All articles published by MDPI are made immediately available worldwide under an open access license. No special
permission is required to reuse all or part of the article published by MDPI, including figures and tables. For
articles published under an open access Creative Common CC BY license, any part of the article may be reused without
permission provided that the original article is clearly cited. For more information, please refer to
https://www.mdpi.com/openaccess.
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature
Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for
future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive
positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world.
Editors select a small number of articles recently published in the journal that they believe will be particularly
interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the
most exciting work published in the various research areas of the journal.
To simultaneously reduce automobile exhaust pollution to the environment and satisfy the demand for high-quality gasoline, the treatment of fluid catalytic cracking (FCC) gasoline is urgently needed to minimize octane number (RON) loss. We presented a new systematic method for determining an optimal operation scheme for minimising RON loss and operational risks. Firstly, many data were collected and preprocessed. Then, grey correlative degree analysis and Pearson correlation analysis were used to reduce the dimensionality, and the major variables with representativeness and independence were selected from the 367 variables. Then, the RON and sulfur (S) content were predicted by multiple nonlinear regression. A multi-objective nonlinear optimization model was established with the maximum reduction in RON loss and minimum operational risk as the objective function. Finally, the optimal operation scheme of the operating variable corresponding to the sample with a RON loss reduction greater than 30% in 325 samples was solved in Python.
Gasoline is the main fuel for small vehicles. The exhaust emitted from gasoline combustion has an important impact on the atmospheric environment [1,2]. Therefore, countries around the world have set increasingly stringent petrol quality standards (Table 1).
With the continuous improvement in the requirements for environmental protection, the quality of gasoline products is also constantly improving, in which octane number (RON) is an important index of the quality of gasoline products [3], which directly affects whether the gasoline is qualified. Therefore, in order to meet the requirements of environmental protection and reduce the emission of harmful substances in gasoline tail gas, the demand for high-octane gasoline is increasing each year.
Heavy oil usually accounts for 40–60% of crude oil, which is difficult to directly used given the high impurity content represented by sulfur (S). In order to effectively use heavy oil resources, it is necessary to develop heavy oil lighterization technology centering on FCC to convert heavy oil into gasoline, diesel and low carbon olefin [4].
As a secondary processing unit of petroleum, the fluid catalytic cracking (FCC) unit performs the task of blending slag oil and lightening heavy oil. FCC gasoline is the main source of motor gasoline, which accounts for a large proportion of fuel in many countries at present [5]. For example, more than 70% of gasoline in China is produced by FCC, so more than 95% of S and olefins in finished gasoline is from FCC. Desulfurization and dealkylation are the key to improving the quality of FCC gasoline, so FCC gasoline must be refined to meet the gasoline quality requirements. This has attracted the attention of many scholars [6,7,8,9]. In recent years, several new FCC gasoline desulfurization and olefins reduction processes have been developed abroad, such as ExxonMobil’s Octgain process [10] and Scanfining process [11], Universal Oil Products Company’s ISAL process [12], and Institute of Petrole France’s Primer-G process [6].
In order to protect the environment and reduce the emission of harmful substances in gasoline exhaust, gasoline cleanness will be necessary. The core aspect of the cleaning is to significantly reduce the contents of S, olefin, aromatic hydrocarbon, and benzene in gasoline, while maintaining a high RON [13].
With the increasing demand for high-octane gasoline at present, research on RON is also increasing [14,15,16,17,18]. The measures to improve the gasoline RON of heavy oil FCC unit are being analyzed and discussed in order to achieve the goal of increasing the gasoline RON.
RON is the most important index reflecting the gasoline combustion performance, and is used as a commodity brand of gasoline (such as #92, #95, and #89). In the process of desulfurization and olefins reduction of FCC gasoline, the octane number of gasoline is generally reduced using existing technology. Each reduction in octane rating by one unit is equivalent to a loss of about RMB 150 per ton. Take a 1 million tons/year catalytic cracking gasoline refining unit as an example, if RON loss can be reduced by 0.3 units, the economic benefit would be RMB 45 million.
The chemical process is usually modeled by data association or mechanism modeling, and some achievements have been made [19,20,21,22,23,24,25]. However, because of the complexity of the refining process and the diversity of the equipment, their operation variables (control variables) are highly nonlinear, with coupling between the relationships. Given the relatively few variables in traditional data correlation models, mechanism models for the analysis of the raw material demand do not responding to the process optimization in a timely manner, so the effect is not ideal. Recently, data mining has been widely used in various fields [26,27]. Typically, the task of data mining is to predict variables that are difficult to obtain from experiments. By fitting the function well, the predictive variable can be output quickly through the input of the independent variable. Therefore, data mining assisted by machine learning [28,29] is a good tool to solve chemical process.
Because of the complexity of the engineering process system, most engineering knowledge is based on a variety of empirical equations. Therefore, it is very difficult to excavate the internal relationship in the process of engineering. Kalogirou [30] presented a typical study, applying data mining methods to optimize and design engineering applications. Artificial neural network (ANN) was applied to the training of transient simulation data of typical solar energy system in industrial engineering. Then, genetic algorithm [31,32] was used to estimate the optimal size of the parameters according to the results of ANN. But given the “black box” nature of neural networks, this means that we don’t know how and why the neural network will produce a certain output. If we want to show the optimization process and explain the operation scheme better, applying the optimization model will be a good choice.
Sinopec Gaoqiao Petrochemical was established in 1957. It is one of the earliest petrochemical plants in China. With total assets of 19.3 billion yuan, it is one of Sinopec’s key 10 million-ton-level oil refining bases and clean oil production bases. It is the backbone enterprise of refined oil supply in Shanghai and the only fuel-lubricant oil refining enterprise in the Yangtze River Delta region, known as the cradle of China’s chemical industry.
At present, an FCC gasoline refining desulfurization unit of Sinopec Gaoqiao Petrochemical has been running for 4 years and has accumulated large amounts of historical data. The average RON loss of its gasoline products is 1.37 units (%), but the minimum RON loss of similar units is only 0.6 units. Therefore, there is still a large room for optimization.
The goal of this study was to optimize and adjust the operation plan of the FCC refinery desulfurization unit in the petrochemical plant.
2. Process and Methods
2.1. Sample
We used four years of data from April 2017 to May 2020 from Sinopec Gaoqiao Petrochemical, using the data of 325 samples, considering 354 operation sites of the FCC gasoline refining desulfurization unit, and 367 variables including 7 raw material properties, 2 properties of raw adsorbents, 2 properties of regenerative adsorbents, 2 product properties, and so on. Data acquisition information is provided in Table 2.
2.2. Modeling Purposes
Based on the data from these samples, a mathematical model was established to predict the RON loss of gasoline, and the optimum operating conditions of the samples were obtained. Under the condition of S content being no more than 5 μg/g, the RON loss of gasoline was reduced by at least 30%.
2.3. Modeling Procedures
The modeling procedure was performed according to the following steps:
Data preprocessing.
Based on the data of 325 samples, major variables were selected from 367 operational variables by dimension reduction to establish the RON loss reduction model.
According to the main variables selected, data mining technology was used to establish the RON loss prediction model, and the model was verified.
Based on the regression model, the optimization model was established. Using the computer algorithm to solve it, so as to obtain the optimal operation scheme.
2.4. Data Preprocessing
For the data comparison in this study, a common situation occurred: Some of the data only contained part of the time point, so we needed to eliminate outliers from the incomplete value free sample data.
Delete the data that is difficult to recover and correct (abbreviated as delete). Replace the blank value with the average of the data before and after the two hours (abbreviated as mean patch). For the data that can be made up, mean patch is carried out after it is removed.
When processing data, it is sometimes necessary to exclude certain outliers in order to improve the accuracy of the data. In this case, the Laida criterion, also known as the criterion, can be considered.
Assume that a set of measurement variables contains only random error. Let these variables be . Take the average of them, and denote it as x. And then calculate the residual error . The standard error is calculated by using Bessel’s formula. If the residual error of a measurement value satisfies , it is considered that the residual error belongs to the gross error and should be eliminated. Bessel’s formula is as follows:
The data preprocessing method is shown in Figure 1.
2.5. Descending Dimension
In order to establish the RON loss prediction model and the RON loss reduction model for gasoline, it was necessary to screen out the main variables that affected the model. Given the 367 variables involved, variable filtering was the top priority in the modeling. Variable screening was needed to reduce the dimension of raw materials, adsorbent properties, and operating variables. The operating variables were highly nonlinear and strongly coupled, so the main variables needed to be selected having representativeness and with the the two elements being independent.
For a screening factor or feature selection problem, the amount of computation increases exponentially as the number of variables increases, and we wanted to identify the set of variables that reflected the characteristics of the problem while minimizing the amount of computation. Thus, in essence, this is a combinatorial optimization problem. For this optimization problem, each method can only provide an approximate solution because the subset search methods and evaluation criteria are different, and the rationality of the solutions of different methods is affected by their own limitations. In order to obtain a more systematic and reasonable subset of variables, we used integration learning as a reference and used a combination of various methods to form an integration method to minimize the problems caused by the single datum and methods, and thus improve the effect.
There are many types of dimension reduction methods [33,34]. According to the data’s characteristics in this article, principal component analysis (PCA) should not be used because the variables obtained through PCA are no longer independent and representative. There were only 325 data samples and 367 variables, so direct multiple linear regression dimension reduction was not possible. If we regressed directly, there would be serious overfitting. Similarly, random forest and other machine learning algorithms were not appropriate. As such, first, we used grey relational analysis [35,36,37] to screen out the variables with a large correlation degree with octane number to identify the representative variables. Then, the Pearson correlation coefficient [38,39,40] was used to investigate the correlation between variables to obtain both representative and independent variable sets, and only one of the strongly correlated variable sets was retained. The same method was used to screen out the main variables affecting the S content.
Grey correlation degree analysis [37] provides a reliable theoretical basis for system prediction, control, and decision making. This method is suitable for time series data, that is, it can accurately and rapidly reflect the situation change in data over time. When the sample data reflect the change trend in two factors are basically the same, the shapes of the time series curve are relatively close, reflecting the high correlation degree between the two factors, or, vice versa, reflecting the low correlation degree between the two factors. The specific steps are as follows:
(1)
Deterministic analysis sequence
An index is determined as a dependent variable, and its time data series, as a reference series, denoted as . The remaining indexes are taken as independent variables, and their data sequence is taken as a comparison sequence, denoted as , where and the number of observation samples is n. Then, a two-dimensional table of for the sequence data is obtained, where the value is and .
(2)
Dimensionless processing
In order to eliminate the influence of different index dimensions on the data analysis results, variables need to be standardized.
Forward pointer:
Negative pointer:
(3)
Calculate the correlation coefficient between each factor
where , is the coefficient of the correlation between the comparison sequence and the reference sequence; is the resolution coefficient, usually taken as 0.5; and and are the two-stage minimum difference and the two-stage maximum difference, respectively.
(4)
Calculate the correlation degree between all the variables
2.6. Regression
Among the many statistical models, the multiple regression model is the most frequently used [41,42,43]. If the relationship between dependent variables and independent variables can be expressed in linear form, multiple linear regression models can be used for analysis. The multiple linear regression model uses the known data set to fit the dependent variables of interest and the main influencing factors, and then the effect of the influencing variables can be analyzed through the obtained linear expression to explain and predict the changing trend in the dependent variables with the changes in these influencing factors.
The ordinary linear regression model of dependent variable y and variable is:
where is the regression constant, , represents the regression coefficient; y is the predictive variable; , is the explanatory variable; and is the random error term. Moreover, it is assumed that . When , the above ordinary linear regression model is a unitary linear regression model; when , it is a multiple linear regression model.
In practical problems, the relationship between dependent variables and independent variables of many regression models is not linear, and some regression models can be transformed into linear relationships by functional transformation of independent variables or dependent variables, and linear regression can be used to solve unknown parameters and perform regression diagnosis. Common transformations are shown in Table 3.
2.7. Optimization
The first determining objective functions were the largest RON loss decline and minimum operation risk. According to the problem, the corresponding constraint conditions were given to establish a multi-objective nonlinear optimization model [44]. Then, we transformed the multi-objective model into single-objective optimization model, and by introducing a new variable to the absolute value, nonlinear optimization becomes linear optimization. Finally, the optimal operation scheme of operation variables was obtained by Python.
In practice, the multi-objective problem is widely used, and there are many methods available to solve this problem. Generally, the basic approach involves transforming solving the multi-objective problem into solving a single-objective problem.
The common methods to transform multi-objective problem into single-objective problem include optimization method, linear weighted sum method, stratified sequencing method and so on. When one objective is clearly important among multiple objectives, optimization method is more appropriate.
Multi-objective programming is generally expressed as:
Optimization method can optimize the main objective while taking into account other objectives, then the problem becomes to find the optimal value of the main objective. Other objectives are constraining conditions that limit their variation within a certain range. Thus, multi-objective problem can be reduced to the following single-objective problem.
3. Results and Discussion
3.1. Filtering of Major Variables
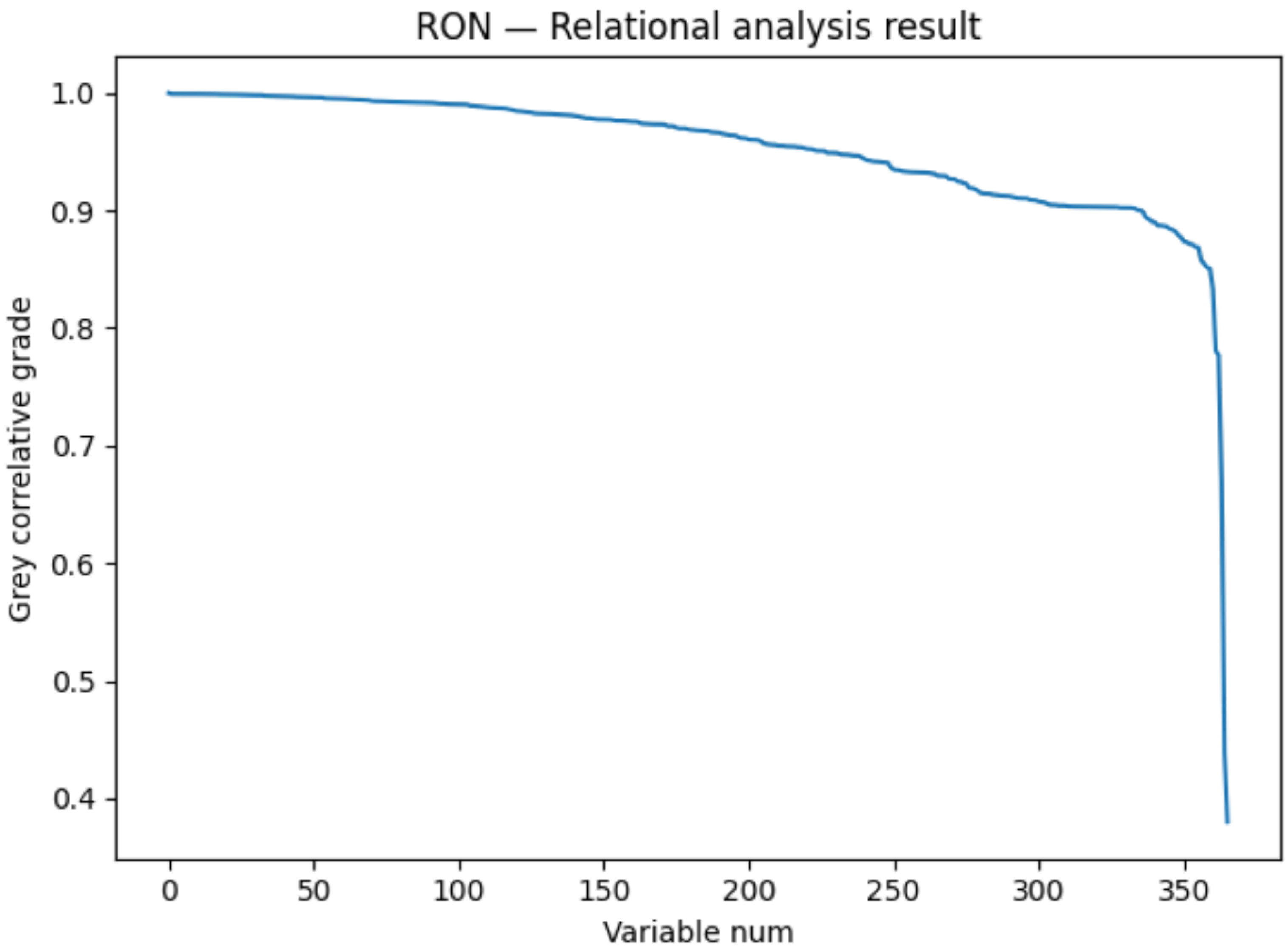
The idea of reducing dimensionality first and then modeling is often used in engineering problems. In order to screen out the main variables affecting the model, the grey correlation degree analysis was first used to screen out the variables with a greater correlation degree with RON to obtain representative variables. It was solved in Python to produce Figure 2.
After obtaining the grey correlative degree results of the independent variables and RON, we found that most of the non-operated variables in the independent variables are ranked in the top 150 of the grey correlative degree results, and most of the variables after the 150 are operated variables. This is also logical, because it is the non-operated variables that have a decisive impact on the change of RON, and the operated variables can only play an auxiliary role.
We can know from Figure 2 that the grey correlative degree of variables after the number of 150 began to decline significantly. If we choose more than 150 variables, this will not significantly increase the number of final independent variables. The variables after 150 are basically operating variables that have a relatively general impact on RON and they will have a strong relationship with the operated variables in the top 150 variables. These added variables will be replaced by the top 150 variables in the correlation analysis. So we finally adopted 150 as the demarcation point.
Perform Pearson correlation analysis on these 150 variables. Only one of them was kept in the strongly correlated variable group, identifying 19 variables that were representative and independent. The variable names and properties are shown in Table 4.
The correlation coefficients of these 19 variables are shown in Table 5.
As shown in Table 5, we found independence between variables. Therefore, these 19 variables are both representative and independent major variables affecting the gasoline RON.
The 14 main variables affecting S content were obtained by the same method. The variable names and properties are shown in Table 6.
The correlation coefficients of these 14 variables are shown in Table 7.
As shown in Table 7, we found independence between variables. Therefore, these 14 variables were found to be both representative and independent main variables affecting S content.
3.2. Regression Analysis Model
First, the screened variables were taken as independent variables, the RON and S content of the product were taken as dependent variables to establish a multiple regression model, and the T-test and F-test were carried out to construct the product prediction model.
The logarithm model, inverse model, quadratic model, and combination model were transformed into linear regression separately in the form shown in Table 3.
Then, stepwise regression analysis was used for the linear model, logarithm model, inverse model, quadratic model, and combination model, separately. We used mean square error (MSE) as the evaluation criterion to determine the optimal case in each model. The optimal model of various models were obtained and their effects were recorded as shown in Table 8.
In this study, the MSE and MAE were selected as the measurement indexes of the prediction effect and prediction accuracy.
Mean square error:
Mean absolute error:
Then, we compared these models to obtain Figure 3.
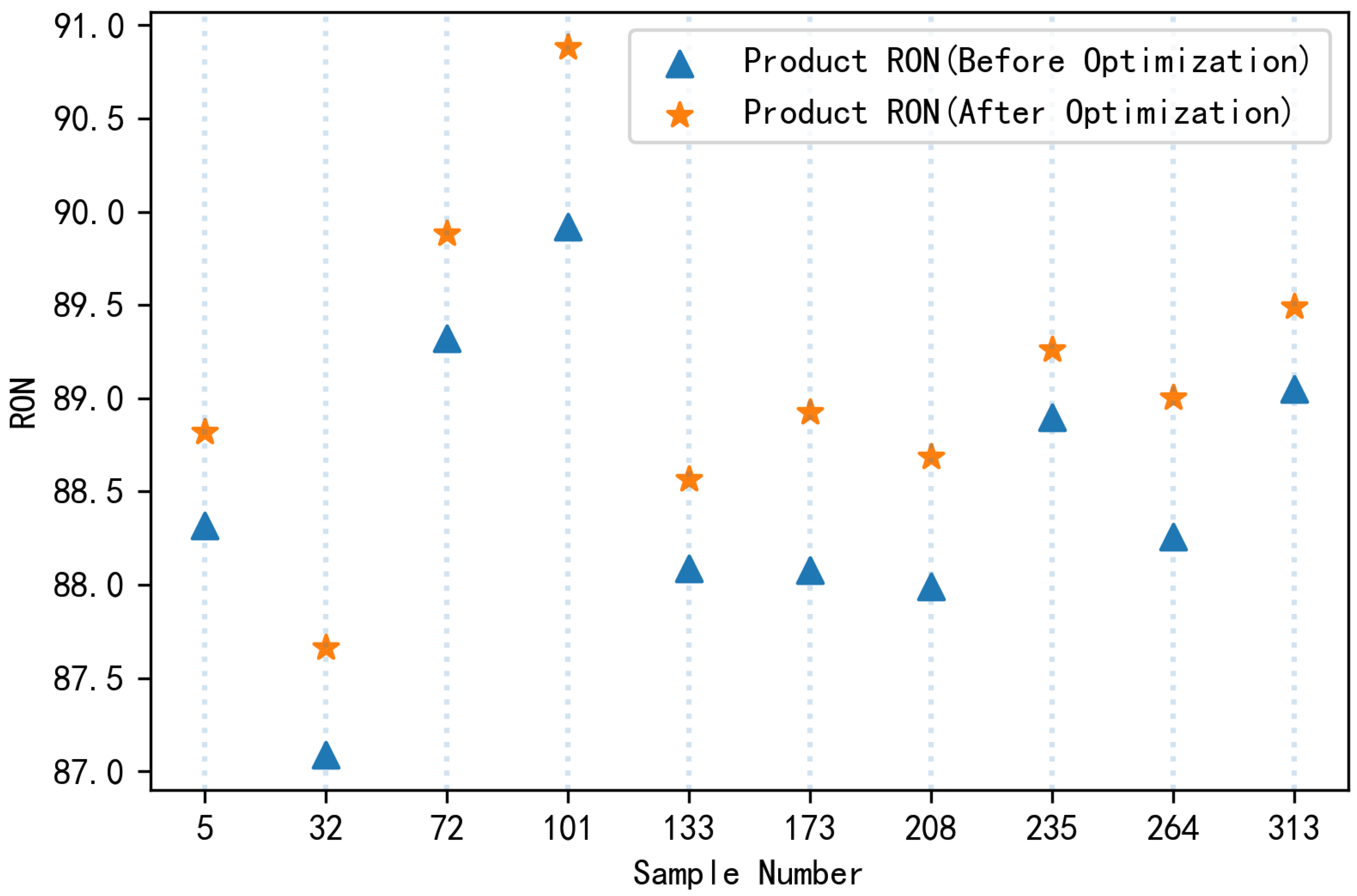
As shown in Figure 3, both the MSE and MAE of the combination model were obviously the smallest, and was also the best, so we chose the combination model.
Based on the 325 sample data and using the main variables selected, the product RON was used as the predictive variable in the least squares method, and the variables with were eliminated by the t-test. The optimal model of combination model was obtained as
which can be abbreviated to
Similarly, the S content prediction model was obtained
That is,
The symbolic descriptions of (12) and (14) were listed in Table 9.
It should be noted that and are the same variable, and and are also the same variable, so there is a certain correlation between the product RON and S content in the production process.
3.3. RON Loss Reduction Multi-Objective Optimization Model
Our goal was to optimize and adjust the operation plan of the FCC refinery desulfurization unit in the petrochemical plant to try to reduce the RON loss of gasoline by more than 30% under the premise of ensuring the desulfurization effect of gasoline products (S content being not more than 5 μg/g). In addition to the consideration of RON loss and operational risk, other factors such as the range of operational variables for the feasibility of S content operations were also considered. Only after the comprehensive measurement of all factors can the decision be more reasonable, which is a typical multi-objective optimization problem.
Combined with the actual situation, we ignored the minor factors. Therefore, we set up two objective functions: maximum RON loss reduction and minimum operational risk.
3.3.1. Objective Function 1
Taking the maximum RON loss reduction as the target, the corresponding function relation was obtained: RON loss = original RON loss – adjusted RON loss. If represents raw material RON, represents original product RON, and represents adjusted product RON, then RON loss can be expressed as
Substitute (12) into the above equation to obtain the objective function
3.3.2. Objective Function 2
In order to minimize the operational risk, we wrote the corresponding function relations. In the actual engineering operation process, for either manual adjustment or computer or machine control, each operation may pose certain risks: the less, the better. The original value of is denoted by , and represents the maximum amount of change in the operation variable each time. The original value of is denoted by , and represents the maximum amount of change in the operation variable each time. As are not operation variables, in the function expression for the number of operations of RON. As are not operation variables, in the function expression for the number of operations of S content. In addition, the number of operations that need to change but do not reach a multiple of and should be rounded up, even if it is less than and . Then, the objective function with the smallest number of operations can be expressed as
However, the number of operations is related to the variable, and the relationship containing the variable needs to be rounded up. This was difficult to achieve in the solver process, so we needed to remove the integer symbol. After removing the integer symbol, this expression expresses the relative modification range. Similarly, the smaller the relative modification range, the fewer the operation times, and the lower the operation risk. Therefore, the function expression of objective function 2 can be expressed as
3.3.3. Constraint Condition 1
First, since optimization was carried out, the product RON after the optimized operation had to be larger than the previous product RON ; otherwise, the optimization would be meaningless. In addition, the product RON was transformed from the raw material RON, so the product RON after optimized operation could not be greater than the raw material RON . Therefore, the constraint condition1 was
3.3.4. Constraint Condition 2
Our goal was to reduce the RON loss of gasoline to more than 30% under the condition that the S content was no more than 5 μg/g, so we needed to restrict the S content to less than or equal to 5 μg/g. Therefore, the constraint condition 2 was
3.3.5. Constraint Condition 3
Due to process requirements and operation experience, each operation variable has its operating range, with denoting the operating range corresponding to , and denoting the operating range corresponding to . In addition, are not operation variables, so for and for . Therefore, the corresponding constraint condition 3 is
It ensures the robustness of the model. Because as long as the variable meets the constraints of the scope of operation, the operability of the solution can be guaranteed.
3.3.6. Constraint Condition 4
As and are the same variable, and and are also the same variable, the constraint condition 4 is
3.3.7. Constraint Condition 5
As are not operation variables, they are equal to their original value and do not change, so the constraint condition 5 is
By sorting out the above objective function and constraint conditions, the multi-objective nonlinear optimization model of the RON loss reduction is expressed as
Although the RON loss reduction multi-objective optimization model was established, we found that there were two urgent problems to be addressed before solving: The dual objective needed to be changed into a single objective and the absolute values needed to be removed, and nonlinear programming needed to be changed into linear programming. Then, we used Python to solve the model.
Here, RON loss reduction was an obviously important main goal, so risk minimization was set as a constraint condition to transform the multi-objective problem into a single-objective problem. We set the maximum value of the constraint range corresponding to operational risk as T, then the RON loss reduction multi-objective nonlinear optimization model was transformed into the single-objective nonlinear model.
There were also absolute values in the model, so the nonlinear optimization was changed into linear optimization by introducing new variables to the absolute value. We introduced the non-negative variable and
Let
Thus,
In conclusion, the multi-objective nonlinear optimization model is transformed into
We used SLSQP in Python to solve the model. Some adjustments to the sample with a loss reduction of 30% were in Table 10.
Where, N represents total number of adjustments, denotes the number of adjustments of the variable with the largest number of adjustments.
Note that in the model, the larger the T, the more samples can reach the 30% loss reduction. The T value is usually set according to practical experience. In this study, it was set to 120. After calculation, we found that 245 of the 325 samples achieved 30% loss reduction, that is, 78.2% reached the target, indicating that a good effect was achieved.
We randomly selected 10 samples with a loss reduction greater than 30% and compared the product RON before and after optimization to obtain Figure 4.
The operation scheme of the main variables of some samples whose loss reduction was greater than 30% is provided in Table 11.
It can be seen from Table 11 that and need not to be adjusted, while ,,, are optimal in the fixed state regardless of which sample.
Their feature descriptions are summarized into Table 12.
From the above results, we can briefly summarize the optimal operation scheme. For any sample, adjust S-ZORB.TE_2103.PV, S-ZORB.FT_9002.DACA, S-ZORB.TE_5004.DACA to 410, 650, 40 respectively. S-ZORB.FC_2801.PV, S-ZORB.TE_2501.DACA, S-ZORB. TXE_3201A.DACA need be adjusted differently depending on the initial state. And there is no need to adjust S-ZORB.TE_1203.PV, S-ZORB.PDC_2702.DACA.
4. Conclusions
This research was conducted on the basis of four years’ data from Sinopec Gaoqiao Petrochemical, including 325 samples, 354 operation sites of the FCC gasoline refining desulfurization unit, and 367 variables. Data preprocessing was first carried out on these data. Then, the main variables were selected from 367 operational variables through grey correlation analysis and Pearson correlation analysis. Then, according to the selected major variables, the RON loss prediction model was established by multiple regression analysis, and the model was verified. The same method was used to predict S content. Notably, and are the same variable and and are also the same variable, so there is a certain correlation between product RON and S content in the production process. In the end, under the condition that the S content would be no more than 5 μg/g, the reduction in RON loss was more than 30%, and the operating conditions after the optimization of the major variables were obtained.
We presented a new systematic method for determining an optimal operation scheme for minimising RON loss and operational risks. For the data with highly nonlinear and strongly coupled, it was preprocessed first, dimension reduction and regression prediction were carried out, finally an optimization model was established to solve the optimization scheme. With the system we’ve built, just input data that needs to be improved, operation scheme to reduce RON loss can be output.
This system can be applied to the dimensionality reduction, prediction, and operation scheme optimization of data with the same properties. The regression model in the paper can be used to fields related to forecasting, such as medical care, geography, finance, and industry. The optimization model is suitable for optimizing model parameters, seeking extreme values, and so on. The optimization model is based on the regression model, which can well solve most of the problems that require modeling or optimization due to data clutter, such as the establishment of a bank credit information system, the measurement of the effectiveness of biomedical reagents, etc.
Author Contributions
Conceptualization, X.L. and T.J.; methodology, X.L. and M.X.; software, Y.L. and X.H.; validation, X.L. and T.J.; data curation, Y.L. and X.H.; writing–review and editing, X.L. and M.X.; visualization, Y.L. and X.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (11971433) and First Class Discipline of Zhejiang-A (Zhejiang Gongshang University-Statistics 1020JYN4120004G-091), Zhejiang Provincial Department of Education (Y202045232).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
FCC
fluid catalytic cracking
RON
octane number
S
sulfur
ANN
artificial neural network
PHD
Doctor of Philosophy
LIMS
Laboratory Information Management System
PCA
principal component analysis
MSE
mean square error
MAE
mean absolute error
SLSQP
Sequential Least Squares Programming
References
Gaffney, J.S.; Marley, N.A.; Martin, R.S.; Dixon, R.W.; Reyes, L.G.; Popp, C.J. Potential air quality effects of using ethanol-gasoline fuel blends: A field study in Albuquerque, New Mexico. Environ. Sci. Technol.1997, 31, 3053–3061. [Google Scholar] [CrossRef]
Nelson, P.; Quigley, S. The hydrocarbon composition of exhaust emitted from gasoline fuelled vehicles. Atmos. Environ.1984, 18, 79–87. [Google Scholar] [CrossRef]
Barcia, P.S.; Silva, J.A.; Rodrigues, A.E. Adsorption dynamics of C5–C6 isomerate fractions in zeolite beta for the octane improvement of gasoline. Energy Fuels2010, 24, 1931–1940. [Google Scholar] [CrossRef]
Ahmadlou, M.; Rezakazemi, M. Computational fluid dynamics simulation of moving-bed nanocatalytic cracking process for the lightening of heavy crude oil. J. Porous Media2018, 21. [Google Scholar] [CrossRef]
Samolada, M.; Baldauf, W.; Vasalos, I. Production of a bio-gasoline by upgrading biomass flash pyrolysis liquids via hydrogen processing and catalytic cracking. Fuel1998, 77, 1667–1675. [Google Scholar] [CrossRef]
Shih, S.; Owens, P.; Palit, S.; Tryjankowski, D. Mobil’s OCTGAIN™ Process: FCC Gasoline Desulfurization Reaches a New Performance Level. In Proceedings of the NPRA 1999 Annual Meeting, San Antonio, TX, USA, 21–23 March 1999. [Google Scholar]
Zainullin, R.; Koledina, K.; Akhmetov, A.; Gubaidullin, I. Kinetics of the catalytic reforming of gasoline. Kinet. Catal.2017, 58, 279–289. [Google Scholar] [CrossRef]
Ayanoğlu, A.; Yumrutaş, R. Production of gasoline and diesel like fuels from waste tire oil by using catalytic pyrolysis. Energy2016, 103, 456–468. [Google Scholar] [CrossRef]
Wang, W.; Wang, S.; Wang, Y.; Liu, H.; Wang, Z. A new approach to deep desulfurization of gasoline by electrochemically catalytic oxidation and extraction. Fuel Process. Technol.2007, 88, 1002–1008. [Google Scholar] [CrossRef]
Nocca, J.; Cosyns, J.; Debuisschert, Q.; Didillon, B. The domino interaction of refinery processes for gasoline quality attainment. In Proceedings of the NPRA Annual Meeting, San Antonio, TX, USA, 26–28 March 2000. [Google Scholar]
Halbert, T.R.; Greeley, J.P. Technology options for meeting low sulfur targets. In Proceedings of the NPRA Annual Meeting, AM-00-11, San Antonio, TX, USA, 26–28 March 2000. [Google Scholar]
Nelson, P.; George, J.; Edward, J. Meeting gasoline pool sulfur and octane targets with ISAL (r) process. In Proceedings of the NPRA Annual Meeting, AM-00-52, San Antonio, TX, USA, 23–25 March 2000. [Google Scholar]
Jiang, H.; Huang, S. Eight-lump reaction kinetic model for the maximizing isoparaffin process for cleaning gasoline and enhancing propylene yield. Energy Fuels2016, 30, 10770–10776. [Google Scholar] [CrossRef]
Sadighi, S.; Zahedi, S.; Hayati, R.; Bayat, M. Studying Catalyst Activity in an Isomerization Plant to Upgrade the Octane Number of Gasoline by Using a Hybrid Artificial-Neural-Network Model. Energy Technol.2013, 1, 743–750. [Google Scholar] [CrossRef]
Hamadi, A.S. Selective additives for improvement of gasoline octane number. Tikrit J. Eng. Sci.2010, 17, 22–35. [Google Scholar]
Daly, S.R.; Niemeyer, K.E.; Cannella, W.J.; Hagen, C.L. Predicting fuel research octane number using Fourier-transform infrared absorption spectra of neat hydrocarbons. Fuel2016, 183, 359–365. [Google Scholar] [CrossRef] [Green Version]
Santikunaporn, M.; Alvarez, W.E.; Resasco, D.E. Ring contraction and selective ring opening of naphthenic molecules for octane number improvement. Appl. Catal. A Gen.2007, 325, 175–187. [Google Scholar] [CrossRef]
Diwekar, U.M.; Rubin, E. Stochastic modeling of chemical processes. Comput. Chem. Eng.1991, 15, 105–114. [Google Scholar] [CrossRef] [Green Version]
Te Braake, H.; Van Can, H.; Verbruggen, H. Semi-mechanistic modeling of chemical processes with neural networks. Eng. Appl. Artif. Intell.1998, 11, 507–515. [Google Scholar] [CrossRef]
Rice, R.G.; Do, D.D. Applied Mathematics and Modeling for Chemical Engineers; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
Tränkle, F.; Zeitz, M.; Ginkel, M.; Gilles, E. PROMOT: A modeling tool for chemical processes. Math. Comput. Model. Dyn. Syst.2000, 6, 283–307. [Google Scholar] [CrossRef]
McBride, K.; Sundmacher, K. Overview of surrogate modeling in chemical process engineering. Chem. Ing. Tech.2019, 91, 228–239. [Google Scholar] [CrossRef] [Green Version]
Kulov, N.; Gordeev, L. Mathematical modeling in chemical engineering and biotechnology. Theor. Found. Chem. Eng.2014, 48, 225–229. [Google Scholar] [CrossRef]
Ni, J.; Zhou, Y.; Li, S. Hamiltonian Monte Carlo-Based D-Vine Copula Regression Model for Soft Sensor Modeling of Complex Chemical Processes. Ind. Eng. Chem. Res.2020, 59, 1607–1618. [Google Scholar] [CrossRef]
Xuan, Z.; Wei, G.; Ni, Z.; Zhang, J. Decoupling Offloading Decision and Resource Allocation via Deep Reinforcement Learning and Sequential Least Squares Programming. In Proceedings of the International Conference on Communications and Networking, Shanghai, China, 20–21 November 2020; pp. 554–566. [Google Scholar]
Sultana, N.; Hossain, S.; Taher, S.; Khan, A.; Razzak, S.; Haq, B. Modeling and optimization of non-edible papaya seed waste oil synthesis using data mining approaches. S. Afr. J. Chem. Eng.2020, 33, 151–159. [Google Scholar] [CrossRef]
Arendt, K.; Jradi, M.; Wetter, M.; Veje, C.T. Modestpy: An open-source python tool for parameter estimation in functional mock-up units. In Proceedings of the American Modelica Conference, Cambridge, MA, USA, 9–10 October 2018. [Google Scholar]
Kalogirou, S.A. Optimization of solar systems using artificial neural-networks and genetic algorithms. Appl. Energy2004, 77, 383–405. [Google Scholar] [CrossRef]
Kumar, M.; Husain, M.; Upreti, N.; Gupta, D. Genetic Algorithm: Review and Application; SSRN 3529843; SSRN: Rochester, NY, USA, 2010. [Google Scholar]
Whitley, D. A genetic algorithm tutorial. Stat. Comput.1994, 4, 65–85. [Google Scholar] [CrossRef]
Liu, X.; Liu, Y.; He, X.; Xiao, M.; Jiang, T.
Multi-Objective Nonlinear Programming Model for Reducing Octane Number Loss in Gasoline Refining Process Based on Data Mining Technology. Processes2021, 9, 721.
https://doi.org/10.3390/pr9040721
AMA Style
Liu X, Liu Y, He X, Xiao M, Jiang T.
Multi-Objective Nonlinear Programming Model for Reducing Octane Number Loss in Gasoline Refining Process Based on Data Mining Technology. Processes. 2021; 9(4):721.
https://doi.org/10.3390/pr9040721
Chicago/Turabian Style
Liu, Xiao, Yilai Liu, Xuejun He, Min Xiao, and Tao Jiang.
2021. "Multi-Objective Nonlinear Programming Model for Reducing Octane Number Loss in Gasoline Refining Process Based on Data Mining Technology" Processes 9, no. 4: 721.
https://doi.org/10.3390/pr9040721
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.
Article Metrics
No
No
Article Access Statistics
For more information on the journal statistics, click here.
Multiple requests from the same IP address are counted as one view.
Liu, X.; Liu, Y.; He, X.; Xiao, M.; Jiang, T.
Multi-Objective Nonlinear Programming Model for Reducing Octane Number Loss in Gasoline Refining Process Based on Data Mining Technology. Processes2021, 9, 721.
https://doi.org/10.3390/pr9040721
AMA Style
Liu X, Liu Y, He X, Xiao M, Jiang T.
Multi-Objective Nonlinear Programming Model for Reducing Octane Number Loss in Gasoline Refining Process Based on Data Mining Technology. Processes. 2021; 9(4):721.
https://doi.org/10.3390/pr9040721
Chicago/Turabian Style
Liu, Xiao, Yilai Liu, Xuejun He, Min Xiao, and Tao Jiang.
2021. "Multi-Objective Nonlinear Programming Model for Reducing Octane Number Loss in Gasoline Refining Process Based on Data Mining Technology" Processes 9, no. 4: 721.
https://doi.org/10.3390/pr9040721
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.








{kind=link}
{kind=link}
{kind=link}
{kind=link}