
An Improved Line-Up Competition Algorithm for Unrelated Parallel Machine Scheduling with Setup Times
Abstract
:1. Introduction
- (1)
- An improved queuing competition algorithm is proposed to handle the UPMST problem.
- (2)
- A new heuristic artifact allocation rule is proposed for the research problem.
- (3)
- Different mutation strategies are proposed to execute different mutation strategies by giving different mutation probabilities for families and parents in different positions.
- (4)
- Its effectiveness and performance are verified by improving the algorithm to improve its search accuracy and speed.
2. Problem Formulation
2.1. Problem Description
- (1)
- All processing parameters are deterministic.
- (2)
- The setup time in a machine is independent of job order and properties.
- (3)
- Machine malfunction will not occur.
- (4)
- Unlimited storage capacity between stages.
- (5)
- There are multiple machines in each stage, and the production capacity of each machine is different, which means that the actual processing time of each job is different.
- (6)
- The job cannot be interrupted once machining has started.
- (7)
- A machine can handle only one job at a time.
- (8)
- A job can only be processed on one machine at a time.
2.2. Mathematical Model
2.2.1. Objective Function
2.2.2. Heuristic Order Allocation Rules
- (1)
- Select the machine with the shortest job sequence change over time.
- (2)
- Select the machine with the shortest job processing time.
- (3)
- Select the machine that can process jobs at the earliest.
- (4)
- Select the machine with the largest processing time.
- (5)
- Select the machine with the largest current time.
- (6)
- Select the machine with the smallest sum of job processing time and current time of the machine.
- (7)
- Select the machine with the maximum sum of job processing time and machine current time.
- (8)
- Select the machine that has the smallest sum of job sequence transition time and processing time.
- (9)
- Select the machine that has the smallest sum of job sequence transition time and current machine time.
- (10)
- Select the machine with the smallest job completion time. In the job allocation process, if a certain rule is used to obtain multiple machinable machines, any one of them can be selected to process the current job.
2.2.3. Job-Machine Allocation Steps for UPMST Scheduling Problems
| Algorithm 1: Job-machine assignment process |
- (1)
- At the initial moment, the current available time of each machine is 0, and the job number of all machines currently completed is set to be 0, and all jobs are in the first production stage;
- (2)
- The production sequence P of the job is taken, and the job to be processed is processed in order. According to the selected job allocation rules, the machine set that can be used in the current production stage j of the job is obtained so as to select the most suitable machine k to process the job;
- (3)
- Determine the start processing time and completion time of job on machine k;
- (4)
- The completion time of job on machine k is recorded as the current available time of machine k;
- (5)
- Record the completion time of the current production stage of the job ;
- (6)
- Recording the current completed job number on machine k;
- (7)
- Judging whether is the last job of the production sequence, if so, continue the following steps to complete the scheduling process, and if not, return to step (2), and then arrange the production of the next job;
- (8)
- Arrange the completion time of the jobs in the current stage j in ascending order to obtain the production sequence of the jobs in the next stage, and the completion time of the job at this stage j is regarded as the release time of the virtual job at the beginning of the next process;
- (9)
- Determine whether the current production stage j is the last production process; if so, complete the job allocation, otherwise return to (2), and continue to arrange the job production in the next stage.
3. Proposed Improved LCA
3.1. Original LCA
- (1)
- Use random or other methods to generate n groups of mixed sequences consisting of all job production sequences and jobs using job assignment rules at each stage to form n initial populations;
- (2)
- Calculate the scheduling objective function corresponding to each mixed sequence, and arrange each mixed sequence in ascending or descending order according to the fitness value;
- (3)
- According to the sorting result, separate the production sequence and the job assignment rule set in the mixed sequence to implement the mutation strategy, and obtain the corresponding m sub-generation mixed sequences;
- (4)
- Comparing the fitness values of the mixed sequences of the descendants of each family and the mixed sequences of the parents, in turn, and retaining the optimal individual as the parent to participate in the next round of competition for a platooning position;
- (5)
- Judge whether the evolution reaches the given termination condition; if not, return to step (2); if it is reached, stop the evolution.
3.2. Improved LCA
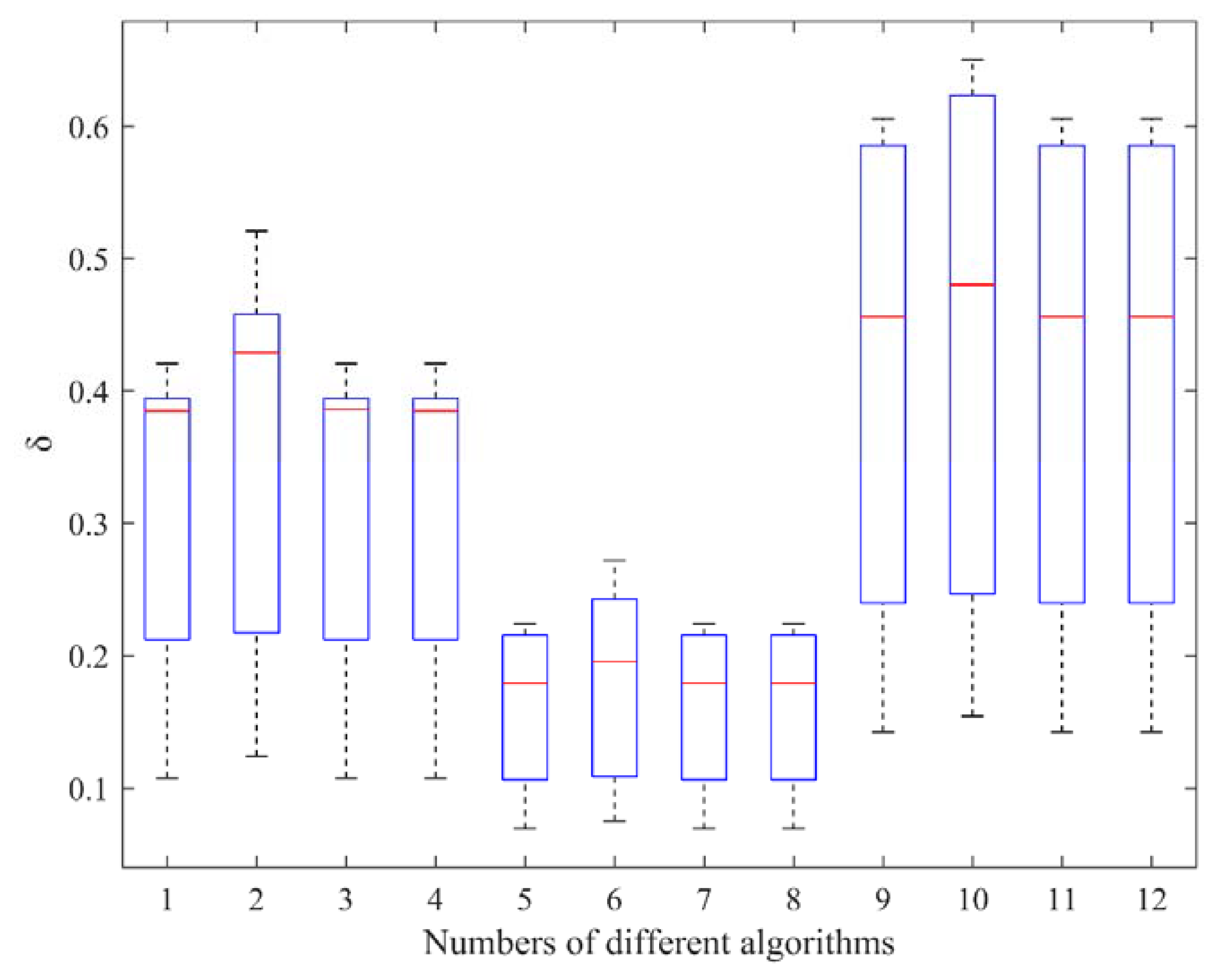
4. Computational Experiments
4.1. Single-Stage UPMST Scheduling
4.2. Multi-Stage UPMST Scheduling
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lapczynska, D.; Lapczynski, K.; Burduk, A.; Machado, J. Solving the problem of scheduling the production process based on heuristic algorithms. J. Univers. Comput. Sci. 2022, 28, 292–310. [Google Scholar] [CrossRef]
- Goli, A.; Tirkolaee, E.B.; Aydın, N.S. Fuzzy Integrated Cell Formation and Production Scheduling Considering Automated Guided Vehicles and Human Factors. Trans. Fuzy Syst. 2021, 29, 3686–3695. [Google Scholar] [CrossRef]
- Ezugwu, A.E. Advanced discrete firefly algorithm with adaptive mutation-based neighborhood search for scheduling unrelated parallel machines with sequence-dependent setup times. Int. J. Intell. Syst. 2022, 37, 4612–4653. [Google Scholar] [CrossRef]
- Cheng, C.Y.; Pourhejazy, P.; Ying, K.C.; Li, S.F.; Chang, C.W. Learning-Based Metaheuristic for Scheduling Unrelated Parallel Machines With Uncertain Setup Times. IEEE Access 2020, 8, 74065–74082. [Google Scholar] [CrossRef]
- Rakovitis, N.; Li, D.; Zhang, N.; Li, J.; Zhang, L.; Xiao, X. Novel approach to energy-efficient flexible job-shop scheduling problems. Energy 2022, 238, 121773. [Google Scholar] [CrossRef]
- Tadumadze, G.; Emde, S.; Diefenbach, H. Exact and heuristic algorithms for scheduling jobs with time windows on unrelated parallel machines. OR Spectr. 2020, 42, 461–497. [Google Scholar] [CrossRef]
- Fanjul-Peyro, L. Models and an exact method for the unrelated parallel machine scheduling problem with setups and resources. Expert Syst. Appl. X 2020, 5, 100022. [Google Scholar] [CrossRef]
- Yunusoglu, P.; Topaloglu Yildiz, S. Constraint programming approach for multi-resource-constrained unrelated parallel machine scheduling problem with sequence-dependent setup times. Int. J. Prod. Res. 2022, 60, 2212–2229. [Google Scholar] [CrossRef]
- Vélez-Gallego, M.C.; Maya, J.; Montoya-Torres, J.R. A beam search heuristic for scheduling a single machine with release dates and sequence dependent setup times to minimize the makespan. Comput. Oper. Res. 2016, 73, 132–140. [Google Scholar] [CrossRef]
- Laha, D.; Gupta, J.N.D. An improved cuckoo search algorithm for scheduling jobs on identical parallel machines. Comput. Ind. Eng. 2018, 126, 348–360. [Google Scholar] [CrossRef]
- Arnaout, J.; Musa, R.; Rabadi, G. Ant colony optimization algorithm to parallel machine scheduling problem with setups. In Proceedings of the 2008 IEEE International Conference on Automation Science and Engineering, Arlington, VA, USA, 23–26 August 2008; pp. 578–582. [Google Scholar]
- Arnaout, J.-P. A worm optimization algorithm to minimize the makespan on unrelated parallel machines with sequence-dependent setup times. Ann. Oper. Res. 2020, 285, 273–293. [Google Scholar] [CrossRef] [Green Version]
- Ying, K.-C.; Lee, Z.-J.; Lin, S.-W. Makespan minimization for scheduling unrelated parallel machines with setup times. J. Intell. Manuf. 2012, 23, 1795–1803. [Google Scholar] [CrossRef]
- Avalos-Rosales, O.; Angel-Bello, F.; Alvarez, A. Efficient metaheuristic algorithm and re-formulations for the unrelated parallel machine scheduling problem with sequence and machine-dependent setup times. Int. J. Adv. Manuf. Technol. 2015, 76, 1705–1718. [Google Scholar] [CrossRef]
- Santos, H.G.; Toffolo, T.A.M.; Silva, C.L.T.F.; Vanden Berghe, G. Analysis of stochastic local search methods for the unrelated parallel machine scheduling problem. Int. Trans. Oper. Res. 2019, 26, 707–724. [Google Scholar] [CrossRef]
- Lin, D.-Y.; Huang, T.-Y. A Hybrid Metaheuristic for the Unrelated Parallel Machine Scheduling Problem. Mathematics 2021, 9, 768. [Google Scholar] [CrossRef]
- Chen, C.; Fathi, M.; Khakifirooz, M.; Wu, K. Hybrid tabu search algorithm for unrelated parallel machine scheduling in semiconductor fabs with setup times, job release, and expired times. Comput. Ind. Eng. 2022, 165, 107915. [Google Scholar] [CrossRef]
- Huang, X.; Chen, L.; Zhang, Y.; Su, S.; Lin, Y.; Cao, X. Improved firefly algorithm with courtship learning for unrelated parallel machine scheduling problem with sequence-dependent setup times. J. Cloud Comput. 2022, 11, 9. [Google Scholar] [CrossRef]
- Fang, W.; Zhu, H.; Mei, Y. Hybrid meta-heuristics for the unrelated parallel machine scheduling problem with setup times. Knowl. Based Syst. 2022, 241, 108193. [Google Scholar] [CrossRef]
- Pei, Z.; Wan, M.; Wang, Z. A new approximation algorithm for unrelated parallel machine scheduling with release dates. Ann. Oper. Res. 2020, 285, 397–425. [Google Scholar] [CrossRef]
- Lei, D.; Yang, H. Scheduling unrelated parallel machines with preventive maintenance and setup time: Multi-sub-colony artificial bee colony. Appl. Soft Comput. 2022, 125, 109154. [Google Scholar] [CrossRef]
- Moser, M.; Musliu, N.; Schaerf, A.; Winter, F. Exact and metaheuristic approaches for unrelated parallel machine scheduling. J. Sched. 2022, 25, 507–534. [Google Scholar] [CrossRef]
- Yan, L.; Ma, D. A new algorithm for global optimization search line-up competition algorithm (I) solving nonlinear programming and mixed-integer nonlinear programming problem. CIESC J. 1999, 50, 663–670. [Google Scholar]
- Shi, B.; Yan, L. Scheduling of multi-purpose batch process with parallel units. CIESC J. 2010, 61, 2875–2880. [Google Scholar]
- Helal, M.; Rabadi, G.; Al-Salem, A. A tabu search algorithm to minimize the makespan for the unrelated parallel machines scheduling problem with setup times. Int. J. Oper. Res. 2006, 3, 182–192. [Google Scholar]
- Rabadi, G.; Moraga, R.J.; Al-Salem, A. Heuristics for the unrelated parallel machine scheduling problem with setup times. J. Intell. Manuf. 2006, 17, 85–97. [Google Scholar] [CrossRef]
- Arnaout, J.-P.; Musa, R.; Rabadi, G. A two-stage Ant Colony optimization algorithm to minimize the makespan on unrelated parallel machines—Part II: Enhancements and experimentations. J. Intell. Manuf. 2014, 25, 43–53. [Google Scholar] [CrossRef]
- Scheduling Research. Available online: http://schedulingresearch.com/ (accessed on 10 May 2022).
- Arnaout, J.-P.; Rabadi, G.; Musa, R. A two-stage ant colony optimization algorithm to minimize the makespan on unrelated parallel machines with sequence-dependent setup times. J. Intell. Manuf. 2010, 21, 693–701. [Google Scholar] [CrossRef]
- Larbi, R.; Abrar, K.; Nadjib, B. Scheduling aluminum billet casting lines: A case study. J. Ind. Intell. Inform 2016, 4, 257–262. [Google Scholar] [CrossRef]
- Xu, X.; Yin, E.; Zou, F. Researches on optimal scheduling for aluminum industry continuous casting and rolling production. In Proceedings of the 2010 IEEE International Conference on Intelligent Computing and Intelligent Systems, Xiamen, China, 29–31 October 2010; pp. 348–352. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nomenclature | |
|---|---|
| Sets | |
| N | All jobs |
| M | Set of all machines |
| S | Set of operations that jobs need to be processed |
| Set of machines that can process i | |
| Set of machines that can process i at stage s | |
| Indices | |
| i | Jobs |
| k | Machines |
| j | Stages |
| Machines selected with heuristic job assignment rules | |
| Parameters | |
| Completion time of the most recently processed job on machine k | |
| The last processed job number on machine k | |
| Virtual release time of job i at stage j | |
| Release time of job i | |
| Processing time of job i on machine k | |
| Relative sequential transition time between jobs i and | |
| Completion time of job i on machine | |
| Start time of job i on machine | |
| Completion time of workpiece i on stage s | |
| Variables | |
| Job allocation rules used in stage s | |
| Production sequence of job | |
| Production sequence of jobs sorted by completion time | |
| The most suitable machine is obtained by evaluating each machine of a job according to a job assignment rule |
| M | N | Balanced | Dominant | Dominant | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MR | TS | ACO | ACOII | MR | TS | ACO | ACOII | MR | TS | ACO | ACOII | ||
| 2 | 6 | 0.212 | 0.217 | 0.212 | 0.212 | 0.145 | 0.149 | 0.145 | 0.145 | 0.306 | 0.310 | 0.306 | 0.306 |
| 7 | 0.165 | 0.177 | 0.165 | 0.165 | 0.103 | 0.107 | 0.103 | 0.103 | 0.223 | 0.230 | 0.223 | 0.223 | |
| 8 | 0.122 | 0.131 | 0.121 | 0.121 | 0.106 | 0.109 | 0.106 | 0.106 | 0.240 | 0.246 | 0.240 | 0.240 | |
| 9 | 0.120 | 0.131 | 0.120 | 0.120 | 0.095 | 0.100 | 0.095 | 0.095 | 0.186 | 0.196 | 0.186 | 0.186 | |
| 10 | 0.108 | 0.124 | 0.108 | 0.108 | 0.075 | 0.081 | 0.075 | 0.075 | 0.192 | 0.199 | 0.192 | 0.192 | |
| 11 | 0.410 | 0.449 | 0.410 | 0.410 | 0.069 | 0.075 | 0.069 | 0.069 | 0.142 | 0.154 | 0.142 | 0.142 | |
| 4 | 6 | 0.386 | 0.458 | 0.386 | 0.386 | 0.223 | 0.237 | 0.223 | 0.223 | 0.593 | 0.633 | 0.593 | 0.593 |
| 7 | 0.386 | 0.458 | 0.386 | 0.386 | 0.222 | 0.257 | 0.222 | 0.222 | 0.561 | 0.604 | 0.561 | 0.561 | |
| 8 | 0.392 | 0.428 | 0.392 | 0.392 | 0.215 | 0.226 | 0.215 | 0.215 | 0.558 | 0.600 | 0.558 | 0.558 | |
| 9 | 0.292 | 0.290 | 0.289 | 0.289 | 0.141 | 0.139 | 0.141 | 0.141 | 0.360 | 0.361 | 0.360 | 0.360 | |
| 10 | 0.262 | 0.270 | 0.262 | 0.262 | 0.149 | 0.154 | 0.149 | 0.149 | 0.332 | 0.337 | 0.332 | 0.332 | |
| 11 | 0.234 | 0.261 | 0.234 | 0.234 | 0.136 | 0.164 | 0.138 | 0.136 | 0.324 | 0.346 | 0.324 | 0.324 | |
| 6 | 8 | 0.420 | 0.467 | 0.420 | 0.420 | 0.224 | 0.240 | 0.224 | 0.224 | 0.606 | 0.634 | 0.606 | 0.606 |
| 9 | 0.411 | 0.477 | 0.411 | 0.411 | 0.222 | 0.252 | 0.222 | 0.222 | 0.593 | 0.637 | 0.593 | 0.593 | |
| 10 | 0.383 | 0.459 | 0.386 | 0.383 | 0.213 | 0.249 | 0.213 | 0.213 | 0.585 | 0.650 | 0.585 | 0.585 | |
| 11 | 0.391 | 0.521 | 0.393 | 0.391 | 0.209 | 0.272 | 0.209 | 0.209 | 0.552 | 0.623 | 0.552 | 0.552 | |
| 8 | 10 | 0.394 | 0.430 | 0.394 | 0.394 | 0.208 | 0.229 | 0.209 | 0.208 | 0.583 | 0.601 | 0.583 | 0.583 |
| 11 | 0.416 | 0.435 | 0.416 | 0.416 | 0.215 | 0.242 | 0.215 | 0.215 | 0.587 | 0.618 | 0.587 | 0.587 | |
| Average | 0.299 | 0.338 | 0.299 | 0.299 | 0.162 | 0.179 | 0.162 | 0.162 | 0.408 | 0.433 | 0.408 | 0.408 | |
| Paired t Tests | Mean Difference (MD) | SD | t Stat | Two-Tailed p | 95% CI on MD | |
|---|---|---|---|---|---|---|
balanced | TS-ACOII | 7.448 | 9.543 | 12.825 | [6.305,8.592] | |
| ACOII-MR | −0.067 | 0.778 | −1.408 | 0.160 | [−0.160,0.027] | |
| MR-ILCA | 70.463 | 5.410 | 214.015 | [69.815,71.111] | ||
| ACO-ILCA | 70.452 | 5.328 | 217.295 | [69.814,71.090] | ||
dominant | TS-ACOII | 6.759 | 9.710 | 11.438 | [5.596,7.923] | |
| ACOII-MR | −0.015 | 0.243 | −1.000 | 0.318 | [−0.044,0.014] | |
| MR-ILCA | 72.848 | 6.933 | 172.662 | [72.017,73.679] | ||
| ACO-ILCA | 72.911 | 6.899 | 173.653 | [72.084,73.738 | ||
dominant | TS-ACOII | 8.063 | 9.922 | 13.353 | [6.874,9.252] | |
| ACOII-MR | −0.015 | 0.243 | −1.000 | 0.318 | [−0.044,0.014] | |
| MR-ILCA | 146.993 | 8.432 | 286.460 | 0.000 | [145.982,148.003] | |
| ACO-ILCA | 146.996 | 8.436 | 286.325 | 0.000 | [145.986,148.007] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Shi, B. An Improved Line-Up Competition Algorithm for Unrelated Parallel Machine Scheduling with Setup Times. Processes 2022, 10, 2676. https://doi.org/10.3390/pr10122676
Xu Y, Shi B. An Improved Line-Up Competition Algorithm for Unrelated Parallel Machine Scheduling with Setup Times. Processes. 2022; 10(12):2676. https://doi.org/10.3390/pr10122676
Chicago/Turabian StyleXu, Yuting, and Bin Shi. 2022. "An Improved Line-Up Competition Algorithm for Unrelated Parallel Machine Scheduling with Setup Times" Processes 10, no. 12: 2676. https://doi.org/10.3390/pr10122676