Temporal Feature Selection for Multi-Step Ahead Reheater Temperature Prediction

Abstract
:1. Introduction
2. System Description and Problem Statement
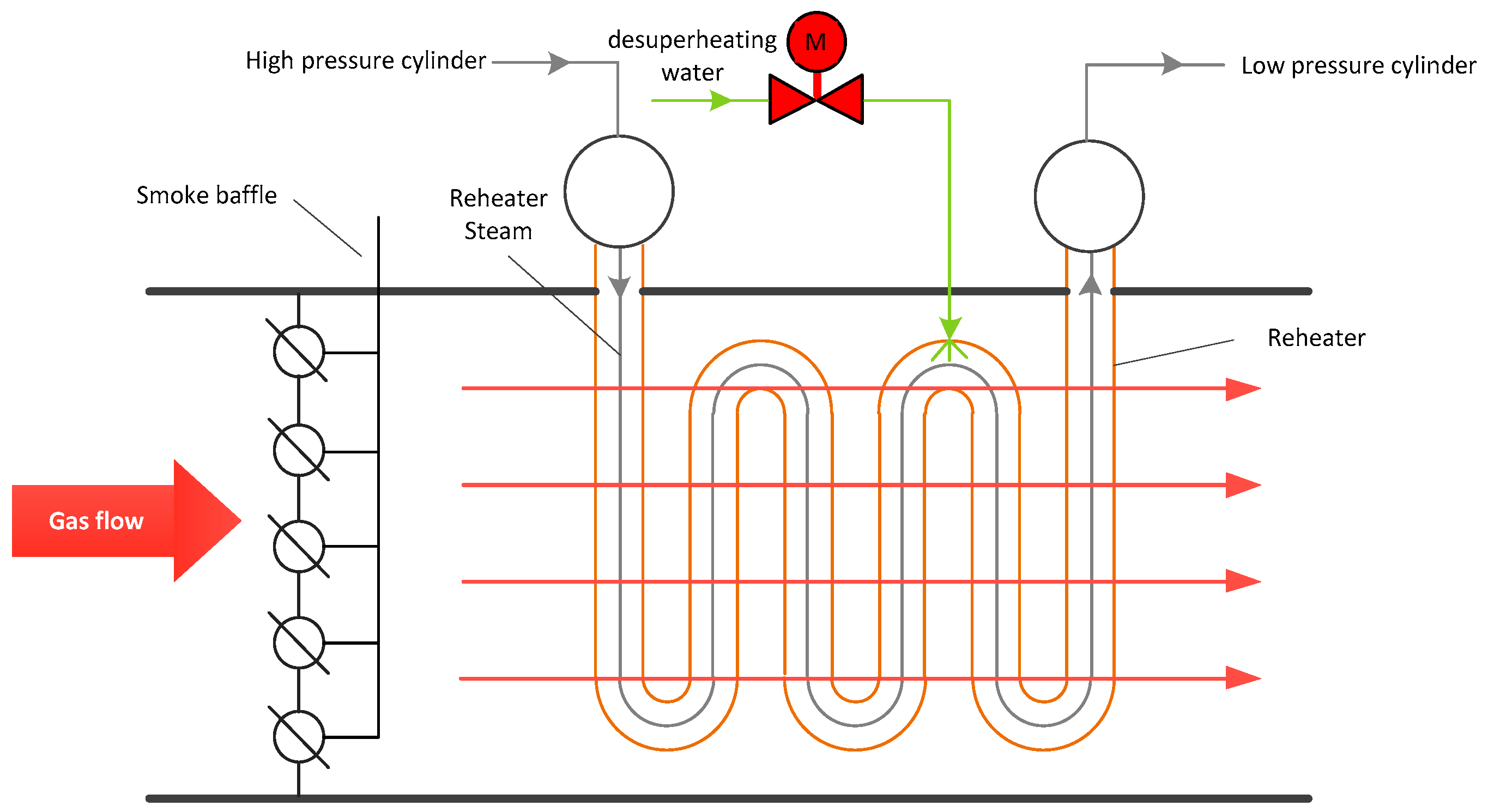
2.1. Description of Reheater System
2.2. Problem Statement
3. Objective Function for Model Evaluation
3.1. Multi-Step Prediction
3.2. Optimization Function
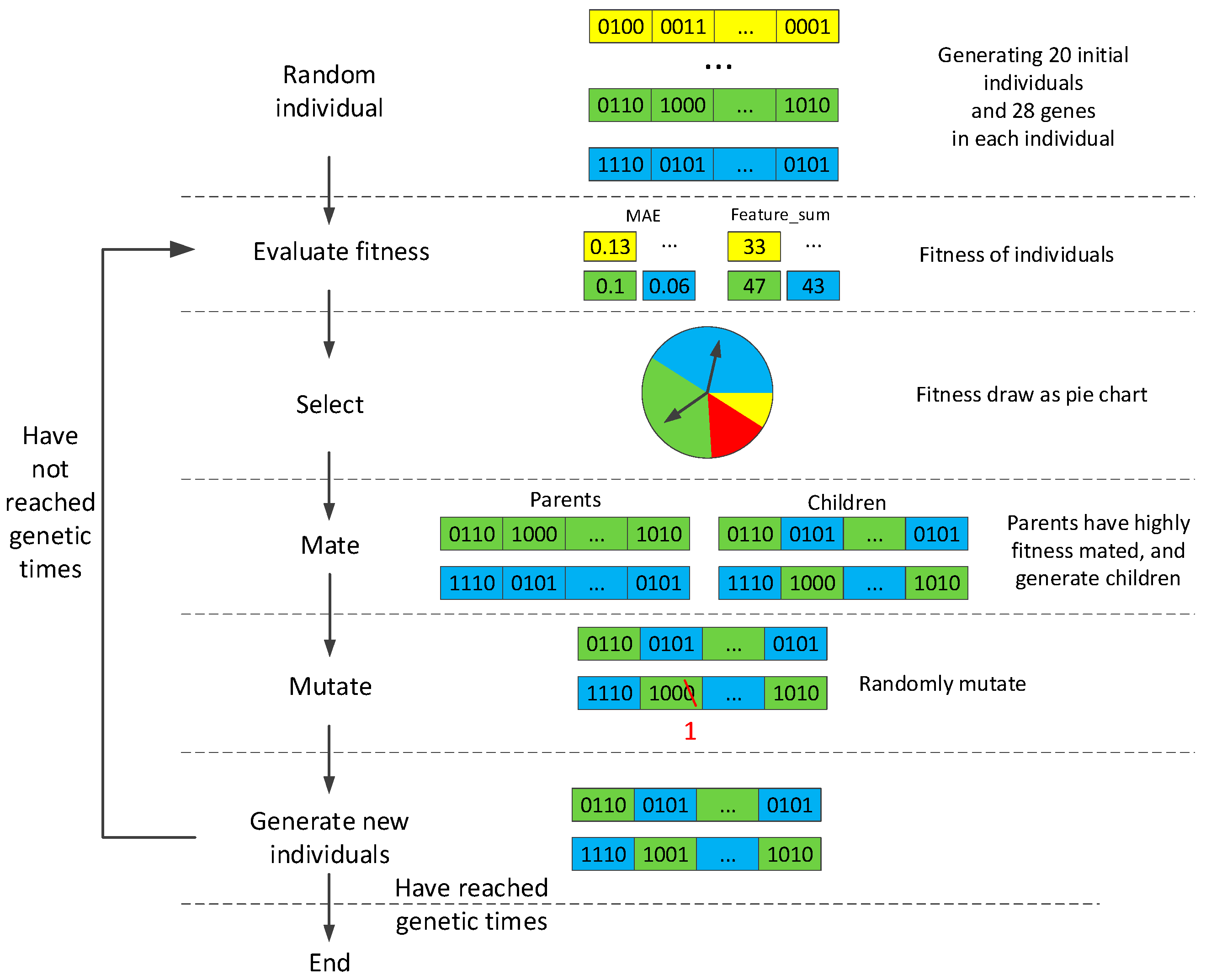
4. Delay Order Selection
4.1. Delay Order Optimization
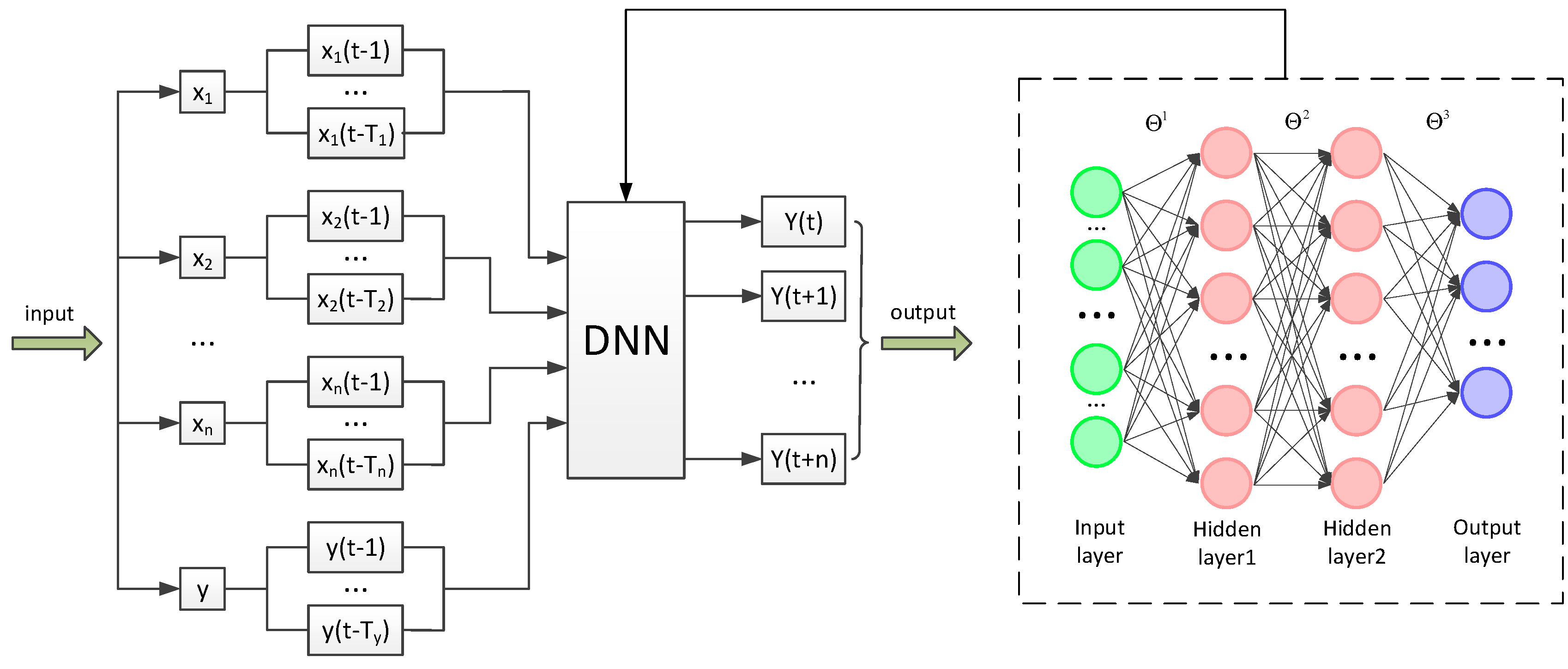
4.2. Prediction Model
5. Experiments and Discussion
5.1. Data Preprocessing
5.2. Experiment Settings
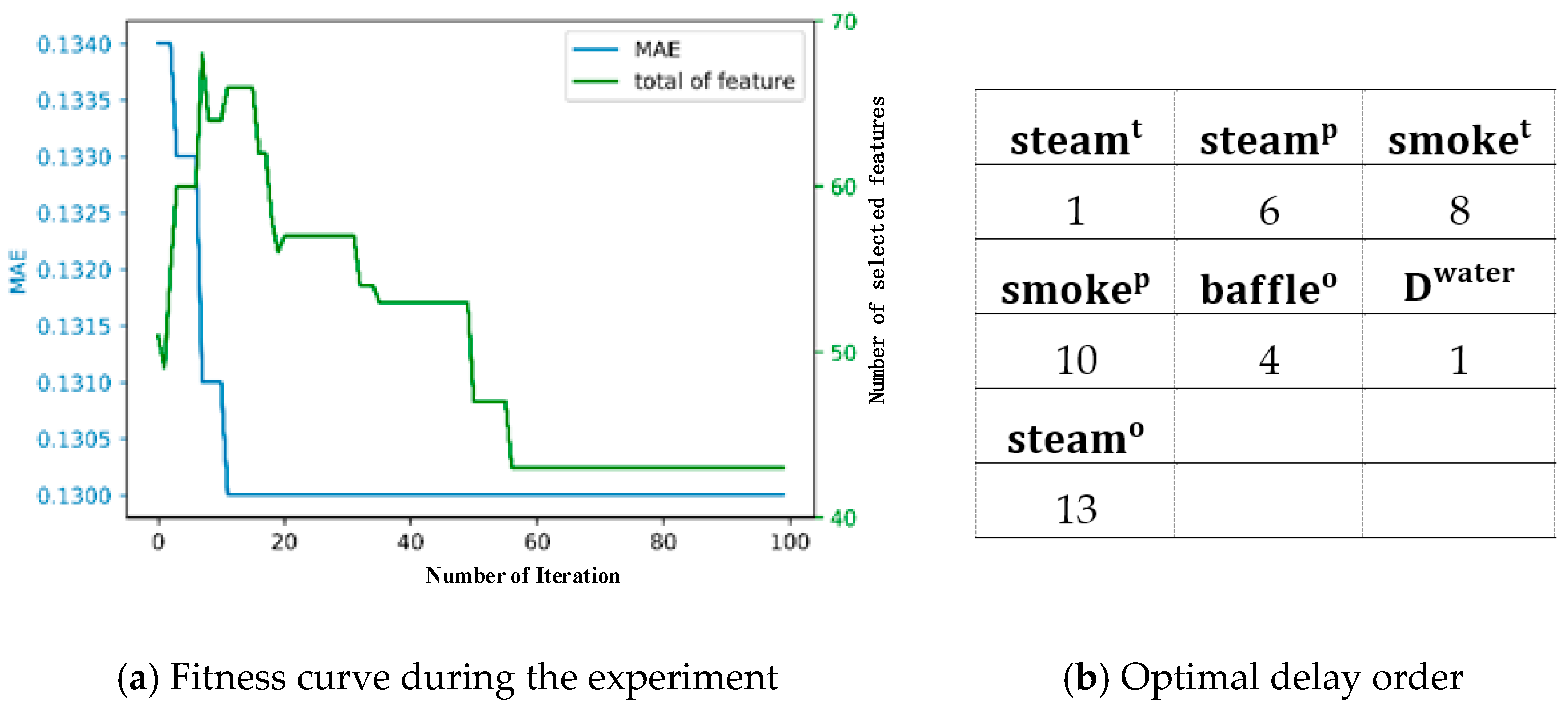
5.3. Results and Discussion
- (1)
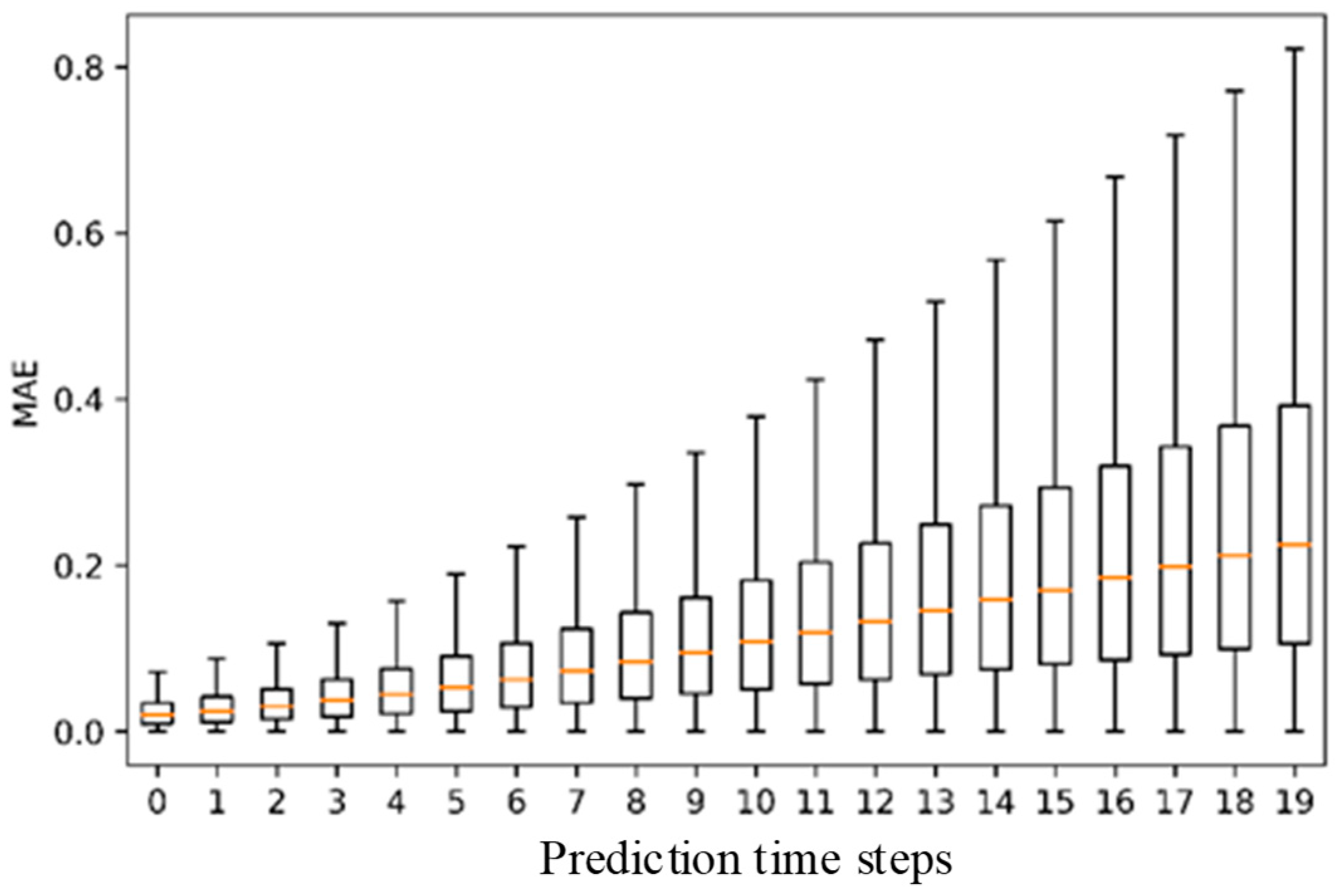
- Results of the one-round simulation
- (2)
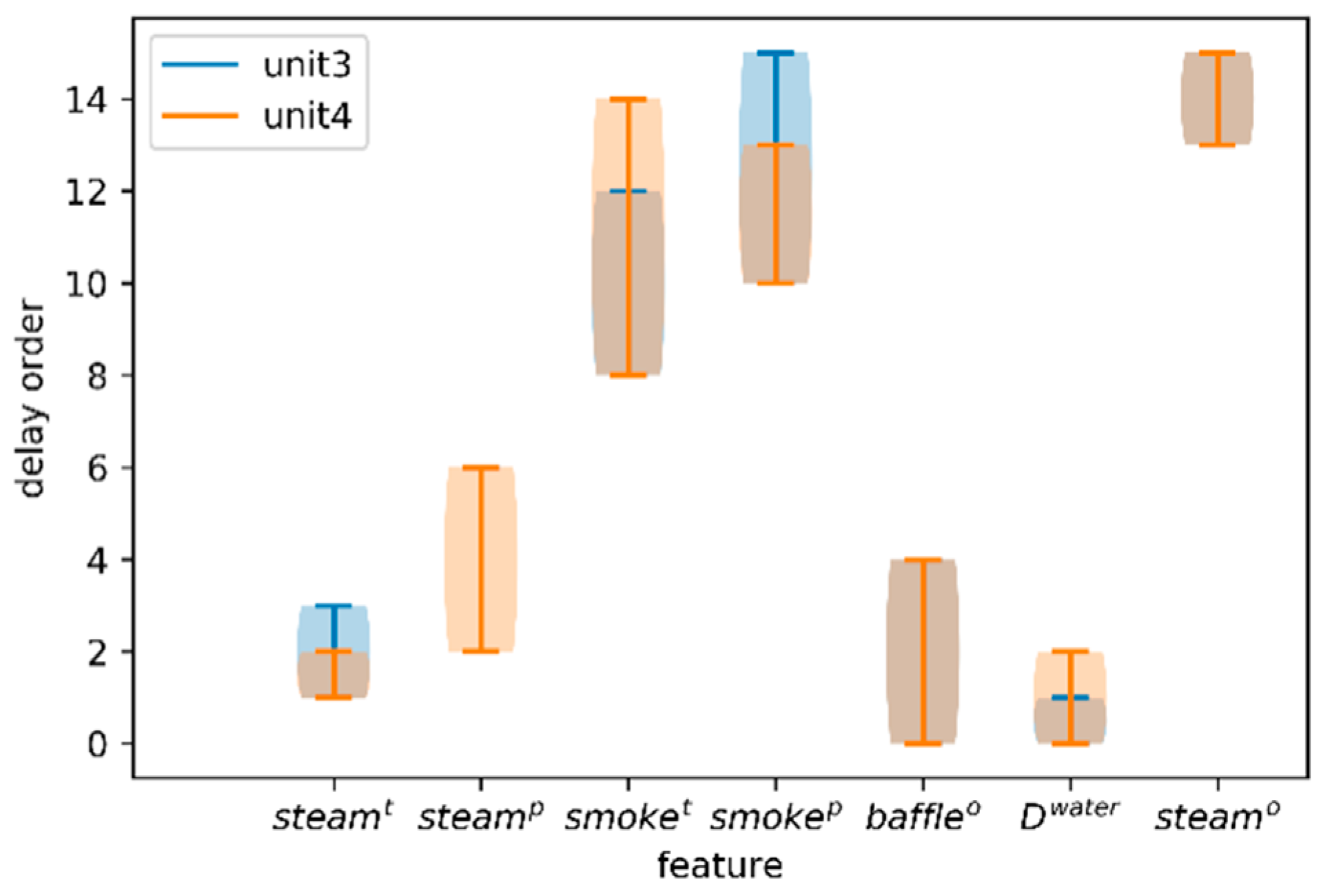
- Comparisons of unit 3 and unit 4 from different perspectives
- (3)
- Determination of delay order
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, L. Principle of Boiler; China Machine Press: Beijing, China, 2011. [Google Scholar]
- Ge, Z.; Zhang, F.; Sun, S.; He, J.; Du, X. Energy Analysis of Cascade Heating with High Back-Pressure Large-Scale Steam Turbine. Energies 2018, 11, 119. [Google Scholar] [CrossRef]
- Lee, K.Y.; Ma, L.; Boo, C.J.; Jung, W.H.; Kim, S.H. Intelligent modified predictive optimal control of reheater steam temperature in a large-scale boiler unit. In Proceedings of the 2009 IEEE Power & Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009. [Google Scholar]
- Fan, Q.G. Principle of Boiler; China Electric Power Press: Beijing, China, 2014. [Google Scholar]
- Khartchenko, N.V.; Kharchenko, V.M. Advanced Energy Systems; CRC Press: Cleveland, OH, USA, 2013. [Google Scholar]
- Hogg, B.W.; El-Rabaie, N.M. Multivariable generalized predictive control of a boiler system. IEEE Trans. Energy Convers. 1991, 6, 82–288. [Google Scholar] [CrossRef]
- Liu, X.J.; Kong, X.B.; Hou, G.L.; Wang, J.H. Modeling of a 1000 MW power plant ultra super-critical boiler system using fuzzy-neural network methods. Energy Convers. Manag. 2013, 65, 518–527. [Google Scholar] [CrossRef]
- Suryanarayana, G.; Lago, J.; Geysen, D.; Aleksiejuk, P.; Johansson, C. Thermal load forecasting in district heating networks using deep learning and advanced feature selection methods. Energy 2018, 157, 141–149. [Google Scholar] [CrossRef]
- Staehelin, C.; Schultze, M.; Kondorosi, É.; Mellor, R.B.; Boiler, T.; Kondorosi, A. Structural modifications in Rhizobium meliloti Nod factors influence their stability against hydrolysis by root chitinases. Plant J. 1994, 5, 319–330. [Google Scholar] [CrossRef]
- Gnanapragasam, N.V.; Reddy, B.V. Numerical modeling of bed-to-wall heat transfer in a circulating fluidized bed combustor based on cluster energy balance. Int. J. Heat Mass Transf. 2008, 51, 5260–5268. [Google Scholar] [CrossRef]
- Black, S.; Szuhánszki, J.; Pranzitelli, A.; Ma, L.; Stanger, P.J.; Ingham, D.B.; Pourkashanian, M. Effects of firing coal and biomass under oxy-fuel conditions in a power plant boiler using CFD modelling. Fuel 2013, 113, 780–786. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [Green Version]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Li, J.Q.; Gu, J.J.; Niu, C.L. The Operation Optimization based on Correlation Analysis of Operation Parameters in Power Plant. In Proceedings of the 2008 International Symposium on Computational Intelligence and Design, Wuhan, China, 17–18 October 2008. [Google Scholar]
- Wei, Z.; Li, X.; Xu, L.; Cheng, Y. Comparative study of computational intelligence approaches for NOx reduction of coal-fired boiler. Energy 2013, 55, 683–692. [Google Scholar] [CrossRef]
- Buczyński, R.; Weber, R.; Szlęk, A. Innovative design solutions for small-scale domestic boilers: Combustion improvements using a CFD-based mathematical model. J. Energy Inst. 2015, 88, 53–63. [Google Scholar] [CrossRef]
- Pisica, I.; Taylor, G.; Lipan, L. Feature selection filter for classification of power system operating states. Comput. Math. Appl. 2013, 66, 1795–1807. [Google Scholar] [CrossRef]
- Wang, F.; Ma, S.; Wang, H.; Li, Y.; Qin, Z.; Zhang, J. A hybrid model integrating improved flower pollination algorithm-based feature selection and improved random forest for NOX emission estimation of coal-fired power plants. Measurement 2018, 125, 303–312. [Google Scholar] [CrossRef]
- Sun, L.; Li, D.; Lee, K.Y. Enhanced decentralized PI control for fluidized bed combustor via advanced disturbance observer. Control Eng. Pract. 2015, 42, 128–139. [Google Scholar] [CrossRef]
- Lv, Y.; Hong, F.; Yang, T.; Fang, F.; Liu, J. A dynamic model for the bed temperature prediction of circulating fluidized bed boilers based on least squares support vector machine with real operational data. Energy 2017, 124 (Suppl. C), 284–294. [Google Scholar] [CrossRef]
- Galicia, H.J.; He, Q.P.; Wang, J. A reduced order soft sensor approach and its application to a continuous digester. J. Process Control 2011, 21, 489–500. [Google Scholar] [CrossRef]
- Souza, F.; Santos, P.; Araújo, R. Variable and delay selection using neural networks and mutual information for data-driven soft sensors. In Proceedings of the 2010 IEEE 15th Conference on Emerging Technologies & Factory Automation (ETFA 2010), Bilbao, Spain, 13–16 September 2010. [Google Scholar]
- Shakil, M.; Elshafei, M.; Habib, M.A.; Maleki, F.A. Soft sensor for NOx and O2 using dynamic neural networks. Comput. Electr. Eng. 2009, 35, 578–586. [Google Scholar] [CrossRef]
- Xia, C.; Wang, J.; McMenemy, K. Short, medium and long term load forecasting model and virtual load forecaster based on radial basis function neural networks. Int. J. Electr. Power Energy Syst. 2010, 32, 743–750. [Google Scholar] [CrossRef] [Green Version]
- Gosselin, L.; Tye-Gingras, M.; Mathieu-Potvin, F. Review of utilization of genetic algorithms in heat transfer problems. Int. J. Heat Mass Transf. 2009, 52, 2169–2188. [Google Scholar] [CrossRef]
- Woodward, R.I.; Kelleher, E.J.R. Towards ‘smart lasers’: Self-optimisation of an ultrafast pulse source using a genetic algorithm. Sci. Rep. 2016, 6, 37616. [Google Scholar] [CrossRef] [PubMed]
- Kreszig, E. Advanced Engineering Mathematics, 4th ed.; Wiley: Weinheim, Germany, 1979; p. 880. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Unit | Inertia | Not. |
|---|---|---|---|
| Inlet steam temperature | °C | small | |
| Inlet steam pressure | Mpa | small | |
| Inlet smoke temperature | °C | large | |
| Inlet smoke pressure | Kpa | small | |
| Smoke baffle opening | % | small | |
| Desuperheated water flow | t/h | large | |
| Reheater steam temperature | °C | - |
| Neutral Network | Value | GA | Value |
|---|---|---|---|
| Number of hidden layers | 2 | Number of initial individuals | 20 |
| Number of first/second layer neurons | 42/23 | Mate rate | 0.5 |
| Number of outputs | 20 | Mutate rate | 0.2 |
| Activation function | tanh | Number of genes | 0–15 |
| Solver | sgd | Iterations | 100 |
| Learning_rate | 0.001 | 0.14 | |
| Λ | 0.0001 | - | - |
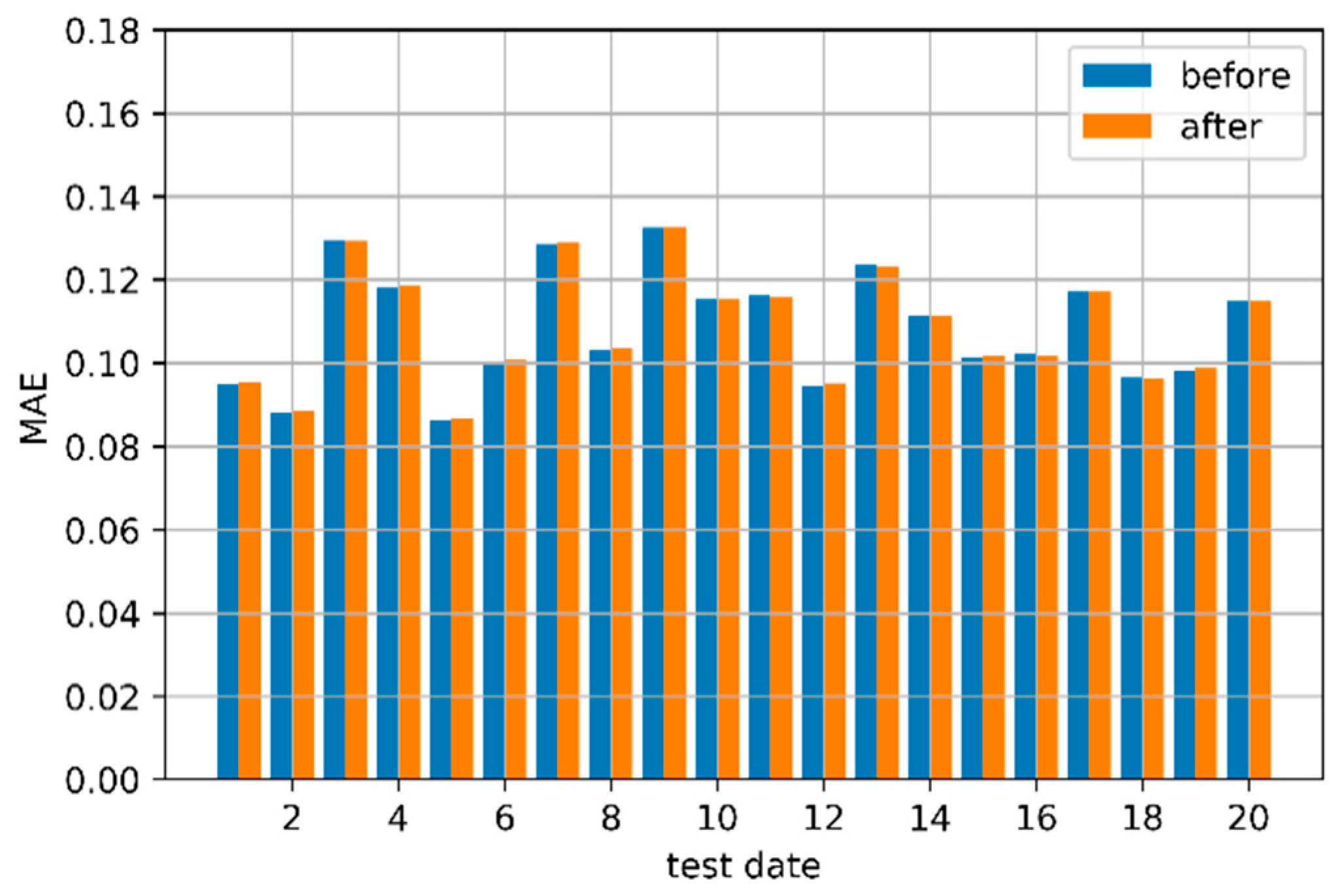
| Test | Sample Date | MAE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1/11 | 8 May–15 May/1 May–8 May | 1/1 | 6/6 | 9/8 | 10/10 | 4/4 | 1/1 | 15/13 | 0.095/0.116 |
| 2/12 | 16 May–23 May/17 May–24 May | 1/2 | 6/2 | 9/8 | 10/11 | 4/0 | 1/1 | 15/15 | 0.088/0.094 |
| 3/13 | 20 May–27 May/24 May–31 May | 1/1 | 6/6 | 8/8 | 10/10 | 4/4 | 1/1 | 13/13 | 0.129/0.123 |
| 4/14 | 9 June–16 June/5 June –12 June | 3/1 | 6/6 | 12/8 | 10/13 | 0/4 | 1/1 | 13/13 | 0.118/0.111 |
| 5/15 | 17 June–24 June/8 June–15 June | 1/1 | 6/4 | 9/14 | 13/10 | 4/4 | 1/1 | 15/15 | 0.086/0.101 |
| 6/16 | 1 July–8 July/16 June–23 June | 3/1 | 6/6 | 9/8 | 15/10 | 4/0 | 1/0 | 15/13 | 0.100/0.101 |
| 7/17 | 22 July–29 July/17 July–24 July | 1/1 | 6/2 | 12/11 | 10/10 | 0/0 | 1/2 | 13/15 | 0.128/0.117 |
| 8/18 | 6 August–13 August/24 July–31 July | 1/1 | 6/2 | 9/12 | 10/13 | 4/0 | 1/0 | 15/13 | 0.103/0.095 |
| 9/19 | 10 August–17 August/5 August –12 August | 1/2 | 6/6 | 8/10 | 13/10 | 4/2 | 0/1 | 13/15 | 0.132/0.115 |
| 10/20 | 13 August–20 August/17 August–24 August | 1/2 | 6/6 | 8/9 | 10/10 | 4/2 | 0/1 | 15/14 | 0.115/0.115 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gui, N.; Lou, J.; Qiu, Z.; Gui, W. Temporal Feature Selection for Multi-Step Ahead Reheater Temperature Prediction. Processes 2019, 7, 473. https://doi.org/10.3390/pr7070473
Gui N, Lou J, Qiu Z, Gui W. Temporal Feature Selection for Multi-Step Ahead Reheater Temperature Prediction. Processes. 2019; 7(7):473. https://doi.org/10.3390/pr7070473
Chicago/Turabian StyleGui, Ning, Jieli Lou, Zhifeng Qiu, and Weihua Gui. 2019. "Temporal Feature Selection for Multi-Step Ahead Reheater Temperature Prediction" Processes 7, no. 7: 473. https://doi.org/10.3390/pr7070473