] [CrossRef]
- Goh, C.-K.; Tan, K.C. A competitive-cooperative coevolutionary paradigm for dynamic multiobjective optimization. IEEE Trans. Evol. Comput. 2008, 13, 103–127. [Google Scholar] [CrossRef]
- Jiang, S.; Yang, S.; Yao, X.; Tan, K.C.; Kaiser, M.; Krasnogor, N. Benchmark problems for CEC2018 competition on dynamic multiobjective optimisation. In Proceedings of the IEEE Congress on Evolutionary Computation (IEEE CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Zhou, A.; Jin, Y.; Zhang, Q. A population prediction strategy for evolutionary dynamic multiobjective optimization. IEEE Trans. Cybern. 2014, 44, 40–53. [Google Scholar] [CrossRef]
- Jiang, S.; Yang, S. A steady-state and generational evolutionary algorithm for dynamic multiobjective optimization. IEEE Trans. Evol. Comput. 2016, 21, 65–82. [Google Scholar] [CrossRef] [Green Version]
- He, C.; Li, L.; Tian, Y.; Zhang, X.; Cheng, R.; Jin, Y.; Yao, X. Accelerating large-scale multiobjective optimization via problem reformulation. IEEE Trans. Evol. Comput. 2019, 23, 949–961. [Google Scholar] [CrossRef]




| Instance | Definition |
|---|---|
| Fun1 [18] | |
| Fun2 [18] | |
| Fun3 [40] | |
| Fun4 [41] | |
| Fun5 [18] | |
| Fun6 [42] |
| Problem | DPS Changes | DPF Changes |
|---|---|---|
| Fun1 | Yes | No, the DPF is convex |
| Fun2 | Yes | Yes, the DPF changes from convex to nonconvex |
| Fun3 | Yes, the time-varying nonmonotonic dependencies are introduced | Yes |
| Fun4 | Yes | Yes, the DPF changes from convex to concave |
| Fun5 | Yes | Yes, the DPF changes its shape over time |
| Fun6 | Yes, the DPS is rather simple | Yes, the DPF is sometimes linear, and sometimes concave or convex |
| Symbol | Meaning | Value |
|---|---|---|
| N | population size | 100 |
| M | the number of objectives | 2 |
| D | dimensions of decision vectors | 10 |
| FEs | fitness evaluation times | 10,000 |
| T | the time window | 20 |
| R | number of runs | 30 |
| Metrics | Fun1 | Fun2 | Fun3 | Fun4 | Fun5 | Fun6 |
|---|---|---|---|---|---|---|
| MIGD | 6 | 3 | 5 | 4 | 4 | 6 |
| MHV | 6 | 6 | 5 | 4 | 4 | 4 |
| MGD | 6 | 5 | 5 | 6 | 4 | 6 |
| Total | 18 | 14 | 15 | 14 | 12 | 16 |
| Metrics | (5,5) | (5,10) | (5,20) | (10,5) | (10,10) | (10,20) |
|---|---|---|---|---|---|---|
| MIGD | 3 | 5 | 6 | 5 | 5 | 4 |
| MHV | 5 | 5 | 6 | 5 | 4 | 5 |
| MGD | 5 | 5 | 5 | 5 | 6 | 6 |
| Total | 13 | 15 | 17 | 15 | 15 | 15 |
| Algorithms | Fun1 | Fun2 | Fun3 | Fun4 | Fun5 | Fun6 |
|---|---|---|---|---|---|---|
| SDNSGA-III | 5/5/4 | 3/3/4 | 4/5/3 | 3/4/3 | 3/2/3 | 4/3/3 |
| NSGA-III | 0/0/0 | 0/0/0 | 0/0/0 | 0/0/0 | 0/0/0 | 0/0/0 |
| NSGA-IIIs | 1/0/1 | 2/3/1 | 0/0/0 | 2/2/3 | 2/2/1 | 0/0/0 |
| NSGA-IIIr | 0/1/1 | 1/0/1 | 2/1/3 | 1/0/0 | 1/2/2 | 2/3/3 |
| Algorithms | (5,5) | (5,10) | (5,20) | (10,5) | (10,10) | (10,20) |
|---|---|---|---|---|---|---|
| SDNSGA-III | 2/2/2 | 2/5/4 | 4/3/2 | 4/5/4 | 5/3/2 | 5/4/6 |
| NSGA-III | 0/0/0 | 0/0/0 | 0/0/0 | 0/0/0 | 0/0/0 | 0/0/0 |
| NSGA-IIIs | 3/3/2 | 1/0/1 | 0/0/1 | 1/0/1 | 1/2/1 | 1/2/0 |
| NSGA-IIIr | 1/1/2 | 3/1/1 | 2/3/3 | 1/1/1 | 0/1/3 | 0/0/0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Wang, G.-G.; Dong, J.; Gandomi, A.H. Improved NSGA-III with Second-Order Difference Random Strategy for Dynamic Multi-Objective Optimization. Processes 2021, 9, 911. https://doi.org/10.3390/pr9060911
Zhang H, Wang G-G, Dong J, Gandomi AH. Improved NSGA-III with Second-Order Difference Random Strategy for Dynamic Multi-Objective Optimization. Processes. 2021; 9(6):911. https://doi.org/10.3390/pr9060911
Chicago/Turabian StyleZhang, Haijuan, Gai-Ge Wang, Junyu Dong, and Amir H. Gandomi. 2021. "Improved NSGA-III with Second-Order Difference Random Strategy for Dynamic Multi-Objective Optimization" Processes 9, no. 6: 911. https://doi.org/10.3390/pr9060911