
GraphSAGE-Based Multi-Path Reliable Routing Algorithm for Wireless Mesh Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
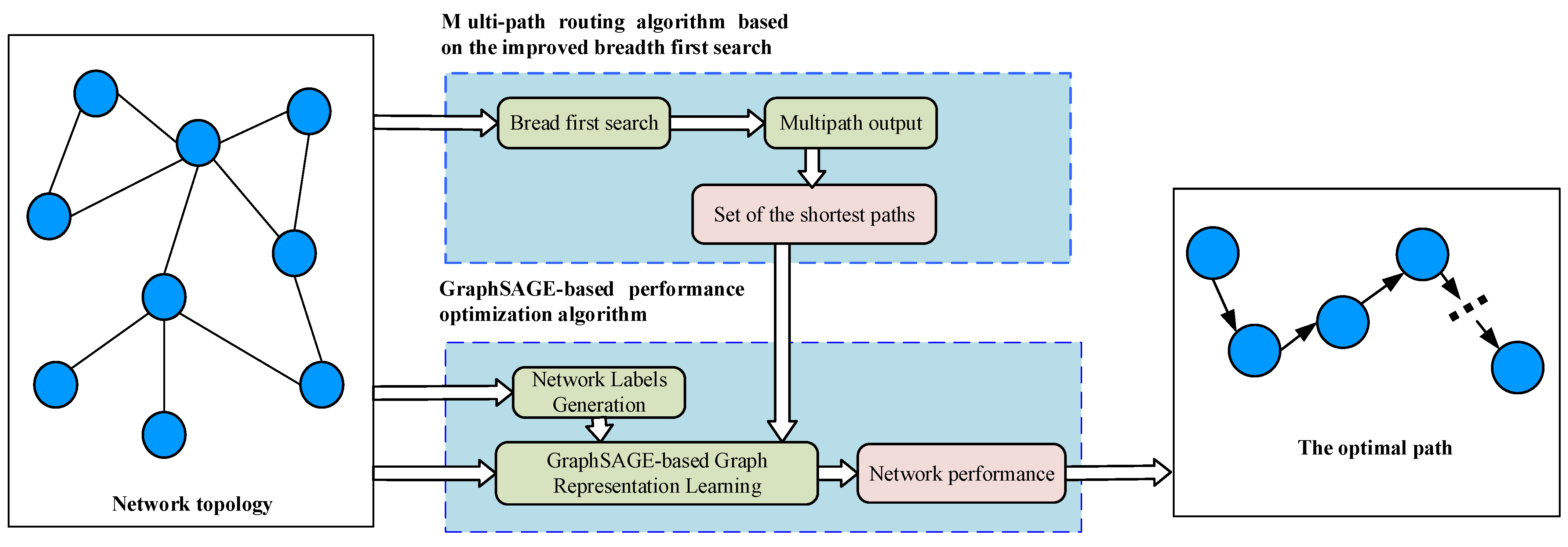
- Propose a multi-path routing algorithm based on the improved breadth-first search. The algorithm can traverse the information of all neighbor nodes of the source, calculate the shortest hop count and predecessor nodes from neighbor nodes to the source, and then output all shortest paths based on this information.
- (2)
- Based on the multiple shortest paths found, a GraphSAGE-based performance optimization algorithm is proposed. The algorithm can generate network labels to train the GraphSAGE model. And then the network performance value of each node is obtained according to the inputting network topology, node features, and the trained GraphSAGE model. The network performance of each shortest path is composed of the sum of the network performance of each node in the path. Eventually, the path with the best network performance is selected for data transmission.
- (3)
- The proposed algorithm is evaluated from the effects of data sending rate, topology size, and channel environment on network performance (average end-to-end delay, packet loss rate, and throughput), respectively. The rest of the paper is organized as follows: Section 2 presents the system model. Section 3 presents the multi-path routing algorithm based on the improved breadth-first search. Section 4 presents the GraphSAGE-based performance optimization algorithm. The simulation methodology and results are shown in Section 5. Finally, Section 6 summarizes the findings of the paper.
2. System Model
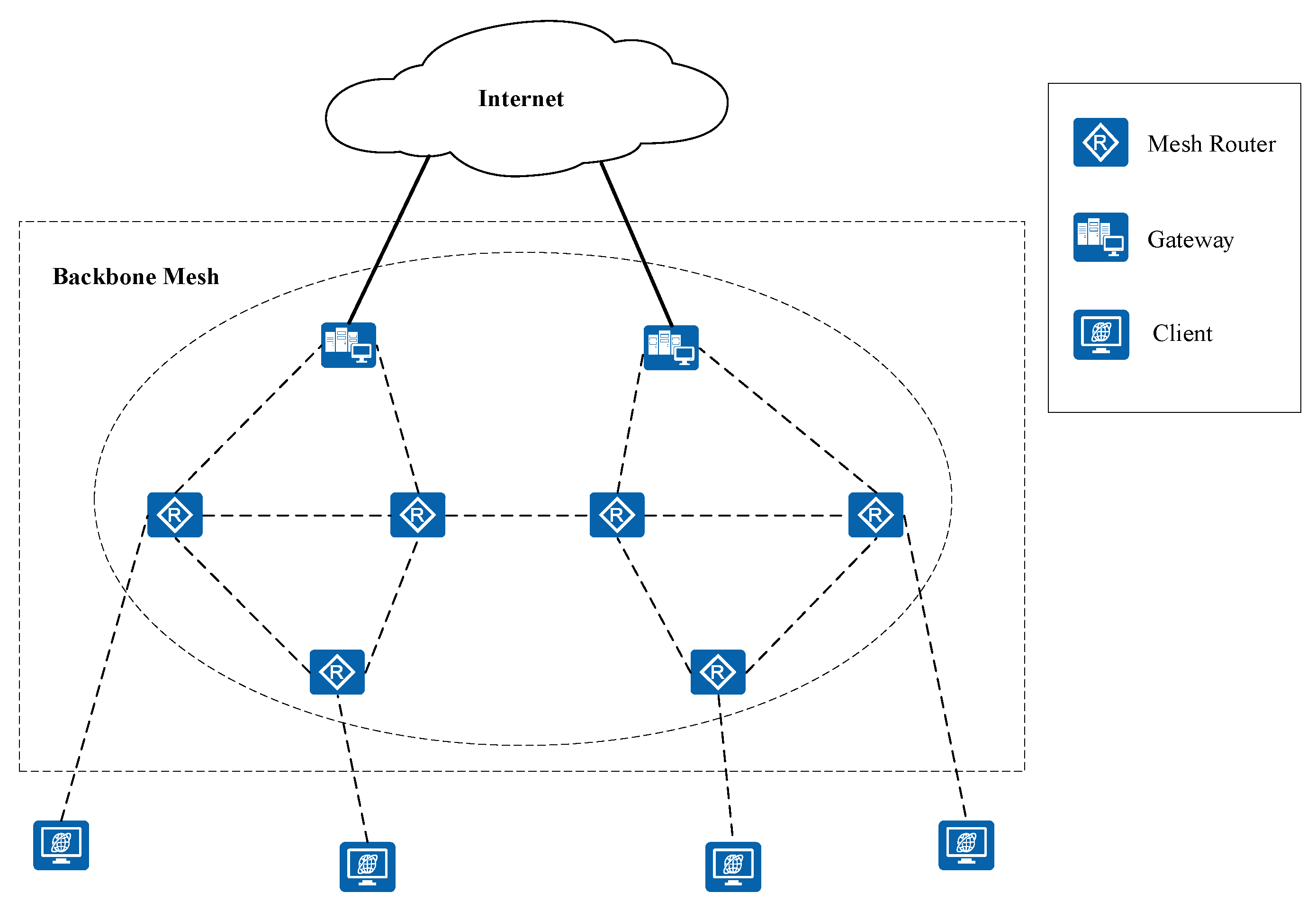
2.1. Network Model
2.2. Architecture
2.3. Notations
- : Head node, the first element of the queue.
- : Queue used to store neighbor nodes.
- : Visited status, if , the neighbor node has been visited and has been in the queue. Otherwise .
- : Searched status, if , the neighbor node has already been searched, and can be skipped.
- : The shortest hop count from node to the source.: The number of predecessor nodes of node .
- : Set of predecessor nodes of node . There are elements in the set.
- : Neighbor node list used to store all neighbor nodes of the top element of the main stack.
- : Set of the shortest paths used to store the shortest paths output by multi-path routing algorithm based on the improved breadth first search.
3. Multi-Path Routing Algorithm Based on the Improved Breadth First Search
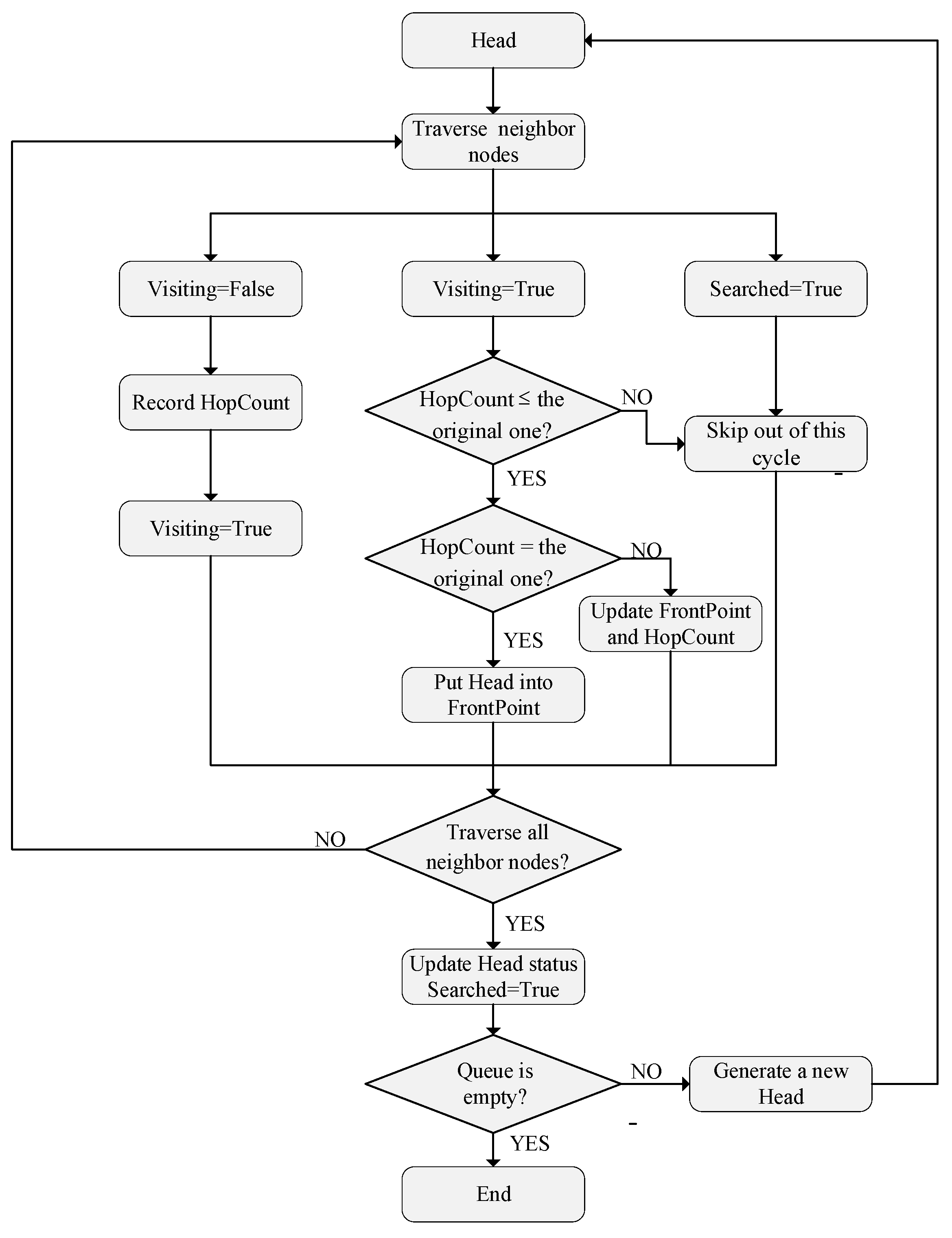
3.1. Breadth-First Search
- Step 1:
- First initialize the correlation parameters, put the source as the head node into , set the status of the source to , the rest of the nodes to , and the status of all nodes to . Set to zero, which represents the hop count from the head node to the source is zero. Traverse adjacency matrix to find all the neighbor nodes of the head node and the address of one of the neighbor nodes is denoted by . Query the current status of this neighbor node.
- Step 2:
- If , = , and the number of predecessor nodes of this neighbor node is increased by one. At the same time, put the head node as the predecessor node of the current neighbor node into . Finally, put the neighbor node in and set the status of this node to .
- Step 3:
- If , this node is also a neighbor node of other nodes, it is necessary to compare the size of the shortest hop count from the neighbor node to the source. If the shortest hop count obtained in this loop is smaller than the original one, update to the shortest hop count of this loop and keep unchanged. If the shortest hop count obtained in this loop is equal to the original one, is increased by one. At the same time, put as another predecessor node of the current neighbor node into . If the shortest hop count obtained in this loop is larger than the original one, skip out of this loop.
- Step 4:
- If , this node has been searched, so skip out of this loop. After all neighbor nodes are traversed, update the status of the head node as . In the end, remove the head node from and generate a new head node.
- Step 5:
- Repeat steps 2 to 4 until becomes empty.
3.2. Multipath Output
| Algorithm 1: Multipath Output Algorithm |
| Input:; ; Output: . as the top of the stack. 3 while is not empty do is not empty then 6 , press it into 7 Query the neighbor node list of the element at the , if the list contains elements in , eliminate the duplicate elements from directly 9 end if then 13 end if 14 end while |
4. GraphSAGE-Based Performance Optimization Algorithm
4.1. Network Labels Generation
- Step 1:
- Randomly initialize the membership value , and the fuzzy coefficient is generally set to 2 by default [23]. Use the FCM algorithm to iterate parameters on the network feature dataset to obtain the cluster center and fuzzy partition coefficient FPC.
- Step 2:
- Repeat Step 1 with a different number of clusters , record the number of clusters with the largest FPC value as , and obtain the cluster center . At this point, has been divided into classes.
- Step 3:
- Take the average of the network feature vectors of the network feature dataset by category to obtain network feature vectors, and calculate their corresponding network performance value . Rank the network performance classes according to the network performance value , the larger the value the better the network performance, thus the network performance can correspond to the cluster categories.
- Step 4:
- According to the cluster centers obtained from Step 2 and the relationship between network performance and cluster categories obtained from Step 3, label the node feature vectors by network performance value , which provides conditions for the supervised training of the GraphSAGE model.
4.2. GraphSAGE-Based Graph Representation Learning
- (1)
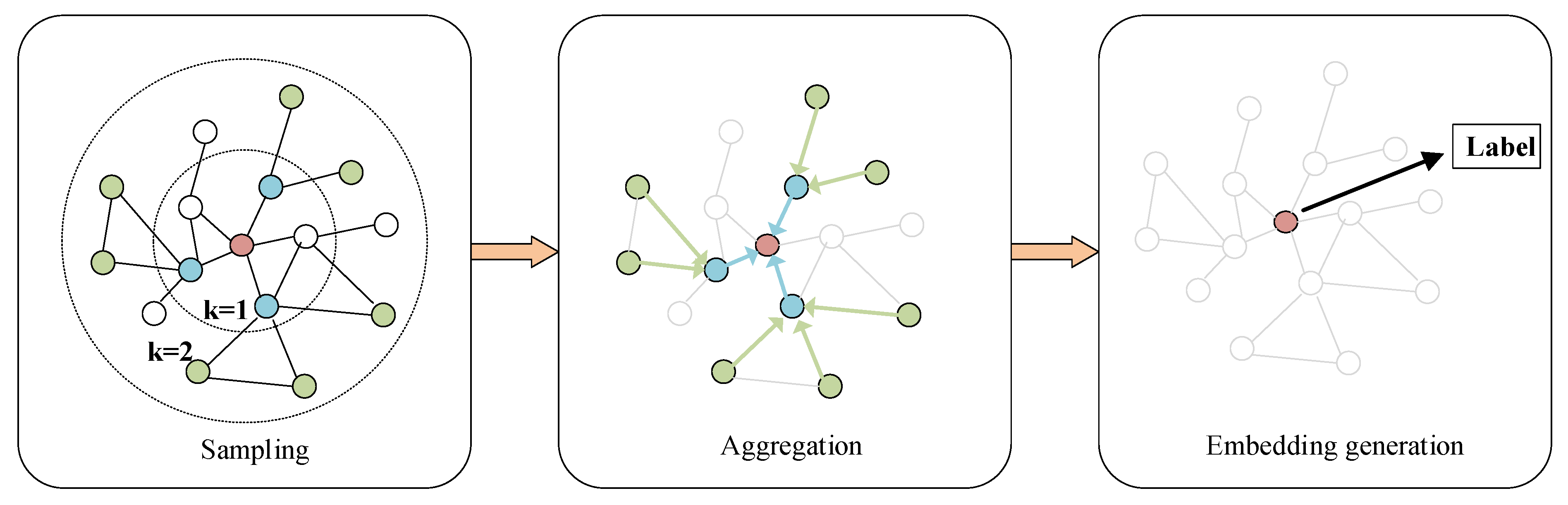
- Sampling: The target node is selected by random walk, and then the neighbor nodes of the target node are sampled. The number of neighbors sampled in each hop is . If the number of neighbor nodes is less than , a resampling method with put back is used. If the number of neighbor nodes is greater than , a negative sampling method without put back is used. represents the search depth, and according to the study of [15], when , GraphSAGE can get excellent performance, so is set as 2. When , , , the sampling process is shown in the sampling section of Figure 4.
- (2)
- Aggregation: GraphSAGE aggregates the information of neighbor nodes at each layer by aggregator functions and updates the target node’s own node information. In this paper, the Mean aggregator is used to obtain the aggregated features of neighbor nodes at each layer. GraphSAGE then splices the feature representation of the target node at layer with the aggregated features of the neighbor nodes in layer , and eventually uses the nonlinear activation function to obtain the vector representation of the target node of layer . The process of neighbor nodes aggregation is as follows:where denotes the set of neighbor nodes of node ; donates the feature representation of the neighbor node at layer ; donates the aggregated features of neighbor nodes of node at layer . The process of node at layer to generate vector representations is as follows:where uses the residual concatenation to linearly superimpose each feature vector; is the weight matrix to be learned; is a nonlinear activation function; represents the vector representation of node at layer . When , the vector representation of node , is defined as the input feature of node , i.e., .
- (3)
- Embedding generation: The vector representation of each node in layer in the graph structure is obtained as the final vector representation for the following node classification task. The process is as follows:
| Algorithm 2: GraphSAGE Embedding Generation Algorithm [15] |
| Input:, ; search depth ; nonlinear activation function Output: ; do do 6 end 8 end |
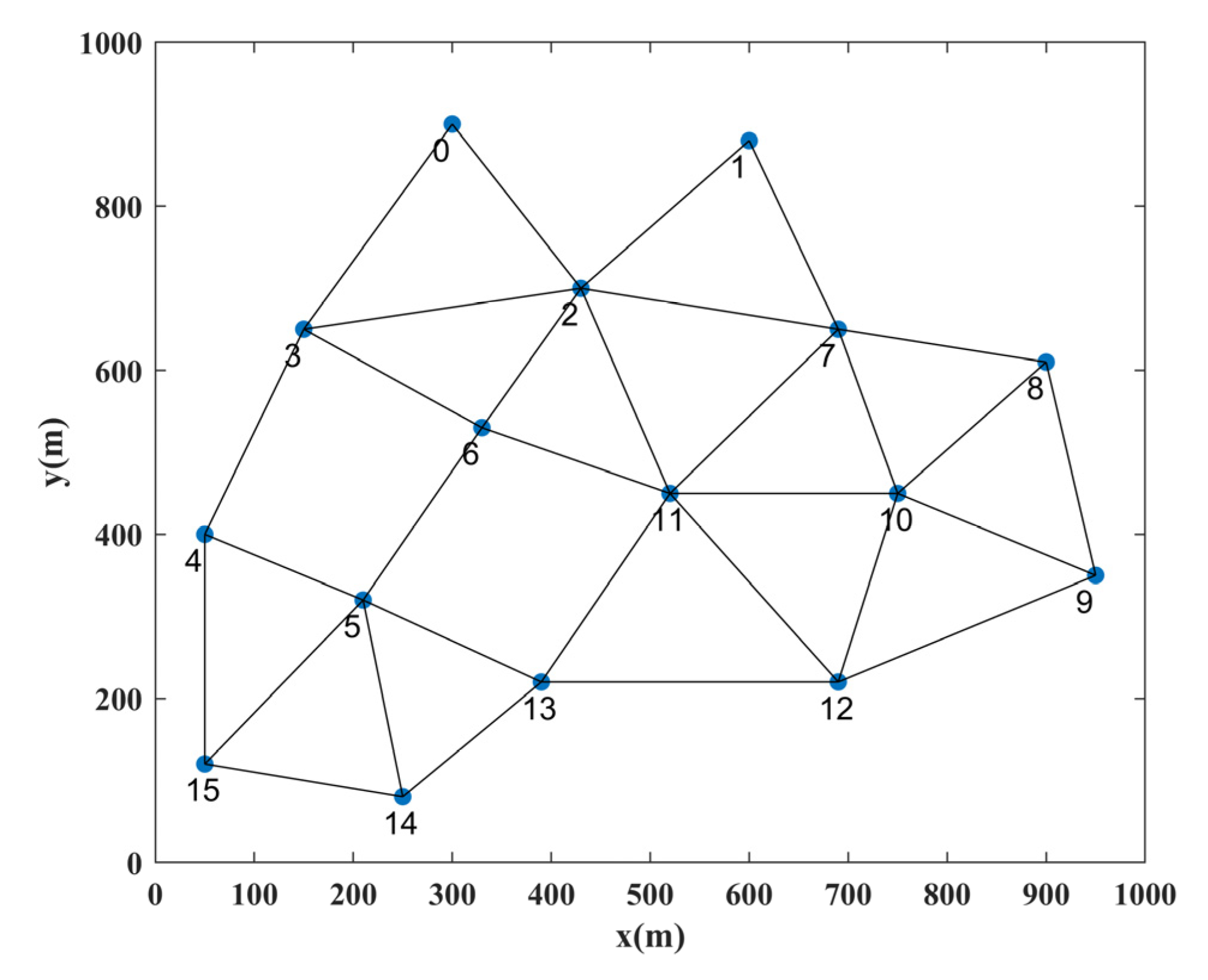
5. Simulation
5.1. Experimental Environment and Model Training Process
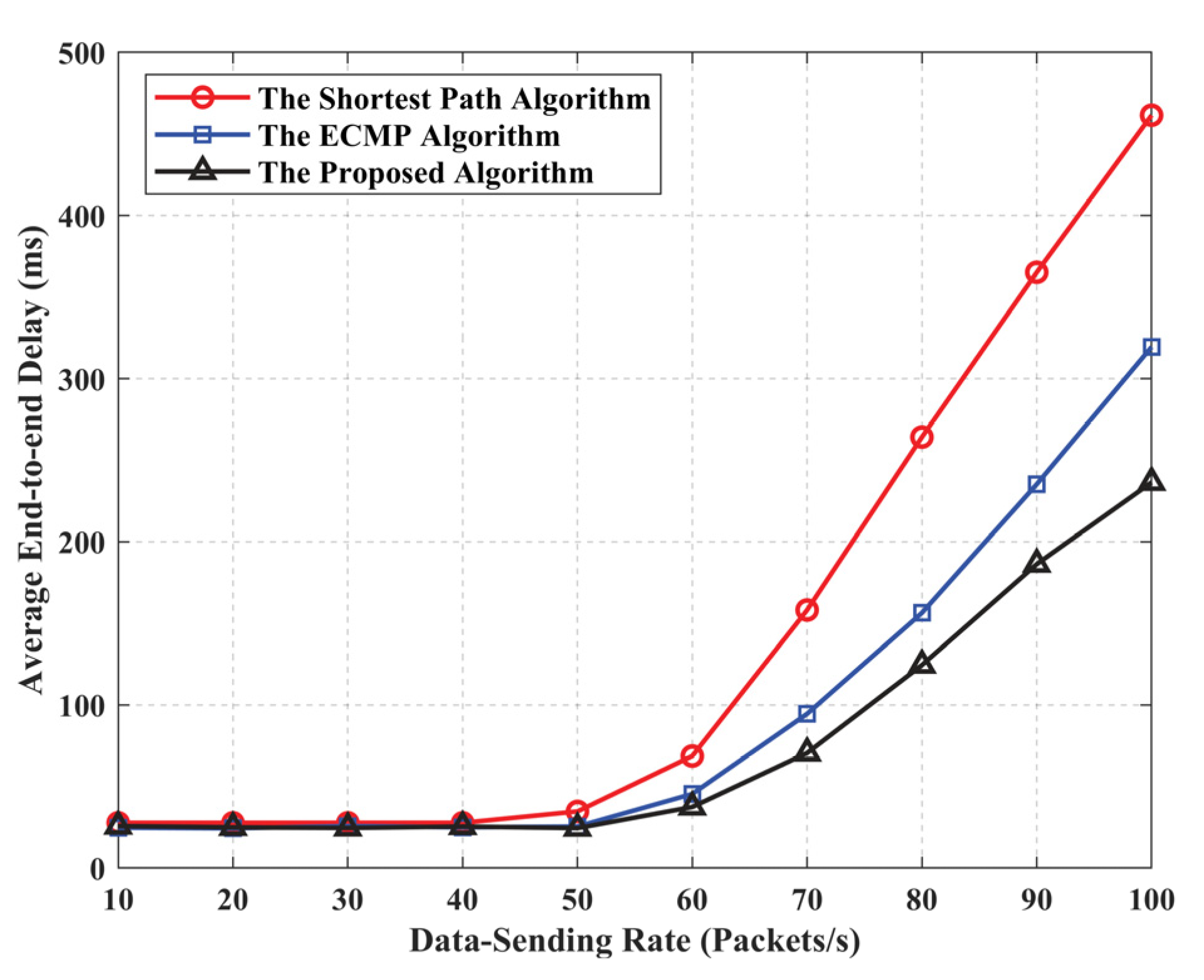
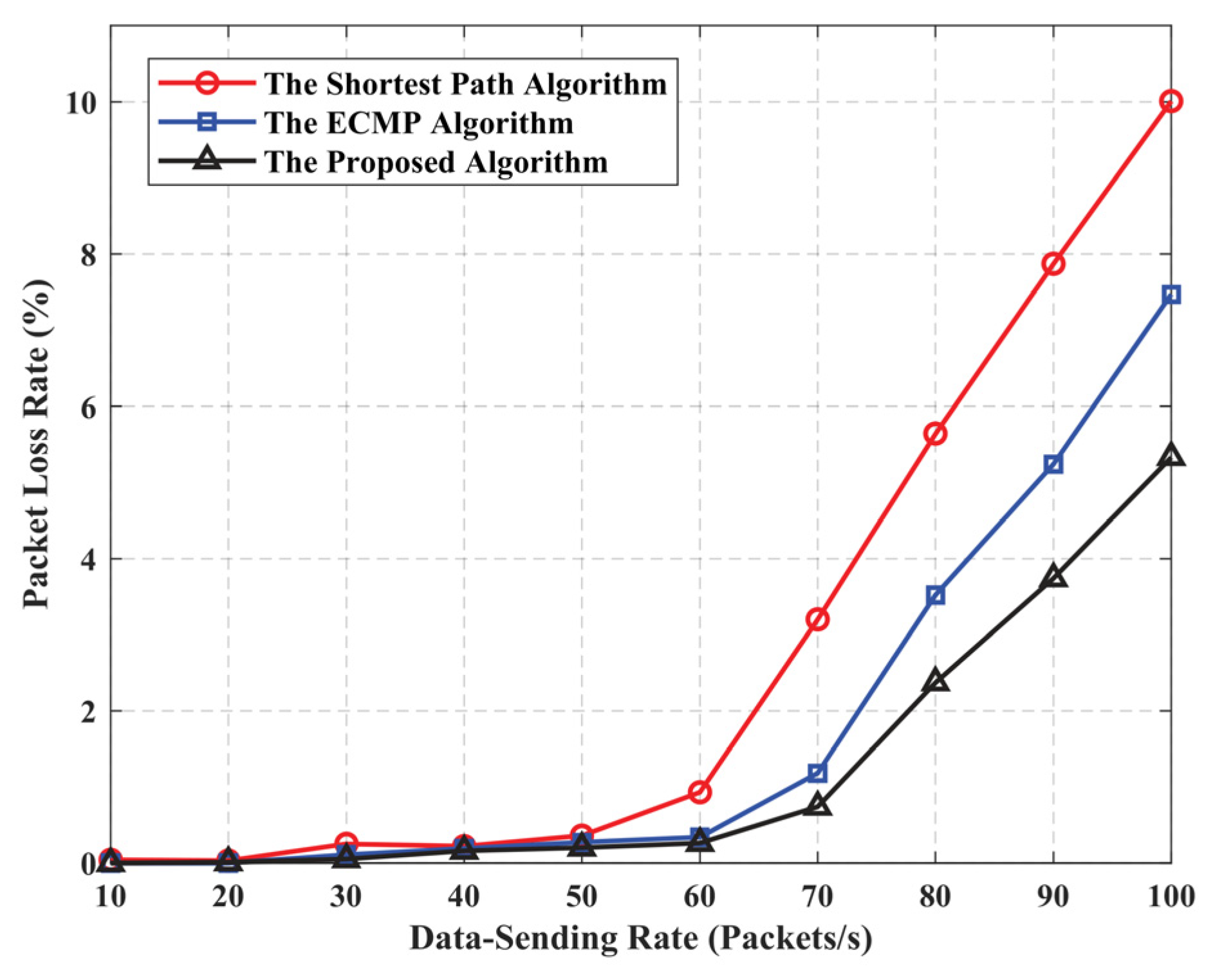
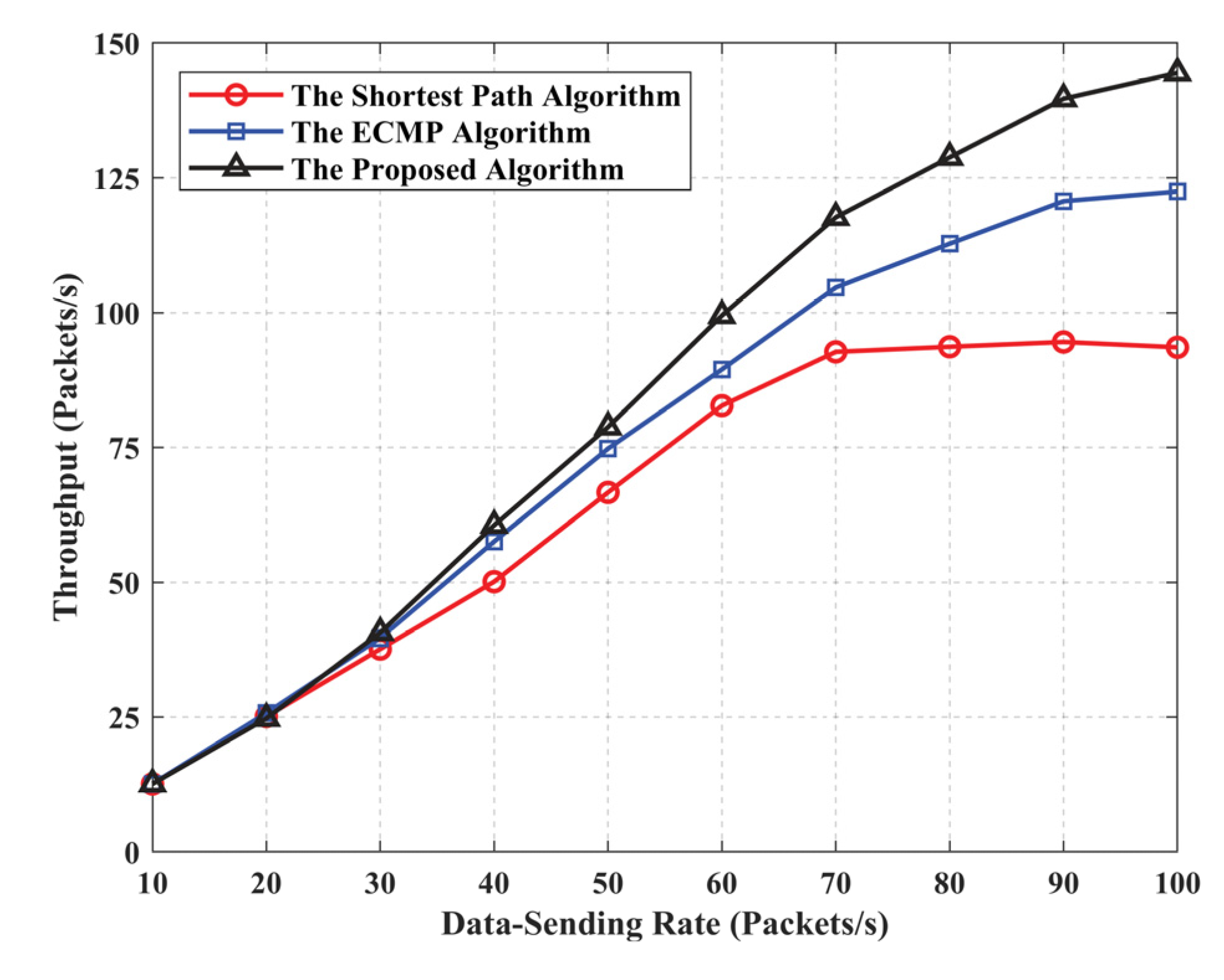
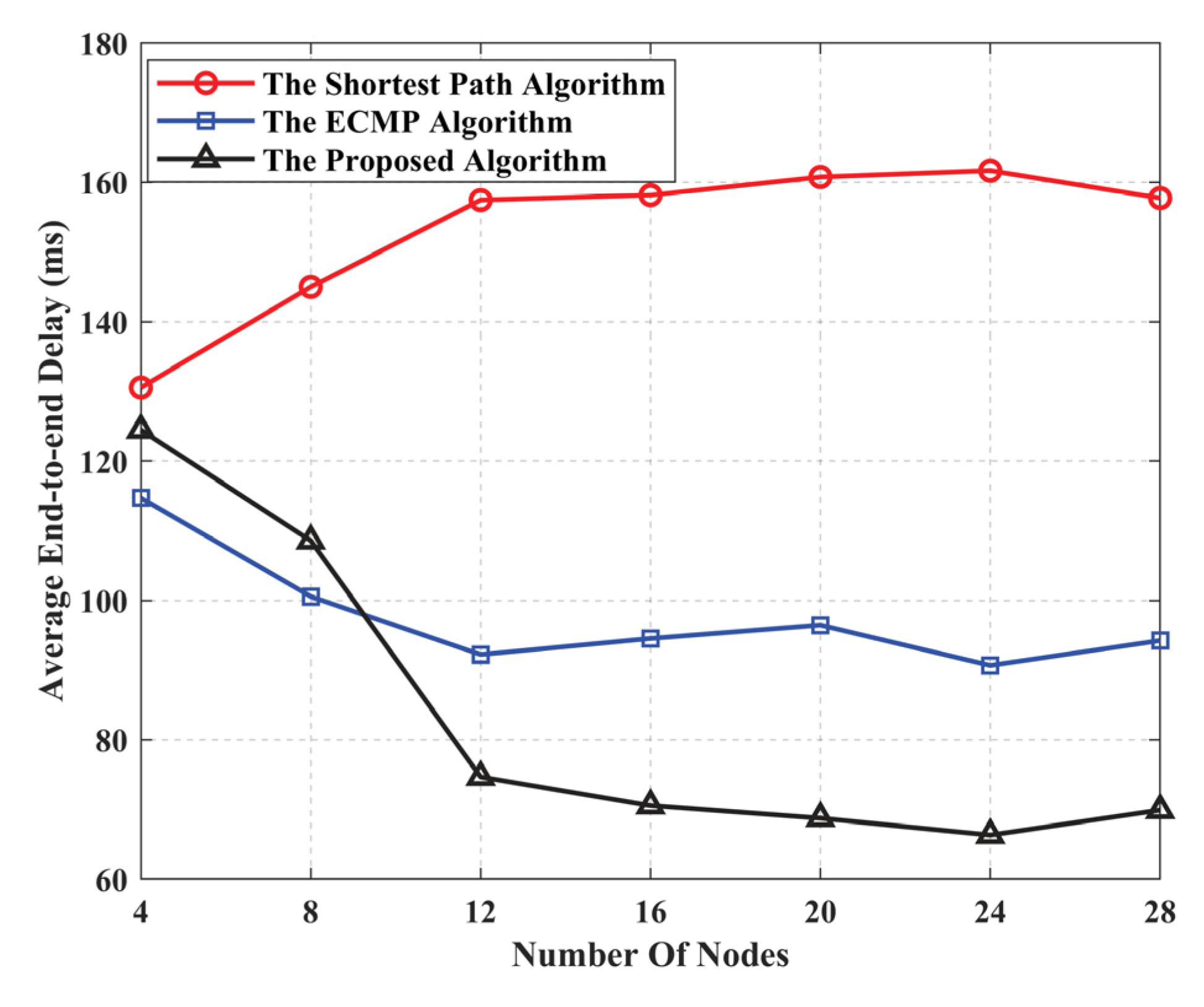
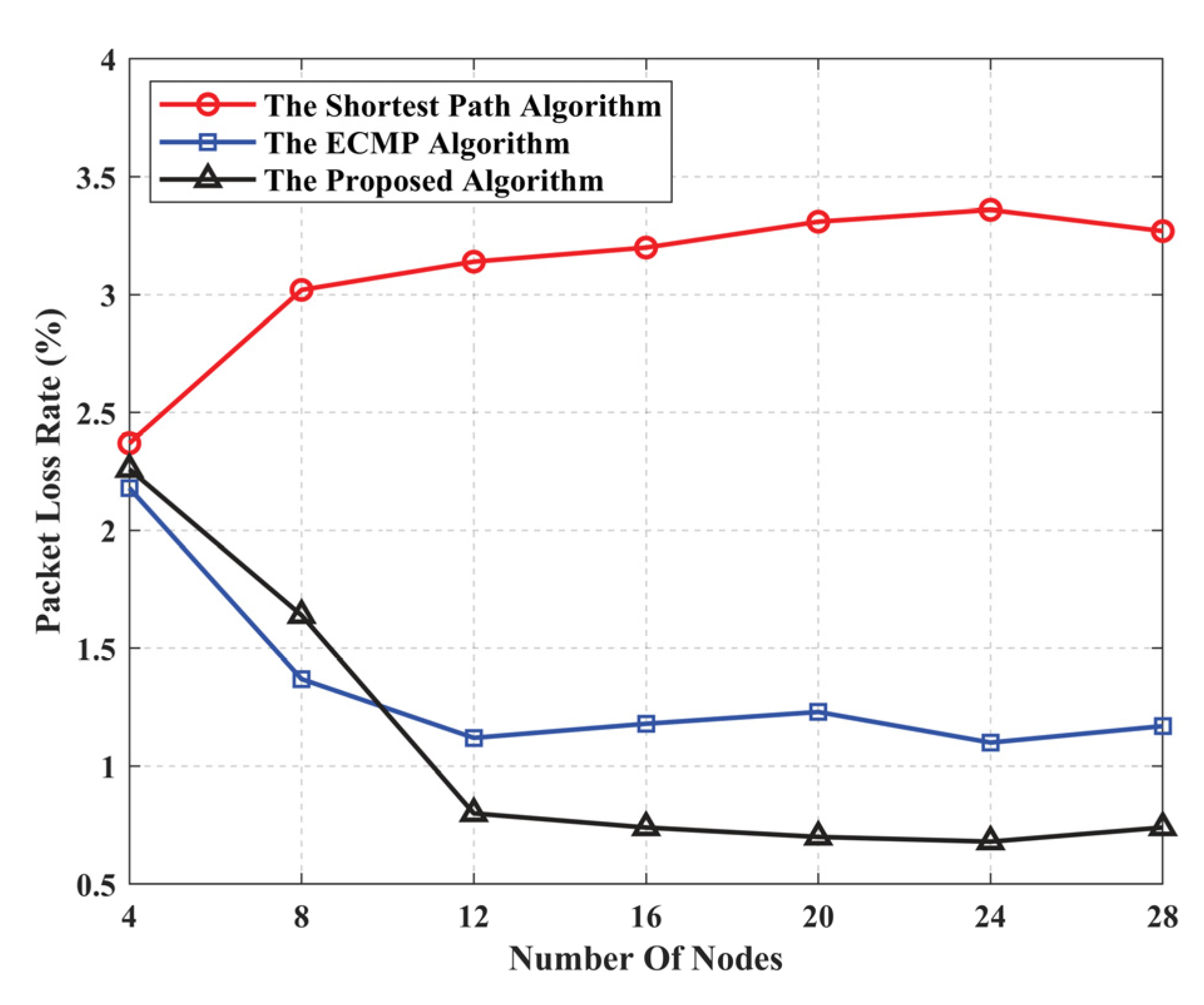
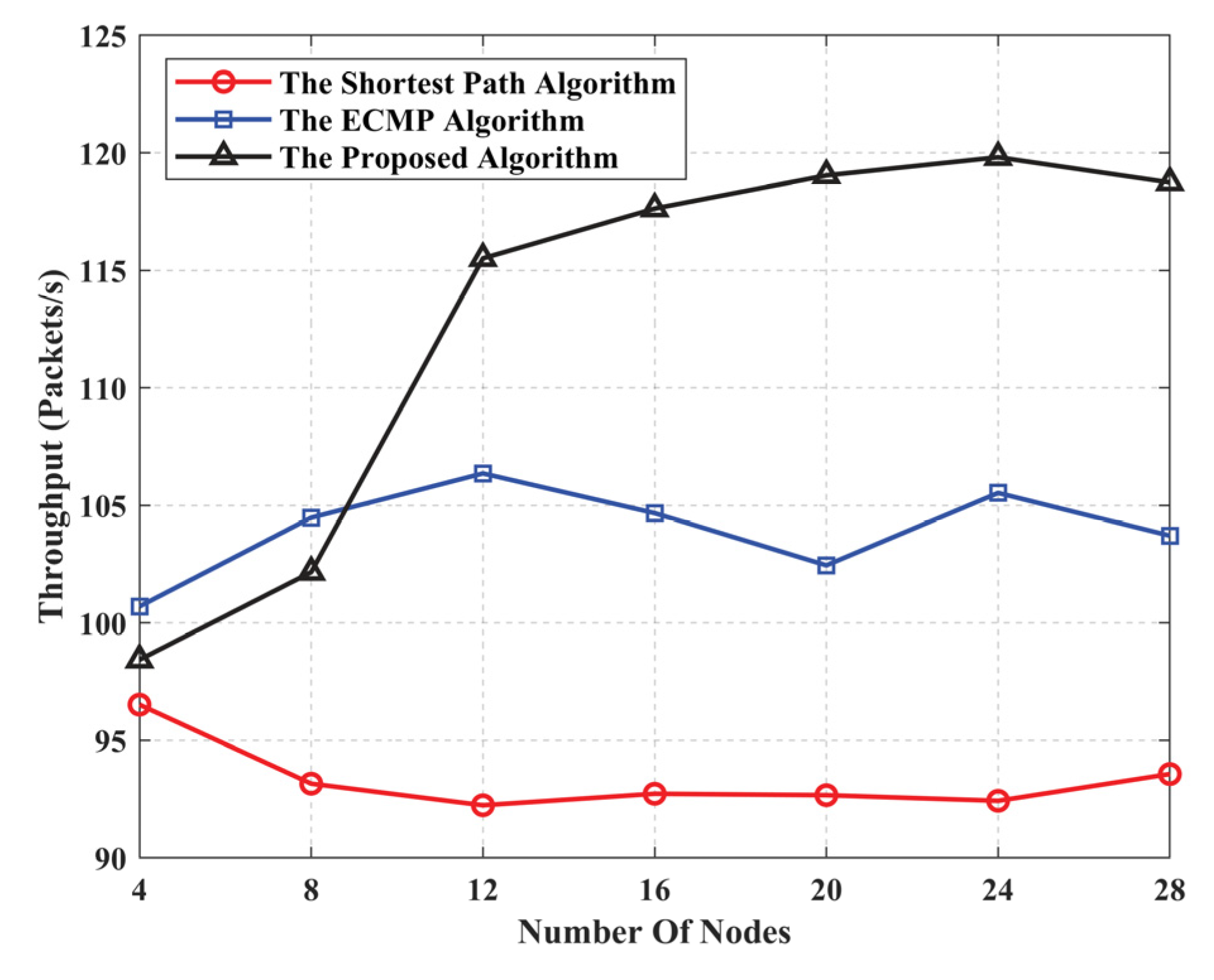
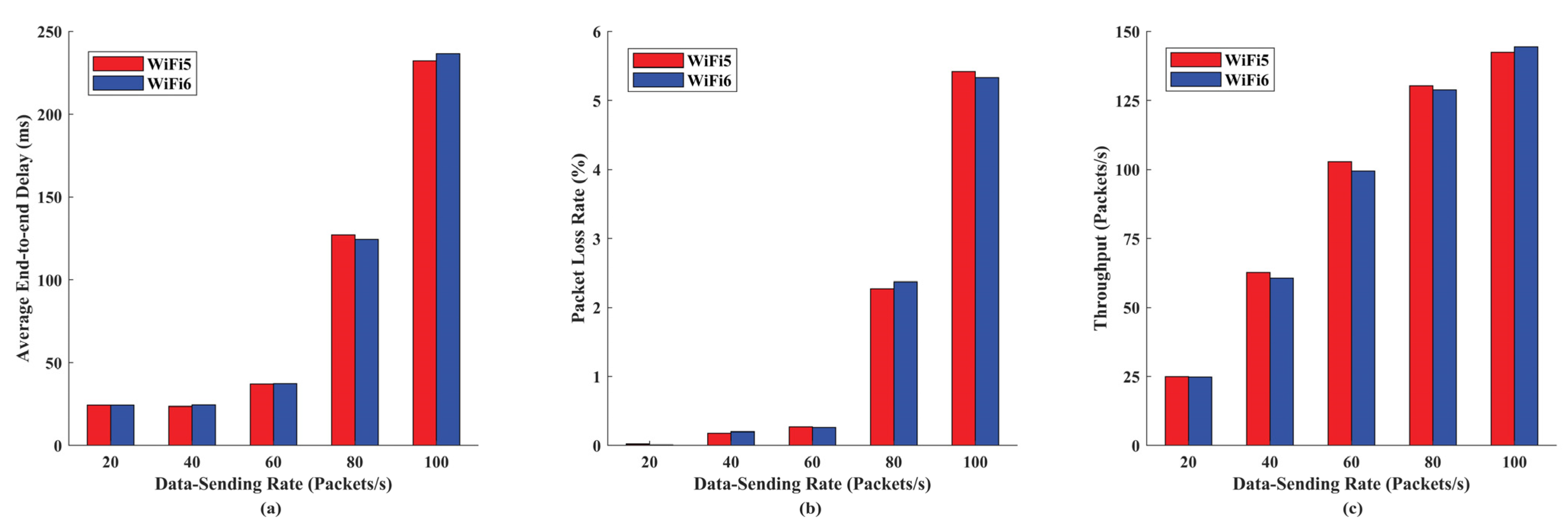
5.2. Algorithm Performance Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dey, S.; Sarmah, H.; Samantray, S.; Divakar, D.; Pathak, S. Energy efficiency in wireless mesh networks. In Proceedings of the 2010 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 28–29 December 2010; pp. 1–4. [Google Scholar]
- Rozner, E.; Seshadri, J.; Mehta, Y.; Qiu, L. SOAR: Simple opportunistic adaptive routing protocol for wireless mesh networks. IEEE Trans. Mob. Comput. 2009, 8, 1622–1635. [Google Scholar] [CrossRef]
- Vijayakumar, K.; Ganeshkumar, P.; Anandaraj, M. Review on routing algorithms in wireless mesh networks. Int. J. Comput. Sci. Telecommun. 2012, 3, 87–92. [Google Scholar]
- Wang, L.; Zhang, L.; Shu, Y.; Dong, M. Multipath source routing in wireless ad hoc networks. In Proceedings of the 2000 Canadian Conference on Electrical and Computer Engineering. Conference Proceedings. Navigating to a New Era (Cat. No. 00TH8492), Halifax, NS, Canada, 7–10 May 2000; pp. 479–483. [Google Scholar]
- Jia, D.; Zou, S.; Li, M.; Zhu, H. Adaptive multi-path routing based on an improved leapfrog algorithm. Inf. Sci. 2016, 367, 615–629. [Google Scholar]
- Guo, X.; Wang, F.; Liu, J.; Cui, Y. Path diversified multi-QoS optimization in multi-channel wireless mesh networks. Wirel. Netw. 2014, 20, 1583–1596. [Google Scholar] [CrossRef]
- Pan, C.; Liu, B.; Zhou, H.; Gui, L. Multi-path routing for video streaming in multi-radio multi-channel wireless mesh networks. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Liu, C.; Xu, M.; Geng, N.; Zhang, X. A survey on machine learning based routing algorithms. J. Comput. Res. Dev. 2020, 57, 671–687. [Google Scholar]
- Yun, W.-K.; Yoo, S.-J. Q-learning-based data-aggregation-aware energy-efficient routing protocol for wireless sensor networks. IEEE Access 2021, 9, 10737–10750. [Google Scholar] [CrossRef]
- Tang, J.; Mihailovic, A.; Aghvami, H. Constructing a DRL decision making scheme for multi-path routing in All-IP access network. In Proceedings of the GLOBECOM 2022–2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; pp. 3623–3628. [Google Scholar]
- Modi, T.M.; Swain, P. Intelligent routing using convolutional neural network in software-defined data center network. J. Supercomput. 2022, 78, 13373–13392. [Google Scholar] [CrossRef]
- Zheng, X.; Huang, W.; Li, H.; Li, G. Research on Generalized Intelligent Routing Technology Based on Graph Neural Network. Electronics 2022, 11, 2952. [Google Scholar] [CrossRef]
- Xu, Z.; Tang, J.; Meng, J.; Zhang, W.; Wang, Y.; Liu, C.H.; Yang, D. Experience-driven networking: A deep reinforcement learning based approach. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1871–1879. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Sarkar, S.K.; Basavaraju, T.G.; Puttamadappa, C. Ad Hoc Mobile Wireless Networks: Principles, Protocols and Applications; Auerbach Publications: Boca Raton, FL, USA, 2007. [Google Scholar]
- Priyana, R.; Handayani, E.T.E. Perancangan Game “Heroes Surabaya†Sebagai Edukasi Pengetahuan Sejarah Menggunakan Algoritma BFS Berbasis Android. JIMP (J. Inform. Merdeka Pasuruan) 2019, 4, 1–7. [Google Scholar] [CrossRef]
- Li, H. Binary Tree’s Recursion Traversal Algorithm and Its Improvement. J. Comput. Commun. 2016, 4, 42–47. [Google Scholar] [CrossRef]
- Nayak, J.; Naik, B.; Behera, H. Fuzzy C-means (FCM) clustering algorithm: A decade review from 2000 to 2014. In Computational Intelligence in Data Mining—Volume 2, Proceedings of the International Conference on CIDM, Orlando, FL, USA, 9–12 December 2014; Springer: Berlin/Heidelberg, Germany, 2015; pp. 133–149. [Google Scholar]
- Trauwaert, E. On the meaning of Dunn’s partition coefficient for fuzzy clusters. Fuzzy Sets Syst. 1988, 25, 217–242. [Google Scholar] [CrossRef]
- Meng, J.; Tang, W.; Tang, H.; Xu, W.; Wang, M. A Comprehensive Evaluation System Urban Distribution Network. In Proceedings of the 2018 IEEE 4th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 14–16 December 2018; pp. 1139–1143. [Google Scholar]
- Hanemann, A.; Liakopoulos, A.; Molina, M.; Swany, D.M. A study on network performance metrics and their composition. Campus-Wide Inf. Syst. 2006, 23, 268–282. [Google Scholar] [CrossRef]
- Pei, H.-X.; Zheng, Z.-R.; Wang, C.; Li, C.-N.; Shao, Y.-H. D-FCM: Density based fuzzy c-means clustering algorithm with application in medical image segmentation. Procedia Comput. Sci. 2017, 122, 407–414. [Google Scholar] [CrossRef]
- Yang, P.; Tong, L.; Qian, B.; Gao, Z.; Yu, J.; Xiao, C. Hyperspectral image classification with spectral and spatial graph using inductive representation learning network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 791–800. [Google Scholar] [CrossRef]
- Phunthawornwong, M.; Pengwang, E.; Silapunt, R. Indoor location estimation of wireless devices using the log-distance path loss model. In Proceedings of the TENCON 2018–2018 IEEE Region 10 Conference, Jeju, Republic of Korea, 28–31 October 2018; pp. 499–502. [Google Scholar]
- Jain, M.; Dovrolis, C. Path selection using available bandwidth estimation in overlay-based video streaming. Comput. Netw. 2008, 52, 2411–2418. [Google Scholar] [CrossRef]
- Zhang, H.; Guo, X.; Yan, J.; Liu, B.; Shuai, Q. SDN-based ECMP algorithm for data center networks. In Proceedings of the 2014 IEEE Computers, Communications and IT Applications Conference, Beijing, China, 20–22 October 2014; pp. 13–18. [Google Scholar]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, P.; Jing, C.; Zhu, X. GraphSAGE-Based Multi-Path Reliable Routing Algorithm for Wireless Mesh Networks. Processes 2023, 11, 1255. https://doi.org/10.3390/pr11041255
Lu P, Jing C, Zhu X. GraphSAGE-Based Multi-Path Reliable Routing Algorithm for Wireless Mesh Networks. Processes. 2023; 11(4):1255. https://doi.org/10.3390/pr11041255
Chicago/Turabian StyleLu, Pan, Chuanfang Jing, and Xiaorong Zhu. 2023. "GraphSAGE-Based Multi-Path Reliable Routing Algorithm for Wireless Mesh Networks" Processes 11, no. 4: 1255. https://doi.org/10.3390/pr11041255