
Establishment of Technical Standard Database for Surface Engineering Construction of Oil and Gas Field
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Research Framework
- (1)
- Identification and audit module: collecting and analyzing oil and gas surface engineering standard information, collecting scanned PDF files through OCR intelligent recognition technology, using text recognition OCR engine to scan the content of the document, converting it into a structured document that can be pulled for recognition and data extraction (editable PDF or WORD file), then reviewing and correcting it manually.
- (2)
- Disassemble module: The classification and grading of standards is the basis for realizing structured identification and storage. Research on the classification mechanism is carried out according to the basic attributes and keywords of standards; the classification includes manual classification and intelligent classification. And the grading includes the first-level title, second-level title, and third-level title. Then, the structured documents are manually disassembled, system-assisted disassembled, or intelligently disassembled, following the basic attributes of standards, clauses of standards, and keywords to form structured data. The standard keyword database formed after disassembly is used as the basic database of intelligent retrieval and matching.
- (3)
- Storage module: Establish a database of standards to realize the storage of structured standard forms.
- (4)
- Intelligent retrieval module: Based on knowledge graph technology, intelligent retrieval under different scenarios is realized, including two retrieval scenarios, three user-oriented retrieval methods, two retrieval mechanisms of the system, and the formation of different standard lists and clause lists. Natural language processing technology (NLP) is used to understand user intentions, reduce ambiguity, and improve retrieval matching degrees.
- (5)
- Intelligent push module: Based on the knowledge graph, intelligent push can be carried out from three dimensions of keyword matching degree, release time, and terms requirements, and can be applied to different application scenarios.
- (6)
- Knowledge graph technology module: The basic construction process of a knowledge graph includes data acquisition, knowledge extraction, knowledge fusion, knowledge processing, and Knowledge update. And we apply knowledge graph technology to intelligent retrieval and intelligent push of standards.
3. Basic Theory of Knowledge Graph
3.1. Data Acquisition
3.2. Knowledge Extraction
- (1)
- Entity extraction, also known as entity recognition (NER), aims to extract entity elements from the text and form knowledge (structured data) into the knowledge graph. The methods of entity extraction can be divided into rule-based entity extraction, supervised entity extraction, and unsupervised entity extraction. Alternative models include the hidden markov model (HMM), conditional random field (CRF) model, and neural network model. Commonly used methods include rule matching, machine learning, and deep learning. In this study, we employ a convolutional neural network (CNN) algorithm for entity recognition tasks using a dataset containing 300 standards. We divide the labeled data set into a training set, a validation set, and a test set at a ratio of 8:1:1. A multi-level convolutional neural network model with an embedding dimension set to 200, a dropout rate of 0.3, and batch size of 32 is constructed. The core feature of the model is a three-layer convolution operation, which uses convolution kernel sizes of 3, 4, and 5, respectively, to capture local features at different scales in the text. Each convolution is followed by a maximum pooling layer to preserve the most significant feature information. In addition, we set the initial learning rate to 0.001 and adopted the learning rate attenuation strategy to ensure smooth convergence of the model during training. To reduce the risk of overfitting, we introduce dropout regularization techniques and use ReLU activation functions to enhance the nonlinear capabilities of the model. During the training process, we use the cross entropy loss function to measure the prediction error of the model and use the stochastic gradient descent (SGD) optimizer to adjust the model parameters. The key parameters can be tested and adjusted many times to achieve the best performance. We use F1 scores, recall rates, and accuracy rates to evaluate the validity of the model. After model training, we achieved results of an F1 score of 0.6239, a recall rate of 0.5574, and an accuracy rate of 0.9729 on the training set. On the test set, we achieved results with an F1 score of 0.5849, a recall rate of 0.5137, and an accuracy rate of 0.9644. Finally, the extracted entities are mapped to the nodes of the knowledge graph.
- (2)
- Relation extraction (RE) is the core content of knowledge extraction. By obtaining a certain semantic relation or category of relation between entities, the entity pair is automatically identified, and the triplet formed by the relation between this pair of entities is connected. Recent studies on RE are mainly based on neural network methods, including CNN, recurrent neural network (RNN), attention mechanism (ATT), graph convolutional network (GCN), adversarial training (AT), reinforcement learning (RL), and entity-relationship joint extraction (JERE). In this study, convolutional neural networks are also used to extract the relationship between text content. The attention layer is added to improve the CNN model and improve the performance of relation extraction. Set the number of convolutional nuclei to 6, the embedding dimension to 300, the learning rate to 0.0005, and the dropout parameter to 0.5. In addition, this paper uses SAM as the weight distribution model in the Attention layer. The obtained data set with relational annotation is trained on the modified CNN model. After model training, we achieved the results of an F1 score of 0.8641, a recall rate of 0.9264, and an accuracy rate of 0.9348 on the training set. On the test set, we obtained the results of an F1 score of 0.9021, a recall rate of 0.8875, and an accuracy rate of 0.9176. The result shows that it has a good extraction effect and stability. After the model is trained, the extracted information is mapped to the “edge” of the knowledge graph.
- (3)
- Attribute extraction is the foundation of knowledge base construction and application, extracting attribute names and attribute values of entities from raw data of different information sources, constructing attribute lists of entities, forming complete entity concepts, and completing the entities. After completing entity identification and knowledge extraction by the above methods, this paper will manually extract the attributes of the entity identified by the algorithm and the extracted relationship, that is, by reading the standard text, if there is an attribute corresponding to the entity or the attribute corresponding to the relationship in the text, it will be extracted to make the knowledge expressed by the triplet more perfect.
3.3. Knowledge Fusion
3.4. Knowledge Processing
- (1)
- Ontology construction refers to the construction of the concept template of knowledge at the pattern layer, which standardizes the description of concepts and their relationships within a specified domain. The process includes two parts: concept extraction and inter-concept relationship extraction. According to the degree of automation of the construction process, it can be divided into manual construction, semi-automatic construction, and automatic construction. The purpose of ontology construction is to build a knowledge data model and hierarchical system; the main methods are manual editing, entity similarity, entity relationship automatic extraction, and so on.
- (2)
- Knowledge reasoning is to mine or infer unknown or implicit semantic relations because of the incompleteness of existing facts or relations in the knowledge graph. The objects of knowledge reasoning can be entities, relationships, and the structure of a knowledge graph. The main methods of knowledge reasoning include the method based on logical rules, the method based on distributed representation, and the method based on neural networks [25].
- (3)
- Quality assessment is usually carried out at the stage of knowledge extraction or fusion, and the confidence of knowledge is evaluated to retain the knowledge with high confidence and effectively guarantee the quality of the knowledge graph. The purpose is to improve the quality of knowledge samples, enhance the effect of knowledge extraction, and increase the effectiveness of the model.
3.5. Knowledge Update
4. Disassemble and Store
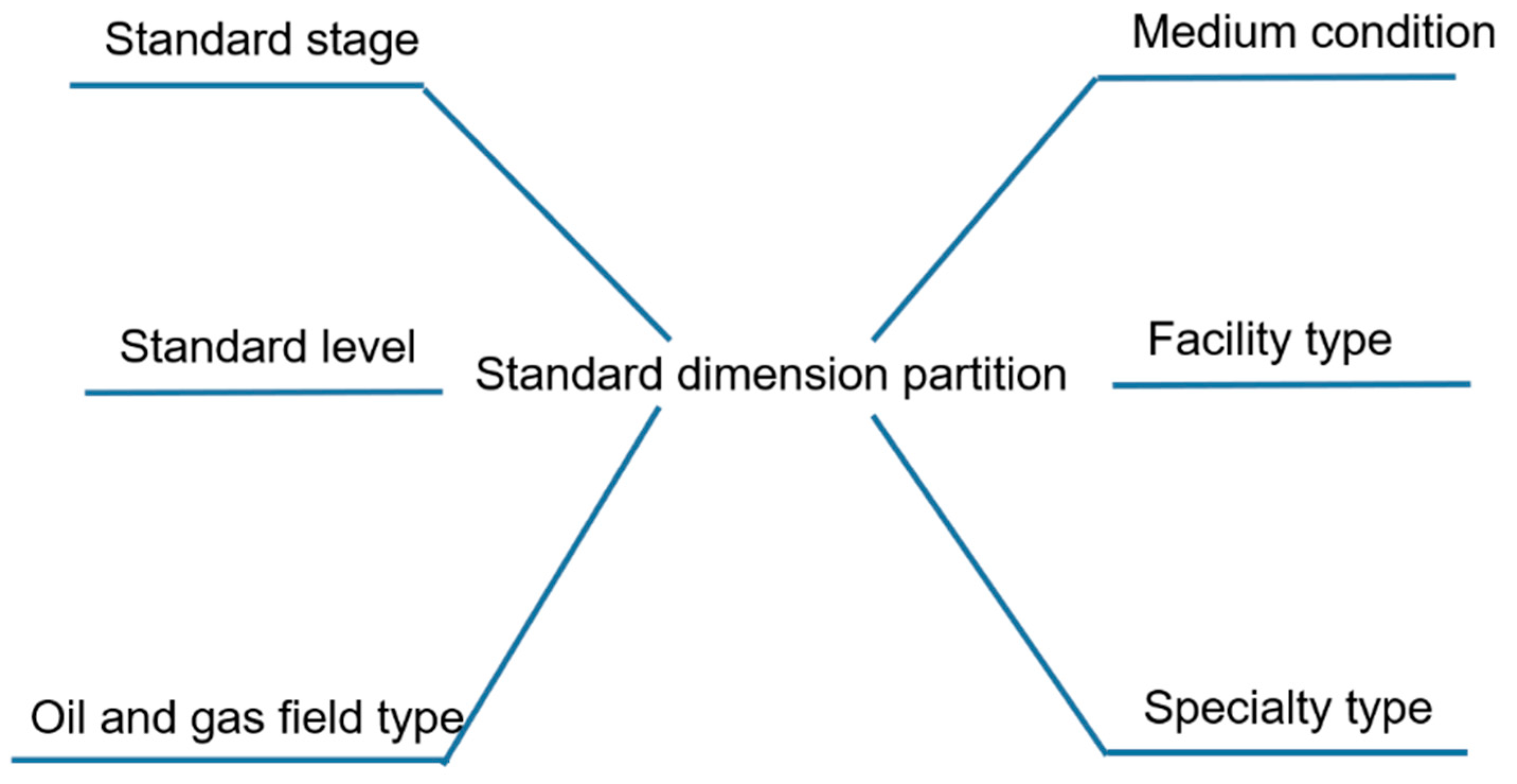
4.1. Classification and Grading of Standards
4.2. Disassembly of Standards
- (1)
- Disassemble the content
- (2)
- Manual disassembly
- (3)
- System assisted disassembly
- (4)
- Intelligent disassembly
4.3. Storage of Standards
- (1)
- Data knowledge storage
- (2)
- Construction of a knowledge map of standards
5. Intelligent Retrieval
- (1)
- The bottom layer is an intelligent retrieval storage system, including two-dimensional plane data, structured database, inter-entity index, and graph database of search objects.
- (2)
- The middle layer is the retrieval processing layer, including the construction of standard and normative knowledge graphs, index construction management, and content retrieval engine.
- (3)
- The presentation layer is the display of content retrieval results, which are sorted according to the keyword matching degree, release time, and terms requirements in the knowledge graph structure to reduce data overburden and improve the efficiency of data query in the system.
5.1. Similarity Retrieval
5.2. Search Dimensions
5.3. Search Method
- (1)
- Search based on classification
- (2)
- Search based on text name
- (3)
- Search based on keyword
- (4)
- Search based on mandatory clause
- (5)
- Search based on text attribute nodes
6. Intelligent Push
6.1. Recommendation Algorithm
6.2. Push Dimensions
6.3. Push Mode
- (1)
- Standard association push: Based on the standard classification knowledge graph, the relevant attributes of the retrieval object are searched upward according to the graph, and other standards that have “reference and supporting use” and the same classification attributes with the retrieval object are associated and recommended, and the recommendation ranking is comprehensive based on the number of matching dimensions.
- (2)
- User habit association push: Build the user habit knowledge graph, view the standard situation according to the user history, comprehensively recommend the standards with the most historical views and the most concerned types, and display the results in the form of a list, open the standards for reading.
- (3)
- Keyword association push: When the standard is read, other standards containing the keyword will be associated and pushed, and the results will be displayed in the form of a list. The standard can be read when opened.
- (4)
- Text mandatory clause association push: When the standard is read, other standards corresponding to the search object mandatory clause will be associated and pushed, and the results will be displayed in the form of a list. When reading standards, other standards containing the keyword will be associated and pushed, and the results will be displayed in the form of a list, which can be opened to read the standards.
- (5)
- The associated push of high-frequency search standards: According to the frequency of search standards and norms of all users of the system, the high-frequency standards and norms are associated and recommended.
7. Applications
8. Conclusions
- (1)
- This paper innovatively applies knowledge graph technology to the construction of a standard database. At the same time, the steps of constructing a knowledge graph and the main algorithms used in this paper are introduced. Through the construction of a knowledge graph, the retrieval efficiency and recommendation effect of standards are improved.
- (2)
- According to the properties and contents of the standards for oil and gas field surface engineering, this paper classifies the standards in six dimensions and introduces disassembly methods of structured documents. Finally, the methods and applications of intelligent search and intelligent push are introduced.
- (3)
- The research can provide technical support for the project management and quality control of oil and gas field surface construction projects and support the unified intelligent management of surface engineering in oil and gas field enterprises. It has good value in popularization and application and provides a reference for the construction of industry-standard databases and intelligent search and push.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, T. Practice and thinking of oil and gas industrial digitalization transformation. Oil Forum 2020, 39, 29–33. [Google Scholar]
- Su, J.; Yao, S.; Liu, H. Data Governance Facilitate Digital Transformation of Oil and Gas Industry. Front. Earth Sci. 2022, 10, 861091. [Google Scholar] [CrossRef]
- Jia, A.; Guo, J. Key technologies and understandings on the construction of smart fields. Pet. Explor. Dev. 2012, 39, 118–122. [Google Scholar] [CrossRef]
- Fang, Z.; Huan, Z.; Wang, Z.; Li, G.; Chen, R. Research on Action Layers and Application and Database Design of Safety Barrier in Petrochemical Plant. In Proceedings of the Pressure Vessels and Piping Conference, Online, 13–15 July 2021; American Society of Mechanical Engineers: New York, NY, USA, 2021; Volume 85314, p. V001T01A043. [Google Scholar]
- Wang, T.; Xuan, W.; Wang, X.; Ren, K. Overview of oil and gas pipeline failure database. In ICPTT 2013: Trenchless Technology; American Society of Civil Engineers: Reston, VA, USA, 2013; pp. 1161–1167. [Google Scholar]
- Bader, S.R.; Grangel-Gonzalez, I.; Nanjappa, P.; Vidal, M.E.; Maleshkova, M. A knowledge graph for industry 4.0. In Proceedings of the Semantic Web: 17th International Conference, ESWC 2020, Heraklion, Greece, 31 May–4 June 2020; Proceedings 17. Springer International Publishing: Cham, Switzerland, 2020; pp. 465–480. [Google Scholar]
- Yu, T.; Li, J.; Yu, Q.; Tian, Y.; Shun, X.; Xu, L.; Zhu, L.; Gao, H. Knowledge graph for TCM health preservation: Design, construction, and applications. Artif. Intell. Med. 2017, 77, 48–52. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Ma, X.; Chen, J.; Chen, J. Information extraction and knowledge graph construction from geoscience literature. Comput. Geosci. 2018, 112, 112–120. [Google Scholar] [CrossRef]
- Siddharth, L.; Blessing, L.T.; Wood, K.L.; Luo, J. Engineering knowledge graph from patent database. J. Comput. Inf. Sci. Eng. 2022, 22, 021008. [Google Scholar] [CrossRef]
- Hao, X.; Ji, Z.; Li, X.; Yin, L.; Liu, L.; Sun, M.; Liu, Q.; Yang, R. Construction and application of a knowledge graph. Remote Sens. 2021, 13, 2511. [Google Scholar] [CrossRef]
- Du, R.; Li, Y.; Shang, F.; Wu, Y. Study on ontology-based knowledge construction of petroleum exploitation domain. In Proceedings of the 2010 International Conference on Artificial Intelligence and Computational Intelligence, Sanya, China, 23–24 October 2010; Volume 2, pp. 42–46. [Google Scholar]
- Tang, X.; Feng, Z.; Xiao, Y.; Wang, M.; Ye, T.; Zhou, Y.; Meng, J.; Zhang, B.; Zhang, D. Construction and application of an ontology-based domain-specific knowledge graph for petroleum exploration and development. Geosci. Front. 2023, 14, 101426. [Google Scholar] [CrossRef]
- Ge, J.; Li, Z.; Li, T.; Qiang, B. Petroleum exploration domain ontology-based knowledge integration and sharing system construction. In Proceedings of the 2011 International Conference on Network Computing and Information Security, Guilin, China, 14–15 May 2011; Volume 1, pp. 84–88. [Google Scholar]
- Guan, Q.; Zhang, F.; Zhang, E. Application prospect of knowledge graph technology in knowledge management of oil and gas exploration and development. In Proceedings of the 2019 2nd International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 25–28 May 2019; pp. 161–166. [Google Scholar]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. (Csur) 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Gong, F.; Ma, Y.; Gong, W.; Li, X.; Li, C.; Yuan, X. Neo4j graph database realizes efficient storage performance of oilfield ontology. PLoS ONE 2018, 13, e0207595. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Wang, C.; Xiong, M.; Wang, H.; Yu, Y. Spark: Adapting keyword query to semantic search. In Proceedings of the International Semantic Web Conference, Busan, Korea, 11–15 November 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 694–707. [Google Scholar]
- Zhu, G.; Iglesias Fernandez, C.A. Sematch: Semantic entity search from knowledge graph. In Proceedings of the SumPre 2015—1st International Workshop on Summarizing and Presenting Entities and Ontologies, Portoroz, Slovenia, 1 June 2015. [Google Scholar]
- Huang, S.; Wang, Y.; Yu, X. Design and Implementation of Oil and Gas Information on Intelligent Search Engine Based on Knowledge Graph. J. Phys. Conf. Ser. 2020, 1621, 012010. [Google Scholar] [CrossRef]
- Wang, C.; Yu, H.; Wan, F. Information retrieval technology based on knowledge graph. In Proceedings of the 2018 3rd International Conference on Advances in Materials, Mechatronics and Civil Engineering (ICAMMCE 2018); Atlantis Press: Amsterdam, The Netherlands, 2018; pp. 291–296. [Google Scholar]
- Ehrlinger, L.; Wöß, W. Towards a definition of knowledge graphs. SEMANTiCS (Posters Demos SuCCESS) 2016, 48, 2. [Google Scholar]
- Peng, C.; Xia, F.; Naseriparsa, M.; Osborne, F. Knowledge graphs: Opportunities and challenges. Artif. Intell. Rev. 2023. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition and applications. arXiv 2020, arXiv:2002.00388. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, W.; Wang, Y.; Sun, Z. Constructing and inferring event logic cognitive graph in the field of big data. Sci. Sin. Informationis 2020, 50, 988–1002. (In Chinese) [Google Scholar]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Pplications 2020, 141, 112948. [Google Scholar] [CrossRef]
- Yao, S.; Wang, R.; Sun, S.; Bu, D.; Liu, J. Rule-guided joint embedding learning of knowledge graphs. J. Comput. Res. Dev. 2020, 57, 2514–2522. (In Chinese) [Google Scholar]
- Zhao, X.; Jia, Y.; Li, A.; Chang, C. A survey of multisource knowledge fusion technology. J. Yunnan Univ. Nat. Sci. Ed. 2020, 42, 65–79. (In Chinese) [Google Scholar]
- Vakulenko, S.; Fernandez Garcia, J.D.; Polleres, A.; de Rijke, M.; Cochez, M. Message passing for complex question answering over knowledge raphs. In Proceedings of the 28th ACM Int Conf on Information and Knowledge Management, Beijing, China, 3–7 November 2019; ACM: New York, NY, USA, 2019; pp. 1431–1440. [Google Scholar]
- Quijano-Sánchez, L.; Cantador, I.; Cortés-Cediel, M.E.; Gil, O. Recommender systems for smart cities. Inf. Syst. 2020, 92, 101545. [Google Scholar] [CrossRef]
- Catherine, R.; Cohen, W. Personalized recommendations using knowledge graphs: A probabilistic logic programming approach. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 325–332. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, T.; Dai, Z.; Huang, Z.; Liu, L.; Luo, M.; Wang, F.; Zhang, W.; Zhou, D.; Zhou, J. Establishment of Technical Standard Database for Surface Engineering Construction of Oil and Gas Field. Processes 2023, 11, 2831. https://doi.org/10.3390/pr11102831
Xia T, Dai Z, Huang Z, Liu L, Luo M, Wang F, Zhang W, Zhou D, Zhou J. Establishment of Technical Standard Database for Surface Engineering Construction of Oil and Gas Field. Processes. 2023; 11(10):2831. https://doi.org/10.3390/pr11102831
Chicago/Turabian StyleXia, Taiwu, Zhixiang Dai, Zhan Huang, Li Liu, Ming Luo, Feng Wang, Wei Zhang, Dan Zhou, and Jun Zhou. 2023. "Establishment of Technical Standard Database for Surface Engineering Construction of Oil and Gas Field" Processes 11, no. 10: 2831. https://doi.org/10.3390/pr11102831