
A Knowledge-Based Cooperative Differential Evolution Algorithm for Energy-Efficient Distributed Hybrid Flow-Shop Rescheduling Problem

Abstract
:1. Introduction
2. Distributed Hybrid Flow-Shop Rescheduling Problem
2.1. Problem Description
| Indices | Description |
| F | Number of factories. |
| f | Index of factories, . |
| The first order. | |
| The newly arrived order during the processing of . | |
| Number of jobs in . | |
| Number of jobs in . | |
| Number of jobs under processing at time in . | |
| Number of unprocessed jobs at time in . | |
| Index of jobs in , . | |
| Index of jobs in , . | |
| Index of jobs under processing at time , . | |
| Index of unprocessed jobs at time , . | |
| j | Index of all jobs, . |
| s | Number of stages. |
| k | Index of stages, . |
| Number of machines for stage k in factory f. | |
| i | Index of machines, . |
| Parameters | Description |
| The arrival time of . | |
| Processing time of job j at stage k. | |
| Energy consumption of machine i per unit time at stage k in factory f in | |
| processing mode. | |
| Energy consumption per unit time in idle mode. |
| Variables | Description |
| Energy consumption of machine i in processing mode at stage k in factory f. | |
| Energy consumption of machine i in idle mode at stage k in factory f. | |
| Begin time of processing job j at stage k. | |
| Completion time of processing job j at stage k. | |
| Makespan of . | |
| Makespan of . | |
| Total energy consumption. |
| Decision Variables | Description |
| Binary variable whose value equals 1 when job j is assigned to | |
| factory f or 0 otherwise. | |
| Binary variable whose value equals 1 when job j is assigned to | |
| machine i at stage k in factory f or 0 otherwise. | |
| Binary variable whose value equals 1 when job j is processed | |
| before on machine i at stage k in factory f or 0 otherwise. |
2.2. Mathematical Model
3. KCDE for EDHFRP
3.1. Solution Representation
3.2. Hybrid Initialization
| Algorithm 1: Greedy NEH heuristic |
 |
| Algorithm 2: NEH heuristic with biased optimization |
 |
3.3. 3D Knowledge Base
3.4. Cooperative DE
| Algorithm 3: Cooperative Differential Evolution |
 |
3.4.1. Mutation
3.4.2. Crossover
3.4.3. Selection
3.5. Local Intensification
| Algorithm 4: Local intensification |
 |
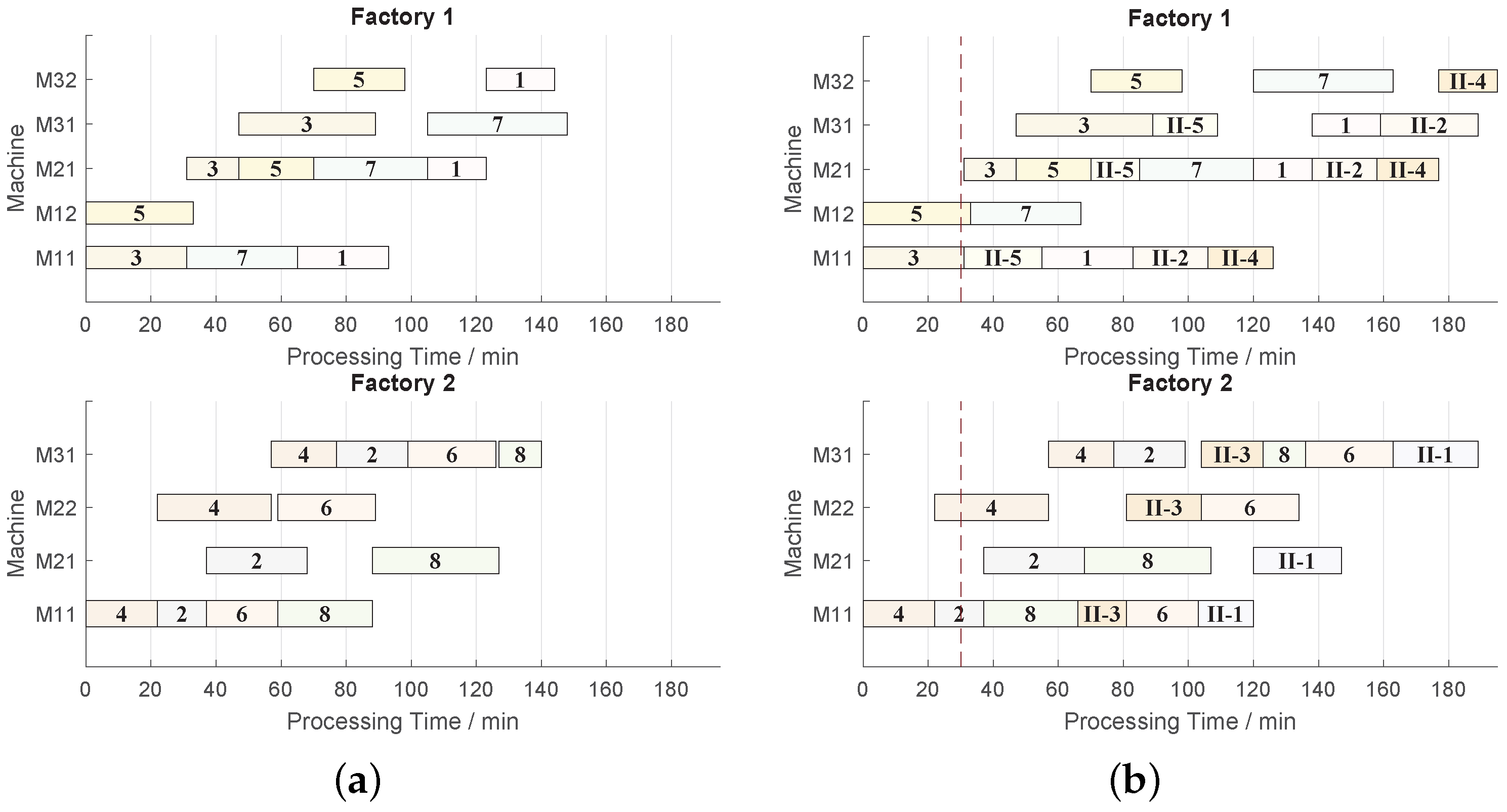
3.6. Rescheduling Strategy
- The state of jobs in at time are recorded, and the unprocessed jobs are counted.
- The unprocessed jobs are then put with jobs in , together forming the new order. The factory assignments of unprocessed jobs are also recorded, which are used as the constraints during the rescheduling stage since the jobs cannot be transformed into other factories once assigned.
- The available machine times are updated into the completion times of jobs, which are processed at time .
3.7. Framework of KCDE
4. Numerical Results and Comparisons
4.1. Experimental Settings
4.2. Model Validation
4.3. Parameter Setting
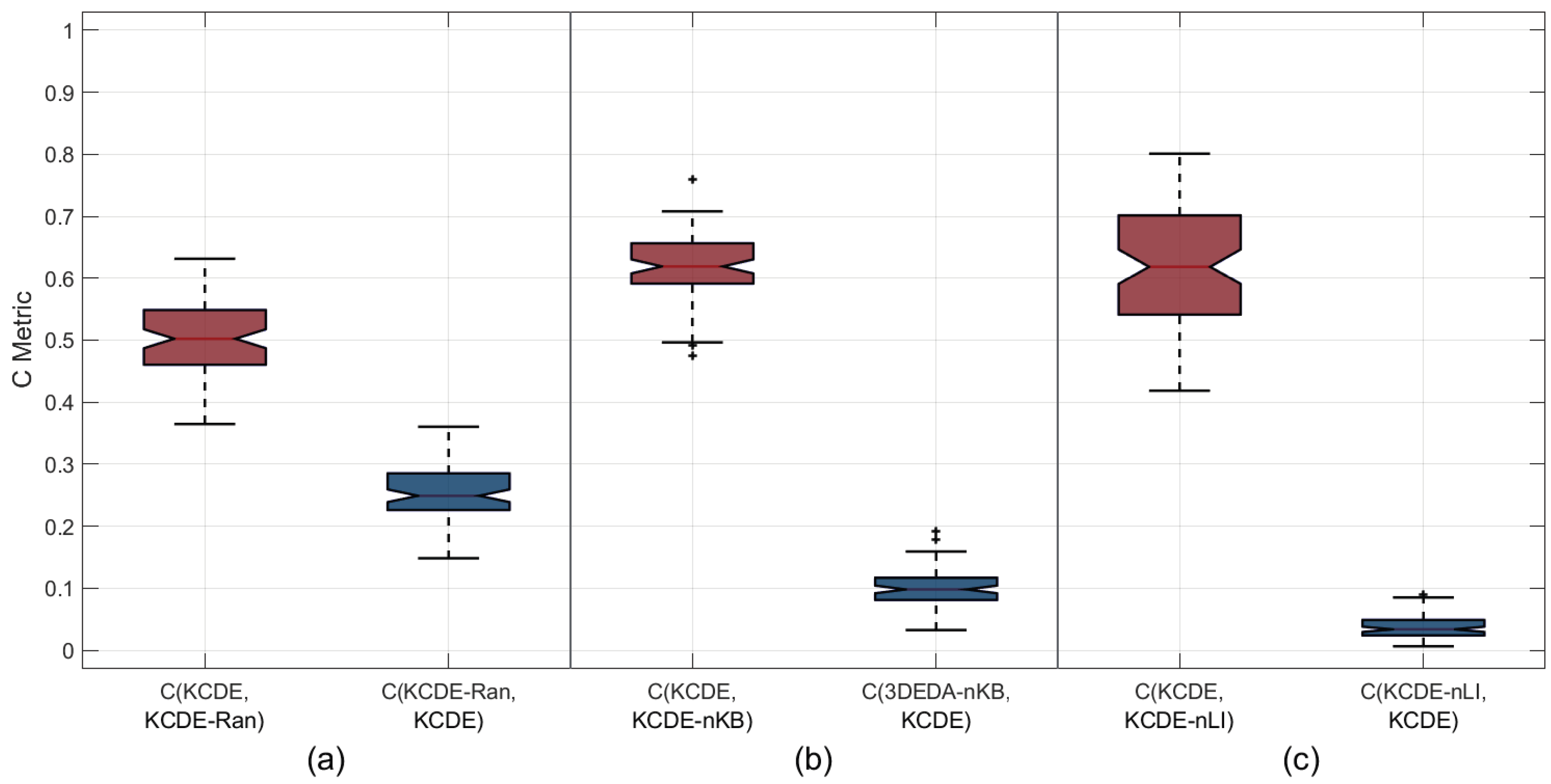
4.4. Effect of Hybrid Initialization
4.5. Effect of Knowledge Base
4.6. Effect of Local Intensification
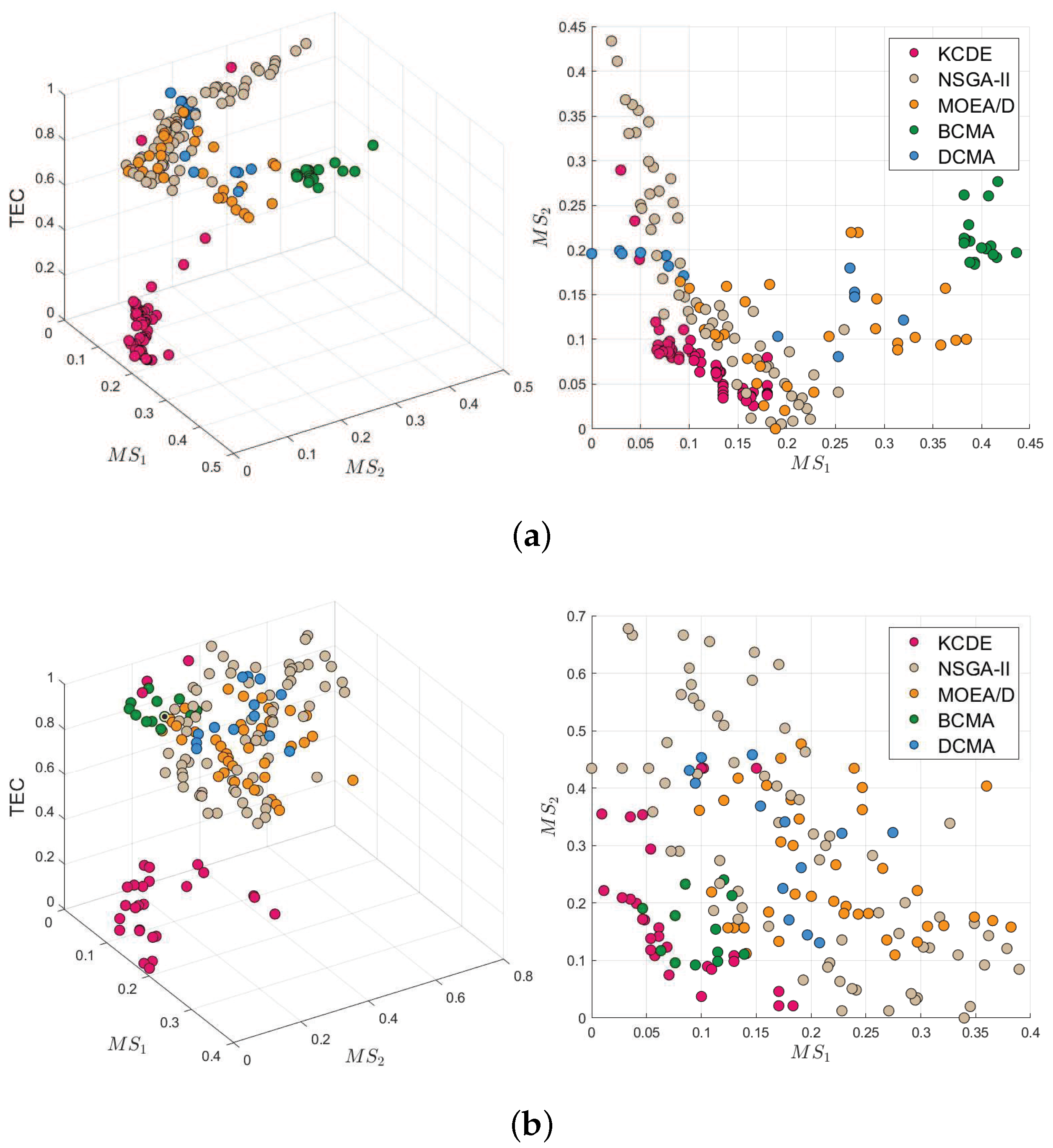
4.7. Comparisons to Other Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, K.; Huang, Y.; Sadollah, A.; Wang, L. A review of energy-efficient scheduling in intelligent production systems. Complex Intell. Syst. 2020, 6, 237–249. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, C.; Chen, X.; Jia, L.; Guo, X.; Chen, R.; Zhang, M.; Chen, Z.; Wang, H. Carbon peak and carbon neutrality in China: Goals, implementation path and prospects. China Geol. 2021, 4, 720–746. [Google Scholar] [CrossRef]
- Fu, Y.; Hou, Y.; Wang, Z.; Wu, X.; Gao, K.; Wang, L. Distributed scheduling problems in intelligent manufacturing systems. Tsinghua Sci. Technol. 2021, 26, 625–645. [Google Scholar] [CrossRef]
- Li, J.; Song, M.; Wang, L.; Duan, P.; Han, Y.; Sang, H.; Pan, Q. Hybrid artificial bee colony algorithm for a parallel batching distributed flow-shop problem with deteriorating jobs. IEEE Trans. Cybern. 2020, 50, 2425–2439. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.; Xu, Z.; Wang, L.; Zhu, N.; Xu, T.; Jonrinaldi. A population-based iterated greedy algorithm for distributed assembly no-wait flow-shop scheduling problem. IEEE Trans. Ind. Inform. 2022, 1–12, early access. [Google Scholar] [CrossRef]
- Zhao, F.; Ma, R.; Wang, L. A self-learning discrete Jaya algorithm for multiobjective energy-efficient distributed no-idle flow-shop scheduling problem in heterogeneous factory system. IEEE Trans. Cybern. 2022, 52, 12675–12686. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, L. A bi-population cooperative memetic algorithm for distributed hybrid flow-shop scheduling. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 947–961. [Google Scholar] [CrossRef]
- Pan, Z.; Lei, D.; Wang, L. A knowledge-based two-population optimization algorithm for distributed energy-efficient parallel machines scheduling. IEEE Trans. Cybern. 2022, 52, 5051–5063. [Google Scholar] [CrossRef]
- Pan, Q.; Gao, L.; Wang, L. An effective cooperative co-evolutionary algorithm for distributed flowshop group scheduling problems. IEEE Trans. Cybern. 2022, 52, 5999–6012. [Google Scholar] [CrossRef]
- Shao, W.; Shao, Z.; Pi, D. An ant colony optimization behavior-based MOEA/D for distributed heterogeneous hybrid flow shop scheduling problem under nonidentical time-of-use electricity tariffs. IEEE Trans. Cybern. 2022, 19, 3379–3394. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, B.; Wang, L.; Yu, D.; Xing, K. Distributed co-evolutionary memetic algorithm for distributed hybrid differentiation flowshop scheduling problem. IEEE Trans. Evol. Comput. 2022, 26, 1043–1057. [Google Scholar] [CrossRef]
- Jiang, E.; Wang, L.; Wang, J. Decomposition-based multi-objective optimization for energy-aware distributed hybrid flow shop scheduling with multiprocessor tasks. Tsinghua Sci. Technol. 2021, 26, 646–663. [Google Scholar] [CrossRef]
- Li, J.; Chen, X.; Duan, P.; Mou, J. KMOEA: A knowledge-based multiobjective algorithm for distributed hybrid flow shop in a prefabricated system. IEEE Trans. Ind. Informatics 2022, 18, 5318–5329. [Google Scholar] [CrossRef]
- Framinan, J.M.; Viagas, V.F.; Gonzalez, P.P. Using real-time information to reschedule jobs in a flowshop with variable processing times. Comput. Ind. Eng. 2019, 129, 113–125. [Google Scholar] [CrossRef]
- Gao, K.; Yang, F.; Zhou, M.; Pan, Q.; Suganthan, P.N. Flexible Job-shop rescheduling for new job insertion by using discrete Jaya algorithm. IEEE Trans. Cybern. 2019, 49, 1944–1955. [Google Scholar] [CrossRef]
- Gao, K.; Yang, F.; Li, J.; Sang, H.; Luo, J. Improved Jaya algorithm for flexible job shop rescheduling problem. IEEE Access 2020, 8, 86915–86922. [Google Scholar] [CrossRef]
- Nouiri, M.; Bekrar, A.; Trentesaux, D. Towards energy efficient scheduling and rescheduling for dynamic flexible job shop problem. IFAC-PapersOnLine 2018, 51, 1275–1280. [Google Scholar] [CrossRef]
- An, Y.; Chen, X.; Gao, K.; Zhang, L.; Li, Y.; Zhao, Z. A hybrid multi-objective evolutionary algorithm for solving an adaptive flexible job-shop rescheduling problem with real-time order acceptance and condition-based preventive maintenance. Swarm Evol. Comput. 2023, 77, 101243. [Google Scholar] [CrossRef]
- An, Y.; Chen, X.; Gao, K.; Zhang, L.; Li, Y.; Zhao, Z. Integrated optimization of real-time order acceptance and flexible job-shop rescheduling with multi-level imperfect maintenance constraints. Expert Syst. Appl. 2023, 212, 178711. [Google Scholar] [CrossRef]
- Lv, Y.; Li, C.; Tang, Y.; Kou, Y. Toward energy-efficient rescheduling decision mechanisms for flexible job shop with dynamic events and alternative process plans. IEEE Trans. Autom. Sci. Eng. 2022, 19, 3259–3275. [Google Scholar] [CrossRef]
- Wang, Z.; Shen, L.; Li, X.; Gao, L. An improved multi-objective firefly algorithm for energy-efficient hybrid flowshop rescheduling problem. J. Clean. Prod. 2023, 385, 135738. [Google Scholar] [CrossRef]
- Li, J.; Pan, Q.; Mao, K. A hybrid fruit fly optimization algorithm for the realistic hybrid flowshop rescheduling problem in steelmaking systems. IEEE Trans. Autom. Sci. Eng. 2016, 13, 932–949. [Google Scholar] [CrossRef]
- Peng, K.; Pan, Q.; Gao, L.; Li, X.; Das, S.; Zhao, B. A multi-start variable neighbourhood descent algorithm for hybrid flowshop rescheduling. Swarm Evol. Comput. 2019, 45, 92–112. [Google Scholar] [CrossRef]
- Guo, Y.; Huang, M.; Wang, Q.; Leon, V.J. Single-machine rework rescheduling to minimize total waiting time with fixed sequence of jobs and release times. IEEE Access 2021, 9, 1205–1218. [Google Scholar] [CrossRef]
- Silva, N.C.O.; Scarpin, C.T.; Ruiz, A.; Pécora, J.E. Rescheduling production on identical parallel machines upon new jobs arrivals. IFAC-PapersOnLine 2019, 52, 2525–2530. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Opara, K.R.; Arabas, J. Differential evolution: A survey of theoretical analyses. Swarm Evol. Comput. 2019, 44, 546–558. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Y.; Yang, Y.; Gen, M. Hybrid multiobjective evolutionary algorithm based on differential evolution for flow shop scheduling problems. Comput. Ind. Eng. 2019, 130, 661–670. [Google Scholar] [CrossRef]
- Morais, M.F.; Ribeiro, M.; Silva, R.G.; Mariani, V.C.; Coelho, L. Discrete differential evolution metaheuristics for permutation flow shop scheduling problems. Comput. Ind. Eng. 2022, 166, 107956. [Google Scholar] [CrossRef]
- Santucci, V.; Baioletti, M.; Milani, A. Algebraic differential evolution algorithm for the permutation flowshop scheduling problem with total flowtime criterion. IEEE Trans. Evol. Comput. 2016, 20, 682–694. [Google Scholar] [CrossRef]
- Xue, L.; Wu, X. A multi-objective discrete differential evolution algorithm for energy-efficient two-stage flow shop scheduling under time-of-use electricity tariffs. Appl. Soft Comput. 2023, 133, 109946. [Google Scholar] [CrossRef]
- Li, H.; Wang, X.; Peng, J. A hybrid differential evolution algorithm for flexible job shop scheduling with outsourcing operations and job priority constraints. Expert Syst. Appl. 2022, 201, 117182. [Google Scholar] [CrossRef]
- Mahmoodjanloo, M.; Moghaddam, R.T.; Baboli, A.; Amiri, A.B. Flexible job shop scheduling problem with reconfigurable machine tools: An improved differential evolution algorithm. Appl. Soft Comput. 2020, 94, 106416. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, L. Differential evolution algorithm for hybrid flow-shop scheduling problems. J. Syst. Eng. Electron. 2011, 22, 794–798. [Google Scholar] [CrossRef]
- Gao, D.; Wang, G.; Pedrycz, W. Solving fuzzy job-shop scheduling problem using DE algorithm improved by a selection mechanism. IEEE Trans. Fuzzy Syst. 2020, 28, 3265–3275. [Google Scholar] [CrossRef]
- Wang, G.; Gao, D.; Pedrycz, W. Solving multiobjective fuzzy job-shop scheduling problem by a hybrid adaptive differential evolution algorithm. IEEE Trans. Ind. Inform. 2022, 18, 8519–8528. [Google Scholar] [CrossRef]
- Wu, X.; Wang, L. Multiobjective differential evolution algorithm for solving robotic cell scheduling problem with batch-processing machines. IEEE Trans. Autom. Sci. Eng. 2021, 18, 757–775. [Google Scholar] [CrossRef]
- Zhou, S.; Xing, L.; Zheng, X.; Du, N.; Wang, L.; Zhang, Q. A self-adaptive differential evolution algorithm for scheduling a single batch-processing machine with arbitrary job sizes and release times. IEEE Trans. Cybern. 2021, 51, 1430–1442. [Google Scholar] [CrossRef]
- Nawaz, M.; Ensore, E.E.; Ham, I. A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega 1983, 11, 91–95. [Google Scholar] [CrossRef]
- Viagas, V.F.; Ruiz, R.; Framinan, J.M. A new vision of approximate methods for the permutation flowshop to minimise makespan: State-of-the-art and computational evaluation. Eur. J. Oper. Res. 2017, 257, 707–721. [Google Scholar] [CrossRef]
- Wang, J.; Wang, L. A cooperative memetic algorithm with learning-based agent for energy-aware distributed hybrid flow-shop scheduling. IEEE Trans. Evol. Comput. 2022, 26, 1–14. [Google Scholar] [CrossRef]
- Zhao, F.; Di, S.; Wang, L. A hyperheuristic with Q-learning for the multiobjective energy-efficient distributed blocking flow shop scheduling problem. IEEE Trans. Cybern. 2022, 1–14, early access. [Google Scholar] [CrossRef]
- Bilal; Pant, M.; Zaheer, H.; Garcia-Hernandez, L.; Abraham, A. Differential evolution: A review of more than two decades of research. Eng. Appl. Artif. Intell. 2020, 90, 103479. [Google Scholar] [CrossRef]
- Das, S.; Mullick, S.S.; Suganthan, P.N. Recent advances in differential evolution—An updated survey. Swarm Evol. Comput. 2016, 27, 1–30. [Google Scholar] [CrossRef]
- Mahmud, S.; Abbasi, A.; Chakrabortty, R.K.; Ryan, M.J. Multi-operator communication based differential evolution with sequential Tabu Search approach for job shop scheduling problems. Appl. Soft Comput. 2021, 108, 107470. [Google Scholar] [CrossRef]
- Hou, Y.; Wu, Y.; Liu, Z.; Han, H.; Wang, P. Dynamic multi-objective differential evolution algorithm based on the information of evolution progress. Sci. China Technol. Sci. 2021, 64, 1676–1689. [Google Scholar] [CrossRef]
- Wu, X.; Liu, X.; Zhao, N. An improved differential evolution algorithm for solving a distributed assembly flexible job shop scheduling problem. Memetic Comput. 2019, 11, 335–355. [Google Scholar] [CrossRef]
- Zitzler, E.; Deb, K.; Thiele, L. Comparison of multiobjective evolutionary algorithms: Empirical results. Evol. Comput. 2000, 8, 173–195. [Google Scholar] [CrossRef] [PubMed]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | Original Order | Rescheduling Plan | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CPLEX | KCDE | CPLEX | KCDE | |||||||
| f2n4+3s2 | 117.70 | 33.67 | 117.70 | 33.27 | 119.10 | 107.40 | 68.34 | 118.20 | 107.40 | 65.14 |
| f2n4+3s2 | 118.50 | 33.02 | 118.20 | 32.66 | 143.90 | 143.00 | 59.62 | 143.80 | 142.50 | 58.70 |
| f2n4+3s3 | 123.00 | 55.35 | 123.00 | 55.27 | 166.00 | 179.70 | 103.55 | 164.10 | 178.20 | 99.95 |
| f2n4+3s3 | 146.20 | 61.90 | 145.60 | 61.43 | 153.00 | 195.10 | 96.44 | 153.00 | 195.00 | 94.55 |
| f2n5+3s2 | 82.30 | 44.07 | 82.00 | 43.23 | 121.40 | 119.00 | 76.44 | 121.30 | 118.10 | 74.04 |
| f2n5+3s2 | 150.20 | 43.42 | 150.20 | 43.39 | 149.60 | 151.50 | 79.13 | 149.60 | 151.50 | 76.13 |
| f2n5+3s3 | 126.90 | 58.47 | 126.90 | 58.48 | 146.00 | 102.90 | 115.95 | 145.70 | 102.40 | 113.76 |
| f2n5+3s3 | 200.60 | 74.07 | 200.60 | 73.04 | 228.90 | 176.80 | 121.70 | 228.60 | 176.00 | 120.34 |
| f3n5+3s2 | 96.30 | 40.88 | 95.90 | 40.71 | 99.10 | 105.00 | 99.84 | 98.50 | 103.00 | 98.47 |
| f3n5+3s2 | 139.50 | 40.53 | 139.50 | 40.51 | 140.00 | 142.30 | 96.76 | 138.80 | 140.10 | 96.32 |
| Experiment | Factor Level | HV | ||
|---|---|---|---|---|
| Number | F | |||
| 1 | 1 | 1 | 1 | 0.77799 |
| 2 | 1 | 2 | 2 | 0.76874 |
| 3 | 1 | 3 | 3 | 0.78359 |
| 4 | 1 | 4 | 4 | 0.78363 |
| 5 | 2 | 1 | 2 | 0.77442 |
| 6 | 2 | 2 | 1 | 0.77722 |
| 7 | 2 | 3 | 4 | 0.78411 |
| 8 | 2 | 4 | 3 | 0.78266 |
| 9 | 3 | 1 | 3 | 0.77947 |
| 10 | 3 | 2 | 4 | 0.78020 |
| 11 | 3 | 3 | 1 | 0.78163 |
| 12 | 3 | 4 | 2 | 0.78488 |
| 13 | 4 | 1 | 4 | 0.77749 |
| 14 | 4 | 2 | 3 | 0.77721 |
| 15 | 4 | 3 | 2 | 0.77504 |
| 16 | 4 | 4 | 1 | 0.78175 |
| Level | F | ||
|---|---|---|---|
| 1 | 0.77849 | 0.77734 | 0.77965 |
| 2 | 0.77960 | 0.77584 | 0.77577 |
| 3 | 0.78154 | 0.78109 | 0.78073 |
| 4 | 0.77787 | 0.78323 | 0.78136 |
| Delta | 0.00367 | 0.00738 | 0.00559 |
| Rank | 3 | 1 | 2 |
| Dataset | 1 | 2 | p | Dataset | p | Dataset | p | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| f3n30+20s4 | 0.43 | 0.31 | 0.02 | f4n30+20s4 | 0.53 | 0.24 | 0.02 | f5n30+20s4 | 0.50 | 0.23 | 0.02 |
| f3n30+20s5 | 0.47 | 0.34 | 0.02 | f4n30+20s5 | 0.44 | 0.32 | 0.02 | f5n30+20s5 | 0.45 | 0.29 | 0.02 |
| f3n30+20s6 | 0.43 | 0.32 | 0.02 | f4n30+20s6 | 0.43 | 0.29 | 0.02 | f5n30+20s6 | 0.39 | 0.31 | 0.02 |
| f3n30+30s4 | 0.47 | 0.30 | 0.02 | f4n30+30s4 | 0.50 | 0.30 | 0.02 | f5n30+30s4 | 0.45 | 0.28 | 0.02 |
| f3n30+30s5 | 0.52 | 0.27 | 0.02 | f4n30+30s5 | 0.53 | 0.24 | 0.00 | f5n30+30s5 | 0.56 | 0.24 | 0.00 |
| f3n30+30s6 | 0.53 | 0.28 | 0.02 | f4n30+30s6 | 0.46 | 0.36 | 0.02 | f5n30+30s6 | 0.53 | 0.25 | 0.02 |
| f3n30+50s4 | 0.61 | 0.19 | 0.00 | f4n30+50s4 | 0.53 | 0.28 | 0.02 | f5n30+50s4 | 0.58 | 0.23 | 0.02 |
| f3n30+50s5 | 0.54 | 0.26 | 0.02 | f4n30+50s5 | 0.53 | 0.27 | 0.02 | f5n30+50s5 | 0.54 | 0.23 | 0.02 |
| f3n30+50s6 | 0.49 | 0.35 | 0.02 | f4n30+50s6 | 0.48 | 0.31 | 0.02 | f5n30+50s6 | 0.61 | 0.19 | 0.00 |
| f3n50+20s4 | 0.42 | 0.28 | 0.02 | f4n50+20s4 | 0.47 | 0.26 | 0.02 | f5n50+20s4 | 0.44 | 0.24 | 0.00 |
| f3n50+20s5 | 0.53 | 0.28 | 0.02 | f4n50+20s5 | 0.41 | 0.28 | 0.02 | f5n50+20s5 | 0.46 | 0.32 | 0.02 |
| f3n50+20s6 | 0.48 | 0.29 | 0.02 | f4n50+20s6 | 0.50 | 0.24 | 0.00 | f5n50+20s6 | 0.46 | 0.32 | 0.02 |
| f3n50+30s4 | 0.54 | 0.19 | 0.02 | f4n50+30s4 | 0.55 | 0.24 | 0.02 | f5n50+30s4 | 0.48 | 0.29 | 0.02 |
| f3n50+30s5 | 0.57 | 0.27 | 0.02 | f4n50+30s5 | 0.46 | 0.33 | 0.02 | f5n50+30s5 | 0.54 | 0.26 | 0.02 |
| f3n50+30s6 | 0.51 | 0.29 | 0.02 | f4n50+30s6 | 0.51 | 0.26 | 0.02 | f5n50+30s6 | 0.49 | 0.30 | 0.02 |
| f3n50+50s4 | 0.60 | 0.22 | 0.02 | f4n50+50s4 | 0.58 | 0.23 | 0.00 | f5n50+50s4 | 0.57 | 0.22 | 0.00 |
| f3n50+50s5 | 0.63 | 0.20 | 0.02 | f4n50+50s5 | 0.56 | 0.26 | 0.02 | f5n50+50s5 | 0.62 | 0.19 | 0.00 |
| f3n50+50s6 | 0.59 | 0.24 | 0.02 | f4n50+50s6 | 0.57 | 0.23 | 0.00 | f5n50+50s6 | 0.59 | 0.23 | 0.00 |
| f3n80+20s4 | 0.47 | 0.19 | 0.02 | f4n80+20s4 | 0.45 | 0.26 | 0.02 | f5n80+20s4 | 0.40 | 0.22 | 0.02 |
| f3n80+20s5 | 0.50 | 0.28 | 0.02 | f4n80+20s5 | 0.43 | 0.22 | 0.02 | f5n80+20s5 | 0.52 | 0.22 | 0.00 |
| f3n80+20s6 | 0.45 | 0.29 | 0.02 | f4n80+20s6 | 0.49 | 0.24 | 0.02 | f5n80+20s6 | 0.36 | 0.23 | 0.02 |
| f3n80+30s4 | 0.48 | 0.18 | 0.02 | f4n80+30s4 | 0.47 | 0.22 | 0.02 | f5n80+30s4 | 0.48 | 0.15 | 0.00 |
| f3n80+30s5 | 0.55 | 0.24 | 0.02 | f4n80+30s5 | 0.46 | 0.27 | 0.02 | f5n80+30s5 | 0.50 | 0.29 | 0.02 |
| f3n80+30s6 | 0.47 | 0.24 | 0.02 | f4n80+30s6 | 0.56 | 0.20 | 0.00 | f5n80+30s6 | 0.44 | 0.28 | 0.02 |
| f3n80+50s4 | 0.52 | 0.23 | 0.02 | f4n80+50s4 | 0.54 | 0.24 | 0.02 | f5n80+50s4 | 0.62 | 0.16 | 0.00 |
| f3n80+50s5 | 0.57 | 0.19 | 0.02 | f4n80+50s5 | 0.50 | 0.26 | 0.02 | f5n80+50s5 | 0.60 | 0.23 | 0.02 |
| f3n80+50s6 | 0.52 | 0.21 | 0.02 | f4n80+50s6 | 0.55 | 0.19 | 0.02 | f5n80+50s6 | 0.60 | 0.22 | 0.02 |
| Dataset | 1 | 2 | p | Dataset | p | Dataset | p | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| f3n30+20s4 | 0.68 | 0.11 | 0.00 | f4n30+20s4 | 0.68 | 0.12 | 0.00 | f5n30+20s4 | 0.64 | 0.09 | 0.00 |
| f3n30+20s5 | 0.64 | 0.15 | 0.00 | f4n30+20s5 | 0.53 | 0.18 | 0.02 | f5n30+20s5 | 0.70 | 0.07 | 0.00 |
| f3n30+20s6 | 0.61 | 0.13 | 0.00 | f4n30+20s6 | 0.65 | 0.11 | 0.00 | f5n30+20s6 | 0.63 | 0.10 | 0.00 |
| f3n30+30s4 | 0.67 | 0.10 | 0.00 | f4n30+30s4 | 0.62 | 0.12 | 0.02 | f5n30+30s4 | 0.70 | 0.06 | 0.00 |
| f3n30+30s5 | 0.68 | 0.12 | 0.00 | f4n30+30s5 | 0.67 | 0.09 | 0.00 | f5n30+30s5 | 0.71 | 0.08 | 0.00 |
| f3n30+30s6 | 0.65 | 0.09 | 0.00 | f4n30+30s6 | 0.70 | 0.12 | 0.00 | f5n30+30s6 | 0.69 | 0.12 | 0.00 |
| f3n30+50s4 | 0.64 | 0.09 | 0.00 | f4n30+50s4 | 0.65 | 0.11 | 0.02 | f5n30+50s4 | 0.76 | 0.06 | 0.00 |
| f3n30+50s5 | 0.61 | 0.19 | 0.02 | f4n30+50s5 | 0.68 | 0.10 | 0.00 | f5n30+50s5 | 0.67 | 0.09 | 0.00 |
| f3n30+50s6 | 0.58 | 0.12 | 0.00 | f4n30+50s6 | 0.59 | 0.11 | 0.00 | f5n30+50s6 | 0.65 | 0.09 | 0.00 |
| f3n50+20s4 | 0.55 | 0.11 | 0.00 | f4n50+20s4 | 0.60 | 0.10 | 0.00 | f5n50+20s4 | 0.59 | 0.09 | 0.00 |
| f3n50+20s5 | 0.58 | 0.16 | 0.00 | f4n50+20s5 | 0.55 | 0.15 | 0.00 | f5n50+20s5 | 0.67 | 0.10 | 0.00 |
| f3n50+20s6 | 0.61 | 0.09 | 0.00 | f4n50+20s6 | 0.54 | 0.12 | 0.00 | f5n50+20s6 | 0.67 | 0.10 | 0.00 |
| f3n50+30s4 | 0.59 | 0.07 | 0.00 | f4n50+30s4 | 0.68 | 0.09 | 0.00 | f5n50+30s4 | 0.65 | 0.07 | 0.00 |
| f3n50+30s5 | 0.66 | 0.09 | 0.00 | f4n50+30s5 | 0.59 | 0.10 | 0.00 | f5n50+30s5 | 0.66 | 0.11 | 0.00 |
| f3n50+30s6 | 0.62 | 0.07 | 0.00 | f4n50+30s6 | 0.59 | 0.12 | 0.02 | f5n50+30s6 | 0.62 | 0.09 | 0.00 |
| f3n50+50s4 | 0.65 | 0.07 | 0.00 | f4n50+50s4 | 0.61 | 0.10 | 0.00 | f5n50+50s4 | 0.61 | 0.10 | 0.00 |
| f3n50+50s5 | 0.60 | 0.11 | 0.00 | f4n50+50s5 | 0.62 | 0.12 | 0.00 | f5n50+50s5 | 0.62 | 0.12 | 0.00 |
| f3n50+50s6 | 0.66 | 0.09 | 0.00 | f4n50+50s6 | 0.59 | 0.12 | 0.00 | f5n50+50s6 | 0.56 | 0.13 | 0.00 |
| f3n80+20s4 | 0.50 | 0.08 | 0.00 | f4n80+20s4 | 0.63 | 0.12 | 0.00 | f5n80+20s4 | 0.49 | 0.10 | 0.00 |
| f3n80+20s5 | 0.59 | 0.08 | 0.00 | f4n80+20s5 | 0.60 | 0.11 | 0.00 | f5n80+20s5 | 0.57 | 0.14 | 0.02 |
| f3n80+20s6 | 0.55 | 0.09 | 0.00 | f4n80+20s6 | 0.60 | 0.12 | 0.02 | f5n80+20s6 | 0.47 | 0.12 | 0.00 |
| f3n80+30s4 | 0.58 | 0.06 | 0.00 | f4n80+30s4 | 0.65 | 0.07 | 0.00 | f5n80+30s4 | 0.52 | 0.11 | 0.00 |
| f3n80+30s5 | 0.65 | 0.03 | 0.00 | f4n80+30s5 | 0.61 | 0.06 | 0.00 | f5n80+30s5 | 0.65 | 0.08 | 0.02 |
| f3n80+30s6 | 0.59 | 0.05 | 0.00 | f4n80+30s6 | 0.61 | 0.08 | 0.00 | f5n80+30s6 | 0.58 | 0.10 | 0.00 |
| f3n80+50s4 | 0.56 | 0.06 | 0.00 | f4n80+50s4 | 0.64 | 0.05 | 0.00 | f5n80+50s4 | 0.59 | 0.05 | 0.00 |
| f3n80+50s5 | 0.58 | 0.07 | 0.00 | f4n80+50s5 | 0.67 | 0.04 | 0.00 | f5n80+50s5 | 0.64 | 0.08 | 0.00 |
| f3n80+50s6 | 0.58 | 0.08 | 0.00 | f4n80+50s6 | 0.63 | 0.07 | 0.00 | f5n80+50s6 | 0.61 | 0.09 | 0.00 |
| Dataset | 1 | 2 | p | Dataset | p | Dataset | p | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| f3n30+20s4 | 0.67 | 0.03 | 0.00 | f4n30+20s4 | 0.73 | 0.02 | 0.00 | f5n30+20s4 | 0.66 | 0.03 | 0.00 |
| f3n30+20s5 | 0.55 | 0.03 | 0.00 | f4n30+20s5 | 0.64 | 0.03 | 0.02 | f5n30+20s5 | 0.67 | 0.03 | 0.00 |
| f3n30+20s6 | 0.55 | 0.05 | 0.00 | f4n30+20s6 | 0.72 | 0.02 | 0.00 | f5n30+20s6 | 0.63 | 0.03 | 0.00 |
| f3n30+30s4 | 0.59 | 0.02 | 0.00 | f4n30+30s4 | 0.75 | 0.02 | 0.00 | f5n30+30s4 | 0.65 | 0.03 | 0.00 |
| f3n30+30s5 | 0.56 | 0.03 | 0.00 | f4n30+30s5 | 0.72 | 0.02 | 0.00 | f5n30+30s5 | 0.71 | 0.01 | 0.00 |
| f3n30+30s6 | 0.65 | 0.03 | 0.00 | f4n30+30s6 | 0.78 | 0.01 | 0.00 | f5n30+30s6 | 0.69 | 0.02 | 0.00 |
| f3n30+50s4 | 0.65 | 0.03 | 0.00 | f4n30+50s4 | 0.71 | 0.02 | 0.00 | f5n30+50s4 | 0.80 | 0.01 | 0.00 |
| f3n30+50s5 | 0.53 | 0.02 | 0.00 | f4n30+50s5 | 0.79 | 0.01 | 0.00 | f5n30+50s5 | 0.72 | 0.01 | 0.00 |
| f3n30+50s6 | 0.62 | 0.03 | 0.00 | f4n30+50s6 | 0.74 | 0.01 | 0.00 | f5n30+50s6 | 0.79 | 0.01 | 0.00 |
| f3n50+20s4 | 0.56 | 0.07 | 0.00 | f4n50+20s4 | 0.69 | 0.04 | 0.00 | f5n50+20s4 | 0.63 | 0.03 | 0.00 |
| f3n50+20s5 | 0.51 | 0.07 | 0.02 | f4n50+20s5 | 0.70 | 0.04 | 0.00 | f5n50+20s5 | 0.61 | 0.05 | 0.00 |
| f3n50+20s6 | 0.48 | 0.06 | 0.00 | f4n50+20s6 | 0.58 | 0.05 | 0.00 | f5n50+20s6 | 0.61 | 0.05 | 0.00 |
| f3n50+30s4 | 0.63 | 0.05 | 0.00 | f4n50+30s4 | 0.75 | 0.03 | 0.00 | f5n50+30s4 | 0.71 | 0.02 | 0.00 |
| f3n50+30s5 | 0.52 | 0.06 | 0.00 | f4n50+30s5 | 0.68 | 0.03 | 0.00 | f5n50+30s5 | 0.62 | 0.02 | 0.00 |
| f3n50+30s6 | 0.52 | 0.05 | 0.00 | f4n50+30s6 | 0.58 | 0.05 | 0.00 | f5n50+30s6 | 0.66 | 0.03 | 0.00 |
| f3n50+50s4 | 0.62 | 0.04 | 0.00 | f4n50+50s4 | 0.78 | 0.03 | 0.00 | f5n50+50s4 | 0.74 | 0.02 | 0.00 |
| f3n50+50s5 | 0.51 | 0.04 | 0.00 | f4n50+50s5 | 0.72 | 0.02 | 0.00 | f5n50+50s5 | 0.67 | 0.01 | 0.00 |
| f3n50+50s6 | 0.47 | 0.04 | 0.00 | f4n50+50s6 | 0.53 | 0.04 | 0.00 | f5n50+50s6 | 0.66 | 0.02 | 0.00 |
| f3n80+20s4 | 0.55 | 0.09 | 0.02 | f4n80+20s4 | 0.59 | 0.05 | 0.00 | f5n80+20s4 | 0.60 | 0.04 | 0.00 |
| f3n80+20s5 | 0.46 | 0.09 | 0.02 | f4n80+20s5 | 0.56 | 0.05 | 0.02 | f5n80+20s5 | 0.57 | 0.04 | 0.00 |
| f3n80+20s6 | 0.48 | 0.08 | 0.00 | f4n80+20s6 | 0.50 | 0.07 | 0.00 | f5n80+20s6 | 0.58 | 0.04 | 0.00 |
| f3n80+30s4 | 0.52 | 0.07 | 0.00 | f4n80+30s4 | 0.66 | 0.04 | 0.00 | f5n80+30s4 | 0.59 | 0.05 | 0.00 |
| f3n80+30s5 | 0.44 | 0.08 | 0.02 | f4n80+30s5 | 0.57 | 0.06 | 0.02 | f5n80+30s5 | 0.52 | 0.04 | 0.02 |
| f3n80+30s6 | 0.48 | 0.08 | 0.02 | f4n80+30s6 | 0.42 | 0.06 | 0.02 | f5n80+30s6 | 0.71 | 0.04 | 0.02 |
| f3n80+50s4 | 0.49 | 0.05 | 0.00 | f4n80+50s4 | 0.71 | 0.04 | 0.00 | f5n80+50s4 | 0.71 | 0.03 | 0.00 |
| f3n80+50s5 | 0.43 | 0.06 | 0.02 | f4n80+50s5 | 0.59 | 0.03 | 0.00 | f5n80+50s5 | 0.60 | 0.02 | 0.00 |
| f3n80+50s6 | 0.46 | 0.05 | 0.00 | f4n80+50s6 | 0.44 | 0.05 | 0.00 | f5n80+50s6 | 0.70 | 0.02 | 0.00 |
| Dataset | 1 | 2 | p | 3 | 4 | p | 5 | 6 | p | 7 | 8 | p |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| f3n30+20 | 0.735 | 0.018 | 0.00 | 0.796 | 0.014 | 0.00 | 0.517 | 0.013 | 0.00 | 0.705 | 0.000 | 0.00 |
| f3n30+30 | 0.763 | 0.013 | 0.00 | 0.792 | 0.011 | 0.00 | 0.500 | 0.010 | 0.00 | 0.595 | 0.000 | 0.00 |
| f3n30+50 | 0.731 | 0.012 | 0.00 | 0.752 | 0.012 | 0.00 | 0.489 | 0.008 | 0.00 | 0.381 | 0.000 | 0.00 |
| f3n50+20 | 0.676 | 0.034 | 0.00 | 0.768 | 0.022 | 0.00 | 0.521 | 0.022 | 0.00 | 0.898 | 0.000 | 0.00 |
| f3n50+30 | 0.749 | 0.021 | 0.00 | 0.792 | 0.019 | 0.00 | 0.561 | 0.018 | 0.00 | 0.820 | 0.000 | 0.00 |
| f3n50+50 | 0.751 | 0.014 | 0.00 | 0.814 | 0.014 | 0.00 | 0.595 | 0.009 | 0.00 | 0.705 | 0.000 | 0.00 |
| f3n80+20 | 0.674 | 0.035 | 0.01 | 0.710 | 0.032 | 0.00 | 0.446 | 0.036 | 0.01 | 0.952 | 0.000 | 0.00 |
| f3n80+30 | 0.675 | 0.031 | 0.00 | 0.731 | 0.027 | 0.00 | 0.458 | 0.026 | 0.00 | 0.933 | 0.000 | 0.00 |
| f3n80+50 | 0.740 | 0.024 | 0.01 | 0.768 | 0.020 | 0.00 | 0.547 | 0.018 | 0.01 | 0.903 | 0.000 | 0.00 |
| f4n30+20 | 0.784 | 0.011 | 0.00 | 0.842 | 0.011 | 0.00 | 0.499 | 0.008 | 0.00 | 0.713 | 0.000 | 0.00 |
| f4n30+30 | 0.827 | 0.008 | 0.00 | 0.851 | 0.005 | 0.00 | 0.532 | 0.006 | 0.00 | 0.634 | 0.000 | 0.00 |
| f4n30+50 | 0.848 | 0.004 | 0.00 | 0.869 | 0.003 | 0.00 | 0.468 | 0.004 | 0.00 | 0.549 | 0.000 | 0.00 |
| f4n50+20 | 0.770 | 0.020 | 0.00 | 0.821 | 0.013 | 0.00 | 0.567 | 0.013 | 0.00 | 0.860 | 0.000 | 0.00 |
| f4n50+30 | 0.817 | 0.011 | 0.00 | 0.860 | 0.012 | 0.00 | 0.569 | 0.011 | 0.00 | 0.773 | 0.000 | 0.00 |
| f4n50+50 | 0.847 | 0.008 | 0.00 | 0.890 | 0.009 | 0.00 | 0.578 | 0.009 | 0.00 | 0.653 | 0.000 | 0.00 |
| f4n80+20 | 0.735 | 0.026 | 0.00 | 0.782 | 0.015 | 0.00 | 0.508 | 0.018 | 0.01 | 0.935 | 0.000 | 0.00 |
| f4n80+30 | 0.772 | 0.020 | 0.00 | 0.813 | 0.019 | 0.00 | 0.563 | 0.012 | 0.00 | 0.895 | 0.000 | 0.00 |
| f4n80+50 | 0.861 | 0.010 | 0.00 | 0.883 | 0.010 | 0.00 | 0.594 | 0.009 | 0.00 | 0.852 | 0.000 | 0.00 |
| f5n30+20 | 0.769 | 0.013 | 0.00 | 0.802 | 0.010 | 0.00 | 0.519 | 0.006 | 0.00 | 0.645 | 0.003 | 0.00 |
| f5n30+30 | 0.838 | 0.006 | 0.00 | 0.864 | 0.004 | 0.00 | 0.574 | 0.004 | 0.00 | 0.480 | 0.001 | 0.00 |
| f5n30+50 | 0.831 | 0.005 | 0.00 | 0.863 | 0.003 | 0.00 | 0.523 | 0.003 | 0.00 | 0.656 | 0.001 | 0.00 |
| f5n50+20 | 0.754 | 0.011 | 0.00 | 0.858 | 0.006 | 0.00 | 0.571 | 0.007 | 0.00 | 0.855 | 0.000 | 0.00 |
| f5n50+30 | 0.818 | 0.010 | 0.00 | 0.910 | 0.008 | 0.00 | 0.643 | 0.006 | 0.00 | 0.764 | 0.001 | 0.00 |
| f5n50+50 | 0.822 | 0.007 | 0.00 | 0.914 | 0.004 | 0.00 | 0.653 | 0.005 | 0.00 | 0.828 | 0.000 | 0.00 |
| f5n80+20 | 0.703 | 0.027 | 0.01 | 0.824 | 0.018 | 0.00 | 0.521 | 0.020 | 0.01 | 0.946 | 0.002 | 0.00 |
| f5n80+30 | 0.763 | 0.017 | 0.01 | 0.869 | 0.010 | 0.00 | 0.559 | 0.011 | 0.00 | 0.917 | 0.001 | 0.00 |
| f5n80+50 | 0.823 | 0.011 | 0.00 | 0.913 | 0.006 | 0.00 | 0.562 | 0.013 | 0.00 | 0.798 | 0.000 | 0.00 |
| Dataset | HV | GD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| KCDE | NSGA | MOEA/D | BCMA | DCMA | KCDE | NSGA | MOEA/D | BCMA | DCMA | |
| f3n30+20 | 0.85 | 0.10 | 0.10 | 0.08 | 0.04 | 0.13 | 1.06 | 1.02 | 1.00 | 1.40 |
| f3n30+30 | 0.86 | 0.11 | 0.11 | 0.09 | 0.05 | 0.10 | 1.02 | 0.96 | 0.99 | 1.35 |
| f3n30+50 | 0.86 | 0.12 | 0.11 | 0.10 | 0.06 | 0.09 | 0.95 | 0.91 | 1.00 | 1.26 |
| f3n50+20 | 0.86 | 0.08 | 0.07 | 0.07 | 0.03 | 0.15 | 1.11 | 1.04 | 1.03 | 1.50 |
| f3n50+30 | 0.88 | 0.09 | 0.09 | 0.07 | 0.03 | 0.11 | 1.06 | 0.99 | 1.03 | 1.45 |
| f3n50+50 | 0.88 | 0.10 | 0.10 | 0.08 | 0.05 | 0.07 | 0.98 | 0.92 | 1.01 | 1.39 |
| f3n80+20 | 0.87 | 0.06 | 0.06 | 0.05 | 0.02 | 0.18 | 1.16 | 1.08 | 1.07 | 1.56 |
| f3n80+30 | 0.87 | 0.06 | 0.07 | 0.06 | 0.02 | 0.15 | 1.14 | 1.03 | 1.05 | 1.54 |
| f3n80+50 | 0.89 | 0.08 | 0.08 | 0.07 | 0.03 | 0.09 | 1.02 | 0.98 | 1.03 | 1.51 |
| f4n30+20 | 0.87 | 0.10 | 0.10 | 0.07 | 0.04 | 0.10 | 1.03 | 0.99 | 1.07 | 1.27 |
| f4n30+30 | 0.90 | 0.11 | 0.11 | 0.08 | 0.05 | 0.07 | 0.98 | 0.95 | 1.04 | 1.22 |
| f4n30+50 | 0.91 | 0.13 | 0.12 | 0.10 | 0.06 | 0.06 | 0.95 | 0.90 | 1.01 | 1.16 |
| f4n50+20 | 0.88 | 0.07 | 0.07 | 0.05 | 0.02 | 0.12 | 1.09 | 1.02 | 1.13 | 1.46 |
| f4n50+30 | 0.90 | 0.09 | 0.08 | 0.06 | 0.03 | 0.09 | 1.06 | 0.97 | 1.12 | 1.37 |
| f4n50+50 | 0.90 | 0.10 | 0.10 | 0.08 | 0.05 | 0.06 | 0.99 | 0.92 | 1.09 | 1.27 |
| f4n80+20 | 0.87 | 0.06 | 0.06 | 0.05 | 0.02 | 0.16 | 1.14 | 1.07 | 1.14 | 1.51 |
| f4n80+30 | 0.89 | 0.06 | 0.06 | 0.05 | 0.02 | 0.12 | 1.09 | 1.02 | 1.14 | 1.47 |
| f4n80+50 | 0.91 | 0.08 | 0.08 | 0.06 | 0.03 | 0.08 | 1.03 | 0.97 | 1.14 | 1.41 |
| f5n30+20 | 0.84 | 0.09 | 0.09 | 0.06 | 0.05 | 0.17 | 1.09 | 1.05 | 1.07 | 1.36 |
| f5n30+30 | 0.90 | 0.11 | 0.11 | 0.08 | 0.05 | 0.08 | 1.03 | 0.97 | 1.05 | 1.32 |
| f5n30+50 | 0.91 | 0.13 | 0.12 | 0.09 | 0.04 | 0.07 | 0.97 | 0.92 | 1.04 | 1.40 |
| f5n50+20 | 0.87 | 0.07 | 0.07 | 0.05 | 0.03 | 0.15 | 1.12 | 1.08 | 1.15 | 1.47 |
| f5n50+30 | 0.91 | 0.08 | 0.08 | 0.06 | 0.04 | 0.08 | 1.06 | 1.01 | 1.13 | 1.42 |
| f5n50+50 | 0.91 | 0.10 | 0.09 | 0.07 | 0.03 | 0.05 | 1.00 | 0.96 | 1.11 | 1.49 |
| f5n80+20 | 0.85 | 0.05 | 0.05 | 0.04 | 0.02 | 0.20 | 1.20 | 1.14 | 1.17 | 1.54 |
| f5n80+30 | 0.89 | 0.06 | 0.06 | 0.04 | 0.03 | 0.11 | 1.12 | 1.08 | 1.15 | 1.51 |
| f5n80+50 | 0.91 | 0.07 | 0.07 | 0.05 | 0.04 | 0.07 | 1.05 | 1.00 | 1.12 | 1.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di, Y.; Deng, L.; Liu, T. A Knowledge-Based Cooperative Differential Evolution Algorithm for Energy-Efficient Distributed Hybrid Flow-Shop Rescheduling Problem. Processes 2023, 11, 755. https://doi.org/10.3390/pr11030755
Di Y, Deng L, Liu T. A Knowledge-Based Cooperative Differential Evolution Algorithm for Energy-Efficient Distributed Hybrid Flow-Shop Rescheduling Problem. Processes. 2023; 11(3):755. https://doi.org/10.3390/pr11030755
Chicago/Turabian StyleDi, Yuanzhu, Libao Deng, and Tong Liu. 2023. "A Knowledge-Based Cooperative Differential Evolution Algorithm for Energy-Efficient Distributed Hybrid Flow-Shop Rescheduling Problem" Processes 11, no. 3: 755. https://doi.org/10.3390/pr11030755