
Modeling Vehicle Insurance Adoption by Automobile Owners: A Hybrid Random Forest Classifier Approach

Abstract
:1. Introduction
- First, we combined PCA and SMOTE with an ML technique (random forest) and proposed a framework that significantly improves the prediction performance as compared with a conventional classifier. In doing so, we utilized PCA to perform feature selection to identify the essential features for enhancing accuracy. Additionally, we employed SMOTE to address the class imbalance in vehicle insurance by generating synthetic examples for the underrepresented minority class.
- Secondly, we propose the random forest classifier for prediction, developing a hybrid random forest classifier that produces high accuracy.
2. Literature Review
3. Method
3.1. Predicting Customer’s Adoption of Vehicle Insurance
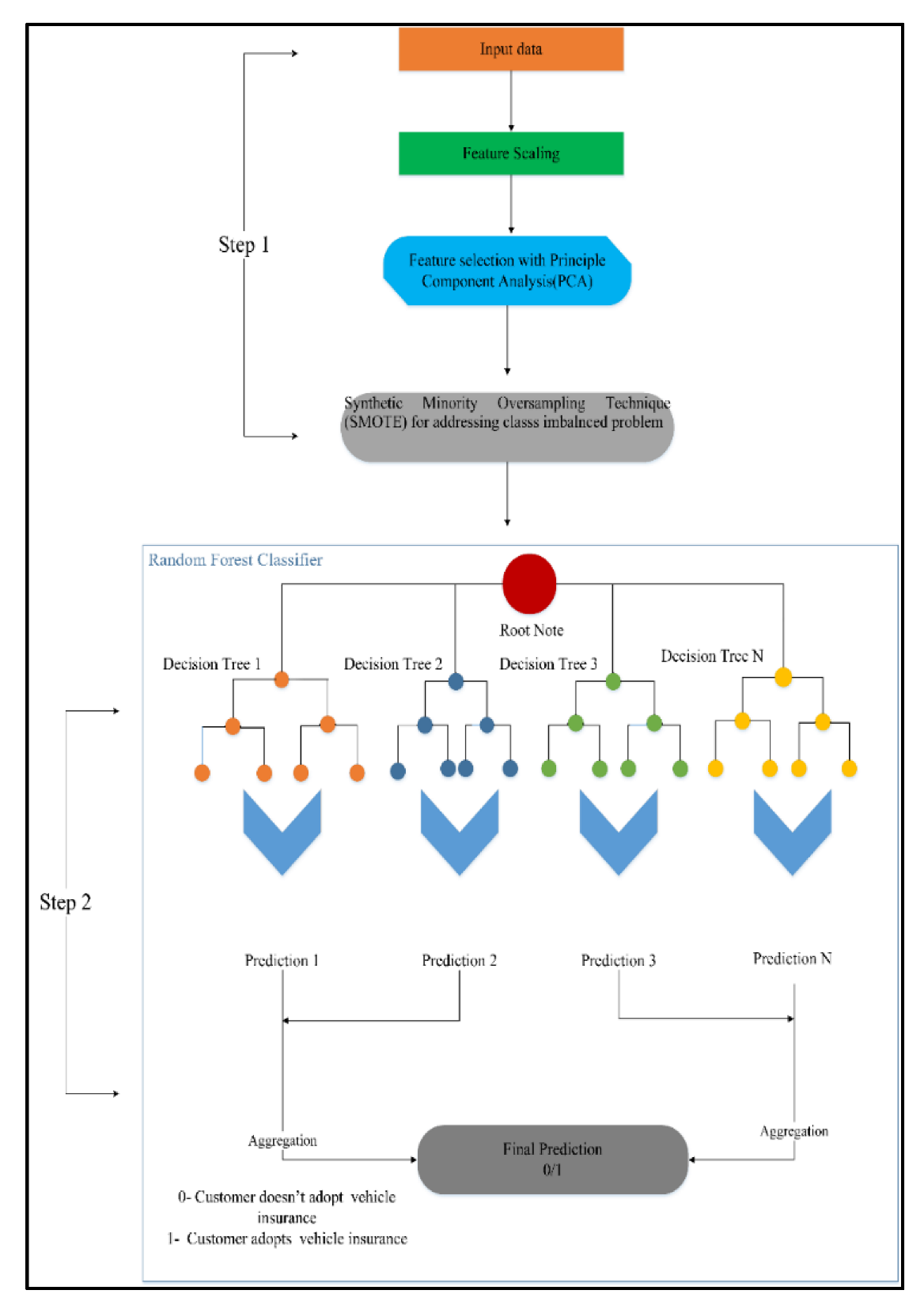
3.2. Conceptual Framework of Vehicle Insurance Prediction: PS-RandomForest
3.2.1. Vehicle Insurance Data Collection (Step 1)
3.2.2. Feature Scaling (Step 2)
3.2.3. Feature Selection with PCA (Step 3)
3.2.4. SMOTE (Step 4)
3.2.5. Random Forest Classifier (Step 5)
- Step 1—The first step selects random samples from the dataset.
- Step 2—In the next step, a decision tree is made for each sample, and a prediction result is obtained for every single tree.
- Step 3—The third step performs voting for every predicted result.
- Step 4—The algorithm selects the most voted prediction result as a final prediction result.
4. Empirical Study
4.1. PCA Results
4.2. SMOTE Results
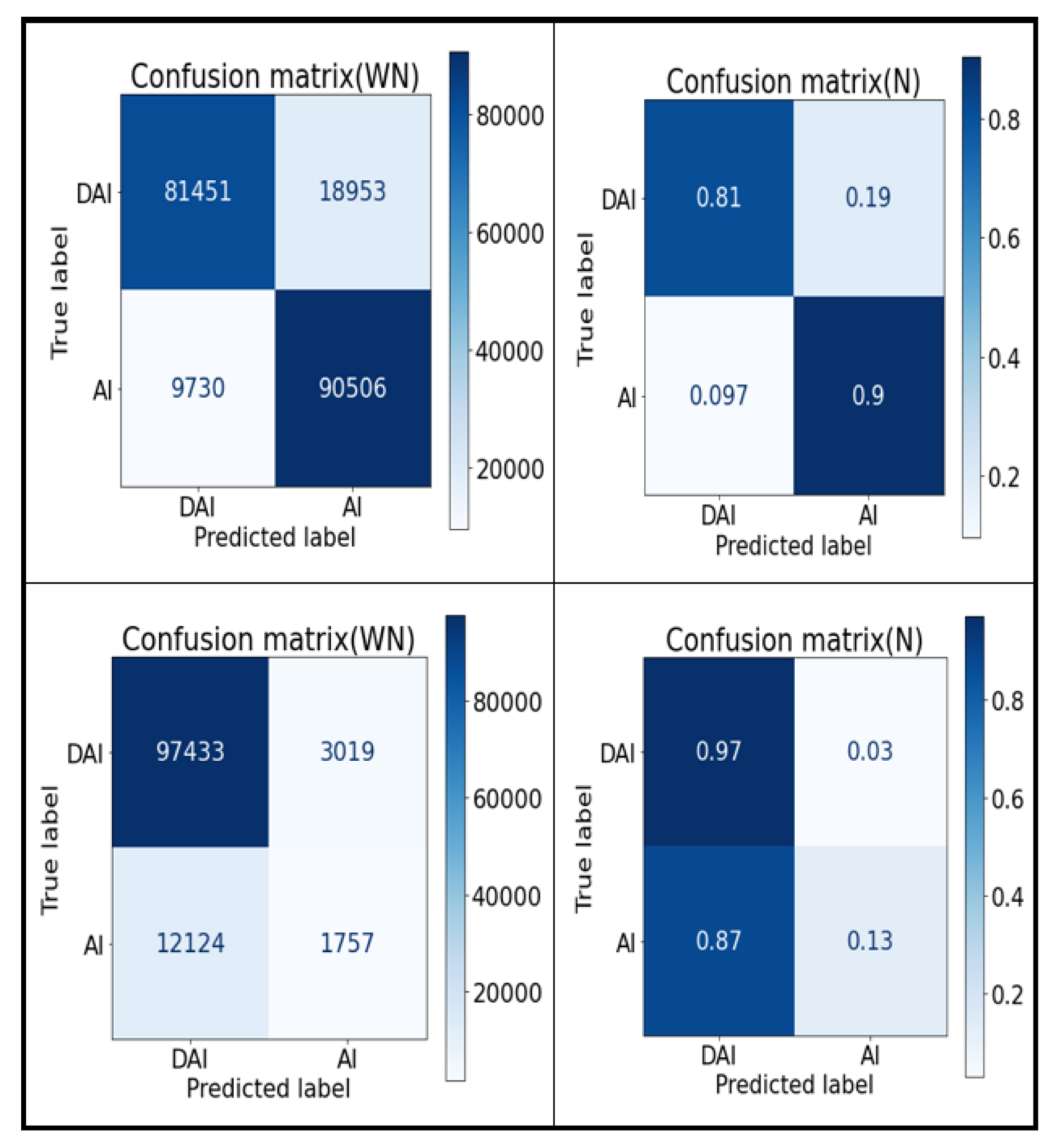
4.3. Performance Evaluation
AUC and ROC Curves
- Sensitivity/true-positive rate/recall: This metric evaluates the proportion of positive class that is correctly classified (i.e., customers who will adopt insurance are correctly identified by the classifier that they will adopt insurance).
- True-negative rate: This metric shows the negative class proportion correctly classified as negative with respect to all the negative classes (i.e., customers who will not adopt insurance are correctly identified by the classifier).
- False-positive rate: This rate shows the proportion of the negative class incorrectly classified as belonging to the positive class (i.e., customers who will not adopt insurance who are misclassified by the classifier that they will adopt insurance).
- False-negative rate: This rate shows the proportion of the positive class incorrectly classified as belonging to the negative class (i.e., customers who will adopt insurance who are misclassified by the classifier that they will not adopt insurance).
5. Conclusions, Implications, and Limitations of the Study
5.1. Conclusions
5.2. Implications for Managers
5.3. Limitations of the Study and Future Directions
- First, the generalization of the results might have suffered due to the configuration of the limited parameters (for instance, vehicle age, vehicle damage, annual premium and policy sales channel). Future studies may identify additional key parameters and develop more advanced models for vehicle insurance prediction.
- Second, the outcomes of this research are based on existing insurance data obtained from a previous study; therefore, the proposed model may be replicated with caution.
- Finally, the current study has not considered management’s willingness to invest in high-end technology. Future researchers may consider this important parameter to encourage insurance companies to allocate resources toward technology and data analytics so as to drive better decision making and improve revenue.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Global motor insurance market report. Growth, Trends, and forecast 2018–2024. 2019. Available online: https://www.researchandmarkets.com/reports/4771935/e-retail-market-growth-trends-and-forecast (accessed on 20 January 2022).
- Bastürk, F.H. Insurance Fraud: The Case in Turkey. In Contemporary Issues in Audit Management and Forensic Accounting; Grima, S., Boztepe, E., Baldacchino, P.J., Eds.; Emerald Publishing Limited: Bingley, UK, 2020; Volume 102, pp. 77–97. [Google Scholar] [CrossRef]
- Nasir, M.; Adil, M. Exploring the applicability of SERVPERF model in Indian two-wheeler industry: A CFA approach. Int. J. Product. Qual. Manag. 2020, 29, 329–354. [Google Scholar] [CrossRef]
- Dodge, E.; Gamez, C.; Jauregui, A.; Keenan, D.; MacDonald, D.; Richardson, C.; Moledina, A.; Shapiro, D. Principles of Micro-economics 2e. for AP® Courses; Rice University: Houston, TX, USA, 2016. [Google Scholar]
- Mau, S.; Pletikosa, I.; Wagner, J. Forecasting the next likely purchase events of insurance customers. Int. J. Bank Mark. 2018, 36, 0265–2323. [Google Scholar] [CrossRef]
- Adil, M.; Wu, J.-Z.; Chakrabortty, R.K.; Alahmadi, A.; Ansari, M.F.; Ryan, M.J. Attention-Based STL-BiLSTM Network to Forecast Tourist Arrival. Processes 2021, 9, 1759. [Google Scholar] [CrossRef]
- Di Franco, G.; Santurro, M. Machine learning, artificial neural networks and social research. Qual. Quant. Int. J. Methodol. 2020, 33, 2007851. [Google Scholar] [CrossRef]
- Schmidt, J.; Marques, M.R.G.; Botti, S. Recent advances and applications of machine learning in solid-state materials science. Nat. Partn. J. (Npj) Comput. Mater. 2019, 6, 19375. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, O.; Fatima-Zahra, B.; Ayoub, A.L.; Samir, B. Big Data technologies: A survey. J. King Saud Univ. 2018, 19, 171–209. [Google Scholar] [CrossRef]
- Attaran, M.; Deb, P. Machine learning: The new ‘big thing’ for competitive advantage. Int. J. Knowl. Eng. Data Min. 2018, 5, 277–305. [Google Scholar] [CrossRef]
- Dimiduk, D.M.; Holm, E.A.; Niezgoda, S.R. Perspectives on the Impact of Machine Learning, Deep Learning, and Artificial Intelligence on Materials, Processes, and Structures Engineering. Integr. Mater. Manuf. Innov. 2018, 7, 157–172. [Google Scholar] [CrossRef] [Green Version]
- Adil, M.; Ansari, M.F.; Alahmadi, A.; Wu, J.-Z.; Chakrabortty, R.K. Solving the problem of class imbalance in the prediction of hotel cancelations: A hybridized machine learning approach. Processes 2021, 9, 1713. [Google Scholar] [CrossRef]
- Parveen, A.; Inbarani, H.; Sathishkumar, E. Performance analysis of unsupervised feature selection methods. In Proceedings of the 2012 International Conference on Computing, Communication and Applications, Dindigul, India, 22–24 February 2012; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, SAI, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Chen, R.C.; Dewi, C.; Huang, S.W. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 42. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Weerasinghe, K.P.M.L.P.; Wijegunasekara, M.C. A comparative study of data mining algorithms in the prediction of auto insurance claims. Eur. Int. J. Sci. Technol. 2016, 5, 47–54. [Google Scholar]
- Smith, K.A.; Willis, R.J. An analysis of customer retention and insurance claim patterns using data mining: A case study. J. Oper. Res. Soc. 2017, 51, 532–541. [Google Scholar] [CrossRef]
- Thakur, S.S.; Singh, J.K. Prediction of Online Vehicle Insurance System using Decision Tree Classifier and Bayes Classifier–A Comparative Analysis. Int. J. Comput. Appl. 2014, 975, 8887. [Google Scholar]
- Pesantez-Narvaez, J.; Guillen, M.; Alcañiz, M. Predicting Motor Insurance Claims Using Telematics Data—XGBoost versus Logistic Regression. Risks 2019, 7, 70. [Google Scholar] [CrossRef] [Green Version]
- Neumann, L.; Nowak, R.M.; Okuniewski, R.; Wawrzyński, P. Machine Learning-based predictions of customers’ decisions in car insurance, Applied Artificial Intelligence. Appl. Artif. Intell. 2019, 33, 817–828. [Google Scholar] [CrossRef]
- Khalili-Damghani, K.; Abdi, F.; Abolmakarem, S. Solving customer insurance coverage recommendation problem using a two-stage clustering-classification model. Int. J. Manag. Sci. Eng. Manag. 2019, 14, 9–19. [Google Scholar] [CrossRef]
- Bian, Y.; Yang, C.; Zhao, J.L.; Liang, L. Good drivers pay less: A study of usage-based vehicle insurance models. Transp. Res. Part. A 2018, 107, 20–34. [Google Scholar] [CrossRef]
- Wu, C.-H.; Kao, S.-C.; Su, Y.-Y.; Wu, C.C. Targeting customers via discovery knowledge for the insurance industry. Expert Syst. Appl. 2005, 29, 291–299. [Google Scholar] [CrossRef]
- Kim, S.-Y.; Jung, T.-S.; Suh, E.-H.; Hwang, H.S. Customer segmentation and strategy development based on customer lifetime value: A case study. Expert Syst. Appl. 2006, 31, 101–107. [Google Scholar] [CrossRef]
- Kuo, R.J.; Lin, S.Y.; Shih, C.W. Mining association rules through integration of clustering analysis and ant colony system for health insurance database in Taiwan. Expert Syst. Appl. 2007, 33, 794–808. [Google Scholar] [CrossRef]
- Kumar, A. Health Insurance Cross Sell Prediction dataset. Available online: https://www.kaggle.com/anmolkumar/health-insurance-cross-sell-prediction (accessed on 13 February 2023).
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 1568–4946. [Google Scholar] [CrossRef]
- Christopher, B. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: New York, NY, USA, 2007. [Google Scholar]
- Le, T.; Vo, M.; Vo, B.; Lee, M.; Baik, S. A Hybrid Approach Using Oversampling Technique and Cost-Sensitive Learning for Bankruptcy Prediction. Complexity 2019, 2019, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Patel, H.; Prajapati, P. Study and analysis of Decision Tree based classification algorithms. Int. J. Comput. Sci. Eng. 2018, 6, 74–78. [Google Scholar] [CrossRef]
- Hassan, S.G.; Ahmed, S.; Iqbal, S.; Elahi, E.; Hasan, M.; Li, D.L.; Zhou, Z.; Abbas, A.; Song, C. Fish as a source of acoustic signal measurement in an aquaculture tank: Acoustic sensor based time frequency analysis. Int. J. Agric. Biol. Eng. 2019, 12, 110–117. [Google Scholar] [CrossRef] [Green Version]
- Sadiq, M.; Adil, M.; Khan, M.N. Automated banks’ service quality in developing economy: Empirical evidences from India. J. Serv. Oper. Manag. 2019, 33, 331–350. [Google Scholar] [CrossRef]
- Adil, M.; Nasir, M.; Sadiq, M.; Bharti, K. SSTQUAL model: Assessment of ATM service quality in an emerging economy. Int. J. Bus. Excell. 2020, 22, 114–138. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| List of Parameters | Parameter Value | Method |
|---|---|---|
| Criterion | (‘Gini’, ‘Entropy’) | Decision Tree |
| Min Samples Leaf | (1, 2, 3, 4, 5) | |
| Min Samples Split | (4, 5, 6, 7, 8) | |
| Max Features | (‘Auto’,’Log2′) | |
| Splitter | (‘Best’, ‘Random’) | |
| N_Estimators | (90, 100, 115) | Random Forest |
| Criterion | (‘Gini’, ‘Entropy’) | |
| Min Samples Leaf | (1, 2, 3, 4, 5) | |
| Min Samples_Split | (4, 5, 6, 7, 8) | |
| Max Features | (‘Auto’,’Log2′) |
| Predicted Class | |||
|---|---|---|---|
| Class 1 | Class 0 | ||
| Actual Class | Class 1 | E11 (True_positive) | E10 (False_positive) |
| Class 0 | E01 (False_negative) | E00 (True_negative) | |
| Methods | AUC Score |
|---|---|
| Decision Tree | 60.56 |
| Hybrid Decision Tree | 81.17 |
| Random Forest | 54.80 |
| PS-RandomForest (Ours) | 85.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uddin, M.; Ansari, M.F.; Adil, M.; Chakrabortty, R.K.; Ryan, M.J. Modeling Vehicle Insurance Adoption by Automobile Owners: A Hybrid Random Forest Classifier Approach. Processes 2023, 11, 629. https://doi.org/10.3390/pr11020629
Uddin M, Ansari MF, Adil M, Chakrabortty RK, Ryan MJ. Modeling Vehicle Insurance Adoption by Automobile Owners: A Hybrid Random Forest Classifier Approach. Processes. 2023; 11(2):629. https://doi.org/10.3390/pr11020629
Chicago/Turabian StyleUddin, Moin, Mohd Faizan Ansari, Mohd Adil, Ripon K. Chakrabortty, and Michael J. Ryan. 2023. "Modeling Vehicle Insurance Adoption by Automobile Owners: A Hybrid Random Forest Classifier Approach" Processes 11, no. 2: 629. https://doi.org/10.3390/pr11020629